��ƪ��Ҫ�����������֣�
1.�����������
2.�ر�ģ�������ں�������ι�����
3.�����
���
��������Ա���Ϊ��ʹ����㷺�����������Ľ�����������Ĺ� ��ԭ�������ǽ������������ڵ�ַ������google.com���㿴��google��ҳ�����ж�������ʲô��
�����۵������
���죬�������������������IE��Firefox��Safari��Chrome��Opera��
���Ľ�����һЩ��Դ����������ӡ���Firefox�� Chrome��Safari��Safari�Dz��ֿ�Դ�ġ�
����W3C��World Wide Web Consortium ��ά�����ˣ��������ͳ�����ݣ���ǰ��2011��5�£���Firefox��Safari��Chrome���г�ռ�����ۺ��ѽӽ�60������ԭ��Ϊ2009��10�£�����û��̫��仯����ˣ�����˵��Դ������Ѿ�ռ����������г��İ�ڽ�ɽ��
���������Ҫ����
���������Ҫ�����ǽ��û�ѡ���web��Դ���ֳ���������Ҫ�ӷ�����������Դ����������ʾ������������У���Դ�ĸ�ʽͨ����HTML��Ҳ����PDF��image��������ʽ���û���URI��Uniform Resource Identifier ͳһ��Դ��ʶ������ָ����������Դ��λ�ã�������һ���и������ۡ�
HTML��CSS�淶�й涨�����������html�ĵ��ķ�ʽ���� W3C��֯����Щ�淶����ά����W3C�Ǹ����ƶ�web������֯��
HTML�淶�����°汾��HTML4(http://www.w3.org/TR/html401/)��HTML5�����ƶ��У���ע������ǰ�������µ�CSS�淶�汾��2��http://www.w3.org/TR/CSS2����CSS3Ҳ�������ƶ��У���ע��ͬ������ǰ����
��Щ��������������̷����Լ�����չ���Թ淶����ѭ�������ƣ���Ϊweb�����ߴ��������صļ��������⡣
���ǣ���������û��������࣬�������û�����Ԫ�ذ�����
�� ��������URI�ĵ�ַ��
�� ǰ�������˰�ť
�� ��ǩѡ��
�� ����ˢ�¼���ͣ��ǰ�����ĵ���ˢ�¡���ͣ��ť
�� ���ڵ�����ҳ����ҳ��ť
��ֵ��ǣ���û���ĸ���ʽ�����Ĺ淶���û����������涨����Щ�Ƕ����������������֮���ģ�ºͲ��ϸĽ��ý����
HTML5��û�й涨�����������е�UIԪ�أ����г���һЩ����Ԫ�أ�������ַ����״̬����������������һЩ��������Լ�ר�еù��ܣ�����Firefox�����ع���������������ݽ��ں��������û�����ʱ���ܡ�
���������Ҫ����High Level Structure
���������Ҫ���������
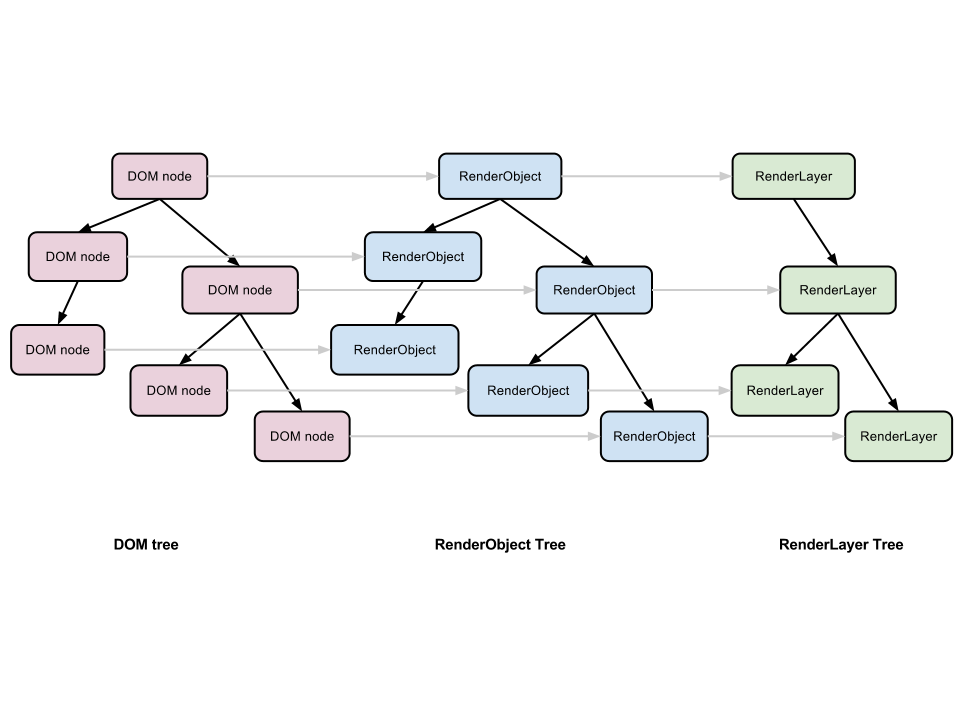
1. �û����棭 ������ַ��������/ǰ����ť����ǩĿ¼�ȣ�Ҳ�������������ij���������ʾ��������ҳ���������֮�����������
2. ��������棭 ������ѯ��������Ⱦ����Ľӿ�
3. ��Ⱦ���棭 ������ʾ��������ݣ����磬�����������Ϊhtml�����������html��css������������Ľ����ʾ����
4. ���磭 �������������ã�����http����������ƽ̨�صĽӿڣ������ڲ�ͬƽ̨�Ϲ���
5. UI ��ˣ� ���������������ѡ��Ի���Ȼ�����������в��ض���ij��ƽ̨��ͨ�ýӿڣ��ײ�ʹ�ò���ϵͳ���û��ӿ�
6. JS�������� ��������ִ��JS����
7. ���ݴ洢�� ���ڳ־ò㣬�������Ҫ��Ӳ���б�������cookie�ĸ������ݣ�HTML5������web database����������һ�������������Ŀͻ��˴洢����
ͼ1���������Ҫ���
��Ҫע����ǣ���ͬ�ڴ��������ChromeΪÿ��Tab�����˸��Ե���Ⱦ����ʵ����ÿ��Tab����һ�������Ľ��̡�
���ڹ������������Щ������������һ��ϸ���ۡ�
������ͨ�� Communication between the components
Firefox��Chrome��������һ�������ͨ�Žṹ�����潫��ר�ŵ�һ�½������ۡ�
��Ⱦ���� The rendering engine
��Ⱦ�����ְ�������Ⱦ�������������������ʾ����������ݡ�
Ĭ������£���Ⱦ���������ʾhtml��xml�ĵ���ͼƬ����Ҳ���Խ��������һ���������չ����ʾ�����������ݣ�����ʹ��PDF�Ķ��������������ʾPDF��ʽ������ר��һ�½���������չ������ֻ������Ⱦ��������Ҫ����;������ʾӦ����CSS֮���html��ͼƬ��
��Ⱦ���� Rendering engines
���������۵����������Firefox��Chrome��Safari�ǻ���������Ⱦ���湹���ģ�Firefoxʹ��Geoko����Mozilla�����з�����Ⱦ���棬Safari��Chrome��ʹ��webkit��
Webkit��һ�Դ��Ⱦ���棬��������Ϊlinuxƽ̨�з��ģ�������Apple��ֲ��Mac��Windows�ϣ����������ο�http://webkit.org��
������ The main flow
��Ⱦ��������ͨ���������������ĵ������ݣ�ͨ����8K�ֿ�ķ�ʽ��ɡ�
��������Ⱦ������ȡ������֮��Ļ������̣�
����html�Թ���dom��->����render��->����render��->����render��
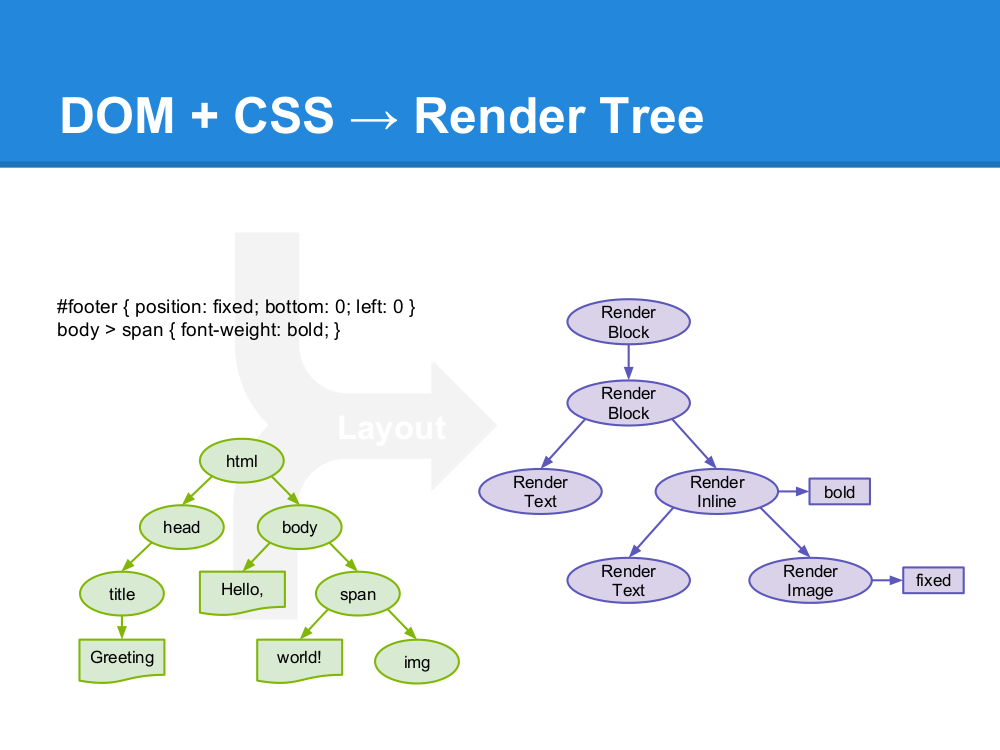
ͼ2����Ⱦ�����������
��Ⱦ���濪ʼ����html��������ǩת��Ϊ�������е�dom�ڵ㡣���ţ��������ⲿCSS�ļ���style��ǩ�е���ʽ��Ϣ����Щ��ʽ��Ϣ�Լ�html�еĿɼ���ָ�������������һ��������render����
Render����һЩ��������ɫ�ʹ�С�����Եľ�����ɣ����ǽ���������ȷ��˳����ʾ����Ļ�ϡ�
Render����������֮����ִ�в��ֹ��̣�����ȷ��ÿ���ڵ�����Ļ�ϵ�ȷ�����ꡣ����һ�����ǻ��ƣ�������render������ʹ��UI��˲����ÿ���ڵ㡣
ֵ��ע����ǣ��������������ɵģ�Ϊ�˸��õ��û����飬��Ⱦ���潫�ᾡ������Ľ����ݳ��ֵ���Ļ�ϣ�������ȵ����е�html���������֮����ȥ�����Ͳ���render�������ǽ�����һ�������ݾ���ʾһ�������ݣ�ͬʱ�����ܻ���ͨ�����������������ݡ�
ͼ3��webkit������
ͼ4��Mozilla��Geoko ��Ⱦ����������
��ͼ3��4�п��Կ���������webkit��Geckoʹ�õ��������в�ͬ�����ǵ���Ҫ���̻�����ͬ��Gecko�ƿɼ��ĸ�ʽ��Ԫ����ɵ���Ϊframe����ÿ��Ԫ�ض���һ��frame��webkit��ʹ��render�������������������Ⱦ������ɵ�����Webkit��Ԫ�صĶ�λ��Ϊ���֣���Gecko�г�Ϊ������Webkit������dom�ڵ㼰��ʽ��Ϣȥ����render���Ĺ���Ϊattachment��Gecko��html��dom��֮�丽����һ�㣬����Ϊ���ݽ��������൱����domԪ�صĹ��������潫���������еĸ����Ρ�
���� Parsing��general
��Ȼ��������Ⱦ������һ���dz���Ҫ�Ĺ��̣����ǽ���������о��������ȼ�Ҫ����һ�½�����
����һ���ĵ�������ת��Ϊ����һ������Ľṹ����������������ʹ�õĶ����������Ľ��ͨ���DZ����ĵ��ṹ�Ľڵ�������Ϊ�������������
���磬������2��3��1���������ʽ�����ܷ�������һ������
ͼ5����ѧ����ʽ���ڵ�
�ķ� Grammars
���������ĵ����ݵ�������ĵ������Ի��ʽ��ÿ�ֿɱ������ĸ�ʽ��������ɴʻ㼰�������ɵ��ض����ķ�����Ϊ���������ķ����������Բ�������һ���ԣ���˲��ܱ�һ��Ľ���������������
���������ʷ������� Parser��Lexer combination
�������Է�Ϊ�����ӹ��̡�����������ʷ�����
�ʷ��������ǽ�����ֽ�Ϊ���ţ����������ԵĴʻ������������Ч��Ԫ�ļ��ϡ���������������˵�����൱�������ֵ��г��ֵ����е��ʡ�
�����ָ������Ӧ�������
������һ�㽫���������������������ʷ�����������ʱҲ�зִ�������������ֽ�Ϊ�Ϸ��ķ��ţ���������������Ե����������ĵ��ṹ���Ӷ��������������ʷ�������֪����ô�����հͻ���֮������ַ���
ͼ6����Դ�ĵ���������
���������ǵ����ģ��������Ӵʷ���������ȡ��һ���µķ��ţ����������������ƥ��һ����������ƥ����һ������������Ŷ�Ӧ�Ľڵ㽫�����ӵ��������ϣ�Ȼ�������������һ�����š����û��ƥ�䵽�������������ڲ�����÷��ţ����Ӵʷ�������ȡ��һ�����ţ�ֱ�������ڲ�����ķ����ܹ�ƥ��һ��������������û���ҵ�ƥ��Ĺ����������׳�һ���쳣������ζ���ĵ���Ч���ǰ��������
ת�� Translation
�ܶ�ʱ���������������ս��������һ����ת����ʹ�á����������ĵ�ת��Ϊ��һ�ָ�ʽ��������Ǹ����ӣ��������ڽ�һ��Դ�����Ϊ�������ʱ���Ƚ�Դ�����Ϊ��������Ȼ����ת��Ϊһ���������ĵ���
ͼ7����������
����ʵ�� Parsing example
ͼ5�У����Ǵ�һ����ѧ����ʽ������һ�������������ﶨ��һ������ѧ���������½������̡�
�ʻ�������ǵ��������������Ӻż����š�
���
1. �����Ե��������Ԫ��������ʽ��term��������
2. �����Կ������������ʽ
3. һ������ʽ����Ϊ����termͨ��һ������������
4. �����������ǼӺŻ����
5. term������һ��������һ������ʽ
����������һ�¡�2��3��1���������
��һ��ƥ���������ַ����ǡ�2�������ݹ���5������һ��term���ڶ���ƥ����ǡ�2��3���������ϵ�2������һ����������������term����һ��ƥ�䷢��������Ľ���������2��3��1����һ������ʽ����Ϊ�����Ѿ�֪����2��3����һ��term��������������һ��term������һ������������һ��term����2������������ƥ���κι��������һ����Ч���롣
�ʻ������Ķ���
�ʻ��ͨ�������������ʽ�����塣
������������Կ��Զ���Ϊ��
INTEGER��0����1��9�ݣ�0��9�ݣ�
PLUS����
MINUS����
���翴���ģ��������������ʽ����������
�ͨ����BNF��ʽ���壬���ǵ����Կ��Զ���Ϊ��
expression :�� term operation term
operation := PLUS | MINUS
term := INTEGER | expression
���һ�����Ե��ķ����������صģ���������������������������������������ķ���һ��ֱ�۵Ķ����ǣ����ķ�������BNF�������ı���ɲ鿴http://en.wikipedia.org/wiki/Context-free_grammar��
���������� Types of parsers
�����ֻ����Ľ����������Զ����½������Ե����Ͻ������Ƚ�ֱ�۵Ľ����ǣ��Զ����½������鿴�����߲�ṹ������ƥ������һ�����Ե����Ͻ���������뿪ʼ������ת��Ϊ����ӵײ����ʼֱ��ƥ��߲����
����һ�������ֽ�������ν�����������ӣ�
�Զ����½���������߲����ʼ��������ʶ�����2��3����������Ϊһ������ʽ��Ȼ��ʶ�����2��3��1��Ϊһ������ʽ��ʶ�����ʽ�Ĺ�����ƥ����������������������߲����
�Ե����Ͻ�����ɨ������ֱ��ƥ����һ������Ȼ���øù���ȡ��ƥ������룬ֱ���������������롣����ƥ��ı���ʽ�������ڽ�����ջ�С�
| Stack |
Input |
| |
2 + 3 �C 1 |
| term |
+ 3 - 1 |
| term operation |
3 �C 1 |
| expression |
- 1 |
| expression operation |
1 |
| expression |
|
�Ե����Ͻ�������Ϊshift reduce ����������Ϊ���������ƶ�������һ��ָ������ָ�����뿪ʼ�����������ƶ���������Ϊ�����
�Զ������� Generating parsers automatically
������������������߿����Զ����ɽ�������ֻ��Ҫָ�����Ե��ķ������ʻ������������Ϳ�������һ��������������һ����������Ҫ�Խ�������������⣬�����ֶ��Ĵ���һ���ɽϺ����ܵĽ������������ף����Խ��������������á�Webkitʹ������֪���Ľ����������������ڴ������������Flex��������������Bison������ܽӴ���Lex��Yacc����Flex��������һ�������˷��Ŷ�����������ʽ��Bison����������BNF��ʽ��ʾ�������
HTML������ HTML Parser
HTML�������Ĺ����ǽ�html��ʶ����Ϊ��������
HTML�ķ����� The HTML grammar definition
W3C��֯�ƶ��淶������HTML�Ĵʻ�������
�����������ķ� Not a context free grammar
�����ڽ���������ᵽ�ģ����������ķ��������������BNF�ĸ�ʽ�����塣
���ҵ��ǣ����еĴ�ͳ������ʽ����������html����Ȼ��������Dz���ֻ����Ϊ���棬���ǽ���������css��js����html���ܼ��ý�����������������ķ������塣
Html ��һ����ʽ�ĸ�ʽ���塪��DTD��Document Type Definition �ĵ����Ͷ��壩�����������������������ķ���html���ӽ���xml�������кܶ���õ�xml��������html�и�xml�ı��塪��xhtml�����Ǽ�IJ�ͬ���ڣ�html�����ݣ�����������һЩ�ض���ǩ����ʱ����ʡ�Կ�ʼ�������ǩ���ܵ���˵������һ��soft�������xml���塢��ִ��
��Ȼ�������������С�IJ���ȴ�����˺ܴ�IJ�ͬ��һ���棬����html���е�ԭ�����Ŀ���ʹweb������Ա�Ĺ����������ɣ�����һ���棬��Ҳʹ����ȥдһ����ʽ�����ķ������ԣ�html�Ľ������������Ȳ����ô�ͳ�Ľ�����������Ҳ������xml������������
HTML DTD
Html����DTD��ʽ���ж��壬��һ��ʽ�����ڶ���SGML��������ԣ������˶���������Ԫ�ؼ����ǵ����ԺͲ�ι�ϵ�Ķ��塣����ǰ���ᵽ�ģ�html DTD��û������һ�����������ķ���
DTD��һЩ���֣���ģʽֻ���ع淶��������ģʽ������˶��������ȥ��ʹ�ñ�ǩ��֧�֣���ô����Ϊ�˼�����ǰ���ݡ����µı�DTD��http://www.w3.org/TR/html4/strict.dtd
DOM
���������Ҳ���ǽ�����������DOMԪ�ؼ����Խڵ���ɵġ�DOM���ĵ�����ģ�͵���д������html�ĵ��Ķ����ʾ����ΪhtmlԪ�ص��ⲿ�ӿڹ�js�ȵ��á�
���ĸ��ǡ�document������
DOM�ͱ�ǩ������һһ��Ӧ�Ĺ�ϵ�����磬���µı�ǩ��
<html>
<body>
<p>
Hello DOM
</p>
<div><img src=��example.png�� /></div>
</body>
</html>
���ᱻת��Ϊ�����DOM����
ͼ8��ʾ����ǩ��Ӧ��DOM��
��htmlһ����DOM�Ĺ淶Ҳ����W3C��֯�ƶ��ġ�����http://www.w3.org/DOM/DOMTR������ʹ���ĵ���һ��淶��һ��ģ������һ���ض���htmlԪ�أ�������http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.htm �鿴html���塣
������ν����������DOM�ڵ���˵������ʵ����DOM�ӿڵ�Ԫ�ع������ɵģ������ʹ���ѱ�������ڲ�ʹ�õ��������Եľ���ʵ�֡�
�����㷨 The parsing algorithm
����ǰ���½������۵ģ�hmtl���ܱ�һ����Զ����»��Ե����ϵĽ�������������
ԭ���ǣ�
1. �������Ա����Ŀ�������
2. �������һЩ�����ķǷ�html���ݴ�����
3. ���������������ģ�ͨ��Դ�벻���ڽ��������з����ı䣬����html�У��ű���ǩ�����ġ�document.write ���������ӱ�ǩ����˵���ڽ���������ʵ������������
����ʹ��������������������Ϊhtml������ר���Ľ�������
Html5�淶����������������㷨���㷨���������Ρ������Ż�����������
���Ż��Ǵʷ������Ĺ��̣����������Ϊ���ţ�html�ķ��Ű�����ʼ��ǩ��������ǩ��������������ֵ��
����ʶ����ʶ������ź��䴫�ݸ���������������ȡ��һ���ַ�����ʶ����һ�����ţ�����ֱ���������������롣
ͼ9��HTML��������
����ʶ���㷨 The tokenization algorithm
�㷨���html���ţ����㷨��״̬����ʾ��ÿ�ζ�ȡ�������е�һ�������ַ�����������Щ�ַ�ת�Ƶ���һ��״̬����ǰ�ķ���״̬��������״̬��ͬӰ����������ζ�ţ���ȡͬ�����ַ���������Ϊ��ǰ״̬�IJ�ͬ���õ���ͬ�Ľ���Խ�����һ����ȷ��״̬��
����㷨�ܸ��ӣ�������һ�����������������ԭ����
����ʾ���������Ż������html��
<html>
<body>
Hello world
</body>
</html>
��ʼ״̬Ϊ��Data State������������<���ַ���״̬��Ϊ��Tag open state������ȡһ��a��z���ַ�������һ����ʼ��ǩ���ţ�״̬��Ӧ��Ϊ��Tag name state����һֱ�������״ֱ̬����ȡ����>����ÿ���ַ������ӵ�����������ϣ������д�������һ��html���š�
����ȡ����>������ǰ�ķ��ž�����ˣ���ʱ��״̬�ص���Data state������<body>���ظ���һ�������̡������html��body��ǩ��ʶ������ˡ����ڣ��ص���Data state������ȡ��Hello world���е��ַ���H����������ʶ���һ���ַ����ţ������Ϊ��Hello world���е�ÿ���ַ�����һ���ַ����š�
����ֱ��������</body>���еġ�<�������ڣ��ֻص��ˡ�Tag open state������ȡ��һ���ַ���/��������һ���պϱ�ǩ���ţ�����״̬ת�Ƶ���Tag name state�������DZ�����һ״̬��ֱ��������>����Ȼ����һ���µı�ǩ���Ų��ص���Data state��������ġ�</html>�����͡�</body>��һ��������
ͼ10�����Ż�ʾ������
���Ĺ����㷨 Tree construction algorithm
�����Ĺ����Σ�������DocumentΪ����DOM������Ԫ�ظ��ӵ����ϡ�ÿ���ɷ���ʶ����ʶ�����ɵĽڵ㽫�ᱻ�����������д������淶�ж�����ÿ���������Ӧ��DomԪ�أ���Ӧ��DomԪ�ؽ��ᱻ��������ЩԪ�س��˻ᱻ���ӵ�Dom���ϣ����������ӵ�����Ԫ�ض�ջ�С������ջ��������Ƕ��δƥ���δ�պϱ�ǩ������㷨Ҳ����״̬�������������е�״̬���ò���ģʽ��
����һ��ʾ�������Ĵ������̣�
<html>
<body>
Hello world
</body>
</html>
��������һ�ε������Ƿ���ʶ������ɵķ������С�
�����ǡ�initial mode�������յ�html���ź�ת��Ϊ��before html��ģʽ�������ģʽ�ж�������Ž����ٴ�������ʱ��������һ��HTMLHtmlElementԪ�أ������丽�ӵ���Document�����ϡ�
״̬��ʱ��Ϊ��before head�������յ�body����ʱ����ʹ����û��head���ţ�Ҳ���Զ�����һ��HTMLHeadElementԪ�ز����ӵ����ϡ�
���ڣ�ת����in head��ģʽ��Ȼ���ǡ�after head���������body���Żᱻ�ٴδ�����������һ��HTMLBodyElement�����뵽���У�ͬʱ��ת�Ƶ���in body��ģʽ��
Ȼ���յ��ַ�����Hello world�����ַ����ţ���һ���ַ������´���������һ��text�ڵ㣬�����ַ������ӵ��ýڵ㡣
���յ�body��������ʱ��ת�Ƶ���after body��ģʽ�����Ž��յ�html�������ţ����������ζ��ת�Ƶ��ˡ�after after body��ģʽ�������յ��ļ�������ʱ�������������̽�����
ͼ11��ʾ��html���Ĺ�������
��������ʱ�Ĵ��� Action when the parsing is finished
������Σ���������ĵ����Ϊ�ɽ����ģ�����ʼ����������ʱģʽ�еĽű�������Щ�ű����ĵ�������ִ�С�
�ĵ�״̬��������Ϊ��ɣ�ͬʱ����һ��load�¼���
Html5�淶���з��Ż����������������㷨(http://www.w3.org/TR/html5/syntax.html#html-parser)��
������ݴ� Browsers error tolerance
�����������һ��htmlҳ���Ͽ�������Ч��������Ĵ��������������Ч���ݲ�����������
���������html����
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
���htmlΥ���˺ܶ����mytag���ǺϷ��ı�ǩ��p��div�����Ƕ�ȵȣ��������������Ȼ����û���κ�Թ�Եļ�����ʾ�����ڽ����Ĺ���������html���ߵĴ���
����������д����������������ǣ����˾��ȵ��ǣ��Ⲣ����html���¹淶�����ݣ�������ǩ��ǰ�����˰�ťһ������ֻ����������ڷ�չ�Ľ����һЩ�Ƚ�֪���ķǷ�html�ṹ��������վ���г��ֹ����������������һ�ֺ����������һ�µķ�ʽȥ����
Html5�淶�������ⷽ�������webkit��html�����ʼ���ֵ�ע�������˺ܺõ��ܽᡣ
�����������Ż����������Ϊ�ĵ��������ĵ��������ҵ��ǣ����DZ��봦���ܶ�û�кܺø�ʽ����html�ĵ�������ҪС�����漸�ִ��������
1. ��δ�պϵı�ǩ��������ȷ��ֹ��Ԫ�ء���������£�Ӧ���Ƚ�ǰһ��ǩ�պ�
2. ����ֱ������Ԫ�ء���Щ����д�ĵ���ʱ��������м�һЩ��ǩ�������м��ǩ�ǿ�ѡ�ģ�������HTML HEAD BODY TR TD LI��
3. ����һ������Ԫ�������ӿ�״Ԫ�ء��ر����е�����Ԫ�أ�ֱ����һ�����ߵĿ�״Ԫ��
4. �����Щ�����У��ͱպϵ�ǰ��ǩֱ���������Ӹ�Ԫ�ء�
��������һЩwebkit�ݴ������ӣ�
</br>���<br>
һЩ��վʹ��</br>���<br>��Ϊ�˼���IE��Firefox��webkit���俴��<br>��
���룺
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Note������Ĵ��������ڲ����У��û���������
��·�ı���
��ָһ������Ƕ������һ�������У�����������ij����Ԫ���ڡ�
��������������ӣ�
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
webkit���ὫǶ�ı����Ϊ�����ֵܱ���
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
���룺
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
webkitʹ�ö�ջ��ŵ�ǰ��Ԫ�����ݣ��������ⲿ����Ķ�ջ�е����ڲ��ı��������DZ�Ϊ���ֵܱ���
Ƕ�ı���Ԫ��
�û���һ������Ƕ����һ�������У���ڶ��������������ԡ�
���룺
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
̫��ı�ǩ�̳�
www.liceo.edu.mx��һ����Ƕ�ײ�ε�վ������ӣ����ֻ����20����ͬ���͵ı�ǩǶ�ף�������Ľ������ԡ�
���룺
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
�Ŵ��˵ط���html��body�պϱ�ǩ
��һ�β���������
֧�ֲ�������html�����Ǵ������պ�body����ΪһЩ������ҳ�����ڻ�δ��������ʱ�ͱպ�����������������end����ȥִ�йرյĴ�����
���룺
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
���ԣ�web������ҪС���ˣ����������Ϊwebkit�ݴ�����ķ�����������д��ʽ���õ�html�ɡ�
CSS���� CSS parsing
���ǵü�����ᵽ�Ľ����ĸ����𣬲�ͬ��html��css�������������ķ���������ǰ���������Ľ�������������Css�淶������css�Ĵʷ�����ķ���
��һЩ���ӣ�
ÿ�����Ŷ����������ʽ�����˴ʷ��ķ����ʻ������
comment ///*[^*]*/*+([^/*][^*]*/*+)*//
num [0-9]+|[0-9]*"."[0-9]+
nonascii [/200-/377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
��ident����ʶ��������д���൱��һ��class������name����һ��Ԫ��id���á��������ã���
���BNF����������
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator selector ] ]
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
˵����һ�������������Ľṹ
div.error , a.error {
color:red;
font-weight:bold;
}
div.error��a.errorʱѡ�������������е����ݰ��������������еĹ�������ṹ������Ķ�������ʽ�Ķ����ˣ�
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
��˵����һ�����Ͼ���һ�����ǿ�ѡ�����Ķ��ѡ��������Щѡ�����Զ��źͿո�S��ʾ�ո��зָ���ÿ�����ϰ��������ż��������е�һ��������ԷֺŸ�����������������ѡ�����ں�����ж��塣
Webkit CSS ������ Webkit CSS parser
Webkitʹ��Flex��Bison������������CSS��ļ����Զ����ɽ�����������һ�½������Ľ��ܣ�Bison����һ���Ե����ϵĽ�������Firefoxʹ���Զ����½����������Ƕ��ǽ�ÿ��css�ļ�����Ϊ��ʽ������ÿ���������css����css����������ѡ���������������Լ�����һЩ����css��Ķ���
ͼ12������css
�ű����� Parsing scripts
���½�����Javascript��
�����ű�����ʽ����˳�� The order of processing scripts and style sheets
�ű�
web��ģʽ��ͬ���ģ�������ϣ��������һ��script��ǩʱ��������ִ�нű����������ĵ��Ľ���ֱ���ű�ִ���ꡣ����ű��������ģ���������������������Դ�����������Ҳ��ͬ���ģ��������ĵ��Ľ���ֱ����Դ���������ģʽ�����˺ܶ��꣬������html4��html5�ж��ر�ָ���ˡ������߿��Խ��ű���ʶΪdefer����ʹ�䲻�����ĵ������������ĵ�����������ִ�С�Html5�����˱�ǽű�Ϊ�첽��ѡ���ʹ�ű��Ľ���ִ��ʹ����һ���̡߳�
Ԥ���� Speculative parsing
Webkit��Firefox����������Ż�����ִ�нű�ʱ����һ���߳̽���ʣ�µ��ĵ��������غ�����Ҫͨ��������ص���Դ�����ַ�ʽ����ʹ��Դ���м��شӶ�ʹ�����ٶȸ��졣��Ҫע����ǣ�Ԥ���������ı�Dom����������������������������̣��Լ�ֻ�����ⲿ��Դ�����ã������ⲿ�ű�����ʽ����ͼƬ��
��ʽ�� Style sheets
��ʽ��������һ�ֲ�ͬ��ģʽ�������ϣ���Ȼ��ʽ�����ı�Dom����Ҳ��û�б�Ҫͣ���ĵ��Ľ����ȴ����ǣ�Ȼ��������һ�����⣬�ű��������ĵ��Ľ���������������ʽ��Ϣ�������ʽ��û�м��غͽ������ű����õ������ֵ����Ȼ�⽫�ᵼ�ºܶ����⣬�⿴�����Ǹ���Ե�������ȷʵ�ܳ�����Firefox�ڴ�����ʽ�����ڼ��غͽ���ʱ�������еĽű�����chromeֻ�ڵ��ű���ͼ����ijЩ���ܱ�δ���ص���ʽ����Ӱ����ض�����ʽ����ʱ��������Щ�ű���
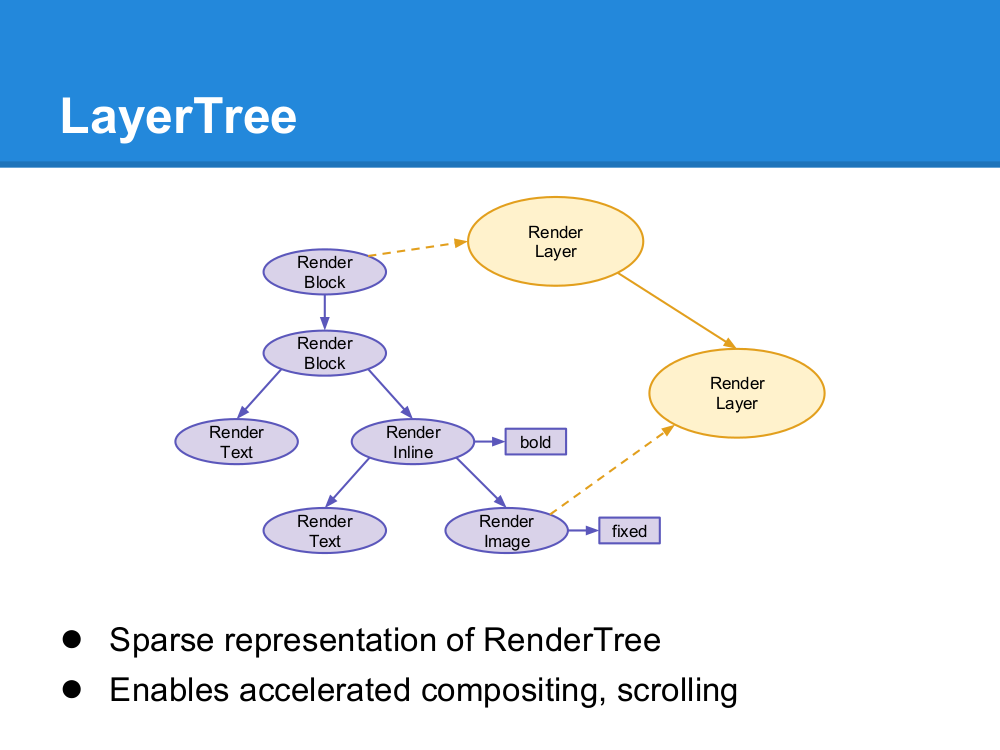
��Ⱦ���Ĺ��� Render tree construction
��Dom���������ʱ���������ʼ������һ����������Ⱦ������Ⱦ����Ԫ����ʾ�����еĿɼ�Ԫ����ɣ������ĵ��Ŀ��ӻ���ʾ�������������Ϊ������ȷ��˳������ĵ����ݡ�
Firefox����Ⱦ���е�Ԫ�س�Ϊframes��webkit����renderer����Ⱦ������������ЩԪ�ء�
һ����Ⱦ����ֱ����ô���ּ������Լ�������children��
RenderObject��Webkit����Ⱦ������࣬���Ķ������£�
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
ÿ����Ⱦ������һ���ýڵ��css��ģ�����Ӧ�ľ�����������ʾ������css2����������������������������ߺ�λ��֮��ļ�����Ϣ����ģ�͵������ܸýڵ���ص�display��ʽ���Ե�Ӱ�죨�ο���ʽ�����½ڣ��������webkit����˵������θ���display���Ծ���ij���ڵ㴴���������͵���Ⱦ����
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Ԫ�ص�����Ҳ��Ҫ���ǣ����磬�����ؼ��ͱ����������Ŀ�ܡ�
��webkit�У����һ��Ԫ���봴��һ���������Ⱦ��������Ҫ��д��createRenderer��������ʹ��Ⱦ����ָ����������Ϣ����ʽ����
��Ⱦ����Dom���Ĺ�ϵ The render tree relation to the DOM tree
��Ⱦ�����DomԪ�����Ӧ�������ֶ�Ӧ��ϵ����һ��һ�ģ����ɼ���DomԪ�ز��ᱻ������Ⱦ��������headԪ�ء����⣬display����Ϊnone��Ԫ��Ҳ��������Ⱦ���г��֣�visibility����Ϊhidden��Ԫ�ؽ���������Ⱦ���У���
����һЩDomԪ�ض�Ӧ�����ɼ���������һ����һЩ���и��ӽṹ��Ԫ�أ�����һ�����������������磬selectԪ����������Ⱦ����һ����ʾ����һ�������б���һ����ť��ͬ�������ı���Ϊ���Ȳ���������ʱ�����н���Ϊ�������ȾԪ�ر����ӡ���һ�������Ⱦ����������Dz��淶��html������css�淶��һ������Ԫ��ֻ�ܽ���������Ԫ�ػ��������״Ԫ�أ��ڴ��ڻ������ʱ�����ᴴ�������Ŀ�״��Ⱦ�������ס����Ԫ�ء�
һЩ��Ⱦ���������Ӧ��Dom�ڵ㲻��������ͬ��λ�ã����磬�����;��Զ�λ��Ԫ�����ı���֮�⣬���������ϵ�λ�ò�ͬ����Ⱦ���ϱ�ʶ����ʵ�Ľṹ������һ��ռλ�ṹ��ʶ������ԭ����λ�á�
ͼ12����Ⱦ������Ӧ��Dom��
������������ The flow of constructing the tree
Firefox�У�����Ϊһ������Dom���µļ���������frame�Ĵ���ί�ɸ�Frame Constructor�����������������ʽ���ο���ʽ���㣩������һ��frame��
Webkit�У�������ʽ��������Ⱦ����Ĺ��̳�Ϊattachment��ÿ��Dom�ڵ���һ��attach������attachment�Ĺ�����ͬ���ģ������½ڵ��attach�������ڵ���뵽Dom���С�
����html��body��ǩ��������Ⱦ���ĸ����������Ⱦ�����Ӧ��css�淶��Ϊcontaining block��Ԫ�ء����������������п�Ԫ�صĶ�����Ԫ�ء����Ĵ�С����viewport������������ڵ���ʾ����Firefox����ΪviewPortFrame��webkit��ΪRenderView����������ĵ���ָ�����Ⱦ�������������IJ��ֶ�����Ϊһ�������Dom�ڵ㱻������
��ʽ���� Style Computation
������Ⱦ����Ҫ�����ÿ����Ⱦ����Ŀ������ԣ������ͨ������ÿ��Ԫ�ص���ʽ���Եõ���
��ʽ����������Դ����ʽ����������ʽԪ�ؼ�html�еĿ��ӻ����ԣ�����bgcolor�������ӻ�����ת��Ϊcss��ʽ���ԡ�
��ʽ����Դ�������Ĭ����ʽ������ҳ�����ߺ��û��ṩ����ʽ��������Щ��ʽ��������û��ṩ�ģ�����������û�����ϲ������ʽ�����磬��Firefox�У�����ͨ����Firefox ProfileĿ¼�·�����ʽ��ʵ�֣���
������ʽ��һЩ���ѣ�
1. ��ʽ�����Ƿdz���Ľṹ�������������ʽ���Ի�����ڴ�����
2. ����������Ż����ҵ�ÿ��Ԫ��ƥ��Ĺ���ᵼ���������⣬Ϊÿ��Ԫ�ز���ƥ��Ĺ�����Ҫ�����������������������кܴ�Ĺ�������ѡ��������и��ӵĽṹ��ƥ������������һ����ʼ������ȷ������ȴ��֤�������õ�·���������ȥ������һ��·����
���磬�����������ѡ���
div div div div������
����ζ�Ź���Ӧ�õ�����div�ĺ��divԪ�أ�ѡ������һ���ض���·��ȥ��飬�������Ҫ�����ڵ��������ȴ������ֻ������div�ĺ��������ʹ�øù���Ȼ������Ҫ������һ��·��ȥ����
3. Ӧ�ù����漰�dz����ӵļ��������Ƕ����˹���IJ��
��������һ���������δ�����Щ���⣺
������ʽ����
webkit�ڵ�������ʽ������Ⱦ��ʽ����ijЩ����£���Щ������Ա��ڵ�乲������Щ�ڵ���Ҫ���ֵܻ��DZ��ֵܽڵ㣬���ң�
1. ��ЩԪ�ر��봦����ͬ�����״̬�����粻��һ������hover������һ�����ǣ�
2. ������Ԫ�ؾ���id
3. ��ǩ������ƥ��
4. class���Ա���ƥ��
5. ��Ӧ�����Ա�����ͬ
6. ����״̬����ƥ��
7. ����״̬����ƥ��
8. ������Ԫ�ر�����ѡ����Ӱ��
9. Ԫ�ز�����������ʽ����
10. ��������Ч���ֵ�ѡ������webcore���κ��ֵ�ѡ��������ʱֻ�Ǽ��׳�һ��ȫ��ת����������������ʾʱʹ�����ĵ�����ʽ����ʧЧ����Щ������ѡ����������:first-child��:last-child������ѡ������
Firefox������ Firefox rule tree
Firefox����������������ʽ���㣭����������ʽ����������webkitҲ����ʽ�������Dz�û�д洢��������ʽ�����������������У�ֻ����Dom�ڵ�ָ������ص���ʽ��
ͼ14��Firefox��ʽ��������
��ʽ�����İ�������ֵ����Щֵ��ͨ������ȷ˳��Ӧ������ƥ��Ĺ�������������ֵת��Ϊ�����ֵ�����磬�����ֵΪ��Ļ�İٷֱȣ���ͨ�����㽫��ת��Ϊ���Ե�λ����ʽ����ʹ��ȷʵ�������ʹ���ڽڵ��й�������Щֵ����Ҫ����μ��㣬ͬʱҲ��ʡ�˴洢�ռ䡣
����ƥ��Ĺ��洢�ڹ������У�һ��·���еĵײ�ڵ�ӵ����ߵ����ȼ�����������������ҵ������й���ƥ���·������ע������ȡ������Ϊÿ��·����Ӧһ���ڵ㣬·���ϰ����˸ýڵ���ƥ������й���������������һ��ʼ��Ϊ���нڵ���м��㣬������ij���ڵ���Ҫ������ʽʱ���Ž�����Ӧ�ļ��㲢��������·�����ӵ����С�
���ǽ����ϵ�·�����ɴǵ��еĵ��ʣ������Ѿ�����������µĹ�������
������ҪΪ�������е���һ���ڵ�ƥ���������֪��ƥ��Ĺ�������ȷ��˳��ΪB-E-I����Ϊ�����Ѿ��������·��A-B-E-I-L�����������Ѿ�����������·����ʣ�µĹ����ͺ����ˡ�
��������һ������α��档
�ṹ��
��ʽ�����İ��ṹ���֣���Щ�ṹ��������border��color�������ض��������ʽ��Ϣ��һ���ṹ�е��������Բ��Ǽ̳еľ��ǷǼ̳еģ��Լ̳е����ԣ�����Ԫ�������ж��壬����ʹ�����parent�̳С��Ǽ̳е����ԣ���Ϊreset���ԣ����û�ж��壬��ʹ��Ĭ�ϵ�ֵ��
��ʽ�����������������Ľṹ������������ֵ��������������ײ�ڵ�û��Ϊһ���ṹ�ṩ���壬��ʹ���ϲ�ڵ㻺��Ľṹ��
ʹ�ù�����������ʽ������
��Ϊһ���ض���Ԫ�ؼ�����ʽʱ�����ȼ�����������е�һ��·��������ʹ���Ѿ����ڵ�һ����Ȼ��ʹ��·���еĹ���ȥ����µ���ʽ�����ģ�����ʽ�ĵײ�ڵ㿪ʼ��������������ȼ���ͨ�������ض���ѡ��������������������ֱ�������ṹ��������Ǹ�����ڵ�û�ж�������Ľṹ����������·�����ϣ�ֱ���ҵ��ýṹ����
�������û���ҵ��ýṹ���κι����壬��ô�������ṹ�Ǽ̳��͵ģ����ҵ������������е�parent�Ľṹ����������£�����Ҳ�ɹ��Ĺ����˽ṹ���������ṹ��reset�͵ģ���ʹ��Ĭ�ϵ�ֵ��
����ض��Ľڵ�������ֵ����ô��Ҫ��һЩ����ļ����Խ���ת��Ϊʵ��ֵ��Ȼ�������ϵĽڵ㻺���ֵ��ʹ����children����ʹ�á�
��һ��Ԫ�غ�����һ���ֵ�Ԫ��ָ��ͬһ�����ڵ�ʱ����������ʽ�����Ŀ��Ա����ǹ�����
����һ�����ӣ��������������html
<html>
<body>
<div class="err" id="div1">
<p>this is a
<span class="big"> big error </span>
this is also a
<span class="big"> very big error</span>
error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
�Լ�������Щ����
1. div {margin:5px;color:black}
2. .err {color:red}
3. .big {margin-top:3px}
4. div span {margin-bottom:4px}
5. #div1 {color:blue}
6. #div2 {color:green}
�������⣬����ֻ��������ṹ����color��margin��color�ṹֻ����һ����Ա����ɫ��margin�ṹ�����ıߡ�
���ɵĹ��������£��ڵ�����ָ��Ĺ���
�����������£��ڵ�����ָ��Ĺ���ڵ㣩
�������ǽ���html�������ڶ���div��ǩ��������ҪΪ����ڵ㴴����ʽ�����ģ������������ʽ�ṹ��
���ǽ��й���ƥ�䣬�ҵ����divƥ��Ĺ���Ϊ1��2��6�����Ƿ��ֹ��������Ѿ�������һ�����ǿ���ʹ�õ�·��1��2������ֻ��Ϊ����6����һ���ڵ����ӵ����棨���ǹ������е�F����
Ȼ��һ����ʽ�����IJ�����ŵ����������У��µ���ʽ�����Ľ�ָ��������еĽڵ�F��
����������Ҫ��������ʽ�����ģ��ȴ����margin�ṹ��ʼ����Ȼ���һ������ڵ�û������margin�ṹ������·�����ϣ�ֱ���ҵ������ǰ�����ڵ������Ľṹ�����Ƿ���B�������ָ��marginֵ�Ľڵ㡣��Ϊ�Ѿ�����color�ṹ�Ķ��壬���Բ���ʹ�û���Ľṹ����Ȼcolorֻ��һ�����ԣ�Ҳ�Ͳ���Ҫ����·����������������ԡ����������ֵ�����ַ���ת��ΪRGB�ȣ�������������Ľṹ��
�ڶ���spanԪ�ظ������й���ƥ�������ָ�����G����ǰһ��spanһ������Ȼ���ֵܽڵ�ָ��ͬһ���ڵ㣬�Ϳ��Թ�����������ʽ�����ģ�ֻ��ָ��ǰһ��span�������ġ�
��Ϊ�ṹ�а����̳���parent�Ĺ��������������˻��棨color�����Ǽ̳����ģ���Firefox������Ϊreset���ڹ������л��棩��
���磬�������Ϊһ��paragraph���������ӹ���
p {font-family:Verdana;font size:10px;font-weight:bold}
��ô���p���������е��ӽڵ�div���Ṳ������parentһ����font�ṹ���������������û��Ϊ���divָ��font����ʱ��
Webkit�У���û�й�������ƥ��������ᱻ�����ĴΣ�����Ӧ�÷�important�ĸ����ȼ����ԣ�֮������Ӧ����Щ���ԣ�����Ϊ���������������ǣ�����display��������Ǹ����ȼ�important�ģ�������һ�����ȼ���important�ģ������һ�����ȼ�important�Ĺ������������ֶ�ε����Խ���������ȷ�ļ���˳����д��������һ����Ч��
�ܽ�һ�£�������ʽ���ṹ�����������ݣ����������1��3��Firefox�Ĺ�������������ȷ��˳��Ӧ�ù���
�Թ�����д����Լ�ƥ�����
��ʽ�����м�����Դ��
�� �ⲿ��ʽ����style��ǩ�ڵ�css����
�� ������ʽ����
�� html���ӻ����ԣ�ӳ��Ϊ��Ӧ����ʽ����
��������������ƥ�䵽Ԫ�أ���Ϊ������ӵ�е���ʽ���Ժ�html���Կ��Խ�Ԫ����Ϊkey����ӳ�䡣
����ǰ������2���ᵽ�ģ�css�Ĺ���ƥ����ܺܽƻ���Ϊ�˽��������⣬�����ȶԹ�����д�������ʹ������ױ����ʡ�
��������ʽ��֮��������ѡ�������һЩhashӳ�䣬ӳ������Ǹ���id��class����ǩ�������κβ�������Щ������ۺ�ӳ�䡣���ѡ���Ϊid���������ӵ�idӳ�䣬�����class�������ӵ�classӳ�䣬�ȵȡ�
���������ƥ���������ף�����Ҫ�鿴ÿ�������������ܴ�ӳ�����ҵ�һ��Ԫ�ص���ع�������Ż�ʹ�ڽ��й���ƥ��ʱ������95�����Ĺ�������
�����������ʽ����
p.error {color:red}
#messageDiv {height:50px}
div {margin:5px}
��һ����������classӳ�䣬�ڶ�������idӳ�䣬�������DZ�ǩӳ�䡣
�������htmlƬ�Σ�
<p class="error">an error occurred </p>
<div id=" messageDiv">this is a message</div>
���������ҵ�pԪ�ض�Ӧ�Ĺ���classӳ�佫����һ����error����key���ҵ�p.error�Ĺ���div��idӳ��ͱ�ǩӳ���ж�����صĹ���ʣ�µĹ��������ҳ���Щ��key��Ӧ�Ĺ�������Щȷʵ����ȷƥ��ġ�
���磬���div�Ĺ�����
table div {margin:5px}
��Ҳ�DZ�ǩӳ������ģ���Ϊkey�����ұߵ�ѡ�������������ƥ�������divԪ�أ���Ϊ�����divû��table���ȡ�
Webkit��Firefox���������������
����ȷ�ļ���˳��Ӧ�ù���
��ʽ����ӵ�ж�Ӧ���пɼ����Ե����ԣ��������û�б��κ�ƥ��Ĺ��������壬��ôһЩ���Կ��Դ�parent����ʽ�����м̳У�����һЩʹ��Ĭ��ֵ��
�������IJ�������Ϊ���ڲ�ֹһ���Ķ��壬�����ü���˳����������⡣
��ʽ���ļ���˳��
һ����ʽ���Ե����������ڼ�����ʽ���г��֣�������һ����ʽ���г��ֶ�Σ���ˣ�Ӧ�ù����˳��������Ҫ�����˳����Ǽ���˳����css2�Ĺ淶������˳��Ϊ���ӵ͵��ߣ���
1. ���������
2. �û�����
3. ���ߵ�һ������
4. ���ߵ�important����
5. �û�important����
��������������Ҫ�ģ��û�ֻ�������������Ϊimportantʱ�ŻḲ�����ߵ�����������ͬ�ȼ��������������specifity�Լ����DZ�����ʱ��˳���������Html���ӻ����Խ���ת��Ϊƥ���css���������DZ���Ϊ������ȼ������߹���
Specifity
Css2�淶�ж����ѡ���specifity���£�
�� �����������style���ԣ�������һ��ѡ�����Ĺ������1�������0����a��
�� ����ѡ������id���Ե���������b��
�� ����ѡ������class��α�����������c��
�� ����ѡ������Ԫ������αԪ�ص���������d��
����a��b��c��d�ĸ���������һ��������ļ���ϵͳ�����õ�specifity������ʹ�õĻ����ɷ�������ߵĻ������塣���磬���aΪ14������ʹ��16���ơ���ͬ����£�aΪ17ʱ������Ҫʹ�ð���������17��Ϊ����������������������ѡ���ʱ����html body div div ����ѡ�������17����ǩ��һ�㲻̫���ܣ���
һЩ���ӣ�
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
��������
����ƥ�����Ҫ���ݼ���˳��Թ����������webkit�Ƚ�С�б���ð�������ٽ����Ǻϲ�Ϊһ�����б���webkitͨ��Ϊ����д��>��������ִ������
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
���� Gradual process
webkitʹ��һ����־λ��ʶ���ж�����ʽ�����Ѽ��أ������attchʱ��ʽû����ȫ���أ������ռλ���������ĵ��б�ǣ�һ����ʽ����ɼ��ؾ����½��м��㡣
���� Layout
����Ⱦ�����������ӵ����У����Dz�û��λ�úʹ�С��������Щֵ�Ĺ��̳�Ϊlayout��reflow��
Htmlʹ�û������IJ���ģ�ͣ���ζ�Ŵ�ʱ�䣬�����Ե�һ��;�����м��μ��㡣���п����Ԫ�ز�����Ӱ��ǰ��Ԫ�صļ������ԣ����Բ��ֿ������ĵ��д����������϶��µĽ��С�Ҳ����һЩ���⣬����html tables��
����ϵͳ����ڸ�frame��ʹ��top��left���ꡣ
������һ���ݹ�Ĺ��̣��ɸ���Ⱦ����ʼ������Ӧhtml�ĵ�Ԫ�أ����ּ����ݹ��ͨ��һЩ�����е�frame�㼶��Ϊÿ����Ҫ������Ϣ����Ⱦ������м��㡣
����Ⱦ�����λ����0,0�����Ĵ�С��viewport����������ڵĿɼ����֡�
���е���Ⱦ������һ��layout��reflow������ÿ����Ⱦ���������Ҫ���ֵ�children��layout������
Dirty bit ϵͳ
Ϊ�˲���Ϊÿ��С�仯��ȫ�����²��֣������ʹ��һ��dirty bitϵͳ��һ����Ⱦ�������˱仯���DZ������ˣ��ͱ����������childrenΪdirty����Ҫlayout������������ʶ��dirty��children are dirty��children are dirty˵����ʹ�����Ⱦ�������û���⣬����������һ��child��Ҫlayout��
ȫ�ֺ����� layout
��layout��������Ⱦ������ʱ����Ϊȫ��layout���������������Щ����·�����
1. һ��ȫ�ֵ���ʽ�ı�Ӱ�����е���Ⱦ�������ֺŵĸı�
2. ����resize
layoutҲ�����������ģ�����ֻ�б�־Ϊdirty����Ⱦ��������²��֣�Ҳ������һЩ����IJ��֣������� layout������Ⱦ����dirtyʱ�첽���������磬��������յ��µ����ݲ����ӵ�Dom�����µ���Ⱦ��������ӵ���Ⱦ���С�
ͼ20������ layout
�첽��ͬ��layout
����layout�Ĺ������첽�ģ�FirefoxΪ����layout������reflow���У��Լ�һ������ִ����Щ���������WebkitҲ��һ����ʱ������ִ������layout����������Ϊdirty״̬����Ⱦ�������²��֡�
���⣬���ű�������ʽ��Ϣʱ�����硰offsetHeight������ͬ���Ĵ����������֡�
ȫ�ֵ�layoutһ�㶼��ͬ��������
��Щʱ��layout�ᱻ��Ϊһ����ʼlayout֮��Ļص������绬�����Ļ�����
�Ż�
��һ��layout��Ϊresize������Ⱦλ�øı䣨�����Ǵ�С�ı䣩������ʱ����Ⱦ����Ĵ�С����ӻ����ж�ȡ�����������¼��㡣
һ������£����ֻ�����������ı䣬��layout�����Ӹ���ʼ��������������ڣ��仯������Ԫ���������Ҳ�Ӱ������ΧԪ�أ����磬���ı������ı�����ÿ�λ������������Ӹ���ʼ�����ţ���
layout����
layoutһ���������⼸�����֣�
1. parent��Ⱦ����������Ŀ���
2. parent��Ⱦ�����ȡchilidren������
1. ����child��Ⱦ������������x��y��
2. ����Ҫʱ�����ǵ�ǰΪdirty���Ǵ���ȫ��layout��������ԭ����child��Ⱦ�����layout���⽫����child�ĸ߶�
3. parent��Ⱦ����ʹ��child��Ⱦ������ۻ��߶ȣ��Լ�margin��padding�ĸ߶��������Լ��ĸ߶ȣ��⽫��parent��Ⱦ�����parentʹ��
4. ��dirty��ʶ����Ϊfalse
Firefoxʹ��һ����state������nsHTMLReflowState����Ϊ����ȥ���֣�firefox��Ϊreflow����state����parent�Ŀ��ȼ��������ݡ�
Firefox���ֵ������һ����metrics������nsHTMLReflowMetrics������������Ⱦ���������ĸ߶ȡ�
���ȼ���
��Ⱦ����Ŀ���ʹ�������Ŀ��ȡ���Ⱦ������ʽ�еĿ��ȼ�margin��border���м��㡣���磬�������div�Ŀ��ȣ�
<div style="width:30%"/>
webkit�п��ȵļ�������ǣ�RenderBox���calcWidth��������
�� �����Ŀ����������Ŀ��ÿ��Ⱥ�0�е����ֵ������Ŀ��ÿ���Ϊ��contentWidth=clientWidth()-paddingLeft()-paddingRight()��clientWidth��clientHeight����һ�������ڲ��IJ�����border�ͻ������Ĵ�С
�� Ԫ�صĿ���ָ��ʽ����width��ֵ��������ͨ�����������İٷֱȵõ�һ������ֵ
�� ����ˮƽ�����ϵ�border��padding
����������ѿ��ȵļ�����̣����ڼ�����ȵ����ֵ����Сֵ�������ѿ��ȴ�����������ʹ�������ȣ����С����С������ʹ����С���ȡ�������ֵ������Ҫlayout������δ�ı�ʱʹ�á�
Line breaking
��һ����Ⱦ�����ڲ��ֹ�������Ҫ����ʱ������ͣ����������parent����Ҫ���У�parent�������������Ⱦ���������ǵ�layout��
���� Painting
���ƽΣ�������Ⱦ����������Ⱦ�����paint���������ǵ�������ʾ����Ļ�ϣ�����ʹ��UI�������������UI���½��и���Ľ��ܡ�
ȫ�ֺ�����
�Ͳ���һ��������Ҳ������ȫ�ֵģ����������������������ġ��������Ļ��ƹ����У�һЩ��Ⱦ�����Բ�Ӱ���������ķ�ʽ�ı䣬�ı����Ⱦ����ʹ������Ļ�ϵľ�������ʧЧ���⽫���²���ϵͳ���俴��dirty��������һ��paint�¼�������ϵͳ������Ĵ���������̣������������ϲ�Ϊһ����Chrome�У�������̸�����Щ����Ϊ��Ⱦ�����ڲ�ͬ�Ľ����У����������������С�Chrome��һ���̶���ģ�����ϵͳ����Ϊ������Ϊ�����¼����ɷ���Ϣ����Ⱦ���������в��ҵ���ص���Ⱦ�����ػ����������������������children����
����˳��
css2�����˻��ƹ��̵�˳��http://www.w3.org/TR/CSS21/zindex.html���������Ԫ��ѹ���ջ��˳�����˳��Ӱ���Ż��ƣ���ջ�Ӻ���ǰ���л��ơ�
һ������Ⱦ����Ķ�ջ˳���ǣ�
1. ����ɫ
2. ����ͼ
3. border
4. children
5. outline
Firefox��ʾ�б�
Firefox��ȡ��Ⱦ����Ϊ���Ƶľ��δ���һ����ʾ�б������б�����ȷ�Ļ���˳��������������ص���Ⱦ����
�������ķ���������ʹ�ػ�ʱֻ�����һ������������Ҫ��β��ҡ����������еı��������е�ͼƬ�����е�border�ȵȡ�
Firefox�Ż���������̣��������ӻᱻ���ص�Ԫ�أ�����Ԫ����ȫ����������Ԫ�����档
Webkit���δ洢
�ػ�ǰ��webkit���ɵľ��α���Ϊλͼ��Ȼ��ֻ�����¾ɾ��εIJ��
��̬�仯
�����������������С�Ķ�����Ӧһ���仯������һ��Ԫ����ɫ�ı仯��ֻ���¸�Ԫ�ص��ػ棬Ԫ��λ�õı仯������Ԫ�صIJ��ֺ��ػ棬����һ��Dom�ڵ㣬Ҳ��������Ԫ�صIJ��ֺ��ػ档һЩ��Ҫ�ı仯����������htmlԪ�ص��ֺţ����ᵼ�»���ʧЧ���Ӷ����������IJ��ֺ��ػ档
��Ⱦ������߳�
��Ⱦ�����ǵ��̵߳ģ���������������⣬�������е����鶼�ڵ�һ���߳��д�������Firefox��Safari�У���������������̣߳�Chrome������tab�����̡߳�
��������ɼ��������߳�ִ�У��������ӵĸ��������ģ�ͨ����2��6������
�¼�ѭ��
��������߳���һ���¼�ѭ�����������Ϊ����ѭ���Ա���ִ�й��̵Ŀ��ã��ȴ��¼�������layout��paint�¼�����ִ�����ǡ�������Firefox����Ҫ�¼�ѭ�����롣
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 ����ģ�� CSS2 visual module
���� The Canvas
����CSS2�淶������canvas����������ʽ���Ľṹ����Ⱦ�Ŀռ䡪��������������ݵĵط���������ÿ��ά�ȿռ䶼������ģ������������viewport�Ĵ�Сѡ����һ����ʼ���ȡ�
����http://www.w3.org/TR/CSS2/zindex.html�Ķ��壬��������ǰ����������������������ģ������������ָ��һ����ɫ��
CSS��ģ��
CSS��ģ�������˾��κУ���Щ���κ���Ϊ�ĵ����е�Ԫ�����ɵģ������ݿ��ӵĸ�ʽ��ģ�ͽ��в��֡�ÿ��box��������������ͼƬ���ı��ȣ�����ѡ������padding��border��margin����
ÿ���ڵ�����0��n��������box��
���е�Ԫ�ض���һ��display���ԣ�����������������box�����ͣ����磺
block�����ɿ�״box
inline������һ����������box
none��������box
Ĭ�ϵ���inline�����������ʽ������������Ĭ��ֵ�����磬divԪ��Ĭ��Ϊblock�����Է���http://www.w3.org/TR/CSS2/sample.html�鿴�����Ĭ����ʽ��ʾ����
����� Position scheme
���������ֲ��ԣ�
1. normal��������������ĵ�����λ�ö�λ������ζ��������Ⱦ������Dom����λ��һ�£����������ĺ�ģ�ͺʹ�С���в���
2. float������������ͨ��һ�����֣�Ȼ���ܵ�������������ƶ�
3. absolute����������Ⱦ���е�λ�ú�Dom����λ����
static��relative��normal��absolute��fixed����absolute��
��static��λ�У�������λ�ö�ʹ��Ĭ�ϵ�λ�á����������У�����ָ��λ�á���top��bottom��left��right��
Box���ֵķ�ʽ���⼸�������box�����͡�box�Ĵ�С����λ���Լ���չ��Ϣ������ͼƬ��С����Ļ�ߴ磩��
Box����
Block box������һ���飬������������������Լ��ľ���
Inline box����û���Լ��Ŀ�״����������һ����״������
blockһ������һ����ֱ��ʽ����inline����ˮƽ�����ϸ�ʽ����
Inline��ģ�ͷ��������ڻ���line box�У�ÿ�����ٺ���ߵ�boxһ���ߣ���box��baseline����ʱ������һ��Ԫ�صĵײ�����һ��box�ϳ��ײ������ij����룬�и߿��Ա���ߵ�box�ߡ����������Ȳ���ʱ������Ԫ�ؽ����ŵ������У�����һ��pԪ���о���������
��λ Position
Relative
��Զ�λ�����Ȱ���һ��Ķ�λ��Ȼ����Ҫ��IJ�ֵ�ƶ���
Floats
һ��������box�ƶ���һ�е�����������ұߣ������boxΧ��������Χ���������html��
<p>
<img style="float:right" src="images/image.gif" width="100" height="100">Lorem ipsum dolor sit amet, consectetuer...
</p>
����ʾΪ��
Absolute��Fixed
��������µIJ�����ȫ������ͨ���ĵ�����Ԫ�ز������ĵ�����һ���֣���Сȡ����������Fixedʱ������Ϊviewport����������
ͼ17��fixed
ע�⣭fixed��ʹ���ĵ�������ʱҲ�����ƶ���
Layered representation
�����CSS�����е�z-indexָ������ʾ��ģ�͵ĵ�������С������z���ϵ�λ�á�Box�ַ�����ջ�У���Ϊ��ջ�����ģ���ÿ����ջ�п����Ԫ�ؽ���������ƣ�ջ����ǰ��Ԫ�����û����������������ʱ�������ؿ����Ԫ�ء���ջ����z-index��������ӵ��z-index���Ե�box�γ���һ���ֲ���ջ��viewport���ⲿ��ջ�����磺
<STYLE type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</STYLE>
<P>
<DIV
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</DIV>
<DIV
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</DIV>
</p>
����ǣ�
��Ȼ��ɫdiv���ں�ɫdiv���棬��������������Ҳ�Ѿ��������ں��棬��z-index�и������ȼ��������ڸ�box�Ķ�ջ�и���ǰ��
How Rendering Work (in WebKit and Blink)
Posted by Roger
on 2014 �� 4 �� 16 ��
�Դӿ�ʼ����������ں˿��������������Ѿ�д�����ٸ���Ⱦ��ص����¡�����һֱ��дһƪ�� How Browsers Work ���ƣ��ܹ�ϵͳ�������ز������������Ⱦ��������ι����ģ�������ζ���ҳ��Ⱦ���ܽ����Ż������£�ȴһֱ��Ϊη������Ҫ���ѵ�ʱ��;������ٳ������ʡ�������Σ��������ڹ���������д�ˣ�ϣ���Լ��ܹ���ɰɡ�
���°�������Ҫ�������� ��
- ��Ⱦ���� �� DOM �� RenderObject & RenderLayer
- WebView���������ϣ����߳���Ⱦ
- Ӳ������
- �ֿ���Ⱦ
- ͼ���ϼ���
- ��ҳ��Ϸ��Ⱦ �� Canvas �� WebGL
������ȷ���й�����Ⱦ�Ķ��壬������ں�����ͨ���ֱ���Ϊ��ҳ��Ⱦ���棬�����������Ⱦʵ������һ����ָ���������Ⱦ����������������ں����е���Ҫ���� �� ���أ��������Ű棬���Ƶȵȡ����ڱ����������Ⱦ��ָ���Ǹ�������صIJ��֣�Ҳ�������������ν��Ű��Ľ��������ʾ����Ļ�ϵ���һ���̡��������ϣ���ȶ�������ں����棬�ر��� WebKit ��һ����ŵ��˽⣬How Browsers Work��How WebKit Work��WebKit for Developers �����ṩ����������ָ����
��Σ�������Ҫ���� WebKit �����ʵ�֣�������Ϊ Blink ʵ���ϴ� WebKit ��֧������ʱ�䲢��������������Ⱦ����ܹ��ϻ��ǻ���һ�µģ��������в�����ȷ���������ߡ�
���ϣ����ƪ�����ܹ�������������ں˿������ر�����Ⱦ���濪���Ŀ�����һ���ܹ��������ŵ�ָ��������ǰ�˿������Ż���ҳ��Ⱦ�����ṩ�㹻��֪ʶ�Ͱ�����
��Ϊ���º������п��ܻ�������Ͳ��䣬���Ҫ�鿴���µ����ݣ�����ʸ��˲��͵�ԭ�ģ�http://blog.csdn.net/rogeryi/article/details/23686609�������ʲô��©�ʹ���Ҳ��ӭ��������ָ����roger2yi@gmail.com����
��Ⱦ���� �� DOM �� RenderObject & RenderLayer
ͼƬ���� GPU Accelerated Compositing in Chrome
�������ͨ��������߱����ļ�ϵͳ����һ�� HTML �ļ������������н�����Ϻ��ں˾ͻ�����������Ҫ�����ݽṹ �� DOM ����DOM ����ÿһ���ڵ㶼��Ӧ����ҳ�����ÿһ��Ԫ�أ�������ҳҲ����ͨ�� JavaScript ������� DOM ������̬�ı����Ľṹ������ DOM ������������ֱ�������Ű����Ⱦ���ں˻�����������һ���� �� Render ����Render ���ϵ�ÿһ���ڵ� �� RenderObject���� DOM ���ϵĽڵ㼸����һһ��Ӧ�ģ���һ���ɼ��� DOM �ڵ㱻���ӵ� DOM ����ʱ���ں˾ͻ�Ϊ�����ɶ�Ӧ�� RenderOject ���ӵ� Render ���ϡ�
ͼƬ���� How WebKit Work
Render ����������Ű��������Ҫ��ҵ�����Ű�������� DOM ���� CSS ��ʽ������ʽ���壬����Ԥ�����Ű����ȷ���� Render �����Ľṹ����������ÿһ�� RenderObject �Ĵ�С��λ�ã���һ�þ����Ű�� Render ���������������Ⱦ�������Ҫ���룬���߿�����Ϊ��Render �����ν�������Ű��������Ⱦ����֮��������������Ű�������������Ⱦ��������롣
ͼƬ���� How WebKit Work
�����������Ⱦ���沢����ֱ��ʹ�� Render �����л��ƣ�Ϊ�˷��㴦�� Positioning����λ����Clipping���ü�����Overflow-scroll��ҳ�ȹ�������CSS Transform/Opacity/Animation/Filter��Mask or Reflection��Z-indexing��Z���ȣ��������Ҫ��������һ���� �C Layer ������Ⱦ�����ΪһЩ�ض��� RenderObject ���ɶ�Ӧ�� RenderLayer������Щ�ض��� RenderObject ����Ӧ�� RenderLayer ����ֱ���Ĺ�ϵ����Ӧ�ģ����ǵ��ӽڵ����û�ж�Ӧ�� RenderLayer���ʹ����ڸ��ڵ�� RenderLayer�����գ�ÿһ�� RenderObject ����ֱ�ӻ���ӵش�����һ�� RenderLayer��
RenderObject ���� RenderLayer ������������ GPU Accelerated Compositing in Chrome �C It��s the root object for the page �C It has explicit CSS position properties (relative, absolute or a transform) �C It is transparent �C Has overflow, an alpha mask or reflection
�C Has a CSS filter �C Corresponds to < canvas> element that has a 3D (WebGL) context or an accelerated 2D context �C Corresponds to a < video> element
�������Ⱦ������� Layer ��������ÿһ�� RenderLayer���ٱ������������ RenderLayer �� RenderObject����ÿһ�� RenderObject ���Ƴ��������߿�����Ϊ��Layer ����������ҳ���ƵIJ��˳�������� RenderLayer �� RenderObject ��������� Layer �����ݣ����е� RenderLayer �� RenderObject һ��;�������ҳ����Ļ�����ճ��ֳ��������ݡ�
������Ⱦģʽ�£���������� RenderLayer �� RenderObject ��˳������ GPU Accelerated Compositing in Chrome
In the software path, the page is rendered by sequentially painting all the RenderLayers, from back to front. The RenderLayer hierarchy is traversed recursively starting from the root and the bulk of the work is done in RenderLayer::paintLayer() which performs the following basic steps (the list of steps is simplified here for clarity):
- Determines whether the layer intersects the damage rect for an early out.
- Recursively paints the layers below this one by calling paintLayer() for the layers in the negZOrderList.
- Asks RenderObjects associated with this RenderLayer to paint themselves.
- This is done by recursing down the RenderObject tree starting with the RenderObject which created the layer. Traversal stops whenever a RenderObject associated with a different RenderLayer is found.
- Recursively paints the layers above this one by calling paintLayer() for the layers in the posZOrderList.
In this mode RenderObjects paint themselves into the destination bitmap by issuing draw calls into a single shared GraphicsContext (implemented in Chrome via Skia).
WebView���������ϣ����߳���Ⱦ
ͼƬ���� [UC ����� 9.7 Android��]���м���һ�� WebView���Ϸ��DZ�����������
���������������ֱ�Ӹı���Ļ���������������Ҫͨ��ϵͳ������ GUI Toolkit�����ԣ�һ����˵������Ὣһ��Ҫ��ʾ����ҳ��װ��һ�� UI �����ͨ������ WebView��Ȼ��ͨ���� WebView ������Ӧ�õ� UI �����ϣ��Ӷ�����ҳ��ʾ����Ļ�ϡ�
һЩ GUI Toolkit������ Android��Ĭ�ϵ������ UI ���û���Լ�������λͼ���棬���� UI ��������� UI �����ֱ�ӻ����ڵ�ǰ�Ĵ��ڻ����ϣ����� WebView ÿ�λ��ƣ����൱�ڽ����ڿɼ������ڵ� RenderLayer/RenderObject ������Ƶ����ڻ����ϡ���������Ⱦ��ʽ��һ�������ص����⣬�û��϶���ҳ���ߴ���һ�����Թ���ʱ����ҳ��������Ⱦ���ܻ�ʮ����⡣������Ϊ��ʹ��ҳֻ�ƶ�һ�����أ����� WebView ����Ҫ���»��ƣ���Ҫ����һ�� WebView ��С������� RenderLayer/RenderObject����ʱͨ�����Ƚϳ�������һЩ���ӵ��������ҳ�����ƶ��豸�ϻ���һ�εĺ�ʱ�п�����Ҫ�ϰٺ��룬��Ҫ�ﵽ60֡/ÿ��������ȣ�ÿһ֡���Ƶ�ʱ��Ͳ��ܳ���16.7���룬������������Ⱦģʽ�£�Ҫ�����������ҳ����Ч������Ȼ�Dz����ܵģ�����ҳ�����������̶ȣ������û����������Ⱦ���ܵ���ֱ�ۺ�����Ҫ�ĸ��ܡ�
Ҫ������ҳ���������ܣ�һ�������������� WebView ��������һ������Ļ��棬�� WebView �Ļ��ƾͷֳ������� 1) ������Ҫ�����ڲ����棬����ҳ���ݻ��Ƶ��ڲ��������� 2) ���ڲ����濽�������ڻ����ϡ���һ������ͨ����Ϊ���ƣ�Paint�����߹�դ����Rasterization��������һЩ��ͼָ��ת����������������ɫֵ�����ڶ�������һ���Ϊ��ϣ�Composite����������Ŀ�����ͬʱ�����ܰ���λ�ƣ�Translation�������ţ�Scale������ת��Rotation����Alpha ��ϵȲ�����զһ������Ⱦ��ñ�ԭ�������ӣ�������һ����������ʵ���ϣ���ϵĺ�ʱͨ��ԶԶС����ҳ���ݻ��Ƶĺ�ʱ������ʹ���ƶ��豸��һ��Ҳ���ڼ����������ڣ�����ʱ���ڵ�һ�����棬����ֻ��Ҫ����һ���С�����������Ҫ����һ������ WebView ��С��������������Ч�ؼ����˻�����һ���Ŀ���������ҳ����Ϊ���ӣ�ÿ�ι���ʵ����ֻ��Ҫ�����½��� WebView �ɼ�����IJ��֣�������Ϲ�����10�����أ�������Ҫ���Ƶ������С����10 x Width of WebView������ԭ����Ҫ�������� WebView ��С�������ҳ���ݵ�ȻҪ��Ķ��ˡ�
��һ����˵�������������ʹ�ö��̵߳���Ⱦ�ܹ�������ҳ���ݻ��Ƶ�����IJ����ŵ�����һ���������̣߳������̣߳�����ԭ���̶߳� WebView �Ļ��ƾ�ֻʣ�»���Ŀ���������̣߳��������̸߳�����߳�֮�����ʹ��ͬ��������ͬ������ȫ�첽����ҵģʽ���������������������Ч��֮�������Ҫ����ѡ����˵�첽ģʽ�£����������Ҫ�� WebView ���濽�������ڻ��棬������Ҫ���µIJ��ֻ�û�����ü�����ʱ������������ڻ�δ��ʱ���µIJ��ֻ���һ������ɫ���߿հף�������Ȼ��ȾЧ�������½������DZ�֤��ÿһ֡���ڸ��µļ����������ķ�Χ�ڡ����������������Ϊ WebView ����һ������Ļ��棬���� WebView�����Ĵ�С�������ǿ��Ի���������ҳ���ݣ�����Ԥ�Ȼ��Ʋ��ɼ������������Ϳ�����Ч�����첽ģʽ�³��ֿհ�״���������ܺ�Ч��֮��ȡ�ø��õ�ƽ�⡣
Ӳ������
��������Ⱦģʽ�������ǻ��ƻ��ǻ�ϣ������� CPU ��ɵģ���û��ʹ�õ� GPU����������Ƚϸ��ӣ�����ʹ�� GPU ����ɣ����Ҷ��ڸ��ָ��ӵ�ͼ��/�ı��Ļ�����˵��ʹ�� GPU Ч����ʱ�������ͣ�����ϵͳ��Դ�Ŀ���Ҳ�ϴ����ǻ�ϾͲ�һ���ˣ�GPU ���ó��ľ��Dz��д���������صļ��㣬���� GPU ����� CPU��ִ�л�ϵ��ٶ�Ҫ��Ķ࣬�ر��Ǵ������ţ���ת��Alpha ��ϵ�ʱ���һ�������˵Ҳ�Ƚϼ��ij�ʹ�� GPU ����ɲ������ѡ�
�����ڶ��߳���Ⱦģʽ�£���Ϊ���ƺͻ�Ϸֱ��ڲ�ͬ���̣߳�����ʹ�� CPU�����ʹ�� GPU����������ͨ�� CPU/GPU ֮��IJ���������Ч������������������Ⱦ���ܡ����ο������ڵĸ������ɻ���߳�������ģ���ϵ�Ч��Խ�ߣ����ڸ��µļ����Խ�̣��û����ܵ� UI ����仯�������Ⱦ�Խ�ߣ�ֻҪ���ڸ��µļ���ܹ�ʼ�ձ�����16.7�������ڣ�UI ������ܹ�һֱ����60֡/ÿ��ļ��������ȣ���Ϊһ����˵����ʾ��Ļ��ˢ��Ƶ����60hz������60֡/���Ѿ��Ǽ���֡�ʣ����������ֵ���岻���� OS ��ͼ����ϵͳ�����ͻ�ǿ������ UI ����ĸ��¸���Ļ��ˢ�±���ͬ������
���Զ����ִ��������˵����νӲ�����٣�����ʹ�� GPU �����л�ϣ�������Ȼʹ�� CPU ����ɡ�
�ֿ���Ⱦ
ͼƬ���� [UC ����� 9.7 Android��]��ʹ��256��256��С�ķֿ�
��ҳ�Ļ���ͨ��������һ��飬���ǻ��ֳ�һ��һ���С�飬ͨ��Ϊ256��256����512��512��С��������Ⱦ��ʽ��Ϊ�ֿ���Ⱦ��Tile Rendering����ʹ�÷ֿ���Ⱦ����Ҫԭ������Ϊ �C
- ��ν GPU ��ϣ�ͨ����ʹ�� Open GL/ES ��ͼ��ʵ�ֵģ�����ʱ�Ļ�����ʵ����������GL Texture�������ܶ� GPU �������Ĵ�С�����ƣ����糤/��������2���ݴη�������ܳ���2048����4096�ȣ�������֧�������С�Ļ��棻
- ʹ��С�黺�棬���������ʹ��һ��ͳһ�Ļ��������������Ļ��棬��������һ������ɰ���ǧ������鹩���е� WebView ���á����д���ҳ����Ҫ����ʱ�������Ի����Ϊ��λ������룬������ҳ�رջ��߲��ɼ�ʱ����Щ����Ҫ�Ļ����Ϳ��Ա����չ�������ҳʹ�ã�
��֮�̶���С��С�黺�棬ͨ��һ��ͳһ������������ķ�ʽ������ÿ�� WebView �Լ�����һ��黺���кܶ����ơ��ر��Ǹ��ʺ϶��߳� CPU/GPU ��������Ⱦģ�ͣ����Ի�����֧��Ӳ�����ٵ����������ʹ�÷ֿ���Ⱦ�ķ�ʽ��
ͼ���ϼ���
ͼƬ���� [UC ����� 9.7 Android��]���ɼ���������4�� Layer ���Լ��Ļ��� �C ��ײ�� Base Layer���Ϸ��� Fixed ���������м���ȵ������������·��� Fixed ��ת��ť
ͼ���ϼ��٣�Accelerated Compositing������Ⱦ�ܹ��� Apple ���� WebKit �ģ����� Safari ������ʵ�֣��� Chrome/Android/Qt/GTK+ �ȶ�½��������Լ���ʵ�֡������Ϥ iOS ���� Mac OS GUI ��̵Ķ��߶���Ӧ�ò���е�İ�������� iOS CoreAnimation �� Layer Rendering ��Ⱦ�ܹ��������ƣ���Ҫ����Ϊ�˽���� Layer ������Ƶ�������仯�����ߵ� Layer ����һ��2D/3D�任��2D/3D Transform �����߽������붯��������λ�ƣ����ţ���ת�����ȵ����Բ��Ϸ����仯ʱ����ԭ�е���Ⱦ�ܹ��£���Ⱦ���ܵ��µ����⡣
�ǻ�ϼ��ٵ���Ⱦ�ܹ������е� RenderLayer ��û���Լ������Ļ��棬���Ƕ������Ƶ�ͬһ���������棨�������ǵ��Ⱥ�˳������ֻҪ��� Layer �����ݷ����仯����������һЩ CSS ��ʽ���Ա��� Transform/Opacity �����仯���仯����Ļ������Ҫ�������ɣ���ʱ������Ҫ���Ʊ仯�� Layer�����仯����Damage Region���ཻ������ Layer ����Ҫ�����ƣ���ǰ���Ѿ�˵������ҳ�Ļ�����ʮ�ֺ�ʱ�ġ���� Layer ż�������仯���ǻ���Ҫ�����������һ�� JavaScript ���� CSS �����ڲ��ϵ���ʹ Layer �����仯���������Ҫ�ﵽ60֡/ÿ�������Ч���ͻ����������ˡ�
���ڻ�ϼ��ٵ���Ⱦ�ܹ��£�һЩ RenderLayer ��ӵ���Լ������Ļ��棬���DZ���Ϊ���ͼ�㣨Compositing Layer����WebKit ��Ϊ��Щ RenderLayer ������Ӧ�� GraphicsLayer����ͬ���������Ҫ�ṩ�Լ��� GrphicsLayer ʵ�����ڹ�������ķ��䣬�ͷţ����µȵȡ�ӵ�� GrphicsLayer �� RenderLayer �ᱻ���Ƶ��Լ��Ļ������棬��û�� GrphicsLayer �� RenderLayer ���ǻ��������� GrphicsLayer �ĸ�/���� RenderLayer��ֱ�� Root RenderLayer Ϊֹ��Ȼ��������� GrphicsLayer �ĸ�/���� RenderLayer �Ļ����ϣ��� Root RenderLayer ���ǻᴴ��һ�� GrphicsLayer ��ӵ���Լ������Ļ��档���գ�GraphicsLayer �ֹ�����һ���� RenderLayer ���е������� RenderLayer �� GraphicsLayer �Ĺ�ϵ��Щ������ RenderObject �� RenderLayer ֮��Ĺ�ϵ��
��ϼ�����Ⱦ�ܹ��µ���ҳ��ϣ�Ҳ��ñ���ǰ���ӣ������ǼĽ�һ�����濽�������ڻ����ϣ�������Ҫ���Դ�Բ�ͬ Layer �Ķ������Ŀ������ټ��Ͽ��ܵ�2D/3D�任���ټ��ϻ���֮���Alpha��ϵȲ�������Ȼ������֧��Ӳ�����٣�ʹ�� GPU ����ɻ�ϵ��������˵���ٶȻ��Ǻܿ�ġ�
RenderLayer ���� GraphicsLayer ������������ GPU Accelerated Compositing in Chrome
- Layer has 3D or perspective transform CSS properties
- Layer is used by < video> element using accelerated video decoding
- Layer is used by a < canvas> element with a 3D context or accelerated 2D context
- Layer is used for a composited plugin
- Layer uses a CSS animation for its opacity or uses an animated webkit transform
- Layer uses accelerated CSS filters
- Layer with a composited descendant has information that needs to be in the composited layer tree, such as a clip or reflection
- Layer has a sibling with a lower z-index which has a compositing layer (in other words the layer is rendered on top of a composited layer)
��ϼ��ٵ���Ⱦ�ܹ��£�Layer �����ݱ仯��ֻ��Ҫ���������� GraphicsLayer �Ļ��漴�ɣ�������ĸ��£�Ҳֻ��Ҫ����ֱ�ӻ����������� GraphicsLayer �� RenderLayer ���������е� RenderLayer���ر���һЩ�ض��� CSS ��ʽ���Եı仯��ʵ���ϲ����������ݵı仯��ֻ��Ҫ�ı�һЩ GraphicsLayer �Ļ�ϲ�����Ȼ�����»�ϼ��ɣ��������Ի��ƶ����Ǻܿ�ģ���Щ�ض��� CSS ��ʽ��������һ���֮Ϊ�DZ����ٵģ���ͬ�������֧�ֵ�״����̫һ������������ CSS Transform & Opacity ������֧�ֻ�ϼ��ٵ�������϶��DZ����ٵġ������ٵ�CSS ��ʽ���ԵĶ������ͱȽ����״ﵽ60֡/ÿ�������Ч���ˡ�

ͼƬ���� Understanding Hardware Acceleration on Mobile Browsers��չ���˾���� CSS ���� Demo �C Falling Leaves ��ͼ���ϵ�ʾ��ͼ������ʹ�õ� Transform �� Opacity ����������֧�ֻ�ϼ��ٵ�������϶��DZ����ٵ�
����������ӵ�ж�������� RenderLayer Խ��Խ�ã�̫��ӵ�ж�������� Layer �����һЩ���صĸ����� �C ����������������ڴ�Ŀ�����������ƶ��豸�ϵ�Ӱ��������������������һЩ�ڴ���ٵ��ƶ��豸�����ܺõ�֧��ͼ���ϼ��٣���Σ����Ӵ��˻�ϵ�ʱ�俪�������»�����ܵ��½�����������ܸ���ҳ����/���Ų�������������ϢϢ��أ����յ�����ҳ����/���ŵ��������½������û����ò�������������
�� Chrome://flags ���濪�����ϳ���Ⱦ��߿Ϳ��Կ�����Щ Layer ��һ�� Compositing Layer��Ҳ����ӵ���Լ��Ķ������档ǰ�˿����߿����ô˰����Լ����� Compositing Layer �Ĵ������ܵĵ�˵�� Compositing Layer ���������������ܣ����ǻή�ͻ�����ܣ���ҳֻ�к�����ʹ�� Compositing Layer�������ڻ��ƺͻ��֮��ȡ��һ�����õ�ƽ�⣬ʵ��������Ⱦ���ܵ�������

ͼƬ���� Chrome��չ���˾���� CSS ���� Demo �C Falling Leaves �ĺϳ���Ⱦ��߿�
��ҳ��Ϸ��Ⱦ �� Canvas �� WebGL

ͼƬ���� [UC ����� 9.7 Android��]������2D Canvas ����Ϸ�������������������ֻ��Ͽ��Դﵽ60֡/ÿ���������
��ǰ��ҳ��Ϸһ�㶼��ʹ�� Flash ��ʵ�֣��������� Flash ���ƶ��豸����̭��Խ��Խ�����ҳ��Ϸ����� Canvas �� WebGL ����������������� Canvas �Ļ����������̿��Բο�����ǰ������ Introduce My Work����Ȼһ����ҳԪ�ض���ʹ�� CPU �����ƣ����Ƕ��ڼ��ٵ�2D Canvas �� WebGL ��˵�����ǵĻ�����ֱ��ʹ�� GPU �ģ���������һ���ӵ��һ�� GL FBO��FrameBufferObject����Ϊ�Լ��Ļ��棬Canvas/WebGL �����ݱ����Ƶ���� FBO ���棬����� FBO ���������������ڻ�ϲ������汻���������ڻ����ϡ�����˵�����ڼ��ٵ�2D Canvas �� WebGL�����ǵĻ��ƺͻ�϶���ʹ�� GPU��

ͼƬ���� [UC ����� 9.7 Android��]��һ����ʾ WebGL ����ҳ Demo
��������Ż� Canvas ��Ϸ�����ܣ���ο�����ǰ������ �C High Performance Canvas Game for Android��������Android Canvas��Ϸ��������
[��]Google Chrome�еĸ���������
Posted by Horky
on 2013 �� 11 �� 6 ��
Google Chrome����ʷ��ָ��ԭ��
����ע���ⲿ�ֲ�����ϸ���룬ֻ�г�������˼��
����Chrome����ǰ���ĺ���ԭ�����:
- Speed: ������(fastest)���������
- Security:Ϊ�û��ṩ��Ϊ��ȫ��(most secure)������������
- Stability: �ṩһ����׳���ȶ���(resilient and stable)��WebӦ��ƽ̨��
- Simplicity: �Լ������û�����(simple user experience)��װ�����ļ���(sophisticated technology)��
���Ĺؽ�ע�ڵ�һ�㣬�ٶȡ�
�������ܵķ�������
һ���ִ����������һ���Ͳ���ϵͳһ����ƽ̨����Chrome֮ǰ����������ǵ����̵�Ӧ�ã�����ҳ�湲����ͬ�ĵ�ַ�ռ����Դ���������̼ܹ�����Chrome��Ϊ�����ĸĽ�����ע:ʡ��һЩ����̸�۵�ϸ�ڡ���

һ�������ڣ�WebӦ����Ҫ��Ҫִ����������:��ȡ��Դ��ҳ�� �Ű漰��Ⱦ��������JavaScript����Ⱦ�ͽű������������н����Ե��̵߳ķ�ʽ���еģ���ԭ����Ϊ�˱���DOM��һ���ԣ���JavaScript�� ��Ҳ��һ�����̵߳����ԡ������Ż���Ⱦ�ͽű��������۶���ҳ�濪����������������߶��Ǽ�Ϊ��Ҫ�ġ�
Chrome����Ⱦ������WebKit, JavaScript Engine��ʹ���������۵�V8 (��V8�� JavaScript runtime)�����ǣ�������粻���������Ż�V8��JavaScriptִ�У������Ż�WebKit�Ľ�������Ⱦ��������ʵ�����ޡ��ɸ���Ϊ����֮��������û���͵õ���!
������û����飬������Ϊ���Եľ�������Ż�������Դ�ļ���˳ �����ȼ���ÿһ����Դ���ӳ�ʱ��(latency)��Ҳ������������Chrome����ģ��ÿ�춼�ڽ���������ÿ����Դ�ļ��سɱ�����DNS lookupsѧϰ����סҳ�����˽ṹ(topology of the web), Ԥ�����ӿ��ܵ�Ŀ����ַ���ȵȣ����кܶࡣ��������������һ������Դ���صĻ��ƣ������ڲ�ȴ��һ�����ʵ����硣
����WebӦ��
��ʼ����ǰ�����������˽�һ��������ҳ����WebӦ���������ϵ�����
HTTP Archive ��Ŀһֱ������ҳ����������ҳ�������⣬�������������ҳ��ʹ�õ���Դ���������ͣ�ͷ��Ϣ�Լ���ͬĿ���ַ��Ԫ����(metadata)��������2013��1�µ�ͳ�����ϣ���300��000Ŀ��ҳ��ó���ƽ������:

- 1280 KB
- ����88����Դ(Images,JavaScript,CSS ��)
- ����15�����ϵIJ�ͬ����(distinct hosts)
��Щ�����ڹ�ȥ������һֱ��������(steadily increasing)��û��ͣ�µļ�����˵�����������ϵؽ���һ�������Ӵ�ġ�Ұ�IJ���������Ӧ�á���Ҫע�⣬ƽ������ÿ����Դ����12KB, ����������������紫�䶼�Ƕ̴�(short and bursty)�ġ����TCP��Դ����ݡ���ʽ(streaming)���صķ���һ�£�����Ϊ��ˣ���������һЩ����֢���������һ����������˿���룬һ����������
һ��Resource Request��һ��
W3C��Navigation Timing specification������һ��API�����Թ۲쵽�������ÿһ������(request)��ʱ����������ݡ������˽�һЩϸ��:

����һ����ҳ��Դ��ַ��������ͻ��鱾�ػ����Ӧ�û��档���֮ǰ��ȡ����������Ӧ�Ļ�����Ϣ(appropriate cache headers)(��Expires, Cache-Control, etc.), �ͻ��û����������������Ͼ������������û������(the fastest request is a request not made)����������������֤��Դ������Ѿ�ʧЧ(expired),���߸�����û������һ���ķ�����������������ط����ˡ�
������һ������������Դ·����Chrome���Ǽ�������ѽ���������(existing open connections)�Ƿ���Ը���, ��socketsָ������(scheme��host��port)��������ӳ�(pool)�������������һ������������ָ����proxy auto-config(PAC)�ű���Chrome�ͻ�����proxy�����ӡ�PAC�ű�����URL�ṩ��ͬ�Ĵ���������Ϊ��ָ�����ض� �Ĺ�����ÿһ�������䶼�������Լ���socket pool�������������������ڣ��������ͻ��DNS��ѯ(DNS lookup)��ʼ�ˣ��Ա�������IP��ַ��
���˵Ļ�������������Ѿ�����������������ȷ���һ�� DNS Query��������������ʱ���ISP,ҳ���֪���ȣ����������м仺��(intermediate caches)�Ŀ����ԣ��Լ�authoritative servers����Ӧʱ����Щ�����йء�Ҳ����˵��������ܶ࣬����һ�㻹�����ڵ����ٺ�����ô���š�

�õ���������IP��,Chrome�ͻ���Ŀ���ַ���һ����TCP���ӣ����Ǿ�Ҫִ��һ��3������(��three-way handshake��): SYN > SYN-ACK > ACK���������ÿ���µ�TCP���Ӷ�������ɣ�û�нݾ�������Զ����·��·����ѡ��������̿���Ҫ��ʱ���ٺ��룬�������롣�������ڣ�������һ����Ч���ֽڶ���û�յ���
��TCP��������ˣ�����������ӵ���һ��HTTPS��ַ������һ��SSL���ֹ��̣�ͬʱ��Ҫ����������ֵ��ӳٵȴ������SSL�Ự�������ˣ���ֻ��һ�Ρ�
���Chrome����Ҫ����HTTP������ (������ͼʾ�е�requestStart)�� �������յ�����ͻᴫ����Ӧ����(response data)�ص��ͻ��ˡ�����������ٵ������ӳٺͷ���Ĵ���ʱ�䡣Ȼ��һ�����������ˡ����ǣ������һ��HTTP�ض���(redirect)�Ļ������� ��Ҫ��ͷ��ʼ������̡�������ҳ������Щ������ض��������˼һ�£�
��ó����е��ӳ�ʱ������? ���Ǽ���һ�����͵Ŀ���������û�б��ػ��棬��ԽϿ��DNS lookup(50ms), TCP���֣�SSLЭ�̣��Լ�һ���Ͽ��������Ӧʱ��(100ms)��һ���ӳ�(80ms,���������ڵ�ƽ��ֵ):
- 50ms for DNS
- 80ms for TCP handshake (one RTT)
- 160ms for SSL handshake (two RTT��s)
- 40ms ����������������
- 100ms (����������)
- 40ms (�������ش���Ӧ����)
һ��������470����, ����80%��ʱ�䱻�����ӳ�ռȥ�ˡ������˰ɣ���������кܶ�����Ҫ������ʵ��,470�����Ѿ����ֹ���:
- ���������û�дﵽ����ʼTCP��ӵ������(congestion window)����4-15KB���ͻ��������������ӳ١�
- SSL�ӳ�Ҳ���ܱ�ø��㡣�����Ҫ��ȡһ��û�е���֤(certificate)����ִ��online certificate status check(OCSP), ������������Ҫһ���µ�TCP���ӣ�����������������ǧ������ӳ١�
�������㡱���족?
ǰ����Կ�����������Ӧʱ��������ӳ�ʱ���20%����������DNS�����ֵȲ���ռ���ˡ���ȥ�û������о�(user experience research)�����û����ӳ�ʱ��IJ�ͬ��Ӧ��
- 0 �C 100ms Ѹ��
- 100 �C 300ms ���
- 300 �C 1000ms ������������
- 1s+ �������¡���
- 10s+ ��һ�����������ɡ���
�ϱ�ͬ��������ҳ������ܱ���: ��Ⱦҳ�棬����Ҫ��250ms�ڸ�����Ӧ������ס�û�������Ǽ�����ٶȡ���Google, Amazon, Microsoft,�Լ�������ǧ��վ��������������ӳ�ֱ��Ӱ��ҳ����֣�������ҳ������������������Լ���ǿ���û�������(engagement) ��ҳ��ת����(conversion rates).
��������֪����������ӳ�ʱ����250ms����ǰ���ʾ���������ǣ�DNS Lookup, TCP��SSL���֣��Լ�request����ʱ�仨ȥ��370ms, ���㲻���Ƿ���������ʱ�䣬����Ҳ������50%��
���ھ���������û�����ҳ��������˵��DNS, TCP���Լ�SSL�ӳٶ��������������˻��뵽������Ҳ����ΪʲôChrome������ģ����ô�ĸ��ӡ�
�����Ѿ�ʶ��������⣬��������������һ��ʵ�ֵ�ϸ����
����Chrome������ģ��
����̼ܹ�
Chrome�Ķ���̼ܹ�Ϊ�������������������������Ҫ���壬��Ŀǰ֧�����ֲ�ͬ��ִ��ģʽ(four different execution models)��
Ĭ������£������Chrome�����ʹ��process-per-siteģʽ, ����ͬ����վҳ���������, ��ͬ��վ��ҳ����֯��һ�𡣾ٸ�������: ÿ��tab����һ�����̡����������ܵĽǶ���˵,��ûʲô�����ϵIJ�ͬ��ֻ��process-per- tablģʽ���������⡣

ÿһ��tab��һ����Ⱦ����(render process)�����а��������ڽ���ҳ��(interpreting)���Ű�(layout out)��WebKit���Ű�����(layout engine), ����ͼ�е�HTML Render������V8���������֮���DOM Bindings���������ⲿ�ֺܺ��棬���Կ�����(great introduction to the plumbing)��
ÿһ����������Ⱦ���̱�������һ��ɳ�价���У�ֻ����û��ĵ� �Ի����������ķ��ʨC�������硣��ʹ����Щ��Դ��ÿһ����Ⱦ���̱��������ں˽���(browser[kernel] process)��ͨ���Թ���ÿ����Ⱦ���̵İ�ȫ�Ժͷ��ʲ���(access policies)��
���̼�ͨѶ(IPC)�Ͷ������Դ����
��Ⱦ���̺��ں˽���֮���ͨѶ��ͨ��IPC��ɵġ���Linux�� Mac OS�ϣ�ʹ����һ���ṩ�첽�����ܵ�ͨѶ��ʽ��socketpair()��ÿһ����Ⱦ���̵���Ϣ�ᱻ���л��ص�һ��ר�õ�I/O�߳��У�Ȼ�������������� �˽��̡��ڽ��նˣ��ں˽����ṩһ�����˽ӿ�(filter interface)���ڽ�����Դ��ص�IPC����(ResourceMessageFilter), �ⲿ�־�������ģ�鸺��ġ�

����������һ���ô������е���Դ������I/O���̴�����������UI�����Ļ�����������¼������Ľ��������ں˽���(browser/kernel process)��I/O�߳̽�����Դ������Ϣ����ת����һ��ResourceDispatcherHost�ĵ���(singleton)�����д�����
��������ӿ��������������ÿ����Ⱦ���̶�����ķ��ʣ�Ҳ�ܴﵽ��Ч��һ�µ���Դ������
- Socket pool �� connection limits: �����������ÿһ��profile��256��sockets, ÿ��proxy��32��sockets, ��ÿһ��{scheme, host, port}���Դ�6����ע��ͬʱ���һ��{host,port}����ʼƴ�6��HTTP��6��HTTPS���ӡ�
- Socket reuse: ��Socket Pool���ṩ�־ÿ��õ�TCP connections���Թ����á���������Ϊ�µ����ӱ�����⽨��DNS��TCP��SSL(�����Ҫ�Ļ�)�����ѵ�ʱ�䡣
- Socket late-binding(�ӳٰ�): �����������ǵ�Scoket���÷�������ʱ����һ��TCP���ӹ������������������л���������������Ч�ּ�(prioritization)�����磬�� socket���ӹ����п��ܻᵽ�ﵽһ���������ȼ�������ͬʱҲ�����и��õ�������(throughput),���磬�����Ӵ����У�ȥ����һ���պ� ���õ�socket, �Ϳ���ʹ�õ�һ����ȫ���õ�TCP���ӡ���ʵ��ͳ��TCP pre-connect(Ԥ����)�������������Ż�����Ҳ�����Ч����
- Consistent session state(һ�µĻỰ״̬): ��Ȩ��cookies���������ݻ���������Ⱦ���̼乲����
- Global resource and network optimizations(ȫ����Դ�������Ż�): ������ܹ���������Ⱦ���̺�δ����������������ŵľ��ߡ��������ǰtab��Ӧ�������Ը��õ����ȼ���
- Predictive optimizations��Ԥ���Ż���: ͨ�����������Chrome�Ὠ������������Ԥ��ģ�����������ܡ�
- �� ��Ŀ���������С�
����һ����Ⱦ���̶���, ��IPC������Դ��������ף�ֻҪ����������ں˽���һ��ΨһID, ����ͽ����ں˽��̴����ˡ�
��ƽ̨����Դ����
��ƽ̨Ҳ��Chrome����ģ���һ����Ҫ����������Linux, Windows, OS X, Chrome OS, Android, ��iOS�� Ϊ�ˣ�����ģ�龡��ʵ�ֳ��˵�����ģʽ��ֻ�ֳ��˶�����cache��proxy���̣��Ŀ�ƽ̨������, �����Ϳ�����ƽ̨�乲�û������(infrastructure)��������ͬ�������Ż������л�������ͬʱΪ����ƽ̨�����Ż���
��صĴ�������������ҵ�the ��src/net�� subdirectory)�����IJ�����ϸչ��ÿ������������˽�һ�´���ṹ�����������������������ṹ�� ����:
- net/android ��Android ����ʱ(runtime) [��ע(Horky):����ʱ����һ�����õ��������û��һ����]
- net/base ���������繤�ߺ���������,���������� cookies, ����ת�����(network change detection),�Լ�SSL��֤����
- net/cookies ʵ����Cookie�Ĵ洢����������ȡ
- net/disk_cache ���̺��ڴ滺���ʵ��
- net/dns ʵ����һ���첽��DNS������(DNS resolver)
- net/http ʵ����HTTPЭ��
- net/proxy ����(SOCKS �� HTTP)���á�����(resolution) ���ű�ץȡ(script fetching), ��
- net/socket TCP sockets,SSL streams��socket pools�Ŀ�ƽ̨ʵ��
- net/spdy ʵ����SPDYЭ��
- net/url_request URLRequest, URLRequestContext��URLRequestJob��ʵ��
- net/websockets ʵ����WebSocketsЭ��
����ÿһ�ֵ�úúö�����������֯�ĺܺã��㻹�ᷢ�ִ����ĵ�Ԫ���ԡ�
Mobileƽ̨�ϵļܹ�������
�ƶ���������ڴ�չ��Chrome�Ŷ�Ҳ���Ż��ƶ��˵�����Ϊ������ȼ�����Ҫ˵�������ƶ����Chrome�IJ�����������汾��ֱ����ֲ����Ϊ����������������õ��û����顣�ƶ��˵��������Ծ;���������һ����Դ�������Ļ����������в�����һЩ�����IJ�ͬ:
- �����û�ʹ�����������������ص��Ĵ��ڣ������Ļ��Ҳ���õ��ĵ�ء�����Ҳ�dz��ȶ����д����Ĵ洢�ռ���ڴ档
- �ƶ��˵��û����Ǵ��������Ʋ�������ĻС����ص������ޣ�ͨ��ֻ���ù����Ұ�������磬�洢�ռ���ڴ�Ҳ���൱���ޡ�
���ߣ�����û�е��͵������ƶ��豸����������һ������ɫӲ�����豸��ChromeҪ���ģ�ֻ�����跨������Щ�豸������Chrome�в�ͬ������ģʽ(execution models)�������Щ���⣬�������࣡
��Android�汾�ϣ�Chromeͬ������������汾�Ķ���̼ܹ���һ��������ں˽��̣��Լ�һ��������Ⱦ���̡�����Ϊ�ڴ�����ƣ��ƶ����Chrome��Ϊÿһ��tabl����һ���ض�����Ⱦ���̣����Ǹ����ڴ��������������һ����ѵ���Ⱦ���̸�����Ȼ��ͻ��ڶ��tab�乲����Щ��Ⱦ���̡�
����ڴ�ʵ�ڲ��㣬������ԭ����Chrome�����ж���̣����ͻ��е������̡����̵߳�ģʽ��������iOS�豸�ϣ���Ϊ��ɳ����Ƶ����ƣ�Chromeֻ������������ģʽ�¡�
�����������ܣ�����Chrome��Android��iOSʹ�õ��� ������ƽ̨��ͬ������ģ�顣�����������ƽ̨�������Ż�����Ҳ��Chrome�������ȵ�����֮һ������ͬ������Ҫ������������������豸��������Щ������ �����Ʋ��Ż�(speculative optimization)�����ȼ���socket�ij�ʱ���ú������������С�ȡ�
���磬Ϊ���ӳ�����������ƶ��˵�Chrome���������ӳٹرտ� �е�sockets (lazy closing of idle sockets), ͨ����Ϊ�˼����ź�(radio)��ʹ�ö��ڴ��µ�socketʱ�رվɵġ�������ΪԤ��Ⱦ(pre-rendering,�Ժ�����)��ʹ��һ������ ��ʹ�����Դ����ͨ��ֻ��WiFi�Ż�ʹ�á�
�����ƶ������������һ�£�Ҳ������POSAϵ�е���һ�ڡ�
Chrome Predictor��Ԥ����Ż�
Chrome������ʹ�ñ�ø����������������ͨ��һ����������Predictor��ʵ�ֵġ����������������ں˽���(Browser Kernel Process)��ʵ��������Ψһ��ְ����ǹ۲��ѧϰ��ǰ������ʽ����ǰԤ���û���һ���IJ�����������һ��ʾ����
- �û������ͣ����һ�������ϣ���Ԥʾ��һ���û���ƫ���Լ���һ���������Ϊ����ʱChrome�Ϳ�����ǰ����DNS Lookup��TCP���֡��û��ĵ������ƽ����Ҫ����200ms,�����ʱ��Ϳ��ܴ�����DNS��TCP��صIJ���, Ҳ����ʡȥ���ٺ�����ӳ�ʱ�䡣
- ���ڵ�ַ��(Omnibox/URL bar) �����߿�����ѡ��ʱ����ͬ���ᴥ��һ��DNS lookup��TCPԤ����(pre-connect)��������һ�����ɼ���ҳǩ�н���Ԥ��Ⱦ(pre-render)!
- ����ÿ���˶�һ���������ʵ���վ, Chrome���о�����Щҳ���ϵ�����Դ, ���ҳ��Խ���Ԥ����(pre-resolve), �������ܻ����Ԥ����(pre-fetch)���Ż�������顣
��������������кܶ�..
Chrome������ʹ�ù�����ѧϰWeb�����˽ṹ������������������ģʽ������Ļ�������Ϊ��ʡȥ���ٺ�����ӳ�, ���ӽ��ڼ�ʱҳ����ص�״̬. ����Ϊ�����Ŀ��,ChromeͶ�������µĺ����Ż�����:
- DNSԤ����(pre-resolve)����ǰ����������ַ,�Լ���DNS�ӳ�
- TCPԤ����(pre-connect)����ǰ���ӵ�Ŀ�������,�Լ���TCP�����ӳ�
- ��ԴԤ����(prefetching)����ǰ����ҳ��ĺ�����Դ,�Լ���ҳ����ʾ
- ҳ��Ԥ��Ⱦ(prerendering)����ǰ��ȡ����ҳ����������Դ,��������������ʱ��ʾ
ÿһ�����߶�������һ���������Ż�, �����˷���������������. �����Ͼ���ֻ��Ԥ���Ե��Ż����ԣ����Ч�������룬�ͻ��������Ĵ��������紫�䡣�������ܻ����һЩ����ʱ���ϵĸ����顣
Chrome��δ�����Щ������? Predictor�ᾡ���ռ�������Ϣ�������û���������ʷ������ݣ��Լ�������Ⱦ����(render)������ģ����������Ϣ��
��Chrome�и�������������ȵ�ResourceDispatcherHost��ͬ��Predictor���������û�����������һ�������(filter):
- IPC channel filter�����������render���̵�����
- ÿ�������϶����һ��ConnectInterceptor ���������Ϳ��Ը������紫���ģʽ�Լ�ÿһ������Ķ������ݡ�
��Ⱦ����(render process)����һϵ�е��¼��·�����Ϣ�����������(browser process), ��Щ�¼���������һ��ö��(ResolutionMotivation)���Ա���ʹ�� (url_info.h):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
enum
ResolutionMotivation
{
MOUSE_OVER_MOTIVATED
,
// �����ͣ.
OMNIBOX_MOTIVATED
,
// Omni-box��������.
STARTUP_LIST_MOTIVATED
,
// ������ǰ10���������е���Դ.
EARLY_LOAD_MOTIVATED
,
// ��ʱ��Ҫʹ��prefetched����ǰ��������.
// ���涨����Ԥ���������ķ�ʽ������һ��navigation����ָ��.
// referring_url_Ҳ��Ҫͬʱָ��.
STATIC_REFERAL_MOTIVATED
,
// �ⲿ���ݿ�(External Database)������н�����
LEARNED_REFERAL_MOTIVATED
,
// ǰһ�����(prior navigation������н���.
SELF_REFERAL_MOTIVATED
,
// �²���һ�������Dz�����Ҫ���н���.
// <��> ...
}
;
|
ͨ����Щ�������� ����Predictor��Ŀ��Ϳ����������ɹ��Ŀ�����, Ȼ������ʱ����������ÿһ���¼�������ɹ��Ļ��ʡ����ȼ��Լ�ʱ�������Щ�������ڲ�ά��һ�������ȼ������Ķ��У�Ҳ���Ż���һ���ֶΡ����գ���������� ���з�����ÿһ������ijɹ��ʣ������Ա�Predictor�ٵ���������Щ���ݣ�Predictor�Ϳ��Խ�һ���Ż����ľ��ߡ�
Chrome����ܹ�С��
- Chromeʹ�ö���̼ܹ�������Ⱦ����ͬ��������̸��뿪����
- Chromeά����һ����Դ�ַ�����ʵ��(a single instance of the resource dispatcher), ��������������ں˽��̣����ڸ�����Ⱦ���̼乲����
- ������ǿ�ƽ̨��,��������Ե����̿���ڡ�
- �����ʹ�÷�����ʽ(no-blocking)����������������������
- �����������֧����Ч����Դ�����á���Ϊ������ṩ�ڶ���̼����ȫ���Ż���������
- ÿһ����Ⱦ����ͨ��IPC����Դ�ַ���(resource dispatcher)ͨѶ��
- ��Դ�ַ���(Resource dispatcher)ͨ���Զ����IPC Filter������Դ����
- Predictor�ڽ�����Դ�������Ӧ����������ѧϰ�����Ժ�����������������Ż���
- Predictor�����ѧϰ������������ģʽԤ���ԵĽ���DNS����, TCP���֣���������Դ����Ϊ�û�ʵ�ʲ���ʱ��ʡ���ٺ����ʱ�䡣
�˽��ɬ���ڲ�ϸ�ں�����������һ���û����Ը��ܵ����Ż���һ�д�ȫ�µ�Chrome��ʼ��
�Ż�������(Cold-Boot)����
��һ�����������������Ȼ�������˽����ʹ��ϰ�ߺ�ϲ����ҳ�档����ʵ�ϣ����Ǵ�������������������������Щ���Ƶ����飬���絽��������鿴�ʼ�����һЩ����ҳ�桢�罻ҳ�漰�ڲ� ҳ�浽�ҵ����������ࡣ��Щҳ����в�ͬ����������Ȼ����һЩ�����ԣ�����Predictor��Ȼ���Զ�����������١�
Chrome�������û���ȫ�����������ʱ��õ�10�������������������ʱ��Chrome����ǰ����Щ��������DNSԤ�������������Chrome��ʹ��chrome://dns�鿴������б����ڴ�ҳ���������ı����л��г�����ʱ�ı�ѡ�����б���

ͨ��Omnibox�Ż����û��Ľ���
����Omnibox��Chrome��һ���, �����Ǽش���Ŀ���URL�����˼�¼֮ǰ���ʹ���ҳ��URL��������������������ϣ�����֧������ʷ��¼�н���ȫ������(���磬ֱ������ҳ������)��
���û�����ʱ��Omnibox�Զ�����һ����Ϊ��Ҫô���������¼�е�URL, Ҫô����һ��������ÿһ�η���IJ������ᱻ�������֣���ͳ���������ܡ��������Chrome����chrome://predictors���۲���Щ���ݡ�

Chromeά����һ����ʷ��¼�����ݰ����û������ǰ�����֣����õ���Ϊ�������е���������������б�������Կ�����������gʱ����76%�Ļ��᳢�Դ�Gmail. ����ٲ���һ��m (����gm), ��Gmail�Ŀ��������ӵ�99.8%��
��ô����ģ�����ʲô�أ��� ���еĻ�ɫ����ɫ����ResourceDispatcher�dz���Ҫ�������һ��һ������Ե�ҳ��(��ɫ), Chrome���Ƿ���DNSԤ�����������һ���߿����Ե�ҳ��(��ɫ)��Chrome������DNS��������TCPԤ���ӡ�������������ˣ��û���Ȼ ����¼�룬Chrome�ͻ���һ�����ص�ҳǩ����Ԥ��Ⱦ(pre-render)��
��Եģ���������ǰ�������Ҳ������ʵ�ƥ����Ŀ��Chrome����������������߷���DNSԤ������TCPԤ�����Ի�ȡ���Ƶ����������
ƽ�������û�����д��ѯ���ݵ����������Ľ�����Ҫ�������ٺ��롣��ʱChrome�����ں�̨����Ԥ������Ԥ���ӣ���������Ԥ��Ⱦ���ٵ��û������»س���ʱ�������������ӳ��Ѿ�����ǰ�������ˡ�
�Ż���������
�����������û������ ���ۺ�ʱ�������ܣ������ܲ�̸���档�������Ѿ�Ϊҳ����������Դ�Ķ��ṩ��Expires, ETag, Last-Modified��Cache-Control��Щ��Ӧͷ��Ϣ(response headers)��ʲô? ��û�У����㻹���ȴ�������������!
Chrome�����ֲ�ͬ���ڲ������ʵ�֣�һ�ֱ����ڱ��ش���(local disk)����һ����洢���ڴ�(in-memory)�С��ڴ�ģʽ(in-memory)��ҪӦ���������ģʽ(Incognito browsing mode),���ڹرմ���������� ���ַ�ʽʹ������ͬ���ڲ��ӿ�(disk_cache::Backend, ��disk_cache::Entry)��������ϵͳ�ܹ����������ʵ��һ���Լ��Ļ����㷨�����Ժ�����ʵ�ֽ�ȥ��
���ڲ������̻���(disk cache)ʵ�������Լ���һ�����ݽṹ, ���DZ��洢��һ�������Ļ���Ŀ¼������������ļ�(�����������ʱ���ص��ڴ���)�������ļ�(�洢��ʵ�����ݣ��Լ�HTTPͷ�Լ�������Ϣ)���Ƚ���Ȥ ���ǣ�16KB���µ��ļ��洢�ڹ�ͬ�����ݿ��ļ���(data block-files,��С�ļ����д洢��һ�����ļ���)�������ϴ���ļ��Ż�洢���Լ�ר�����ļ��С�����̻������̭������ά��һ��LRU��ͨ ���������Ƶ�ʺ���Դ��ʹ��ʱ��(age)�Ķ������й�����

��Chrome����ҳǩ������chrome://net-internals/#httpCache�� �����Ҫ����ʵ�ʵ�HTTP���ݺͻ������Ӧ���������Դ�chrome://cache, ������г����л����п��õ���Դ����ÿһ������Կ�����ϸ������ͷ����Ϣ��
�Ż�DNSԤ����
ǰ���Ѿ�����ᵽ��DNSԤ������������ʵ��֮ǰ���Ȼ���һ��DNSԤ�����ij���������:
- ��������Ⱦ�����е�WebKit�ĵ�������(document parser), ��Ϊ��ǰҳ�������е������ṩһ��������(hostname)�б���Chrome����ѡ���Ƿ���ǰ������
- ���û�Ҫ��ҳ��ʱ����Ⱦ�����Ȼᴥ��һ�������ͣ(hover)��(button down)�¼���
- Omnibox���ܻ����һ���߿����ԵĽ���ҳ�淢���������
- Chrome Predictor����ڹ��������¼����Դ�������ݷ���������������(�������ϸ���͡�)
- ҳ�汾������ʽ��Ҫ��Chrome��ijЩ�������ƽ���Ԥ������
�����������Chrome��ֻ��һ��������Chrome������֤Ԥ����һ���ᱻִ�У����е���������Predictor�����������Ծ��������IJ������������£���������ʱ�������������û��ͱ���ȴ�һ�� DNS����ʱ�䣬Ȼ����TCP����ʱ�䣬�������Դ����ʱ�䡣Predictor����������������δ������ʱ��Ӧ�ؼ��Բο�����֮��һ����Խ��Խ�졣
֮ǰ�����Chrome���� ��סÿ��ҳ�������(topology),�����Ի��������Ϣ���м��١����ǵðɣ�ƽ��ÿ��ҳ�����88����Դ���ֱ�������30���������������ÿ���� ��ҳ�棬Chrome�������Դ�бȽϳ��õ����������ں�������������У�Chrome�ͻᷢ�����ijЩ��������ȫ��������DNS������������TCPԤ����!

ʹ��chrome://dns �Ϳ��Թ۲쵽���������(Google+ҳ��), ������6������Դ��Ӧ��������������¼��DNSԤ���������Ĵ�����TCPԤ���ӷ����Ĵ������Լ���ÿ�������������������Щ���ݾͿ�����Chrome Predictorִ����Ӧ���Ż����ߡ�
�����ڲ��¼�֪ͨ�⣬ҳ������߿�����ҳ����Ƕ�����µ�����������������Ԥ������
|
|
<
link
rel
=
"dns-prefetch"
href
=
"//host_name_to_prefetch.com"
>
|
֮�������������һ�����͵��������ض���(redirects). Chrome����û�취�жϳ�����ģʽ��ͨ�����ַ�ʽ��������������ǰ���н�����
�����ʵ��Ҳ����汾���������죬������ԣ�Chrome�е�DNS������������Ҫ��ʵ�֣�1.������ʷ����(historically), ͨ������ƽ̨�ص�getaddrinfo()ϵͳ����ʵ�֡�2.��������ϵͳ��DNS�������������ַ������ڱ�Chrome����ʵ�ֵ�һ���첽DNS��������(asynchronous DNS resolver)��ȡ����
������ϵͳ��ʵ�֣������ٶ� �Ҽ�����getaddrInfo()��һ������ʽ��ϵͳ���ã�����Ч�ز��ж����ѯ�������������ݻ���ʾ������������������ᳬ��·�����ĸ�� ChromeΪ�������һ�����ӵĻ��ơ��������д���worker-pool��Ԥ����, Chromeֻ�Ǽķ���getaddrinfo() ����, ͬʱ����worker threadֱ���յ���Ӧ���ݡ���Ϊϵͳ��DNS�����ԭ����Խ������������������������������ء� ������̼���Ч��
���������� getaddrinfo()������̫�����õ���Ϣ������Time-to-live(TTL)ʱ���, DNS�����״̬�ȡ�����Chrome�����Լ�ʵ��һ��ƽ̨���첽DNS��������

����¼�������֧�������Ż�:
- ���õؿ�����ת��ʱ��������������ִ�ж����ѯ������ �����ؼ�¼TTLs��
- ���õش���IPv4��IPv6�ļ��ݡ�
- ����RTT�������¼�����Բ�ͬ���������д�����(failover)
Chrome��Ȼ�����ų������Ż�. ͨ��chrome://histograms/DNS���Թ۲쵽DNS�������ݣ�

�������״ͼչʾ�� DNSԤ�����ӳ�ʱ��ķֲ������罫��50%(���Ҳ�)�IJ�ѯ��20ms����ɡ���Щ���ݻ���������������(����9869��)���û�����ѡ���Ƿ��� Щʹ�����ݣ�Ȼ����Щ���ݻ�����������ʽ���ɹ����ŶӼ��Է����������Ϳ����˽���ܵ����ܣ��Լ�δ����ν�һ���������ܶ���ʼ�������Ż���
ʹ��Ԥ�����Ż���TCP���ӹ���
�Ѿ�Ԥ����������������Ҳ���� ��OmniBox��Chrome Predictor�ṩ�źţ�Ԥʾ���û�δ���IJ�����Ϊʲô�ٽ�һ�����ӵ�Ŀ�����������û�������������ǰ���TCP�����أ������Ϳ�ʡ������һ�������� �ӳ٣����ؾ���Ϊ�û���ʡ���ϰٺ��롣��ʵ�������TCPԤ���ӵĹ����� ͨ������chrome://dns �Ϳ��Կ���TCPԤ���ӵ�ʹ�������

����, Chrome�������socket pool����û��Ŀ���������Ը��õ�socket�� ��Щsockets����socket pool�ﱣ��һ��ʱ�䣬�Խ�ʡTCP����ʱ�估������ʱ(slow-start penalty)�����û�п��õ�socket, ����Ҫ����TCP���֣�Ȼ��ŵ�socket pool�С��������û���������ʱ���Ϳ��������socket��������HTTP����
�� chrome://net-internals#sockets �Ϳ��Կ�����ǰ��sockets��״̬:

����Կ���ÿһ��socket��ʱ����:���Ӻʹ�����ʱ�䣬ÿ����������ʱ�䣬�Լ�����һЩ��Ϣ����Ҳ������Щ���ݵ������Է����һ���������߱������⡣�кõIJ����������Ż��Ļ���, chrome://net-internals����Chrome�������Ϣ������
ʹ��Ԥ�����Ż���Դ����
Chrome֧����ҳ���HTML��ǩ�м���������������Ż���Դ����:
|
|
<
link
rel
=
"subresource"
href
=
"/javascript/myapp.js"
>
<
link
rel
=
"prefetch"
href
=
"/images/big.jpeg"
>
|
��rel��ָ���� subresource(����Դ)��prefetch(Ԥ����)�dz����ơ���ͬ���ǣ����һ��linkָ��rel(relation)Ϊprefetch ���Ǹ�������������Դ���Ժ��ҳ����Ҫ�õ��ġ���ָ��Ϊsubresource���ʾ�ڱ�ҳ�оͻ��õ�,��������ʹ��ǰ���ء����߲�ͬ�������� resource loader�в�ͬ����Ϊ��prefetch�����ȼ��ϵͣ�һ��ֻ����ҳ�������ɺ�ŻῪʼ����subresource����ڽ�������ʱ�ͱ���������ִ�С�
��Ҫע�⣬prefetch��HTML5��һ���֣�Firefox��Chrome������֧�֡���subresource��ֻ������Chrome�С�
Ӧ��Browser Prefreshing�Ż���Դ����
���������������е�Web������Ը���������������subresource relation, ������ˣ�ҲҪ���յ����ĵ�����������Щ���ݲ��У����ʱ�俪�������ڷ���������Ӧʱ��Ϳͻ��������������ӳ�ʱ�䣬����Ҫ��ȥ��ǧ���롣
��ǰ���Ԥ����,Ԥ����һ�������ﻹ��һ��prefreshing::
- �û���ʼ��һ��Ŀ��ҳ�������
- Chrome��ѯPredictor֮ǰ���Ŀ��ҳ�������Դ���أ���ʼ��һ��DNSԤ������TCPԤ���Ӽ���Դprefreshing��
- �����ڻ����з���֮ǰ��¼������Դ���ɴӴ����м��ص��ڴ��С�
- ���û�л����Ѿ������ˣ����Ƿ�����������

ֱ����2013���, prefreshing���Ǵ������ڵ����۽Ρ����ͨ�����ݽ������������������������ˣ����ǾͿ�������Щʱ��ʹ�õ����ˡ�
ʹ��Ԥ��Ⱦ�Ż�ҳ�����
ǰ�����۵�ÿ���Ż����������������û�����������ҳ�����ݵ��ӳ�ʱ�䡣�����ܴ�����ʱ���ֵ������أ������û��������ݣ����ʱ����100���룬����û�������ӳ���ʲô�ռ䡣����100�����ڣ���������Ⱦҳ���أ�
��ҿ��ܶ�������������: ͬʱ�����ҳǩʱ�����Կ�����һ��ҳǩ�еȴ��������Ϊ���ṩ��һ��ʵ�ַ�ʽ:
|
|
<
link
rel
=
"prerender"
href
=
"http://example.org/index.html"
>
|
�����Chrome��Ԥ��Ⱦ(prerendering in Chrome)! �����ֻ����һ����Դ�ġ�prefetch��, ��prerender������Chrome��һ�����ɼ���ҳǩ����Ⱦһ��ҳ��,�����������е�����Դ�����û�Ҫ�����ʱ�����ҳǩ���е�ǰ̨�������˼�ʱ�����顣
�������prerender-test.appspot.com������һ��Ч������ͨ��chrome://net-internals/#prerender�鿴����ʷ��¼��Ԥ����ҳ���״̬��

��ΪԤ��Ⱦ��ͬʱ����CPU��������Դ����Щһ��Ҫ��ȷ��Ԥ��Ⱦҳ��ᱻʹ�õ�����²��á�Google Search��������������������prerender, ��Ϊ��һ����������ܿ��ܾ�����һ��ҳ��(Ҳ����Google Instant Pages)
�����ʹ��Ԥ��Ⱦ���ԣ�������������һ��Ҫ�μ�:
- ���еĽ��������ֻ����һ��Ԥ��Ⱦҳ��
- HTTPS�ʹ���HTTP��֤��ҳ�治����Ԥ��Ⱦ��
- ���������Դ��Ҫ������ݵȣ�non-idempotent,idempotent request������Ϊ�����Σ������������ĸ�����Ӧ������)������(ֻ��GET����)ʱ��Ԥ��ȾҲ�����á�
- ���е���Դ�����ȼ����ܵ͡�
- ҳ����Ⱦ���̵�ʹ����͵�CPU���ȼ���
- �����Ҫ����100MB���ڴ棬����ʹ��Ԥ��Ⱦ��
- ��֧��HTML5��ý��Ԫ�ء�
Ԥ��Ⱦֻ��Ӧ����ȷ�Ű�ȫ��ҳ�档����JavaScriptҲ���������ʱʹ��Page Visibility API���ж�һ�µ�ǰҳ�Ƿ�ɼ�(�ο� you should be doing anyway) !

�����֮��Chrome�����Ż������ӳٺ��û����飬���������û���ʹ��Խ��Խ�죡