�Ͻڿ�������Ҫ������Kernel SVM���Ƚ�����ת���ͼ����ڻ�����������ϲ����������㡢������ٶȣ�����Dual SVM����ⷽ���������Kernel SVM�����ܽ�������Է������⣬Ҳ�������dz���������������ά�ķ������⣬�ؼ����ں˺�����ѡ���������Ժ˺���������ʽ�˺�����˹�˺����ȵȡ����ǣ�����֮ǰ������Щ��������Hard-Margin SVM�������뽫���е�������������ȷ���С���������Ҫ��������ӵ�����ת����������ɹ���ϡ����ڿν�����һ��Soft-Margin SVM��Ŀ�����÷������ĵ�Խ��Խ�ã������DZ��뽫���е������ȷ��Ҳ����������noise���ڡ����������ܴ�̶��ϲ���ʹģ���ڸ��ӣ�������ɹ���ϣ����ҷ���Ч������������ġ�
Ŀ¼
1. Motivation and Primal Problem
2. Dual Problem
3. Messages behind Soft-Margin SVM
4. Model Selection
5. �ܽ�
1. Motivation and Primal Problem
�Ͻڿ�����˵����һ�㣬����SVMͬ�����ܻ����overfit��ԭ����������һ�����������ǵ�SVMģ�ͣ���kernel�����ڸ��ӣ�ת����ά��̫�࣬����powerful�ˣ�����һ�����������Ǽ��Ҫ�����е�������������ȷ����������������ڣ����ģ���ڸ��ӡ�����ͼ��ʾ����ߵ�ͼ�����Եģ���Ȼ�м������������Ǵֶ�����ȫ�ֿ����ұߵ�ͼ
���Ĵζ���ʽ�����е㶼������ȷ�ˣ�����ģ�ͱȽϸ��ӣ�������ɹ���ϡ�ֱ������˵����ߵ�ͼ�Ǹ�������ģ�͡�

��α������ϣ������������з������ĵ㣬����ijЩ�㵱����noise��������Щnoise�㣬���Ǿ�������Щnoise����Խ��Խ�á��ع�һ�������ڻ���ѧϰ��ʯ�ʼ��н��ܵ�pocket�㷨��pocket��˼�벻�ǽ����е���ȫ�ֿ��������ҵ�һ�����������÷������ĵ����١���Hard-Margin SVM��Ŀ���ǽ����е㶼��ȫ�ֿ����������д������ڡ�Ϊ�˷�ֹ����ϣ����ǿ��Խ��pocket��˼�룬�������з�����ĵ㣬Ŀ��������Щ��Խ��Խ�á�
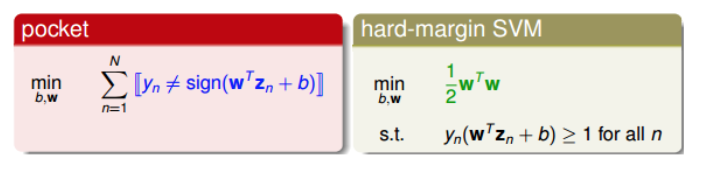
Ϊ����������������ĵ㣬���ǽ�Hard-Margin SVM��Ŀ���������һЩ��Ϻ�������ת��Ϊ������ʽ��
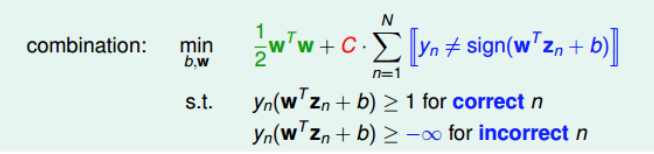
������������У����ڷ�����ȷ�ĵ㣬��������,������noise�㣬����
,��û�����ơ��������Ŀ�����
���������
,��noise��ĸ���������C��������Ϊ��Ȩ��Ŀ���һ��͵ڶ���Ĺ�ϵ����Ȩ��large margin��noise tolerance�Ĺ�ϵ��
�����ٶ������������������������������ϲ����õ���

���ʽ�Ӵ�����������ĵط������ȣ���С��Ŀ���еڶ����Ƿ����Եģ�������QP��������������ʹ��dual����kernel SVM�����㡣Ȼ���ڷ�����ĵ㣬�е����ֱ߽�ܽ�����errorС�����е����ֱ߽��Զ��error�ܴ���ʽ��������Ŀ��û������small error��large error�����ַ���Ч���Dz������ġ�

Ϊ�˸�����Щ���㣬���Ǽ���������������

������ı���ʽ�У������������µIJ�������ʾÿ���㷸����ij̶�ֵ��
.ͨ��ʹ��errorֵ�Ĵ�С�����Ƿ���error����������������⣬����QP��ʽҪ�����ַ��������������ڻ���ѧϰ��ʯ�ʼ��н��ܵ�0/1 error��squared error������soft-margin SVM�����µIJ���
.
���ˣ����յ�Soft-Margin SVM��Ŀ��Ϊ��

�����ǣ�
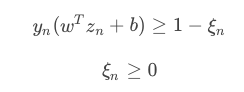
���У���ʾÿ���㷸����ij̶ȣ�
,��ʾû�д���
Խ��ʾ����Խ�������߽磨���ģ�Խ����C��ʾ������ѡ����߽�;����ܲ�Ҫ��������֮���Ȩ�⣬��Ϊ�߽���ˣ�����������ĵ�����ӡ�large C��ʾϣ���õ����ٵķ��������ϧѡ��խ�߽�ҲҪ�����ܰѸ������ȷ���ࣻsmall C��ʾϣ���õ������ı߽磬����ϧ���Ӵ�������ҲҪѡ������ķ���߽硣
��֮��Ӧ��QP�����У������µIJ��������룬�ܹ���������Ϊ
,��������������
��������������Ϊ2N��

2. Dual Problem
�����������ǽ��Ƶ�Soft-Margin SVM�Ķ�żdual��ʽ���Ӷ���QP������Ӽ�����������kernel�㷨�����ȣ����ǰ�Soft-Margin SVM��ԭʼ��ʽд������

Ȼ�������ڵڶ��ڿ��н��ܵ�Hard-Margin SVM����һ��������һ���������պ�������Ϊ������,ԭʼ����������������������������������������
.�������պ����ɱ�ʾΪ������ʽ��

����֮ǰ���ܵ�KKT���������Ƕ���ʽ���м���ʽ����������Ƕ��������պ���������Сֵ����ô�����ݶ��½��㷨˼�룺��Сֵλ�������ݶ�Ϊ�㡣
�����ȶ���ƫ�֣�

������ʽ���õ�,��Ϊ��
,����
.��
���뵽dual��ʽ�в��������Ƿ���
������ȥ�ˣ�

�����ʽ��Hard-Margin SVM�е�dual��ʽ�ǻ���һ�µģ�ֻ��������ͬ����ô�����Ƿֱ����������պ���L��b��w��ƫ����Ϊ�㣬�ֱ�õ���
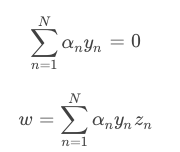
����������Ƶ������ձ���Soft-Margin SVM��Dual��ʽ����ͼ��ʾ��

Soft-Margin SVM Dual��Hard-Margin SVM Dual����һ�£�ֻ��һЩ������ͬ��Hard-Margin SVM Dual������Soft-Margin SVM Dual��
,���µ�������������
.��QP������Soft-Margin SVM Dual�IJ���
ͬ����N�������ǣ�������Hard-Margin SVM Dual�е�N+1�����2N+1����������Ϊ����N��
���Ͻ�������
3. Messages behind Soft-Margin SVM
�Ƶ���Soft-Margin SVM Dual�ļ���ʽ�Ϳ�������QP���ҵ�Q��p��A��c��Ӧ��ֵ�����������߰��õ���ֵ���������ú˺����ķ�ʽ��ͬ�����Լ��㣬�Ż�����Ч����Soft-Margin SVM Dual����
�ķ���������Hard-Margin SVM Dual�Ĺ�������ͬ�ġ�

������θ�����ֵ����b�أ���Hard-Margin SVM Dual�У���complementary slackness������
,�ҵ�SV����
�õ㣬
.
��ô����Soft-Margin SVM Dual�У���Ӧ��complementary slackness��������������Ϊ����������������):

�ҵ�SV�����ĵ㣬���ڲ���
�Ĵ��ڣ���������ȫ�����b��ֵ�����ݵڶ���complementary slackness�����������
,��
,��ô
,���뵽��һ��complementary slackness���������ɼ���õ�
.���ǰ�
�ĵ��Ϊfree SV������˺�����b�ı���ʽΪ��
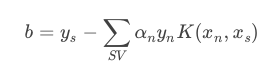
�������b�ᵽ��һ��������,��������Ƿ�һ�������أ����û��free SV������
�ĵ㶼����
��ô�죿һ������£����ٴ���һ��SVʹ
�ĸ����Ǻܴ�ġ��������û��free SV���������ôbͨ�����������ʽ��������ȡֵ��Χ��ֵ�Dz�ȷ���ģ�ֻҪ���ҵ���������KKT����������һ��bֵ�Ϳ����ˡ��ⲿ��ϸ�ڱȽϸ��ӣ���������

�����������ǿ���Cȡ��ͬ��ֵ��margin��Ӱ�졣���磬����Soft-Margin Gaussian SVM��C�ֱ�ȡ1��10��100ʱ����Ӧ��margin����ͼ��ʾ��

����ͼ���Կ�����C=1ʱ��margin�Ƚϴ֣����Ƿ������ĵ�Ҳ�Ƚ϶࣬��CԽ��Խ���ʱ��marginԽ��Խϸ���������ĵ�Ҳ�ڼ��١�����ǰ����ܵģ�Cֵ��ӳ��margin�ͷ�����ȷ��һ��Ȩ�⡣CԽС��Խ�����ڵõ��ֵ�margin���������ӷ������ĵ㣻CԽ��Խ�����ڵõ��ߵķ�����ȷ�ʣ�����margin��ϸ�����Ƿ��֣���Cֵ�ܴ��ʱ����Ȼ������ȷ����ߣ����ܿ��ܰ�noiseҲ�����˴������Ӷ�������ɹ���ϡ�Ҳ����˵Soft-Margin Gaussian SVMͬ�����ܻ���ֹ�����������Բ�����ѡ��dz���Ҫ.
������������ȡ��ֵͬʱ��Ӧ���������塣��֪
��������complementary slackness(�������ɳ���)������
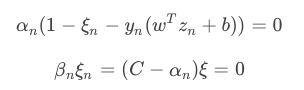
�����õ�
.
��ʾ�õ�û�з�����
��ʾ�õ㲻��SV�����Զ�Ӧ�ĵ���margin֮�⣨������margin�ϣ����Ҿ�������ȷ��
��,�õ�
,��
.
��ʾ�õ�û�з�����
��ʾ�õ���margin�ϡ���Щ�㼴free SV��ȷ����b��ֵ��
��������ȷ��
�Ƿ�Ϊ�㣬�ҵõ�
,���ʽ��ʾ�õ�ƫ��margin�ij̶ȣ�
Խ��ƫ��margin�ij̶�Խ��ֻ�е�
ʱ���õ�����margin�ϡ��������������Ӧ�ĵ���margin֮�ڸ���������margin�ϣ����з�����ȷҲ�з������ġ���Щ���Ϊbounded SV��
���ԣ���Soft-Margin SVM Dual�У�������ȡֵ���Ϳ����ƶ����ݵ��ڿռ�ķֲ������

4. Model Selection
��Soft-Margin SVM Dual�У�kernel��ѡ��C�Ȳ�����ѡ�dz���Ҫ��ֱ��Ӱ�����Ч�������磬����Gaussian SVM����ͬ�IJ�������õ���ͬ��margin������ͼ��ʾ��

���к�������C����������������������������������ͬ��
��ϣ�margin�IJ��ܴ���ô���ѡ����õ�
�ȳ������أ��������õĹ��߾���validation��
validation�����ڻ���ѧϰ��ʯ�γ����Ѿ����ܹ���ֻ��Ҫ���ɲ�ͬ�ȳ������õ���ģ������֤���Ͻ���cross validation��ѡȡ
��С�Ķ�Ӧ��ģ�;Ϳ����ˡ�������ͼ�и���
��ϵõ���
����ͼ��ʾ��

��Ϊ���½ǵ���С�����Ծ�ѡ���
��Ӧ��ģ�͡�ͨ����˵��
������
����������������ʹ�����Ż�ѡ�������ݶ��½�����һ��������ѡȡ��ͬ����ɢ��
ֵ������ϣ��õ���С��
�����Ӧ��ģ�ͼ�Ϊ���ģ�͡������㷨��������֮ǰ�ڻ���ѧϰ��ʯ�н��ܹ���V-Fold cross validation����SVM��ʹ�÷dz��㷺��
V-Fold cross validation��һ�ּ�����Leave-One-Out CV��Ҳ������֤��ֻ��һ������������SVM���⣬������֤��Error���㣺
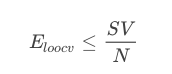
Ҳ����˵��һ����֤��Error��С������֧������SVռ���������ı�������������֤��������������ΪN������N�������SVM�����õ�margin�������N������
,����SV����Զ��margin��������,������ȷ������ʱ���������ֻʹ��ʣ�µ�N-1����������SVM���࣬��ô��N����
��Ȼ�Ƿ�����ȷ�ĵ㣬���õ�SVM margin��ʹ��N����ĵ�������ȫһ�µġ�������Ϊ���Ǽ����N������non-SV����w��bû�й��ף���Ӱ��margin��λ�ú���״������ǰN-1�����N����õ���margin��һ���ġ�
��ô������non-SV�ĵ㣬����,���Ե�N���㣬����Error��ȻΪ�㣺
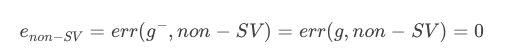
��һ���棬�����N���� ,������SV�ĵ㣬����Error������0��Ҳ������1����Ȼ�У�
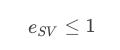
������������֤����.���������֮ǰ�õ��Ľ��ۣ���ֻ��SVӰ��margin��non-SV��marginû���κ�Ӱ�죬����������
SV��������SVMģ��ѡ����Ҳ�Ǻ���Ҫ�ġ�һ����˵��SVԽ�࣬��ʾģ�Ϳ���Խ���ӣ�Խ�п��ܻ���ɹ���ϡ����ԣ�ͨ��ѡ��SV�������ٵ�ģ�ͣ�Ȼ����ʣ�µ�ģ����ʹ��cross-validation���Ƚ�ѡ�����ģ�͡�
5. �ܽ�
���ڿ���Ҫ������Soft-Margin SVM�����ǵij���������Hard-Margin SVM��ͬ����һ��Ҫ�����е������㶼��ȫ�ֿ��������з������ĵ㣬��ʹmargin�ȽϿ���Ȼ��������������Ϊ�������ijͷ������֮ǰ���ܵ�Dual SVM���Ƶ�����Soft-Margin SVM��QP��ʽ���õ���
����Ҫ��������㣬����һ���Ͻ�C�����Ž�����ͨ��
ֵ�Ĵ�С�����Խ����ݵ��Ϊ���֣�non-SVs��free SVs��bounded SVs�����ָ��������������ͱ������ݷ����������������ѡ����ʵ�SVMģ�ͣ�ͨ���İ취��cross-validation������SV����������ɸѡ��