背景
Serverless 将成为下一个十年云的默认编程范式
随着 Serverless 概念的进一步普及,开发者逐渐从观望状态进入尝试阶段,越来越多的企业用户开始将业务迁移到 Serverless 平台。在阿里集团内部,淘宝、飞猪、闲鱼、高德、语雀等核心功能稳步落地,在阿里集团外部,新浪微博、世纪联华、石墨文档、TPLink、蓝墨云班课等各行各业的企业也纷纷解锁 Serverless 使用的不同场景。Serverless 正在成为成为下一个十年云的默认编程范式。
更多案例请参考 函数计算用户案例
Serverless 降本增效免运维的特性为开发者带来了实打实的好处:基于函数计算的 Serverless 方案为蓝墨节省了 60% 左右的 IT 成本,为石墨文档节约了 58% 的服务器成本;提升码隆科技的开发效率,实现两周内功能上线;平稳支撑负载的波峰波谷相差 5 倍以上的新浪微博,每天轻松处理数十亿请求。
广告时间:欢迎加入云原生Serverless 团队(函数计算,Serverless工作流,Serverless应用引擎),以公共云、集团、开源社区三位一体的方式打造业界领先的Serverless 产品体系。职位需求见 JD,招聘长期有效,有兴趣的同学可以联系本文作者或 @Chang, Shuai(shuai.chang)。
可观测性成为 Serverless 发展的绊脚石?
随着 Serverless 的深入使用,开发者逐渐发现 Serverless 架构下的问题定位比传统应用更加困难,主要原因如下:
- 组件分布化:Serverless 架构的应用往往粘合多个云服务,请求需要流经多款云产品,一旦端到端延时变长或表现不符合预期,问题定位十分复杂,需要依次去各个产品侧逐步排查。
- 调度黑盒化:Serverless 平台承担着请求调度、资源分配的责任,实时弹性扩容会带来不可避免的冷启动,Serverless 的资源伸缩是无需开发者参与也不受开发者控制的。冷启动会影响端对端延时,这次请求有没有遇到冷启动,冷启动的时间都消耗在哪些步骤,有没有可优化的空间都是开发者急于知道的问题。
- 执行环境黑盒化:开发者习惯于在自己的机器上执行自己的代码,出了问题登录机器查看异常现场,查看执行环境的 CPU/内存/IO 情况。面对 Serverless 应用,机器不是自己的,登也登不上,看也看不了,开发者眼前一片漆黑。
- 产品非标化:在 Serverless 场景下,开发者无法控制执行环境,无法安装探针,无法使用开源的三方监控平台,调查问题的方式不得不发生改变,传统的调查问题经验无法施展,非常不顺手。
函数计算是阿里云的 Serverless 产品,在过去的一年,函数计算团队为了更好地回答以上问题做了很多努力。
本文主要介绍函数计算在可观测性上的尝试与函数计算可观测性现状。
Serverless 下可观测性
可观测性是通过外部表现判断系统内部状态的衡量方式。
--维基百科
在应用开发中,可观测性帮助我们判断系统内部的健康状况。在系统平稳运行时,帮助我们评估风险,预测可能出现的问题。当系统出现问题时,帮助我们快速定位问题,及时止损。
一个好的可观测性系统要帮助用户尽可能快地发现问题、定位问题并且端到端地解决问题。
在 Serverless 这种免运维的平台体系中,可观测性是开发者的眼睛,没有可观测,何谈高可用?
可观测性 1.0
图1:可观测性基础
可观测性主要包含三个部分:日志、指标、链路追踪。
和几乎所有 FaaS 产品一样,函数计算(FC)在商业化之初就支持了函数日志和指标的查看。
- 函数日志
用户在 FC 配置 SLS 的 Project 和 Logstore,FC将函数打到 stdout 的日志转存到用户的 Logstore中。用户可以通过 SLS 控制台查看函数日志,并借助 SLS 的能力对日志进行分析和聚合。
- 基本指标
FC 将指标日志推送到云监控,通过云监控提供函数调用数/错误数/函数延时/函数内存等基本指标。
函数日志和基本指标是应用的听诊器,虽然朴素简陋,却也能帮助用户发现问题,定位问题。
即使出现开发者无法排查的问题,在用户量不那么大的年代,开发同学可以为用户提供贴身服务,结合后台日志帮用户定位问题。
函数日志和指标使用详细信息请参考 配置并查看函数日志,监控指标。
可观测性 2.0 -- 云原生的可观测
随着 Serverless 的发展,越来越多的场景在 Serverless 落地,使用规模越来越大,产品架构越来越复杂,应用听诊器的可观测性 1.0 已经不能满足各行各业开发者的监控诉求。这种近乎黑盒的执行环境给开发者带来了强烈的距离感与不信任感。
开发者需要掌控自己的应用,想要知道每一个请求在函数计算经历了怎样的历程,想要看看端到端的延时长是不是因为冷启动,想要查看函数实例的执行环境,想要在请求出现异常时第一时间定位问题,想要复用熟悉的开源观测平台。
在面对这些需求时,团队内部也经过了长时间的激烈讨论,一部分同学认为我们应该支持这些需求,另一部分同学则认为这些需求某种程度上与 Serverless 本质相违背,Serverless 就是要屏蔽底层的计算资源,用户不需要关心底层计算资源的情况。另一方面我们暴露了这些指标有什么用呢,用户就算看到了有冷启动,看到了系统时间消耗,看到了底层实例的 CPU,用户又不能有任何实质操作,这些指标真的意义吗?这两种观点争论不休,而我,是坚定的反对者。
后来团队搬到了 EFC,每天都要等待着那不知什么时候会来的电梯(输入你要去的楼层,去对应的电梯安静地等待,看不到电梯目前所在楼层)。电梯告诉我们,你就在这里等哦,我肯定会来的,但是我现在到了哪层,我什么时候下来你大可不必知道,你知道了也没用,我的这个调度肯定是最优的,你要相信专业电梯的调度算法。可是,我怎么能相信你呢?
于开发者而言,函数计算也是那不知什么时候会来的电梯吧,我们和开发者说您的请求我们一定会稳定执行的,您的执行环境一定很健康,请求过多我们会自动扩容的,但是当前实例的监控指标,我什么时候扩容您大可不必知道,我们的调度肯定是最优的,您要相信专业研发团队的调度算法。同样的,开发者又怎么相信我们呢?
Serverless 的可观测性不单单要帮助开发者排查问题,也要逐步揭开 Serverless 那层神秘的面纱,赢取开发者对 Serverless 的信任。
于是有了函数计算可观测性 2.0,我们希望可观测性 2.0 可以成为应用的心电图。

图2:函数计算可观测性现状
- 为了回答请求在函数计算的生命历程,串联分布式系统的上下游服务,拥抱开源可观测能力,我们集成了 OpenTracing,支持链路追踪。
- 为了暴露系统状态,提供应用级别监控,我们集成了 ARMS(Java),内置了 APM 能力。
- 为了加快端到端定位问题的速度,我们支持了请求级别指标(FC Insights),发布了监控中心,问题发现/调查一站式解决。
- 为了兼容开发者已有的用户体验,我们拥抱开源,集成 OpenTracing,支持 Grafana Dashboard;我们支持三方监控平台,实现代码几乎零改造接入APM 监控系统。
- 为了兼容传统开发者的可观测体验,支持探针安装,我们拓展了编程模型,支持函数LifeCycle,为集成三方监控提供可能。

图3:函数计算兼容开源可观测能力
相比于自己发明创造 FaaS 可观测性新体验,函数计算兼容开源可观测能力,集成 Jaeger,支持 Grafana 大盘,也支持以非常小的改动接入 New Relic 等优秀三方监控平台。函数计算是首家兼容开源、拥抱容器生态和云原生开发者的 FaaS 提供商,可观测体验的平滑迁移支撑应用在容器和 Serverless 平台的平滑迁移。
集成OpenTracing,支持链路追踪
FC 与链路追踪服务集成,为开发者提供了完整的调用链路还原、调用量统计、链路拓扑分析、冷启动定位等工具。帮助开发者快速分析和诊断分布式架构下的性能瓶颈。
FC 链路追踪具有以下特点:
? 拥抱开源:完全兼容OpenTracing 协议,没有附加学习成本;
? 主动记录:上报请求在函数计算中消耗的端对端时间;
? 调度透明:暴露代码准备时间与实例启动时间,是首个暴露冷启动延时与具体时间消耗的 FaaS 产品;
? 承上启下:串起上下游应用,既可以通过span context 与上游应用连接,又将 span context 传入函数,连接下游服务。

图4:链路追踪链路示例
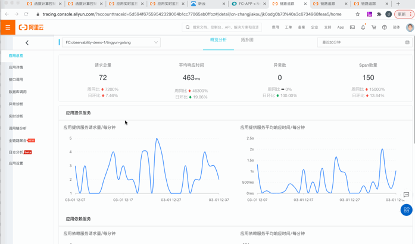
图5:链路追踪综合能力详情
集成 ARMS,内置 APM 能力
FC 无缝对接 ARMS 应用监控,开发者只需为函数新增一个环境变量即可开启 APM 应用监控功能,ARMS 探针以对代码无入侵的方式监测应用性能,提供应用级别的可观测性,包括函数实例的 CPU、内存指标、Java 虚拟机指标、代码 Profiling 信息、SQL 查询等函数实例的指标。
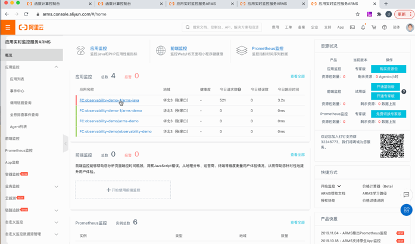
图6:ARMS 示例
发布监控中心(Insights),问题发现调查一站式解决
FC 支持请求级别指标,通过为用户每个请求多打一条指标日志的方式为请求装上摄像头。通过请求级别指标,用户可以清楚地看到请求的执行时间、使用内存,是否异常、错误类型、冷启动情况,traceID 等信息。也可以基于请求级别指标串联起所有的可观测性能力。
监控中心则是 FC 可观测性能力的集大成者,监控中心集成了 Metrics、Logs、Tracing的能力,可以在一个站点完成预览指标、查看日志、分析链路的能力,争取做到问题发现调查一站式解决。
监控中心具有如下特点:
- 多维度:支持 Region、Service、Function、Qualifier、Request 多维度的指标,展示各个维度下的调用数和错误分布;
- 多层次:集成 Metrics、Logs、Tracing 的能力,全方位多层次对应用进行监控;
- 全链路:结合指标、日志、链路等信息,层层递进,抽丝剥茧,真正做到可以在一个站点发现问题,定位问题并解决问题。
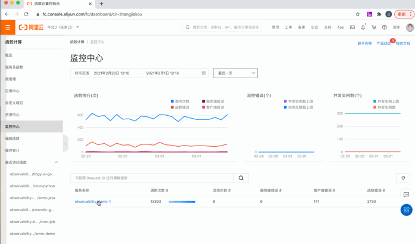
图7:监控中心示例
扩展编程模型,集成三方监控
函数实例的生命周期完全由平台控制,用户无法控制实例的启动与回收,也不感知实例的暂停与重启,这就使得在函数计算上执行除主线程外的背景线程格外困难。监控探针就是诸多重要的背景线程的一种。
FC 扩展了编程模型,发布 Runtime LifeCycle 功能,Runtime LifeCycle 会监听函数实例生命周期事件,允许函数实例在暂停和回收前回调用户的函数逻辑。这一功能的发布使 FC 集成三方 APM 监控成为可能。用户只需要在实例暂停前将采集的指标发出去、在实例回收前将内存中的数据清理掉就可以在 APM 平台上实时地查看监控指标了。
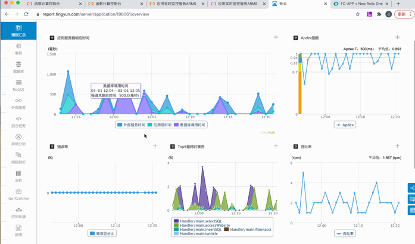
图8:Tingyun APM 示例
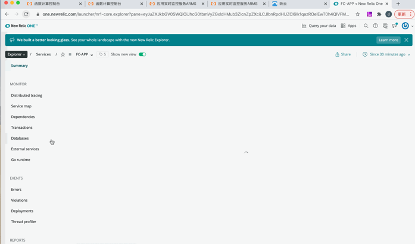
图9:NewRelic APM 示例
总结
函数计算可观测性经历了 1.0 -> 2.0 的发展,从闭门造车的可观测发展成开源的可观测,从平台的可观测发展为开发者的可观测,从FaaS Only 的可观测演进成了云原生的可观测。
作为首家兼容开源可观测、拥抱容器生态和云原生开发者的 FaaS 提供商,函数计算也将更有实力实现开发者业务的平滑迁移。
未来规划
FC 可观测性相比于一年前前进了一小步,从黑盒的可观测演进成了微弱烛光的可观测,但距离 “Serverless 应用白盒化” 的目标还有着很长的路要走。我们希望能够兼容开发者的监控体验,支撑着用户平滑地放心地将业务迁到 Serverless 上来。
接下来我们会继续投入做以下事情:
- 完善监控中心,支持报警配置,预警异常指标;
- 提供实例级别指标,做到代码问题可定位,环境现场可追溯;
- 集成开源项目,集成 Prometheus,Opentelemetry,配置 Grafana 大盘;
- 丰富指标内容,目前还有一些指标是不好透出的,没有暴露的,我们要逐步都暴露出来;
- ... ...
希望函数计算的可观测性成为一盏灯,照亮每一个 Serverless 应用。