���ࣨspectral clustering���ǹ㷺ʹ�õľ����㷨������ͳ��K-Means�㷨����������ݷֲ�����Ӧ�Ը�ǿ������Ч��Ҳ�����㣬ͬʱ����ļ�����ҲС�ܶ࣬�������ܿɹ����ʵ������Ҳ�����ӡ��ڴ���ʵ�ʵľ�������ʱ��������Ϊ������Ӧ�����ȿ��ǵļ����㷨֮һ���������ǾͶ�������㷨ԭ����һ���ܽᡣ
1. �������
�����Ǵ�ͼ�����ݻ��������㷨�������ھ����еõ��˹㷺��Ӧ�á�������Ҫ˼���ǰ����е����ݿ����ռ��еĵ㣬��Щ��֮������ñ����������������Զ��������֮��ı�Ȩ��ֵ�ϵͣ�������Ͻ���������֮��ı�Ȩ��ֵ�ϸߣ�ͨ�����������ݵ���ɵ�ͼ������ͼ������ͼ��ͬ����ͼ���Ȩ�غ;����ܵĵͣ�����ͼ�ڵı�Ȩ�غ;����ܵĸߣ��Ӷ��ﵽ�����Ŀ�ġ�
էһ��������㷨ԭ����ȷ������Ҫ��ȫ��������㷨�Ļ�����Ҫ��ͼ���е�����ͼ�����Դ����;����������һ�����˽⡣�������Ǿʹ���Щ��Ҫ�Ļ���֪ʶ��ʼ��һ����ѧϰ���ࡣ
2. �������֮һ������Ȩ��ͼ
���������ǻ���ͼ�۵ģ��������������ϰ��ͼ�ĸ������һ��ͼG������һ���õ�ļ���V�ͱߵļ���E����������ΪG(V,E)������V��Ϊ�������ݼ��������еĵ�(v1,v2,��vn)������V�е����������㣬�����б����ӣ�Ҳ����û�б����ӡ����Ƕ���Ȩ��wijΪ��vi�͵�vj֮���Ȩ�ء���������������ͼ������wij=wji��
�����б����ӵ�������vi��vj��wij>0,����û�б����ӵ�������vi��vj��wij=0������ͼ�е�����һ����vi�����Ķ�di����Ϊ�������������бߵ�Ȩ��֮�ͣ���

����ÿ����ȵĶ��壬���ǿ��Եõ�һ��nxn�ĶȾ���D,����һ���ԽǾ���ֻ�����Խ�����ֵ����Ӧ��i�еĵ�i����Ķ������������£�

�������е�֮���Ȩ��ֵ�����ǿ��Եõ�ͼ���ڽӾ���W����Ҳ��һ��nxn�ľ���i�еĵ�j��ֵ��Ӧ���ǵ�Ȩ��wij��
����֮�⣬���ڵ㼯V�ĵ�һ���Ӽ�A?V�����Ƕ��壺
|A|:=�Ӽ�A�е�ĸ���

3. �������֮�������ƾ���
����һ�����ǽ������ڽӾ���W����������������֮���Ȩ��ֵwij��ɵľ���ͨ�����ǿ����Լ�����Ȩ�أ������������У�����ֻ�����ݵ�Ķ��壬��û��ֱ�Ӹ�������ڽӾ�����ô��ô�õ�����ڽӾ����أ�
����˼���ǣ������Զ��������֮��ı�Ȩ��ֵ�ϵͣ�������Ͻ���������֮��ı�Ȩ��ֵ�ϸߣ�����������Ƕ��ԣ�������Ҫ������Ȩ��ֵ��һ����˵�����ǿ���ͨ�������������������ƾ���S������ڽӾ���W��
�����ڽӾ���W�ķ��������ࡣ?-�ڽ�����K�ڽ�����ȫ���ӷ���
����?-�ڽ�������������һ��������ֵ?��Ȼ����ŷʽ����sij������������xi��xj�ľ��롣�����ƾ����sij=||xi?xj||2, Ȼ�����sij��?�Ĵ�С��ϵ���������ڽӾ���W���£�

����ʽ�ɼ���������Ȩ��Ҫ������?,Ҫ������0��û����������Ϣ�ˡ�����Զ�������ܲ���ȷ�������ʵ��Ӧ���У����Ǻ���ʹ��?-�ڽ�����
�ڶ��ֶ����ڽӾ���W�ķ�����K�ڽ���������KNN�㷨�������е������㣬ȡÿ�����������k������Ϊ���ڣ�ֻ�к��������������k����֮���wij>0���������ַ���������ع�֮����ڽӾ���W�ǶԳƣ����Ǻ�����㷨��Ҫ�Գ��ڽӾ���Ϊ�˽���������⣬һ���ȡ�������ַ���֮һ��

�����ֶ����ڽӾ���W�ķ�����ȫ���ӷ������ǰ���ַ����������ַ������еĵ�֮���Ȩ��ֵ������0����˳�֮Ϊȫ���ӷ�������ѡ��ͬ�ĺ˺����������Ȩ�أ����õ��ж���ʽ�˺�������˹�˺�����Sigmoid�˺�������õ��Ǹ�˹�˺���RBF����ʱ���ƾ�����ڽӾ�����ͬ��
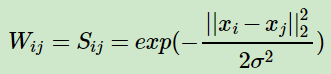
��ʵ�ʵ�Ӧ���У�ʹ�õ�����ȫ���ӷ��������ڽӾ��������ձ�ģ�����ȫ���ӷ���ʹ�ø�˹�����RBF�����ձ�ġ�
4. �������֮����������˹����
������������˹����(Graph Laplacians)�ó�����������Ϊ������㷨��������������ϢϢ��ء����Ķ���ܼ�������˹����L=D?W��D��Ϊ���ǵڶ��ڽ��ĶȾ�������һ���ԽǾ���W��Ϊ���ǵڶ��ڽ����ڽӾ��������������ǵ����ڵķ�����������
��������������˹������һЩ�ܺõ��������£�
��������1��������˹�����ǶԳƾ����������D��W���ǶԳƾ�����á�
��������2������������˹�����ǶԳƾ������������е�����ֵ����ʵ����
��������3���������������f,������

�������������������˹����Ķ�������õ����£�
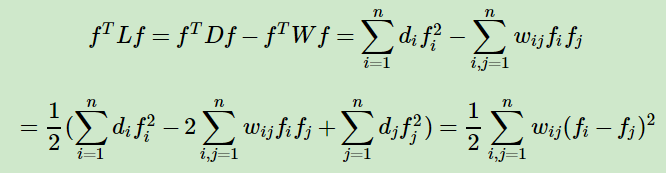
��������4) ������˹�����ǰ������ģ��Ҷ�Ӧ��n��ʵ������ֵ�����ڵ���0����0=��1�ܦ�2�ܡ��ܦ�n�� ����С������ֵΪ0�����������3�����ó���
5. �������֮�ģ�����ͼ��ͼ
��������ͼG����ͼ�����ǵ�Ŀ���ǽ�ͼG(V,E)�г��û�����ӵ�k����ͼ��ÿ����ͼ��ļ���Ϊ��A1,A2,..Ak����������Ai��Aj=?,��A1��A2�ȡ���Ak=V.
��������������ͼ��ļ���A,B?V, A��B=?, ���Ƕ���A��B֮�����ͼȨ��Ϊ��

��ô��������k����ͼ��ļ��ϣ�A1,A2,..Ak�����Ƕ�����ͼcutΪ��
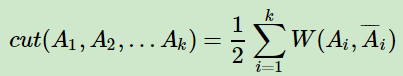
����A????iΪAi�IJ�������Ϊ��Ai�Ӽ�������V���Ӽ��IJ�����
��ô�����ͼ��������ͼ�ڵĵ�Ȩ�غߣ���ͼ��ĵ�Ȩ�غ͵��أ�һ����Ȼ���뷨������С��cut(A1,A2,��Ak), ���ǿ��Է��֣����ּ�С������ͼ�������⣬����ͼ��
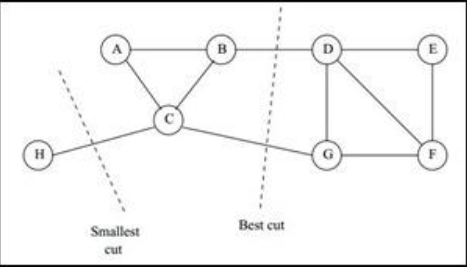
����ѡ��һ��Ȩ����С�ı�Ե�ĵ㣬����C��H֮�����cut������������С��cut(A1,A2,��Ak), ����ȴ�������ŵ���ͼ����α���������ͼ�������ҵ�����ͼ�С�Best Cut��������������ͼ�أ�������һ�ھ�����������ʹ�õ���ͼ����������
6. �����㷨����
�̵�����ô�ã����ڿ����ܽ�������Ļ��������ˡ�һ����˵��������Ҫ��ע���Ϊ���ƾ�������ɷ�ʽ���μ��ڶ��ڣ�����ͼ�ķ�ʽ���μ������ڣ��Լ����ľ�������μ������ڣ���
��õ����ƾ�������ɷ�ʽ�ǻ��ڸ�˹�˾����ȫ���ӷ�ʽ����õ���ͼ��ʽ��Ncut����������õľ����ΪK-Means��������Ncut�ܽ������㷨���̡�
�����������룺������D=(x1,x2,��,xn)�����ƾ�������ɷ�ʽ, ��ά���ά��k1, �������������ά��k2
������������� �ػ���C(c1,c2,��ck2).��
��������1) ������������ƾ�������ɷ�ʽ�������������ƾ���S
��������2���������ƾ���S�����ڽӾ���W�������Ⱦ���D
��������3�������������˹����L
��������4�������������������˹����
��������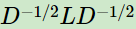
��������5������
��������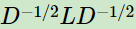
����������С��k1������ֵ�����Զ�Ӧ����������f
��������6) �����Զ�Ӧ����������f��ɵľ����б������������n��k1ά����������F
��������7����F�е�ÿһ����Ϊһ��k1ά����������n��������������ľ�������о��࣬����ά��Ϊk2��
��������8���õ��ػ���C(c1,c2,��ck2).������������������
7. �����㷨�ܽ�
�����㷨��һ��ʹ�����������ǽ����ȴ������ô�����㷨������Ҫ����һ������ѧ��������������������࣬�������Ծ��������ͼ���и���������⡣ͬʱ�Խ�ά������ɷַ���Ҳ��������⡣
�������������ܽ��������㷨����ȱ�㡣
�������������㷨����Ҫ�ŵ��У�
��������1������ֻ��Ҫ����֮������ƶȾ�����˶��ڴ���ϡ�����ݵľ������Ч����㴫ͳ�����㷨����K-Means��������
��������2������ʹ���˽�ά������ڴ�����ά���ݾ���ʱ�ĸ��Ӷȱȴ�ͳ�����㷨�á�
�������������㷨����Ҫȱ���У�
��������1��������վ����ά�ȷdz��ߣ������ڽ�ά�ķ��Ȳ���������������ٶȺ����ľ���Ч�������á�
��������2) ����Ч�����������ƾ���ͬ�����ƾ���õ������վ���Ч�����ܺܲ�ͬ��
��������
ע��������ת�ԣ�https://www.cnblogs.com/pinard/p/6221564.html