���������� Self-Supervised Representation Learning by Rotation Feature Decoupling ����ת�����������??�Ҽල��ʾѧϰ���ķ��룬�����߱���ˮƽ���ޣ������в���֮�����������߲��ߴͽ̣�лл��
ժҪ
���ǽ�����һ�����Ҽල��ѧϰ�������÷��������ڱ�ʾ���������Լ������ƹ㵽ʵ�������е��������÷�������ת��������������ѧϰ��ܣ������Ӿ���ʾ�����������Ҿ�������о�������֮һ������ǰ�Ļ�����Ⱦ�������������Ҽල�ı�ʾѧϰ�������ٶԴ˼������ͻ����á��ر��ǣ����ǵ�ģ��ѧϰ�˰�����ת��ز��ֺͲ���ز��ֵIJ�ֱ�ʾ��ͨ������Ԥ��ͼ����ת�����ֵ���ʵ����ѵ�������硣�����ǣ����ǵ�ģ�ͽ���ת�б���ʵ���б�����ʹ�����ܹ�ͨ��������ת��ǩ������Ӱ�����Ľ���תԤ�⣬Ҳ��������ʵ����������ͼ����ת���������������Ը���ĸ���������и��õ�ͨ��������ʵ�����������ڱ������Ҽල����ѧϰ���ϣ����ǵ�ģ�����ڵ�ǰ�����·�����
1 ����
��������磬�����Ǿ��������磨ConvNets������ȡ�ü�����Ӿ�������ش�ͻ�ơ��������ģ�ֶ���ǵ�ͼ�����ݼ�������ImageNet���������������ͨ�������������õ�ѵ������������������ʵ�����Ƚ������ܣ�����ͼ�����[25��45]��Ŀ����[31]����Щ������ȡ�ķḻ��ʾ��ͨ������£�����������Ϊѵ����������������ͨ�ù��ܣ����һ������������������Ӿ�������������ָ�[33]���Ӿ�������[2]�����ǣ�����ȫ�ල�ķ�ʽѵ�������������Ҫ�������ֶ���ǹ���������ijЩʵ�ʳ������Dz����еġ���Ϊ�мල������ѧϰ������������������ڰ����ҷ�ʱ�������ǩ���ල�������ܵ�Խ��Խ��Ĺ�ע��������ֵ��Լලѧϰ��ʽ[10��43��52��27��37]������ѧϰ���õ�ͨ���Ӿ���ʾ�Ŀ���չ����ϣ���Ľ����������Щ��������ʹ�����ݱ����Ľṹ��Ϣ��������ѧϰ��������������Ӧ���йصĸ�����pretext��������ѵ�������硣�ڸ�����pretext�������У�������������������ɿ����ල�źţ���˿��Խ��������ڻ�õ�ͼ��Ӧ����ѵ����
�ڹ�ȥ�ļ����У��Ѿ���������ͬ�ĸ�����pretext���������������Ҽලѧϰ�����磬��Щ�����е�һ����ͼ����һ���ֱ����лָ�һ��������[43��28��53]��Ȼ����Щ������ȱ�����ؽ���Ԥ��ͼ������ֵͨ����Ҫ�����ļ�����Դ�����������Ҳ���Ա�ѵ��������ԭʼͼ��ͻָ��IJ�����ͼ��[21]�����ǣ����ɺϳ�ͼ������һ�������¡������Ҽලѧϰ���Ѿ��о��� Siamese ������ϵ�ṹ[2��36��53]�������ڴ�����ͨ���ܴ���һ�ֲ�ͬ���ձ���õIJ���������Ƶ�з��ּල�źţ��������ͼ��[47]�Ͷ�֡���н�������[30]��
���еĴ������������������Ƹ��ָ�����pretext���������ٹ���ѧϰ�ı�ʾ��ӵ�е������Լ������Ƿ�ȷʵ��������ʵ����������ķ��������磬����ʾӦ�ô�������Ľ��ͻ�Ա仯���ص�ȷ��������[5]������ij�����Ԥ��ͼ����ת[17]��ͨ�����ַ���ѧϰ���������Ժܺõظ�����������ʵ�����µ����ܡ����ǣ���Щ��������ת�任��������ģ���˲���ʹ֧����ת�����Ե��Ӿ��������档���⣬���������������ǣ��������е�ʾ����ʵ���ж�����ת��ȷ���Եġ�ͼ��ķ�������Բ��������˵��ģ�����ɵģ����Ҷ���ͼ���з���֪����������Ҳģ�����ɣ����磬�Ӷ����۲��һЩ��Ʒ���߾��жԳ���״��ijЩ���壬��ͼ1��ʾ����ת��Щ��������Ӱ�����ǵ����������⡣

ͼ1��ImageNet��һЩ��ת����֪ͼ���ʾ������Щͼ���Ĭ�Ϸ�����ȷ��
�ڱ����У����������һ���µ��Լලѧϰ�㷨�����㷨ͨ��һ����תԤ�������һ��ʵ����������ʾ���롣ѧϰ��ʾ�������ֱ�����ת�б����ת������Ҫ����ɡ���ת�б���������ͨ��Ԥ��ͼ����ת�����֣����Ǽ���Ч�ģ�������ijЩ���Ͽ��Դﵽ���µĽ��[17]���������ݼ��е���Щ�뷽���ص�ͼ���Զ��������ת��ǩͨ����������������Ȼ�ᵼ�������δ���ѧϰ���⡣Ĭ�Ϸ����ԭʼͼ��Ϊ��ʵ��������ת��ĸ���Ϊδ���ʵ��������Ϊ�����������ȷ��ʶ�����ת�����ı任�����ǽ�����Ϊ���ޱ�Ǽ����о���Ĭ�Ϸ������ʵ������μ���������е�ͼ1������һ���棬����ͨ���ͷ���ͬͼ���ڲ�ͬ��ת�µ�����֮��ľ������ѧϰ����ת�ص�������Ӧ�÷Dz�������������Щ��ת�����������ֲ�ͬʵ������ˣ���Щ��������ʵ����������б�������
Ϊ��֤�����ǵ��Լලѧϰ��������Ч�ԣ������ڱ�����ת��ѧϰ���Ͻ�����ʵ�顣����ִ�������о��Լ��ģ�ͺͲ�ͬ�����еĸ�����������ǻ���������ת���ݼ��ϵ�������ʵ�����������б�Ҫ�о�����ת��غͲ���ص���������������ϣ�������ImageNet��Places�ϵ����Է��࣬�Լ���PASCAL VOC�ϵķ��࣬���ͷָ���Ƿ�����ѧϰ���������������·�����
2 ��ع���
������漰����ѧϰ�ͼ�����Ӿ��еĶ�����⣺�Լලѧϰ������δ��ǣ�PU��ѧϰ��ͼ����ת�����ԡ�
���Ҽලѧϰ���Լලѧϰ������һЩֱ�Ӹ����������ݼ�����ļල�źš����磬ijЩ�������Իָ��������ݱ���������ͼ��ȫ[43]��ͼ����ɫ[52��27��28]��ͨ��Ԥ��[53]����������������ͼ���еĸ�����Ϣ��Ȼ����Լ��������ͼ��߿�λ��[10��36]�����ƴͼ��Ϸ[37]������[38]����ת[17]��ʵ���б�[13��48]�������Կ�ѵ���ķ�������[12]��[21]��Norooziet�� [39] ��Caronet�� [6]ʹ�þ��������α��ǩ�����˵�������Doersch��Zisserman [11]�Լ�Ren��Lee [44]������һ��ʹ�ö��������������ܡ�������Ƶ���ල�ź��У������˶�[1��42]��ʱ�����[47��30]������[41]�����ǵķ�������Ԥ��ͼ����ת[17]����������ѧϰ��ʾ��ӵ�е����ԡ����ǽ��ص��������ת��غ��ص������ϡ�
����δ���ѧϰ����PUѧϰ�У�δ��ǵ�����ͨ������Ϊ����ʾ��������ζ��ֻ�й۲쵽�ĸ���ʾ���������ӵı�ǩ[14]������������������������������ֵ֮��Ĺ�ϵ����ģ��ǩ������[46��40]��Ȼ��ǩ����ı��ʿ�ͨ�����ַ�ʽ���ڴ������ӵĹ۲⸺�����������ų����ŶȽϵ͵�����[40]��������ŶȽϸߵ�����[49��23��19]���ؼ�Ȩ����[14��35��32]�����ǣ����������������Ե�PUѧϰ������������ȷ��չ��ʹ�������������ѵ����������硣��������У����ǽ�Ԥ��ͼ����ת��������ΪPUѧϰ��������˹�ʽ������ͨ��Ӧ��δ���������Ȩ����������ǩ������
��ת�����������ྭ����ֹ��������������������ڼ�����Ӿ���SIFT [34]��RIFT [29]����ijЩ��ת�任�������С���������Ļ��ھ������������ѧϰ��һЩ����������Ƶ�����ṹ������G-CNN [7]��Warped Convolutions [20]����ѧϰ��ת��������������ֳ�����ijɼ���ͨ�������������ʵ�ֶ�����任���IJ����ԡ�Laptevet��[26]��ȡͼ��Ķ����ת���������ؼ��Dielemanet��[9]ͨ����ϸ��ֱ任�����������չ����ͼ����Щ�����ʾѧϰ������Ҫ���мල��������ѵ��������ּ��ѧϰ���ල�ķ�ʽ������ת�ز��ֵĸ������������ǵķ��������������ݵĶ����ת�����������ǽ�������ת��Ϣ��Ч����������������ල����
3 ��ת��������
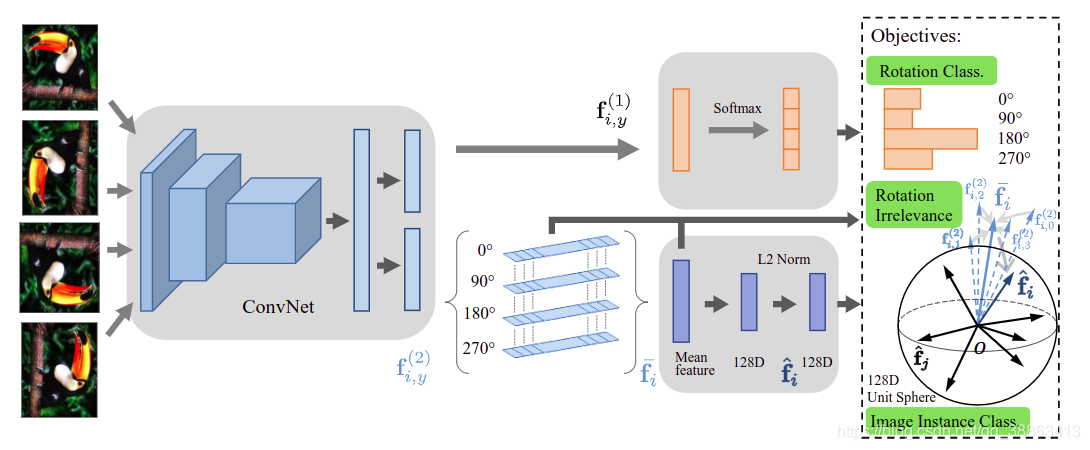
ͼ2������ķ�����ʾ��ͼ�����������һ��������������������а�����ת��غͲ���صIJ��֡�ͨ��Ԥ��ͼ����ת��ѵ����һ���֡���ת��ǩ�е���������ģΪPUѧϰ���⣬������ѧϰʵ��Ȩ���Լ�����ת��ȷ��ͼ���Ӱ�졣��һ����ʹ�÷Dz���������о���ͷ���ʧѵ������ǿ��ִ����ת�����Լ�ʵ���б�����
�ڱ����У��������Ȼع�Ԥ��ͼ����ת�ķ�����RotNet��[17]��Ȼ�������±���Ϊ����ģ�û�б�ǩ��ѧϰ���⣬�Ӷ�����˸�����������е�����ȱ�ݡ�������ϸ��������ת����ȥ�������������������ģ�ͣ���ͼ2����
3.1 ͼ����תԤ��
���������ڽ�ԭʼͼ��ӳ�䵽��������������������������ر�ǿ��ͨ��ʹ��ͼ������Ӧ����ʵ��ǩ�������ѵ����Ϊ����һ���ල�ķ�ʽ���ͼ���ͨ��������RotNet���о�ͼ��ļ��α任���ر��ǽ�ͼ����ת90����Ϊ�ල�źţ���ѵ����������Ԥ����任[17]����ˣ�����������ı�ʾ�����ھ���������߲������ͼ�н��б��롣
����һ��ѵ���� S={Xi}i=1NS=\{X_i\}_{i=1}^NS={
Xi?}i=1N?������N��ͼ��RotNetΪÿ��ͼ��X������һ����ת�任G={g(X;y)}y=1KG=\{g(X; y)\}^K_{y=1}G={
g(X;y)}y=1K?��Xi,yX_{i,y}Xi,y?��ʾ��iii��ͼ����е�yyy���任�õ���ͼ�Σ�Xi,y=g(Xi;y)X_{i,y}=g(X_i;y)Xi,y?=g(Xi?;y)��ѵ����һ����������ģ��F(?;��)F(\cdot ; \theta)F(?;��)����ÿ����ת��ͼ�����Ϊһ��ת����Ŀ�꺯��Ϊ��
min?��1NK��i=1N��y=1Kl(F(Xi,y;��),y),(1)\min_{\theta}\frac{1}{NK}\sum_{i=1}^N\sum_{y=1}^Kl(F(X_{i,y};\theta),y), \tag{1}��min?NK1?i=1��N?y=1��K?l(F(Xi,y?;��),y),(1)
����lll������������Ľ�������ʧ���任������Ϊ��ת����90�ȣ�����K=4������g(X;y)g(X;y)g(X;y)����ʾ��ͼ��X��ʱ����ת��y-1��* 90�ȡ�
RotNet�Ļ���ǰ������תͼ���ı�ͼ���ж���ķ���Ӧ������ʶ��Ϊ��Ԥ��ͼ����ת�����������ʶ��λͼ���е��������岿�֡���ˣ�ѵ�����ص����������Ϊͼ���е����Ŷ�������ȷ��������������Щ�����������ɵ�ת�Ƶ�ʵ�������У�������ͷָ
3.2 ���ӵ���תͼ��
��תԤ��ģ����������Ⱦ�������������������Ȼͼ���������Щͼ��ͨ�����д�����ǰ���ƵĶ�������ͼ��ͨ������Ĭ�Ϸ���ͼ����κ���ת���ᵼ���쳣�����巽�������������طֱ档��ImageNet���������ݼ��е�����ʵ������������ͼ�����ʺ�����תԤ������
���ܾ��м��Ժ���Ч�ԣ��������ǰ�����Ϊͼ���е�һЩ����ķ���֪�������㣬����Ӷ����۲��������߶ԳƵ����壨���ͼ1������ʵ���У�ʶ�����Щͼ��ľ�ȷ��ת�任�Ǻ�������ģ��������κ�����¶�����˼����Ӧ�þ������磬ֻ�Ὣ�����������뵽ģ��ѵ���С����ң���RotNet��ѧϰ������������ת�Ƕ���������ġ����������縡������[8]��ISBI2012���������ָ���ս[3]֮�������ת�ص�ͼ�����ݼ��в����ܻ�ӭ������������������һ��С���н��ܼ���������ת��ǩӰ��ķ�����������ѧϰ��ת�������ķ�����
���ǽ����ݼ��е�ԭʼͼ����ΪĬ�Ϸ���������Ϊ��������δ��ǵ���������������ת��ĸ���������ijЩ��������ת���Դ���Ĭ�Ϸ�����ˣ���Щͼ���Զ��������ת��ǩ����RotNet���ԱȽ����ӡ���ˣ��������δ��ǵ����ݶ�����Ϊ����������Ԥ������ͼ���Ƿ���ת��һ������������[4]����PUѧϰ�У����Ƶ����������������ʺ������Ƿ�ɾ��Ŀ��Ŷ��й�[40��19]���������ʹ�ù��Ƶĸ�������Ȩÿ����תͼ��������ת����ͼ��������ʧ��
���ȣ�ѵ��һ����������ģ�ͽ��ж����ࡣ������F?(Xi,y)\breve{F}(X_{i,y})F?(Xi,y?)��ʾ�Ӹ�Ԥѵ��ģ����ͼ��Ϊ���ĸ��ʡ����ǽ�ÿ��ʵ����Ȩ�����ӵ����пɵ�������\gamma���Ľ�������ʧ�У�����
wi,y={1y=11?F?(Xi,y)��otherwise(2)w_{i,y}=\begin{cases}1 & y=1 \\ 1-\breve{F}(X_{i,y})^{\gamma} & otherwise\end{cases}\tag{2}wi,y?={
11?F?(Xi,y?)��?y=1otherwise?(2)
����ʹ�ü����ʵ��Ȩ���������ƶ�Ŀ�꺯��(1)��
min?��1NK��i=1N��y=1Kwi,yl(F(Xi,y;��),y)(3)\min_{\theta}\frac{1}{NK}\sum_{i=1}^N\sum_{y=1}^Kw_{i,y}l(F(X_{i,y};\theta),y)\tag{3}��min?NK1?i=1��N?y=1��K?wi,y?l(F(Xi,y?;��),y)(3)
����Ԥ��ͼ����ת��ͬʱ��������������Ӱ�졣
3.3 ��������
���漰ͼ����ת��ͼ�����������漰��ת����֪ͼ�����������ʵ�á���һ�ֽ������������ͼ����ת�ص�������������������ת��ص�����������ͨ���������������㷨��ʵ�ִ�Ŀ�꣬���㷨ѧϰ��һ������������������������ͼ����ת������������ԣ���ij�̶ֳ�����ͼ����ת�ء��������ĵ�һ���ֽ����ܴӹ���ͼ����ת�������м̳еĺô�����һ������ͼ����ת�أ�������ijЩ�����ص�����
��ת���� ���Ǽ��轫ͼ�� X��������ʾΪf=[f(1)T,f(2)T]Tf=[f^{(1)^T},f^{(2)^T}]^Tf=[f(1)T,f(2)T]T������f(1)f^{(1)}f(1) ͼ����ת��ʽ�йأ���f(2)f^{(2)}f(2)��������ת�任�ص���Ϣ��ʹ�þ��в�����f\theta^f��f�Ļ��ھ��������������ȡ��Ff(?;��f)F_f(\cdot;\theta_f)Ff?(?;��f?)����һ���������ת����ͼƬXi,yX_{i,y}Xi,y?ӳ�䵽һ���̶���С������fi,y=Fy(Xi,y;��f)f_{i,y}=F_y(X_{i,y};\theta_f)fi,y?=Fy?(Xi,y?;��f?)��������Fc(?;��c)F_c(\cdot;\theta_c)Fc?(?;��c?)��������fi,y(1)f_{i,y}^{(1)}fi,y(1)?��Ϊ�����Թ���ͼ�����ת���͡���ת������ʧ�������Ա�ʾΪ��
Lc=1NK��i=1N��y=1Kwi,yl(Fc(fi,y(1);��c),y)(4)L_c=\frac{1}{NK}\sum_{i=1}^N\sum_{y=1}^Kw_{i,y}l(F_c(f_{i,y}^{(1)};\theta_c),y)\tag{4}Lc?=NK1?i=1��N?y=1��K?wi,y?l(Fc?(fi,y(1)?;��c?),y)(4)
���ʽ3��ͬ����Ϊ�˴���ʹ������f��һ������ʶ����ת��
��ת�ؽ�Ҫ ��Ϊ��ʵ����ת��������Ŀ�꣬�����ھ��в�ͬ��ת�Ƕȵ�ͬһͼ��ĸ�������֮��ʵʩ�����ԡ���������ͼ�����ת������{Xy}y=1K\{X_y\}_{y=1}^K{
Xy?}y=1K?�����ǵ�����{fy(2)}y=1K\{f_y^{(2)}\}_{y=1}^K{
fy(2)?}y=1K?Ӧ�þ����ܱ˴����ơ�����ͨ����С��ÿ������{fy(2)}y=1K\{f_y^{(2)}\}_{y=1}^K{
fy(2)?}y=1K?�����ǵ�ƽ����������f?=1K��y=1Kfy(2)\overline{f}=\frac{1}{K}\sum_{y=1}^Kf_y^{(2)}f?=K1?��y=1K?fy(2)?�ľ�������������⣬����Ŀ�꺯��дΪ��
Lr=1NK��i=1N��y=1Kd(fi,y(2),f?i)(5)L_r=\frac{1}{NK}\sum_{i=1}^N\sum_{y=1}^Kd(f_{i,y}^{(2)},\overline{f}_i)\tag{5}Lr?=NK1?i=1��N?y=1��K?d(fi,y(2)?,f?i?)(5)
Ϊ�˼���Ч�ʣ����Dz���ŷ����þ��룬����d(x,y)=��x?y��2d(x,y)=\begin{Vmatrix}x-y\end{Vmatrix}_2d(x,y)=����?x?y?����?2?��
Ȼ����ֻ�����Ŀ�꺯��ֻ�ܲ���������Ľ��������������ͬͼ���ڲ�ͬ��ת�Ƕ��µ����������Ƶģ�����������Լ������ͬʸ����������ʸ��������������ͼ���ء���ˣ����˵�ʽ5������ϣ������ת�ص����������ͼƬʵ�����������ԣ���������ת���������ԡ�����Ӧ�÷Dz�������[48]�����������˻��Ľ��������
ͼ��ʵ������������ͬһͼ���ڲ�ͬ��ת�£�����f(2)�˴�֮���������Ҫ�ȶԲ�ͬͼ�������f(2)�����ơ�����ͼ�����ת�����������ѱ�Լ��Ϊ�ӽ���ʽ5�е�ƽ������������������Ǽ����������ֺ�ɢ����Щƽ���������ڷDz��������У���ͼ��XԤ��Ϊ���ݼ��е�i��ʵ���ĸ���Ϊ��
P(i�Of^)=exp?(fiT^f^/��)��j=1Nexp?(fjT^f^/��)(6)P(i|\hat{f})=\frac{\exp(\hat{f_i^T}\hat{f}/\tau)}{\sum_{j=1}^N\exp(\hat{f_j^T}\hat{f}/\tau)}\tag{6}P(i�Of^?)=��j=1N?exp(fjT?^?f^?/��)exp(fiT?^?f^?/��)?(6)
����f^\hat{f}f^?��f?\overline{f}f?��L2L_2L2?��һ���汾����\tau�����¶Ȳ���������ѵ�����ݼ�S�����ǹ�ע����С����������Ȼ��
Ln=?��i=1Nlog?P(i�Ofi^)(7)L_n=-\sum_{i=1}^N\log P(i|\hat{f_i})\tag{7}Ln?=?i=1��N?logP(i�Ofi?^?)(7)
Ϊ�˼����ڴ������ݼ��ϼ����ʽ7��ʱ��Ϳռ䣬�����ڹ�һ��֮ǰ����ֵ��������ӳ�䵽128άʸ���������������������ƣ�NCE���ͽ�������[48]��Ŀ������С��������ʧ������
Ln=?EPd[log?h(i,fi^(t?1))?�ˡ�fi^(t)?fi^(t?1)��22]?m?EPn[log?(1?h(i,f��^(t?1)))](8)L_n=-\mathbb{E}_{P_d}\left[\log h(i,\hat{f_i}^{(t-1)})-\lambda\begin{Vmatrix}\hat{f_i}^{(t)}-\hat{f_i}^{(t-1)}\end{Vmatrix}_2^2\right]\\-m\cdot\mathbb{E}_{P_n}\left[\log(1-h(i,\hat{f^{\prime}}^{(t-1)}))\right]\tag{8}Ln?=?EPd??[logh(i,fi?^?(t?1))?��������?fi?^?(t)?fi?^?(t?1)?������?22?]?m?EPn??[log(1?h(i,f��^?(t?1)))](8)
����h(i,f^):=P(i�Of^)/[p(i�Of^)+mPn(i)]h(i,\hat{f}):=P(i|\hat{f})/\left[p(i|\hat{f})+mP_n(i)\right]h(i,f^?):=P(i�Of^?)/[p(i�Of^?)+mPn?(i)]��PdP_dPd?����ʵ�����ݵķֲ���PnP_nPn?����NCE�������ľ��ȷֲ���f��^\hat{f^{\prime}}f��^?����һ��ͼ��Ĺ�һ��������
���ɵ�ģ�Ͱ�����������ģ�飺��ת���ࣨEq.4������ת����أ�Eq.5����ͼ��ʵ�����ࣨEq.8��������д�ɣ�
min?��f,��c��cLc+��rLr+��nLn(9)\min_{\theta_f,\theta_c}\lambda_cL_c+\lambda_rL_r+\lambda_nL_n\tag{9}��f?,��c?min?��c?Lc?+��r?Lr?+��n?Ln?(9)���ǽ�f(1)f^{(1)}f(1)��f(2)f^{(2)}f(2)����������ʾһ������ͼ��ͼ������������ת��غͲ���ص������ɣ�����������������ḻ�ĸ�����ͼ���ʾ��f(1)f^{(1)}f(1)��������Ҫ����Ϣ���������������λ�ü���Ĭ�Ϸ�����Ԥ��ͼ����ת����һ���棬f(2)f^{(2)}f(2)û������ת�йص���Ϣ�����Ǹ���ع�עÿ��ͼ��IJ��졣
4 ʵ��
�ڱ����У����ǽ���ʵ����֤�����Ƿ�������Ч�ԡ�������ල�ķ�ʽѧϰ�����Ӿ���ʾ����Ч��ͨ�õģ����ǽ��ܺõ��ƹ㵽�����������ȣ����Ƕ��Եط�����ͨ�����㷨ѧϰ�������硣Ȼ�������ڼ�������Ǩ��ѧϰ���ϱ�������
4.1 ʵ��ϸ��
Ϊ������ǰ�Ĺ������бȽϣ�����ʹ����pytorch [24]ʵ�ֵı�AlexNet��ϵ�ṹ����������ͨ������Ϊ������ȡ��Ff(?;��f)F_f(\cdot;\theta_f)Ff?(?;��f?)��������������������ȫ���Ӳ���ɡ�����ʡ���˾ֲ���Ӧ��һ����LRN���㣬����ÿ�����Բ�֮������������һ����BN��������������Լලѧϰ�����еij����Ĺ���[10��52��12��53, 17��48��44 ��6]�������������f(1)f^{(1)}f(1)��f(2)f^{(2)}f(2)������Ϊ������ͬ�ijߴ磬������ʾfff��Ϊ���롣����ʹ��һ����������ʵ����ת������Fc(?;��c)F_c(\cdot;\theta_c)Fc?(?;��c?)�������ǵ�ģ���У���\gamma������\tau����mmm�ֱ�����Ϊ2,0.07��4096�����ǼĽ�������ʧƽ��IJ�����c\lambda_c��c?����r\lambda_r��r?����n\lambda_n��n?������Ϊ1��������ILSVRC 2012ѵ�����Ͻ�ģ��ѵ�����ܹ�200��epoch�������ѧϰ������Ϊ0.01��Ȼ����ǰ90�����ں�ÿ40������˥��10����ѵ������ʹ��0.9�Ķ�����192��������С��Ȩ����\theta����L2L_2L2?�ͷ�Ϊ5?10?45\cdot10^{-4}5?10?4��
4.2 ���Է���
����ھӼ������Լලѵ������Ϊ�������Ƶ�ͼ��������Ƶ��������������ȶ�ImageNet ILSVRC 2012��֤��ִ������ڼ������Բ���ѧϰ������������������Ϣ�����������ǽ�����RotNet���߽��бȽϣ����˽�����ȥ���Ч���� ���ǵ�ģ�ʹ�������ȡ������Ff(?;��f)F_f(\cdot;\theta_f)Ff?(?;��f?)�����4,096ά�����л�ȡ��������Ӧ�ģ�RogNet�� FC7���ȡ����������ʹ���������ƶȼ�������֮��ľ��롣
ͼ3�д����Ұ����������˳��������һЩ�����ļ������ݡ�RotNet���������ģ�Ͷ��ܹ�����ijЩ����ͼ���е����塣RotNet�����ǵ�ģ���ڰ������Ŷ�������ת��ȷ�����ѡ��ͼ���ϵĽ�����������⡣���ǵ�ģ����ʱ���Բ����ϸ���ȵ������ԡ����磬�ڵڶ����У�RotNet����һЩ���Ƶı���ֲ�������ǰ�����������ӵ�ͷ�г��ϣ����ǵ�ģ�ͳɹ��ҵ�����ͬ����ͼ��������ͨ�ij��������⣬����ijЩ��ת����֪��ͼ���ѯ��RotNet����ȡͼ���ж����DZ����Ϣ�� RotNet������������ͼ�����ѯ��ȫ�أ����к�ɫ�߿����������ΪRotNet���ӹ�ע�������״�����Բ�ͬʵ�����б�ȴ���١��෴�����ǵ�ģ�Ϳ��������Щ��ѯ���������ϸ����Ƶ�ͼ����ȷ��������ģ����ʵ�����������������
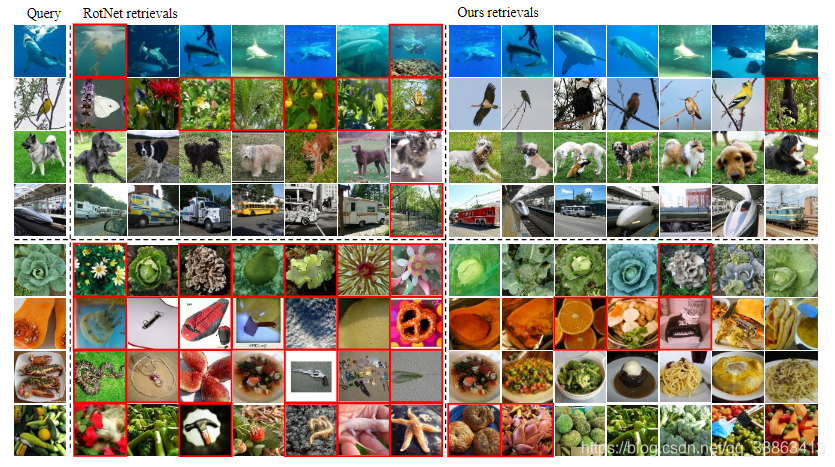
ͼ3������ھӼ��������������ImageNet��֤������ʾRotNet���߸�����ھӺ���ȥ�����硣��ѯ�������ѡ���ͼ�������У��Ͳ�����ת��ͼ�������У��������ϲ���صļ������к�ɫ�߿�
�˲������ӻ���Ϊ�˸��õ��˽�ͨ�����ǵķ���ѧϰ�����˲���������������ʹ���˲�ͬ��������ӻ�������ͼ4ʾ�������Ե�һ��[25]���˲�����ʹÿ���������ij��ͨ����ijЩ������ĺϳ�ͼ��[15��50]������ͼ��[51]�����Ƿ���ģ���еĽ�����ƺ������˸����Ӻͳ���������ṹ��

ͼ4�����������ӻ������ǻ���������conv1��Ĺ�����������ʾ�˿������̶ȵؼ��ͬ��������ij��ͨ�����ض�����ͼ�ĺϳ�ͼ��Ӧ�ڸ�ͨ����ImageNetѵ�����е�ǰ9�ż����ͼ�����Ҳࡣ
4.3��������Է���
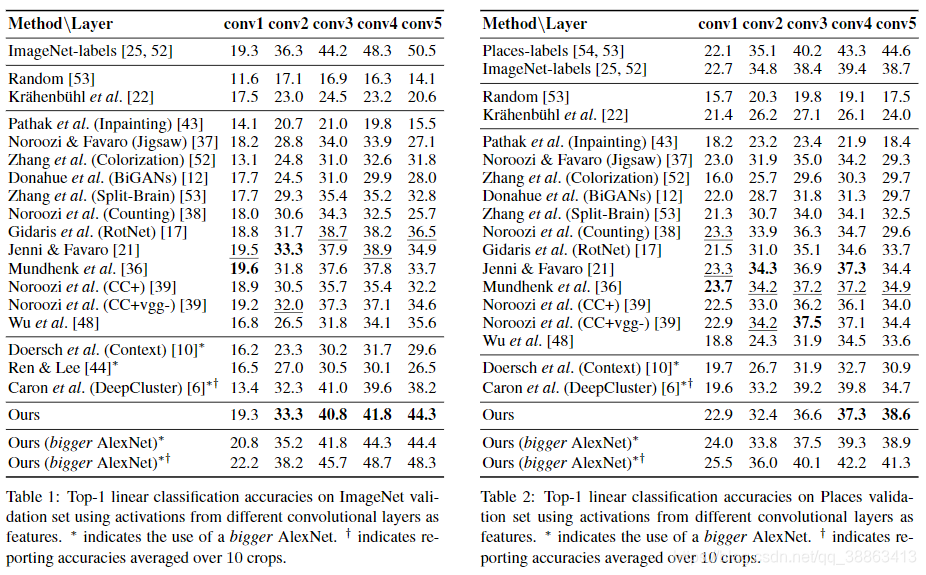
����Zhanget�� [52]�������ڲ�ͬ��������ȡ�������Ķ���ѵ�����Է��������÷�������ʾ��ѧϰ��ʾ���ض���������������ر��ǶԶ��������б�������ͨ�������ǻ���ILSVRC 2012 [45]��Places���ݼ�[54]�Ͻ��������о�������������ȡ�����������Ȩ�أ����ڿռ��ϵ�������ͼ�Ĵ�С��ʹ������Ӧ���أ����Ծ���Լ9,000��Ԫ�ء�����ֱ��¼�ڱ�1��2�С����е����з�����ʹ�û���AlexNet�����磬������ImageNet�Ͻ�����Ԥѵ��������ImageNet��ǩ��Places��ǩ��Random��Ŀ�⣬û�б�ǩ��������*��ǵķ���ʹ�õ��Ǹ���汾��AlexNet����û�з����ͨ���������٣����������еIJ���������50����ͨ����������ܡ� �ڱ����У����ǻ������˸������ϵĽ����������[36��39]�б�����ÿ�ַ�������ѱ�š����ǻ��ڲ����������ImageNet���ṩ�˷����Է���Ľ����
��ImageNet�ϣ����ǵķ�����conv3t��conv5ȡ�������Ƚ��Ľ����������conv1��conv2�ϵĽ������ǰ�Ľ����ImageNet��ǩ��Ŀ�൱����ע�⣬����ĽϵͲ�ͨ������ͼ���еĵͼ���Ϣ�����Ե�������������Ҿ�����Խϵ͵�Ǩ�ƾ��ȣ����ͨ������ֱ��ʹ����Щ��������Ҫ����Ҫע�⣬�������ǰ���������ܻ�����������Ƚ��͡���֮�γ������Աȵ��ǣ����dzɹ���С��I??mageNet��ǩ�ڸ��߲��ϵIJ�ࡣ���ĸĽ���7.8��������conv5����ʵ�ֵģ��ò�ͨ����ȡ����������Ϣ����������ǵķ�����ȡ�ĸ�������ʵ��Ӧ���и���ϣ����
��Places���ݼ��ϣ����Ƿ����Ľ�����ֳ���ImageNet���Ƶ����ơ�������Conv4��Conv5��ȡ�������ľ��ȣ�ͬʱ��Conv1��Conv3��Ҳȡ���˿ɱȽϵľ��ȡ���Conv5�㣬����ȡ�������Ƚ���3.7%��
4.4 PASCAL VOC�ϵĶ��ǩ���࣬Ŀ���������ָ�
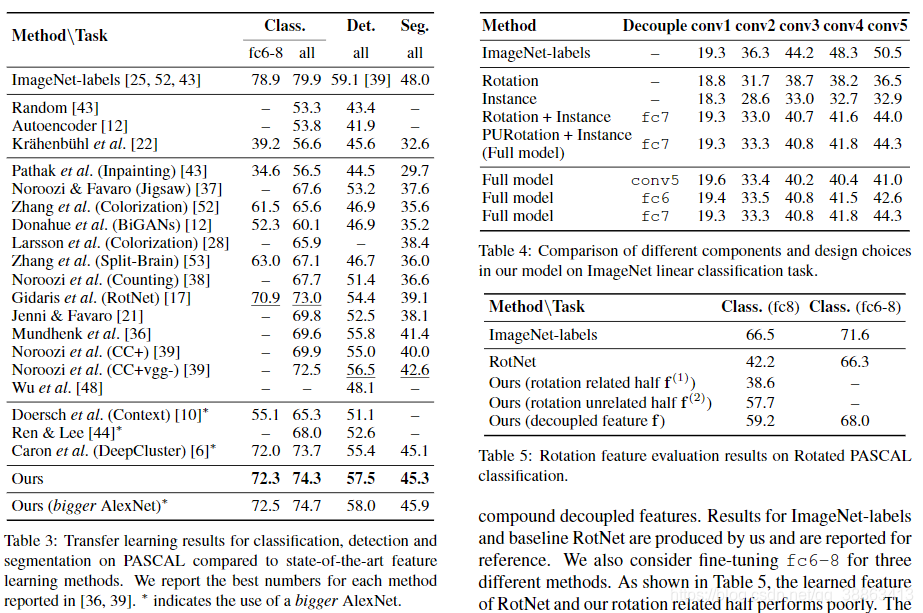
������PASCAL VOC���ݼ��ϲ�����ѧϰ���������Ŀɴ�����[16]������ʹ���ල��ѵ������Ff(?;��f)F_f(\cdot;\theta_f)Ff?(?;��f?)��ΪPASCAL������ij�ʼ��ģ�͡�����ͼ�������ͨ��ƽ����ֵ���ȣ�mAP�����в������ָ��������ͨ��ƽ��������ϣ�mIU�����в������ڴ�������У����ǽ�������һ���������յ�����ǰ�����Բ��У����������ڼ䲻ʹ��BN�㡣 Kr?ahenb?uhlet����������������ݵ����ŷ���[22]��Ϊ������������������ʵ�������µ���Ȩ�ء���3�ܽ������ǵķ��������������ıȽϡ����������������������϶�������ǰ�ķ�����
PASCAL VOC 2007�ϵķ���������ʹ��Kr?ahenb?uhl��https://github.com/philkr/voc-classification���ṩ�Ŀ�ԴЭ��ִ�ж��ǩ���ࡣ������ѵ������������������fc6-8�㣬���ڲ��Լ������������ǵķ������ԸĽ�RotNet��Ŀǰ�������ѷ����������Թ۲쵽�������AlexNetģ�ͽ����������ϵ�������
��PASCAL VOC 2007�ϵļ�������������⣬����ʹ���Լලѵ����������ΪFast-RCNN[18]�ij�ʼ��������ʹ��Girshick�ṩ�Ĺ������Կ��[18]����ʹ�ö�߶�ѵ���͵��߶Ȳ��ԡ���һ���Ȩ�������ڼ��ǹ̶��ģ���Ϊ����Fast-RCNN�е�Ĭ�����á���57.5����mAP�����Ǵﵽ����ѽ������������л��ṩ�����Ƿ�����ÿ�������ܡ�
��PASCAL VOC 2012�Ͻ��зָ�������ʹ��FCN [33]��PASCAL VOC 2012ѵ��������ģ�Ͳ��ڲ��Լ��������������ǵķ��������¼����߳�2.7����
4.5 ����
�����о���Ҫ�鿴ģ����ÿ�������Ӱ�죬���ǶԾ��й̶�������ImageNet���Է�����������о������DZȽ���תԤ������Rotation������ת��ʵ�����ࣨInstance�����������������ϣ�Rotation + Instance���Ϳ���δ��Ǽ��е����ӱ�ǩ��PURotation +Instance������4���м�������ʾ�˲�ͬ��������ܡ���������תʶ��������ǩ��ʵ��ʶ��ʱ����ģ�͵�Ч����ѡ�
��ͬ������������ͨ����ImageNet�ϵ����Է��������������ѡ���Ч�������DZȽ�������ȡ������Ff(?;��f)Ff(\cdot;\theta_f)Ff(?;��f?)�IJ�ͬ�ṹ��AlexNet��conv5���ľ����㣬conv5����һ��ȫ���Ӳ㣨fc6���������conv5��������ȫ���Ӳ㣨fc7�������������ܽ��ڱ�4���������С����߲������������ʱ���߲㽫ѧϰ�����õ���������Ȥ���ǣ��²�����������½������������Ϊ����ʧ����Ӧ���ڽϸ߲�ʱ����Ч���ݶ���Ϣ�ԽϵͲ�İ�����С��
��ת������������������֤���������������е�ͼ����ֳ���ת�Գ���ʱ�������������ʺϡ�Ϊ�ˣ����ǽ�PASCAL VOC 2007�е�ͼ����ת90�ȵı�������90��180��270�������ڷ�����������������ת������ݼ���20,044������ѵ����ͼ���19,808�����ڲ��Ե�ͼ����ԭʼ���ݼ���4���������в�ͬ��ת�Ƕȵ�ÿ��ʵ��������ͬ�����ǩ������ֱ�����ϰ벿�֣���ת��أ�����f(1)f^{(1)}f(1)���°벿�֣���ת�أ�����f(2)f^{(2)}f(2)���Ͻ��������Ķ���ѵ�����Է���������������ImageNet��ǩ�ͻ�RotNet�Ľ���������������ο������ǻ�����������ֲ�ͬ�ķ�����fc6-8�����������5��ʾ��RotNetѧϰ���������Լ�����ģ��������ת��ص���һ���������ܽϲԭ�������Ƕ���ͼ����ת���������ԣ���������ת�����ݼ���û�кܺõķ����������ý��������������ת��������Ͳ����������������ġ����ǵķ������ʺ�����Ҫ��ת������Ӿ�����
5 ����
�ڱ����У����������һ���ල�ı�ʾѧϰ�������÷���ѧϰ������ת��ز��ֺͲ���ز��ֵ���������������������ǵķ��������ֵ���ʵ���з����ͼ����תԤ�⡣������Լලѧϰ����ȣ�������Ǩ�ƿ�ʵ�ֱ����·������ߵ����ܡ������������ŵ�����ת����֪�����еõ���һ��֤�����������ţ�Ϊ�Լල��ѧϰ�������������Եı�ʾ�����ƹ���а�����������һ����ǰ;��δ������
�����
[1] Pulkit Agrawal, Joao Carreira, and Jitendra Malik. Learningto see by moving. InThe IEEE International Conference onComputer Vision (ICCV), December 2015.
[2] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, MargaretMitchell, Dhruv Batra, C. Lawrence Zitnick, and DeviParikh. Vqa: Visual question answering. InThe IEEE Inter-national Conference on Computer Vision (ICCV), December2015.
[3] Ignacio Arganda-Carreras, Srinivas C. Turaga, Daniel R.Berger, Dan Cires ?an, Alessandro Giusti, Luca M. Gam-bardella, J ?urgen Schmidhuber, Dmitry Laptev, SarveshDwivedi, Joachim M. Buhmann, Ting Liu, Mojtaba Seyed-hosseini, Tolga Tasdizen, Lee Kamentsky, Radim Burget,Vaclav Uher, Xiao Tan, Changming Sun, Tuan D. Pham,Erhan Bas, Mustafa G. Uzunbas, Albert Cardona, JohannesSchindelin, and H. Sebastian Seung. Crowdsourcing the cre-ation of image segmentation algorithms for connectomics.Frontiers in Neuroanatomy, 9:142, 2015.
[4] Jessa Bekker and Jesse Davis. Learning from positive andunlabeled data: A survey.arXiv:1811.04820, 2018.
[5] Y. Bengio, A. Courville, and P. Vincent. Representationlearning: A review and new perspectives.IEEE Transactionson Pattern Analysis and Machine Intelligence, 35(8):1798�C1828, Aug 2013.
[6] Mathilde Caron, Piotr Bojanowski, Armand Joulin, andMatthijs Douze. Deep clustering for unsupervised learningof visual features. In Vittorio Ferrari, Martial Hebert, Cris-tian Sminchisescu, and Yair Weiss, editors,Computer Vision�C ECCV 2018, pages 139�C156, Cham, 2018. Springer Inter-national Publishing.
[7] Taco Cohen and Max Welling. Group equivariant convo-lutional networks. In Maria Florina Balcan and Kilian Q.Weinberger, editors,Proceedings of The 33rd InternationalConference on Machine Learning, volume 48 ofProceed-ings of Machine Learning Research, pages 2990�C2999, NewYork, New York, USA, 20�C22 Jun 2016. PMLR.
[8] Robert K Cowen, S Sponaugle, K Robinson, and J Luo.Planktonset 1.0: Plankton imagery data collected from fgwalton smith in straits of florida from 2014�C06-03 to 2014�C06-06 and used in the 2015 national data science bowl (nceiaccession 0127422).NOAA National Centers for Environ-mental Information, 2015.
[9] Sander Dieleman, Jeffrey De Fauw, and Koray Kavukcuoglu.Exploiting cyclic symmetry in convolutional neural net-works. In Maria Florina Balcan and Kilian Q. Weinberger,editors,Proceedings of The 33rd International Conferenceon Machine Learning, volume 48 ofProceedings of MachineLearning Research, pages 1889�C1898, New York, New York,USA, 20�C22 Jun 2016. PMLR.
[10] Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsu-pervised visual representation learning by context prediction.InThe IEEE International Conference on Computer Vision(ICCV), December 2015.
[11] Carl Doersch and Andrew Zisserman. Multi-task self-supervised visual learning. InThe IEEE International Con-ference on Computer Vision (ICCV), Oct 2017.
[12] Jeff Donahue, Philipp Kr ?ahenb ?uhl, and Trevor Darrell. Ad-versarial feature learning. InInternational Conference onLearning Representations, 2017.
[13] Alexey Dosovitskiy, Jost Tobias Springenberg, Martin Ried-miller, and Thomas Brox. Discriminative unsupervised fea-ture learning with convolutional neural networks. In Z.Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, andK. Q. Weinberger, editors,Advances in Neural InformationProcessing Systems 27, pages 766�C774. Curran Associates,Inc., 2014.
[14] Charles Elkan and Keith Noto. Learning classifiers from onlypositive and unlabeled data. InProceedings of the 14th ACMSIGKDD International Conference on Knowledge Discoveryand Data Mining, KDD ��08, pages 213�C220, New York, NY,USA, 2008. ACM.
[15] Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pas-cal Vincent. Visualizing higher-layer features of a deep net-work. Technical Report 1341, University of Montreal, June2009. Also presented at the ICML 2009 Workshop on Learn-ing Feature Hierarchies, Montr ?eal, Canada.
[16] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I.Williams, J. Winn, and A. Zisserman. The pascal visual ob-ject classes challenge: A retrospective.International Journalof Computer Vision, 111(1):98�C136, Jan. 2015.
[17] Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Un-supervised representation learning by predicting image rota-tions. InInternational Conference on Learning Representa-tions, 2018.
[18] Ross Girshick. Fast r-cnn. InThe IEEE International Con-ference on Computer Vision (ICCV), December 2015.
[19] Fengxiang He, Tongliang Liu, Geoffrey I Webb, andDacheng Tao. Instance-dependent PU learning by bayesianoptimal relabeling.arXiv:1808.02180, 2018.
[20] Jo ?ao F. Henriques and Andrea Vedaldi. Warped convolu-tions: Efficient invariance to spatial transformations. InDoina Precup and Yee Whye Teh, editors,Proceedings ofthe 34th International Conference on Machine Learning,volume 70 ofProceedings of Machine Learning Research,pages 1461�C1469, International Convention Centre, Sydney,Australia, 06�C11 Aug 2017. PMLR.
[21] Simon Jenni and Paolo Favaro. Self-supervised feature learn-ing by learning to spot artifacts. InThe IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), June2018.
[22] Philipp Kr ?ahenb ?uhl, Carl Doersch, Jeff Donahue, and TrevorDarrell. Data-dependent initializations of convolutional neu-ral networks. InInternational Conference on Learning Rep-resentations, 2016.
[23] Jan Kremer, Fei Sha, and Christian Igel. Robust active la-bel correction. In Amos Storkey and Fernando Perez-Cruz,editors,Proceedings of the Twenty-First International Con-ference on Artificial Intelligence and Statistics, volume 84 ofProceedings of Machine Learning Research, pages 308�C316,Playa Blanca, Lanzarote, Canary Islands, 09�C11 Apr 2018.PMLR.
[24] Alex Krizhevsky. One weird trick for parallelizing convolu-tional neural networks.CoRR, abs/1404.5997, 2014.
[25] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton.Imagenet classification with deep convolutional neural net-works. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q.Weinberger, editors,Advances in Neural Information Pro-cessing Systems 25, pages 1097�C1105. Curran Associates,Inc., 2012.
[26] Dmitry Laptev, Nikolay Savinov, Joachim M. Buhmann, andMarc Pollefeys. Ti-pooling: Transformation-invariant pool-ing for feature learning in convolutional neural networks.InThe IEEE Conference on Computer Vision and PatternRecognition (CVPR), June 2016.
[27] Gustav Larsson, Michael Maire, and GregoryShakhnarovich. Learning representations for automaticcolorization. In Bastian Leibe, Jiri Matas, Nicu Sebe, andMax Welling, editors,Computer Vision �C ECCV 2016, pages577�C593, Cham, 2016. Springer International Publishing.
[28] Gustav Larsson, Michael Maire, and GregoryShakhnarovich. Colorization as a proxy task for visualunderstanding. InThe IEEE Conference on Computer Visionand Pattern Recognition (CVPR), July 2017.
[29] S. Lazebnik, C. Schmid, and Jean Ponce. Semi-localaffine parts for object recognition. InProceedings ofthe British Machine Vision Conference, pages 98.1�C98.10.BMVA Press, 2004. doi:10.5244/C.18.98.
[30] Hsin-Ying Lee, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. Unsupervised representation learning by sort-ing sequences. InThe IEEE International Conference onComputer Vision (ICCV), Oct 2017.
[31] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,Pietro Perona, Deva Ramanan, Piotr Doll ?ar, and C. LawrenceZitnick. Microsoft coco: Common objects in context. InDavid Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuyte-laars, editors,Computer Vision �C ECCV 2014, pages 740�C755, Cham, 2014. Springer International Publishing.
[32] T. Liu and D. Tao. Classification with noisy labels by impor-tance reweighting.IEEE Transactions on Pattern Analysisand Machine Intelligence, 38(3):447�C461, March 2016.
[33] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fullyconvolutional networks for semantic segmentation. InTheIEEE Conference on Computer Vision and Pattern Recogni-tion (CVPR), June 2015.
[34] David G. Lowe. Distinctive image features from scale-invariant keypoints.International Journal of Computer Vi-sion, 60(2):91�C110, Nov 2004.
[35] Nagarajan Natarajan, Inderjit S Dhillon, Pradeep K Raviku-mar, and Ambuj Tewari. Learning with noisy labels. InC. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani,and K. Q. Weinberger, editors,Advances in Neural Informa-tion Processing Systems 26, pages 1196�C1204. Curran Asso-ciates, Inc., 2013.
[36] T. Nathan Mundhenk, Daniel Ho, and Barry Y. Chen. Im-provements to context based self-supervised learning. InTheIEEE Conference on Computer Vision and Pattern Recogni-tion (CVPR), June 2018.
[37] Mehdi Noroozi and Paolo Favaro. Unsupervised learningof visual representations by solving jigsaw puzzles. In Bas-tian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors,Computer Vision �C ECCV 2016, pages 69�C84, Cham, 2016.Springer International Publishing.
[38] Mehdi Noroozi, Hamed Pirsiavash, and Paolo Favaro. Rep-resentation learning by learning to count. InThe IEEE Inter-national Conference on Computer Vision (ICCV), Oct 2017.
[39] Mehdi Noroozi, Ananth Vinjimoor, Paolo Favaro, andHamed Pirsiavash. Boosting self-supervised learning viaknowledge transfer. InThe IEEE Conference on ComputerVision and Pattern Recognition (CVPR), June 2018.
[40] Curtis G. Northcutt, Tailin Wu, and Isaac L. Chuang. Learn-ing with confident examples: Rank pruning for robust classi-fication with noisy labels. InProceedings of the Thirty-ThirdConference on Uncertainty in Artificial Intelligence, UAI��17.AUAI Press, 2017.
[41] Andrew Owens, Jiajun Wu, Josh H. McDermott, William T.Freeman, and Antonio Torralba. Ambient sound provides su-pervision for visual learning. In Bastian Leibe, Jiri Matas,Nicu Sebe, and Max Welling, editors,Computer Vision �CECCV 2016, pages 801�C816, Cham, 2016. Springer Inter-national Publishing.
[42] Deepak Pathak, Ross Girshick, Piotr Dollar, Trevor Darrell,and Bharath Hariharan. Learning features by watching ob-jects move. InThe IEEE Conference on Computer Visionand Pattern Recognition (CVPR), July 2017.
[43] Deepak Pathak, Philipp Kr ?ahenb ?uhl, Jeff Donahue, TrevorDarrell, and Alexei A. Efros. Context encoders: Featurelearning by inpainting. InThe IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), June 2016.
[44] Zhongzheng Ren and Yong Jae Lee. Cross-domain self-supervised multi-task feature learning using synthetic im-agery. InThe IEEE Conference on Computer Vision andPattern Recognition (CVPR), June 2018.
[45] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San-jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy,Aditya Khosla, Michael Bernstein, Alexander C. Berg, andLi Fei-Fei. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211�C252,Dec 2015.
[46] Clayton Scott. A Rate of Convergence for Mixture Propor-tion Estimation, with Application to Learning from NoisyLabels. In Guy Lebanon and S. V. N. Vishwanathan, ed-itors,Proceedings of the Eighteenth International Confer-ence on Artificial Intelligence and Statistics, volume 38 ofProceedings of Machine Learning Research, pages 838�C846,San Diego, California, USA, 09�C12 May 2015. PMLR.
[47] Xiaolong Wang and Abhinav Gupta. Unsupervised learningof visual representations using videos. InThe IEEE Inter-national Conference on Computer Vision (ICCV), December2015.
[48] Zhirong Wu, Yuanjun Xiong, Stella X. Yu, and Dahua Lin.Unsupervised feature learning via non-parametric instancediscrimination. InThe IEEE Conference on Computer Visionand Pattern Recognition (CVPR), June 2018.
[49] Pengyi Yang, Wei Liu, and Jean Yang. Positive unlabeledlearning via wrapper-based adaptive sampling. InProceed-ings of the Twenty-Sixth International Joint Conference onArtificial Intelligence, IJCAI-17, pages 3273�C3279, 2017.
[50] Jason Yosinski, Jeff Clune, Thomas Fuchs, and Hod Lipson.Understanding neural networks through deep visualization.InICML Workshop on Deep Learning, 2015.
[51] Matthew D. Zeiler and Rob Fergus. Visualizing and under-standing convolutional networks. In David Fleet, Tomas Pa-jdla, Bernt Schiele, and Tinne Tuytelaars, editors,ComputerVision �C ECCV 2014, pages 818�C833, Cham, 2014. SpringerInternational Publishing.
[52] Richard Zhang, Phillip Isola, and Alexei A. Efros. Color-ful image colorization. In Bastian Leibe, Jiri Matas, NicuSebe, and Max Welling, editors,Computer Vision �C ECCV2016, pages 649�C666, Cham, 2016. Springer InternationalPublishing.
[53] Richard Zhang, Phillip Isola, and Alexei A. Efros. Split-brain autoencoders: Unsupervised learning by cross-channelprediction. InThe IEEE Conference on Computer Vision andPattern Recognition (CVPR), July 2017.
[54] Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio Tor-ralba, and Aude Oliva. Learning deep features for scenerecognition using places database. In Z. Ghahramani, M.Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger,editors,Advances in Neural Information Processing Systems27, pages 487�C495. Curran Associates, Inc., 2014.