
���ߣ�ChrisCao
https://zhuanlan.zhihu.com/p/75468124
��Һã�����Сz
�������һ������ѧϰ�ĸɻ�~
һ. ������
��������һ���мල����ģ�ͣ�������ѡ��һ�������Ϣ���������ֵ������ķֱָ���ﵽ����������Ҷ�ӽڵ㴿�ȴﵽ��ֵ����ͼ�Ǿ�������һ��ʾ��ͼ��
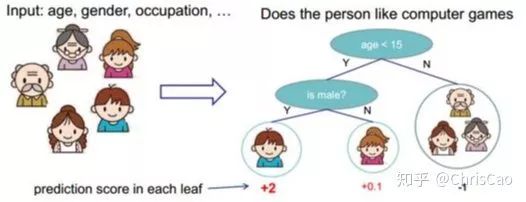
���ݷָ�ָ��ͷָ�����ɷ�Ϊ��ID3��C4.5��CART�㷨��
1.ID3�㷨������Ϣ����Ϊ����ѡ�����Ż�������
��Ϣ����ļ����ǻ�����Ϣ�أ������������ϴ��ȵ�ָ�꣩
��Ϣ��ԽС�����ݼ�
�Ĵ���Խ��
����������ݼ� �Ͻ�����������������
�����

��ʽ(1)�У�
��ʾ��K������������ռ���ݼ�D���������ı�����
��ʽ(2)��ʾ��������A��Ϊ�ָ�����ԣ��õ�����Ϣ�أ�Di��ʾ����������AΪ���֣��ֳ�n����֧����i����֧�Ľڵ㼯�ϡ���ˣ��ù�ʽ��õ���������AΪ���֣�n����֧����Ϣ���ܺ͡�
��ʽ(3)����AΪ���Ի���ǰ�ͻ��ֺ����Ϣ�ز�ֵ��Ҳ������Ϣ���棬Խ��Խ�á�
����ÿ����¼��һ������'ID',������ID���зָ�Ļ�������������ϣ��ܹ�ȡ�õ�����ֵ����������������Ŀ̫�࣬��������һ��ID���л��֣�Ҷ�ӽڵ��ֵֻ����һ�������Ⱥܴõ�����Ϣ����ܴ��������ֳ����ľ�����û�����壬����ID3ƫ����ȡֵ�϶�����Խ��зָ����һ����ƫ����Ϊ������һӰ�죬��ѧ�������C4.5�㷨��
2.C4.5������Ϣ�������� ѡ�����зָ����Ե��㷨
��Ϣ������ͨ������һ������Ϊ������Ϣ(Split information)�ijͷ������ͷ�ȡֵ�϶�����ԣ�
,
���У�IV(a)��������A������ֵ���������ģ�����Խ�࣬IVֵԽ������Ϣ������ԽС�������Ϳ��Ա���ģ��ƫ������ֵ������ԣ�������������ָģ���ֻ�ƫ������ֵ�ٵ����������C4.5�������ȴӺ�ѡ�����������ҳ���Ϣ�������ƽ��ˮƽ�����ԣ��ڴ���ѡ����������ߵġ�
��������ֵ������˵����ȡֵ��Ŀ�������ޣ���˿��Բ�����ɢ������������ַ������д�����������ֵ��С��������Ȼ��ѡ���м�ֵ��Ϊ�ָ�㣬��ֵ����С�ĵ㱻���ֵ�����������ֵ��С�����ĵ㱻�ֵ�������������ָ����Ϣ�����ʣ�ѡ����Ϣ��������������ֵ���зָ
3.CART:�Ի���ϵ��Ϊ��ѡ�����Ż������ԣ������ڷ���ͻع�
CART��һ�ö����������ö�Ԫ�зַ���ÿ�ΰ����ݷֳ����ݣ��ֱ������������������������ÿ����Ҷ�ӽڵ㶼���������ӣ�����CART��Ҷ�ӽڵ�ȷ�Ҷ�ӽڵ��һ�������ID3��C4.5��CART��Ӧ��Ҫ��һЩ���ȿ������ڷ���Ҳ�������ڻع顣CART����ʱ��ѡ�����ָ����Gini��Ϊ��õķ���������gini�������Ǵ��ȣ�����Ϣ�غ������ƣ�CART��ÿ�ε������ή�ͻ���ϵ����
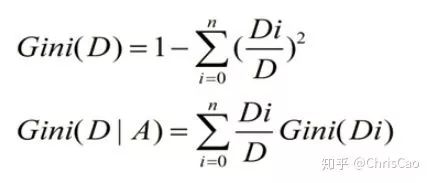
Gini(D)��ӳ�����ݼ�D�Ĵ��ȣ�ֵԽС������Խ�ߡ������ں�ѡ������ѡ��ʹ�û��ֺ����ָ����С��������Ϊ���Ż������ԡ�
�������ͻع���
��˵��������ID3��C4.5��ÿһ�η�֧ʱ�������ÿһ���������Ե�ÿһ����ֵ���ҵ�ʹ�ð�������ֵ<=��ֵ��������ֵ>��ֵ�ֳɵ�������֧����������������ֵ�����ոñ���֧�õ������½ڵ㣬��ͬ���ķ������з�֧��ֱ�������˱������Ա�Ψһ��Ҷ�ӽڵ㣬��ﵽԤ�����ֹ������������Ҷ�ӽڵ����Ա�Ψһ�����Զ����˵��Ա���Ϊ��Ҷ�ӽڵ���Ա�
�ع�����������Ҳ�����ƣ�������ÿ���ڵ�(��һ����Ҷ�ӽڵ�)����õ�Ԥ��ֵ��������Ϊ������Ԥ��ֵ������������ڵ�������������ƽ��ֵ����֧ʱ���ÿ��������ÿ����ֵ������õķָ�㣬�������ı��������С������������ÿ���˵�����-Ԥ�����䣩^2 ���ܺ� / N������˵��ÿ���˵�Ԥ�����ƽ���� ���� N����ܺ����⣬��Ԥ����ֵ�����Խ�࣬����Խ���ף��������Խ��ͨ����С�������������ķ�֧���ݡ���ֱ֧��ÿ��Ҷ�ӽڵ��ϵ��˵����䶼Ψһ(��̫����)�����ߴﵽԤ�����ֹ����(��Ҷ�Ӹ�������)��������Ҷ�ӽڵ����˵����䲻Ψһ�����Ըýڵ��������˵�ƽ��������Ϊ��Ҷ�ӽڵ��Ԥ�����䡣
��.���ɭ��
�Ȳ�����Ϸ������ĸ��������������Ľ�����ж�Ʊ������ȡƽ��ֵ���Դ���Ϊ���յĽ����
1.������Ϸ������ĺô���
(1)����ģ�;��ȣ����ϸ���ģ�͵ķ��������õ��������ľ��߽߱磬������������أ�ʵ�ָ��õķ���Ч����

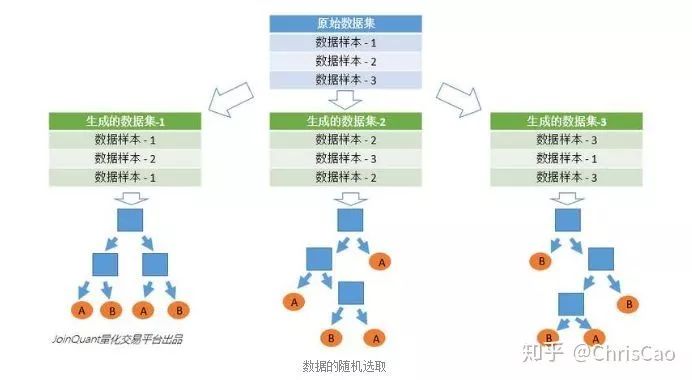
(2)����������С�����ݼ������ݼ��ϴ�ʱ���ɽ����ݼ����ֳɶ���Ӽ������Ӽ������������������ݼ���Сʱ��ͨ����������(bootstrap)��ԭʼ���ݼ������������鲻ͬ�����ݼ���������������
(3)�����߽߱���ڸ��ӣ�������ģ�Ͳ��ܺܺõ�������ʵ�������ˣ��ֶ����ض���������ݼ���ѵ��������Է��������ٽ����Ǽ��ɡ�
(4)�Ƚ��ʺϴ�����Դ�칹���ݣ��洢��ʽ��ͬ����ϵ�͡��ǹ�ϵ�ͣ������ͬ��ʱ���͡���ɢ�͡������͡�����ṹ���ݣ���
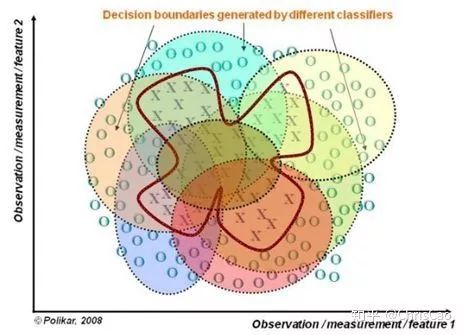
���ɭ����һ�������������Ϸ������������Ҫ�������������棺����ѡȡ������Ժ�����ѡȡ������ԡ�
(1)���ݵ����ѡȡ
��һ����ԭʼ���ݼ��в�ȡ�зŻصij���(bootstrap),���������ݼ��������ݼ��O������ԭʼ���ݼ�������һ������ͬ�������ݼ���Ԫ�ؿ����ظ���ͬһ�������ݼ��е�Ԫ��Ҳ�����ظ���
�ڶ������������ݼ������Ӿ���������������ݷŵ�ÿ���Ӿ������У�ÿ���Ӿ��������һ������������������µ������谡Ӵͨ�����ɭ�ֵõ����������Ϳ���ͨ���Ӿ��������жϽ����ͶƱ���õ����ɭ�ֵ�������������ͼ���������ɭ������3���Ӿ�������2�������ķ�������A�࣬1�������ķ�������B�࣬��ô���ɭ�ֵķ���������A�ࡣ
(2)��ѡ���������ѡȡ
���������ݼ������ѡȡ���漴ɭ���е�������ÿһ�����ѹ��̲�δ�õ����еĴ�ѡ���������Ǵ����еĴ�ѡ���������ѡȡһ����������֮���������ѡȡ��������ѡ�����ŵ�������������ʹ���ɭ���еľ������ܲ�ͬ������ϵͳ�Ķ����ԣ��Ӷ������������ܡ�
�����ʾ��ͼ
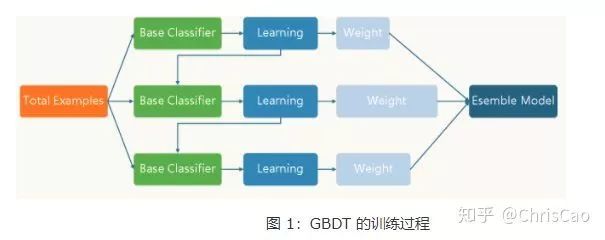
����GBDT��XGBoost
1.�ڽ�GBDT��XGBoost֮ǰ�Ȳ���Bagging��Boosting��֪ʶ��
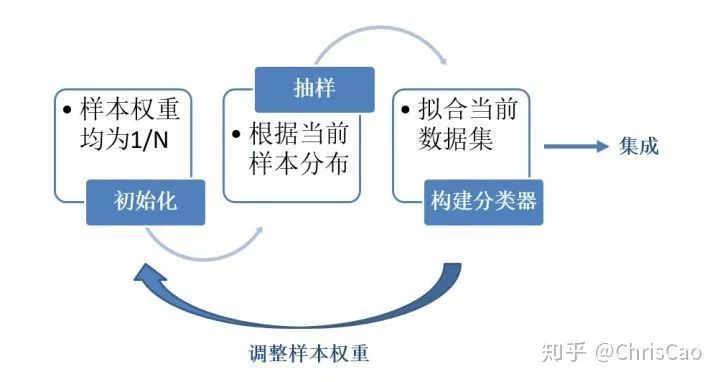
Bagging�Dz��е�ѧϰ�㷨��˼��ܼ���ÿһ����ԭʼ�����и��ݾ��ȸ��ʷֲ��зŻصij�ȡ��ԭʼ���ݼ�һ����С�����ݼ��ϡ���������Գ����ظ���Ȼ���ÿһ�β��������ݼ�����һ�����������ٶԷ�����������ϡ�
Boosting��ÿһ�γ����������ֲ��Dz�һ������ÿһ�ε��������Ǹ�����һ�ε����Ľ�������ӱ���������������Ȩ�ء�ʹģ����֮��ĵ����и���ע�����Է��������������һ������ѧϰ�Ĺ��̣�Ҳ��һ�����������Ĺ��̣������Boosting˼��ı������ڡ�����֮��ÿ�ε����Ļ����������м��ɣ���ô��ν�������Ȩ�صĵ����ͷ������ļ�����������Ҫ���ǵĹؼ����⡣
Boosting�㷨�ṹͼ
��������Adaboost�㷨������
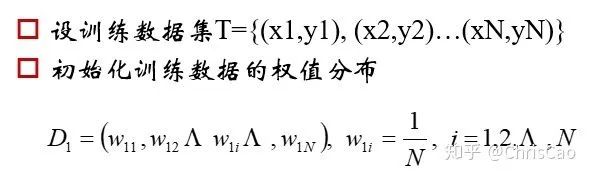
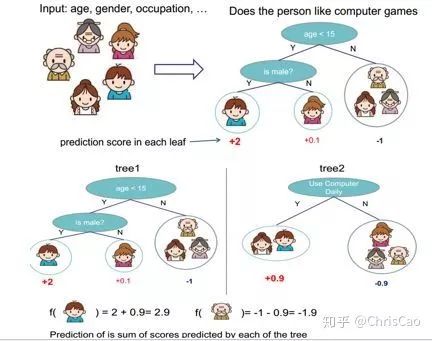
��һ�����ݼ���������СΪN��ÿһ��������Ӧһ��ԭʼ��ǩ��������dz�ʼ��������Ȩ��Ϊ1/N

������ǵ�ǰ�����£�ģ�͵ķ�������ʣ�ģ�͵�ϵ��ֵ�ǻ��ڷ�������ʵ�

����ģ�͵ķ�����������ԭʼ���������ݵķֲ������ӱ����ֵ����ݱ����еĸ��ʣ��Ա���һ�ε�����ʱ���ܱ�ģ������ѵ��

���յķ������Ǹ����������������
2.GBDT
GBDT���Ծ�����(CART)Ϊ��ѧϰ����GB�㷨���ǵ����������Ƿ�������Boost��"����"����˼��һ��Boosting�㷨����һ�������Ĺ��̣�ÿһ���µ�ѵ������Ϊ�˸Ľ���һ�εĽ��������ǰ��Adaboost���̵棬���Ӧ���ܺ������������˼�롣
GBDT�ĺ����ǣ�ÿһ����ѧϰ����֮ǰ���������ۺ͵IJв����в����һ����Ԥ��ֵ���ܵ���ʵֵ���ۼ���������A����ʵ������18�꣬����һ������Ԥ��������12�꣬����6�꣬���в�Ϊ6�ꡣ��ô�ڵڶ����������ǰ�A��������Ϊ6��ȥѧϰ������ڶ���������ܰ�A�ֵ�6���Ҷ�ӽڵ㣬���ۼ��������Ľ��۾���A����ʵ���䣻����ڶ������Ľ�����5�꣬��A��Ȼ����1��IJв����������A������ͱ��1�꣬����ѧϰ��

3.XGBoost
XGBoostt�����GBDT��˵��������ЧӦ������ֵ�Ż�������Ҫ�Ƕ���ʧ������Ԥ��ֵ����ʵֵ������ø�������Ŀ�꺯����Ȼ����������Ԥ��ֵ��ӵ���Ԥ��ֵ��
��ʧ�������£�������һ��������������

�õ�ģ����Ҫ�߱���������Ҫ�أ�һ��Ҫ�кõľ��ȣ����õ���ϳ̶ȣ�������ģ��Ҫ�����ܵļ����ӵ�ģ�����׳��ֹ���ϣ����Ҹ��Ӳ��ȶ�����ˣ����ǹ�����Ŀ�꺯���ұߵ�һ����ģ�͵������ڶ����������Ҳ����ģ���Ӷȵijͷ��
���õ��������ƽ��������˹���������ijͷ�����l1��l2����l1�����ǽ�ģ����Ԫ�ؽ�����ͣ�l2�����Ƕ�Ԫ����ƽ����

ÿһ�ε����������������Ļ����ϣ�����һ����ȥ���ǰ������Ԥ��������ʵֵ֮��IJв�
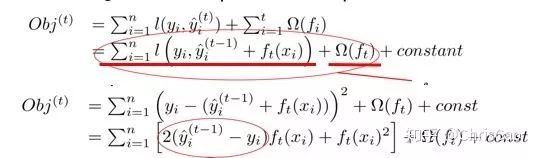
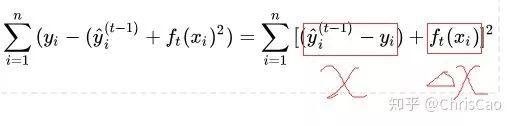
Ŀ�꺯������ͼ�����һ�л�Ȧ����ʵ���Ͼ���Ԥ��ֵ����ʵֵ֮��IJв�
�ȶ�ѵ��������չ����

xgboost��Դ��ۺ��������˶���̩��չ����ͬʱ�õ��˲в�ƽ���͵�һ�Ͷ�����
���о�Ŀ�꺯���е������
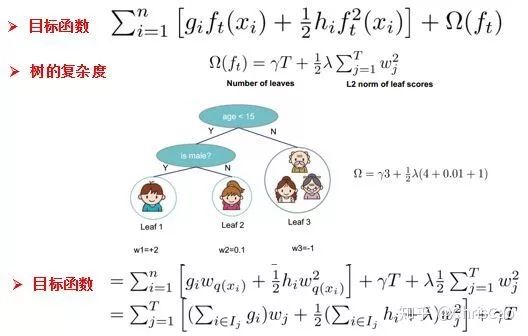
���ĸ��Ӷȿ��������ķ�֧��Ŀ�����������ķ�֧���ǿ�����Ҷ�ӽ�����������ʾ
��ô���ĸ��Ӷ�ʽ�ӣ��ұߵ�һ����Ҷ�ӽ�������T���ڶ���������Ҷ�ӽ��Ȩ��w��l2����������Ϊ�˷�ֹҶ�ӽ�����
��ʱ��ÿһ�ε������൱����ԭ��ģ��������һ������Ŀ�꺯���У�������wq��x����ʾһ���������������Ľṹ�Լ�Ҷ�ӽ���Ȩ�أ�w��ʾȨ�أ���ӳԤ��ĸ��ʣ���q��ʾ�������ڵ������ţ���ӳ���Ľṹ��
�����յõ���Ŀ�꺯���Բ���w������Ŀ�꺯������֪Ŀ�꺯��ֵ�ɺ�ɫ���־�����
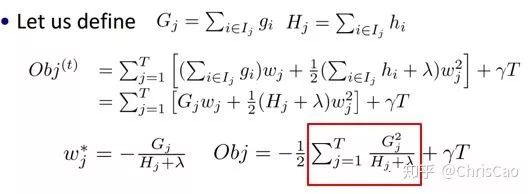
��ˣ�xgboost�ĵ���������ͼ��gainʽ�Ӷ����ָ��ѡ�����ŷָ��ģ�

��ô��εõ������������أ�
һ�ְ취��̰���㷨������һ���ڵ��ڵ��������������չ�ʽ���������ÿһ�������ָ����Ϣ���棬�ҵ���Ϣ�������ĵ�������ķָ���ӵ���Ҷ�ӳͷ����Ӧ�����ļ�֦����gainС��ij����ֵ��ʱ�����ǿ��Լ�������ָ�������ְ취�����������������ʱ����ˣ�������Ҫ���ý����㷨��
��һ�ַ�����XGBoost��Ѱ��splitpoint��ʱ����ö�����е�����ֵ�����������ֵ���оۺ�ͳ�ƣ���������ֵ���ܶȷֲ�������ֱ��ͼ��������ֵ�ֲ��������Ȼ�ֲַ��γ����ɸ�bucket(Ͱ)��ÿ��bucket�������ͬ����bucket�߽��ϵ�����ֵ��Ϊsplit
point�ĺ�ѡ���������еĺ�ѡ���ѵ����ҵ���ѷ��ѵ㡣
��ͼ�����㷨��ʽ�Ľ��ͣ�������k������ֵ��������������ֵ�ֲ���rk��z����ʾ���Ƕ�������k���ԣ�������ֵС��z��Ȩ��֮��ռ��Ȩ�صı�������������Щ����ֵ����Ҫ�̶ȣ����ǰ�������������㹫ʽ��������ֵ�ֳ����ɸ�bucket��ÿ��bucket�ı�����ͬ��ѡȡ�⼸������ֵ�ı߽���Ϊ���ֺ�ѡ�㣬���ɺ�ѡ����ѡ���ѡ����������Ҫʹ�����ڵ�������ѡ���ѽڵ��ֵС��ij����ֵ
�ۺ��������������ǿ��Եõ�xgboost�����GBDT�Ĵ���֮����
1����ͳGBDT��CART��Ϊ����������xgboost��֧�����Է����������ʱ��xgboost�൱�ڴ�L1��L2���������˹�ٻع飨�������⣩�������Իع飨�ع����⣩��
2����ͳGBDT���Ż�ʱֻ�õ�һ������Ϣ��xgboost��Դ��ۺ�������������̩��չ����ͬʱ�õ���һ�Ͷ�������˳����һ�£�xgboost����֧���Զ�����ۺ�����ֻҪ������һ�Ͷ�����
3��xgboost�����ۺ������������������ڿ���ģ�͵ĸ��Ӷȡ������������������Ҷ�ӽڵ������ÿ��Ҷ�ӽڵ��������score��L2ģ��ƽ���͡���Bias-variance tradeoff�Ƕ����������������ģ�͵�variance��ʹѧϰ������ģ���Ӽ���ֹ����ϣ���Ҳ��xgboost���ڴ�ͳGBDT��һ�����ԡ�
4��Shrinkage�����������൱��ѧϰ���ʣ�xgboost�е�eta����ÿ�ε����������µ�ģ�ͣ���ǰ�����һ��С��1��ϵ���������Ż����ٶȣ�ÿ����һС���ƽ�����ģ�ͱ�ÿ����һ�ƽ��������ױ�����������
5���г�����column subsampling����xgboost��������ɭ�ֵ�������֧���г�������ÿ�ε�������������ȫ���������������ܽ�����ϣ����ܼ��ټ��㣬��Ҳ��xgboost���ڴ�ͳgbdt��һ�����ԡ�
6������ȱʧֵ����Ѱ��splitpoint��ʱ����Ը�����Ϊmissing���������б���ͳ�ƣ�ֻ�Ը�������ֵΪnon-missing�������϶�Ӧ������ֵ���б�����ͨ��������̼�����������Ϊϡ����ɢ����Ѱ��splitpoint��ʱ�俪����
7��ָ��ȱʧֵ�ķָ���������Ϊȱʧֵ����ָ����ֵָ����֧��Ĭ�Ϸ���Ϊ�˱�֤�걸�ԣ���ֱ�����missing������ֵ���������䵽��Ҷ�ӽ�����Ҷ�ӽ����������Σ��ֵ��Ǹ��ӽڵ�����������Ĭ�ϵķ�������ĸ��ӽڵ㣬���ܴ�������㷨��Ч�ʡ�
8�����л���������ѵ��֮ǰ��Ԥ�ȶ�ÿ�������ڲ������������ҳ���ѡ�и�㣬Ȼ��Ϊblock�ṹ������ĵ������ظ���ʹ������ṹ������С���������ڽ��нڵ�ķ���ʱ����Ҫ����ÿ�����������棬����ѡ���������Ǹ�����ȥ�����ѣ���ô�����������������Ϳ��Կ����߳̽��У����ڲ�ͬ�����������ϲ��ö��̲߳��з�ʽѰ����ѷָ�㡣


��ͼ����õ�10�����ѧϰ�㷨��
��12000+�ֳ���ϸ SQL ��ٳɣ�
��̨�ظ�����Ⱥ�����ɼ���Сz�ɻ�����Ⱥ