前言
朴素贝叶斯分类器是低方差高偏差的分类器,假设各个特征之间存在条件独立性假设:对于给定的类别,所有的特征相互独立。显然,这个假设把问题想的太简单了,但朴素贝叶斯在文本分类任务上确实拥有很好的效果。
朴素贝叶斯模型是一组非常简单快速的分类算法,通常适用于维度非常高的数据集。因为运行速度快,而且可调参数少,因此非常适合为分类问题提供快速粗糙的基本方案。之所以称为“朴素”或“朴素贝叶斯”,是因为如果对每种标签的生成模型进行非常简单的假设,就能找到每种类型生成模型的近似解,然后就可以使用贝叶斯分类。朴素贝叶斯的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
朴素贝叶斯算法包括高斯NB(假设每个标签的数据都服从简单的高斯分布,适用于特征是连续变量)、多项式NB(假设特征是由一个简单多项式分布生成的,适用于离散特征的情况)和伯努利NB(假设特征服从伯努利分布,适用于离散特征的情况。不同于多项式贝叶斯模型的是,伯努利模型中每个特征的取值只能是1和0,以文本分类为例,某个单词在文档中出现过,则其特征值为1,否则为0)
特点
优点
- 训练和预测的速度非常快。
- 直接使用概率预测。
- 通常很容易解释。
- 可调参数(如果有的话)非常少。
适用于
- 假设分布函数与数据匹配(实际中很少见)。
- 各种类型的区分度很高,模型复杂度不重要。
- 非常高维度的数据,模型复杂度不重要。
原理
P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。
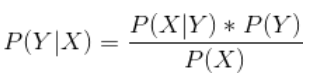
利用概率统计知识进行分类,其分类原理就是利用贝叶斯公式根据某对象的先验概率计算出其后验概率(即该对象属于某一类的概率),然后选择具有最大后验概率的类作为该对象所属的类。总的来说:当样本特征个数较多或者特征之间相关性较大时,朴素贝叶斯分类效率比不上决策树模型;当各特征相关性较小时,朴素贝叶斯分类性能最为良好。
通过举例更容易了解其原理,可参考文章中的例子讲解:https://blog.csdn.net/ac540101928/article/details/103941495
pySpark API
class pyspark.ml.classification.NaiveBayes(featuresCol='features', labelCol='label', predictionCol='prediction', probabilityCol='probability', rawPredictionCol='rawPrediction', smoothing=1.0, modelType='multinomial', thresholds=None, weightCol=None) Pyspark Documentation
- smoothing:平滑参数需>= 0,默认为1.0
- modelType:模型类型是一个字符串(区分大小写)。支持的选项 : multinomial(多项式,default) | bernoulli(伯努利)
案例
'''
内容:pyspark实现朴素贝叶斯二元分类
版本:spark 2.4.4
数据:垃圾邮件数据
数据源:http://archive.ics.uci.edu/ml/datasets/Spambase
'''from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import NaiveBayes
from pyspark.ml.evaluation import BinaryClassificationEvaluator,MulticlassClassificationEvaluator
from pyspark.ml import Pipeline
from pyspark.ml.tuning import CrossValidator,ParamGridBuilderspark = SparkSession.builder.master("local").appName("NaiveBayes").getOrCreate()sc =spark.sparkContextdata = spark.read.format("csv").option("header","true").load(u"D:\Data\Spam-Dataset\spambase.csv")for i in data.columns:data = data.withColumn(i,col(i).cast("Double"))if i == "spam":data = data.withColumnRenamed(i, "label") # 更改列名trainData, testData = data.randomSplit([0.8, 0.2])featuresArray = data.columns[:-1]assembler = VectorAssembler().setInputCols(featuresArray).setOutputCol("features")nb = NaiveBayes().setLabelCol("label").setFeaturesCol("features")pipeline = Pipeline().setStages([assembler,nb])ParamGrid = ParamGridBuilder().addGrid(nb.smoothing,[0.1,0.3,0.5]).build()evaluator = BinaryClassificationEvaluator().setMetricName("areaUnderROC").setRawPredictionCol("rawPrediction").setLabelCol("label")CV = CrossValidator().setEstimator(pipeline).setEvaluator(evaluator).setEstimatorParamMaps(ParamGrid).setNumFolds(3)# 训练数据
nbModel = CV.fit(trainData)# 预测数据
nbPrediction = nbModel.transform(testData)
#nbPrediction.show(10)''' 最佳模型参数 '''
bestModel = nbModel.bestModel
NBModel = bestModel.stages[1]
print("best smoothing : ", NBModel.explainParam(NBModel.smoothing))''' 评估模型1 -- AUC '''
AUC = evaluator.evaluate(nbPrediction)print("朴素贝叶斯 Area Under ROC::",AUC)''' 评估模型2 -- 准确率 '''
evaluatorX = MulticlassClassificationEvaluator().setMetricName("accuracy").setLabelCol("label")ACC = evaluatorX.evaluate(nbPrediction)print("朴素贝叶斯 预测准确值:",ACC)
![]()
参考
Determined22 原文:机器学习 —— 基础整理(二)朴素贝叶斯分类器;文本分类的方法杂谈
图灵教育 原文:朴素贝叶斯分类
琥珀彩 原文:朴素贝叶斯的三个常用模型:高斯、多项式、伯努利
suipingsp y原文:机器学习经典算法详解及Python实现