����ת���ԣ�http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
�������߲�����д����
1.1��ժҪ
��Ҷ˹������һ������㷨���ܳƣ������㷨���Ա�Ҷ˹����Ϊ��������ͳ��Ϊ��Ҷ˹���ࡣ������Ϊ�����㷨�ĵ�һƪ�������Ƚ��ܷ������⣬�Է����������һ����ʽ�Ķ��塣Ȼ���ܱ�Ҷ˹�����㷨�Ļ���������Ҷ˹���������ͨ��ʵ�����۱�Ҷ˹���������һ�֣����ر�Ҷ˹���ࡣ
1.2��������������
���ڷ������⣬��ʵ˭������İ����˵����ÿ����ÿ�춼��ִ�з������һ�㶼�����ţ�ֻ������û����ʶ�����ˡ����磬���㿴��һ��İ���ˣ������������ʶ�ж�TA������Ů������ܾ���������·�϶����Ե�����˵�������һ���ͺ���Ǯ���DZ��и���������֮��Ļ�����ʵ�����һ�ַ��������
����ѧ�Ƕ���˵����������������¶��壺
��֪���ϣ���
��ȷ��ӳ�����
��ʹ������
���ҽ���һ��
ʹ��
��������������ģ����ѧ���ģ���������
����C������ϣ�����ÿһ��Ԫ����һ����𣬶�I������ϣ�����ÿһ��Ԫ����һ���������f�����������������㷨��������ǹ��������f��
����Ҫ����ǿ�������������������þ����Է�������ӳ�����һ������µķ�������ȱ���㹻����Ϣ������100%��ȷ��ӳ�������ͨ���Ծ������ݵ�ѧϰ�Ӷ�ʵ��һ��������������ȷ�ķ��࣬�����ѵ�����ķ�����������һ���ܽ�ÿ����������ȷӳ�䵽����࣬����������������������췽�������������ݵ������Լ�ѵ��������������������йء�
���磬ҽ���Բ��˽�����Ͼ���һ�����͵ķ�����̣��κ�һ��ҽ������ֱ�ӿ������˵IJ��飬ֻ�ܹ۲첡�˱��ֳ���֢״���ֻ������������ƶϲ��飬��ʱҽ���ͺñ�һ���������������ҽ����ϵ�ȷ�ʣ����������ܵ��Ľ�����ʽ�����췽���������˵�֢״�Ƿ�ͻ�������������ݵ����ԣ��Լ�ҽ���ľ�����٣�ѵ�������������������й�ϵ��
1.3����Ҷ˹����Ļ���������Ҷ˹����
ÿ���ᵽ��Ҷ˹�����������еij羴֮�鶼��Ȼ��������������Ϊ�����������������Ϊ���ر����á���������������ʵ�����ᆳ�����������⣺��֪ij�������ʣ���εõ������¼�������ĸ��ʣ�Ҳ��������֪P(A|B)�������������P(B|A)�������Ƚ���ʲô���������ʣ�
��ʾ�¼�B�Ѿ�������ǰ���£��¼�A�����ĸ��ʣ������¼�B�������¼�A���������ʡ��������ʽΪ��
��
��Ҷ˹����֮�������ã�����Ϊ�����������о�������������������ǿ��Ժ�����ֱ�ӵó�P(A|B)��P(B|A)�����ֱ�ӵó��������Ǹ�����P(B|A)����Ҷ˹������Ϊ���Ǵ�ͨ��P(A|B)���P(B|A)�ĵ�·��
���治��֤����ֱ�Ӹ�����Ҷ˹������
1.4�����ر�Ҷ˹����
1.4.1�����ر�Ҷ˹�����ԭ��������
���ر�Ҷ˹������һ��ʮ�ּķ����㷨���������ر�Ҷ˹��������Ϊ���ַ�����˼�����ĺ����أ����ر�Ҷ˹��˼������������ģ����ڸ����Ĵ����������ڴ�����ֵ������¸��������ֵĸ��ʣ��ĸ������Ϊ�˴������������ĸ����ͨ����˵���ͺñ���ô�����������ڽ��Ͽ���һ�����ˣ����������������������ģ���ʮ�а˾Ų·��ޡ�Ϊʲô�أ���Ϊ�����з����˵ı�����ߣ���Ȼ�˼�Ҳ�����������˻������ˣ�����û������������Ϣ�£����ǻ�ѡ�������������������������ر�Ҷ˹��˼�������
���ر�Ҷ˹�������ʽ�������£�
1����Ϊһ�����������ÿ��aΪx��һ���������ԡ�
2���������
3��������
4���������
��
��ô���ڵĹؼ�������μ����3���еĸ����������ʡ����ǿ�����ô����
1���ҵ�һ����֪����Ĵ�������ϣ�������Ͻ���ѵ����������
2��ͳ�Ƶõ��ڸ�����¸����������Ե��������ʹ��ơ�����
3����������������������������ģ�����ݱ�Ҷ˹�����������Ƶ���
��Ϊ��ĸ�����������Ϊ��������Ϊ����ֻҪ��������Կɡ�����Ϊ���������������������ģ������У�
�����������������ر�Ҷ˹��������̿�������ͼ��ʾ����ʱ��������֤����
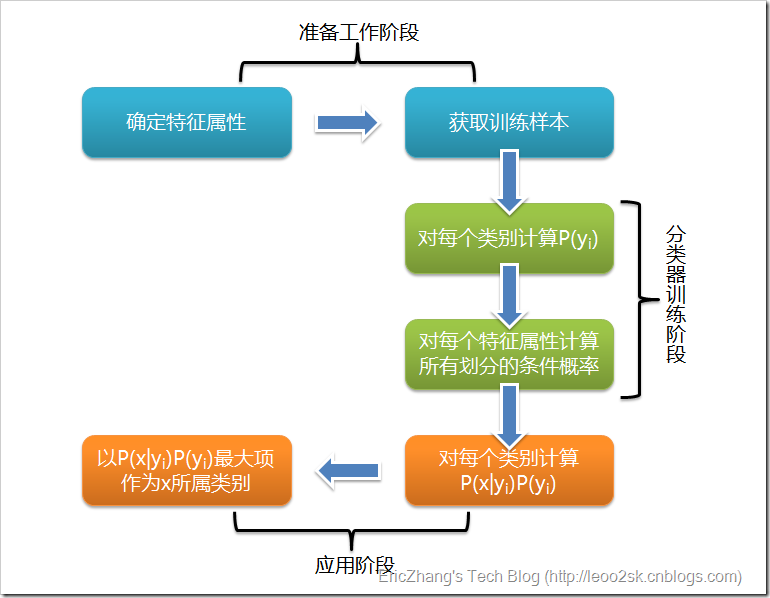
���Կ������������ر�Ҷ˹�����Ϊ�����Σ�
��һ�Ρ����������Σ�����ε�������Ϊ���ر�Ҷ˹��������Ҫ��������Ҫ�����Ǹ��ݾ������ȷ���������ԣ�����ÿ���������Խ����ʵ����֣�Ȼ�����˹���һ���ִ���������з��࣬�γ�ѵ���������ϡ���һ�ε����������д��������ݣ�������������Ժ�ѵ����������һ�����������ر�Ҷ˹������Ψһ��Ҫ�˹���ɵĽΣ����������������̽�����ҪӰ�죬�������������ܴ�̶������������ԡ��������Ի��ּ�ѵ����������������
�ڶ��Ρ���������ѵ���Σ�����ε�����������ɷ���������Ҫ�����Ǽ���ÿ�������ѵ�������еij���Ƶ�ʼ�ÿ���������Ի��ֶ�ÿ�������������ʹ��ƣ����������¼�����������������Ժ�ѵ������������Ƿ���������һ���ǻ�е�ԽΣ�����ǰ�����۵Ĺ�ʽ�����ɳ����Զ�������ɡ�
�����Ρ���Ӧ�ýΡ�����ε�������ʹ�÷������Դ���������з��࣬�������Ƿ������ʹ����������Ǵ�������������ӳ���ϵ����һ��Ҳ�ǻ�е�ԽΣ��ɳ�����ɡ�
1.4.2������������������Ի��ֵ��������ʼ�LaplaceУ
��һ������P(a|y)�Ĺ��ơ�
�����Ŀ���������������ֵ���������P(a|y)�����ر�Ҷ˹����Ĺؼ��Բ��裬����������Ϊ��ɢֵʱ��ֻҪ�ܷ����ͳ��ѵ�������и���������ÿ������г��ֵ�Ƶ�ʼ�����������P(a|y)�������ص�������������������ֵ�������
����������Ϊ����ֵʱ��ͨ���ٶ���ֵ���Ӹ�˹�ֲ���Ҳ����̬�ֲ���������
��
���ֻҪ�����ѵ�������и�������д�������ֵĸ���ֵ�ͱ������������ʽ���ɵõ���Ҫ�Ĺ���ֵ����ֵ�����ļ����ڴ˲�������
��һ����Ҫ���۵�������ǵ�P(a|y)=0��ô�죬��ij�������ij���������û�г���ʱ�����Dz���������������������������͡�Ϊ�˽��������⣬��������LaplaceУ������˼��dz������Ƕ�û��������л��ֵļ�����1���������ѵ��������������ִ�ʱ��������Խ������Ӱ�죬���ҽ��������Ƶ��Ϊ0�����ξ��档
1.4.3�����ر�Ҷ˹����ʵ�������SNS�����в���ʵ�˺�
��������һ��ʹ�����ر�Ҷ˹������ʵ����������ӣ�Ϊ�˼�������������е����������ʵ��ļ�
��������������ģ�����SNS������˵������ʵ�˺ţ�ʹ��������ݻ��û���С�ţ���һ���ձ���ڵ����⣬��ΪSNS��������Ӫ�̣�ϣ�����Լ�����Щ����ʵ�˺ţ��Ӷ���һЩ��Ӫ���������б�����Щ�˺ŵĸ��ţ�����Լ�ǿ��SNS�������˽����ܡ�
���ͨ�����˹���⣬��Ҫ�ķѴ�����������Ч��Ҳʮ�ֵ��£����������Զ������ƣ��ؽ������������Ч�ʡ��������˵���ˣ�����Ҫ�������������˺�����ʵ�˺źͲ���ʵ�˺���������Ͻ��з��࣬��������һ��һ��ʵ��������̡�
������C=0��ʾ��ʵ�˺ţ�C=1��ʾ����ʵ�˺š�
1��ȷ���������Լ�����
��һ��Ҫ�ҳ�����������������ʵ�˺��벻��ʵ�˺ŵ��������ԣ���ʵ��Ӧ���У��������Ե������Ǻܶ�ģ�����Ҳ��Ƚ�ϸ�£�������Ϊ�˼���������������������������Լ��ϴֵĻ��֣��������������ġ�
����ѡ�������������ԣ�a1����־����/ע��������a2����������/ע��������a3���Ƿ�ʹ����ʵͷ����SNS������������ǿ���ֱ�Ӵ����ݿ���õ����������ġ�
����������֣�a1��{a<=0.05, 0.05<a<0.2, a>=0.2}��a2��{a<=0.1, 0.1<a<0.8, a>=0.8}��a3��{a=0�����ǣ�,a=1���ǣ�}��
���ʣ�����{a<=0.05, 0.05<a<0.2, a>=0.2}�Ļ�����ֱ��ͨ���˹��о����ֵ����Ƿ����ͨ�������㷨���л��֣�
2����ȡѵ������
����ʹ����ά��Ա�����˹�������1����˺���Ϊѵ��������
3������ѵ��������ÿ������Ƶ��
��ѵ����������ʵ�˺źͲ���ʵ�˺������ֱ����һ�õ���
4������ÿ����������¸����������Ի��ֵ�Ƶ��
5��ʹ�÷��������м���
��������ʹ������ѵ���õ��ķ���������һ���˺ţ�����˺�ʹ�÷���ʵͷ����־������ע�������ı���Ϊ0.1����������ע�������ı���Ϊ0.2��
���Կ�������Ȼ����û�û��ʹ����ʵͷ����ͨ���������ļ��𣬸������ڽ����˺Ź�����ʵ�˺�����������Ҳչʾ�˵��������Գ�ֶ�ʱ�����ر�Ҷ˹����Ը������ԵĿ������ԡ�
1.5��������������
��Ȼ���������ᵽ���������㷨������������������һ��������۷�������������
����Ҫ���壬����������ȷ��ָ��������ȷ�������Ŀռ���б�������Ŀ�ı��ʡ�
ͨ��ʹ�ûع������������������ȷ�ʣ���ķ������ù�����ɵķ�������ѵ�����ݽ��з��࣬Ȼ����ݽ��������ȷ�����������ⲻ��һ���÷�������Ϊʹ��ѵ��������Ϊ��������п�����Ϊ������϶����½�������ֹۣ�����һ�ָ��õķ������ڹ�����ڽ�ѵ������һ��Ϊ������һ���ֹ����������Ȼ������һ���ּ���������ȷ�ʡ�
���Ļ�������-����ҵ��ʹ�� 3.0����Э�鷢������ӭת�أ�������DZ��뱣�����ĵ������������������ӣ����Ҳ���������ҵĿ�ġ��������κ����ʻ�����Ȩ�����Э�̣���������ϵ��