我们知道卷积神经网络(CNN)在图像领域的应用已经非常广泛了,一般一个CNN网络主要包含卷积层,池化层(pooling),全连接层,损失层等。虽然现在已经开源了很多深度学习框架(比如MxNet,Caffe等),训练一个模型变得非常简单,但是你对这些层具体是怎么实现的了解吗?你对softmax,softmax loss,cross entropy了解吗?相信很多人不一定清楚。虽然网上的资料很多,但是质量参差不齐,常常看得眼花缭乱。为了让大家少走弯路,特地整理了下这些知识点的来龙去脉,希望不仅帮助自己巩固知识,也能帮到他人理解这些内容。
这一篇主要介绍全连接层和损失层的内容,算是网络里面比较基础的一块内容。先理清下从全连接层到损失层之间的计算。来看下面这张图,来自参考资料1(自己实在懒得画图了)。
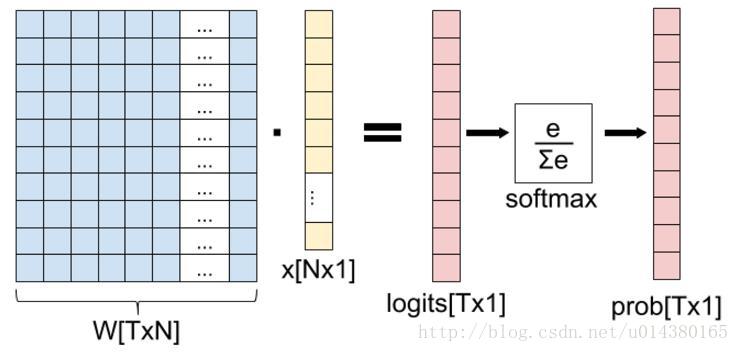
这张图的等号左边部分就是全连接层做的事,W是全连接层的参数,我们也称为权值,X是全连接层的输入,也就是特征。从图上可以看出特征X是N*1的向量,这是怎么得到的呢?这个特征就是由全连接层前面多个卷积层和池化层处理后得到的,假设全连接层前面连接的是一个卷积层,这个卷积层的输出是100个特征(也就是我们常说的feature map的channel为100),每个特征的大小是4*4,那么在将这些特征输入给全连接层之前会将这些特征flat成N*1的向量(这个时候N就是100*4*4=1600)。解释完X,再来看W,W是全连接层的参数,是个T*N的矩阵,这个N和X的N对应,T表示类别数,比如你是7分类,那么T就是7。我们所说的训练一个网络,对于全连接层而言就是寻找最合适的W矩阵。因此全连接层就是执行WX得到一个T*1的向量(也就是图中的logits[T*1]),这个向量里面的每个数都没有大小限制的,也就是从负无穷大到正无穷大。然后如果你是多分类问题,一般会在全连接层后面接一个softmax层,这个softmax的输入是T*1的向量,输出也是T*1的向量(也就是图中的prob[T*1],这个向量的每个值表示这个样本属于每个类的概率),只不过输出的向量的每个值的大小范围为0到1。
现在你知道softmax的输出向量是什么意思了,就是概率,该样本属于各个类的概率!
那么softmax执行了什么操作可以得到0到1的概率呢?先来看看softmax的公式(以前自己看这些内容时候对公式也很反感,不过静下心来看就好了):
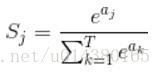
公式非常简单,前面说过softmax的输入是WX,假设模型的输入样本是I,讨论一个3分类问题(类别用1,2,3表示),样本I的真实类别是2,那么这个样本I经过网络所有层到达softmax层之前就得到了WX,也就是说WX是一个3*1的向量,那么上面公式中的aj就表示这个3*1的向量中的第j个值(最后会得到S1,S2,S3);而分母中的ak则表示3*1的向量中的3个值,所以会有个求和符号(这里求和是k从1到T,T和上面图中的T是对应相等的,也就是类别数的意思,j的范围也是1到T)。因为e^x恒大于0,所以分子永远是正数,分母又是多个正数的和,所以分母也肯定是正数,因此Sj是正数,而且范围是(0,1)。如果现在不是在训练模型,而是在测试模型,那么当一个样本经过softmax层并输出一个T*1的向量时,就会取这个向量中值最大的那个数的index作为这个样本的预测标签。
因此我们训练全连接层的W的目标就是使得其输出的WX在经过softmax层计算后其对应于真实标签的预测概率要最高。
举个例子:假设你的WX=[1,2,3],那么经过softmax层后就会得到[0.09,0.24,0.67],这三个数字表示这个样本属于第1,2,3类的概率分别是0.09,0.24,0.67。
———————————–华丽的分割线——————————————
弄懂了softmax,就要来说说softmax loss了。
那softmax loss是什么意思呢?如下:
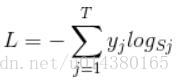
首先L是损失。Sj是softmax的输出向量S的第j个值,前面已经介绍过了,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。那么哪个位置的值是1呢?答案是真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
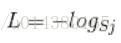
当然此时要限定j是指向当前样本的真实标签。
来举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。我们知道log函数在输入小于1的时候是个负数,而且log函数是递增函数,所以-log(0.6) < -log(0.3) < -log(0.1)。简单讲就是你预测错比预测对的损失要大,预测错得离谱比预测错得轻微的损失要大。
———————————–华丽的分割线———————————–
理清了softmax loss,就可以来看看cross entropy了。
corss entropy是交叉熵的意思,它的公式如下:
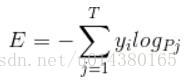
是不是觉得和softmax loss的公式很像。当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss。Pj是输入的概率向量P的第j个值,所以如果你的概率是通过softmax公式得到的,那么cross entropy就是softmax loss。这是我自己的理解,如果有误请纠正。
下一篇将介绍 卷积神经网络系列之softmax loss对输入的求导推导
参考资料1:http://eli.thegreenplace.net/2016/the-softmax-function-and-its-derivative/