WeaQA:Weak Supervision via Captions for Visual Question Answering论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 VQA中的鲁棒性
- 3.2 无监督的QA
- 3.3 弱监督学习
- 3.4 视觉特征提取
- 四、合成Q-A问题对的框架
-
- 4.1 问题的产生
-
- 4.1.1 基于模板的方法
- 4.1.2 提问语义标签
- 4.1.3 改述或回译
- 4.2 与VQA-V2和GQA相关的领域迁移
- 五、方法
-
- 5.1 空间金字塔块
- 5.2 编码器模块
- 5.3 Mask Question Answering(MQA)
- 5.4 Image-Text Matching (ITM)
- 5.5 Sub-phrase Weighted Answer Loss
- 六、实验步骤
- 七、结果
- 八、讨论与结论
- 参考文献推荐
写在前面
??这是一篇采用弱监督方式解决VQA的文章,与上一篇: Visual Question Answering with Textual Representations for Images 论文笔记有异曲同工之妙,但是这一篇更加花里胡哨一点。前者只采用问题+图像描述作为VQA模型的输入,后者采用图像+视觉字幕的方法取代监督的Q-A问答对,也就是本文标题所说的WeaQA。另外,前者采用的图像描述中包含了视觉字幕,这两者我一开始以为差不多的工作,看完后发现两篇文章都有各自的idea。
- 论文地址:WeaQA:Weak Supervision via Captions for Visual Question Answering
- 代码:未开源~
- 收录于 ACL 2021
一、Abstract
??首先指出现有的问题:VQA模型极大依赖于标注好的数据以及难以泛化到新的问题类型和场景上。同时由于标注人员的主观想法,使得模型可能存在bias,因此就有了这篇文章。
??本文研究 在没有人为标注的Q-A情况下,仅仅依赖于问题和文本描述或者字幕,来建模VQA。另外,本文采用图像空间金字塔Patches来代替原来的box-annotation特征作为模型的图像输入,节约了计算成本。实验在VQA-CP上的效果很好。这里照例吐槽一下,原本的VQA-CP给你们用来衡量模型的泛化性的,现在成了指标,批评,这必须得批评,下一篇文章就写。
二、引言
??照例讲述一下VQA和VQA中的bias,然后引出本文。为了避免使用人为标注,采用一种无监督的方式来训练模型,所用数据为合成的训练数据,而这些训练数据是从字幕中逐渐产生的,例如采用模板的方法。接下来就是解释为什么采用字幕数据作为合成数据集的源头,原因主要是现有的字幕数据集多,人为参与少,字幕生成的答案有多种形式等。那么接下来如何合成训练数据?作者提出了三种方法:基于模板的方法,基于回译的方法,使用QA-SRL合成图像语义问题。数据集样本如下图所示:

??另外作者这里解释了弱监督的含义,由于合成的数据集不存在来自评估数据集中的领域和标签迁移,因此本文提出的方法为弱监督方法。此外,本文的亮点之一在于没有用boudning box特征,而是直接采用的图像块的空间金字塔特征。本文的贡献如下:
- 从Captions中引入一种合成Q-A对 用于合成数据集;
- 提出了一种子阶段权重损失来弥补bias;
- 提出预训练任务:使用图像Patch金字塔来代替object-bounding特征;
- 无监督的实验很成功。数据集:VQA-v2、VQA-CP、GQA。
三、相关工作
3.1 VQA中的鲁棒性
??评估鲁棒性的标志:领域迁移和标签/答案迁移
- 领域迁移
S∩T≠TS\cap T\neq TS∩T??=T,其中S、TS、TS、T分别代表着训练和测试分布,也就是说在领域迁移中,测试集和训练集并不在同一分布中 - 标签/答案迁移
AS∩AT≠ATA_S\cap A_T\neq A_TAS?∩AT???=AT?,其中AS、ATA_S、A_TAS?、AT?分别代表着训练和测试时的答案分布,也就是说在标签/答案迁移,训练和测试时的答案并不在同一分布中。
3.2 无监督的QA
??无监督QA定义:上下文-问题-答案三元组并不提供
3.3 弱监督学习
??弱监督:主动研究的区域
3.4 视觉特征提取
??BUTP
四、合成Q-A问题对的框架
??定义为在没有任何标注的Q-A情况下回答未知的图像问题。
4.1 问题的产生
??四种方法:使用基于模板的方法+对重要的语义标签进行提问+改述 or 回译,对比上一篇,这里好像差不多?问题基于答案类型分类:是否、数量、颜色、位置、目标、短语
4.1.1 基于模板的方法
??对于yes/no的问题,举例:去掉动词,加上"is there"或者"is this";对于目标、数量、位置、颜色的问题,从字幕中提取目标和名词短语作为可能的答案,然后用whta代替。
4.1.2 提问语义标签
??采用QA-SRL对关键词进行提问。
4.1.3 改述或回译
4.2 与VQA-V2和GQA相关的领域迁移

五、方法
??所采用的数据集:MS-COCO captions,注意一下这里并没有任何人为标注的QA或者Bounding box的特征作为输入。

5.1 空间金字塔块
??利用空间金字塔特征来将图像表示为不同尺度的特征序列:图像III划分为{Ik1,?,Ikn}{\{}I_{k1},\cdots,I_{k_{n}}{\}}{ Ik1?,?,Ikn??},其中每一个IknI_{k_{n}}Ikn??都是一块ki×kik_i\times k_iki?×ki?的网格,之后利用ResNet提取每一块的特征,大的Patch编码全局特征,而小的Patch编码低水平的特征。
5.2 编码器模块
??编码器模块类似UNITER单流Transform,唯一的不同是输入的特征为Patchs的投影编码+位置编码。
5.3 Mask Question Answering(MQA)
??答案被mask掉,与VQA问题类似,只不过这里是利用合成数据集进行监督。
5.4 Image-Text Matching (ITM)
??2张图像,1条描述,判断描述和哪个图像相符,2分类问题。
5.5 Sub-phrase Weighted Answer Loss
??对于一个问题来说,可能会产生多种答案,而这些答案可能某些是符合的,所以需要对其加权,同样采用BCE损失训练:
LSWA=LBCE(σ(z[CLS]),ywa)\mathcal{L}_{S W A}=\mathcal{L}_{B C E}\left(\sigma\left(z^{[C L S]}\right), y_{w a}\right) LSWA?=LBCE?(σ(z[CLS]),ywa?)
??总体损失:
L=LMLM+LMQA+α?LITM+β?LSWA\mathcal{L}=\mathcal{L}_{M L M}+\mathcal{L}_{M Q A}+\alpha \cdot \mathcal{L}_{I T M}+\beta \cdot \mathcal{L}_{S W A} L=LMLM?+LMQA?+α?LITM?+β?LSWA?
六、实验步骤
- 数据集:VQA-V2,VQA-CP-V2,GQA
- 训练:8个 cross-modal层 dim=768, batch_size=256, Adam, 4块 V100 16G,这个还可以玩玩
- Baseline:UpDowm,也就是BUTP
七、结果
??实验结果基本上没啥看头,这里就放一起了





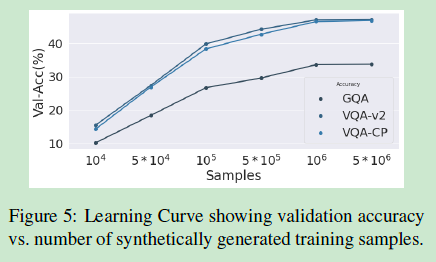
八、讨论与结论
??之前很少有方法能够不依赖于大数据的标注来研究视觉问答,本文算是其中之一。另外一个亮点在于使用金字塔的块特征来提高方法的有效性。附录是合成数据集的一些介绍,这里略去不讲,感兴趣的可以查看原文。
参考文献推荐
Damien Teney, Kushal Kafle, Robik Shrestha, Ehsan Abbasnejad, Christopher Kanan, and Anton van den Hengel. 2020c. On the value of out-of-distribution testing: An example of goodhart’s law. arXiv preprint arXiv:2005.09241.
写在后面
??连读两篇这种用字幕来描述图像的文章,最大的区别在于一个有图像的输入,一个无图像的输入,数据量也还算比较小了,推荐GPU充足的同学可以试一下~