为什么池化?
池化(Pooling)层和卷积层、全连接层一样,都是卷积神经网络的组成部分。
卷积神经网络中的卷积层会将卷积Filter应用于输入图像,以便创建特征映射来总结输入中这些特征的存在。
卷积层被证明是非常有效的,在深层模型中叠加卷积层可以让接近输入的层学习低层特征(如线条),在模型中更深(高)的层用于学习高阶或者更抽象的特征,如形状或特定对象。
卷积层特征映射输入的一个局限性是它们只能精确记录特征在输入层的位置。这意味着在输入图像中特征位置的小幅移动将导致不同的特征映射。这可以随着重新裁剪、旋转、移动以及输入图像的其他的微小变化而发生。
因此,我们将信号处理中所用的一种叫做下采样的方法应用于卷积神经网络用于解决上述问题。通过改变卷积在图像上的跨步长(stride),可以用卷积层实现下采样。一个更加robust和common的方法是使用池化层(pooling)。
哪里池化?
池化层是在卷积层之后的一个新的层。具体而言,在一个卷积层将非线性(例如:ReLU)应用到特征映射输出之后。例如,模型中的层可能看起来如下:
- Input Image 输入图像
- Convolutional Layer 卷积层
- Nonlinearity Activation 非线性激活函数
- Pooling Layer 池化层
在卷积层后添加池化层是一种常见的操作,在一个给定模型中可以出现一次或者多次。
怎么池化?
池化层涉及选择一个池化(Pooling)操作,很像应用于特性映射的过滤器(卷积核)。池化(Pooling)操作或过滤器的大小小于特征映射的大小; 很多时候,它的大小为2 × 2像素,跨度(Stride)为2像素。
这意味着池化层总是将每个特征映射的大小减少一倍,例如每个维度减半,这将每个特征映射的像素或值减少到大小的四分之一。例如,将池层应用于6 × 6(36像素)的特征映射,将产生3 × 3(9像素)的输出池特征映射。
池化(Pooling)操作是指定的,而不是学习的。池操作中使用的两个常见函数是:
- Average Pooling (平均池化): Calculate the average value for each patch on the feature map.
- Maximum Pooling (or Max Pooling) 最大池(或最大池): Calculate the maximum value for each patch of the feature map.
刚刚我们说到卷积神经网络中更深(高)的层用于学习高阶或者更抽象的特征,如形状或特定对象。某种程度上,我们可以说这是用来取代传统卷积神经网络中的全连接层。其思想是为最后一层的分类任务的每个相应类别生成一个特征映射。我们没有在特征映射的顶部添加全连接层,而是取每个特征映射的平均值,并将得到的向量矩阵直接馈入Softmax层。
Average Pooling,它是一种计算feature map的patches平均值的操作,并使用它创建下采样(pooled)特性映射。它通常用在卷积层之后。它增加了少量的平移不变性――这意味着将图像进行少量平移不会显著影响大多数合并输出的值。它提取功能比 Maximum Pooling 更平滑,而Maximum Pooling 提取更明显的特征,如边缘。
Maximum Pooling ,它是一种计算feature map的patches最大值的操作,并使用它创建一个下采样(池)特性映射。它通常用在卷积层之后。它增加了少量的平移不变性――这意味着将图像进行少量平移不会显著影响大多数合并输出的值。
Global Average Pooling,它旨在取代传统卷积神经网络中的全连接层。其思想是为最后一层的分类任务的每个相应类别生成一个特征映射。我们没有在特征映射的顶部添加完全连接的层,而是取每个特征映射的平均值,并将得到的矢量直接馈入Softmax层。它是通过增强特征映射和类别之间的对应使之更符合卷积结构。因此,特征映射可以很容易解释为类别置信度映射。另一个优点是:没有参数优化的 Global Average Pooling 可以避免在这一层因参数学习不到位而导致过拟合。此外,Global Average Pooling 汇总了空间信息,因此对输入的spatial translations(空间平移)有更强的鲁棒性(我个人的理解是:当平移input时,Global Average Pooling 出的结果可能会是不变的或是变化较为缓慢)。
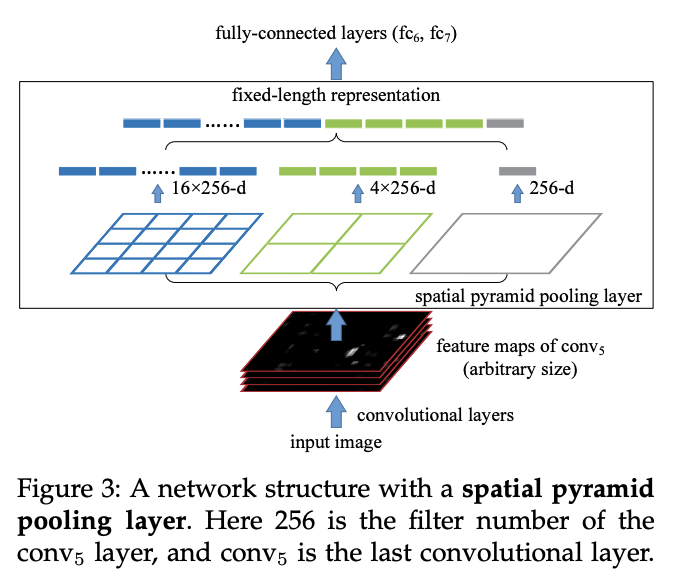
Spatial Pyramid Pooling(SPP)也是一种池化层,它消除了网络的固定大小约束,即卷积神经网络不需要固定大小的输入图像。具体来说,我们在最后一个卷积层的顶部增加了一个 SPP 层。SPP 层汇集特征并生成固定长度的输出,然后将输出送入完全连接的层(或其他分类器)。换句话说,我们在网络层次的更深层次(卷积层和完全连接层之间)执行一些信息聚合,以避免在开始时裁剪或扭曲的需要。
Center Pooling 是一种目标检测的集合技术,旨在捕捉更丰富和更易识别的视觉模式。物体的几何中心不一定传达非常可识别的视觉模式(例如,人的头部包含强烈的视觉模式,但中心关键点往往在人体的中部)。Center Pooling 的详细过程如下: 主干输出一个特征映射,并确定特征映射中的一个像素是否为中心关键点,我们需要找到其水平方向和垂直方向的最大值,并将它们相加。通过这样做,中心池有助于更好地检测中心关键点。
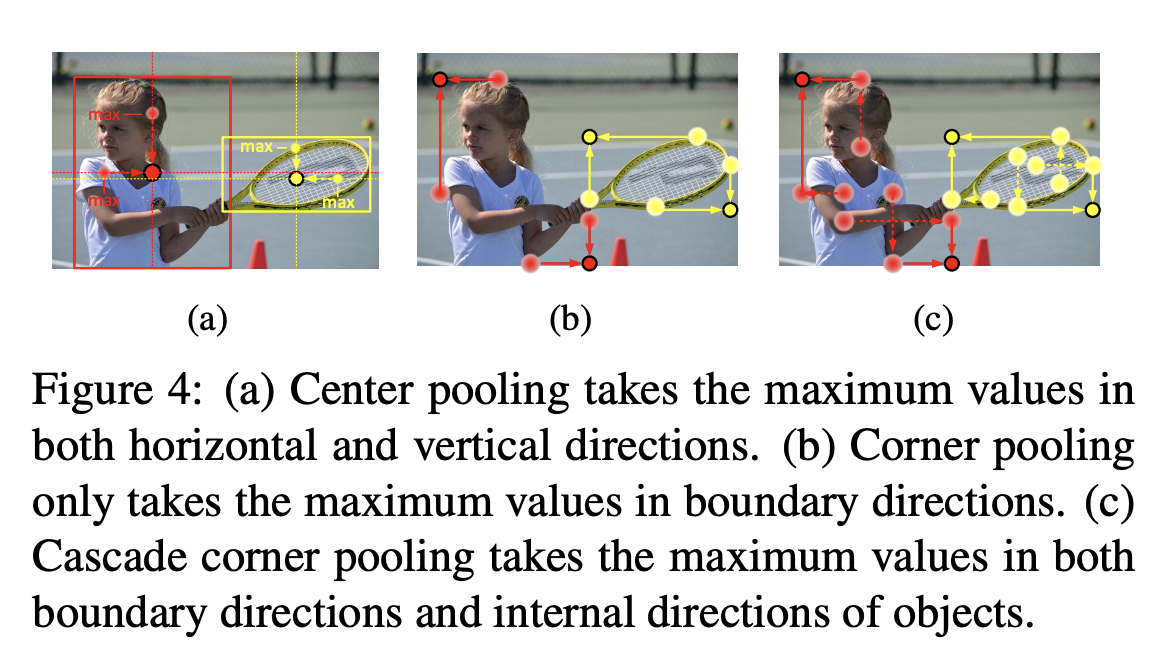
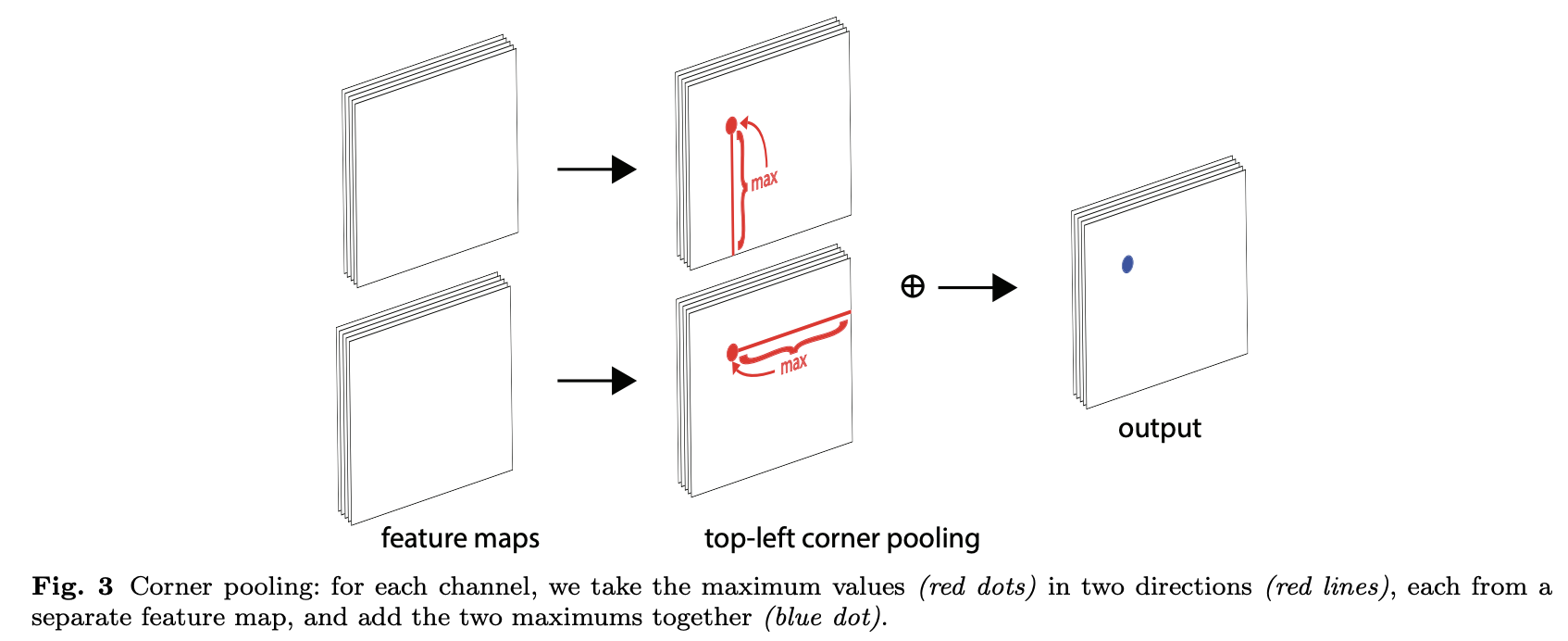
Corner Pooling 是一种针对目标检测的汇集技术,旨在通过编码显性的先验知识来更好地本地化角落。假设我们想要确定位置(i,j)上的像素是否是左上角。设 和
是特征映射,它们是左上角池层的输入,
和
分别是
和
位置(i,j)的向量。利用 h × w 特征映射,角点池层首先将(i,j)和(i,h)之间的所有特征向量以 ft 为单位转换为特征向量
,将(i,j)和(w,j)之间的所有特征向量转换为特征向量
。最后,将
和
加在一起。