udf函数:
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
import numpy as np
import math@udf(returnType=StringType())
def caculateClusterBelongTo(inlist):try:#不用再进行for line in sys.stdin#直接对数据执行split,因为进来的就只有一行数据thing1,thing2,thing3,thing4 = inlist.strip().decode('utf-8').split('&&')…….. #省略中间过程out= '$$'.join([str(thing1),str(currentShortestDistance),str(thisPoiCurrentCluster)])return outexcept Exception,e:return 'wrong'pass
eg:
输入

输出
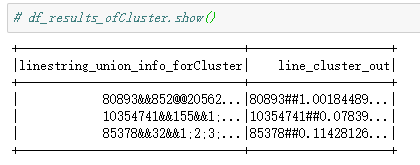
输入输出都是拼接后的字符串形式
得到结果后可以再对字段进行拆分
import pyspark.sql.functions as F
df_split = df1.withColumn("s", F.split(df1['line_cluster_out'], "##")) df_split = df_split.withColumn('Item0', df_split["s"].getItem(0))
df_split = df_split.withColumn('Item1', df_split["s"].getItem(1))
df_split = df_split.withColumn('Item2', df_split["s"].getItem(2))
拆分可以参考我的另一篇文章 https://blog.csdn.net/sunflower_sara/article/details/104044252
参考:
https://www.jianshu.com/p/bded081b5350