在用sklearn的时候经常用到feature_importances_ 来做特征筛选,那这个属性到底是啥呢。
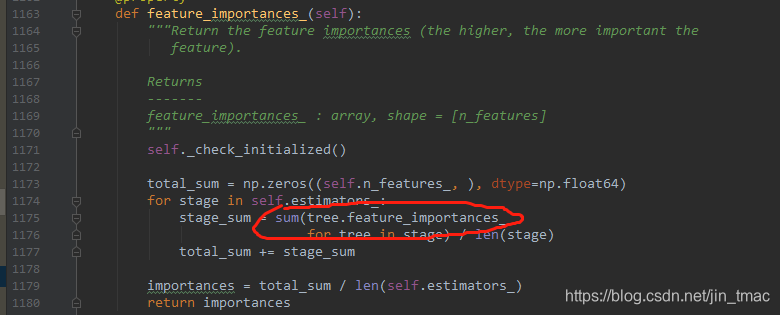
分析gbdt的源码发现来源于每个base_estimator的决策树的
feature_importances_
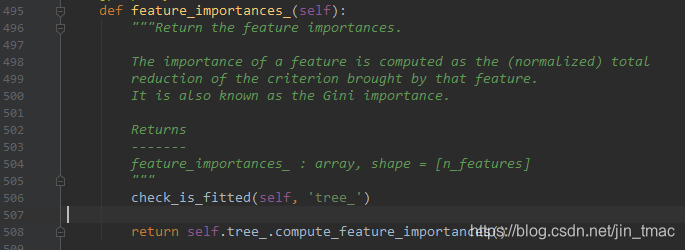


由此发现计算逻辑来源于cython文件,这个文件可以在其github上查看源代码

而在DecisionTreeRegressor和DecisionTreeClassifier的对feature_importances_定义中

到此决策树的feature_importances_就很清楚了:impurity就是gini值,weighted_n_node_samples 就是各个节点的加权样本数,最后除以根节点nodes[0].weighted_n_node_samples的总样本数。
下面以一个简单的例子来验证下:
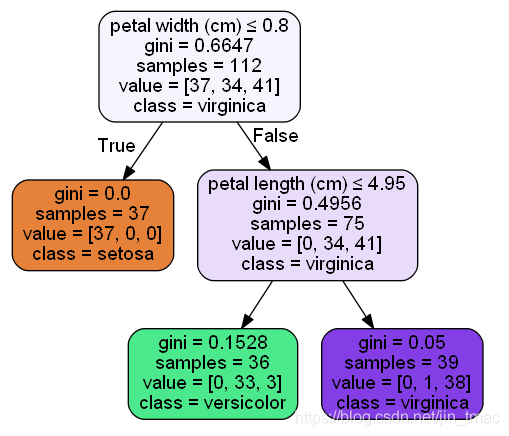
上面是决策树跑出来的结果,来看petal width (cm)就是根节点,
featureimportance=(112?0.6647?75?0.4956?37?0)/112=0.5564007189feature_importance=(112*0.6647-75*0.4956-37*0)/112=0.5564007189feature
i
?
mportance=(112?0.6647?75?0.4956?37?0)/112=0.5564007189,
petal length (cm)的
featureimportance=(75?0.4956?39?0.05?36?0.1528)/112=0.4435992811feature_importance=(75*0.4956-39*0.05-36*0.1528)/112=0.4435992811feature
i
?
mportance=(75?0.4956?39?0.05?36?0.1528)/112=0.4435992811
忽略图上gini计算的小数位数,计算结果相同。