Segment
Segment �ǻ��ڽ�ͷִʴʿ�ʵ�ֵĸ����������ܵ� java �ִ�ʵ�֡�
�����־
����Ŀ��
�ִ����� NLP ��ع������dz�������һ��ܡ�
jieba-analysis ��Ϊһ��dz��ܻ�ӭ�ķִ�ʵ�֣�����ʵ�ֵ� opencc4j ֮ǰһֱʹ������Ϊ�ִʡ�
�������ŶԷִʵ��˽⣬���ֽ�ͷִʶ���һЩ�����ϲ�����
��1���кܶ����ָ���رգ����� HMM ���ڷ�����ת�������õģ���Ϊ������ǹ̶��ģ�����ҪԤ�⡣
��2�����°汾�Ĵ��Եȹ��ܺ���Ҳ���Ƴ��ˣ�������Щ���Ǹ��˷dz���Ҫ�ġ�
��3���������ķ���ִ�֧�ֲ��Ѻá�
��������ʵ����һ�飬ϣ��ʵ��һ�������������Եķִʿ�ܡ�
���� jieba-analysis �ĸ����ƺ�ͣ���ˣ����˵�ʵ�ַ�ʽ����ϴ����Խ�����ȫ�µ���Ŀ��
Features �ص�
-
�����û��ļ���̬ api ���
-
������ fluent-api ��ƣ������ø����������
-
��ϸ�����Ĵ���ע�ͣ�����Դ���Ķ�
-
���� DFA ʵ�ֵĸ����ִܷ�
-
���� HMM ���´�Ԥ��
-
֧�ֲ�ͬ�ķִ�ģʽ
-
֧��ȫ�ǰ��/Ӣ�Ĵ�Сд/���ķ������ʽ����
-
����ָ���Զ���ʿ�
���±��
- ֧�����ķ���ִ�
��������
��
jdk1.7+
maven 3.x+
maven ����
<dependency><groupId>com.github.houbb</groupId><artifactId>segment</artifactId><version>0.1.2</version>
</dependency>
��ش���μ� SegmentHelperTest.java
Ĭ�Ϸִ�ʾ��
���طִʣ��±����Ϣ��
final String string = "����һ�����ֲ�����ָ�ĺ�ҹ���ҽ�����գ��Ұ��������Ұ�ѧϰ��";List<ISegmentResult> resultList = SegmentHelper.segment(string);
Assert.assertEquals("[����[0,2), һ��[2,4), ���ֲ�����ָ[4,10), ��[10,11), ��ҹ[11,13), ��[13,14), ��[14,15), ��[15,16), �����[16,19), ��[19,20), �Ұ�[20,22), ����[22,24), ��[24,25), �Ұ�[25,27), ѧϰ[27,29), ��[29,30)]", resultList.toString());
ָ��������ʽ
��ʱ�����Ǹ����Լ���Ӧ�ó�������Ҫѡ��ͬ�ķ�����ʽ��
SegmentResultHandlers ����ָ�����ڷִʽ���Ĵ���ʵ�֣����ڱ�֤ api ��ͳһ�ԡ�
| ���� | ʵ�� | ˵�� |
|---|---|---|
common() |
SegmentResultHandler | Ĭ��ʵ�֣����� ISegmentResult �б� |
word() |
SegmentResultWordHandler | ֻ���طִ��ַ����б� |
Ĭ��ģʽ
Ĭ�Ϸִ���ʽ���ȼ��������д��
List<ISegmentResult> resultList = SegmentHelper.segment(string, SegmentResultHandlers.common());
ֻ��ȡ�ִ���Ϣ
final String string = "����һ�����ֲ�����ָ�ĺ�ҹ���ҽ�����գ��Ұ��������Ұ�ѧϰ��";List<String> resultList = SegmentHelper.segment(string, SegmentResultHandlers.word());
Assert.assertEquals("[����, һ��, ���ֲ�����ָ, ��, ��ҹ, ��, ��, ��, �����, ��, �Ұ�, ����, ��, �Ұ�, ѧϰ, ��]", resultList.toString());
�ִ�ģʽ
�ִ�ģʽ���
�ִ�ģʽ����ͨ���� SegmentModes �������ȡ��
| ��� | ���� | ȷ�� | ���� | ��ע |
|---|---|---|---|---|
| 1 | search() | �� | һ�� | ��ͷִʵ�Ĭ��ģʽ |
| 2 | dict() | �ϸ� | һ�� | �� search ģʽ���ƣ�����ȱ�� HMM �´�Ԥ�� |
| 3 | index() | һ�� | �� | �����ܶ�ķ��ش�����Ϣ������ٻ��� |
| 4 | greedyLength() | һ�� | �� | ̰�����ƥ�䣬��ȷ��Ҫ��ʱ�ɲ��á� |
ʹ�÷�ʽ
����������ã������� SegmentBs ��Ϊ�����࣬�������������ò�����������⡣
���Դ���μ� SegmentModeTest.java
search ģʽ
segmentMode() ָ���ִ�ģʽ����ָ��ʱĬ�Ͼ��� SegmentModes.search()��
final String string = "����һ�����ֲ�����ָ�ĺ�ҹ��";List<ISegmentResult> resultList = SegmentBs.newInstance().segmentMode(SegmentModes.search()).segment(string);Assert.assertEquals("[����[0,2), һ��[2,4), ���ֲ�����ָ[4,10), ��[10,11), ��ҹ[11,13), ��[13,14)]", resultList.toString());
dict ģʽ
ֻ�����ʿ�ʵ�ִַʣ�û�� HMM �´�Ԥ��ܡ�
final String string = "����һ�����ֲ�����ָ�ĺ�ҹ��";List<ISegmentResult> resultList = SegmentBs.newInstance().segmentMode(SegmentModes.dict()).segment(string);
Assert.assertEquals("[��[0,1), ��[1,2), һ��[2,4), ���ֲ�����ָ[4,10), ��[10,11), ��ҹ[11,13), ��[13,14)]", resultList.toString());
index ģʽ
������Ҫ��������ǻ᷵�� ���������ֲ��� ���������顣
final String string = "����һ�����ֲ�����ָ�ĺ�ҹ��";List<ISegmentResult> resultList = SegmentBs.newInstance().segmentMode(SegmentModes.index()).segment(string);
Assert.assertEquals("[��[0,1), ��[1,2), һ��[2,4), ����[4,6), ���ֲ���[4,8), ���ֲ�����ָ[4,10), ��[10,11), ��ҹ[11,13), ��[13,14)]", resultList.toString());
GreedyLength ģʽ
����ʹ��̰���㷨ʵ�֣�ȷ��һ�㣬���ܽϺá�
final String string = "����һ�����ֲ�����ָ�ĺ�ҹ��";List<ISegmentResult> resultList = SegmentBs.newInstance().segmentMode(SegmentModes.greedyLength()).segment(string);
Assert.assertEquals("[��[0,1), ��[1,2), һ��[2,4), ���ֲ�����ָ[4,10), ��[10,11), ��ҹ[11,13), ��[13,14)]", resultList.toString());
��ʽ������
��ʽ���ӿ�
����ͨ�� SegmentFormats �������ȡ��Ӧ�ĸ�ʽ��ʵ�֣��ڷִ�ʱָ�����ɡ�
| ��� | ���� | ���� | ˵�� |
|---|---|---|---|
| 1 | defaults() | Ĭ�ϸ�ʽ�� | �ȼ���Сд+��Ǵ����� |
| 2 | lowerCase() | �ַ�Сд��ʽ�� | Ӣ���ַ�����ʱͳһת��ΪСд |
| 3 | halfWidth() | �ַ���Ǹ�ʽ�� | Ӣ���ַ�����ʱͳһת��Ϊ��� |
| 4 | chineseSimple() | ���ļ����ʽ�� | ����֧�ַ������ķִ� |
| 5 | none() | ��ʽ�� | ���κθ�ʽ������ |
| 6 | chains(formats) | ��ʽ�������� | �������������ĸ�ʽ��������ϣ�ͬʱ�����Զ����ʽ���� |
Ĭ�ϸ�ʽ��
ȫ�ǰ��+Ӣ�Ĵ�Сд��ʽ��������Ĭ�Ͽ�����
����� �� Ϊȫ�Ǵ�д��Ĭ�ϻᱻת��������
String text = "���Ѿ���";
List<ISegmentResult> segmentResults = SegmentHelper.segment(text);Assert.assertEquals("[����[0,2), ����[2,4)]", segmentResults.toString());
���ķ���ִ�
�����ǽ�ͷִʻ��ǵ�ǰ��ܣ�Ĭ�϶Է������ĵķִʶ����Ѻá�
Ĭ�Ϸִ�ʾ��
��Ȼ�ͼ������ĵķִ���ʽ��ͬ��
String text = "�@��һ�����ֲ�Ҋ��ָ�ĺ�ҹ";List<String> defaultWords = SegmentBs.newInstance().segment(text, SegmentResultHandlers.word());
Assert.assertEquals("[�@��, һ, ��, ����, ��Ҋ, ��ָ, ��, ��ҹ]", defaultWords.toString());
�������ķ���ִ�
ָ���ִ����ĸ�ʽ�������Եõ���������Ԥ�ڵķִʡ�
String text = "�@��һ�����ֲ�Ҋ��ָ�ĺ�ҹ";List<String> defaultWords = SegmentBs.newInstance().segmentFormat(SegmentFormats.chineseSimple()).segment(text, SegmentResultHandlers.word());
Assert.assertEquals("[�@��, һ��, ���ֲ�Ҋ��ָ, ��, ��ҹ]", defaultWords.toString());
��ʽ��������
��ʽ������ʽ�����кܶ࣬���ǿ��Ը����Լ�������������ϡ�
����������ͬʱ����Ĭ�ϸ�ʽ��+���ļ����ʽ����
final String text = "���ѣ��@��һ�����ֲ�Ҋ��ָ�ĺ�ҹ";List<String> defaultWords = SegmentBs.newInstance().segmentFormat(SegmentFormats.chains(SegmentFormats.defaults(),SegmentFormats.chineseSimple())).segment(text, SegmentResultHandlers.word());
Assert.assertEquals("[����, ��, �@��, һ��, ���ֲ�Ҋ��ָ, ��, ��ҹ]", defaultWords.toString());
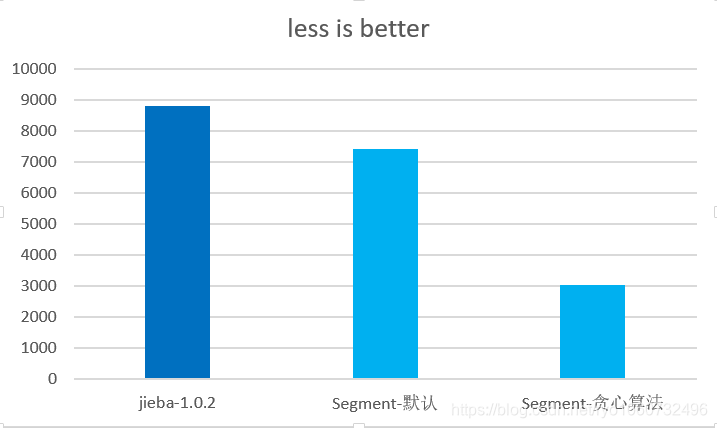
Benchmark ���ܶԱ�
���ܶԱ�
���ܶԱȻ��� jieba 1.0.2 �汾��������������һ�£���֤���߶�����Ԥ�ȣ�Ȼ��ͳһ������
��֤������Ĭ��ģʽ���������� jieba �ִʣ�̰��ģʽ�������� 3 �����ҡ�
��ע��
��1��Ĭ��ģʽ�ͽ�� Search ģʽһ�¡�
���ڿ��� HMM Ҳ���������Ƿ������ݶ�ΪĬ�Ͽ���
��2�����ڽ�������߳��������ܡ�
����μ� BenchmarkTest.java
���ܶԱ�ͼ
��ͬ���ı���ѭ�� 1W �κ�ʱ����Less is Better��
���� Road-Map
��������
-
HMM ���Ա�ע
-
HMM ʵ���ע
-
CRF �㷨ʵ��
-
N Ԫ���㷨ʵ��
�Ż�
-
���̵߳�֧�֣������Ż�
-
˫���� DFA ʵ�֣������ڴ�����
��������
- ��չ�Զ���ʿ������
������л
��л jieba �ִ��ṩ�Ĵʿ⣬�Լ� jieba-analysis �����ʵ�֡�