计数排序->桶排序->基数排序,三者的排序思想是相通的,是逐渐复杂,使用性更广的.(个人理解,欢迎指正,wiki上说基数排序是桶排序的变形,两者的方法相似,都是分配和收集.百度百科说基数排序又叫bucket sort,基数在这里个人理解就是基座,如果当前数的要分配的那一位与基座一致,就放进对应基座的桶内)
计数排序
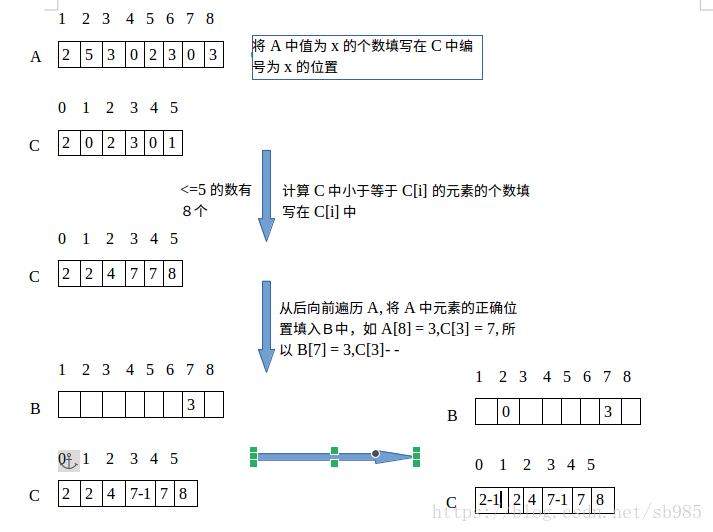
计数排序是一种根据小整数键对一组对象进行排序的算法,使用键值作为数组中的索引,因此它不是比较排序,它是一个整数排序算法。它通过计算具有每个不同键值的对象的数量并使用这些计数的算术来确定输出序列中每个键值的位置。计数排序只适合元素是整数,小规模的排序
counting_sort(A,B,k){new C[0...k];for i = 0 to kC[i] = 0;for j = 1 to A.lengthC[A[i]] = C[A[j]] +1;//C[i]中保存的就是等于i的元素的个数for j = A.length downto 1B[C[A[i]]] = A[i];C[A[j]] = C[A[j]] -1;
}
桶排序
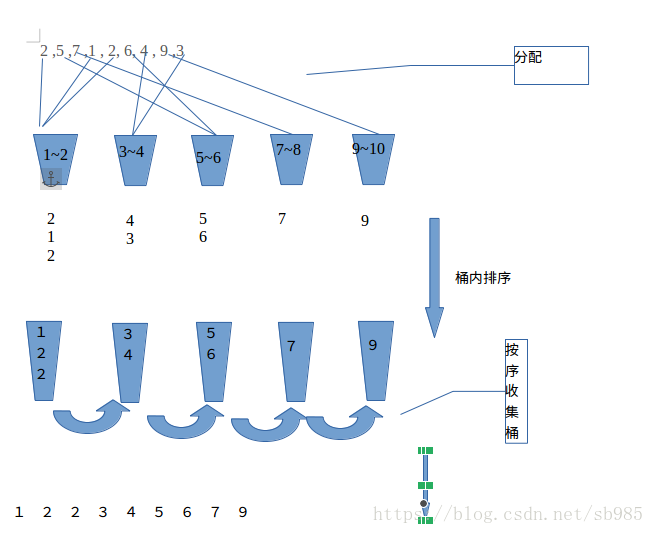
桶排序或桶排序是一种排序算法,它通过将数组元素分配到多个桶中来工作。然后,使用不同的排序算法或递归应用桶排序算法,将每个桶单独排序。
基数排序
wilki百科解释:
基数排序是一种非比较性的整数排序算法,它使用整数键对数据进行排序,方法是将键分组为具有相同重要位置和值的单个数字。需要位置表示法,但由于整数可以表示字符串(例如,名称或日期)和特殊格式的浮点数,所以基数排序不限于整数。
least significant digit (LSD) 基数排序通常使用以下排序顺序:短键(长度短)在较长的键之前,而长度相同的键按字典顺序排序。这与整数表示的正常顺序一致,例如顺序1,2,3,4,5,6,7,8,9,10,11。从个位开始向高位挪动
most significant digit (MSD)基数排序使用词典顺序,这适合排序字符串,如单词或固定长度整数表示。诸如“b,c,d,e,f,g,h,i,j,ba”的序列按字典顺序排序为“b,ba,c,d,e,f,g,h,i,j ”。如果使用词典排序来对可变长度整数表示进行排序,则从1到10的数字的表示将被输出为1,10,2,3,4,5,6,7,8,9,如同较短的按键左对齐,并在右侧用空白字符填充以使短按键与最长按键一样长,以确定排序顺序。从高位向地位开始比较,MSD的方式与LSD相反,是由高位数为基底开始进行分配,但在分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中,在进行完最低位数的分配后再合并回单一的数组中。
LSD:

1.DataDefinition.h
//链式基数排序
const int RADIX = 10;
//对于基数排序只能是int 元素类型
typedef int ArrType[RADIX];
ArrType f,e;template <class T>
struct SLCell{
//SLCell is a numberT *keys;//一个数的各个位int next;
};
template <class T>
struct SLList{SLCell<T> *SList;//将输入数依次连接起来int keynum;int recnum;
};
template <class T>
void OutPut(SLList<T> &SL){for(int i = SL.SList[0].next;i;i=SL.SList[i].next){for(int j = 1;j <= SL.keynum;j++){cout <<SL.SList[i].keys[j];//输出数字的每一位}//endforcout<<"\t";}//endforcout<<endl;
}
#endif2.RadixSort.h
#ifndef __RADIXSORT__
#define __RADIXSORT__
#include "DataDefinition.h"template <class T>
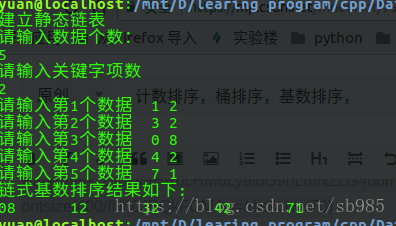
void InitSLList(SLList<T> &SL){//创建静态链表cout<<"建立静态链表"<<endl<<"请输入数据个数:"<<endl;cin >>SL.recnum;SL.SList = new SLCell<T>[SL.recnum+1];cout<<"请输入关键字项数"<<endl;cin >>SL.keynum; //关键字的位数,也是基的个数//创建基,SL.SList[i]是输入第i个数,SList[i].key[j]是第i个数的第j位for(int i = 1;i <= SL.recnum; ++i){//为每个数创建keynum位,因为下标j从1开始,所以创建keynum+1个元素的数组SL.SList[i].keys = new T[SL.keynum+1]; //创建一个桶(基),以i为基底}//endfor//输入数据SL.SList[0].next = 1;for(int i = 1;i <= SL.recnum; ++i){cout<<"请输入第"<<i<<"个数据 ";for(int j = 1;j <= SL.keynum; j++){//输入数字的每一位cin>>SL.SList[i].keys[j];}//endfor//连接各个基底if (i != SL.recnum) {SL.SList[i].next = i+1;} else {SL.SList[i].next = 0;}}//endfor
}template <class T>
void RelList(SLList<T> &SL){//Release distributed spacefor(int i = 1;i <= SL.recnum; ++i){delete SL.SList[i].keys;}//endfordelete SL.SList;
}template <class T>
void Distribute(SLCell<T> *r,int i,ArrType &f,ArrType &e){//按第i个关键字s[i]建立RADIX个子表,使同一子表中记录的keys[i]相同//f[0..RADIX]和e[0..RADIX]分别指向各个子表中第一个和最后一个记录int j;//初始化RADIX个基底for(j = 0;j < RADIX; ++j){f[j] = 0;}//endforfor(int a = r[0].next;a;a = r[a].next){//r[0].next is the first radix,the last's next is 0//r[i] 是一个数,按照第i位进行分配,j是数r[a]的第i位的值j = r[a].keys[i];if(!f[j]){ //如果基数为j的桶为空,则将这个数的序号放进桶中,否则就添加在原始链的后面f[j] = a; //这一步只代表该基底有数,且存放链表的首地址,原序列中的第a个数} else {r[e[j]].next = a; //把原待排序数字序列中基底为j的最后一个数的下一个元素是当前元素a}e[j] = a; //e记录基为j的桶中最后放入的数在原序列中的序号}
}
template <class T>
void Collect(SLCell<T>*r,int i,ArrType &f,ArrType &e){//按keys[i]自小到大将f[0...RADIX]所指各个子表依次链接成一个链表int j;for(j=0;!f[j];++j); //找第一个非空子表,(非空桶)j是桶的编号r[0].next = f[j]; //r[0].next指向第一个非空子表中的第一个结点int t = e[j]; //基数为j的桶最后放入的数序号while(j < RADIX){for(j++;j<RADIX-1 && !f[j];j++);//找下一个非空子表if(f[j]){r[t].next = f[j]; //链接两个非空子表t = e[j]; //记录当前基底的最后一个数的序号,方便与下一个非空桶链接}}//endwhiler[t].next = 0; //t指向最后一个非空子表中的左后一个结点
}
template <class T>
void RadixSort(SLList<T> &SL){//对L做基数排序,使得L按关键字自小到大有序for(int i = SL.keynum;i>=1;i--){
//按最高位优先依次对各位进行分配和收集Distribute(SL.SList,i,f,e); //第i趟分配,按照第i位分配Collect(SL.SList,i,f,e); //第i趟收集}//endfor
}
#endif
3.RadixMain.cpp
#include <iostream>
using namespace std;
#include "DataDefinition.h"
#include "RadixSort.h"int main(int argc, char* argv[]){SLList<int> SL;InitSLList(SL);RadixSort(SL);cout<<"链式基数排序结果如下:"<<endl;OutPut(SL);RelList(SL);return 0;
}