�ֿ�ֱ�
һ����˵�����ݿ�ֿ�ֱ���������������
����ϣ��Ƭ������һ�����ݵı�ʶ�����ϣֵ��������䵽�ض������ݿ������У�
����Χ��Ƭ������һ�����ݵı�ʶ��һ����ֵ����������䵽�ض������ݿ������У�
���б���Ƭ������ijЩ�ֶεı�ʶ�����������������䵽�ض������ݿ������С�
�ֿ�ֱ��������кܶ��֣������д����⣬�ڳ�����֧�ֶ����ݿ⣬������Ҫ֪��ÿ�����ݿ�ĵ�ַ����Ҫ��д�������֧�֣�ʹ���м����������ݿ�������������������ֻ��Ҫ֪���м����ַ��
���Ƿֿ�ֱ�����Ϊ���������������ڲ�ͬ�����ݿ�ʵ���У��������������Ӳ�ѯʱ���������ݿ�ʵ��֮��Ľ�����ø�������������Ⱥ�е��������ϴ�ʱ���㲻������ join �ˣ�������Ҫ������ʽ֧�žۺϲ�ѯ��
�ֿ�ֱ����ŵ���ȱ�㣬����Ͳ��ٶ�˵����ѧ���ٴ��㡣
MariaDB Server �ǿ�Դ�ģ�Ŀǰ�����еĹ�ϵ�����ݿ�֮һ��MariaDB �Ǵ� Mysql �ķ�֧����������һֱ���ֶ� Mysql �ļ����ԡ���Ϊ���ĵ��չ���MySQL ���� Oracle ���У����ڱ�Դ�Ŀ��ܣ��Լ�����ҵ������ò����棬���� Mysql֮�������� MariaDB��Ŀ������ȫ���� Mysql�����ҿ�Դ����ѡ�
MariaDB ʹ�� Spider ������зֿ�ֱ���֧�֣�Spider �洢������һ�����÷�Ƭ���ܵĴ洢���档��֧�ַ�����xa ��������������ͬ MariaDB ʵ���ı����ͺ���������ͬһ��ʵ����һ����
��ο����ϣ�https://mariadb.com/kb/en/spider/
����ƪ�����У����߽�ʹ�� MariaDB Spider ���зֿ�ֱ���ʵ����
���� MariaDB ʵ��
Ϊ�˸��õش����ֿ�ֱ�ʵ��������������Ҫ���� �����������ݿ⣬һ�������ݿ⣬���ĸ� MariaDB ʵ����MariaDB ʵ��ռ�õ��ڴ沢������ 4G �ڴ�ķ�����װ�� Kubernetes ���� Docker �����ĸ� MariaDB ���ݿ⣬�����ٶ��������������Dz�����ϰ 4G �ڴ����ԡ�
�ĸ����ݿ�Ĺ�ϵ��ͼ��
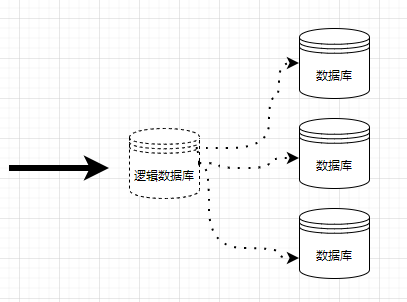
���У������ݿ�ʵ����Ϊ Spider Proxy Node��ʵ�ʴ洢���ݵ����ݿ�ʵ������Ϊ Backend Node��
���͵� Spider ������������ļ�Ⱥ�ܹ�����ϵͳ�������κ����۵�Ӳ�������Ҷ�Ӳ�����������ض�Ҫ����͡�����һ��������ɣ�����һ������ MariaDB ���̣���Ϊ�ڵ㡣
�洢���ݵĽڵ㽫�����ΪBackend Nodes�����ҿ������κ� MariaDB��MySQL��Oracle ������ʵ����ʹ�ú���ڿ��õ��κδ洢���档
Docker ����
�������������ʹ��������������Եú��鷳���������ʹ�� Docker ���ٲ�����ϰ��
�ο����ϣ�https://mariadb.com/kb/en/installing-and-using-mariadb-via-docker/
�鿴 MariaDB ����汾�б���https://hub.docker.com/_/mariadb/
ֱ�Ӵ����ĸ����ݿ�ʵ��������һ���� Spider ʵ����ʵ��ʹ�ö˿����֡�
docker run --name mariadbtest1 -e MYSQL_ROOT_PASSWORD=123456 -p 13306:3306 -d docker.io/library/mariadb:10.7docker run --name mariadbtest2 -e MYSQL_ROOT_PASSWORD=123456 -p 13307:3306 -d docker.io/library/mariadb:10.7docker run --name mariadbtest3 -e MYSQL_ROOT_PASSWORD=123456 -p 13308:3306 -d docker.io/library/mariadb:10.7docker run --name mariadbspider -e MYSQL_ROOT_PASSWORD=123456 -p 13309:3306 -d docker.io/library/mariadb:10.7���ţ�����ÿ������ʵ���У����� /etc/mysql/mariadb.conf.d Ŀ¼����50-server.cnf�ļ�������Զ�̷������ݿ�ʵ��������������û�� nano��vi ��Щ�༭�����˿���ʹ���������������滻�ļ����ݣ�
echo '
[server]
[mysqld]
pid-file = /run/mysqld/mysqld.pid
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp
lc-messages-dir = /usr/share/mysql
lc-messages = en_US
skip-external-locking
bind-address = 0.0.0.0
expire_logs_days = 10
character-set-server = utf8mb4
collation-server = utf8mb4_general_ci
[embedded]
[mariadb]
[mariadb-10.7]
' > 50-server.cnf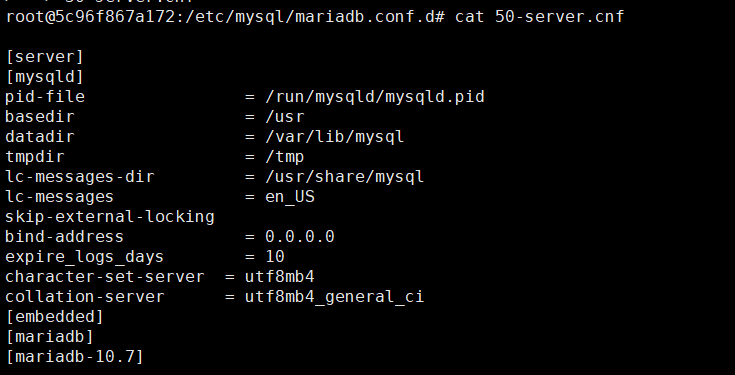
Ȼ��鿴ÿ�������������� IP��
docker inspect --format='{
{.NetworkSettings.IPAddress}}' mariadbtest1 mariadbtest2 mariadbtest3 mariadbspider172.17.0.2
172.17.0.3
172.17.0.4
172.17.0.5���Ŵ���Ϊ mariadbspider �������������水�� Spider �����
apt update
apt install mariadb-plugin-spider���������
������Ҫ�ĸ��������ÿ�����������Ҫ�Ȱ�װ MariaDB ���ݿ������Լ�һЩ���߰���
�ɲο���https://mariadb.com/kb/en/spider-installation/
������ÿ�����ⰲװ MariaDB Community Server�������ݿ����档
���ʹ�����������װ����Ҫ�滻���ھ���Դ���Ա����������Ҫ�İ��� Centos ������������ֱ������������ٸ��¾���Դ������� Debain ϵ�У������в��Ҷ�Ӧ�ľ���Դ��
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
#�������
yum clean all
#�����µĻ���
yum makecache���ţ����� MariaDB �ٷ����������洢�⣺
sudo yum install wget
wget https://downloads.mariadb.com/MariaDB/mariadb_repo_setup
echo "fd3f41eefff54ce144c932100f9e0f9b1d181e0edd86a6f6b8f2a0212100c32c mariadb_repo_setup" | sha256sum -c -
chmod +x mariadb_repo_setup
sudo ./mariadb_repo_setup --mariadb-server-version="mariadb-10.7"�ٴθ��¾���Դ���棺
#�������
yum clean all
#�����µĻ���
yum makecache��װ MariaDB �����������������������
sudo yum install MariaDB-server MariaDB-backup���ţ���������Զ�̷������ݿ⡣
MariaDB �������ļ����� /etc/my.cnf �У��� /etc/my.cnf.d/ Ŀ¼���� server.cnf �ļ�������Զ�̷��ʡ��ҵ� bind-address ���ԣ�ȥ�� # ��
#bind-address=0.0.0.0
��
bind-address=0.0.0.0�����˽�ÿ�����õ����ã���ο����ϣ�https://mariadb.com/docs/deploy/community-spider/#configuration
�����롣��Ϊ�����������ݿ⣬����û�����룬������Ҫ�ֶ����á�
���նˣ�ִ���������
mysql -u root -pset password for root @localhost = password('123456');Ȼ��ִ�� quit; �˳����ݿ�����նˡ�
�����ʾ root �����ڣ�����ʹ��
mysql -u mysql -p������Ϊ�գ�ֱ�Ӱ��»س������ɡ�������У���ο���https://www.whuanle.cn/archives/1385
Ȼ���������ݿ�ʵ����
systemctl restart mariadb
systemctl status mariadb���ż�����ǽ���ã���ִ��
sudo iptables -F��������ǽ���á�
MariaDB ����
MariaDB �����ļ��У�������Ҫ���Ե�˵���������£�
| �ֶ� | ˵�� |
|---|---|
| bind_address | ���ʵ�ַ |
| max_connections | ��������� |
| thread_handling | ���� MariaDB ������������δ����ͻ������ӵ��߳� |
| log_error | ������־����ļ� |
MariaDB ���������
| ˵�� | ���� |
|---|---|
| ���� | sudo systemctl start mariadb |
| ֹͣ | sudo systemctl stop mariadb |
| �������� | sudo systemctl restart mariadb |
| �������ڼ����� | sudo systemctl enable mariadb |
| ����ʱ���� | sudo systemctl disable mariadb |
| ״̬ | sudo systemctl status mariadb |
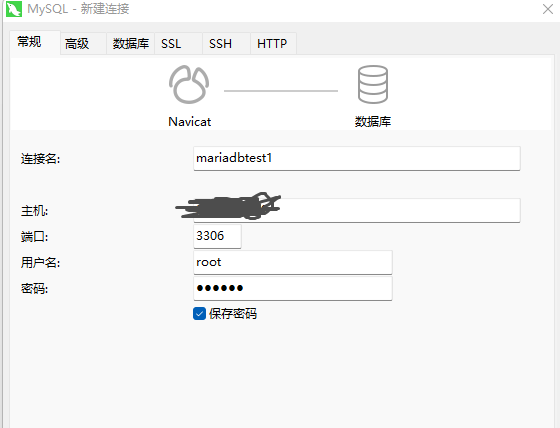
���ÿ��ʵ��
�������ݿ����Ҫ����ÿ�����ݿ���в��ԣ��Ա������ݿ��Ƿ�������
���� Spider
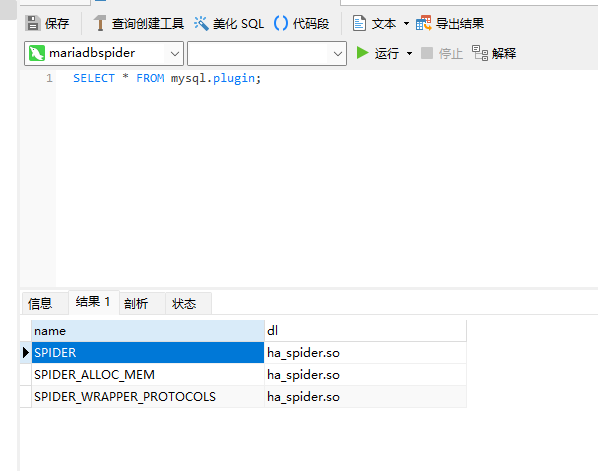
�� mariadbspider ���ݿ�ʵ����ִ������������� spider �������������Ϊ Spider ���ݿ�ʵ����
INSTALL SONAME 'ha_spider';ִ�������ѯ�Ƿ��Ѿ����� Spider �����
SELECT * FROM mysql.plugin;
��ο����ϣ�https://mariadb.com/kb/en/spider-installation/
Զ�̱�
MariaDB Spider ģʽ�Ѿ�����ˣ����↑ʼ����ʵ����
�����ģʽ�У�Spider �е�һ������Ӧһ�����ݿ�ʵ���е�ͬ�����ݿ��ͬ�����������ݿ�����ϵͳ����������ͬ��
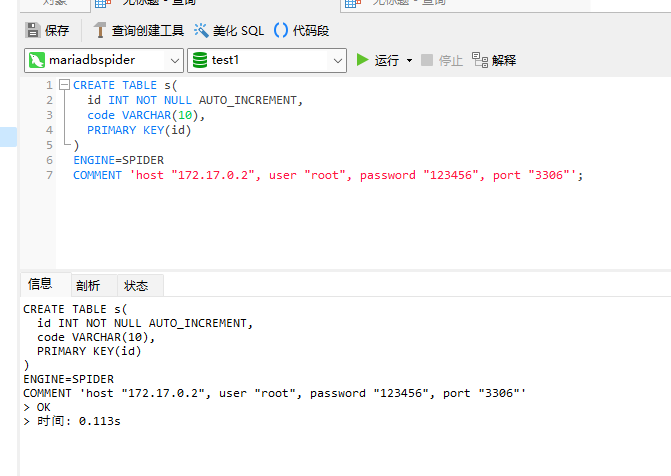
������ �������ݿ�ʵ���У�����һ���������ݿ⣬����Ϊ test1 ��Ȼ��ִ�����������
CREATE TABLE s(id INT NOT NULL AUTO_INCREMENT,code VARCHAR(10),PRIMARY KEY(id));Ȼ���� mariadbspider ʵ���У�ִ�������������������������� mariadbtest1 ʵ���С�
CREATE TABLE s(id INT NOT NULL AUTO_INCREMENT,code VARCHAR(10),PRIMARY KEY(id)
)
ENGINE=SPIDER
COMMENT 'host "172.17.0.2", user "root", password "123456", port "3306"';ע���滻��� IP������ע��˿ڣ��������������������ֱ��ʹ�� 3306��
���û�����úã����ݿⲻ��Ӧ�ȣ����ܻ���֣�
> 1046 - No database selected > ʱ��: 0.062s
Ȼ���� mariadbspider �У������������ݣ�
INSERT INTO s(code) VALUES ('a');
INSERT INTO s(code) VALUES ('b');
INSERT INTO s(code) VALUES ('c');
INSERT INTO s(code) VALUES ('d');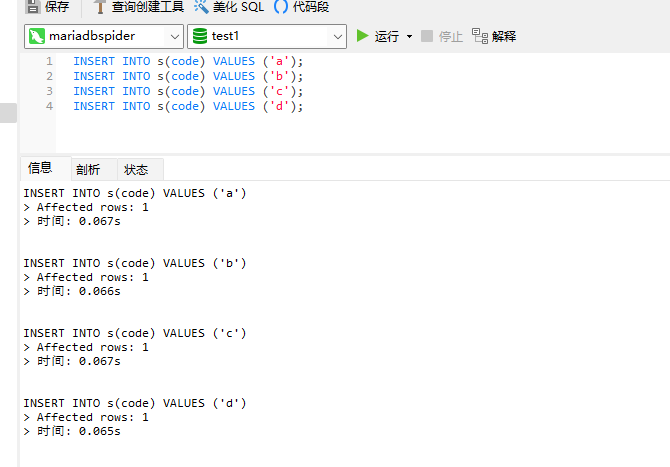
����ֱ������ʵ������ᷢ�֣����������ֻ������� mariadbtest1 �г��֣���Ϊ�����ֻ���������㻹������ mariadbspider �϶������������ɾ��ģ����в�������ͬ������Ӧ���ݿ�ʵ���С�
�����ܲ���
SysBench ��һ��ģ�黯����ƽ̨�Ͷ��̵߳Ļ����Թ��ߣ�֧�� Windows �� Linux���������������ڸ߸������������ݿ��ϵͳ�dz���Ҫ�IJ���ϵͳ��������������������뷨�ǣ��ڲ����ø��ӵ����ݿ����������������װ���ݿ������£����ٻ��ϵͳ���ܵ�ӡ�������Բ��Գ���
�ļ� i/o ����
����������
�ڴ����ʹ����ٶ�
POSIX �߳�ʵ������
���ݿ����������(OLTP ��)
��Ŀ��ַ��https://github.com/akopytov/sysbench
Linux ����ֱ�Ӱ�װ�����ư���
Debian/Ubuntu
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.deb.sh | sudo bash sudo apt -y install sysbenchRHEL/CentOS:
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash sudo yum -y install sysbenchFedora:
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bash sudo dnf -y install sysbenchArch Linux:
sudo pacman -Suy sysbench
sysbench �����ʽ��
sysbench <TYPE> --threads=2 --report-interval=3 --histogram --time=50 --db-driver=mysql --mysql-host=<HOST> --mysql-db=<SCHEMA> --mysql-user=<USER> --mysql-password=<PASSWORD> run���ȣ��ڵ�ǰ�ض����ݿ��´���ģ�����ݣ�
sysbench oltp_read_write --db-driver=mysql --mysql-user=root --mysql-password=123456 --mysql-host=123.123.123.123 --mysql-port=13309 --mysql-db=test1 preparesysbench 1.0.18 (using system LuaJIT 2.1.0-beta3)Creating table 'sbtest1'...
Inserting 10000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'...�������в��ԣ�
sysbench oltp_read_write --db-driver=mysql --mysql-user=root --mysql-password=123456 --mysql-host=123.123.123.123 --mysql-port=13309 --mysql-db=test1 runSQL statistics:queries performed:read: 112write: 32other: 16total: 160transactions: 8 (0.80 per sec.)queries: 160 (15.96 per sec.)ignored errors: 0 (0.00 per sec.)reconnects: 0 (0.00 per sec.)General statistics:total time: 10.0273stotal number of events: 8Latency (ms):min: 1244.02avg: 1253.36max: 1267.8795th percentile: 1258.08sum: 10026.85Threads fairness:events (avg/stddev): 8.0000/0.00execution time (avg/stddev): 10.0269/0.00����ÿ 3 ������һ��ֱ��ͼ��
sysbench oltp_read_write --threads=2 --report-interval=3 --histogram --time=50 --table-size=1000000 --db-driver=mysql --mysql-user=root --mysql-password=123456 --mysql-host=123.123.123.123 --mysql-port=13309 --mysql-db=test1 run
����ģ�����ɵ����ݣ�
sysbench oltp_read_write --db-driver=mysql --mysql-user=root --mysql-password=123456 --mysql-host=123.123.123.123 --mysql-port=13309 --mysql-db=test1 cleanupsysbench �ܲ���ʱ����ѡ�������£�
ʹ��
�Ctime=<SECONDS>���й̶�ʱ��ʹ��
�Cevents=0��ִ�еIJ�ѯ����������ʹ��
�Cdb-ps-mode=disable�������õ����ʹ��
�Creport-interval=<SECONDS>��ȡ��ͼ����
--histogram�õ�һ��ֱ��ͼ
sysbench ���������̻�ִ��ģʽ��
prepare��Ϊ��Ҫ���ǵIJ���ִ���������������ڴ�����Ϊfileio���Դ�����Ҫ���ļ��������������ݿ��Խ������ݿ�����ԡ�run������ʹ��testname ����ָ����ʵ�ʲ��ԡ������������в����ṩ��cleanup���ڴ���һ���IJ����в������к�ɾ����ʱ���ݡ�
��Ҳ���Բο����ߵ���һƪ���£�ʹ�ñ�ķ����������ԣ�https://www.whuanle.cn/archives/1388
���������ݿ�
��Զ�̱�һ���У��������ڴ�������ʱ���ٰ�һ�����ݿ�ʵ������ʵҲ������ǰ���ö�����ݿ�ʵ���� Spider �У��������� Spider ��ִ�е��������
CREATE SERVER mariadbtest1 FOREIGN DATA WRAPPER mysql
OPTIONS( HOST '172.17.0.2', DATABASE 'test1',USER 'root',PASSWORD '123456',PORT 3306
);CREATE SERVER mariadbtest2 FOREIGN DATA WRAPPER mysql
OPTIONS( HOST '172.17.0.3', DATABASE 'test1',USER 'root',PASSWORD '123456',PORT 3306
);CREATE SERVER mariadbtest3 FOREIGN DATA WRAPPER mysql
OPTIONS( HOST '172.17.0.4', DATABASE 'test1',USER 'root',PASSWORD '123456',PORT 3306
);��ϣ��Ƭ
����һС���У����ǽ�һ�������з�Ƭ���ڲ�������ʱ�������Զ���Ƭ���������ݿ�ʵ���С�
���������ݽڵ����ݿ��У��� test1 ���ݿ��£�ִ�������������
CREATE TABLE shardtest
(id int(10) unsigned NOT NULL AUTO_INCREMENT,k int(10) unsigned NOT NULL DEFAULT '0',c char(120) NOT NULL DEFAULT '',pad char(60) NOT NULL DEFAULT '',PRIMARY KEY (id),KEY k (k)
)��ʱ���������ݿ�ʵ����������ͬ�ı���
Ȼ���� mariadbspider ʵ���У�ִ��������������������˱�ͨ����Ƭ��ģʽ�����ӵ��������ݿ�ʵ���С�
CREATE TABLE test1.shardtest
(id int(10) unsigned NOT NULL AUTO_INCREMENT,k int(10) unsigned NOT NULL DEFAULT '0',c char(120) NOT NULL DEFAULT '',pad char(60) NOT NULL DEFAULT '',PRIMARY KEY (id),KEY k (k)
) ENGINE=spider COMMENT='wrapper "mysql", table "shardtest"'PARTITION BY KEY (id)
(PARTITION pt1 COMMENT = 'srv "mariadbtest1"',PARTITION pt2 COMMENT = 'srv "mariadbtest2"',PARTITION pt3 COMMENT = 'srv "mariadbtest3"'
) ;
Ȼ��� https://github.com/whuanle/write_share_database���ҵ� ��Ƭ��������.sql ����ļ��������кܶ�ģ�����ݡ�
����Թ۲쵽���������ݿ�ʵ���������Dz�ͬ�ġ�
����ֵ��Χ��Ƭ
��Ƭ��ʽ��ѡ������ PARTITION BY ���ԣ������ϣ��Ƭ�Ǹ���һ�������м���ģ�����������Ϊ PARTITION BY KEY (id)������Ǹ���ֵ��Χ��Ƭ������ PARTITION BY range columns (<�ֶ�����>)��
) ENGINE=spider COMMENT='wrapper "mysql", table "shardtest"'PARTITION BY range columns (k)
(PARTITION pt1 values less than (5000) COMMENT = 'srv "mariadbtest1"',PARTITION pt2 values less than (5100) COMMENT = 'srv "mariadbtest2"'PARTITION pt3 values less than (5200) COMMENT = 'srv "mariadbtest3"'
) ;�����б���Ƭ
�����б���Ƭ��һ����ij���ֶΣ����Խ����ݻ���Ϊ��ͬ���ͣ����Ը�������ֶε����ݶ����ݽ��з��顣
) ENGINE=spider COMMENT='wrapper "mysql", table "shardtest"'PARTITION BY list columns (k)
(PARTITION pt1 values in ('4900', '4901', '4902') COMMENT = 'srv "mariadbtest1"',PARTITION pt2 values in ('5000', '5100') COMMENT = 'srv "mariadbtest2"'PARTITION pt3 values in ('5200', '5300') COMMENT = 'srv "mariadbtest3"'
) ;�����ݵ� k �ֶΣ�ֵ�� 4900 ��4901 �� 4902 ʱ��������Ƭ�� mariadbtest1 ʵ���С�