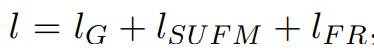Motivation
������Ϊ�Ի�����������Ҫ���ԡ�
��һ�����ԣ���ͳ���ı�ժҪ����˵����ժҪ������ֻ��ע���ŵ�ǰ���仰�����Ի�ժҪ��ע�Ľ��㣬����Ҫ�ӶԻ��Ŀ�ʼ������ת�Ƶ��Ի��Ľ��������߽�����ص��Ϊsupporting utterance flow����������߶�����supporting utterances����������ժҪ�е�ÿ�����ӣ��Ի��а���Ϣ����utterances(��ժҪ���ӵ�Jaccard���ƶ���ߵ�utterances)������Ϊsupporting utterances���ٸ����ӣ���ͼ�����˶Ի�ժҪSAMSUM���ݼ�������ժҪCNN/Dairy���ݼ���supporting utterances��λ�÷ֲ���S1����ժҪ�ĵ�һ�����ӣ�S2����ժҪ�ĵڶ������ӣ�position range����utterances��λ�÷�Χ��[0.1,0.2������ǰ10%��ǰ20%��utterances����ͼ�п������Ի�ժҪ�������ݼ��ϣ�ժҪ�ĵ�һ�����Ӷ�Ӧ��supporting utterances��Ҫ�ֲ���ǰ10%��30%�ķ�Χ��ժҪ�ĵڶ������Ӷ�Ӧ��supporting utterances��Ҫ�ֲ���ǰ50%��ǰ60%�ķ�Χ�����������Ӷ�Ӧ��supporting utterances��Ҫ�ֲ���80%��ķ�Χ����������ժҪ���ݼ��ϣ�ժҪ���������Ӷ�Ӧ��utterances��Ҫ�ֲ���ǰ30%�ķ�Χ��
�ڶ������ԣ��Ի�ժҪ���һ����ı�ժҪ�������˸������ʵ��Ԫ��ṹ(fact triplets,Ҳ������ν���ṹ)�����ú���Щ��Ԫ�飬���������ɵ�ժҪ���и��õ���ʵһ���ԡ����еķ���û�кܺõĿ��ǵ��Ի����������ص㣬�����ƪ���������һ���˵��˵�ģ�ͣ������� supporting utterance flow module��fact regularization module������ģ�飬�Ӷ���Ч�������˶Ի����������ص㡣
ͼ1��

Method
����ܹ�����ͼ��ʾ������������basic model,supporting utterance modeling(SUFM),Fact Regularization(FR)

basic model
����ģ����hierarchical encoder decoder
���Ƚ�����utterance������һ��ͨ��embedding�õ���Ƕ������[ e x 1 e_{x_1} ex1??,�� e x i e_{x_i} exi??,�� e x L x e_{x_{L_x}} exLx???]��ͨ��hierarchical encoder�õ�world-level��������ʾ [ h 1 , �� , h j , �� , h L x ] \left[\mathbf{h}_{1}, \ldots, \mathbf{h}_{j}, \ldots, \mathbf{h}_{L_{\mathbf{x}}}\right] [h1?,��,hj?,��,hLx??]�Լ�utterance-level��������ʾ [ u 1 , �� , u i , �� , u L x ~ ] \left[\mathbf{u}_{1}, \ldots, \mathbf{u}_{i}, \ldots, \mathbf{u}_{L_{\tilde{\mathbf{x}}}}\right] [u1?,��,ui?,��,uLx~??]��hierarchical decoderͨ����λ���ע�������ƽ��word-level��utterance-level����Ϣ�������յ�summary y = [ y 1 , �� , y t , �� , y L y ] \mathbf{y}=\left[y_{1}, \ldots, y_{t}, \ldots, y_{L_{\mathbf{y}}}\right] y=[y1?,��,yt?,��,yLy??],��ؼ��㹫ʽ���£�
����������״̬��
s t = GRU ? ( e y t ? 1 , s t ? 1 ) \mathbf{s}_{t}=\operatorname{GRU}\left(\mathbf{e}_{y_{t-1}}, \mathbf{s}_{t-1}\right) st?=GRU(eyt?1??,st?1?)
utterance_level��attention��
�� t , i u = ( v u ) T tanh ? ( W 1 u s t + W 2 u u i + b u ) , �� t , i u = exp ? ( �� t , i u ) / �� k = 1 L x ~ exp ? ( �� t , k ) c t u = �� i = 1 L x ~ �� t , i u u i \begin{aligned} \beta_{t, i}^{u} &=\left(\mathbf{v}^{u}\right)^{T} \tanh \left(\mathbf{W}_{1}^{u} \mathbf{s}_{t}+\mathbf{W}_{2}^{u} \mathbf{u}_{i}+\mathbf{b}^{u}\right), \\ \alpha_{t, i}^{u} &=\exp \left(\beta_{t, i}^{u}\right) / \sum_{k=1}^{L_{\tilde{\mathbf{x}}}} \exp \left(\beta_{t, k}\right) \\ \mathbf{c}_{t}^{u} &=\sum_{i=1}^{L_{\tilde{\mathbf{x}}}} \alpha_{t, i}^{u} \mathbf{u}_{i} \end{aligned} ��t,iu?��t,iu?ctu??=(vu)Ttanh(W1u?st?+W2u?ui?+bu),=exp(��t,iu?)/k=1��Lx~??exp(��t,k?)=i=1��Lx~??��t,iu?ui??
word-level attention���ƣ���u���h
c t w = �� j = 1 L x �� �� t , j w h j \mathbf{c}_{t}^{w}=\sum_{j=1}^{L_{\mathbf{x}}} \bar{\alpha}_{t, j}^{w} \mathbf{h}_{j} ctw?=j=1��Lx??����t,jw?hj?
ͨ��MLP�����б�ʾ����һ��
s ? t = Dropout ? ( W m [ s t ; c t u ; c t w ] + b m , r ) \overline{\mathbf{s}}_{t}=\operatorname{Dropout}\left(\mathbf{W}^{m}\left[\mathbf{s}_{t} ; \mathbf{c}_{t}^{u} ; \mathbf{c}_{t}^{w}\right]+\mathbf{b}^{m}, r\right) st?=Dropout(Wm[st?;ctu?;ctw?]+bm,r)
��pointer-generatorһ������ԭʼ�����и���һ���ִʵ������У�
P ( y t ) = ( 1 ? g t ) P V ( y t ) + g t P X ( y t ) P\left(y_{t}\right)=\left(1-g_{t}\right) P_{\mathcal{V}}\left(y_{t}\right)+g_{t} P_{\mathcal{X}}\left(y_{t}\right) P(yt?)=(1?gt?)PV?(yt?)+gt?PX?(yt?)
g t = sigmoid ? ( W g s ? t + b g ) g_{t}=\operatorname{sigmoid}\left(\mathbf{W}^{g} \overline{\mathbf{s}}_{t}+b^{g}\right) gt?=sigmoid(Wgst?+bg)
P V ( y t ) = softmax ? ( W V s ? t + b V ) P_{\mathcal{V}}\left(y_{t}\right)=\operatorname{softmax}\left(\mathbf{W}^{\mathcal{V}} \overline{\mathbf{s}}_{t}+\mathbf{b}^{\mathcal{V}}\right) PV?(yt?)=softmax(WVst?+bV)
P X ( y t ) = �� j : x j = y t �� �� t , j w P_{\mathcal{X}}\left(y_{t}\right)=\sum_{j: x_{j}=y_{t}} \bar{\alpha}_{t, j}^{w} PX?(yt?)=j:xj?=yt?��?����t,jw?
ʹ�ø�������Ȼ������Ϊ��ʧ������
l G = ? �� t = 1 L y log ? P ( y t �O y 1 , �� , y t ? 1 ; x ; F ) l_{G}=-\sum_{t=1}^{L_{\mathbf{y}}} \log P\left(y_{t} \mid y_{1}, \ldots, y_{t-1} ; \mathbf{x} ; \mathcal{F}\right) lG?=?t=1��Ly??logP(yt?�Oy1?,��,yt?1?;x;F)
SUFM
SUFMģ�飬����������SUFM embedding��SUFM loss��
SUFM embedding��ʾutterance position��summary token position֮���correlation����ԭ��encoder����Ļ����������� e i u e_i^u eiu?,��ʾ��i��utterance��position embedding��������ͼ�У���һ��token x 1 x_1 x1?�ڶ���token x 2 x_2 x2?�����ڵ�һ��utterance,��Ӧ��position embedding���� e 1 u e_1^u e1u?����ԭ��decoder����Ļ����������� e t s e_t^s ets?�������˵�t��summary token��Ӧ��position embedding��SUFM embedding�ṩ�����ɵ�summary tokens��dialogue utterances֮���word-level alignment��
SUFM loss�ṩ�����ɵ�summary tokens��input utterances֮���sentence-level alignment,ʹ��ģ�Ϳ���ƽ����ת������dialogue�ϵ�focus����ͨ������Jaccard���ƶȵõ�ÿ��summary sentence��Ӧ��supporting utterances�����嵱ǰ��summary sentence����Ϊ C S S k CSS_k CSSk?,��ǰsummary sentence��Ӧ��supporting utterancesΪ C S U k CSU_k CSUk?����һ��summary utterance��Ӧ��supporting utterancesΪ P S U k PSU_k PSUk?,SUFM loss���������� l C S U k l_{CSU_k} lCSUk??�� l P S U k l_{PSU_k} lPSUk??, l C S U k l_{CSU_k} lCSUk??ʹ��ģ��ע��ǰsummary sentence��supporting utterance�����㹫ʽ���£�
l C S U K = log ? ( �� t : y t �� C S S k �� j : y j �� C S U k �� t , j w �� �� t : y t �� C S S k �� j : y j �� t , j w �� ) l_{CSU_K}=\log {\left(\frac{\sum_{t:{y_t}\in{CSS_k}} \sum_{j:{y_j \in{CSU_k}}}\bar{\alpha_{t,j}^w}}{\sum_{t:{y_t}\in{CSS_k}}\sum_{j:{y_j }}\bar{\alpha_{t,j}^w}} \right)} lCSUK??=log(��t:yt?��CSSk??��j:yj??��t,jw?��?��t:yt?��CSSk??��j:yj?��CSUk??��t,jw?��??)
l P S U k l_{PSU_k} lPSUk??ʹ��ģ�ͺ�����һ��summary sentence��supporting utterance�����㹫ʽ���£�
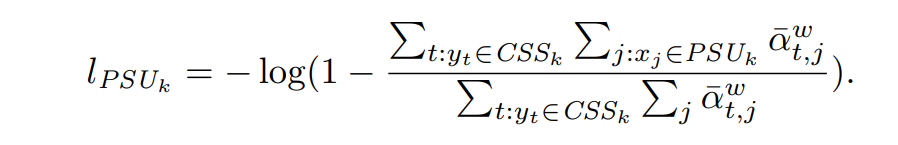
���յ� l S U F M l_{SUFM} lSUFM?���㹫ʽ���£�
l S U F M = �� k = 1 n ( �� 1 l C S U k + �� 2 l P S U k ) l_{SUFM}=\sum_{k=1}^n \left(\lambda_{1}{l_{CSU_k}}+\lambda_{2}{l_{PSU_k}}\right) lSUFM?=k=1��n?(��1?lCSUk??+��2?lPSUk??)
FR:
FRģ�飬��������fact triplet extractor��gold summary����ȡ��fact triplets,ͬʱ��ѵ��Ŀ��������һ�����������ģ���������ժҪ����ʵһ���ԣ�fact triplet extractor����dependency parse,���ӵ���������㹫ʽ���£�
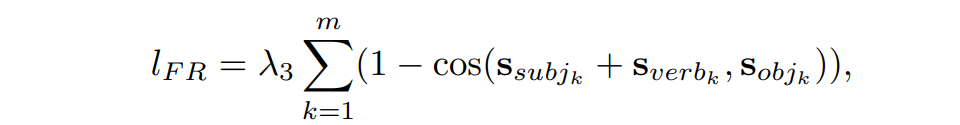
s��������summary��hidden states,Ŀ����ʹ�������һ�£�������TransE��˼�롣 s u b j k subj_k subjk?������k��fact triples�е�subj��index,sverb,sobj����
ģ������loss��ʾΪ��