
论文复现:Progressive Growing of GANs for Improved Quality, Stability, and Variation
一、简介
本文提出了一种新的训练 GAN 的方法――在训练过程中逐步增加生成器和鉴别器的卷积层:从低分辨率开始,随着训练的进行,添加更高分辨率的卷积层,对更加精细的细节进行建模,生成更高分辨率和质量的图像。
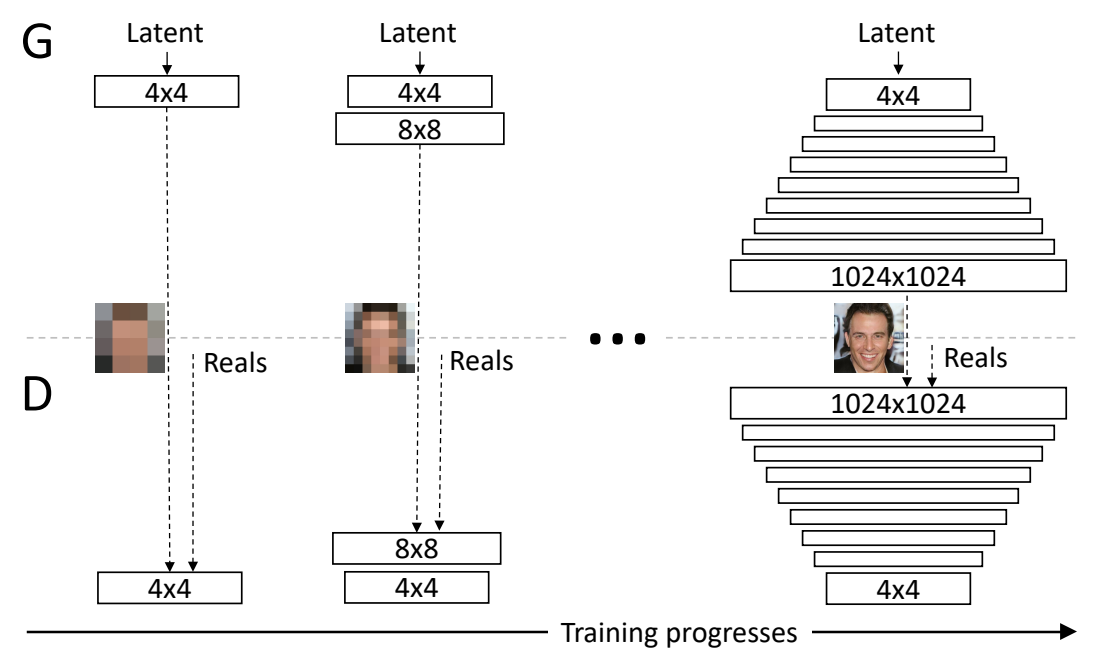
这个方法既加快了 GAN 的训练速度,又增加了训练的稳定性,因为预先训练的低分辨率层能给更难收敛的高分辨率层带来更有利于训练的隐藏编码。
本文还提出了一种新的评估 GAN 生成图像的指标――Sliced Wasserstein Distance(SWD),来评估源图和生成图像的质量和变化。
论文链接:Progressive Growing of GANs for Improved Quality, Stability, and Variation
赛场:
- 飞桨论文复现挑战赛(第四期)
- 飞桨论文复现挑战赛(第四期)榜单
二、复现精度
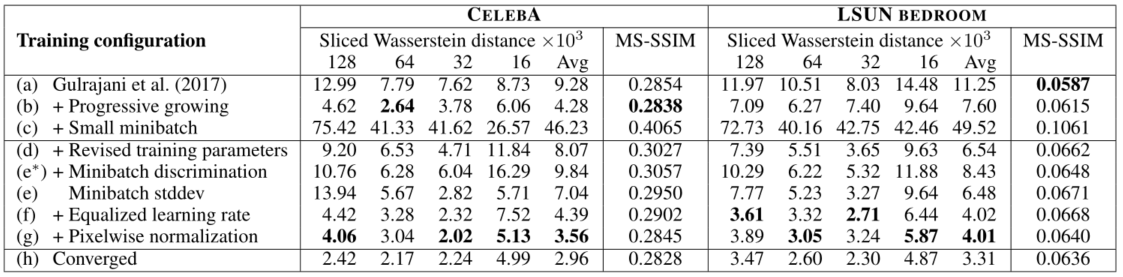
参考官方开源的 pytorch 版本代码 https://github.com/facebookresearch/pytorch_GAN_zoo,基于 paddlepaddle 深度学习框架,对文献算法进行复现后,本项目达到的测试精度,如下表所示。 参考文献的最高精度为 CelebA MS-SSIM=0.2838, SWD=2.64(64)
| 指标 | SWD × 1 0 3 10^3 103 | MS-SSIM |
|---|---|---|
| 分辨率 | 128、64、32、16 | 128 |
| paddle 版本精度 | 4.46、2.61、4.98、11.41 | 0.2719 |
| 参考文献精度 | 4.62、2.64、3.78、6.06 | 0.2838 |
超参数配置如下:
详见
PGAN-Paddle/models/trainer/standard_configurations/pgan_config.py
| 超参数名 | 设置值 | 说明 |
|---|---|---|
| miniBatchSize | 32 | Mini batch size |
| initBiasToZero | True | 是否把网络的 bias 初始化为 0? |
| perChannelNormalization | True | Per channel normalization |
| lossMode | WGANGP | loss mode,默认 |
| lambdaGP | 10.0 | Gradient penalty coefficient (WGANGP) |
| leakyness | 0.2 | Leakyness of the leakyRelU activation function |
| epsilonD | 0.001 | Weight penalty on D ( x ) 2 D(x)^2 D(x)2 |
| miniBatchStdDev | True | Mini batch regularization |
| baseLearningRate | 0.001 | Base learning rate |
| GDPP | False | 是否使用 GDPP loss 加入训练? |
三、数据集
本项目使用的是 celeba 数据集。(CelebA)是一个大规模人脸属性数据集,拥有超过 20 万张名人头像。该数据集中的图像包含大量姿势变化和背景噪音以及模糊。
-
数据集概述:
- 图像数量:202599 张人脸图像
- 图像大小:178 × 218 分辨率
- 数据集名称:
img_align_celeba
-
数据集链接:CELEBA
四、环境依赖
- 硬件:
- x86 cpu(RAM >= 16 GB)
- NVIDIA GPU(VRAM >= 32 GB)
- CUDA + cuDNN
- 框架:
- paddlepaddle-gpu==0.0.0(nightly build 版本)
- 其它依赖项:
- numpy >= 1.19.2
- scipy = 1.6.2
- h5py = 3.2.1
- imageio = 2.9.0
五、快速开始
5.1 训练
step1: 数据预处理
在开始训练之前先解压下载的 img_align_celeba.zip 数据集,然后使用 datasets.py 脚本对解压后的数据集进行预处理:
每个图像会被 cropped 到 128×128 分辨率
python datasets.py celeba_cropped $PATH_TO_CELEBA/img_align_celeba/ -o $OUTPUT_DATASET
处理完成后,会在项目根目录下生成配置文件 config_celeba_cropped.json 并自动写入了以下内容,指定了预处理数据集路径以及逐层训练的相应迭代次数:
{
"pathDB": "img_dataset/celeba_cropped","config": {
"maxIterAtScale": [48000,96000,96000,96000,96000,96000]}
}
可以在 config 中修改训练配置,比如调整 batch_size,它会覆盖 standard configuration 中的默认配置,以下是我的训练配置:
{
"pathDB": "img_dataset/celeba_cropped","config": {
"miniBatchScheduler": {
"0": 64, "1": 64, "2": 64, "3": 64, "4": 32, "5": 22},"configScheduler": {
"0": {
"baseLearningRate": 0.003},"1": {
"baseLearningRate": 0.003},"2": {
"baseLearningRate": 0.003},"3": {
"baseLearningRate": 0.003},"4": {
"baseLearningRate": 0.001},"5": {
"baseLearningRate": 0.001}},"maxIterAtScale": [48000,96000,96000,96000,96000,160000]}
}
miniBatchScheduler中可以针对不同的 scale 设置不同的 batch_size,因为随着 scale 的增加,需要减小 batch_size 来防止爆显存。configScheduler中可以针对不同的 scale 设置不同的 learning_rate。在代码PGAN-Paddle/models/progressive_gan.py中我还加入了自适应学习率衰减策略(lr.ReduceOnPlateau)。
step2: 运行训练
接着运行以下命令从零开始训练 PGAN:
python train.py PGAN -c config_celeba_cropped.json --restart -n celeba_cropped --np_vis
然后等几天(我用 T4 和百度 AI studio 的 V100,前后跑了 6 天。所以它到底加速了什么呢 ? )。。。各个阶段训练好的模型会被转储到 output_networks/celeba_cropped 中。训练完成后应该得到 128 x 128 分辨率的生成图像。
如果训练中断,重启训练时可以把 --restart 去掉,训练会从 output_networks/celeba_cropped 中保存的最新模型开始。如果想使用 GDPP loss,可以加入 --GDPP True。
output_networks/celeba_cropped 中会保存每个阶段训练完成的:
- 模型:
celeba_cropped_s$scale_i$iters.pdparams - 配置文件:
celeba_cropped_s$scale_i$iters_tmp_config.json - refVectors:
celeba_cropped_refVectors.pdparams - losses:
celeba_cropped_losses.pkl - 生成的图像:
celeba_cropped_s$scale_i$iters_avg.jpg、celeba_cropped_s$scale_i$iters.jpg,_avg.jpg图像效果更好,预测时默认使用其来计算指标。

5.2 预测
训练好的最终模型可到百度网盘自取:celeba_cropped_s5_i96000,提取码:6nv9。将其中的文件放到项目的 output_networks/celeba_cropped 中,在 .json 文件中指定 refVectors.pdparams 的路径,losses.pkl 可以没有。
如需要运行 i80000.pdparams 模型,可以把
.json文件的文件名改成对应的 i80000,因为需要通过这个文件找到refVectors.pdparams的路径。
step1: 图像生成
通过以下命令使用 output_networks/celeba_cropped 中保存的最新模型来生成图像:
python eval.py visualization -n celeba_cropped -m PGAN --np_vis
如果你想指定某个阶段的模型,加入 -s $scale 和 -i $iter:
python eval.py visualization -n celeba_cropped -m PGAN -s $SCALE -i $ITER --np_vis
以上两个命令生成的图像保存在 output_networks/celeba_cropped 中,名为:celeba_cropped_s$scale_i$iter_fullavg.jpg
随机生成一些图像:
python eval.py visualization -n celeba_cropped -m PGAN --save_dataset $PATH_TO_THE_OUTPUT_DATASET --size_dataset $SIZE_OF_THE_OUTPUT --np_vis
其中,$SIZE_OF_THE_OUTPUT 表示要生成多少张图像。
step2: 评估指标
SWD & MS-SSIM metric
运行:
python eval.py laplacian_SWD -c config_celeba_cropped.json -n celeba_cropped -m PGAN -s 5 -i 64000 --np_vis
它会在 config_celeba_cropped.json 里指定的数据路径中随机遍历 16000 张源图像及其生成图像来计算 SWD 指标,Merging the results 的过程会占用不少 CPU 内存(18 GB 左右)和时间。运行后会输出:
Running laplacian_SWD
Checkpoint found at scale 5, iter 64000
Average network found !
202599 images found
Generating the fake dataset...|####################################################################################################| 100.0% |####################################################################################################| 100.0%
Merging the results, please wait it can take some time...|####################################################################################################| 100.0% resolution 128 64 32 16 (background)score 0.006042 0.002615 0.004997 0.011406 ms-ssim score 0.2719
...OK
其中相应的指标数值会保存在 output_networks/celeba_cropped/celeba_cropped_swd.json 中。
六、代码结构与详细说明
6.1 代码结构
├── logs # 训练日志文件
├── models # 包含模型定义、损失函数、数据集读取、训练测试方法
│ ├── datasets # 读取数据集
│ ├── eval # 使用预训练模型进行预测、指标评估
│ ├── loss_criterions # 损失函数定义
│ ├── metrics # 评估指标
│ ├── networks # 网络模型定义
│ ├── trainer # 训练策略封装
│ ├── utils # 工具包
│ ├── UTs # 未使用
│ ├── base_GAN.py # GAN父类
│ ├── gan_visualizer.py # GAN 训练中间图像保存
│ ├── progressive_gan.py # PGAN
│ ├── README.md # models' readme
├── output_networks # 保存训练和预测结果
├── visualization # 可视化、图像保存
├── CODE_OF_CONDUCT.md
├── config_celeba_cropped.json # 数据预处理后生成的配置文件
├── CONTRIBUTING.md
├── datasets.py # 数据预处理脚本
├── eval.py # 预测、生成图像脚本
├── hubconf.py # 用于加载预训练的参考代码,未使用
├── LICENSE # 开源协议
├── README.md # 主页 readme
├── requirements.txt # 项目的其它依赖
├── save_feature_extractor.py # 未使用
├── train.py # 训练脚本
6.2 参数说明
见 二、复现精度
6.3 训练流程
见 五、快速开始
执行训练开始后,将得到类似如下的输出。每 100 个迭代会打印当前 [scale: iters] 以及生成器损失、辨别器损失。
一个 scale 代表添加了一层,scale = len(maxIterAtScale),maxIterAtScale 指定了逐层训练的每层相应迭代次数。
config_celeba_cropped.json:
{
"pathDB": "img_dataset/celeba_cropped","config": {
"maxIterAtScale": [48000,96000,96000,96000,96000,96000]}
}
开头的 loss 会比较大,大小与设置的 batch_size 成正比,到 3000 个迭代后 loss 趋于稳定,稳下来的时间或许也跟设置的 batch_size 大小有关。
Running PGAN
size 10
202599 images found
202599 images detected
size (4, 4)
202599 images found
Changing alpha to 0.000
[0 : 100] loss G : 614.970 loss D : 750532.237
[0 : 200] loss G : 1535.155 loss D : 322471.667
[0 : 300] loss G : 1557.878 loss D : 211534.072
[0 : 400] loss G : 1459.596 loss D : 155299.552
[0 : 500] loss G : 1289.707 loss D : 108436.870
[0 : 600] loss G : 926.709 loss D : 85481.609
[0 : 700] loss G : 616.158 loss D : 55485.711
[0 : 800] loss G : 521.535 loss D : 37811.031
[0 : 900] loss G : 426.269 loss D : 31965.410
[0 : 1000] loss G : 330.425 loss D : 24301.256
[0 : 1100] loss G : 183.268 loss D : 19704.261
[0 : 1200] loss G : 53.901 loss D : 16482.146
[0 : 1300] loss G : -63.348 loss D : 11397.357
[0 : 1400] loss G : 22.371 loss D : 8459.339
[0 : 1500] loss G : -13.653 loss D : 6577.623
[0 : 1600] loss G : 8.768 loss D : 6329.811
[0 : 1700] loss G : -2.990 loss D : 4607.002
[0 : 1800] loss G : 29.571 loss D : 3684.394
[0 : 1900] loss G : 27.713 loss D : 3607.460
[0 : 2000] loss G : -43.031 loss D : 2106.303
[0 : 2100] loss G : -95.974 loss D : 1928.345
[0 : 2200] loss G : -74.860 loss D : 2405.030
[0 : 2300] loss G : -65.015 loss D : 1664.527
[0 : 2400] loss G : -62.593 loss D : 1063.161
[0 : 2500] loss G : -12.376 loss D : 1379.406
[0 : 2600] loss G : 36.092 loss D : 549.926
[0 : 2700] loss G : 49.579 loss D : 691.503
[0 : 2800] loss G : 49.356 loss D : 52.687
[0 : 2900] loss G : 31.852 loss D : 570.363
[0 : 3000] loss G : 54.769 loss D : 382.479
[0 : 3100] loss G : 62.957 loss D : 491.729
[0 : 3200] loss G : 39.215 loss D : 37.412
[0 : 3300] loss G : 29.801 loss D : 215.652
[0 : 3400] loss G : 20.525 loss D : 27.800
[0 : 3500] loss G : 18.882 loss D : 338.726
[0 : 3600] loss G : 39.331 loss D : 128.357
[0 : 3700] loss G : -11.004 loss D : 93.745
[0 : 3800] loss G : 4.962 loss D : 205.661
[0 : 3900] loss G : 10.032 loss D : 187.112
[0 : 4000] loss G : 15.935 loss D : 11.016
[0 : 4100] loss G : 43.358 loss D : 183.713
[0 : 4200] loss G : 5.674 loss D : 5.614
[0 : 4300] loss G : -21.695 loss D : 285.515
[0 : 4400] loss G : 5.493 loss D : 9.029
6.4 测试流程
见 五、快速开始
使用最终的预训练模型 celeba_cropped_s5_i96000.pdparams 生成的图像如下:

七、实验数据比较及复现心得
miniBatchSize
原文的实验中,PGAN 的 batch_size 配置是 64,不是源码中默认设置的 16,batch_size = 16 的配置在论文中是在添加高分辨率层之后才下调的(也起到降低显存的效果),如果从头到尾都使用 batch_size=16 会导致图像生成的效果不好。但是为了防止显存溢出,我使用配置文件设置动态适应每个 scale 的 miniBatchSize。
SWD metric
预测过程会在整个 celeba_cropped 数据集中随机采样 16000 张图像来预测并计算一个模型的不同 scale 下每对图像(输入图像和对应的生成图像)的 SWD 指标,用同样的模型每次计算得到的指标结果有所不同。如果把采样数改成几千或更少,SWD 的值会很大,但是采样数在 16000 左右,SWD 就基本不变了。既然都是在训练集中采样的,模型应该是拟合了所有 20 多万张头像的信息,为何采样数量少的情况下 SWD 指标会变大,我暂时不明白。
MS-SSIM metric
由于源代码没有提供 MS-SSIM 的实现,我参考 GitHub 的开源 pytorch 版本 https://github.com/VainF/pytorch-msssim/blob/master/pytorch_msssim/ssim.py 来计算 MS-SSIM 指标,得到的结果跟论文中在 celeba 数据集上的测试结果差不多。论文中说 SWD 指标能更好反映图像质量以及结构的差异和变化,而 MS-SSIM 只测量输出之间的变化,不会反映生成图像和训练集的差异,所以在生成图像发生了明显改善后,MS-SSIM 指标也几乎没有变化,SWD 指标的结果变好了一点。
生成效果
论文中说明在规定的迭代次数内网络并没有完全收敛,而是达到指定迭代次数后就停止训练,所以生成的图像还不够完美,如果想要生成更完美的图像,那得再等上好几天?
API 转换
将 pytorch 版本代码转为 paddle 有些 API 在 paddle 中是没有的,但是 numpy 里是肯定都有的 ?,找不到的 API 用 numpy 来搭个桥,这是很不错的复现办法。
八、模型信息
| 信息 | 说明 |
|---|---|
| 发布者 | 绝绝子 |
| 时间 | 2021.09 |
| 框架版本 | paddlepaddle 0.0.0 (develop 版本) |
| 应用场景 | GAN 图像生成 |
| 支持硬件 | GPU、CPU(RAM >= 16 GB) |
| CELEBA数据集下载 | CELEBA |
| AI Studio 地址 | https://aistudio.baidu.com/aistudio/projectdetail/2351963 |
| Github 地址 | PGAN-paddle |
License
#encoding=utf8
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at# http://www.apache.org/licenses/LICENSE-2.0# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.