������������ģʽ
��ʵ�ʵ��������������У��������������³�����ij��ģ�鸺��������ݣ���Щ��������һ��ģ�������������˴���ģ���ǹ���ģ��������ࡢ�������̡߳����̵ȣ����������ݵ�ģ�飬������س�Ϊ�����ߣ����������ݵ�ģ�飬�ͳ�Ϊ�����ߡ�
������ڻ���ģʽ��������Բο� ����ѧϰ���߳�-06-Producer Consumer ģʽ
����������
��������������ߺ������ߣ����������������ߣ�������ģʽ����ģʽ����Ҫ��һ�����������������ߺ�������֮�䣬��Ϊһ���н顣�����߰����ݷ��뻺�������������ߴӻ�����ȡ�����ݡ�
����
Ϊ�˲�����̫�������Ǿ�һ�����ŵ����ӣ���˵����ͷ�����Ѿ���ʱ�ˣ���������ӻ��DZȽ����еģ���������Ҫ��һ��ƽ�ţ����¹������£�
1�������д�á����൱����������������
2������ŷ�����Ͳ�����൱�������߰����ݷ��뻺����
3���ʵ�Ա���Ŵ���Ͳȡ�������൱�������߰�����ȡ��������
4���ʵ�Ա������ȥ�ʾ�����Ӧ�Ĵ��������൱�������ߴ�������
�ŵ�
������ͬѧ�����ˣ������������ʲô����Ϊʲô����������ֱ�ӵ��������ߵ�ij��������ֱ�Ӱ����ݴ��ݹ�ȥ�������ôһ��������������
����
���������ߺ������߷ֱ��������ࡣ�����������ֱ�ӵ��������ߵ�ij����������ô�����߶��������߾ͻ����������Ҳ������ϣ���������������ߵĴ��뷢���仯�����ܻ�Ӱ�쵽�����ߡ���������߶�������ij��������������֮�䲻ֱ�����������Ҳ����Ӧ�����ˡ�
�������������ӣ������ʹ����Ͳ��Ҳ���ǻ��������������ð���ֱ�ӽ����ʵ�Ա��
��ͬѧ��˵��ֱ�Ӹ��ʵ�Ա����ͦ���
��ʵ������������ʶ˭���ʵ�Ա�����ܰ��Ÿ�������ƾ���ϴ����Ʒ�����һ���˼�ð���Ͳ��ˣ�����Ͳ���������ʵ�Ա֮����������൱�������ߺ������ߵ�ǿ��ϣ�����һ�����ʵ�Ա�����ˣ��㻹Ҫ������ʶһ�£��൱�������߱仯�����������ߴ��룩������Ͳ�����˵�ȽϹ̶������������ijɱ��ͱȽϵͣ��൱�ںͻ�����֮�������ϣ���
֧�ֲ�����concurrency��
������ֱ�ӵ��������ߵ�ij��������������һ���ˡ����ں���������ͬ���ģ����߽������ģ����������ߵķ���û�з���֮ǰ��������ֻ��һֱ�����DZߡ���һ�����ߴ������ݺ����������߾ͻ�װ���̣���ʱ�⡣
ʹ���������ߣ�������ģʽ֮�������ߺ������߿��������������IJ������壨�������������н��̺��߳����֣���������ӻὲ���ֲ��������µ�Ӧ�ã��������߰����������������������һ�����Ϳ�����ȥ������һ�����ݡ������ϲ������������ߵĴ����ٶȡ�
��ʵ�������ģʽ����Ҫ��������������������ġ�
�Ӽ��ŵ��������������û����Ͳ�����������ɵվ��·�ڵ��ʵ�Ա�����գ��൱�����������������ֻ����ʵ�Ա�ð��Ұ����ʣ�˭Ҫ���ţ��൱����������ѯ�������������ַ�������ͦ���ġ�
�������
������������һ���ô�������������ݵ��ٶ�ʱ��ʱ�����������ĺô������ֳ����ˡ�������������ʱ��������������������δ���������ݿ�����ʱ���ڻ������С��������ߵ������ٶ�����������������������������
Ϊ�˳�ָ��ã��������ü��ŵ�������˵�¡������ʵ�Աһ��ֻ�ܴ���1000���š���һij���������˽ڣ�Ҳ������ʥ���ڣ��ͺؿ�����Ҫ�ij�ȥ���ų���1000�⣬��ʱ����Ͳ����������������ó��ˡ��ʵ�Ա�����������ߵ����ݴ�����Ͳ�У����´ι���ʱ�����ߡ�
������ô���ˮ��ϣ��ԭ�Ȳ�̫�˽������ߣ�������ģʽ��ͬѧ�ܹ�����������ôһ���¡�
������˵˵���ݵ�Ԫ��
���ݵ�Ԫ
�����֮��ÿ�������߷ŵ��������ģ�����һ�����ݵ�Ԫ��ÿ�������ߴӻ�����ȡ���ģ�Ҳ��һ�����ݵ�Ԫ������ǰһ�������м��ŵ����ӣ����ǿ���ÿһ�ⵥ�����ż�������һ�����ݵ�Ԫ��
��������ô���ܣ�̫���ڼ������ڴ���������������������ԣ�������������һ�����ݵ�Ԫ��Ҫ�߱���Щ���ԡ���������Щ����֮�����״Ӹ��ӵ�ҵ�����з������ʺ������ݵ�Ԫ�Ķ����ˡ�
���ݵ�Ԫ������
���ݵ�Ԫ����Ҫ�������¼�����������ԣ�
������ҵ�����
���ȣ����ݵ�Ԫ���������ij��ҵ������ڿ��Ǹ������ʱ�������������ǰ��������ߣ�������ģʽ����Ӧ��ҵ���������ܹ��������ʵ��жϡ�
���ڡ����š����ҵ�����Ƚϼ����Դ��������Ϳ����жϳ����ݵ�Ԫ��ɶ������ʵ�����У�����û��ô�ֹۡ������ҵ�������Ƚϸ��ӣ����а�����ҵ������Dz�η��ࡢ�����졣����������£��Ͳ������������ˡ�
��һ������Ҫ�����ѡ����ҵ����ᵼ�º���������ƺͱ���ʵ�ֵĸ��Ӷȴ�Ϊ�����������˿�����ά���ɱ���
������
��ν�����ԣ������ڴ�������У�Ҫ��֤�����ݵ�Ԫ��������Ҫô�������ݵ�Ԫ�����ݵ������ߣ�Ҫô��ȫû�д��ݵ������ߡ����������ֲ��ִ��ݵ����Ρ�
���ڼ�����˵���㲻�ܰѰ���ŷ�����Ͳ��ͬ���ģ��ʵ�Ա����Ͳ�����ţ�Ҳ����ֻ�ó��ŵ�һ���֡�
������
��ν�����ԣ����Ǹ������ݵ�Ԫ֮��û�л���������ij�����ݵ�Ԫ����ʧ�ܲ�Ӧ��Ӱ���Ѿ���ɴ���ĵ�Ԫ��Ҳ��Ӧ��Ӱ����δ����ĵ�Ԫ��
Ϊɶ����ִ���ʧ����
���������ߵ������ٶ���һ��ʱ����һֱ���������ߵĴ����ٶȣ��Ǿͻᵼ�»����������������ﵽ���ޣ�֮������ݵ�Ԫ�ͻᱻ������������ݵ�Ԫ��������ȵ������ߵ��ٶȽ�����֮���������ݵ�Ԫ���������������ܵ�ǣ������֮��������ݵ�Ԫ֮����ij����ϣ����±����������ݵ�Ԫ��Ӱ�쵽����������Ԫ�Ĵ������Ǿͻ�ʹ��������÷dz����ӡ�
���ڼ�����˵��ij����Ū���ˣ�����Ӱ������ż����ʹ��Ȼ������Ӱ���Ѿ��ʹ���ż���
������
ǰ���ᵽ�����ݵ�Ԫ��Ҫ������ij��ҵ�������ô���ݵ�Ԫ��ҵ������Ƿ�Ҫһһ��Ӧ�ܶೡ��ȷʵ��һһ��Ӧ�ġ�
��������ʱ�������ܵ����صĿ��ǣ�Ҳ���ܻ��N��ҵ���������һ�����ݵ�Ԫ����ô�����N�����ȡֵ���ǿ����ȵĿ����ˡ������ȵĴ�С���н����ġ�̫��Ŀ����ȿ��ܻ����ij���˷ѣ�̫С�Ŀ����ȿ��ܻ�����������⡣�����ȵ�Ȩ��Ҫ���ڶ������أ��Լ�һЩ����ֵ�Ŀ�����
�����ü��ŵ����ӡ���������ȹ�С�������趨Ϊ1�������ʵ�Աÿ��ֻȡ��1���š�����ż����ˣ��Ǿ͵������ܺö��ˣ��˷���ʱ�䡣
���������̫�����趨Ϊ100�����Ǽ��ŵ��˵õȵ�����100���Ų���ȥ������Ͳ������ƽʱ����д�ţ��͵õ��Ϻܾã�Ҳ��̫ˬ��
������ͬѧ���ʣ������ߺ������ߵĿ������ܷ����óɲ�ͬ��С��������ڼ��������ó�1�������ʵ�Ա���ó�100������Ȼ�������Ͽ�����ô�ɣ�������ijЩ����»����ӳ������ʹ���ʵ�ֵĸ��Ӷȡ��������۾��弼��ϸ��ʱ���������ĵ�������⡣
�ã����ݵ�Ԫ�Ļ����˵���⡣ϣ��ͨ�������ӣ������ܹ����������ݵ�Ԫ��������ôһ���¡���һ�����ӣ���������һ�¡����ڶ��еĻ������������������ʵ�֡�
�������ļ���ʵ��
�������
����ǰ���������ӵ��̵棬�������ڿ�ʼ��һЩ����ı�̼����ˡ����ڲ�ͬ�Ļ��������͡���ͬ�IJ����������ھ���ļ���ʵ���нϴ��Ӱ�졣Ϊ������dz�������ڴ������⣬�������������ͳ������ķ�ʽ��Ҳ���ǵ��������߶�Ӧ���������ߣ������ö��У�FIFO�������塣
���̺��߳��и��Ե���ȱ�㣬���߽Բ���ƫ�ϡ����ԣ�����Ը��ֻ��������͵Ľ��ܶ���ͬʱ�ἰ���̷�ʽ���̷߳�ʽ��
�̷߳�ʽ
����˵һ�²����߳���ʹ�ö��е����ӣ��Լ���ص���ȱ�㡣
�ڴ���������
���̷߳�ʽ�£������ߺ������߸�����һ���̡߳������߰�����д�����ͷ�����¼��push���������ߴӶ���β���������ݣ����¼��pop����������Ϊ�գ������߾���Ϣ��������Ϣ���������������ﵽ��ȣ��������߾���Ϣ���������̲������ӡ�
��ô���������̻���ʲô������
һ����Ҫ�������ǹ����ڴ��������ܿ��������ڳ����Ķ���ʵ�֣���ÿ��pushʱ�������漰�����ڴ�ķ��䣻��ÿ��popʱ�������漰���ڴ���ͷš����������ߺ������߶����ڿ죬Ƶ����push��pop�����ڴ����Ŀ����ͺܿɹ��ˡ�
������C/C++��ͬѧ����ض�OS�ײ���ƻ�������Ӧ��֪��������ڴ棨new��malloc�����м����Ŀ������û�̬������̬�л��Ŀ�����
�Ǹ���ô�����������ķֽ⣬���ڡ������ߣ�������ģʽ�����λ���������
ͬ���ͻ��������
���⣬���������̹߳���һ�����У���Ȼ�ͻ��漰���̼߳�����ͬ���������Ⱑ���������ȵ����ķ�������顣
����"����ϵͳ"���ſγ̶Դ�����ϸ���ܣ�ѧ����ͬѧӦ�û��е�ӡ��ɣ�����ûѧ�����ſε�ͬѧ��Ҳ�����ѹ���������صĽ���ͦ��ġ�
����Ҫϸ̸���ǣ�ͬ���ͻ�������ܿ������ںܶೡ���У������ź��������������������ʹ��Ҳ���в�С�Ŀ����ģ�ijЩ����£�Ҳ���ܵ����û�̬������̬�л����������ղ���˵�������ߺ������߶����ڿ죬����Щ����Ҳ����С�ﰡ��
���ָ�զ�����������ĵ����ķֽ⣬���ڡ������ߣ�������ģʽ��˫����������
�����ڶ��еij���
�ղž������˶��е�ȱ�㣬�ѵ����з�ʽ��һ���Ǵ�����Ҳ��
���ڶ����Ǻܳ��������ݽṹ���ֱ�����Զ������˶��е�֧�֣�������ܼ�"����"������Щ���������ṩ���̰߳�ȫ�Ķ��У�����JDK 1.5�����ArrayBlockingQueue������ˣ�������Ա���Լ��ֳɣ����������·������ӡ�
���ԣ�������������������Ǻܴ��ö��л������ĺô����Ǻ����Եģ��������������ά�����㡣
���̷�ʽ
˵�����̵߳ķ�ʽ���������ܻ��ڽ��̵IJ�����
����̵������ߣ�������ģʽ���dz������ھ���Ľ��̼�ͨѶ��IPC����ʽ��
��IPC��������Ŀ���࣬�����ڰ����о٣��Ͼ���ˮ���ޣ������������ѡ���ֿ�ƽ̨���ұ������֧�ֽ϶��IPC��ʽ��˵�¶���
�����ܵ�
�о��ܵ���������е�IPC���͡������߽����ڹܵ���д�˷������ݣ������߽����ڹܵ��Ķ���ȡ�����ݡ�������Ч�����߳���ʹ�ö��зdz����ƣ���������ʹ�ùܵ�����������̰߳�ȫ���ڴ��������£�����ϵͳ���ж�����㶨�ˣ���
�ܵ��ַ������ܵ��������ܵ����֣�������Ҫ�������ܵ�����Ϊ�����ܵ��ڲ�ͬ�IJ���ϵͳ�²���ϴ���Win32��POSIX���������ܵ���API�ӿں���ʵ���϶��нϴ���죻��Щƽ̨��֧�������ܵ�������Windows CE�������˲���ϵͳ�����⣬������Щ������ԣ�����Java����˵�������ܵ�����ʹ�õġ�������һ�㲻�Ƽ�ʹ�����������
��ʵ�����ܵ��ڲ�ͬƽ̨�ϵ�API�ӿڣ�Ҳ���в���ģ�����Win32��CreatePipe��POSIX��pipe���÷��ͺܲ�һ�������������ǿ��Խ�ʹ�ñ�����ͱ���������¼��stdio�����������ݵ�����������Ȼ������shell�Ĺܵ����������߽��̺������߽��̹���������û��˵�������ַ���ͬѧ�����Կ�"����"����ʵ���ϣ��ܶ����ϵͳ��������POSIX���ģ��Դ������������������������ʵ�����ݵĴ��䣨����more��grep�ȣ���
�ŵ�
��ô���м����ô���
1�����������в���ϵͳ��֧����shell��ʽ��ʹ�ùܵ�������˺�����ʵ�ֿ�ƽ̨��
2���ֱ�����Զ��ܹ�����stdio����˿�������Ҳ������ʵ�֡�
3���ղ��Ѿ��ᵽ���ܵ���ʽʡȴ���̰߳�ȫ��������¡������ڽ��Ϳ��������Գɱ���
ȱ��
��Ȼ�����ַ�ʽҲ��������ȱ�㣺
1�������߽��̺������߽��̱������ͬһ̨�����ϣ��������ͨѶ�����ȱ��Ƚ����ԡ�
2����һ��һ������£����ַ�ʽͦ���á������Ҫ��չ��һ�Զ���߶��һ���Ǿ��е㼬���ˡ��������ַ�ʽ����չ��Ҫ����ۿۡ������������Ƶ���չ�����ȱ��ͱȽ����ԡ�
3�����ڹܵ���shell�����ģ��������ߵĽ��̲��ɼ���������ֻ��stdio������ijЩ����£����³����ڶԹܵ����в��ݣ���������ܻ������ߴ磩�����ȱ�㲻̫���ԡ�
4��������ַ�ʽֻ�ܵ������ݡ����ڴ��������£������߽��̲���Ҫ�����ݸ������߽��̡���һ��ȷʵ��Ҫ��Ϣ�������������ߵ������ߣ����ǾͷѾ��ˡ����ܵÿ��ǻ���IPC��ʽ��
ע������
˳�㲹�伸��ע�������������һ�£�
1����stdio���ж�д��������������ʽ���С�����ܵ���û�����ݣ������߽��̵Ķ������ͻ�һֱͣ���Ķ���ֱ���ܵ������������ݡ�
2������stdio�ڲ������Լ��Ļ�������������ܵ��������������£�����ʱ�ᵼ��һЩ��̫ˬ�������������߽�����������ݣ��������߽���û��������������
SOCKET��TCP��ʽ��
����TCP��ʽ��SOCKETͨѶ����һ�������ڶ��е�IPC��ʽ����ͬ����֤�����ݵ�˳�ͬ���л���Ļ��ơ������������Ҳ�ǿ�ƽ̨�Ϳ����Եģ��ղŽ��ܵ�shell�ܵ�����ʽ���ơ�
SOCKET���shell�ܵ����ķ�ʽ����ɶ�ŵ�����Ҫ�����¼����ŵ㣺
1��SOCKET��ʽ���Կ����������ʵ�ֲַ�ʽ����������Ҫ�ŵ㡣
2��SOCKET��ʽ���ڽ�����չ��Ϊ���һ����һ�Զࡣ��Ҳ����Ҫ�ŵ㡣
3��SOCKET�������������ͷ������������������Ƚ������Ǵ�Ҫ�ŵ㡣
4��SOCKET֧��˫��ͨѶ�������������߷�����Ϣ��
��Ȼ�������бס����������shell�ܵ��ķ�ʽ��ʹ��SOCKET�ڱ���ϻ������һЩ������ǰ���Ѿ����˴����Ĺ���������ܶ�SOCKETͨѶ��Ϳ�ܸ������ã�����C++��ACE�⡢Python��Twisted������������Щ�������Ŀ�Ϳ�ܣ�SOCKET��ʽ���������DZȽ�ˬ�ġ����ھ��������ͨѶ�����ô�ò��DZ�ϵ�е��ص㣬�˴��Ͳ�ϸ˵�ˡ�
��ȻTCP�ںܶ���UDP�ɿ��������ڿ����ͨѶ����IJ���Ԥ���ԣ��������߿��ܱ�ijɵX���δ��ˣ������æ�в������ܴܺ��ڳ�����������ǻ���Ҫ����һ�֡�������������
�����������߽��̺������߽����ڲ���������������̵߳�"�����ߣ�������ģʽ"��
�⻰�������ƿ��Ϊ�˱������⣬����:
�����߽��������߽���==�����ͻ�����==�������߳�==��TCP��/���/API
���͵�������
�����߽���TCP��/���/API==>�����߳�==�����ջ�����==�������߳�
��ô���Ĺؼ������ڰѴ����Ϊ�����֣������̺߳������߳����ں�ҵ������صĴ��루��ͨѶ���أ��������̺߳ͽ����߳�����ͨѶ��صĴ��루��ҵ�����أ���
����
�����ĺô��Ǻ����Եģ��������£�
1���ܹ�Ӧ����ʱ�Ե�������ϡ�������������Ͻ�����ܹ�����������
2��������ϵ�Ӧ�Դ�����ʽ������Ͽ���ij�����������ֻӰ�췢�ͺͽ����̣߳�����Ӱ�������̺߳������̣߳�ҵ�������֣���
3�������SOCKET��ʽ�������ͷ�������ֻӰ�췢�ͺͽ����̣߳���Ӱ�������̺߳������̣߳�ҵ�������֣���
4��������TCP�����ķ��ͻ������ͽ��ջ���������Ĭ�ϵ�TCP�������Ĵ�С����������ʵ��Ҫ��
5��ҵ�����ı仯������ҵ������������Ӱ�췢���̺߳ͽ����̡߳�
������������һ�����ٶ����¼��䡣�������ҵ��ϵͳ���ж�������Dz���������ģʽ���ǻ��������ع�һ�ѣ���ҵ���������ͨѶ������֮����һ������ҵ�����صIJ��ַ�װ��һ��ͨѶ�м����
�������
ǰһ�������ἰ�˶��л��������ܴ��ڵ��������⼰������������λ������������ר��������һ��������⡣
Ϊ�˷�ֹ���˸��ۿ��ϡ�������ơ��Ĵ�ñ�ӣ���������һ�£�ֻ�е��洢�ռ�ķ��䣯�ͷŷdz�Ƶ������ȷʵ���������Ե�Ӱ�죬���Ӧ�ÿ��ǻ��λ�������ʹ�á�����Ļ�����������ʵʵ�����������Ķ��л������ɡ�
����һ����Ҫ˵��һ�£��������ἰ�ġ��洢�ռ䡱�����������ڴ棬�����ܰ�������Ӳ��֮��Ĵ洢���ʡ�
���λ����� vs ���л�����
�ⲿ�ӿ�����
�ڽ��ܻ��λ�����֮ǰ�����������ع�һ����ͨ�Ķ��С���ͨ�Ķ�����һ��д��˺�һ�������ˡ�����Ϊ�յ�ʱ����������ȡ���ݣ������������ﵽ���ߴ磩ʱ��д�����д�����ݡ�
����ʹ�������������λ������Ͷ��л�������һ���ġ���Ҳ��һ��д��ˣ�����push����һ�������ˣ�����pop����Ҳ�л������������͡��ա���״̬�����ԣ��Ӷ��л������л������λ�����������ʹ������˵�ܱȽ�ƽ���ع��ɡ�
�ڲ��ṹ����
��Ȼ���ߵĶ���ӿڲ�࣬�����ڲ��ṹ�����������кܴ��𡣶��е��ڲ��ṹ�˴��Ͳ��������ˡ��ص����һ�»��λ��������ڲ��ṹ��
�������ѻ��λ������Ķ����ˣ����¼��R����д��ˣ����¼��W������������������������ܵ�����RW������R��W��ʱ���ǻ�����Ϊ�գ���W��R��ʱ��W��R����һȦ�������ǻ���������
Ϊ�����������ȥ����һ��ͼ�������ģ����£�
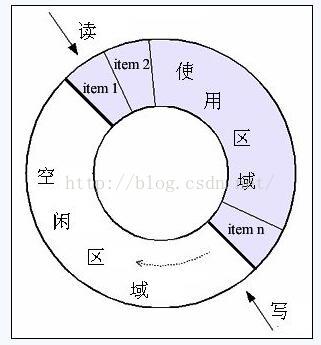
����ͼ���Կ��������λ��������е�push��pop����������һ���̶��Ĵ洢�ռ��ڽ��С������л�������push��ʱ���ܻ����洢�ռ����ڴ洢��Ԫ�أ���popʱ�����ܻ��ͷŷ���Ԫ�صĴ洢�ռ䡣
���Ի��η�ʽ��ȶ��з�ʽ���ٵ��˶��ڻ�����Ԫ�����ô洢�ռ�ķ��䡢�ͷ������ǻ��λ�������һ����Ҫ���ơ�
���λ�������ʵ��
�������ͷ�Ѿ����ֳɵĻ��λ������ɹ�ʹ�ã�������Ի��λ��������ڲ�ʵ�ֲ�����Ȥ������������Ρ�
���鷽ʽ vs ������ʽ
���λ��������ڲ�ʵ�֣����ɻ������飨�˴������飬��ָ�����洢�ռ䣩ʵ�֣�Ҳ�ɻ�������ʵ�֡�
�����������洢����һά���������Խṹ�������ڳ�ʼ��ʱ���Ѵ洢�ռ�һ���Է���ã��������鷽ʽ���ŵ㡣����Ҫʹ��������ģ�������������ϰ������ͷ��β��������˳���������ʱ����β��Ԫ�أ����һ��Ԫ�أ�Ҫ��һ�������������β��Ԫ�ص���һ��Ԫ��ʱ��Ҫ���»ص�ͷ��Ԫ�أ���0��Ԫ�أ���
ʹ�������ķ�ʽ�����ú������෴������ʡȥ��ͷβ����������������������ڳ�ʼ����ʱ��ȽϷ�������������Щ���ϣ���������ᵽ�Ŀ���̵�IPC����̫����ʹ�á�
�����
���λ�����Ҫά�������������ֱ��Ӧд��ˣ�W���Ͷ�ȡ�ˣ�R����
д�루push����ʱ����ȷ����û����Ȼ������ݸ��Ƶ�W����Ӧ��Ԫ�أ����Wָ����һ��Ԫ�أ���ȡ��pop����ʱ����ȷ����û�գ�Ȼ��R��Ӧ��Ԫ�أ����Rָ����һ��Ԫ�ء�
�жϡ��ա��͡�����
�����IJ����������ӣ�������һ��СС���鷳���ջ���������ʱ��R��W��ָ��ͬһ��λ�ã����������жϵ����ǡ��ա����ǡ�������
�����������ַ������Խ�������⡣
�취1��ʼ�ձ���һ��Ԫ�ز���
���ջ���ʱ��R��W�ص�����W��R�ܵÿ죬������R����һ��Ԫ�ؼ����ʱ����Ϊ���Ѿ�����������Ԫ��ռ�õĴ洢�ռ�ϴ��ʱ�����ְ취�Եú������˷ѿռ䣩��
�취2��ά���������
�����ϲ�������취�������Բ��ö���ı�������������������һ��������¼��ǰ�����Ѿ������Ԫ�ظ�����������>=0������R��W�ص���ʱ��ͨ���ñ����Ϳ���֪���ǡ��ա����ǡ�������
Ԫ�صĴ洢
���ڻ��λ�������������Ҫ���ʹ洢�ռ����Ŀ�������˻�������Ԫ�ص�����Ҫѡ�á�
�����洢ֵ���͵����ݣ�����Ҫ�洢ָ�루���ã����͵����ݡ�
��Ϊָ�����͵������ֻ�����洢�ռ䣨������ڴ棩�ķ�����ͷţ�ʹ�û��λ�������Ч�����ۿۡ�
Ӧ�ó���
�ղŽ����˻��λ������ڲ���ʵ�ֻ��ơ�����ǰһ�����ӵĹ���������������һ�����̺߳ͽ��̷�ʽ�µ�ʹ�á�
�������ʹ�õı�����ԺͿ������д����ֳɵġ�����Ļ��λ�������ǿ�ҽ���ʹ���ֳɵĿ⣬��Ҫ�����������ӣ�ȷʵ�Ҳ����ֳɵģ��ſ����Լ�ʵ�֡�����㴿����ҵ��ʱ�������֣����������ۡ�
���ڲ����߳�
���߳��еĶ��л��������ƣ��߳��еĻ��λ�����ҲҪ�����̰߳�ȫ�����⡣������ʹ�õĻ��λ������Ŀ��Ѿ�����ʵ�����̰߳�ȫ�������㻹�ǵ��Լ����ָ㶨���̷߳�ʽ�µĻ��λ������õñȽ϶࣬��ص���������Ҳ�࣬����ʹ��½��ܼ�����
����C++�ij���Ա��ǿ���Ƽ�ʹ��boost�ṩ��circular_bufferģ�壬��ģ���ʼ����boost 1.35�汾������ġ�����boost��C++�����еĵ�λ������Ӧ�ÿ��Է���ʹ�ø�ģ�塣
����C����Ա������ȥ������Դ��Ŀcircbuf����������Ŀ��GPLЭ��ģ���̫ˬ�����һ�Ծ�Ȳ�̫�ߣ�����ֻ��һ��������Ա���������ã�����ֻ�������ο���
����C#����Ա�����Բο�CodeProject�ϵ�һ��ʾ����
Java ����Ա���Բο� Disruptor
���ڲ�������
���̼�Ļ��λ��������ƺ������ֳɵĿ���á�����ֻ���Լ����֡�������ʳ�ˡ�
�����ڽ��̼价�λ����IPC���ͣ��������й����ڴ���ļ����������ַ�ʽ�Ͻ��л��λ��壬ͨ������������ķ�ʽʵ�֡��������ȷ����һ���̶����ȵĴ洢�ռ䣬Ȼ�����Ķ�д�������жϡ��ա��͡�������Ԫ�ش洢��ϸ�ھͿɲ���ǰ����˵�������С�
�����ڴ淽ʽ�����ܺܺã����������������ܴ�ij�����������Щ���ԣ�����Java�����ڹ����ڴ治֧�֡���ˣ��÷�ʽ�ڶ�����Эͬ������ϵͳ�У�����һ���ľ����ԡ�
���ļ���ʽ�ڱ�����Է���֧�ֺܺã��������б�����Զ�֧�ֲ����ļ����������ܻ������ڴ��̶�д��Disk I/O�������ܡ������ļ���ʽ��̫�ʺ��ڿ������ݴ��䣻���Ƕ���ijЩ�����ݵ�Ԫ���ܴ�ij��ϣ��ļ���ʽ��ֵ�ÿ��ǵġ�
���ڽ��̼�Ļ��λ�������ͬ��Ҫ���Ǻý��̼��ͬ������������⣬����ƪ�����˴��Ͳ�ϸ˵�ˡ�
����ʵ��
��ʽһ��synchronized��wait��notify
//wait �� notify
public class ProducerConsumerWithWaitNofity {
public static void main(String[] args) {
Resource resource = new Resource();//�������߳�ProducerThread p1 = new ProducerThread(resource);ProducerThread p2 = new ProducerThread(resource);ProducerThread p3 = new ProducerThread(resource);//�������߳�ConsumerThread c1 = new ConsumerThread(resource);//ConsumerThread c2 = new ConsumerThread(resource);//ConsumerThread c3 = new ConsumerThread(resource);p1.start();p2.start();p3.start();c1.start();//c2.start();//c3.start();}}
/*** ������Դ��* @author **/
class Resource{
//��Ҫ//��ǰ��Դ����private int num = 0;//��Դ����������ŵ���Դ��Ŀprivate int size = 10;/*** ����Դ����ȡ����Դ*/public synchronized void remove(){
if(num > 0){
num--;System.out.println("������" + Thread.currentThread().getName() +"����һ����Դ��" + "��ǰ�̳߳���" + num + "��");notifyAll();//֪ͨ������������Դ}else{
try {
//���û����Դ���������߽���ȴ�״̬wait();System.out.println("������" + Thread.currentThread().getName() + "�߳̽���ȴ�״̬");} catch (InterruptedException e) {
e.printStackTrace();}}}/*** ����Դ����������Դ*/public synchronized void add(){
if(num < size){
num++;System.out.println(Thread.currentThread().getName() + "����һ����Դ����ǰ��Դ����" + num + "��");//֪ͨ�ȴ���������notifyAll();}else{
//�����ǰ��Դ������10����Դtry{
wait();//�����߽���ȴ�״̬�����ͷ���System.out.println(Thread.currentThread().getName()+"�߳̽���ȴ�");}catch(InterruptedException e){
e.printStackTrace();}}}
}
/*** �������߳�*/
class ConsumerThread extends Thread{
private Resource resource;public ConsumerThread(Resource resource){
this.resource = resource;}@Overridepublic void run() {
while(true){
try {
Thread.sleep(1000);} catch (InterruptedException e) {
e.printStackTrace();}resource.remove();}}
}
/*** �������߳�*/
class ProducerThread extends Thread{
private Resource resource;public ProducerThread(Resource resource){
this.resource = resource;}@Overridepublic void run() {
//���ϵ�������Դwhile(true){
try {
Thread.sleep(1000);} catch (InterruptedException e) {
e.printStackTrace();}resource.add();}}}
��ʽ����lock��condition��await��signalAll
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/*** ʹ��Lock �� Condition�������������������* @author tangzhijing**/
public class LockCondition {
public static void main(String[] args) {
Lock lock = new ReentrantLock();Condition producerCondition = lock.newCondition();Condition consumerCondition = lock.newCondition();Resource2 resource = new Resource2(lock,producerCondition,consumerCondition);//�������߳�ProducerThread2 producer1 = new ProducerThread2(resource);//�������߳�ConsumerThread2 consumer1 = new ConsumerThread2(resource);ConsumerThread2 consumer2 = new ConsumerThread2(resource);ConsumerThread2 consumer3 = new ConsumerThread2(resource);producer1.start();consumer1.start();consumer2.start();consumer3.start();}
}
/*** �������߳�*/
class ConsumerThread2 extends Thread{
private Resource2 resource;public ConsumerThread2(Resource2 resource){
this.resource = resource;//setName("������");}public void run(){
while(true){
try {
Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {
e.printStackTrace();}resource.remove();}}
}
/*** �������߳�* @author tangzhijing**/
class ProducerThread2 extends Thread{
private Resource2 resource;public ProducerThread2(Resource2 resource){
this.resource = resource;setName("������");}public void run(){
while(true){
try {
Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {
e.printStackTrace();}resource.add();}}
}
/*** ������Դ��* @author tangzhijing**/
class Resource2{
private int num = 0;//��ǰ��Դ����private int size = 10;//��Դ����������ŵ���Դ��Ŀprivate Lock lock;private Condition producerCondition;private Condition consumerCondition;public Resource2(Lock lock, Condition producerCondition, Condition consumerCondition) {
this.lock = lock;this.producerCondition = producerCondition;this.consumerCondition = consumerCondition;}/*** ����Դ����������Դ*/public void add(){
lock.lock();try{
if(num < size){
num++;System.out.println(Thread.currentThread().getName() + "����һ����Դ,��ǰ��Դ����" + num + "��");//���ѵȴ���������consumerCondition.signalAll();}else{
//���������̵߳ȴ�try {
producerCondition.await();System.out.println(Thread.currentThread().getName() + "�߳̽���ȴ�");} catch (InterruptedException e) {
e.printStackTrace();}}}finally{
lock.unlock();}}/*** ����Դ����ȡ����Դ*/public void remove(){
lock.lock();try{
if(num > 0){
num--;System.out.println("������" + Thread.currentThread().getName() + "����һ����Դ," + "��ǰ��Դ����" + num + "��");producerCondition.signalAll();//���ѵȴ���������}else{
try {
consumerCondition.await();System.out.println(Thread.currentThread().getName() + "�߳̽���ȴ�");} catch (InterruptedException e) {
e.printStackTrace();}//�������ߵȴ�}}finally{
lock.unlock();}}}
��ʽ����BlockingQueue
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;//ʹ����������BlockingQueue���������������
public class BlockingQueueConsumerProducer {
public static void main(String[] args) {
Resource3 resource = new Resource3();//�������߳�ProducerThread3 p = new ProducerThread3(resource);//���������ConsumerThread3 c1 = new ConsumerThread3(resource);ConsumerThread3 c2 = new ConsumerThread3(resource);ConsumerThread3 c3 = new ConsumerThread3(resource);p.start();c1.start();c2.start();c3.start();}
}
/*** �������߳�* @author tangzhijing**/
class ConsumerThread3 extends Thread {
private Resource3 resource3;public ConsumerThread3(Resource3 resource) {
this.resource3 = resource;//setName("������");}public void run() {
while (true) {
try {
Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {
e.printStackTrace();}resource3.remove();}}
}
/*** �������߳�* @author tangzhijing**/
class ProducerThread3 extends Thread{
private Resource3 resource3;public ProducerThread3(Resource3 resource) {
this.resource3 = resource;//setName("������");}public void run() {
while (true) {
try {
Thread.sleep((long) (1000 * Math.random()));} catch (InterruptedException e) {
e.printStackTrace();}resource3.add();}}
}
class Resource3{
private BlockingQueue resourceQueue = new LinkedBlockingQueue(10);/*** ����Դ����������Դ*/public void add(){
try {
resourceQueue.put(1);System.out.println("������" + Thread.currentThread().getName()+ "����һ����Դ," + "��ǰ��Դ����" + resourceQueue.size() + "����Դ");} catch (InterruptedException e) {
e.printStackTrace();}}/*** ����Դ�����Ƴ���Դ*/public void remove(){
try {
resourceQueue.take();System.out.println("������" + Thread.currentThread().getName() + "����һ����Դ," + "��ǰ��Դ����" + resourceQueue.size() + "����Դ");} catch (InterruptedException e) {
e.printStackTrace();}}
}
����˼��
-
���ڸ�����������ο�����ƪ�������ķdz��á�������ֻ��������������ߣ������ߣ����������������˸�ϸ�£����ݵ�Ԫ֮��ġ�
-
���ڼ�����������������������ѵ�ʵ��=����װ��BlockingQueue ͨ�����=�����ܸ�������Ļ��ζ���=��Disruptor ��������������м����
�����
��java ������̵�������
����ѧϰ���߳�-06-Producer Consumer ģʽ
java 23 �����ģʽ-20-java �۲���ģʽ��Observer Pattern��
������������-����ʵ�ַ�ʽ
���IJ�����ʮ��������������ģʽ
https://blog.csdn.net/u011109589/article/details/80519863
Ŀ¼
java���̲߳���֮��-01-��������