- 论文作者单位:美团,阿德莱德大学
- Arxiv: http://arxiv.org/abs/2104.13840
- Github: https://github.com/Meituan-AutoML/Twins (分类、分割代码及模型均已开源)
———————————————
声明
CSDN:越来越胖的GuanRunwei
知乎:无名之辈 / IDPT集萃感知
皆为本人
———————————————
背景
AI大类顶会 Neurl 2021 总共接收到来自全球的9122篇论文,录用率26%(大概2371篇左右)。

对于NLP而言,Transformer的地位自然是无可撼动的;对于CV而言,自 DETR 与 Vision Transformer 分别从 ECCV 2020 和 ICLR 2021 横空出世,CV圈大佬们逐渐开始从CNNs抽身转而开始研究视觉变形金刚。据了解,ICCV 2021 与Vision Transformer相关的论文大概在70篇左右,而前不久刚放榜的 NeurlPS 2021 中的Vision Transformer相关工作达到了30篇之多。此外,自监督和无监督学习相关工作同样非常热门。
前言
近几年,伴随着多种用于密集预测任务的Vision Transformer架构的提出,空间注意力机制显示出对于视觉相关任务的重要性,Transformer的多头注意力机制使得它对于不管是文本还是视觉任务,在 long-range 依赖上都具有很强的灵活性,也就是说Vision Transformer相较于CNN具备了更高效提取图像上下文关系的能力。
总览
将Vision Transformer应用于视觉类任务的其中一个比较突出的问题便是来自空间自注意力操作的繁重的计算复杂度,复杂度以输入图片的像素呈二次增长。
为此,微软的Swin-Transformer提出了一种解决方案,即滑动窗口、层级设计:其中滑动窗口包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量(不客气的说这是对CNN的降维打击)。但是,虽然说它可以显著降低复杂性,但它缺乏不同窗口之间的连接,从而导致了感受野的局限性,对于目标检测和分割任务而言,感受野是一个至关重要的因素。
另一种解决方案是PVT(由南大、港大、南理工、IIAI和商汤合作完成),即引入了和CNN类似的金字塔结构(FPN),使得PVT像FPN那样作为backbone应用在dense prediction任务(分割和检测等)。PVT的优点在于:
- 可以在图像的密集分区上进行训练以获得高输出分辨率,而且可以使用渐进式缩小金字塔以减少大型特征图的计算。
- 继承了CNN和Transformer的优势,只需替换CNN backbone即可使其在各种视觉任务中成为一个统一的骨架,而不用卷积。
因此,从全局的角度看,上述的这些Vision Transformers的核心在于如何设计空间注意力。因此,本文重新审视了Vision Transformer的空间注意力设计,并发现PVT的全局下采样注意力是非常有效的,并且具备了比较合适的位置编码(性能超过了Swin这种 state-of-the-art Vision Transformer),基于此,本文设计了 ——> Twins-PCPVT(基于PVT和CPVT,仅使用全局注意力机制)
在此基础上,本文进一步提出了一个carefully-designed但是非常简单的空间注意力机制,使得整个架构比PVT更有效。本文的注意力机制受到了广泛使用的深度可分离卷积(depthwise separable convolution)的启发,所以将其命名为空间可分离自我注意力[spatially separable self-attention(SSSA)]。SSSA由两部分组成,(1)局部分组注意力[locally-grouped self-attention(LSA)] (2)全局下采样注意力[global sub-sampled attention(GSA)]。其中,LSA捕获细粒度和短距离信息,GSA处理长距离和全局信息,本文将其命名为 ——> Twins-SVT(基于交叉局部注意力和全局注意力的SSSA)
这两个框架只涉及在现代深度学习框架中高度优化的矩阵乘法,值得一提的是,本文提出的框架在图像分类和目标检测和分割(dense prediction)中都取得了不错的成绩。
Twins-PCPVT
作者发现拥有全局注意力、高分辨率、大感受野的PVT在dense prediction tasks性能之所以不如Swin-Transformer这种基于局部滑动窗口的原因主要自安于PVT使用了absolute positional encodings。这种绝对位置编码在处理不同大小的输入图片时遇到了困难(这在密集预测任务中很常见),而且这种绝对位置编码也破坏了translation invariance(平移不变性);而Swin-Transformer则使用了relative positional encodings避开了上述问题。
因此,Twins-PCPVT转而使用了CPVT中的 conditional position encoding(条件位置编码CPE)来替代PVT中的绝对位置编码。CPE以输入为条件,自然就可以避免绝对编码的上述问题。PEG位置编码生成器会生成条件位置编码CPE并将其置于每个阶段的第一个encoder block之后,本文使用了最简单的PEG形式,即不需要带有batch normalization的二维深度卷积。
对于图像分类任务而言,和CPVT一样,删除class token并在最后使用GAP全局平均池化。
对于其他视觉任务而言,Twins-PCPVT模仿了PVT的设计,且继承了PVT和CPVT的优点。
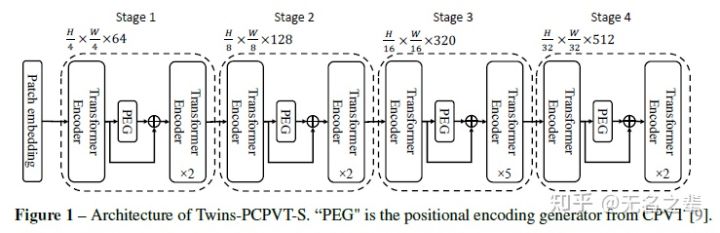
Twins-PCPVT 架构
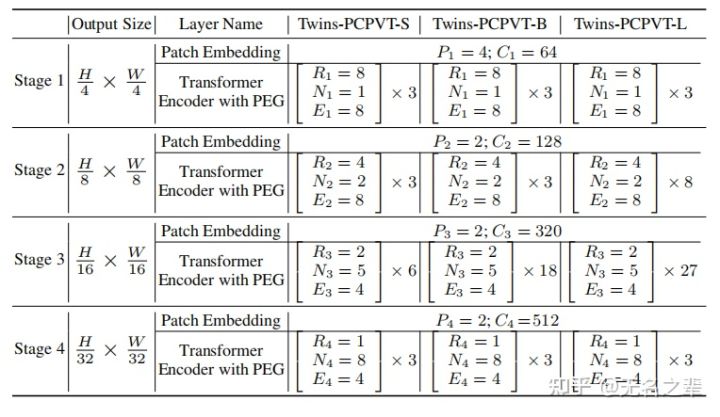
Configuration details of Twins-PCPVT
Twins-SVT
对于dense prediction tasks,vision transformer饱受高计算复杂度的困扰。为缓解这一问题,一个集成了局部自注意力机制和全局下采样注意力机制的框架诞生了,也就是Twins-SVT。
Locally-grouped self-attention(LSA)
基于depthwise convolution的group设计,本文首先将2维的feature map平均划分为多个子窗口,让自注意力机制只发生在子窗口内,这种设计也和自注意力的multi-head多头设计产生了共鸣,在多头设计中,交互仅仅发生在同一个头的不同channel中。
在Twins-SVT中,feature maps被分成了 个子窗口,那么每个window的自注意时间复杂度为
,那么所有子窗口也就是feature maps的自注意时间复杂度为
,我们假设
,那么时间复杂度可表示为
,当
且
也就是被划分的子窗口越多的时候,时间复杂度会非常低,但不能太多,因为只注意自己=没有注意。
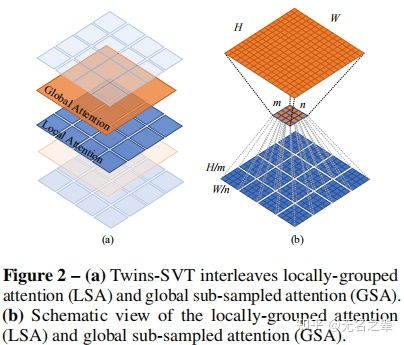
LSA and GSA
虽说LSA机制比较computational friendly,但图像是被划分为不重叠的子窗口,这会导致信息被限制在局部处理,这意味着receptive field感受野变小,而对于目标检测和分割这些dense prediction而言,小感受野是不能被接受的,同时也意味着我们不能将所有的standard convolution标准卷积替换为depth-wise convolution深度卷积。因此,为了像Swin-Transformer一样让每个子窗口的自注意矩阵交互,是时候亮出GSA了。
Global sub-sampled attention(GSA)
为了添加全局注意力,一个简单的方法便是在每个局部注意力block后添加全局注意力层,这就可以让信息跨窗口交换,那么时间复杂度又来到了 。但这似乎难不倒我们的开水厂大佬们,他们想到了一种方法使得时间复杂度显著降低 ,即使用一个single representative来汇总每个 大小的子窗口的重要信息,并使用这个representative与其他子窗口交互(serving as the key in self-attention)。那么整个过程(局部+全局注意力的过程)的时间复杂度为
,而
,最小值取自
。我们注意到在分类任务中, 图片高宽
非常common,那么我们如果取
就非常接近全局最小值了。但我们需要注意,本文的network包含了不同分辨率的stages。比如stage 1的feature map尺寸为
,那么近似最小值取得当
。对于分辨率较低的阶段,我们控制GSA的汇总窗口大小,以避免生成的keys数量太少。具体来说,我们在最后三个阶段分别使用
大小的窗口。
对于 sub-sampling 函数,作者也是调研了包括average pooling、depthwise strided convolution和regular strided convolution,实验结果表明了regular strided convolution在这里表现最好。形式上,我们可以将空间可分离自注意力(SSSA)写为:

LSA -> locally-grouped self-attention with a sub-window(局部分组自注意子窗口)
GSA -> global sub-sampled attention(全局子采样注意),通过与每个子窗口 的representative key(由sub-sampling采样函数生成)交互产生的全局下采样注意力。
同样地,我们使用CPVT的PEG编码位置信息并动态处理不同长度的输入。它被插入到每个阶段的第一个块之后。Twins-SVT 配置信息如下图所示
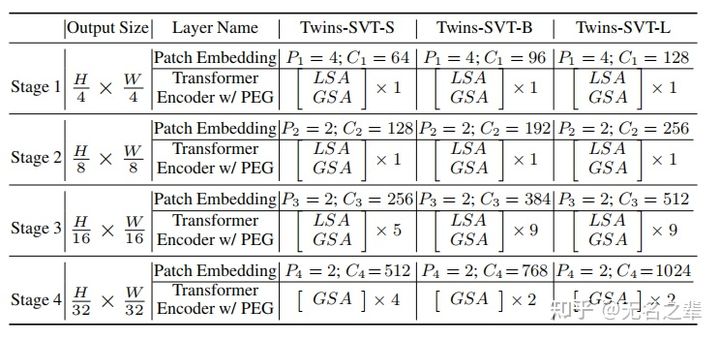
Configuration details of Twins-SVT
基于Pytorch的LSA代码:

LSA实现
效果
ImageNet-1K分类
Twins 的双子星模型 Twins-PCPVT 和 Twins-SVT 在ImageNet-1K 分类任务上同等量级模型均取得 SOTA 结果,吞吐率也占优。下图分别是双子星模型的small, big和large三种变体取得的效果。
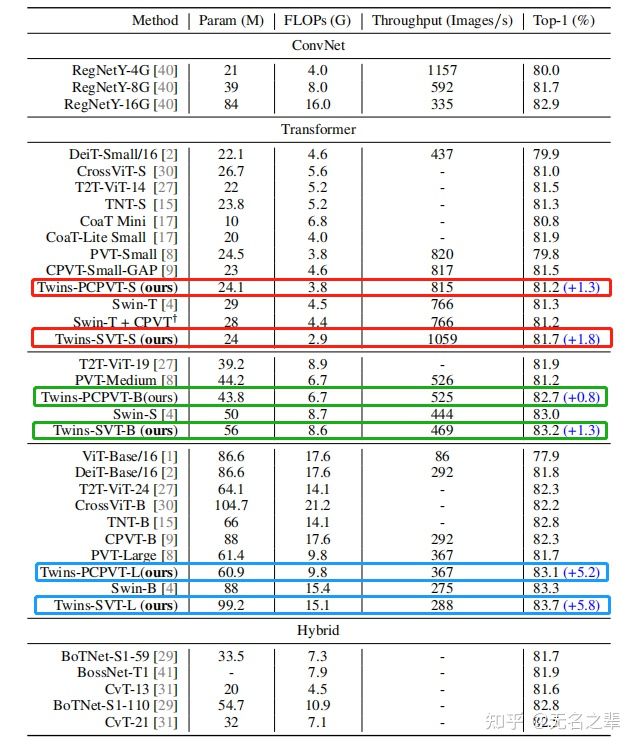
ImageNet-1K 分类
ADE20K目标分割
效果太好了,下次再也不用ResNet了
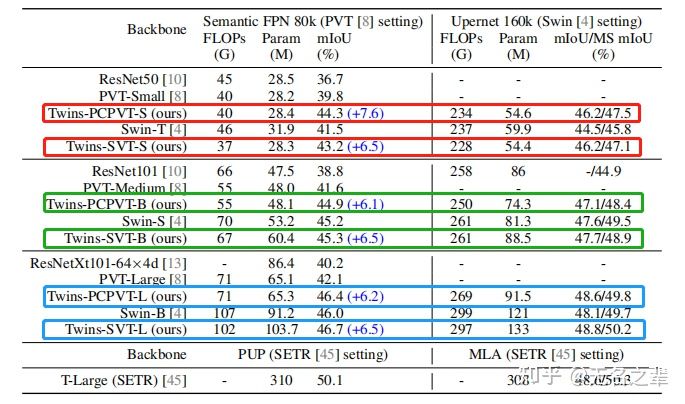
ADE20K目标分割
COCO 2017目标检测
双子星yyds
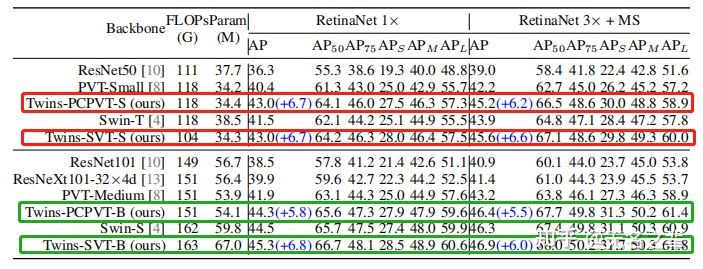
COCO 2017目标检测
总结
在本文中,作者为图像级分类和一些下游密集预测任务提出了两个强大的Vision Transformer Backbone。我们称之为Twin Transformer: Twin-PCPVT 和 Twin-SVT。
前一种变体探讨了条件位置编码在Pyramid Vision Transformer中的适用性,证实了它在许多视觉任务中改善主干的潜力。
在后一种变体中,作者重新审视当前的注意力机制的设计,提供了一个更有效的attention范式。我们发现,将局部和全局注意交叉可以产生非常好的效果,但它带来了更高的吞吐量。这两种Vision Transformer在图像分类、目标检测、语义和实例分割方面都开创了一个新局面。
题外话
为什么需要位置编码?
从语言的角度讲,对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
I do not like the story of the movie, but I do like the cast.
I do like the story of the movie, but I do not like the cast.
对于图像而言,人的嘴巴在鼻子上面,那还叫人吗?(手动旺柴)
关于深度可分离卷积
- 首先我们看下常规卷积
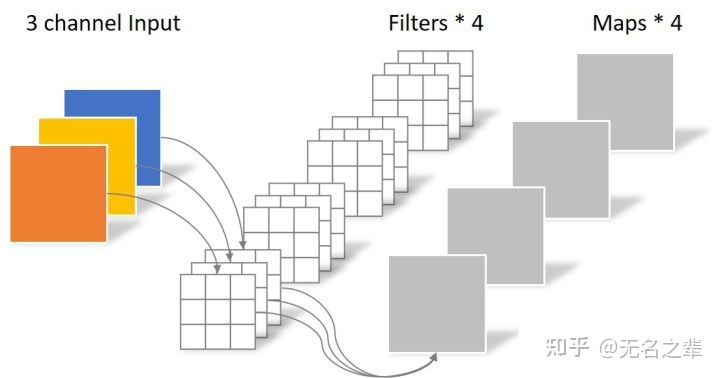
Regular Convolution
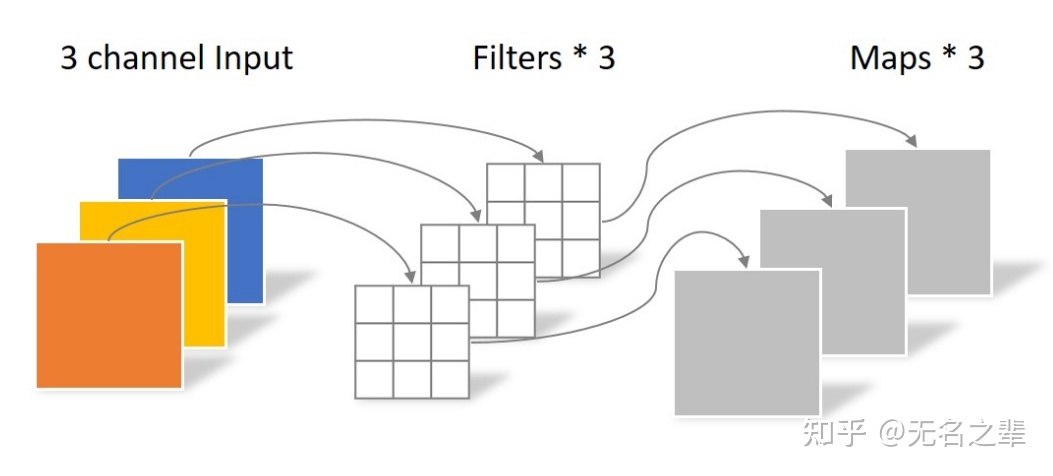
对于一张5×5像素、3通道彩色输入图片(shape为5×5×3)。经过3×3卷积核的卷积层(假设输出通道数为4,则卷积核shape为3×3×3×4),最终输出4个Feature Map,如果有same padding则尺寸与输入层相同(5×5),如果没有则为尺寸变为3×3。
此时,卷积层共4个filters,每个filter包含了3个kernel,每个kernel的大小为3×3。因此卷积层的参数数量为 N_regular = 4 × 3 × 3 × 3 = 108
2. 那什么是Depthwise Separable Convolution呢?
Depthwise Separable Convolution深度可分离卷积是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
Depthwise Convolution不同于常规卷积操作,Depthwise Convolution的1个卷积核负责1个通道,1个通道只被1个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。
Depthwise Convolution
同样是对于一张5×5像素、3通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,不同于上面的常规卷积,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(通道和卷积核一一对应)。所以一个3通道的图像经过运算后生成了3个feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所
其中一个filter只包含一个大小为3×3的kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
3. 那什么是Pointwise Convolution呢?
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。如下图所示:

Pointwise Convolution
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
N_regular = 4 × 3 × 3 × 3 = 108
Depthwise Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature maps,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
————————————————
码字不易,点个赞再走呗