最近读了一篇文章《Image-Question-Answer Synergistic Network for Visual Dialog》,下面是我看完文章对文章的一点理解
一、文章摘要
图像,问题(与取消引用的历史记录相结合)以及相应的答案是视觉对话的三个重要组成部分。经典的可视对话系统集成了图像,问题和历史记录,以搜索或生成最佳匹配的答案,因此,这种方法极大地忽略了答案的作用。在本文中,作者设计了一种新颖的图像问题-答案协同网络,以重视答案在精确视觉对话中的作用。将传统的一阶段解决方案扩展为两阶段解决方案。在第一阶段,根据候选答案与图像和问题对的相关性对候选答案进行粗略打分。之后,在第二阶段,通过与图像和问题的协同作用,重新排列具有较高正确性的答案。在 Visual Dialog v1.0 数据集上,所提出的协同网络增强了判别性可视对话模型,以实现 57.88%的标准化折现累计增益的最新水平。配备拟议技术的生成可视对话模型也显示出可喜的改进。
二、文章介绍
视觉对话是计算机视觉与自然语言处理之间交集的新兴研究主题。一个传统的视觉对话如下
可视化对话任务也可以被视为:
(i)可视化基础,它将定位的边界框中的可视化信息进一步转换为人类语言;
(ii)视觉问答(VQA),其中包括额外的对话历史记录和标题作为输入;
(iii)图片说明,它不仅基于视觉信息而且还基于历史和问题生成描述。
一般的可视对话模型具有两个组件:将输入(例如 图像和问题)嵌入向量中并融合在一起以创建统一表 示形式的编码器,以及将编码后的向量直接转换为单 词或者对候选答案进行排序的解码器,根据不同的解码器,可视对话系统可以分为两大类:生成模型和判别模型。生成模型通常采用 seq2seq或高级强化学习技术来生成答案集(通常是单词),而判别模型则是计算候选答案和模型输出之间的相似度(通过LSTM能够理解句子)
为了突出答案的作用及其在可视对话框中与其他成分(例如,图像和问题)的集成,我们提出了一个图像问题-答案协同网络。将由编码器和解码器组成的传统的一级模型扩展为包含一级( primary stage)和协同级(synergistic stage)的两级模型,primary stage会为每个候选答案进行粗略评分,synergistic stage会基于一些准则而计算每个答案与图像协同的相关性的概率,如下图所示:
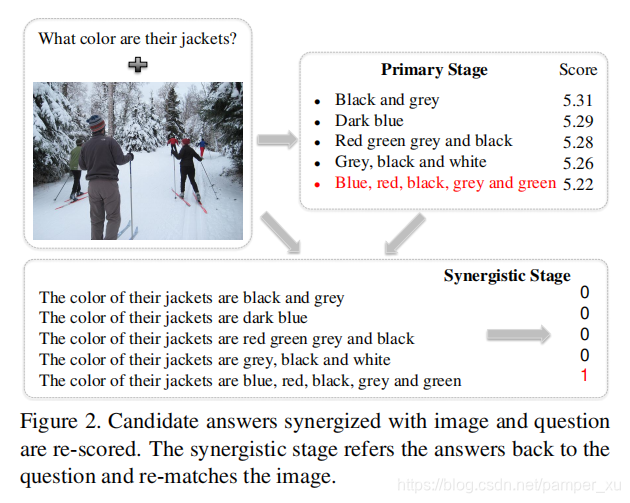
这个过程与人类的经验相似,我们通常首先会排除明显错误的答案,然后再付出更多的努力来比较其余的答案。选择正确的答案,另外,在一个判别模型的初级阶段就解决了类别不平衡问题。例如大量负样本会影响loss函数,因此作者引入了一个temperature factor以改进loss函数。最后,作者基于Visual Dialog v1.0数据集对模型进行了评估。相较于一般的没有修正loss的non-balanced model,修正后在第一阶段和第二阶段都得到了提高
三、相关工作
视觉问答Visual Question Answering(VQA):VQA 是在查询图像以生成文本答案时执行的第一项任务。这是一个分类问题,其中候选答案仅限于数据集中出现的最常见答案。当前模型
可以分为三大类:早期融合模型,后期融合模型和基于外部知识的模型。
视觉对话Visual Dialog:将单轮问答扩展到多轮问答。提供了三种编码方法作为基准,即后期融合(late fusion),分层循环编码器(hierarchical recurrent encoder),以及记忆网络(the memory network),以及两种解码方法:LSTM 和 softmax。
四、协同网络(Synergistic Network)
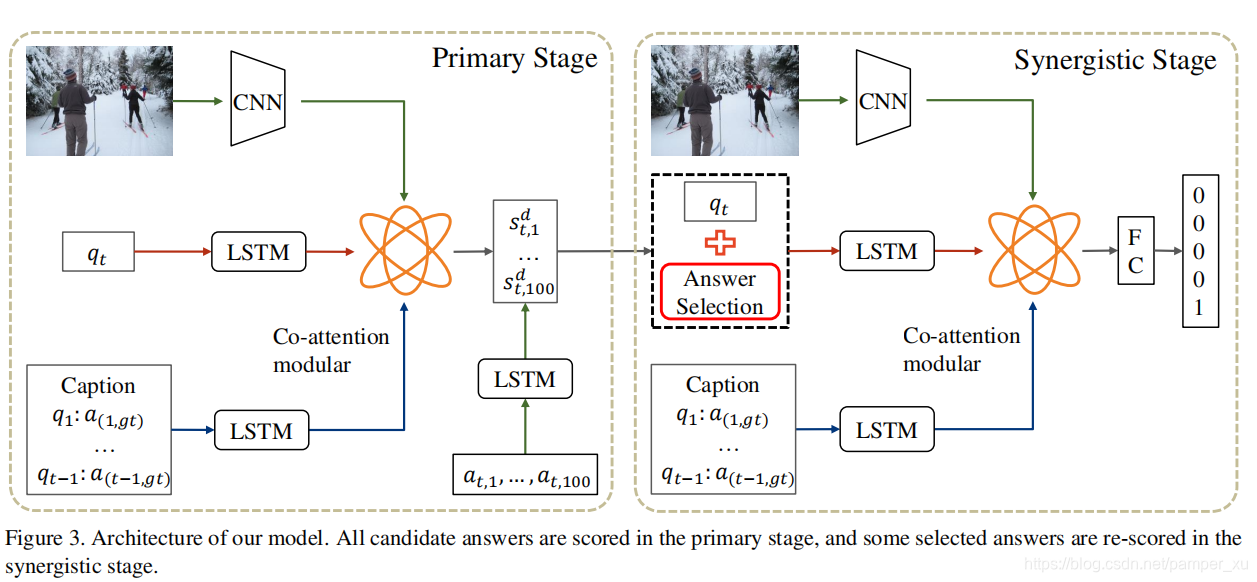
在初级阶段,我们使用共同注意模块学习图像,历史问答的代表性向量,然后计算每个候选答案的分数将hard samples和easy samples分开。在协同阶段,我们选择hard samples以及他们的问题,以形成问题-答案对。这些pairs再配合图像和历史问答来预测他们的分数。(hard samples是指和正确答案非常接近难以区分的样本,而easy samples则指非常容易与正确答案区分的样本)
假定输入图像I和标题C,得到的历史问答集合为H,在第t轮的时候,模型根据问题,给出了答案集合中每一个答案的得分。对于图像信息的处理,采用Faster-RCNN model来提取图像特征,并编码成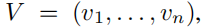 ,其中每个元素就是图像中的一个目标。问题是一系列单词,可以用LSTM进行编码。在第t轮之前的t-1轮,历史问答H连接着正确答案和问题,之后再使用LSTM来提取H中的信息,记录为U。
,其中每个元素就是图像中的一个目标。问题是一系列单词,可以用LSTM进行编码。在第t轮之前的t-1轮,历史问答H连接着正确答案和问题,之后再使用LSTM来提取H中的信息,记录为U。
第一阶段Primary Stage:该阶段采用的是encoder-decoder结构,编码器encoder包含两个任务:一是如何在多轮对话记录中去参考(de-reference)(比如代词,98%的对话都包含代词),二是如何在当前的问题中定位图像中相应的目标。解决这个问题的常用思路就是注意力机制,这里作者用到了MFB(multi-modal factorized bilinear pooling,多模态分解双线性池化),它能解决两个不同特征之间的差异。相较于其他双线性模型(MLB, MCB),MFB能够提供更多的表示(representation),在MFB中,两个特征之间的融合通过下式计算:
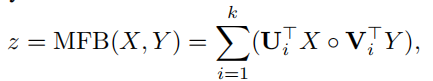
其中 U,V∈Rd×l×k 是要学习的参数,k 是因子数,l 是隐藏大小,?是 Hadamard 乘积(按元素相乘)。
有时,Y表示的是一个多通道输入,上式又可以变为:
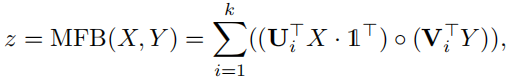
其中 1∈Rφ是所有元素都等于 1 的向量,并且φ是 Y的通道号。为了稳定输出神经元,我们使用幂归一化(z←sign(z)| z |0.5)和 ?2 归一化(z←z / z)。
利用MFB学习问题和历史的统一向量,记为
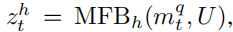
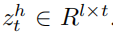
之后再学习注意力权重和向量:


解码器先对每一个答案编码,再使用LSTM计算每一个答案的浮点分数!
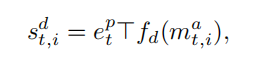
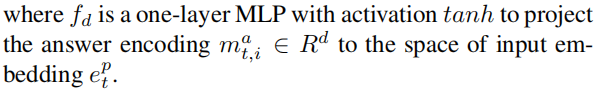
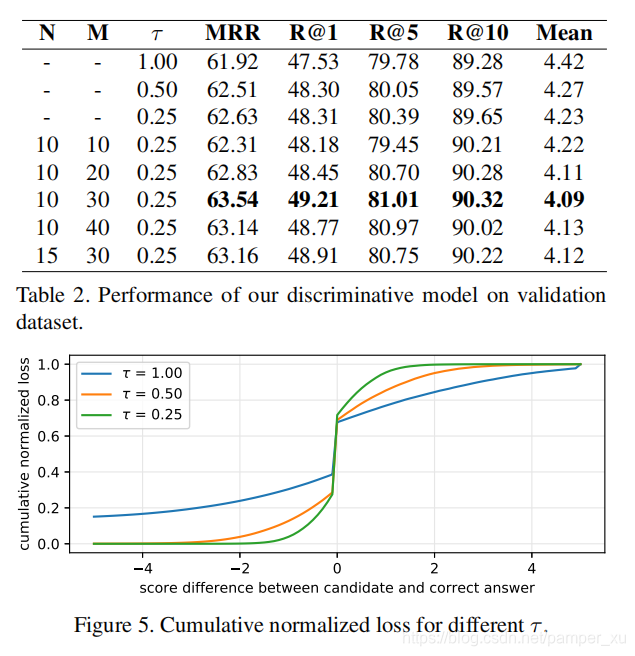
正确答案的得分应该是要比其他得分高的,所以这里作者使用了N-pair loss来衡量这个得分误差。100个候选答案中的大部分都是easy samples,所以这个loss并没有学到一些有用的信号,为了解决这个不平衡性,引入一个“温度”参数τ来修改Loss:
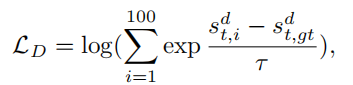
式中,T≤1,如果一个候选答案比真实答案得分低,那么分数中的分子项就会小于0,那么这个答案就会减少它对loss的贡献,反之亦然。
第二阶段Synergistic Stage:在第一阶段中,由于某些评分机制的限制,会导致一些错误答案获得高分,因此在这个阶段中,答案会配合问题和图像重新排序。所以第一阶段的主要任务就是筛选hard answers和easy answers,经过第一阶段的筛选,大概有90%的正确答案都会在top-10的候选答案中。
考虑到单独的答案有时候会引起歧义,因此这一步必须要配合问题来做。作者将问题连接在答案后面,再用LSTM对QA pair进行编码得到一个向量:
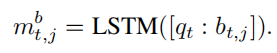
另外,历史问答可以作为问题的补充,因此,我们使用mbt,j 作为问题向量,结合历史问答mht来学习图像的注意参数:
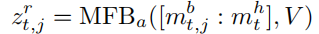
与第一阶段类似,由图像,问题,问答历史,我们可以得到答案向量表示的融合嵌入
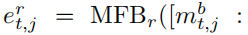
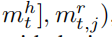
这个嵌入可以用来计算得分:
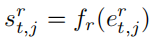
其中fr可以是一层MLP。一个包含更多细节和更好匹配输入的候选集的答案应该比普通的获得更高的分数。
我们将这个阶段视为一个分类问题,其中正确答案的可能性最高,最终答案的计算可以根据下式:
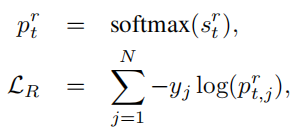
其中ygt等于1,其他为零。我们注意到这个公式可以很容易地扩展到交叉熵,(当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss)
其中yi是将这个答案标记为正确的概率,如果将来有一个密集的注释数据集可用的话。
五、生成网络的扩展Extension to the Generative Model
除了初级阶段的判别模型外,生成模型还可以用于对候选答案进行评分,并与提出的图像问题-答案协同方法无缝地协同工作。生成模型的编码器与 上节中主要阶段的判别模型的编码器相同。如果我们知道图像,问题和历史问答在第t轮的向量,解码器可以将向量解译为答案和概率:
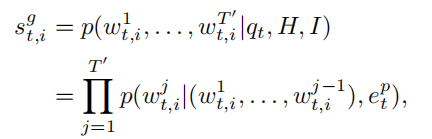
答案的概率也就是答案的得分

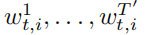 指的是单词
指的是单词
对于每一个单词,它的概率计算为:
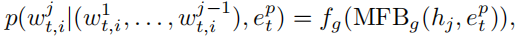
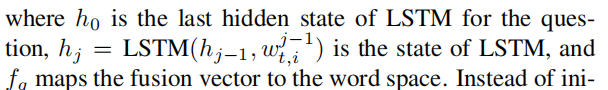
为了使得第一阶段中的得分尽可能的高,我们需要最大化条件概率。因此,损失函数就是每一步中正确单词的负对数似然求和
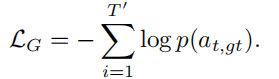
六、实验
最后是文章的实验部分。数据集作者使用了Visual Dialog v1.0,里面的图像有12万张来自COCO-trainval数据集,每一张图片都有一个标题和10轮对话。对话中的每一个问题,都有100个候选答案,其中包含了50个相似问题的答案,30个常见答案,1个正确答案和其他的随机答案。测试数据是1万张来自Flickr的图片。
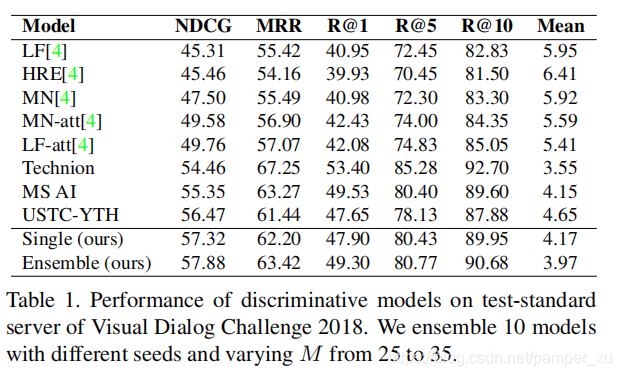
与其他的模型比较
Ablation Study
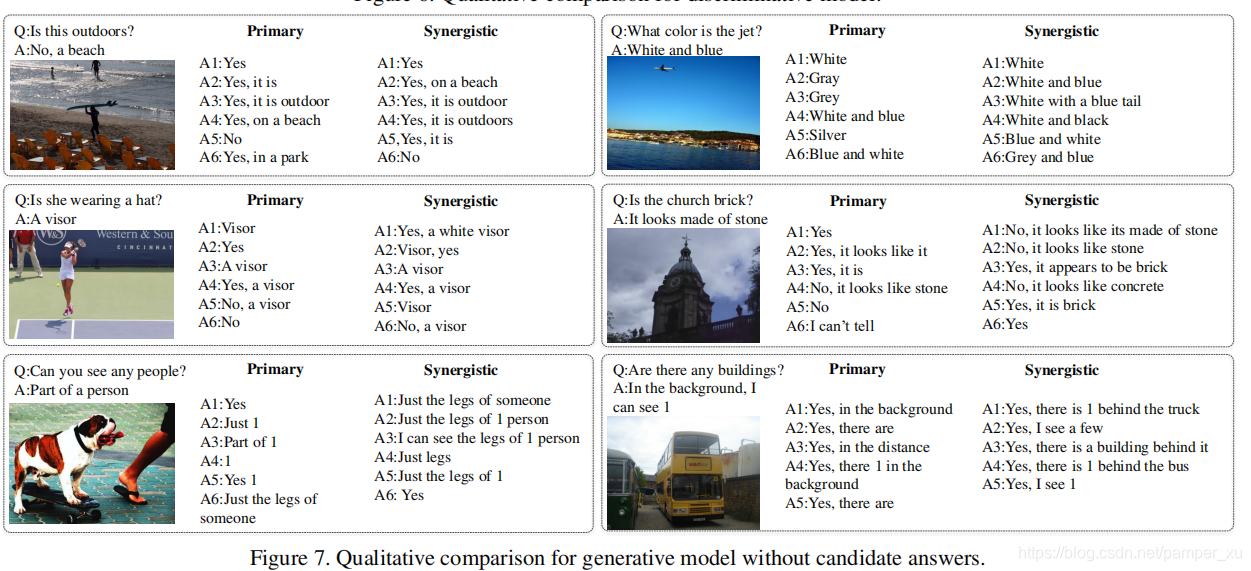
Qualitative Analysis