1、前言
上篇我们已经完成以下功能 :
(1) 语音录入的垃圾与垃圾列表对比;
(2) 语音唤醒及语音合成;
本篇主要完成以下内容:
(1)网络微数据中垃圾分类信息获取;
(2)语音录入准确性优化;
(3)彩蛋编写。
2、网络微数据库及应用
(1)注册用户及密码
我们用的网络微数据库地址为:http://tinywebdb.appinventor.space/,
进去之后,我们可以注册自己的用户名及密码。当然,我们也可以共用的帐号及密码。

登陆后可以进入以下页面:

其中,红色方块就是我们网络微数据要用的地址,而红圈是web调用的,比前者要复杂多了。不过学后用Web调用,以后会很有用的。想了解请Web调用方法,见:
https://blog.csdn.net/crxis/article/details/79314158
在这里,我们只谈怎么用网络微数据的扩展。
我们只要把上述红框内内容复制粘贴到下图中方框中就可以了。

3、网络数据库设置。
我们可以用App inventor 对数据库进行录入操作。但为了保证数据不容被修改,我建议还是在数据库端录入。而app只管调用。
点击下图的数据浏览:

我们在这里录入垃圾分类及信息:(信息由度娘整理,仅用于学习)

大家也可以在下面的text文档中增加和修改,然后再贴到对应的数据标签中。
4、网络数据库获取。
在程序初始化时 ,就向服务器取出相应的数据出来,

然后在把数据装到相应的变量中,然后分折在各个垃圾列表中:

OK,主要程序已经完成了,现在来测试吧。
5、提高识别率
语音短语录入,有时真的不准确。所以 当然我们可以用别方法来提高识别率。不过百度自然语其实还是很强的,如果我们是一个短句,那识别率会提高很多。
我们设定对话的方式为:XXX是什么垃圾。
然后在语音结果中,过滤掉“是什么垃圾”这几个字,识别率就会大大提升了。程序方块如下:
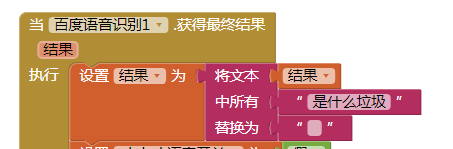
此外,我们增加一个手动输入方式,当语音无法识别时,用它来代替。同时,我们需要把对比的过程变成一个函数,可在语音询问或是输入后调用。界面和程序块变成了以下内容:



6、小小彩蛋
据说上海人民常常被大妈们对灵魂进行拷问,“你是什么垃圾…" @.@
在这里加个小小的彩蛋吧,让机器人更有灵气一点。
至于是什么,大家都能看得懂。
放在那里合适?试一下?
对于学生来说,会增加一些乐趣。记住,在界面设计中新拉入一个百度语音合成,这样就不用增加什么变量了。

好了,这两篇其实有点娱乐性质,小伙伴可以玩玩。孩子们可以自己试试,而家长们,则可以与自己的孩子一起玩玩。
全篇完!谢谢阅读!