准备写一个论文学习专栏,先以对抗样本相关为主,后期可能会涉及到目标检测相关领域。
内容不是纯翻译,包括自己的一些注解和总结,论文的结构、组织及相关描述,以及一些英语句子和相关工作的摘抄(可以用于相关领域论文的写作及扩展)。
平时只是阅读论文,有很多知识意识不到,当你真正去着手写的时候,发现写完之后可能只有自己明白做了个啥。包括从组织、结构、描述上等等很多方面都具有很多问题。另一个是对于专业术语、修饰、语言等相关的使用,也有很多需要注意和借鉴的地方。
本专栏希望在学习总结论文核心方法、思想的同时,期望也可以学习和掌握到更多论文本身上的内容,不论是为自己还有大家,尽可能提供更多可以学习的东西。
当然,对于只是关心论文核心思想、方法的,可以只关注摘要、方法及加粗部分内容,或者留言共同学习。
————————————————
**
Adversarial camera stickers: A physical camera-based attack on deep learning systems
**
JunchengB.Li12 FrankR.Schmidt1 J.ZicoKolter12
1Bosch Center for Arti?cial Intelligence
2School of Computer Science, Carnegie Mellon University, Pittsburgh, USA.
billy.li@us.bosch.com,frank.r.schmidt@de.bosch.com,zico.kolter@us.bosch.com
发表于ICML2019
对抗的相机贴纸:基于物理摄像头的深度学习系统攻击
Abstract
Recent work has documented the susceptibility of deep learning systems to adversarial examples, but most such attacks directly manipulate the digital input to a classi?er.
之前的物理攻击都是将对抗贴纸直接贴在感兴趣的物体上或者是直接创建对抗物体。
通过在相机镜头上放置一个精心制作的半透明贴纸,可以对人们所有观察到的图像产生普遍的干扰,且这些干扰并不明显,但却将目标对象错误地归类为不同的(目标)类。
提出了一个迭代过程,同时保证,扰动的攻击性及扰动对于摄像头的可见性。
展示了一种新的攻击方式。
1.Introduction
In the majority of the cases studied, however, these attacks are considered in a“purely digital”domain,
A smaller but still substantial line of work has emerged to show that these attacks can also transfer to the physical world:
In all these cases, though, the primary mode of attack has been manipulating the object of interest, often with very visually apparent perturbations. Compared to attacks in the digital space, physical attacks have not been explored to its full extent: we still lack base lines and feasible threat models that work robustly in reality. (引言部分的转引)
我们使用视觉上不明显的修改将特定类的所有对象错误分类,创建了具有对抗的相机贴纸。
贴纸包含精心构造的圆点图案,如下图,犹如大部分不可感知的污点,对人而言不明显。
难点:不像过去的攻击是在图像的像素级粒度上操作的,相机的光学意味着我们只能创建模糊的点,没有任何典型的高频率攻击模式。

The overall procedure consists of three main contributions and improvements over past work:
1)我们的威胁模型是第一个将扰动注入相机和物体之间的光路而不改变物体本身的模型。
2)第一个“普遍的”的物理扰动,一个相机贴纸用于所有的图像,且适用于多角度和多尺度。
3)我们的方法联合优化了攻击的对抗性质以及将威胁模型拟合到摄像机可获得的扰动中。这是由于在寻找“允许的”一组可以被摄像机实际观测到扰动时所面临的挑战。
(一个是扰动要具有对抗性,另一个是这种扰动可以被摄像机实际观测到)
Our experiments show that,在真实的视频数据中,通过物理制作的贴纸,我们可以在5种不同的类/目标类组合中实现52%的平均目标欺骗率,并进一步将分类器的准确率降低到27%。
In total, we believe this work substantially adds to the recent crucial considerations of the “right” notion of adversarial threat models, demonstrating that these pose physical risk when an attacker can access a camera. 意义。
2.Background and Related Works
This paper will focus on the so-called white-box attack setting, where we assume access to the model. In this setting, past work can be roughly categorized into two relevant groups for our work: digital attacks and physical attacks.
2.1Digital Attacks
Digital attacks have been relatively well studied since they first rose to prevalence in the context of deep learning in 2014, where Szegedy et al. (2013) used the box-constrained L-BFGS method to ?nd the perturbation. 自从2014年数字攻击首次在深度学习的背景下流行起来以来,人们对其进行了相对深入的研究,
2.2Physical Attacks
Compared with digital attacks, physically realizable attacks have not been explored to a full extent beyond a few existing works. 与数字攻击相比,物理上可实现的攻击除了现有的一些工作外,还没有得到充分的研究。
However, both these attacks may be hard to deploy in some settings because
- they require that each object of interest for where we want to fool the classi?er be explicitly modi?ed; and
- they are visually apparent to humans when inspecting the object. 感兴趣目标需要被改变及这些改变视觉可见。
In contrast to the existing methods of physical attacks, our proposed 不干预感兴趣目标且不可见。
(在相关工作里面同样也再次引出强调我们方法的不同、优点)
3.Crafting Adversarial Stickers
This section contains the main methodological contribution of our paper: the algorithmic and practical pipeline for manufacturing adversarial camera sticker. To begin, we will first describe… We describe our approach… and finally how we adjust the free parameters of our attack to craft adversarial examples. 总括----分述
3.1.A threat model for physical camera sticker attacks
Traditional attacks on neural network models work as follows. Given a classi?er f : X →Y, we want to ?nd some perturbation function π : X →X, such that for any input x ∈X, π(x) looks “indistinguishable” from x,

The goal of standard adversarial attacks is, for a given x ∈ X,y ∈Y, to ?nd a perturbation π ∈ Π that maximizes the loss (描述语言、形式)
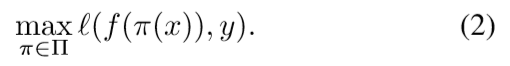
A slight variant of this approach is to最大化原目标损失、最小化目标损失的联合
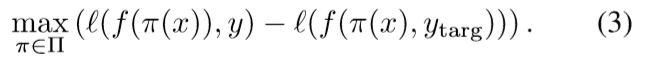
To design a threat model for a physical camera attack, 我们需要考虑在贴纸上放置小点的近似效果。由于相机透镜的光学原理,在相机镜头上放置一个不透明的小点,就会在图像本身形成一个小的半透明块。假设有足够的照明,这种半透明的叠加可以通过混合原始图像和适当大小和颜色的点之间的 alpha-blending operation 来实现。
More formally, explicitly considering x to be an 2D image 更正式的,对于图像当中的单个点引入扰动函数Π:(i,j)表示图像中像素位置,

Intuitively, this perturbation model captures the following process.
每一个扰动点通过其中心坐标和颜色值来表示,扰动图像中的像素为原始像素和颜色的线性组合,权重通过位置独立的alpha mask决定。与点越近alpha越大,beta为平滑下降。
为了形成最终的微扰模型,我们简单地把K个这些单点微扰组合:
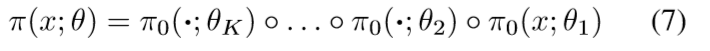
A visualization of a possible perturbation under this model, with multiple dots with different center locations and colors, αmax = 0.3, β = 1.0, and a radius of 40 pixels is shown in Figure 2. 具体参数值描述很清楚,但没必要说这些值是如何获取的。

3.2.Achieving inconspicuous, physically realizable perturbations
尽管如上方法可以实现模型的攻击,但是存在的问题,First,过于明显, But second, and more subtly,很多扰动对于摄像头物理不可见,如上图2的白色点。
In more details, our process works like the following. 如下图a所示原始干净图像记为x0,加点扰动后的图像c/d/e/f记为x1,为了训练扰动模型能够重建扰动,使用 structural similarity (SSIM) 来测量两张图像之间的相似度:

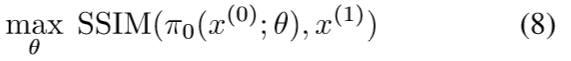
In theory, because both the SSIM and the perturbation model π are differentiable functions, we could simply use projected gradient descent (PGD) to optimize our perturbation model。
We performed this procedure for 50 different physical dots, to learn a single set of αmax, β, and r parameters, and 50 different colors (and of course, 50 different locations, though these parameters were only ?t here in order to ?t the remaining parameters well). 具体的实验调参细节。
3.3.Constructing adversarial examples
Given this perturbation model, our ?nal goal is to
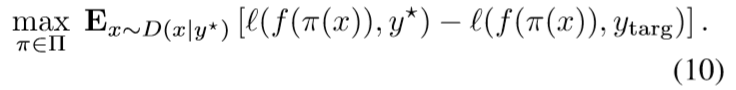

我们使用贪心块坐标下降搜索来搜索每个块的位置和颜色。也就是说,我们将图像离散成一个45×45的网格,网格中包含一个点中心的可能位置(选择45个点,这样ImageNet中每个点之间的距离为5个像素)。在以这种方式运行坐标下降之后,我们最终对这些点的位置进行了微调(因为颜色是离散的,我们无法对这些进行微调),同时对损失函数使用了梯度下降。完整的过程如算法1所示。
4.Experiments
Here we present experiments of our attack evaluating both the ability of the digital version of the attack to misclassify images from the ImageNet dataset (still restricting perturbations to be in our physically realizable subset), and evaluating the system on two real-world tasks: classifying a computer keyboard as a computer mouse, and classifying a stop sign as a guitar pick. We also detail some key results in the process of ?tting the threat model to real data. 总引
4.1.Experimental setup
这里介绍要尽可能详细,他这里包含了网络、数据集、模型、打印机、打印尺寸。
All our experiments consider fooling a ResNet-50 (He etal.,2016) classifier, pretrained using the ImageNet dataset (Dengetal.,2009); we specifically use the pretrained model included in the PyTorch library (Paszke et al., 2017). …
4.2.Training and Classi?cation on ImageNet (关于本文的小标题也都起的比较详尽)
To train and evaluate the system on a broad range of images, we use
Figure 4 shows the learned perturbations for two instances. 直接引出图像并说明分析

Table 1 shows the ability of our learned perturbations (6 dots) to fool images from the ImageNet test set for these two categories. We also showed the average success rate to fool stop sign into 50 random classes. More generally, we also include … 语言描述

Unrealizable attacks :
我们讨论的威胁模型,如果不被限制为物理上可实现的或特别不显著的,可以产生更高的愚弄率;
4.3. Evaluation of attacks in the real world
In this section we present our main empirical result of the work, illustrating that the perturbations we produce can be adversarial in the real world when printed and applied physically to a camera, and when viewing a target object at multiple angles and scales. 引

Figure 6 and 7 shows several snapshots of the process for both the keyboard and stop sign tests. 直接描述及引出其优点:不可见性;
4.4.Other experiments
Finally, because there are several aspects of interest regarding both the power of the thread model we consider and our ability to physically manufacture such dots, we here present additional evaluations that highlight aspects of the setup.引
Effect of the number of dots 点数量的影响

Effect of printed dots on camera perturbations 打印点的影响
由于相机的光学特性,在某一点之后,较小尺寸的印刷点并不会导致相机中较小尺寸的视觉点,而仅仅是一个更透明的相同尺寸的点。这个过程如上图8所示,也强调了为什么我们选择使用小的实心打印点来适应我们的威胁模型,而不是允许打印点是透明的。
5.Conclusion
对于整体工作的一个总结,呼应摘要、引言,强调优点。