Graph-based Knowledge Tracing: Modeling Student Proficiency Using Graph Neural Network
之前的版本:https://rlgm.github.io/papers/70.pdf
发表版本论文:https://dl.acm.org/doi/10.1145/3350546.3352513
代码:https://github.com/jhljx/GKT(论文作者和代码作者不一样,你发现了吗)
基于图形的知识跟踪:基于图神经网络的学生能力建模
首次将GNN应用于知识追踪,提出了一种基于GNN的知识跟踪方法,即基于图的知识跟踪。将知识结构转换为一个图,使我们能够将知识跟踪任务转化为GNN中的时间序列节点级分类问题。由于知识图结构在大多数情况下并没有显式地提供,所以我们提出了图结构的各种实现。对两个开放数据集的实证检验表明,我们的方法在不需要任何额外信息的情况下,可以提高对学生成绩的预测能力,并显示出更多的可解释性预测。
文章贡献
贡献如下:
?我们证明,将知识追踪作为GNN的一种应用,可以在不需要任何额外信息的情况下提高学生成绩预测。学生可以通过更精确的个性化内容更有效地掌握课程。E-learning平台可以提供更高质量的服务,以保持高用户参与度。
?我们的模型提高了模型预测的可解释性。教师和学生可以更准确地识别学生的知识状态,通过理解推荐练习的原因,学生可以更积极地进行推荐练习。E-learning平台和教师可以通过分析学生的失败点来更容易地重新设计课程。
?为了解决隐式图结构问题,我们提出了各种实现方案,并通过经验验证了它们的有效性。研究人员可以从性能提升中获益,而不需要人类专家对概念之间的关系进行昂贵的注释。教育专家可以有一个新的标准来考虑什么是好的知识结构来改进课程设计。
本文提出了一种基于GNN的知识跟踪方法, 一种基于图的知识跟踪(GKT)。我们的模型将知识追踪重新定义为GNN中的时间序列节点级分类问题。该公式基于三个假设:1)将作业知识分解为一定数量的知识概念。2) 学生有自己的时间知识状态,代表他们对课程概念的熟练程度。3) 作业知识是一个图,它影响学生知识状态的更新:如果一个学生正确或错误地回答了一个概念,那么他/她的知识状态不仅会受到回答概念的影响,而且还会影响到其他相关概念,这些概念在图中表示为相邻的节点。
问题定义


模型
- 集合,聚合就是将已经回答的概念i及其相邻的概念j ∈ N 的隐藏状态和嵌入使用一个向量表示。
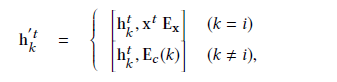

- 更新。接下来,模型根据聚集的特征和知识图结构更新隐藏状态:
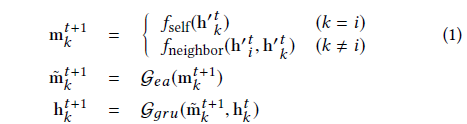

- 预测。最后,模型输出学生在下一时间步正确回答每个概念的预测概率
![]()




将本文提出的方法与以前的方法进行比较,可以从两个方面进行

第一个方面是学生时间知识状态ht的定义,在DKT中,被表示为一个单一的隐向量,并且每个概念的知识状态是不分离的。这使得对每个概念的知识状态分别建模变得复杂,并导致在长时间序列中的性能下降和模型如何预测学生对每个概念的熟练程度的解释性低。为了解决这些缺点, Zhang等[25]提出了动态键值存储网络
(DKVMN)利用两个记忆矩阵,其中一个可以被视为学生时间知识状态h的堆栈,分别为每个概念定义。尽管这与GKT几乎相同,但它们略有不同,因为GKT直接为每个概念建模知识状态,而DKVMN定义另一个低维潜在概念,并随后对其知识状态进行建模。
另一方面是指在知识状态更新过程中概念之间的交互。在DKVMN中,原始输入概念和潜在概念之间的关系权重是通过一个简单的点积注意机制来计算的,这不足以模拟知识概念之间复杂和多重的关系。同时,GKT利用K个不同的神经网络对K个边类型的输入概念之间的关系权值进行建模。这样就可以对概念之间的多种复杂关系进行建模
实验
数据集
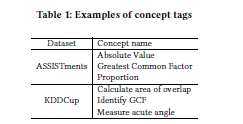
这个实验我们使用了两个开放的学生数学练习日志数据集:在线教育服务ASSISTments的数据和KDDCU的用于教育数据挖掘挑战的数据。我们提供了表1中现有概念标签的示例
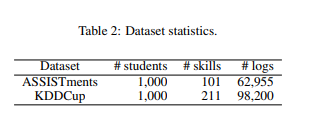
使用某些条件对于数据进行预处理,对于ASSISTments数据集,将同时回答的日志组合成为一个,随后提取与命名概念标记关联的日志,最后提取回答了至少有10次的日志。对于KDDCup数据集,我们将问题和步骤的结合视为一个答案,然后抽取与概念标签相关的日志,最后抽取回答了至少有10次的日志。
将同步答案日志合并到一个集合中,可以防止不公平的高预测性能,因为频繁出现的标记,不包括概念***,每个概念标记的相应次数对日志进行阙值化,可以确保足够数量的日志来消除噪声。利用上述条件对数据集进行处理,最终在ASSISTments中获得了62,955条日志记录,包括1000个学生和101个知识点,在KDDCup数据集中获得了1000个学生和211个知识点。
(对数据如果没有做适当的处理,跑出来的结果很差)
实现细节
每个数据集,都将学生的数据分成:训练、验证、测试三大块,所占比例分别为8:1:1,使用训练数据集来进行训练,用验证数据集来调整超参数。
DKT:根据Piech等人的研究,使用循环神经网络中的GRU来寻找超参数,隐藏层的大小为200,使用dropout为0.5的速率进行减枝,将![]() 变成
变成![]() ,批大小为32,使用Adam为优化器,学习速率为0.001
,批大小为32,使用Adam为优化器,学习速率为0.001
DKVMN:根据Zhang等人的研究,对ASSISTments数据集,内存槽的大小为20,隐藏向量的大小为32;对KDDCup数据集,内存槽的的大小为50,隐藏向量的大小为128;批大小为32,使用Adam为优化器,学习速率为0.001
GKT:所有的隐藏向量和嵌入层矩阵的大小为32,对于模型中的MLP,将隐藏向量的dropout下降为
预测性能

在图3a和图3b中,我们随机抽取了一名学生的做题日志,并以图的形式描绘了学生的知识状态,x轴表示时间,Y轴表示知识点,格子颜色表示学生知识点掌握的变化情况,红格子表示掌握程度降低,绿色表示掌握情况增加。
图3a表示GKT会更具知识点的相关性来更新学生的知识点掌握情况,而DKT依据模糊的依据将所有状态进行更新,在图3b中,能看到时间点28和75的时候,虽然知识点29没有被回答,但是因为和4有关,4有被回答,所以29的状态也被更新了。这表明GKT可以对学生的知识点掌握情况提供更明确和合理的解释。
预测的可解释性
接下来,将GKT预测学生认知状态的过程进行可视化,并且评估模型预测的可解释性。可视化帮助学生以及老师发现过去的知识掌握情况,高效且直观,这是非常有必要的。
我们从两个角度来评估模型的可解释性。1、根据学生已经回答过的知识点,更新相关知识点的掌握情况 2、被更新的部分是根据知识点的结构图来调整的
以下步骤是分析整个知识点状态的变化过程
(1)在时间T之前,随机抽取学生的做题情况
(2)在训练模型的输出层,移除掉偏差向量。
(3)将学生的回答向量![]() 输入到训练模型,并将输出向量
输入到训练模型,并将输出向量![]() 进行叠加
进行叠加
(4)将输出值进行正则化,结果控制在0到1之间

在图3a和图3b中,我们随机抽取了一名学生的做题日志,并以图的形式描绘了学生的知识状态,x轴表示时间,Y轴表示知识点,格子颜色表示学生知识点掌握的变化情况,红格子表示掌握程度降低,绿色表示掌握情况增加。
图3a表示GKT会更具知识点的相关性来更新学生的知识点掌握情况,而DKT依据模糊的依据将所有状态进行更新,在图3b中,能看到时间点28和75的时候,虽然知识点29没有被回答,但是因为和4有关,4有被回答,所以29的状态也被更新了。这表明GKT可以对学生的知识点掌握情况提供更明确和合理的解释。
网络分析

讨论:
(ps 讨论是个寻找自己idea的地方)
基于学习的方法
在本研究中,为了解决隐式图的结构问题,我们提出了两种实现方法,并开发了三种方法,即PAM、MHA和VAE。下面,我们将讨论它们之间的区别。
PAM与其他两种方法的区别在于边缘特征估计是否可行的识别有条件的。PAM直接优化邻接矩阵,不存在估计边缘特征的条件。鉴于,在MHA和VAE,用于限制边缘特征预测的特征可选择;在这里,我们选择了概念嵌入Ec作为使单个输入稳定的概念图对学生不变性可以学习,这也是最相同和最简单的设置用于知识追踪。
MHA与VAE的区别在于计算方法边权重。在MHA中,当一个概念被回答时注意力得分是计算出来的,并在所有相邻的概念。此外,MHA还可以学习k个边权值每边都用多头注意。然而,在VAE中,基于一对被回答的概念及其相邻的每一个概念,各边缘特征独立计算;甘贝尔Softmax函数只渲染靠近1和其他接近0。此外,VAE可以定义一些先验分布这样就可以定义整个图的稀疏性。因此,每种方法学习不同的图形结构,如4.5节所示;但是,我们发现在它们的预测性能。有可能边缘估计中的约束可能会导致预测性能。因此,选择的效果从以学习为基础的方法必须作为研究的一部分今后的工作。
数据集可归纳性
在这项研究中,为了验证我们的模型的性能,我们使用了原始数据集的子集,其中学生和概念如第4.1节所述,排除低数据以降低噪声。虽然实验证明了我们模型的潜力在提高预测性能和可解释性方面,我们必须放松限制,以证明在相同的条件下,我们的模型的优点可以更清楚地显示出来以往研究的背景。此外,我们还必须验证我们的方法在实际应用中的适用性不同的主题数据集。我们使用的数据集的主题是仅限于数学,如Piech等人[17]的案例。鉴于存在DKT应用于编程教育的报告[22]和GKT是一个通用算法,它完成了前面的算法如DKT,GKT也可以有效地在各种科目。然而,不同的被试表现出不同的潜在图形结构;因此,我们必须比较受试者对我们模型的影响,例如,什么类型图的形式适合于预测学生的表现或可以从基于学习的方法中获得。
结合更丰富的GNN架构
我们提出了第一种基于GNN的知识跟踪方法,并验证了相对 简单的体系结构。 在下面,我们讨论了三个方向来改进我 们的模型。 一种是根据节点的边缘类型对节点之间的信息传播施加适当的约束。 在本研究中,为了进行公平的比较,我们为基于统计的方法和基于学习的方法定义了两种类型的边缘。 然而,我们没有对每个节点类型施加任何约束;因此,对每个节点类型(如依赖方向和因果关系)的意义可能很小,特别是对于学习的边缘。 解决办法是根据节点的边缘类型对节点之间的信息传播施加一些约束例如定义边缘的方向,并将传播限制在从源节点到目标节点的一个方向上。 此外,这可 以作为关系归纳偏差,提高GKT的样本效率和可解释性。 另一个是将所有概念(如DKT)所共有的隐藏状态合并到GKT中。虽然只采用单个隐藏向量来表示学生知识状态,使DKT中概念之间复杂交互的建模复杂化,但将这种类型的表示添加到GKT中可以通过充当全局特征来提高性能。 全局特征意味着每个节点的共同特征,并且可以表示跨变量概念或学生原始概念的共同知识状态智力对个体概念理解的不变。最后一个可能的解决方案是实现多跳传播。 在本研究中,我们将传播限制在单个跳,即响应某个节点的信息只在一个时间步长传播到其相邻节点。 然而,要有效地模拟人类的学习机制,使用多跳将更合适。 此外,这可以使模型能够学习稀疏连接,因为模型可以将特征传播到远程节点,而不连接到其他节点。
其他的待补充