LightGBM是微软开源的一个快速的,分布式的,高性能的基于决策树算法的梯度提升算法,对比于XGBoost算法来说准确率在大部分情况下相较无几,但是在收敛速度,内存占用情况下相较于XGBoost来说较为优秀。详细的算法原理可见LightGBM官方文档。
在已经有了训练值和label的情况下可以创建lightgbm进行训练了,这里我是先对数据集进行划分得到了X_train,X_test, y_train, y_test
from sklearn.model_selection import train_test_splitX_train,X_test, y_train, y_test =train_test_split(train,target_train,test_size=0.3, random_state=0)
然后将X_train在用K-Fold划分进行训练,训练的代码:
from sklearn.metrics import r2_score
import lightgbm as lgb
from lightgbm import LGBMRegressor
from sklearn.model_selection import KFold,cross_val_score,GridSearchCV
import time
#参数
params = {'num_leaves': 85,'min_data_in_leaf': 1,'min_child_samples':20,'objective': 'regression','learning_rate': 0.01,"boosting": "gbdt","feature_fraction": 0.9,"bagging_freq": 0,"bagging_fraction": 0.6,"bagging_seed": 23,"metric": 'rmse',"lambda_l1": 0.2,"nthread": 4,
}
#5折K-Fold
folds = KFold(n_splits=5, shuffle=True, random_state=15)
oof_lgb = np.zeros(len(X_train))
predictions_lgb = np.zeros((len(X_test)))
start = time.time()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train.values, y_train.values)):print("fold n°{}".format(fold_))print('trn_idx:',trn_idx)print('val_idx:',val_idx)trn_data = lgb.Dataset(X_train.iloc[trn_idx],label=y_train.iloc[trn_idx])val_data = lgb.Dataset(X_train.iloc[val_idx],label=y_train.iloc[val_idx])num_round = 10000clf = lgb.train(params,trn_data,num_round,valid_sets = [trn_data, val_data],verbose_eval=500,early_stopping_rounds = 200)oof_lgb[val_idx] = clf.predict(X_train.iloc[val_idx], num_iteration=clf.best_iteration)print(oof_lgb)predictions_lgb += clf.predict(X_test, num_iteration=clf.best_iteration) / folds.n_splitsprint(predictions_lgb)
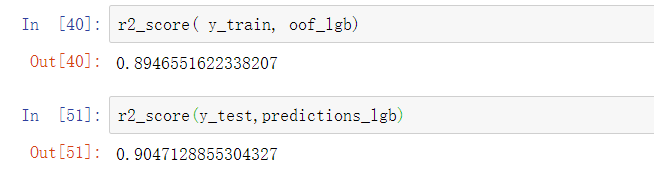
print("CV Score: {}".format(r2_score( y_train, oof_lgb)))#还可以根据需要输出特征贡献值表格
部分运行结果截图
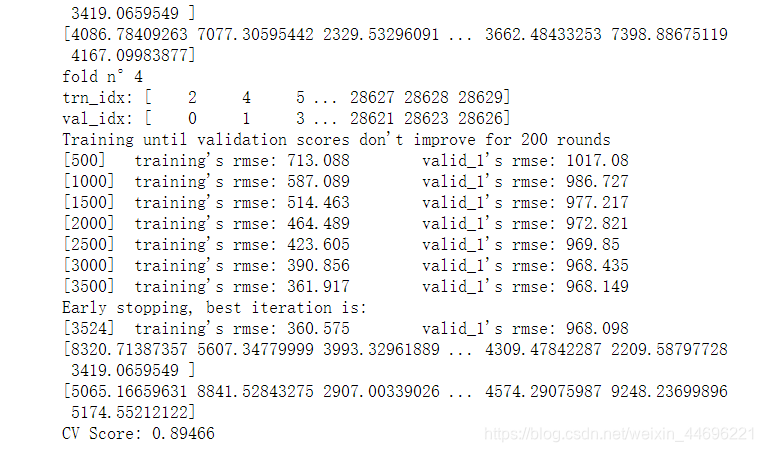
可以看到模型在训练集上r2得分0.89,在测试集上也有0.9左右,应该是较好地收敛了
调参
参考blog:https://blog.csdn.net/u012735708/article/details/83749703
lightGBM需要调的参数除了主要分为以下方面
学习控制参数:
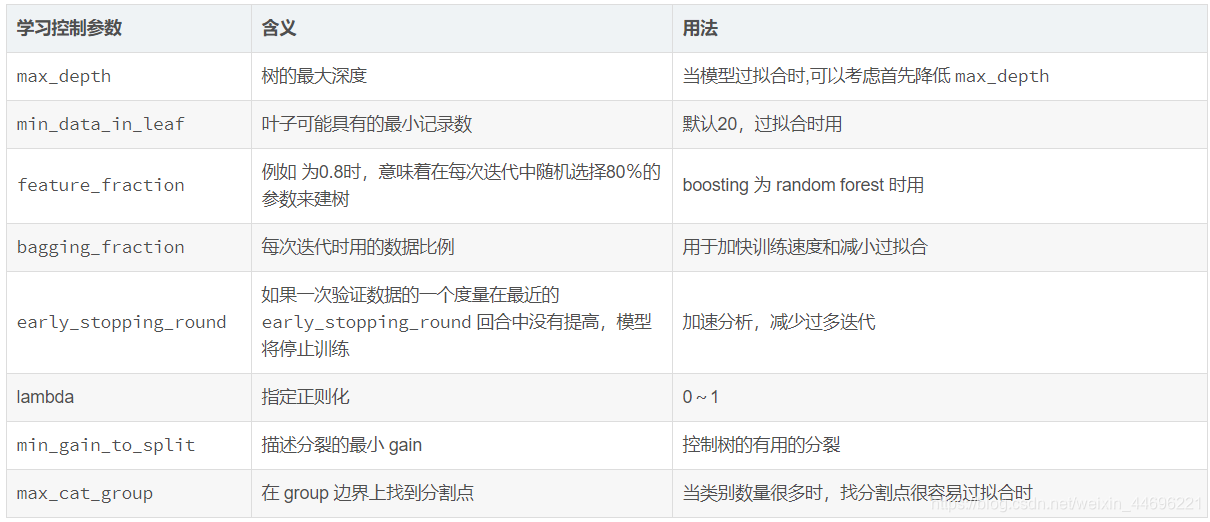



下表 整理了为了达到Faster Speed ,better accuracy ,over-fitting 三种目的时,可以调的参数

LightGBM的调参基本流程如下:
首先选择较高的学习率,大概0.1附近,这样是为了加快收敛的速度。这对于调参是很有必要的。
- 对决策树基本参数调参
- 正则化参数调参
- 最后降低学习率,这里是为了最后提高准确率
学习率和迭代次数
我们先把学习率先定一个较高的值,这里取 learning_rate = 0.1,其次确定估计器boosting/boost/boosting_type的类型,不过默认都会选gbdt。
迭代的次数,也可以说是残差树的数目,参数名为n_estimators/num_iterations/num_round/num_boost_round。我们可以先将该参数设成一个较大的数,然后在cv结果中查看最优的迭代次数,具体如代码。
在这之前,我们必须给其他重要的参数一个初始值。初始值的意义不大,只是为了方便确定其他参数。下面先给定一下初始值:
以下参数根据具体项目要求定:
‘boosting_type’/‘boosting’: ‘gbdt’
‘objective’: ‘binary’ / ‘regression’
‘metric’: ‘auc’
首先选定初始参数
'max_depth': 5 # 由于数据集不是很大,所以选择了一个适中的值,其实4-10都无所谓。
'num_leaves': 30 # 由于lightGBM是leaves_wise生长,官方说法是要小于2^max_depth
'subsample'/'bagging_fraction':0.8 # 数据采样
'colsample_bytree'/'feature_fraction': 0.8 # 特征采样
用lgb自带的cv调参n_estimators,注意调参时学习率最好设为0.1,加快收敛速率,有益于调参
import lightgbm as lgb
params = { 'boosting_type': 'gbdt','objective': 'regression','metric': 'auc','nthread':4,'learning_rate':0.1,#为了加快收敛的速度'num_leaves':30, 'max_depth': 5, 'subsample': 0.8, 'colsample_bytree': 0.8, }data_train = lgb.Dataset(X_train, y_train)
cv_results = lgb.cv(params, data_train, num_boost_round=1000, nfold=5, stratified=False, shuffle=True, metrics='auc',early_stopping_rounds=50,seed=0)
print('best n_estimators:', len(cv_results['auc-mean']))
print('best cv score:', pd.Series(cv_results['auc-mean']).max())
使用sklearn的GridSearchCV调参
确定max_depth和num_leaves
这是提高精确度的最重要的参数
from sklearn.model_selection import GridSearchCVparams_test1={'max_depth': range(3,8,1), 'num_leaves':range(5, 100, 5)}gsearch1 = GridSearchCV(estimator = lgb.LGBMRegressor(boosting_type='gbdt',objective='regression',metrics='auc',learning_rate=0.1, n_estimators=20, max_depth=6, bagging_fraction = 0.8,feature_fraction = 0.8), param_grid = params_test1, cv=5,n_jobs=-1)
gsearch1.fit(X_train,y_train)
#明确是用Regressor还是Classifier
#regressor问题参数中不能加入scoring='roc_auc' 因为roc曲线是用于评估二分类的
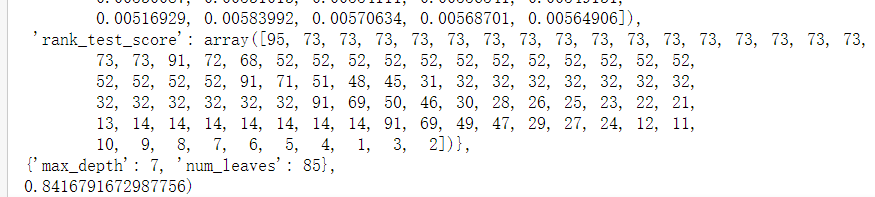
确定min_data_in_leaf和max_bin in
params_test2={'max_bin': range(5,256,10), 'min_data_in_leaf':range(1,102,10)}gsearch2 = GridSearchCV(estimator = lgb.LGBMRegressor(boosting_type='gbdt',objective='regression',metrics='auc',learning_rate=0.1, n_estimators=20, max_depth=7,num_leaves = 85, bagging_fraction = 0.8,feature_fraction = 0.8), param_grid = params_test2, cv=5,n_jobs=-1)
gsearch2.fit(X_train,y_train)
gsearch2.cv_results_, gsearch2.best_params_, gsearch2.best_score_

确定feature_fraction、bagging_fraction、bagging_freq
params_test3={'feature_fraction': [0.6,0.7,0.8,0.9,1.0],'bagging_fraction': [0.6,0.7,0.8,0.9,1.0],'bagging_freq': range(0,81,10)
}
gsearch3 = GridSearchCV(estimator = lgb.LGBMRegressor(boosting_type='gbdt',objective='regression',metrics='auc',learning_rate=0.1, n_estimators=20, max_depth=7,num_leaves = 85,max_bin = 195,min_data_in_leaf = 1, bagging_fraction = 0.8,feature_fraction = 0.8), param_grid = params_test3, cv=5,n_jobs=-1)
gsearch3.fit(X_train,y_train)
gsearch3.best_params_, gsearch3.best_score_
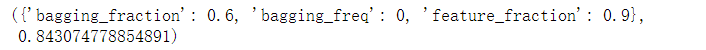
确定lambda_l1和lambda_l2
params_test4={'lambda_l1': [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0],'lambda_l2': [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]
}
确定 min_split_gain
params_test5={'min_split_gain':[0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]}