torchvision « pytorch ΩρΦή ≈δΒΡœύΒ±ΚΟ”ΟΒΡΙΛΨΏΑϋΘ§ΥϋΖβΉΑΝΥΉνΝς––ΒΡ ΐΨίΦ·Θ®torchvision.datasetsΘ©ΓΔΡΘ–ΆΘ®torchvision.modelsΘ©ΚΆ≥Θ”Ο”Ύ CV ΒΡΆΦœώΉΣΜΜΉιΦΰΘ®torchvision.transformsΘ©ΚΆΤδΥϋΙΛΨΏΘΚ
”– ±Φδ“ΜΕ®“ΣΆ®ΕΝ“Μ±ιΙΌΖΫΈΡΒΒ TORCHVISIONΘ§ΡΎ»ί≤ΜΕύΘ§ΦρΟς“ΉΕ°Θ§”–÷ζ”Ύ…œ ÷ΓΘ
“‘ notebook ΒΡΖΫ Ϋ ΒΦυ torchvision
# ΒΦ»κ±Ί“ΣΒΡΑϋ
import torch
import torchvision
from torch import nn, optim
from torch.utils.data import DataLoader
from torchvision import models, datasets, transforms%pylab inline # ΡßΖ®ΖΫΖ®”Ο”Ύœ‘ Ψ plt.show()
“ΜΓΔtorchvision.transforms
”Ο transforms.Compose([ ... ]) Ε®“ε≥Θ”ΟΒΡΆΦœώΉΣΜΜΝς≥ΧΘ§“‘Ή÷ΒδΒΡΖΫ Ϋ±Θ¥φΖΫ±ψΒς”ΟΘΚ
# Α¥’’ ΐΨίΦ·ΒΡΆΦœώ¥σ–Γ―Γ‘ώΉΣΜΜΉιΦΰΚΆ≤Έ ΐ
data_transforms = {
# ―ΒΝΖ ΐΨίΦ·ΒΡΉΣΜΜΉιΦΰ'train': transforms.Compose([transforms.Resize(230), # ΆΦΤ§Ή‘ ”ΠΥθ–ΓΘ®ΜρΖ≈¥σΘ©ΒΫΉν¥σ±Ώ≥ΛΈΣ230ΒΡ¥σ–Γ == transforms.Scale(230)transforms.CenterCrop(224), # Ψ”÷–≤ΟΦτ≥… 224ΓΝ224ΒΡΆΦtransforms.RandomHorizontalFlip(p=0.5), # ΥφΜζΥ°ΤΫΖ≠ΉΣΆΦœώΘ§ΆΦœώ±ΜΖ≠ΉΣΒΡΗ≈¬ Ρ§»œΈΣ p=0.5transforms.ToTensor(), # ΉΣ≥… Tensor Ηώ ΫΘ§≤ΔΙι“ΜΜ·œώΥΊ÷ΒΒΫ [0., 1.]transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # “‘Ψυ÷Β0.5Θ§±ξΉΦ≤ν0.5Θ§Ζ÷±π‘Ύ3ΗωΆ®Βά…œΫχ––Ιι“ΜΜ·]),# ≤β ‘ ΐΨίΦ·ΒΡΉΣΜΜΉιΦΰ'test': transforms.Compose([transforms.Resize(256), # ±ΘΝτ≤β ‘ΆΦœώΗϋ¥σ“Μ–©Θ§ΩΦ―ι“Μœ¬…ώΨ≠Άχ¬γtransforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
}
ΙΌΖΫΈΡΒΒ’Σ»ΓΘΚ
-
torchvision.transforms.ToTensor()
ToTensor()ΫΪ shape ΈΣ (H, W, C) ΒΡ nump.ndarray Μρ PIL img ΉΣΈΣ shape ΈΣ (C, H, W) ΒΡ torch.TensorΘ®Τδ÷–Θ§ C ΈΣΆΦœώΆ®Βά ΐΘ©Θ§≤ΔΫΪΟΩ“ΜΗω ΐ÷ΒΙι“ΜΜ·ΒΫ [0,1]Θ§ΤδΙι“ΜΜ·ΖΫΖ®±»ΫœΦρΒΞΘ§÷±Ϋ”≥ΐ“‘ 255 Φ¥Ω…ΓΘ -
torchvision.transforms.Normalize(mean, std, inplace=False)
Ε‘”Ύ n ΗωΆ®ΒάΘ§ΗχΕ®Ψυ÷Β ΐΉιΘΚ
Θ®mean [1]Θ§...Θ§mean [n]Θ©ΚΆ±ξΉΦ≤ν ΐΉιΘΚΘ®std [1]Θ§..Θ§std [n]Θ©Θ§¥Υ±δΜΜΫΪΕ‘ δ»κΒΡΟΩΗωΆ®ΒάΖ÷±π”ΟΕ‘”Π÷ΒΒΡΫχ––Ιι“ΜΜ·ΓΘΙι“ΜΜ·ΖΫ ΫΘΚ
output[channel] = (input[channel] - mean[channel]) / std[channel]ΥϋΒΡΡΩΒΡ «»ΟΆΦœώΒΡœώΥΊ÷ΒΫ”Ϋϋ N ( 0 Θ§ 1 ) \mathcal N(0Θ§1) N(0Θ§1) ±ξΉΦ’ΐΧ§Ζ÷≤ΦΘ§Φ¥“‘ 0 ΈΣΨυ÷ΒΘ§1 ΈΣ±ξΉΦ≤νΒΡΖ÷≤ΦΘ§Υυ“‘¥σ≤ΩΖ÷ΒΡœώΥΊ÷ΒΉν÷’‘Ύ [-1, 1] «χΦδΓΘ
ΕΰΓΔtorchvision.datasets ΚΆ torch.utils.data.DataLoader
PyTorch ΐΨίΦ”‘ΊΒΡΚΥ–Ρ «
torch.utils.data.DataLoaderάύΓΘΥϋΖΒΜΊ“ΜΗω Python Ω…Βϋ¥ζΒΡ ΐΨίΦ·
DataLoader ΒΡ≤Έ ΐ≈δ÷Ο»γœ¬ΘΚ
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,batch_sampler=None, num_workers=0, collate_fn=None,pin_memory=False, drop_last=False, timeout=0,worker_init_fn=None, *, prefetch_factor=2,persistent_workers=False)
Έ“Ο«“ΜΑψ÷Μ–η“Σ÷ΗΕ® datasetΓΔbatch_sizeΓΔshuffle ΚΆ num_workersΓΘ
DataLoader ΒΡΒΎ“ΜΗω≤Έ ΐ dataset Ϋ” ’“ΜΗω ΐΨίΦ·άύΒΡ ΒάΐΘ§ΗΟάύ±Ί–κΦΧ≥– torch.utils.data.DatasetΘ§≤Δ÷Ν…Ό Βœ÷ΝΫΗωΡßΖ®ΖΫΖ®ΘΚ__getitem__(self, index) ΚΆ __len__(self)ΓΘ
torchvision.datasets ÷–ΒΡΥυ”– ΐΨίΦ·άύΨΆΕΦ «’β―υΒΡΘΚ

Υυ“‘œώ mnist_train = torchvision.datasets.MNIST(train=True)Θ§mnist_train ΨΆΩ…“‘÷±Ϋ”Ζ≈Ϋχ DataLoaderΘΚtrain_loader = DataLoader(dataset=mnist_train, batch_size=1) ≤ΔΒΟΒΫ MNIST ―ΒΝΖ ΐΨίΦ·ΒΡΦ”‘ΊΤς train_loaderΓΘ
»ΐΓΔtorchvision.datasets.ImageFolder
ΥϋΩ…“‘Α―±ΨΒΊΒΡΈΡΦΰΦ–ΚΆάοΟφΒΡΈΡΦΰΉςΈΣ“ΜΗω ΐΨίΦ·≤ΔΉ‘Ε·Α¥ΗςΉ‘ΈΡΦΰΦ–Ζ÷άύΘ§ΥϋΫ” ’ΒΡ≤Έ ΐΈΣΘΚImageFolder(data_dir, data_transforms)Θ§data_dir « ΐΨίΦ·Υυ‘ΎΒΡΈΡΦΰΦ–Θ§data_transforms «…œΟφΕ®“εΒΡΆΦœώΉΣΜΜΖΫ ΫΓΘ
train_set = datasets.ImageFolder(os.path.join(data_dir, 'train'), data_transforms['train'])
test_set = datasets.ImageFolder(os.path.join(data_dir, 'test'), data_transforms['test'])train_loader = DataLoader(train_set, batch_size=5, shuffle=True, num_workers=4)
test_loader = DataLoader(train_set, batch_size=5, shuffle=True, num_workers=4)
ΙΌΖΫΈΡΒΒ’Σ»ΓΘΚ
ImageFolder Ρ§»œ“‘ΆΦΤ§Υυ‘ΎΈΡΦΰΦ–ΉςΈΣΖ÷άύ±ξ«©
- ImageFolder “Σ«σΦ”‘ΊΒΡΈΡΦΰΦ–άοΟφ «ΗςάύΆΦœώΥυ‘ΎΒΡΗςΉ‘ΒΡΈΡΦΰΦ–Θ§≤Δ“‘ΈΡΦΰΦ–Υ≥–ρΉςΈΣ±ξ«©Θ®0, 1, Γ≠, folder_n - 1Θ©
- Returns: (sample, target) where target is class_index of the target class.
ΥΡΓΔtorchvision.utils.make_grid ΚΆ plt.imshow
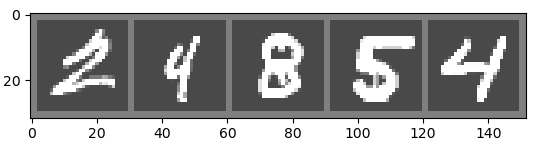
’βΗωΙΛΨΏΩ…“‘ΚήΖΫ±ψΒΊΩ… ”Μ· ΐΨίΦ·ΓΘ’βάο ΜΙ”–ΗϋΕύΖ«≥Θ Β”ΟΒΡ torchvision.utils ΒΡΩ… ”Μ· ΨάΐΓΘ
”–ΝΥ ΐΨίΦ”‘ΊΤς train_loaderΘ§Έ“Ο«Ω…“‘Κή»ί“ΉΆ®ΙΐΒϋ¥ζά¥ΒΟΒΫ“ΜΗω batch_size ¥σ–ΓΒΡΆΦœώΚΆ±ξ«© ΐΨίΉιΘΚ
imgs, labels = next(iter(train_loader))
Ε®“ε“ΜΗω±ψάϊΒΡΆΦœώ≤ιΩ¥Κ· ΐΘΚ
def imshow(imgs):imgs = imgs / 2 + 0.5 # ΡφΙι“ΜΜ·Θ§œώΥΊ÷Β¥”[-1, 1]ΜΊΒΫ[0, 1]imgs = imgs.numpy().transpose((1, 2, 0)) # ΆΦœώ¥”(C, H, W)ΉΣΜΊ(H, W, C)ΒΡnumpyΨΊ’σplt.imshow(imgs)plt.show()
ΈΡΒΒ’Σ»ΓΘΚ
plt.imshow() ΒΡΆΦœώ≤Έ ΐΈΣΘΚnumpy array-like or PIL imageΘ§≤Δ«““Σ«σœώΥΊ÷ΒΈΣ [0,1] «χΦδΒΡ float άύ–ΆΜρ [0, 255] «χΦδΒΡ uint8 άύ–ΆΓΘ
Υυ“‘Ψ≠Ιΐ transforms.ToTensor() ΉΣΜΜΙΐΒΡ PIL img ÷Μ–ηΉΣΜΊ img.numpy() “‘ΦΑΒς’ϊΆ®ΒάΥ≥–ρΦ¥Ω…Θ§≤Μ±Ί“Σ≥Υ“‘ 255ΓΘ
œ÷‘ΎΜώ»Γ“ΜΗω image grid ΆΦœώ’ΛΗώΘ§±ψ”Ύ≥…Ήι’Ι ΨΆΦœσΘΚ
img_grid = torchvision.utils.make_grid(imgs)
ΉςΜ≠ΘΚ
imshow(img_grid)