贝叶斯(Bayes)分类算法是一类利用概率统计知识进行分类的算法,如朴素贝叶斯(Naive Bayes)算法。这些算法主要利用Bayes定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。由于贝叶斯定理的成立本身需要一个很强的条件独立性假设前提,而此假设在实际情况中经常是不成立的,因而其分类准确性就会下降。为此就出现了许多降低独立性假设的贝叶斯分类算法,如TAN(Tree Augmented Na?ve Bayes)算法,它是在贝叶斯网络结构的基础上增加属性对之间的关联来实现的。
通常,事件A在事件B的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯定理就是这种关系的陈述。
贝叶斯定理是指概率统计中的应用所观察到的现象对有关概率分布的主观判断(即先验概率)进行修正的标准方法。当分析样本大到接近总体数时,样本中事件发生的概率将接近于总体中事件发生的概率。
作为一个规范的原理,贝叶斯法则对于所有概率的解释是有效的;然而,频率主义者和贝叶斯主义者对于在应用中概率如何被赋值有着不同的看法:频率主义者根据随机事件发生的频率,或者总体样本里面的个数来赋值概率;贝叶斯主义者要根据未知的命题来赋值概率。
贝叶斯统计中的两个基本概念是先验分布和后验分布:
先验分布。总体分布参数θ的一个概率分布。贝叶斯学派的根本观点,是认为在关于总体分布参数θ的任何统计推断问题中,除了使用样本所提供的信息外,还必须规定一个先验分布,它是在进行统计推断时不可缺少的一个要素。他们认为先验分布不必有客观的依据,可以部分地或完全地基于主观信念。
后验分布。根据样本分布和未知参数的先验分布,用概率论中求条件概率分布的方法,求出的在样本已知下,未知参数的条件分布。因为这个分布是在抽样以后才得到的,故称为后验分布。贝叶斯推断方法的关键是任何推断都必须且只须根据后验分布,而不能再涉及样本分布。
贝叶斯公式为
P(A∩B)=P(A)*P(B|A)=P(B)*P(A|B)
P(A|B)=P(B|A)*P(A)/P(B)
其中:
1、P(A)是A的先验概率或边缘概率,称作"先验"是因为它不考虑B因素。
2、P(A|B)是已知B发生后A的条件概率,也称作A的后验概率。
3、P(B|A)是已知A发生后B的条件概率,也称作B的后验概率,这里称作似然度。
4、P(B)是B的先验概率或边缘概率,这里称作标准化常量。
5、P(B|A)/P(B)称作标准似然度。
贝叶斯法则又可表述为:
后验概率=(似然度*先验概率)/标准化常量=标准似然度*先验概率
P(A|B)随着P(A)和P(B|A)的增长而增长,随着P(B)的增长而减少,即如果B独立于A时被观察到的可能性越大,那么B对A的支持度越小。
贝叶斯公式为利用搜集到的信息对原有判断进行修正提供了有效手段。在采样之前,经济主体对各种假设有一个判断(先验概率),关于先验概率的分布,通常可根据经济主体的经验判断确定(当无任何信息时,一般假设各先验概率相同),较复杂精确的可利用包括最大熵技术或边际分布密度以及相互信息原理等方法来确定先验概率分布。
全概率公式、贝叶斯公式推导过程
(1)条件概率公式
设A,B是两个事件,且P(B)>0,则在事件B发生的条件下,事件A发生的条件概率(conditional probability)为:
P(A|B)=P(AB)/P(B)
(2)乘法公式
1.由条件概率公式得:
P(AB)=P(A|B)P(B)=P(B|A)P(A) //即为乘法公式;
2.乘法公式的推广:对于任何正整数n≥2,当P(A1A2...An-1) > 0 时,有:
P(A1A2...An-1An)=P(A1)P(A2|A1)P(A3|A1A2)...P(An|A1A2...An-1)
(3)全概率公式
1. 如果事件组B1,B2,.... 满足
1.B1,B2....两两互斥,即 Bi ∩ Bj = ? ,i≠j , i,j=1,2,....,且P(Bi)>0,i=1,2,....;
2.B1∪B2∪....=Ω ,则称事件组 B1,B2,...是样本空间Ω的一个划分
设 B1,B2,...是样本空间Ω的一个划分,A为任一事件,则:
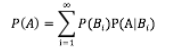 // 即为全概率公式(formula of total probability)
// 即为全概率公式(formula of total probability)
2.全概率公式的意义在于,当直接计算P(A)较为困难,而P(Bi),P(A|Bi) (i=1,2,...)的计算较为简单时,可以利用全概率公式计算P(A)。思想就是,将事件A分解成几个小事件,通过求小事件的概率,然后相加从而求得事件A的概率,而将事件A进行分割的时候,不是直接对A进行分割,而是先找到样本空间Ω的一个个划分B1,B2,...Bn,这样事件A就被事件AB1,AB2,...ABn分解成了n部分,即A=AB1+AB2+...+ABn, 每一Bi发生都可能导致A发生相应的概率是P(A|Bi),由加法公式得
P(A)=P(AB1)+P(AB2)+....+P(ABn) = P(A|B1)P(B1)+P(A|B2)P(B2)+...+P(A|Bn)P(PBn)
3.实例:某车间用甲、乙、丙三台机床进行生产,各台机床次品率分别为5%,4%,2%,它们各自的产品分别占总量的25%,35%,40%,将它们的产品混在一起,求任取一个产品是次品的概率。
解:设..... P(A)=25%*5%+4%*35%+2%*40%=0.0345
(4)贝叶斯公式
1.与全概率公式解决的问题相反,贝叶斯公式是建立在条件概率的基础上寻找事件发生的原因(即大事件A已经发生的条件下,分割中的小事件Bi的概率),设B1,B2,...是样本空间Ω的一个划分,则对任一事件A(P(A)>0),有
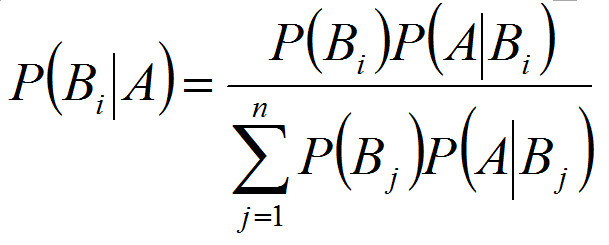
上式即为贝叶斯公式(Bayes formula),Bi 常被视为导致试验结果A发生的”原因“,P(Bi)(i=1,2,...)表示各种原因发生的可能性大小,故称先验概率;P(Bi|A)(i=1,2...)则反映当试验产生了结果A之后,再对各种原因概率的新认识,故称后验概率。
2.实例:发报台分别以概率0.6和0.4发出信号“∪”和“—”。由于通信系统受到干扰,当发出信号“∪”时,收报台分别以概率0.8和0.2受到信号“∪”和“—”;又当发出信号“—”时,收报台分别以概率0.9和0.1收到信号“—”和“∪”。求当收报台收到信号“∪”时,发报台确系发出“∪”的概率。
解:设...., P(B1|A)= (0.6*0.8)/(0.6*0.8+0.4*0.1)=0.923
贝叶斯分类器实例
贝叶斯分类器是各种分类器中分类错误概率最小或者在预先给定代价的情况下平均风险最小的分类器。它的设计方法是一种最基本的统计分类方法。其分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。摘自贝叶斯分类器百度百科
一、从阮一峰网络日志的例子,可以快速理解贝叶斯分类器。
某个医院早上收了六个门诊病人,如下表。
症状 职业 疾病
打喷嚏 护士 感冒
打喷嚏 农夫 过敏
头痛 建筑工人 脑震荡
头痛 建筑工人 感冒
打喷嚏 教师 感冒
头痛 教师 脑震荡
现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:
P(A|B) = P(B|A) P(A) / P(B)
可得
P(感冒|打喷嚏x建筑工人) = P(打喷嚏x建筑工人|感冒) x P(感冒) / P(打喷嚏x建筑工人)
假定"打喷嚏"和"建筑工人"这两个特征是独立的,因此,上面的等式就变成了
P(感冒|打喷嚏x建筑工人) = P(打喷嚏|感冒) x P(建筑工人|感冒) x P(感冒) / P(打喷嚏) x P(建筑工人)
这是可以计算的。
P(感冒|打喷嚏x建筑工人) = 0.66 x 0.33 x 0.5 / 0.5 x 0.33 = 0.66
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
二、朴素贝叶斯分类器的公式
假设某个体有n项特征(Feature),分别为F1、F2、...、Fn。现有m个类别(Category),分别为C1、C2、...、Cm。贝叶斯分类器就是计算出概率最大的那个分类,也就是求下面这个算式的最大值:
P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C) / P(F1F2...Fn)
由于 P(F1F2...Fn) 对于所有的类别都是相同的,可以省略,问题就变成了求
P(F1F2...Fn|C)P(C)
的最大值。
朴素贝叶斯分类器则是更进一步,假设所有特征都彼此独立,因此
P(F1F2...Fn|C)P(C) = P(F1|C)P(F2|C) ... P(Fn|C)P(C)
上式等号右边的每一项,都可以从统计资料中得到,由此就可以计算出每个类别对应的概率,从而找出最大概率的那个类。
虽然"所有特征彼此独立"这个假设,在现实中不太可能成立,但是它可以大大简化计算,而且有研究表明对分类结果的准确性影响不大。
下面再通过两个例子,来看如何使用朴素贝叶斯分类器。
三、账号分类的例子
摘自张洋的《算法杂货铺----分类算法之朴素贝叶斯分类》。
根据某社区网站的抽样统计,该站10000个账号中有89%为真实账号(设为C0),11%为虚假账号(设为C1)。
C0 = 0.89
C1 = 0.11
接下来,就要用统计资料判断一个账号的真实性。假定某一个账号有以下三个特征:
F1: 日志数量/注册天数
F2: 好友数量/注册天数
F3: 是否使用真实头像(真实头像为1,非真实头像为0)F1 = 0.1
F2 = 0.2
F3 = 0
请问该账号是真实账号还是虚假账号?
方法是使用朴素贝叶斯分类器,计算下面这个计算式的值。
P(F1|C)P(F2|C)P(F3|C)P(C)
虽然上面这些值可以从统计资料得到,但是这里有一个问题:F1和F2是连续变量,不适宜按照某个特定值计算概率。
一个技巧是将连续值变为离散值,计算区间的概率。比如将F1分解成[0, 0.05]、(0.05, 0.2)、[0.2, +∞]三个区间,然后计算每个区间的概率。在我们这个例子中,F1等于0.1,落在第二个区间,所以计算的时候,就使用第二个区间的发生概率。
根据统计资料,可得:
P(F1|C0) = 0.5, P(F1|C1) = 0.1
P(F2|C0) = 0.7, P(F2|C1) = 0.2
P(F3|C0) = 0.2, P(F3|C1) = 0.9
因此,
P(F1|C0) P(F2|C0) P(F3|C0) P(C0)
= 0.5 x 0.7 x 0.2 x 0.89
= 0.0623P(F1|C1) P(F2|C1) P(F3|C1) P(C1)
= 0.1 x 0.2 x 0.9 x 0.11
= 0.00198
可以看到,虽然这个用户没有使用真实头像,但是他是真实账号的概率,比虚假账号高出30多倍,因此判断这个账号为真。
四、性别分类的例子
本例摘自维基百科,关于处理连续变量的另一种方法。
下面是一组人类身体特征的统计资料。
性别 身高(英尺) 体重(磅) 脚掌(英寸)
男 6 180 12
男 5.92 190 11
男 5.58 170 12
男 5.92 165 10
女 5 100 6
女 5.5 150 8
女 5.42 130 7
女 5.75 150 9
已知某人身高6英尺、体重130磅,脚掌8英寸,请问该人是男是女?
根据朴素贝叶斯分类器,计算下面这个式子的值。
P(身高|性别) x P(体重|性别) x P(脚掌|性别) x P(性别)
这里的困难在于,由于身高、体重、脚掌都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。怎么办?
这时,可以假设男性和女性的身高、体重、脚掌都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值。
比如,男性的身高是均值5.855、方差0.035的正态分布。所以,男性的身高为6英尺的概率的相对值等于1.5789(大于1并没有关系,因为这里是密度函数的值,只用来反映各个值的相对可能性)。

有了这些数据以后,就可以计算性别的分类了。
P(身高=6|男) x P(体重=130|男) x P(脚掌=8|男) x P(男)
= 6.1984 x e-9P(身高=6|女) x P(体重=130|女) x P(脚掌=8|女) x P(女)
= 5.3778 x e-4
可以看到,女性的概率比男性要高出将近10000倍,所以判断该人为女性。
---------------------------------------------------------------------------------------------------------------------------------


