―――――――――――――――
声明
CSDN:越来越胖的GuanRunwei
知乎:无名之辈 / IDPT集萃感知
皆为本人
―――――――――――――――
背景
自 DETR 与 Vision Transformer 分别从 ECCV 2020 和 ICLR 2021 横空出世,ViT的各类Variants也随之诞生。那么目前ViT们的发展状况如何呢?今天,小编就带你一探究竟。
开山之作 ―― Vision Transformer
我们都知道,Transformer的初衷是借助多头注意力机制解决seq2seq在机器翻译中对长距离上下文翻译不准确的问题,因为seq2seq中的encoder对任意句子只能给出一个固定的size表征,而这个表征在遇到长句时会显得包含的信息量不够。
ViT的标题中的“AN IMAGE IS WORTH 16X16 WORDS”可以看出,ViT将图片分割为固定数量的patches,每个patch都视作一个token,同时引入了多头自注意力机制去提取包含了关系信息的特征信息。
同样,缺点也非常明显,
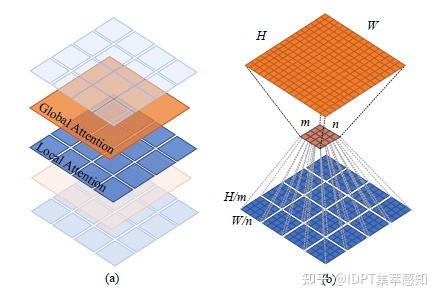
- 计算量大:计算复杂度与token的平方相关,如果输入特征图为56*56的特征图,那么会涉及3000+长宽的矩阵运算,计算量很大,同时在原始Transformer计算过程中token数以及hidden size保持不变,所以后来的研究者采用了几个方法是解决计算量大的问题。参考resnet结构使用金字塔的结构,越高层的token数量越少;使用局部窗口自注意,分别考虑特征图的一部分做自注意,再想办法把这些局部信息进行交互;使用卷积来代替全连接层,以减少参数;在生成Q,K,V过程中,对K,V的特征图或者是token做池化,减少计算复杂度。
- 训练数据需求量高:自注意力机制的inductive-bias较CNN和RNN弱,CNN具有空间不变形的假设,所以它可以用卷积核去滑窗处理整个特征映射;而RNN具有时间不变性,但是自注意力机制并没有这些假设,所以需要更多的数据去学习这些假设。
- 堆叠层数数量受限:存在过度平滑问题,不同的Block之间的相似性随着模型的加深而增加;不同token之间的相似性随着随着模型的加深而增加。
- 模型本身无法编码位置:需要各种各样的位置编码,目前了解到的包括:固定的与可学习的,绝对的和相对的,还有利用卷积的特性使用卷积去作为位置编码的。
- 参数数量大:以上4点导致的问题 或者 也可以与第2点合并
根据以上这5条缺点,后人有针对性地做出了一些改进。
针对Vision Transformer缺点的改进
针对 计算量大
PVT(Pyramid Vision Transformer)
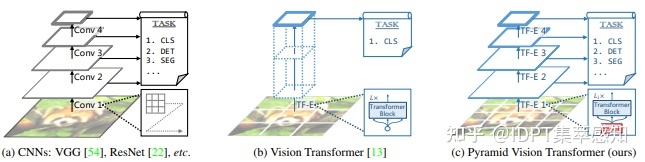
PVT
引入了CNN的金字塔结构,在stage之间通过卷积缩小token数量,并对 中的 使用额外的卷积核以缩小特征映射图的大小。
Swin Transformer
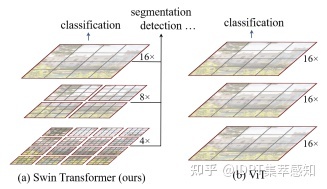
Swin Transformer
同样引入了金字塔结构,在stage之间通过拼接2*2范围内的像素点,再通过线性变换缩小token数量,并使用局部窗口降低计算复杂度,使用窗口移动使前后两层不同的窗口存在信息交流。
Twins
Twins
相较于PVT,Twins使用了相对位置编码去替代绝对位置编码,并使用局部与全局自注意力机制交替的结构一定程度上降低了计算量。
针对 训练数据需求量高
DeiT
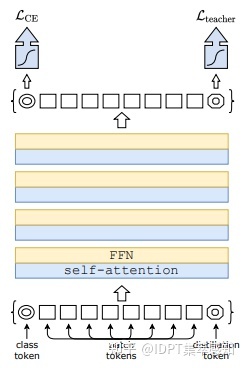
DeiT
引入了Distillation token,在训练过程中引入了蒸馏损失。
CeiT
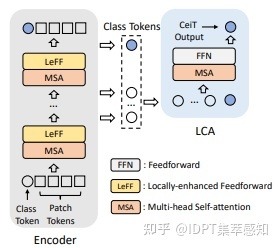
CeiT
使用多个卷积与池化代替ViT中的一个大卷积;在FFN中引入Depth Width Conv2d以融合不同patch的信息。
LV-ViT

LV-ViT
使用Re-labeling给予每个patch一个软标签进行辅助训练。
针对 堆叠层数数量受限
DeepViT
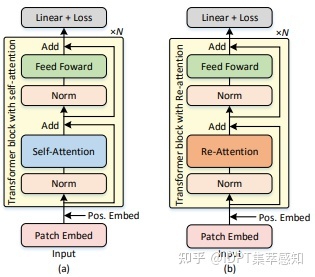
DeepViT
在Re-Attention模块中增大了hidden size
CaiT
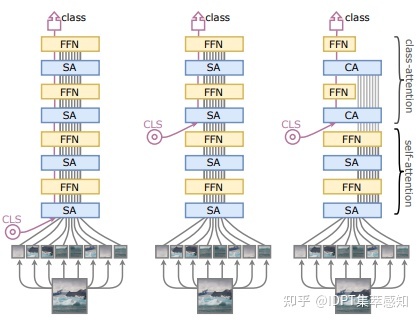
CaiT
CaiT使用了LayerScale,使用可学习参数对FFN/SA的输出在hidden size维度进行不同程度的缩放。此外,加大深层的Dropout,并使用Talking-Heads Attention。
Refiner
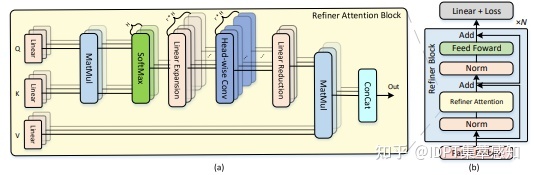
Refiner
在经过softmax的自注意力图后使用线性变换在head处提升维度,经过Depth Width Conv2d增强局部信息交互,再通过线性变换映射回原维度。
针对 模型本身无法编码位置
DETR:使用固定的位置编码
ViT:使用可学习的绝对位置编码
Twins, DVT, Swin Transformer:使用可学习的相对位置编码
CPVT, CVT:使用卷积的空间不变性编码位置信息
针对 参数数量大
DVT:Not All Images are Worth 16*16 Words
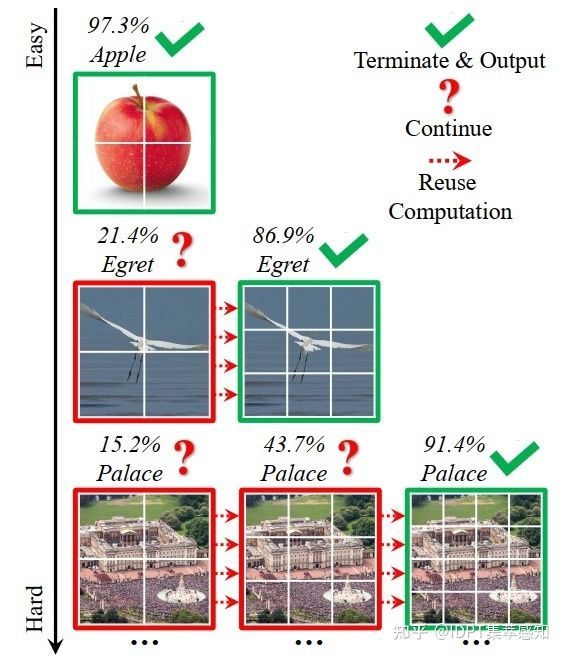
DVT
DVT认为每个图像都有自己的特征,理想情况下,tokens数量应以每个单独的输入为条件。事实上,对于相当多的“简单”图像,它们可以用仅仅数量的 4x4 标记准确预测,而只有一小部分“难”图像需要更精细的表示。
LeViT
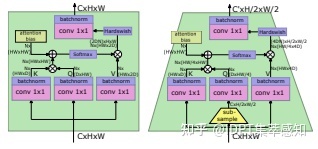
LeViT
用于快速推理的视觉Transformer。
ViT-Lite
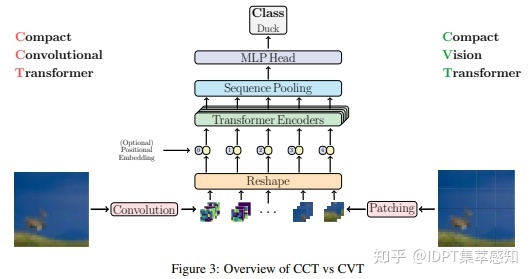
ViT-Lite
紧凑型Vision Transformer,更小更简单。
Mobile-ViT
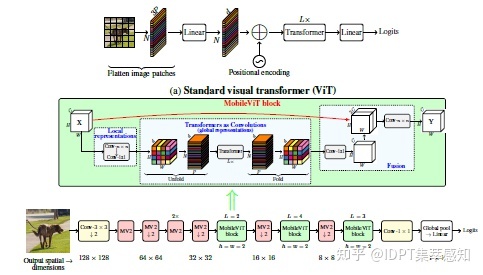
Mobile-ViT
参数个数小于MobileNetv3同时精确率和召回率较MobileNetv3有一定的提升。
总结
我们可以发现,历史的发展总是惊人的相似。Vision Transformer与CNN作为两大视觉Backbone,同样经历了:模型的提出 -> Rethinking -> 陷入自我怀疑,在Vision Transformer提出后,各路大神根据Vision Transformer的缺点进行了结构上的调整,包括计算量、训练数据量过大、堆叠层数数量受限、模型本身无法编码位置以及模型本身参数量过大这几类问题。同样,Vision Transformer的各种魔改Backbone也针对了神经网络本身存在的问题进行了有针对性的调整,包括:梯度消失、密集目标以及小目标检测困难等。
小编有话说
小编注意到Vision Transformer的introduction中提到“We find that large scale training trumps inductive bias”,以及原文conclusion中的“Unlike prior works using self-attention in computer vision, we do not introduce any image-specific inductive biases into the architecture”,会给读者一种inductive bias不是一个好东西的错觉,我们应该将其抛弃。
inductive bias可以理解为assumptions about the nature of the relation between examples and labels。如果这些assumptions跟实际数据分布的确是相符的,那么无论我们已有的数据量是大还是小,我们利用这个inductive bias应该是一个更好的选择。
inductive bias是人类通过学习、实践而归纳总结出来的knowledge,我们设计一个机器学习/深度学习模型,其实也是让模型通过训练集去学习knowledge。knowledge的好坏应该由knowledge与实际数据分布的匹配程度来衡量,而不是knowledge的来源来衡量。
反过来想,如果后面有研究者想在尽量减少inductive bias的路上一路狂奔,也许可以直接用全连接层替换self-attention。然后我们绕了个大圈又回到了几十年前的MLP,MLP-Mixer狂喜:没错,正是在下。
附:小编根据任务类型整理了近两年各大顶会关于Vision Transformer的突出成果,GitHub地址:https://github.com/GuanRunwei/Awesome-Vision-Transformer-Collection ,感兴趣的小伙伴如有补充请在仓库中发送issue或邮件发送至:thinkerai@foxmail.com,欢迎探讨学习与批评指正。