������Դ��2021 �� 6 �� 5 �գ��� SegmentFault ˼������� 2021 �й���������̬���Բ����Ļ�����ϣ���Ϊ MindSpore ��Ӫ�ܼ����������������Ϊ��MindSpore ��Դ��Ӫ�����������ݽ���
�����α�������������Ϊ MindSpore ��Ӫ�ܼ�
�ټ�������������SegmentFault ˼��༭��

�������ҷ���һ�� MindSpore �Ŀ�Դ��Ӫ���������ڽ�֮ǰ���ȸ�����������ҽ��ܡ��ҽк�������15���ҵ����ҵ֮��һֱ�����㷨����ʦ������������㷨����ʦд��������룬19��ȥ�˰ٶȣ������ѧϰ����ʦ��ȥ����뻪Ϊ������ MindSpore ���������Ŀ�Դ��Ӫ����ʵ�ڽӵ���������ʱ���ҷdz��ز��죬Ҳ�dz����ģ���Ϊ���㷨ת����Ӫ��ʱ�����ر��Ļ��ʧҵ��Ц������ΪȦ��̫С�ˣ��ܶ��˲����ر��ע��������Ӫ������顣��ʵ��Դ��Ӫ���������µĹ��֣��������з����㷨����ʦȥ��ͼ���� NLP���зdz���ȷ��Ŀ�ģ�Ҳ�зdz���ȷ��ְҵ�滮�������������κ������Ĺ������dz����㡣���Խ������ҷ�������ʲô�ǿ�Դ��Ӫ��������������һ�굽������ʲô���飿
ʲô�ǿ�Դ��Ӫ��������
��Դ��Ӫ������ʲô�����ܽ��˼����㡣
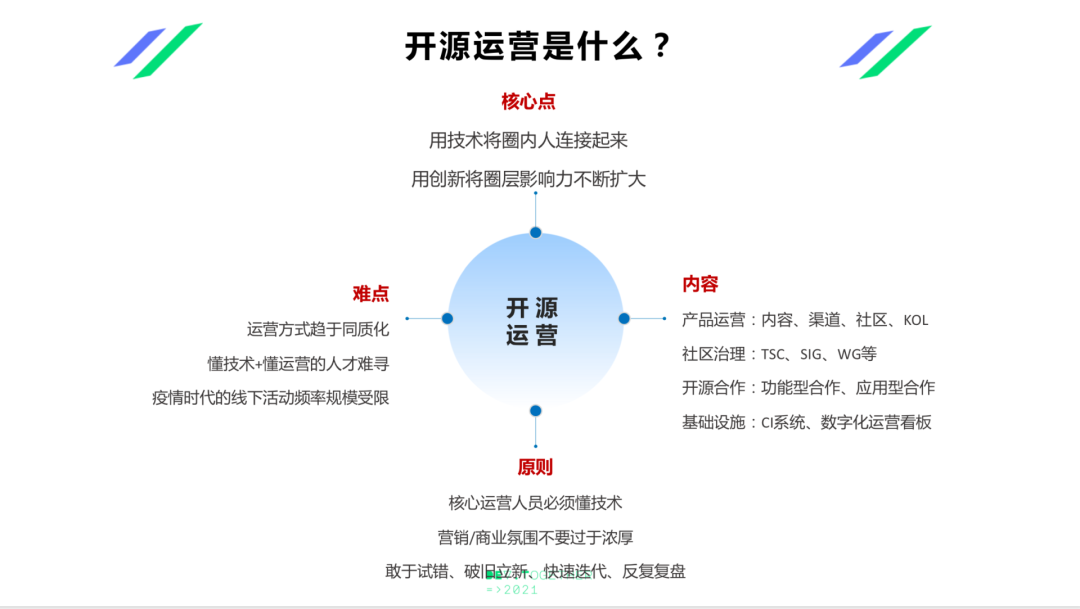
������Ϊ��Դ��Ӫ�ĺ��ĵ��ü�����Ȧ���������������ô��µķ�ʽ��Ȧ���Ӱ��������������Ȧ����Ҳ��֪����ļ�����Ʒ��ʲô���ܶ���ֻע��ǰ�ߣ���������ֻ���Ȧ�ڼ�����Ⱥ���������Ҫ��һ��Ҫ�ò��뿴�����ݵ���Ҳ�ܿ��꣬���ǽС���Ȧ�������ѵ����ڣ����ںܶ���Ӫ�ķ�ʽ�dz�����ͬ�ʻ�����Ҷ�����Ӫ�ܳ��������������������ý��ģ������Dz���������Ȧ�����ģ���Ϊ������С�࣬����ʵ��һ�����������Ƿ����������м�����������Ӫͬѧ�dz��ټ���Ҳ�dz��dz����С�����Ҫ��Ӫ���Ǽ�����ܣ���ô�м�����������������˵�DZز���ȱ�ġ�����Ŀǰ�����Ŷӻ����϶����м��������ġ�
����Ŀ�Դ��Ӫ�����ݣ��Ұ�����Ϊ�Ŀ飺��һ���Dz�Ʒ��Ӫ���������dz��������ݡ�������������KOL �Լ�Ʒ�ƣ��ڶ�������������������TSC��SIG��WG�ȣ��������ǿ�Դ���������������ͺ�����Ӧ���ͺ����ȵȣ�����һ������������Ļ�����ʩ������ CI ϵͳ��Ҳ�����ֻ���Ӫ���壬��������õ��˽���ӪЧ��������ô����
�ܽ���ԣ�����Ŀǰ���ڿ�Դ��Ӫ�м���ԭ��һ��������Ϊ��Դ��Ӫ�ĺ�����Ա����Ҫ���������Ҵ�����һЩ��Ӫ�Ŷ��У��ܶ����Dz��������ġ���ô�������Ĺ����У�����Ѹ�����������Ľ��������ڿ�ܻ��߶Լ������壬���ǵ���Ӧ�ò�ȡ���ֺ��ʵķ�ʽ���ÿ����߸��õ��˽�����������Ϊ֮������Ҫ�������������˱��붮����������㲻�ᣬ�Ǿ�ȥѧ���е�ͬѧ��ѧ�ĿƵģ�����Ҫ��Ҳ����ȥѧShell�ű�ȥѧPython��������ȥѧϰ MindSpore��
�ڶ���Ӫ������ҵ�ķ�Χ��Ҫ����Ũ�����ܶ��˻����Ӫ���г�������BD�ֲ���������ǻ�˵��������������Ի���ת������Ӫ��Ҳ����������Ӫ���г�marketing��Ҳ��������𣿺�������˸о�û�����𡣵���ʵ��Ӫ��marketing��Ӫ����Ա���б�������ģ����Dz��Ǵ����PR�����Ǵ���ش��档
�������������ܽ�����ľ��飬�����е���Ӫ�飬������ΪӦ��Ҫ�����Դ�����������û���ر���������˵�ر�淶��һ��·�ô��ȥ��ѭ�����ںܶʽ�����Ƕ�����ȥ���ԡ�����֮����ȥ������Ч�����������Ч�����ԣ��ͰѱȽϺõľ����ܽ�������������ò�̫�ã������ټ���ȥ���������ϵ����������������ܽᾭ�飬ʵ�����ˣ�·�ͳ����ˡ�
�ȼ�һ��MindSpore��ʲô������ȥ��3��28�Ż�Ϊ��Դ��һ��ȫ����AI�����ܡ����˻���ú��ɻ������������Ѿ���TensorFlow��PyTorch��Ϊʲô���ǻ�Ҫȥ�����ѧϰ��ܣ����ĺ��������������ƾʲô�ÿ�����ѡ����Ŀ�ܣ���ԭ���Ŀ�ܸ��滻����

��ʵMindSpore�м����dz����ĵĵ㡣��ҿ��Կ����ұߡ��Զ����С����������Ż������������ô���ܹ��dz���Ч��ѵ��ģ�͡�����˵��ԭ����Ҫһ�ܻ�һ���ʱ����ѵ��ģ�ͣ���ô�������������������£�ʹ��MindSpore������Լ��������ģ��ѵ��ʱ�䣬����ںܶ���ҵʵ����������Ƿdz�������ơ��ڶ��Ƕ���̬ͼ��ת���dz����㣬�ʺϿ������л���������ȫ��������Эͬ�����ڿ����߶��Լ��˲������̣����зdz��õ������ԡ�����ļ���Ͳ���ϸ���ˣ�������Ҫ�ǽ���Դ��Ӫ������ֻ�Ǹ���ҽ���һ������MindSpore������ʲô��
��������һ��Ŀ�Դ������Ӫ��������˵����ֹ��2020��5�µף�MindSpore�ۼ���������35��࣬�����PR����2.6��Ŀǰ����һ��������120���ģ�͡�2000�������Ӧ�á�û���ù���Ҫ�����������õ��ǻ�Ϊ�ֻ�����Ϊ�ֻ�������MindSpore Liteѵ����ģ��Ӧ�ã��վ�������3�ڶ�Ρ�
��Դ��Ӫ��������������
�������������⡣���������ҷ���������ģ�͵�˼ά����Դ��Ӫ��

����ǰ�����㷨�ģ�����ÿ��Ҫȥѵ�����ָ�����ģ�ͣ����ڷ������˼·����ȫȫ�����õ���Ӫ���档�����һ�£��������㷨��ʱ���õ�һ����Ŀ�����ȹ�ע������Ŀ������Ӧ����ô��ȥ��������������ҵ����ô�ڷ���������֮������Ҫȥ����������������ϴ����ȡ�����������ݣ���ȥ����ģ��ѵ����ģ����������ģ��Ч���ٽ��е��š�����ﵽָ���ˣ����ǾͿ��Խ���ģ�͵����ߺͲ���
�����˼·�ŵ���Ӫ���Ҳ��һ���ģ���ӪҲ����Ҫ���˽�����Ҫ������Ŀ��Ҫ�ﵽ������Ŀ�꣬�����ֽ�������˵����Ҫ��MindSpore�Ŀ�Դ��Ӫ����ô���������Ŀ����ʲô���ڶ����Ŀ����ʲô��������֮������Ҫ����ʲô������Ҫ�������������ͷ�����Ŀ������Ҫ��Ҫȷ��������������ġ������Ŀ��ȷ����֮������Ҫ��Ŀ����зֽ⣬���� MindSpore ��һ������Ҫ�ﵽ��������������10�������������ô�������أ���ʵ10��������ֲ����Ƿdz���ȷ��Ŀ�꣬����˵����������������10������Ҳ����10������ֻ����ΪҪ�ﵽ������֣�����֤�����������ϵ����ƣ����Dz���ֵ�ü�����ǰȥ���Ļ���������֮��������ԣ���������ԡ�
��ô�ֽ�ָ��֮������������������Ӫ�����������СMVPԭ��ʲô��˼�أ������������κλ����������С���ò�Ʒԭ���������Ŷӿ�����һ��������ĿTinyMS�����ǻ���MindSpore���ĸ�API���ߣ����С������Ϊ���ô�ң�������С�����ɵ����֣��dz���ȥѧϰMindSpore������AI����ʱ������������ߵ�ʱ�������Ŷ���Ȼ��Ҷ��м�������������Щͬѧ���Ǵ��㷨��������һ��Ҫ��������Ʒ����С���õIJ�Ʒ��̬����ô���ģ���Ҫ���һ������û�ʹ�㣬ͬʱ���ܲ��ܹ��ڸ��ӵļ����ܹ������������������ļ����ܹ�������������з��Ѻ��Ĺ������������������ȳ�һ���汾������������֮�����ߵķ�Ӧ���ٲ��ϵ�ȥ����������һ���εڶ����汾������ʱ��ȥ����Ӧ�ĵ��������ԣ���СMVP����֮������Ҫ������Ч����һЩ�������������������ļ�����ĿҲ�ã�����˵���κογ̣�����ȥ���������Щ����ָ���ת��������֮������Ż����ٲ�ͣ�ط���������֪�������ܽ��һ���ɸ��óɾ���ķ����ۣ����������²�Ʒ/�����ʱ����������̻�ȥ����������ʡ���������ұ�֤��Ʒ�������ȶ��ԡ�
���ǿ��Կ������㷨ģ�ͺ���Ӫģ���зdz������ͬ������һ����ͬ���Ƕ�������Ϊ��Ŀ�ƣ���Ҫ������СMVPԭ�����Ŀ�������ߣ�������˵��һ�����µ�ʱ��ȥ��һ�ڿΣ���dz��˷�ʱ�䣬�г���������㡣�ڶ����Ƕ���Ҫ������������ͷ�����ȥ������ȥ�����������ڣ����ϵ�ȥ�Ż��������Ч�����ܲ��ϵؽ������������Dz������㷨��������Ӫ������Ҫ�������컯����������˵���Ƽ��㷨���Ա����Ƽ����������Ƽ���ƴ�����Ƽ�һ�����л����ϵIJ���ġ����˵������һ�����Ƕ����û���˵��ѡ���ϻ���һ���ķݶ���ʧ�������Ƕ���Ӫ��˵�������û�в��컯���Ƽ��������û����������������˿γ̣�����ѡ���ǵĿγ̣������ֿ����������Ŀγ̣����û�ΪʲôҪѡ�����ǣ����Ǹ����ǵIJ��컯��ʲô�ط�����������ʦ��ǿ���γ���Ƹ���Ȥ������������Ӫ�ķ���������ã��ܹ������е��û����Ͽ�֮������Щ���ɣ��ܹ��õ�������ѧϰ��������������������Ŀ��ʱ����Ҫ����˼���ĵ㡣
�������ǻ��м�����ͬ�ĵط�����һ�����ڹ�˾�����㷨ģ����Ҫ����ع�ע���������ݡ���Ϊ��������ṹ�Ż���ʲô�ز������ݾ��飬�����ʱ��������������㹻�ã����ӵ��㹻��ĸ���������ȥѵ��ģ�͡�������Ӫ����ע����ʵ�ʵ����ݡ�Ҫ��������ָ�����ٷ��٣�����Ȼ����һ���̶������ֹ����ɹ�����Ҳ���ɱ�����Ҫ�Ľ��������ĵ㡣��Ȼ�����˳ַ����������Ϊ�����ܹ���ӳһ�С����Dz���������۵㣬���������ǿ�Դ��Ӫ������Ƚ��£���û�а취�ҵ��dz�������������Ӫ��������ݣ�ȥ������ǰ�ڵĵ��У��ٸ�����һЩָ�����飬��ȥ����Ŀ�����˵ĵ������ݺ������еķ������ݵ�ͳ��ָ�겻һ���ܸ�����ʵ����ȷ��ָ�ꡣ�ڶ��������㷨ģ�;������������Ż��͵������ﵽһ������ֵ֮�������ߣ�����Ӫ���ǣ���Ӫ����Ҫ���ǿ��ٵز����������������ݡ�Ҫ���Լ�����һ��baseline��������һ�����ߵİ汾��������˵�ҰѲ�Ʒ�Ĺ���ȫ�������ˣ��������ߡ����������ߣ���ľ�Ʒ��������Ѿ������ˣ�ѹ��������㡣���������㷨ģ�Ͷ����쳣ֵ�����߶��ڸ���Ĺ�ע��dz�С�����������Ƕ������������Ĺ�ע�������ر�Ĵֳ����������Ҿ�����Ӫһ����ڸ���Ĺ�ע���ǻ�dz���Ҫ����Ϊ��ֻ��֪�������ߣ�������һ��һ���߸��㹻��Ŀ�����ȥ�ģ�֪����������������ע�IJ�Ʒ����ʹ����ʲô�����������֮������һЩ��ϸ������Ӫ���ҵ���������ĵ������ϵļ����Լ����û����Լ��������û����������飬���������û��ģ������ھ�����ı��ʡ��ⲻ��������Ӫ����Ҫ��һ�㣬����ƷҲ��һ����
��Դ��Ӫ��������ϵ���ṹ���Է�Ϊ�⼸�顣

��һ����Ʒ��Ӫ����Ʒ��Ӫ����飬���ǻ���һЩ���ͻ�����Ŀ�ľ�ֻ��Ϊ������Ʒ�Ƶ�Ӱ���������Թؼ���ָ����ֱ��ת�����ܶ��˻������������ִ��ͻ���״�������Щ���棬���г�����Ҳ���ܻ���Ͳ�������״������������档�����˵����������ȫ���Ĺ�ע�����������ж��٣����ϰ�����㣬�����״�����ʲô���棿�������ó������ۣ�����Ʒ��Ӫ�������Dz��Թؼ���ֱ��ָ����ת�����㿴�����������͵Ļ��顢���͵Ļ��������������������һ�����������ǵĺ���ָ����δ�أ����ø�����û���֪Ҳ�Ƿdz���Ҫ��һ����
�ڶ����ǿ�Դ��Ӫ�ĺ���������������ݷdz��࣬�����и��ָ�����ͬ����ʽ���������¡�ͼ�ġ���Ƶ�����͵ȵȡ���ʽ�dz�����������Ҫ������Ƶ�IJ���������ÿ���������ݣ����Ƕ����趨�ض���ָ��ȥ������������γ̣�����Ϊ���������ĵĿ����ߣ���ô���ĵĿ����ߣ����ǾͲ������������ȥ�����ͻ�������һЩ���ڿ����߱ȽϺõĶ���Ƶ��ȥ��Ϊ����ָ����ȥ������
�������Ǹ�У��չ����У��չ��Ϊ�˽���û���Դͷ���⣬����У��չ��Ϊ�˷�չ�����ߵĻ������ռ�ѧ���Ľ��飬���������ܻ��������Ʒ��Ӧ���ԡ�
���һ������ҵ������������ǻ����ϻ�ΪAI�������ĕN�ڴ������ģ��������������ҵ�л������ҵ�ṩ���������ܣ���չһЩ��ҵ�������Ŀ�������г��ݶ
Ʒ��Ӫ��
�ȸ���ҽ�һ������������ЩƷ��Ӫ��������������³���������CCTV-2�����ð�Сʱ�������ҽ�����MindSpore��һ���������ijɼ����ڶ�����MindSpore�����졣��ΪMindSpore����ȥ��3��28�ſ�Դ�ģ����������ڽ����3��28��������������������TSCίԱ��ij�Ա��ȫ��40��λ����ר�Һͺ��Ŀ������Լ���ҵ����û�¼��ף����Ƶ�ͼ��������������MindSpore�²۴�ᡣ�²۴���ҿ����ɣ�����ΪʲôҪ���²۴���أ���Ϊ�ܶ���߶����ǵIJ�Ʒ��һЩ���飬������û�а취����û��������һЩ�dz�ֱ�۵��²ۣ�����������issue������ȥQQȺ/��̳���ʣ��������Ǿ��������ṩ��ôһ���������ô�Ҽ��е�ȥ�²ۡ������ȿ������������ߺ�����֮��ľ��룬Ҳ���������ǵĺ��Ŀ�����Ա֪����Ʒ��Щ�ط������ÿ����߲������õ����飬ʵ����������Ч���dz��á����⣬�����һЩ�߶˻���ұ��ǽ���ո�ͨ���Ŀ��ſ�Դ����������ϵ��֤��MindSpore������������Ψһһ��ͨ�����ſ�Դ������AI��ܡ�����������������������Ҳ������������Ӫ�������Ĺ淶�������������ȵȣ���ÿ�����涼�������֣����Ƿdz������ġ�
��������
������������������һ�顣�ȸ����˵�²�Ʒ���ݣ�������鲻�������Բ����ݣ�Ҳ���������ߵ����ݡ�����������Լ��������൱�������Լ��������Լ��档����һ��Ҫ���������ߣ������Ǻ��Ŀ�����ȥ�����ǹ������ݡ����������ݲ���������ͨ�Ŀ����ߡ������Ŀ����߸�����ȥд���£��������μ��˻֮��д��һЩ�������£����ǻ�����ϵһЩ���ĵ�KOL��������һЩ���ļ����������Ƶ��
����������Ŷ����ļ�����Ŀ���ոո���ҽ�������ʵ�ܶ��˶���Ӫ�Ŷ��п̰�ӡ����Ӫ�Ŷ�Ҳ����������Ŀ�𣿰������ǹ�˾�ڲ�Ҳ����ú���֣����������Ŀ�����Dz����ҵ��з�ȥ���ģ���ʵ��ȫû�б�Ҫ�����ǵ�ʱ��һ��С�����û�ȥ�Ӵ�MindSpore��ܣ�������˵��������һ���Ѷȵģ�����Ϥ����API������ܹ�������ڴ�С��������˵�����ż��ġ�TinyMS��Ŀ���ǽ����ż����ô�С������ѧϰAIû���ż���������ܹ�ȥѧϰ����AI�����Ŀ��TinyMS������ܹ��dz����������ģ�������˺ܶ����ݼ�����Model���������˲��ٳ��õ����ѧϰģ�ͣ����ڿ�������˵����ֻ��дһ�д���Ϳ��������ݼ��ĵ��á�ģ��ѵ���Լ�ģ�Ͳ���
���˼�����Ŀ���������еĿγ̻����϶���¼��һ��ϵ�С����Ͻǵ���21�켯ѵӪ��������ȥ��ʮ�·�����Ȥζʵս��γ̣����Ͻ���ÿһ�ε��������°汾����֮���������ռ�ѵӪ���ÿ������ܹ�����ٵ��˽����ǵ����������ԣ�������TinyMS���ı�ķ���̳̣��ұ���SIG meeting���Լ�TSC meeting�ȵȡ�ͬһϵ�е���Ƶ�����Ƕ�������ͬ�ķ��棬���dz�ͳһ���ص�Ҳ�dz�ͻ�������㿪����Ѱ����Ƶ�����ں���һ��Ƚϳ��棬�Ͳ���ϸ���ˡ������Ҫ����ϣ�����ǵ���Ӫ�Ŷ��������ںŵ�ʱ���ܹ�������KVɫ��һ�£���Ϊ���ǵ���logo�ǽ�������Ȼ���ڸ߷�ʱ��ͳһ������
MindSpore Bվ��Ӫ�Ļ����ո��Ѿ�����ҽ�������BվĿǰ����Щ���ݣ�Ͷ�ŵĻ�Ҳ���ڸ߷��ʱ���ȥ��������������Щ��Ƶ���Ѿ��ϴ�����CCF�ĵ���ͼ��ݣ���Ҳ���������Bվ�Ͽ���Ҳ������CCF����ͼ��ݿ���Ŀǰ��������Ψһһ����CCFͼ�������������Ƶѧϰ�μ���AI�����ܡ�
˵����������ʵ�ܶ��˻�ܺ�������ΪʲôҪȥ����������Ϊ����������˵���������Ǽ�����Ա������������ܶ����Ա�ֻ��ﶼû�ж������������ǵ�ʱ�����ڿ�����Խ��Խ���ᡣ��MindSpore�ոճ������ܶ��˲���֪��MindSpore������ʲô����������Щ���㣬����������ܵ����ԶԱ������㵽�����ĸ��ط������չ��������Ƿ����°汾������release note�ɣ�����һϵ�о���ĸ��£���Щ���¶�����Ϊ���û��Ŀ�������˵̫���ˣ�����֪���ص�����һ���������Ҿ����ܲ��ܹ���һ���ӵ���Ƶ����ҽ������ǰ汾���������㡣�ص㣺��Ҫ����һ���ӣ�����������������Ĺ���ȥ�����ǰ汾�������µļ������ԡ�
�������½������Ƶ�������0.6-beta�İ汾���ð汾��ʱ�����ĺ��ĵ�֮һWide&Deep��Wide&Deep��ʱѵ���ÕN�ڵ�16pcs��23.6���ӾͿ���ѵ����ɣ���Ŀǰ���п������������ߵġ������ֱ��˵����һ�仰�����еĻᶮ�������㲻���Ƽ�������˲��ᶮ�����о������ˡ����Ե�ʱ���Ǿ�������ôһ�����£�Ů������Ҫ�˽�������Щϲ�ã�������MindSpore��Wide&Deepģ�ͣ�ֻ��Ҫ23.6���ӾͿ���ѵ����ɣ���һ��������ϲ������ϵͳ��Ȼ������ˡ����顱�ı�ǩ������������ij�һ������Ƶ������֮��24Сʱ�ڲ������ﵽ10��+����û�����κ�Ͷ�ţ���Ϊ����Ͷ��̫���ˣ��������Dz�֪��Ч����ô��������ֻ�ǿ�����ȥ������ҹ�ע���ǵIJ�Ʒ���㡣
���˶���֮�⣬���ǻ���Ӫ����Ƶ�źͲ��ͺš���Ƶ���Կ���������Ϊ��������Ƚ϶�䣬��ʽ�dz���Ȥ�������ͺŲ�һ�������ͺŵ����ݼ����ں�AI����ר�ҵķ�̸Ϊ�������ǻ����AI��ҵʵ����صĶ���������Ƶ�Ż��в��컯��
���������֮�����ϵ���������õ�Ҳ�Ǹ��������ϵ���ò�һ���ġ�

��ҿ��Կ������½����ͼ�����Ƿ�ΪSI��ST��GI��GT�ȵȡ�����MindSpore���ʵIJ�֣��м����Gradient��Jacobi�ĵ��ʣ�ÿ���ȼ��Ŀ����߶����б�ţ��ұ��Ψһ�����������μ������ǻ����֤����ô���ǻ������֤�ı�š����������Ĵ�����Ψһ�ģ�������Ų�ͬ��GitHub�˺Ż����������˺�����ĸ��˱�ʶ������˺Ŵ������������ı�ʶ�����ǰ�����Ƴ���֮����Ŀ�����Ը���������߽����ǵ�����������Ϊ�˵õ���������֤��ţ�����������һ�ֹ����кʹ��ڸС���KOL��Ӫ��飬��Bվ�������˿�����KOL��������ʦ�����������÷dz��ķ�ʽ����MindSpore��������ʲô��
ֱ�������ʵ�dz����������Ҳ����������ֱ�����������ʵҲ�������ֵģ����ǻ��ڶ�����Bվ����ֱ����Bվ�ϵıȽϳ��棬�����������ݣ��Ǵ�����ʽ��ֱ�������������������ʱ�̹�ע��Ļȥ������һ�㶼���Ƚ������ٿ�����û�е�Ļ������ȥ�ش𡣶���ֱ�������������������Ҫ��PKģʽ������ڿ�������˵�����Ƿdz��¡����ҳ���ʽ�Ļ������ҿ�������MindSpore����ר�ҹ�ͬ���ļ������Ե�������ô�����ġ�����������������Щ���⣬���ÿ����߶�������������и���̵���Ȥ�����⡣�����Ҽ���ר����ֱ�����⣬����ͬ��Ҳ�����뿪������ֱ�����������е����㿪���߶���Ҫ�ڶ�������ֱ���Ĵ�磬ȥ����������MindSpore�Ĺ��¡�ͬ����MSG��֯��Ҳ��Ҫ������磬�����ΪMSG��֯����Ҫ����Щ���ݡ�����Щ����ȣ���������ֱ�����Ƕ��ṫ������Bվ���档
�γ���飬21�켯ѵӪ��������м������ߵ�Ȥζ�Կγ̡��ܶ�γ̣��������ѧϰ�γ̣���һ�ÿδ��������д����ʶ�𣬶��ںܶ������˵���С�����ƣ�͡��������ҪѧϰMindSpore����һ��Ҳ��Ҫѧ��д����ʶ�𣬾ͻ���ú�û�������ǵ�ʱ�����һ���ܲ�����һ�ֱȽ��µĿγ�ʵ������ʱ���и����ѣ�һ�����ϵ�С������ʳ�˶�Ģ���������˻þ����������Ǿ��룬�ܲ��ܹ���MindSporeȥ����Ģ��ʶ�𣬰↑�������ճ������е����Ǽ��Ģ��������û�ж����������Ͼ��з���ģ�ͣ�����Ģ�������ݼ���ȥ���˰�����û�뵽���컹ͦ�ã�������������֮����ø��ָ�����Ģ��ͼƬ��������������������Ģ��ȥ���ԡ���dz��ܹ����������߶��ڿ�ܼ�����������ϵ����������ռ�ѵӪ����ȥ�꿪ʼ������ÿ������ĩ����һ�ε����������°汾���°汾�����µ����ԡ����˸ոս������ü�����Ƶ��Ȧ������˽����������⣬Ȧ�ڵ��˻��߸�ϣ��֪����Щ�����ܲ��ܹ�������ʵ���������̵��С����������������ռ�ѵӪ��ר������Щ�����з��ļ���ר���������Ե�������ʲô���ݣ���һЩ����ֱ���ĸɻ�������
������MindCon �����ܡ�MindCon ��������ȥ������Ļ����ɱ��dz��ͣ�����û�л�ʲô�ɱ���������Ч���dz��á�������������ջ�����1�����D0�������߲��빱�ף�������20����bugfix��������ô�����أ���ʱ���Ǵ�����һ����֯MSG��MSG��MindSpore Study Group�ļ�ƣ���MindSporeѧϰС�飬����ȥ�������������Ե���֯���ڸ������У������Ϻ��������������Լ����ݡ����ݡ����ȶ�������ôһЩ�����͵���֯�������г�����֯��������ƴ���ĸ����е��˽����bugԽ�࣬���־ͻ�Խ�ߡ����õ�������ߵģ����ǻ���һ�����ʼ�������Ȼ�������࣬���ǻ�dz����������ߵ���Ȥ���������������bugfix��ʱ�������Ѿ�����bugfix�����뿪Դ�Ĺ��̸�����ס�ˣ������ǽ���˵Ϊ�˵õ���������Ųμӻ�����Լ�ʹû�л�õ�һ����Ҳ���뵽��Դ�������ˣ���0��Ϊ��Դת���Ĺ����ߡ�
�ո��ᵽ��һ���ʣ�MSG����ʵ��ҿ���TensorFlow��PyTorch�����и��Ե���������֯��TensorFlow����֯��TFUG��������ȫ�������Լ��ij��л���֯��MSG���Ǹ�����ͬ��������֯һЩ���»��ȥ��������Ҫ�����������͵���֯�����ʱ������һЩ��У�͵ģ��������ǰ�����Ϊϵͳ��������һ�£����������͡���У�ͺ���ҵ�͡���ȥ�����·ݵ����ڣ�����һ���ʱ�䣬���ǹ�������13�����У����������߸����У���Ȼ���ⶼ�����ϵģ��������峡У�У����������ҵ��һ�����ԣ��������ϰ�������Դ�������ʱ���Julia������Graviti��һЩ������˾������һ��������ҵMSG��ȥ�˽����ǹ�˾������������Դ�ij�����˾����������Щ��������߿����ṩ�ġ���ҵ�ж�Ͷ�ʷ���˵�Ƿdz�������ģ���Ϊ�����ڵ��п��Է���һЩ����ij�����Դ��ҵ������������˵Ҳ���а����������˽�����г��϶��ڿ�Դ������������ô���ĺ��������Ӷ�ָ�����ǵĹ��������õ�ȥ����������ڲ������ҵ��˵������Ҳ����ѧϰ������Ŀ�Դ��������Ӧ����ôȥ����������һ��������Ӯ��һ���¶���δ�����ǻ�����������̽�������°����Χ�ƕN�ڴ������ģ��������������ҵ�л������ҵ�ṩ���������ܣ�������չ��
�ڼ���������飬��������ѧ���������ߡ������У���в�ͬ�Ļ��������˵������ѧ���ı���������2021��Դ������Ӧ�������ƻ����ô�Ҳ���������һЩ�����������������һЩTinyMSģ����������ʱ��������ʱ��TinyMS 0.1�汾��3��31�ŷ����ģ����Ƿ������ĸ�ģ�ͣ��ô��ȥ���֡��������������Ŀ������ģ�ͣ��ܲ�����TinyMS��ȥ����һ�¡����֪����һ���ύ���ֵ��Ƕ���ʱ����17Сʱ�ھ��п�������TinyMS�����˵�һ��ģ�͵ĸ��֡��dz�����;�ϲ�������ڣ����Ƿ�����һ����֮���ĸ�ģ�Ͷ��Ѿ��ύ����ˡ����DZ������õ��������£������ߵĻ����ԺͶ��ڲ�Ʒ���Ͽɶ��Ѿ�Զ�����ǵ�ʱ��Ԥ�ڡ�
��Ⱥ��Ӫ���Ͳ�ϸ˵�ˣ����ǰ���QQȺ����Ⱥ��SlackȺ��������Ⱥ����Ŀǰ�Ѿ��ﵽ��2��+���ܶ�Ⱥ�տ�ʼ��ʱ��Ƚϻ��ȣ�������һ��ʱ������˻��ߴ�Ҳ�˵���ˣ�����ʵ�Ǻ�������ġ������Ҳ�˵�������ǻ�����ض�һЩ�������⣬����һЩ����Ķ��������������ߵ���Ȥ���ô�ҳ�����Ⱥ����������ۡ������ѻ�Ծ�Ŀ����߷�ɢ�ڸ�����ͬ��Ⱥ������Ͳ���ȫ�������ɹٷ��Ĺ�����Աȥ��Ӫ��
���������ȥ�곢�Ե��µ���Ӫ�������Ȧ�Ļ�����Ӫ������Ȧ�и��µĹ��ܣ�����#�ţ����ϻ��⣬�����ȥ���Կ����������Ȧ������������������Щ����Ȧ�����Ǹ��������ṩMindSpore Lite��apk�����apk��װ�����ֻ���֮�����������ֱ�������գ�ȥ����������ĵ���������ʲô�������������Dz��ˡ�MindSpore��Ц���껪�������ҵ������Ķ���������������ⷢ����Ȧ������ںܶ������˵��û���κ��Ѷȣ�ֻ��Ϊ���ô���ܹ�����ؽӴ�������Ʒ���������ļ���ٶȡ�ȷ�ʡ����������������ջ��˷dz���ĸ�Ц��ͼƬ�������еĿ����߲�������ֻ�ùٷ��ṩ��apk��ɨ�裬�������Լ�����������ѵ����ģ���������ϸ��ֲ�ͬ���˵ȵȡ�
��У��չ
�������Ǹ�У��չ���������Ǻͽ����������������ܻ�������Ŀ��ǩ��72����У������ѧУ�↑�Σ��Լ�MSG��У�еĻ��ѧ�����û�Դ��ϣ��ͬѧ������ѧУ��������ڿ�Դ��������ϰ�ߡ���Ӵ���������Ŀ��������������������
��ҵ���
���һ������ҵ����ҵ�����ںܶԴ������˵��ʵ��̫�����������Ƕ��µĿ�Դ���������Dz�ȡ�IJ������ȴ�ͷ���û�����������PPT��չʾ�ģ�������HTC��4��23�ţ����Ǻ�����ʵ���Һ����������İ��GPT-3ģ�͡����̹Ŵ�ģ�ͣ���Ҳ�ǹ��ڷ��������������GPT-3ģ�͡�����������ʵ���ң�������ʵ������ʵ������������������������ȥ��7��20�����ĵ�һ������MSG����ʱ������ʵ���ҵ�����ʦ���������Ƿ������Ӷ���ѧ�����ݣ�����MindSpore�ķ����������Dz��ǿ�����MindSpore�������ǵ�ѵ����ܣ���Ϊ���Ӷ���ѧģ���зdz���ĸ߽�����Ҫ���㡣���dz�������TensorFlow����ʱ�õ���һ�㼸�İ汾�����ڷֲ�ʽѵ���Լ��߽����ļ���֧�ֵò�������ô�á�������ת��PyTorch�����ֺܺ��ã���������ȴû��TensorFlow�ã��������ͺ�ì�ܡ�������������MindSpore����֮����MindSpore�����ܷ��������㹻���Ƶģ����Ǿ���MindSporeȥ����Ŀǰ��չ˳��������к;������ϴ�����NLP����㷨�������ܿͷ�������ȥӦ�õȵȡ�
��������
����ǿ�Դ���������������Dz�ȡ��̬������ȫ��Դ���ŵ�̬�ȡ�Ŀǰ�ļ���ίԱ��TSC��Ա�������ڸ�����ͬ�ĸ�У������ҵ������ר��ίԱ�����⣬���ǻ���һЩSIG�飬�����ö�ij��ģ��Ƚϸ���Ȥ��ͬѧ���뵽SIG����������һЩ���뿪���Ĺ�����

��ҿ��Կ��������ͼ��Ŀǰ�а���akgͼ���ںϵġ�data���������봦���ģ��Լ�scurity��ȫ�ĵȵȡ���ʵ���кܶ�SIG�顣���ǽ�����Ϻ�����IJ���ʦ������һ���û�����DX-SIG�飬�ռ��û�ʹ�ò�Ʒ������ͽ��飬��ȥ�Ľ���SIG��Ŀ�����ʽ����ҿ��Կ�һ�£��Ͳ�ϸ���ˡ��ύissue֮�����ǻ���committer��������ָ�ɣ�������ɾͿ����ύPRֱ������ջ���
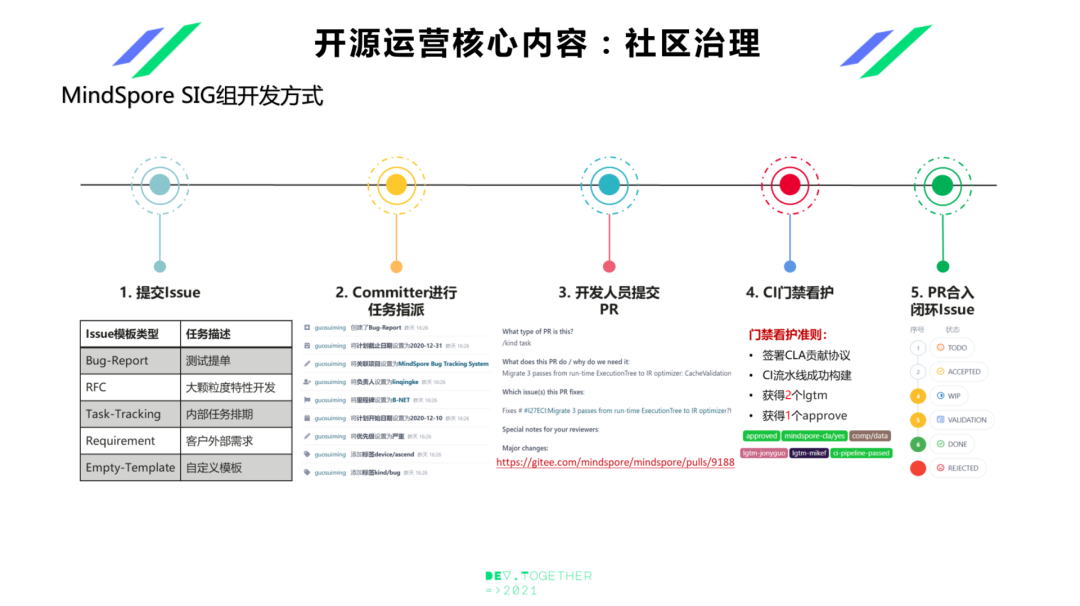
��������������ʩ����CIϵͳ��CI-CLA��������ͬ�������ˡ���ҿ�����Gitee�Ͽ�����Ҳ����ȥGitHub��ȥ���ס�
��������ֻ�����Ӫ���塣�������ܶ࣬����Ŀǰ��star��fork��watch���Լ����ÿ���㼶�Ŀ����ߡ�MindSpore�ĺ���ָ��ı仯���ƣ��Լ�����������ɣ��û������棬��Ŀ�Ľ����ȵȵȣ�������Щ���Ἧ�������ֻ���Ӫ�������档���ֻ���Ӫ������Լ�ʱ�����Ǹ���ÿһ�λ���������棬�����������Լ���ͳ�ƣ�����Ҳ��Ҫ�е�����ƽ̨������ͳ�ƣ������Ļ���˫����֤����֪����Ļ����ʵ�ʴ����������Ƕ��٣��û������º������������ٽ�һ����������Щ������������ȥ��˼���������������������Ӧ�ò�ȡʲô���IJ��Բ��ܸ��óɳ���
��Դ����
��Դ������飬������Apache TVM��CNCF����ᡢLFAI&Data�����Ⱦ��к�����ͬʱ��AIIA��Դ�����ƽ���Ҳ��һЩ����Ŀ�Դ�������ݣ�δ����һһ����Ҽ��档
����ǽ������ҷ�����MindSpore��Դ��Ӫ��������������ݣ�ϣ��δ���и�����˼��뵽��Դ������Ӫ���ƶ���Դ��̬��лл��
��ע����������̬�����ںŻظ���hxm �����ݽ� PPT
������Ķ�ԭ�����ۿ��������ݽ���Ƶ�����¾���ʱ��