Towards Real-World Blind Face Restoration with Generative Facial PriorАыУГЙъіЙКҪИЛБіПИСйҪшРРХжКөКАҪзГӨДҝөДИЛБіЦШ№№
- 1. Introduction
-
- ҪвҫцөДОКМв
- №ұПЧ
- GANДжУіЙд
- [SFT Layer](https://zhuanlan.zhihu.com/p/45145504)
- [Perceptual Loss](https://blog.csdn.net/u013289254/article/details/102880140)
- LapSRN
- 2. Related Work
- 3. Methodology
-
- 3.1. Overview of GFP-GAN
- 3.2. Degradation Removal Module
- 3.3. Generative Facial Prior and Latent Code Mapping
- 3.4. Channel-Split Spatial Feature Transform
- 3.5. Model Objectives
- 4. Experiments
-
- 4.1. Datasets and Implementation
- 4.2. Comparisons with State-of-the-art Methods
- 4.3. Ablation Studies
- 4.4. Limitations
- 5. Conclusion
ВЫОДБҙҪУ: Arxiv
НЕ¶УЈәМЪС¶ARC
»бТйј°КұјдЈәCVPR 2021
ҙъВлЈәФЭОҙ·ўІј
1. Introduction
ГӨДҝөДИЛБіРЮёҙөДДҝұкКЗҙУҙжФЪОҙЦӘНЛ»ҜөДөНЦКБҝИЛБіЦРРЮёҙіцёЯЦКБҝөДИЛБіЈ¬ИзөН·ЦұжВКЎўФлЙщЎўДЈәэЎўС№ЛхОұУ°өИЎЈөұУҰУГөҪПЦКөКАҪзөДіЎҫ°ЦРЈ¬УЙУЪёьёҙФУөДНЛ»ҜЈ¬І»Н¬өДЧЛМ¬әНұнЗйЈ¬ЛьұдөГёьҫЯМфХҪРФЎЈТФНщөДСРҫҝөдРНөШАыУГБЛИЛБіРЮёҙЦРөДМШ¶ЁИЛБіПИСйЈ¬ИзИЛБі№ШјьөгјмІвЎўҪвОцУіЙдЎўИЛБііЙ·ЦИИНјЈ¬ІўұнГчХвР©јёәОИЛБіПИСй¶ФУЪРЮёҙЧјИ·өДИЛБіРОЧҙәНПёҪЪЦБ№ШЦШТӘЎЈИ»¶шЈ¬ХвР©ПИСйРЕПўНЁіЈКЗҙУКдИлНјПсЦР№АјЖіцАҙөДЈ¬ІўЗТІ»ҝЙұЬГвөШ»бФЪКдИлЦКБҝәЬөНөДЗйҝцПВНЛ»ҜЎЈ
ҪвҫцөДОКМв
ИзәОҙУөН·ЦұжВКөНЦКБҝөДХжКөНјПсЦР»сөГҪПәГөДПИСйЦӘК¶Ј¬ёҙФӯИЛБіНјПс
ЧоҪьЈ¬¶ФУЪИЛБіёҙФӯОКМвЈ¬РиТӘҙУөН·ЦұжВКИЛБіНјПсЦРМбИЎјёәОИЛБіПИСйЈ¬УГУЪёҙФӯИЛБіЎЈө«КЗРн¶аКұәтЈ¬ҙУПЦКөөН·ЦұжНјПсЦРЛщМбИЎөДРн¶аИЛБіөДПИСй¶јІ»М«ЧјИ·Ј¬ІўЗТОЖАнРЕПўТІКЬПЮЎЈ
БнТ»ёцІЯВФКЗТэИлІОҝјПИСйЈ¬јҙёЯЦКБҝТэөјИЛБі»тХЯИЛБііЙ·ЦЧЦөдЈ¬ЙъіЙХжКөөДИЛБіҪб№ыЎЈө«КЗЈ¬ёЯ·ЦұжВКІОҝјОДјюөДІ»ҝЙ·ГОКРФПЮЦЖБЛЛьөДКөјКККУГРФЈ¬¶шЧЦөдөД№М¶ЁИЭБҝПЮЦЖБЛЛьөДГжІҝПёҪЪөД¶аСщРФәН·бё»РФЎЈ
ЎӘ> ОТГЗМбіцБЛТ»ЦЦЙъіЙКҪөДИЛБіПИСйЈЁGFPЈ©Ј¬УГУЪХжКөКАҪзөДГӨИЛБіНјПсёҙФӯЎЈУЙУЪФӨСөБ·өДИЛБіЙъіЙ¶Фҝ№НшВзЈЁИзstyleGANЈ©ЛщЙъіЙөДјЩБіЈ¬ҫЯУРёЯ·ЦұжВКЈ¬·бё»өДјёәОРОЧҙЎўИЛБіОЖАнәНСХЙ«Ј¬ХвР©К№өҪЖдДЬ№»БӘәПУГУЪёҙФӯИЛБіөДПёҪЪәНФцЗҝСХЙ«ЎЈ
МбіцБЛТ»ЦЦGFP-GANЈ¬Жд°ьә¬БЛТ»ёцНЛ»ҜИҘіэДЈҝйәНТ»ёцФӨСөБ·өДИЛБіGANЧчОӘИЛБіПИСйЎЈНЁ№эЦұҪУөДЗұФЪҙъВлУіЙдәНјёёцНЁөА·ЦёоҝХјдМШХчұд»»ЈЁCS-SFTЈ©ІгТФҙЦөч·ҪКҪБ¬ҪУЎЈ
№ұПЧ
- АыУГ·бё»¶аСщөДЙъіЙИЛБіПИСйАҙҪшРР°у¶ЁИЛПсёҙФӯЎЈХвР©ПИСй°ьә¬Чг№»өДГжІҝОЖАнәНЙъ¶ҜөДЙ«ІКРЕПўЈ¬ДЬ№»БӘәПЦҙРРИЛБіРЮёҙәНЙ«ІКФцЗҝЎЈ
- МбіцGFP-GANҝтјЬЈ¬ёГҝтјЬҫЯУРҫ«ЗЙөДјЬ№№ЙијЖЈ¬ІўДЬИЪәПИЛБіЙъіЙПИСйЎЈҙшУРCS-SFTІгөДGFP-GANФЪТ»ҙОХэПтҙ«өЭЦРКөПЦБЛұЈХж¶ИәНОЖАнЦТКө¶ИЦ®јдөДБјәГЖҪәвЎЈ
- ҙуБҝКөСйұнГчЈ¬GFP-GANФЪәПіЙКэҫЭјҜәНХжКөКэҫЭјҜЙПҫщИЎөГБЛУЕУЪПЦУРјјКхөДРФДЬЎЈ
GANДжУіЙд
¶ЁТеЈә GAN ДжУіЙдЦёҪ«ёш¶ЁНјПсЧӘ»ҜөҪФӨСөБ· GAN ДЈРНөДТюҝХјдЈ¬ЙъіЙЖчҝЙУГЖдДжУіЙдВлҪшРРҝЙҝҝөДНјПсЦШҪЁЎЈ
АнҪвЈә Т»ёцОЮја¶ҪЎўСөБ·әГөДGANҝЙТФНЁ№эҙУЗұФЪҝХјдZЦРІЙСщИ»әуәПіЙёЯЦКБҝөДНјПсЈ¬ТІҫНКЗZ->imageЎЈ¶шЛщОҪөДGANДжУіЙдЦёөДКЗЈ¬ХТөҪТ»ёцәПККZИҘ»ЦёҙДҝұкНјПсЈ¬ТІҫНКЗimage->ZЈЁZҙЛКұКЗТ»ёцҙэУЕ»ҜөДІОКэЈ©ЎЈGANДжУіЙдіЙОӘБ¬ҪУХжКөНјПсәНјЩНјПсөД№«№ІҝХјдЎЈ
SFT Layer

Perceptual Loss
1.ҪйЙЬ
ФЪҪІёРЦӘЛрК§әҜКэЦ®З°Ј¬ОТГЗПИҪІТ»ПВЈ¬НшВзЛщМбИЎөҪөДМШХчҙъұнКІГҙЈ¬ФЪПВНјЦРЈ¬layer1,layer2С§өҪөДКЗұЯФөЈ¬СХЙ«Ј¬ББ¶ИөИөЧІгөДМШХчЈ»layer3ҝӘКјұдөГёҙФУЈ¬С§өҪөДКЗОЖАнөДМШХчЈ¬Layer4ФтС§өҪөДКЗТ»Р©УРЗшұрРФөДМШХчЈ¬Layer5С§өҪөДМШХчКЗұИҪПНкХыөДЈ¬ҫЯУРұжұрРФөД№ШјьМШХчЎЈҝЙТФЦӘөАCNNС§П°өҪөДМШХчЦрҪҘійПуөҪёьёЯј¶ұрЙПЎЈ

ДЗГҙёРЦӘЛрК§әҜКэәНХвёцУРКІГҙ№ШПөДШЈҝ
ЛьКЗҪ«ХжКөНјЖ¬ҫн»эөГөҪөДfeatureЈЁТ»°гКЗУГvgg16»тХЯvgg19АҙМбИЎЈ©УлЙъіЙНјЖ¬ҫн»эөГөҪөДfeatureЧчұИҪПЈЁТ»°гУГMSEЛрК§әҜКэЈ©Ј¬К№өГёЯІгРЕПўЈЁДЪИЭәНИ«ҫЦҪб№№Ј©ҪУҪьЈ¬ТІҫНКЗёРЦӘөДТвЛјЎЈ
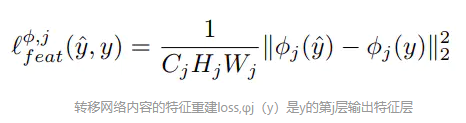
2.ЧчУГ
1Ј©ФЪі¬·ЦЦРЈ¬ТтОӘОТГЗҫӯіЈК№УГMSEЛрК§әҜКэЈ¬»бөјЦВКдіцНјЖ¬ұИҪПЖҪ»¬ЈЁ¶ӘөфБЛПёҪЪІҝ·Ц/ёЯЖөІҝ·ЦЈ©Ј¬ТтҙЛККөұСЎФсДіёцІгКдіцөДМШХчКдИлёРЦӘЛрК§әҜКэКЗҝЙТФФцЗҝПёҪЪЎЈ
2Ј©ФЪ·зёсЧӘТЖЦРЈ¬ОТГЗУГТ»ёцёРЦӘЛрК§әҜКэАҙСөБ·ОТГЗөДНјПсЧӘ»»НшВзДЬИГКдіц·ЗіЈҪУҪьДҝұкНјПсyЈ¬ө«ІўІ»КЗИГЛыГЗЧцөҪНкИ«өДЖҘЕд
3.УЕөг
·зёсЧӘТЖ»тХЯі¬·ЦұжВКЦРЈ¬ЛЩ¶ИҝмЈ¬GANЦРКХБІР§№ыәГЈ¬ҫЯУРёЯЖөПёҪЪРЕПўЎЈ
4.КХБІЛЩ¶Иҝм
»Шҙ«өјКэКұЈ¬ПаұИУЪMSE¶ФpixelУлpixelЦ®јдөДІоТмЈ¬ »Шҙ«·ЦІјёьҫЯУРЖХККРФЎЈЛщТФУГperceptual lossКХБІЛЩ¶ИҝмЎЈ
LapSRN

ХыёцLapSRNНшВзУЙМШХчМбИЎәННјПсЦШҪЁБҪёц·ЦЦ§ЧйіЙЎЈ
ҫЯМеКөПЦЈә
1ЎўМШХчМбИЎЈә
ФЪsІгЈ¬МШХчМбИЎ·ЦЦ§УЙdёцҫн»эІгәН1ёцЙПІЙСщІгЧйіЙЈ¬Ҫ«МбИЎөДМШХч°ҙ2өДіЯ¶ИПтЙПІЙСщЎЈ
ГҝёцЙПІЙСщәуөДҫн»эІгөДКдіцБ¬ҪУөҪБҪёцІ»Н¬өДІг:
(1)Т»ёцҫн»эІгУГУЪЦШҪЁsј¶өДІРІоНјПсЈ¬ТФј°(2)Т»ёцҫн»эІгУГУЪМбИЎs+1ј¶ёьПёөДМШХчЎЈ
НшВзФЪҙЦ·ЦұжВКПВЦҙРРМШХчМбИЎЈ¬¶шФЪҪППё·ЦұжВКПВҪцК№УГТ»ёцЙПІЙСщІгЙъіЙМШХчНјЎЈ
2ЎўНјПсЦШҪЁ
ФЪsІгЈ¬КдИлНјПсЙПІЙСщОӘ2Ј¬ІўЙиЦГБЛТ»ёцЙПІЙСщІгЎЈОТГЗУГЛ«ПЯРФәЛіхКј»ҜХвТ»ІгЈ¬ІўФКРнЛьУлЛщУРЖдЛыІг№ІН¬УЕ»ҜЎЈИ»әуЈ¬Ҫ«ЙПІЙСщНјПс(К№УГФӘЛШЗуәН)УлАҙЧФМШХчМбИЎ·ЦЦ§өДФӨІвІРІоНјПсПаҪбәПЈ¬ЙъіЙёЯ·ЦұжВКөДКдіцНјПсЎЈ
Ҫ«КдіцөДsІгөДёЯ·ЦұжВКНјПсЛНИлs+1ІгНјПсЦШҪЁ·ЦЦ§ЎЈ
3ЎўЛрК§әҜКэ
ЛрК§әҜКэІЙУГБЛВі°фөДCharbonnier ЛрК§әҜКэЈә
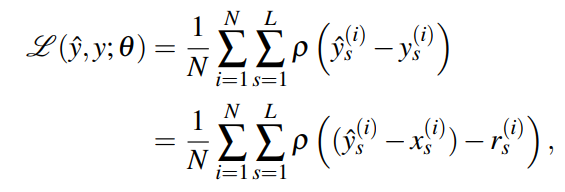
2. Related Work
Image Restoration
НјПсРЮёҙНЁіЈ°ьАЁі¬·ЦұжВКЎўИҘФлЎўИҘДЈәэәНС№ЛхИҘіэЎЈЙъіЙ¶Фҝ№НшВзНЁіЈұ»УГЧчЛрК§ја¶ҪЈ¬ТФНЖ¶Ҝ·Ҫ°ёёьҪУҪьЧФИ»БчРОЈ¬¶шОТГЗөД№ӨЧчКФНјАыУГФӨПИСөБ·өДGANsЧчОӘЙъіЙКҪИЛБіПИСй(GFP)ЎЈ
Face Restoration
ФЪТ»°гИЛБіі¬·ЦұжВКјјКхөД»щҙЎЙПЈ¬ТэИлБҪЦЦөдРНөДИЛБіМШТмРФПИСй:јёәОПИСйәНІОҝјПИСйЈ¬ҪшТ»ІҪМбёЯДЈРНұнПЦЎЈ
- јёәОПИСй°ьАЁИЛБі№ШјьөгЈЁfacial landmarksЈ©Ј¬ИЛБі·ЦёоНјЈЁface parsing mapsЈ©әНИЛБііЙ·ЦИИБҰНјЈЁfacial component heatmaps Ј©ЎЈ
И»¶шЈ¬1) ҙУөНЦКБҝөДНјЖ¬ЦРәЬДСИЎөГұИҪПЧјИ·өДјёәОРЕПўЈ»2) ЛьГЗәЬДСМṩОЖАн·ҪГжөДРЕПўЎЈ
Па·ҙЈ¬ОТГЗІЙУГөДGFPІ»Йжј°ҙУНЛ»ҜНјПсЦРГчИ·өДјёәО№АјЖЈ¬ІўФЪЖдФӨПИСөБ·өДНшВзЦР°ьә¬Чг№»өДОЖАнЎЈ - ІОҝјПИСйНЁіЈТААөУЪПаН¬Йн·ЭөДІОҝјНјПсЎЈјҙҙУКэҫЭҝвЦРИЎөГПаН¬»тХЯПаЛЖөДИЛБіЧчОӘІОҝјЈЁReferenceЈ©АҙёҙФӯЎЈө«КЗХвСщөДёЯЦКБҝөДІОҝјНјФЪКөјКЦРәЬДС»сИЎЎЈECCV20 МбіцөД DFDNet №ӨЧчҪшТ»ІҪ№№ҪЁБЛТ»ёцИЛБіОе№ЩөДЧЦөдАҙЧчОӘІОҝј, ЛьҝЙТФИЎөГёьәГөДР§№ы, ө«КЗ»бКЬПЮУЪЧЦөдөДИЭБҝ, ¶шЗТЦ»ҝјВЗБЛОе№Щ, Г»УРҝјВЗХыёцБіЎЈ¶шGFPҝЙТФМṩ·бё»¶аСщөДПИСйЈ¬°ьАЁјёәОЎўОЖАнәНСХЙ«ЎЈGFP-GANҝЙТФҪ«ГжІҝЧчОӘТ»ёцХыМеҪшРРРЮёҙЎЈ
Generative Priors
ФӨСөБ·№эөДGANөДЙъіЙПИСйПИЗ°ұ»GANДжУіЙдЈЁGAN inversionЈ©ЛщАыУГЈ¬ЖдЦчТӘДҝөДКЗХТөҪёш¶ЁКдИлНјПсөДЧоҪУҪьөДТюұдБҝЈЁlatent codeЈ©ЎЈPULSEөьҙъУЕ»ҜStyleGANөДТюұдБҝЈ¬ЦұөҪКдіцәНКдИлЦ®јдөДҫаАлөНУЪгРЦөЎЈmGANpriorіўКФУЕ»Ҝ¶аёцҙъВлЈ¬ТФМбёЯЦШ№№ЦКБҝЎЈИ»¶шЈ¬УЙУЪөНО¬ТюұдБҝІ»ЧгТФЦёөјРЮёҙЈ¬ХвР©·Ҫ·ЁНЁіЈ»бІъЙъөНұЈХж¶ИөДНјПсЎЈПаұИЦ®ПВЈ¬ОТГЗМбіцөДCS-SFTөчЦЖІгДЬ№»ФӨПИҪбәП¶а·ЦұжВКҝХјдМШХчЈ¬ТФКөПЦёЯұЈХж¶ИЎЈҙЛНвЈ¬ОТГЗөДGFP-GANФЪНЖАн№эіМЦРІ»РиТӘёЯіЙұҫөДөьҙъУЕ»ҜЎЈ
Channel Split Operation
ОӘБЛЙијЖҪфҙХөДДЈРНЈ¬МбёЯДЈРНұнКҫДЬБҰЈ¬НЁіЈІЙУГНЁөА·ЦёоІЩЧчЎЈMobileNetМбіцБЛЙо¶Иҫн»эЈ¬¶шGhostNetҪ«ҫн»эІг·ЦіЙБҪІҝ·ЦЈ¬ІўК№УГҪПЙЩөДВЛІЁЖчАҙЙъіЙДЪФЪМШХчУіЙдЎЈ
DPNөДЛ«В·ҫ¶Ҫб№№ДЬ№»¶ФГҝМхВ·ҫ¶ҪшРРМШХчЦШУГәНРВМШХчМҪЛчЈ¬ҙУ¶шМбёЯБЛDPNөДұнКҫДЬБҰЎЈФЪі¬·ЦұжВКЦРТІІЙУГБЛАаЛЖөДЛјВ·ЎЈОТГЗөДCS-SFTІгУРЧЕПаЛЖөДҫ«ЙсЈ¬ө«КЗУРЧЕІ»Н¬өДІЩЧчәНДҝөДЎЈОТГЗФЪТ»ҙО·ЦБСЙПІЙУГҝХјдМШХчұд»»Ј¬Ҫ«Чу·ЦБСЧчОӘЙн·ЭМШХчЈ¬ТФҙпөҪәЬәГөДХжКөРФәНұЈХж¶ИөДЖҪәвЎЈ
Local Component Discriminators
ҫЦІҝіЙ·ЦЕРұрЖчЎЈұҫОДМбіцБЛҫЦІҝұкК¶·ыАҙ№ШЧўҫЦІҝҝй·ЦІјЎЈөұУҰУГөҪИЛБіКұЈ¬ХвР©ЗшұрРФЛрК§ұ»ЗҝјУФЪөҘ¶АөДУпТеГжІҝЗшУтЎЈОТГЗТэИлөДИЛБііЙ·ЦЛрК§ТІІЙУГБЛХвСщөДЙијЖЈ¬ө«ФЪС§П°өҪөДЕРұрМШХчөД»щҙЎЙПҪшРРБЛҪшТ»ІҪөДСщКҪја¶ҪЈ¬ЦӨГчБЛХвЦЦ·Ҫ·Ё¶Ф»ЦёҙГжІҝПёҪЪКЗУРР§өДЎЈ
3. Methodology
3.1. Overview of GFP-GAN
ФЪёш¶ЁНЛ»ҜОҙЦӘөДКдИлИЛБіНјПсxxxөДЗйҝцПВЈ¬ГӨДҝөДИЛБіРЮёҙөДДҝөДКЗ№АјЖіцУлGTНјПсyyyҫЎҝЙДЬПаЛЖөДёЯЦКБҝНјПсy^\hat{y}y^?ЎЈ
ПВНјКЗёГСРҫҝөДЦчТӘҝтјЬ, КдИлТ»ХЕөНЦКБҝөДИЛБі, КЧПИҫӯ№э UNet Ҫб№№, ФЪХвАпУРёҙФӯ loss өД L1 ФјКш (»ТЙ«јэН·)Ј¬УГТФҙЦВФөШИҘіэ degradations, ұИИзФлЙщЎўДЈәэЎўJPEG өИЎЈН¬КұёьЦШТӘөДКЗ, өГөҪМбИЎөД latent МШХчПтБҝ (ВМЙ«јэН·) әНҝХјдМШХч (»ЖЙ«јэН·)ЎЈ

ИзНј2ЛщКҫЈ¬GFP-GANНшВзјЬ№№°ьә¬БЛТ»ёцНЛ»ҜИҘіэДЈҝйәНТ»ёцФӨСөБ·өДИЛБіGANЧчОӘИЛБіПИСйЈ¬ЖдЦРФӨСөБ·өДИЛБіGANНЁ№эЦұҪУөДТюұдБҝУіЙдәНјёёцНЁөА·ЦёоҝХјдМШХчұд»»(CS-SFT)ІгТФҙЦөч·ҪКҪБ¬ҪУЎЈКЧПИНЛ»ҜДЈҝйЈ¬ИҘіэКдИлxxxөДҝЙјЖЛгНЛ»ҜЈ¬ІўМбИЎЗеОъөДТюұдБҝFlatentF_{latent}Flatent?әНІ»Н¬·ЦұжВКҝХјдМШХчFspaticalF_{spatical}Fspatical?;И»әуТюұдБҝFlatentF_{latent}Flatent?ЖҘЕдөҪЦРјдТюұдБҝWЈ¬ЖдКЗУРЛщС§П°өДИЛБіGAN·ЦІјЦРҪУҪьИЛБіөДҙЦІЪјмЛчМШХчFpriorF_{prior}Fprior? ;ФЪЛщМбіцөДCS-SFTЦРТФҙЦІЪөҪҫ«ПёөД·ҪКҪ,Ҫ«І»Н¬·ЦұжВКҝХјдМШХчFspatialF_{spatial}Fspatial?УГУЪөчЦЖИЛБіGANМШХчFpriorF_{prior}Fprior?Ј¬ЧоәуЙъіЙёЯЗеөДИЛБіЎЈ
3.2. Degradation Removal Module
НјПс°ьә¬УРРн¶аІ»Н¬өДНЛ»ҜТтЛШЎЈұҫОДЛщМбіцөДНЛ»ҜИҘіэДЈҝйЈ¬УГУЪМбИЎЗеОъМШХчЈ»ұҫДЈҝй»щУЪU-netНшВзДЈРНЈ¬ІўМбёЯҙу·¶О§ДЈәэөДККУҰРФәНЙъіЙІ»Н¬·ЦұжВКөДМШХчЎЈАыУГҪрЧЦЛюёҙФӯЦёөјЦРјдҪб№ыЎЈ
3.3. Generative Facial Prior and Latent Code Mapping
ІЙУГStyleGANg2өД·Ҫ·ЁЈ¬Ҫ«КдИлНјПсЧӘ»»өҪЦРјдТюұдБҝWЈ¬ёГұдБҝW УГУЪҙУҝЙС§П°өДИЛБіGAN·ЦІјЦРјмЛчЧоПаҪьөДИЛБіМШХчЈ»И»әуЈ¬ДЬ№»УГGANМШХч»сөГЙъіЙКҪИЛБіПИСйFpriorF_{prior}Fprior?ЎЈ

3.4. Channel-Split Spatial Feature Transform
АыУГПИСйМШХчFpriorF_{prior}Fprior?әНМбИЎөДЗеОъМШХчFlatentF_{latent}Flatent?Ј¬ұҫДЈҝйЙъіЙёЯЗеНјПсЎЈҪијш·ЦёоМШХчЧӘ»»·Ҫ·Ё,ёш¶ЁҙУЗеОъМШХчFlatentF_{latent}Flatent?ЦРС§П°өҪөДТ»Чйұд»»ІОКэ(ҰВ,ҰБ)(\beta,\alpha)(ҰВ,ҰБ)Ј¬И»әу¶ФПИСйМШХчҪшРРөчХы:
Foutput=SFT(FpriorЁOҰБ,ҰВ)=ҰБЎСFprior+ҰВF_{output} = SFT(F_{prior}|\alpha,\beta) = \alpha \odot F_{prior} + \betaFoutput?=SFT(Fprior?ЁOҰБ,ҰВ)=ҰБЎСFprior?+ҰВ
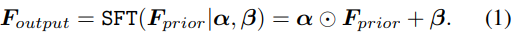
ө«КЗХвЦЦ·Ҫ·ЁДСТФФЪХжКөРФәНұЈХж¶ИЦ®јдҙпөҪәГөДЖҪәвЈ»ТтҙЛұҫОДҪ«ПИСйМШХч·ЦҪвОӘЙн·ЭМШХчІҝ·Ц(УГУЪұЈБф)ТФј°ұд»»МШХчІҝ·Ц(УГУЪМШХчөчЦЖ)Ј¬ІЙУГТФПВөДРОКҪҪшРРЗуҪвЈә

ФЪИЛБіёҙФӯЦР, УлЖдЛы№ӨЧчІ»Н¬, ҪцҪцНЁ№эөчЦЖ StyleGAN өД latent codes, ТтОӘГ»УРҝјВЗҫЦІҝөДҝХјдРЕПў»бј«ҙуУ°ПмИЛБіөД identityЎЈТтҙЛТІТӘАыУГҝХјдөДМШХчАҙөчЦЖ StyleGAN АпГжөДМШХчЎЈ
GFP-GAN »щУЪПЦУРөДёЯР§өДҝХјдМШХчұд»» (Spatial Feature TransformЈ¬SFT) ІгАҙҙпөҪХвёцДҝөДЎЈЛьДЬ№»ёщҫЭКдИлөДМхјю(ХвАпКЗМбИЎөДөНЦКБҝөДНјПсМШХч), ЙъіЙіЛРФМШХчәНјУРФМШХчЈ¬¶Ф StyleGAN өДМШХчЧц·ВЙдұд»»ЎЈОӘБЛҪшТ»ІҪЖҪәвКдИлНјПсөДРЕПўәН StyleGAN ЦРөДРЕПў, GFP-GAN ҪшТ»ІҪҪ«НЁөАІр·ЦОӘБҪІҝ·Ц, Т»Іҝ·ЦУГАҙөчЦЖ, Т»Іҝ·ЦЦұҪУМшФҫ№эИҘЎЈХвСщөДөчЦЖ»бФЪУЙРЎөҪҙуөДГҝёцҝХјдіЯ¶ИЙПҪшРР, МбёЯөчЦЖөДР§№ыЎЈ
3.5. Model Objectives
ЛрК§әҜКэЦчТӘ°ьАЁЛДёцЈә
- ФјКшКдіцy^\hat{y}y^?ҪУҪьGT yyyөДЦШҪЁЛрК§
- »ЦёҙХжКөОЖАнөД¶Фҝ№ЛрК§
- МбіцГжІҝЧйіЙЛрК§ҪшТ»ІҪМбЙэГжІҝПёҪЪ
- Йн·ЭұЈБфЛрК§
Reconstruction Loss Lrec\mathcal{L}_{rec}Lrec?Јә НјПсПсЛШј¶ЦШ№№ТФј°VGGІгҙОөДёРЦӘlossЦШ№№

Adversarial Loss Ladv\mathcal{L}_{adv}Ladv?Јә ЙъІъХжКөОЖАнЈ¬АаЛЖУЪStyleGAN2Ј¬ІЙУГБЛLogistic LossЈ¬СөБ·И«ҫЦөД Discriminator, ЕР¶ПИЛБіКЗ·сХжКөЈ»Г»УРАнҪвХвАпОӘКІГҙІ»РҙЕРұрЖчЛрК§


StyleGANСЎУГұҘәНВЯјӯЛ№ЪРЛрК§Ј¬Loss_G=-log(exp(D(G(z)))+1)
І»ә¬МЭ¶ИіН·ЈКұЈ¬Loss_D=log(exp(D(G(z)))+1)+log(exp(-D(x))+1)
SoftPlusәҜКэ

ЛщТФ№«КҪ(4)ҝЙТФРҙіЙЈә
Ladv=?ҰЛadvEy^log[exp(D(G(z)))+1]\mathcal{L}_{adv}=-\lambda_{adv}\mathbb{E}_{\hat{y}}log[exp(D(G(z)))+1]Ladv?=?ҰЛadv?Ey^??log[exp(D(G(z)))+1]
Facial Component Loss Lcomp\mathcal{L}_{comp}Lcomp?Јә КЧПИУГROI¶ФЖлАҙІГјфёРРЛИӨөДЗшУтЈ¬¶ФУЪГҝёцЗшУтЈ¬СөБ·¶АБўөДәНРЎөДҫЦІҝК¶ұрЖчАҙЗш·Ц»ЦёҙөДpatchesКЗ·сХжКөЈ¬Ҫ«patchesНЖПтҪУҪьЧФИ»өДГжІҝіЙ·Ц·ЦІјЎЈ
НЁ№эROI alignЦ®ә󣬶ФГҝТ»ёцROIІҝ·ЦҪшРРЕР¶ЁЈ»КЧПИЈ¬КЗЕР¶Ё¶ФУҰөДROIКЗ·сХжЈ¬ҪУЧЕЈ¬АыУГGram matrix statistics[6]Ј¬ЕР¶ПROIөД·зёсloss
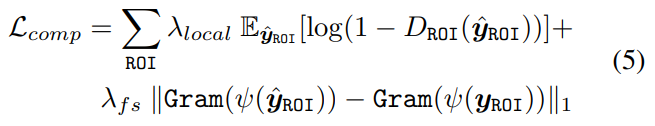
Identity Preserving Loss Lid\mathcal{L}_{id}Lid?Јә ОӘБЛұЈіЦИЛБі identity өДТ»ЦВ, К№УГБЛИЛБі identity Т»ЦВЛрК§әҜКэЈЁФӨСөБ·өДArcFaceЈ©Ј¬јҙФЪИЛБіК¶ұрДЈРНөДМШХчҝХјдЦРИҘАӯҪьЈ¬И·ұЈЦШ№№Ҫб№ыУлGTҪУҪьЎЈ
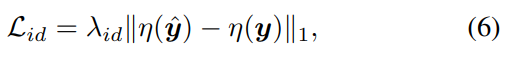

ЧоЦХЛрК§ИзПВЈә
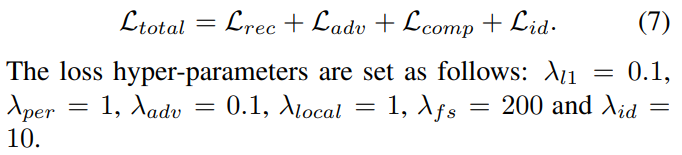
4. Experiments
4.1. Datasets and Implementation
әНЦ®З°ҙуІҝ·Ц№ӨЧчАаЛЖЈ¬GFP-GAN ІЙУГБЛ Synthetic КэҫЭөДСөБ··ҪКҪЎЈСРҫҝХЯГЗ·ўПЦФЪәПАн·¶О§өД Synthetic КэҫЭЙПСөБ·, ДЬ№»әӯёЗҙуІҝ·ЦөДКөјКЦРөДИЛБіЎЈGFP-GAN өДСөБ·ІЙУГБЛҫӯөдөДҪөЦКДЈРН, јҙПИёЯЛ№ДЈәэ, ФЩҪөІЙСщ, И»әујУ°ЧёЯЛ№ФлЙщ, ЧоәуК№УГ JPEG С№ЛхЎЈ

СөБ·КэҫЭјҜЈә әПіЙНЛ»ҜНјПсЈ»FFHQКэҫЭјҜ
ІвКФКэҫЭјҜЈәCelebA-TestЎўLFW-TestЎўCelebChild-TestЎўWebPhoto-Test
ЖАјЫЦёұкЈә PSNRЎўSSIMЈ¬ FIDЈЁјЖЛгХжКөСщұҫУлЙъіЙСщұҫФЪМШХчҝХјдЦ®јдөДҫаАлЈ©ЎўNIQEЎўС§П°ЦӘҫхНјПсІ№¶ЎПаЛЖ¶ИЈЁLPIPSЈ©

КөПЦЈә ІЙУГКдіцОӘ512ЎБ512512\times512512ЎБ512өДФӨСөБ·StyleGANЧчОӘGFPЎЈStyleGAN2өДНЁөАіЛКэЙиЦГОӘ1ЎЈУГУЪҪөҪвИҘіэөДUNetУЙ7ёцПВІЙСщәН7ёцЙПІЙСщЧйіЙЈ¬ГҝҙОІЙСщТ»ёцІРІоҝйЎЈ¶ФУЪГҝёцCS-SFTІгЈ¬ОТГЗК№УГБҪёцҫн»эІг·ЦұрЙъіЙ·ВЙдІОКэҰБәНҰВЎЈ
4.2. Comparisons with State-of-the-art Methods

ОТГЗұИҪПБЛGFP-GANУлјёЦЦЧоПИҪшөДГжІҝРЮёҙ·Ҫ·Ё:HiFaceGAN[69]ЎўDFDNet[46]Ўў
PSFRGAN [6]Ј¬ Super-FAN [4]Ј¬ WanөИ[63]ЎЈУГУЪГжІҝРЮёҙөДөӘ»ҜпШө№ЦГ·Ҫ·Ё:Вціе[54]әНmanprior[20]ТІұ»ДЙИлұИҪПЎЈОТГЗ»№ұИҪПБЛОТГЗөДGFP-GANУлНјПс»Цёҙ·Ҫ·Ё:
RCAN [75]Ј¬ ESRGAN[66]әНDeblurGANv2[41]Ј¬ОТГЗФЪОТГЗөДГжІҝСөБ·јҜЙП¶ФЛьГЗҪшРРОўөчЈ¬ТФұгҪшРР№«ЖҪұИҪПЎЈОТГЗІЙУГБЛЛыГЗөД№Щ·ҪҙъВлЈ¬іэБЛSuper-FANЈ¬ОТГЗК№УГБЛЦШРВКөПЦЎЈ


ОӘБЛҪшРРЖА№АЈ¬ОТГЗК№УГБЛ№г·әК№УГөД·ЗІОҝјёРЦӘЦёұк:FID[28]әНNIQE[55]ЎЈОТГЗ»№ІЙУГПсЛШј¶¶ИБҝ(PSNRәНSSIM)әНёРЦӘ¶ИБҝ(LPIPS[74])УлCelebA-TestөДGTҪшРРұИҪПЎЈОТГЗФЪArcFace[11]МШХчЗ¶ИлЦРУГҪЗ¶ИАҙІвБҝЙн·ЭҫаАлЈ¬КэЦөФҪРЎұнГчЙн·ЭФҪҪУҪьGTЎЈ
әПіЙCelebA-TestЎЈФЪБҪЦЦЙиЦГПВҪшРРұИҪП:1)КдИләНКдіц·ЦұжВКПаН¬өДГӨДҝИЛБіРЮёҙЎЈ2) 4ЎБ4\times4ЎБИЛБіі¬·ЦұжВКЎЈЧўТвЈ¬ОТГЗөД·Ҫ·ЁҝЙТФ»сИЎёьРВөДІЙСщНјПсЧчОӘИЛБіі¬·ЦұжВКөДКдИлЎЈ
ёчЙиЦГөД¶ЁБҝҪб№ыИзұн1әНұн2ЛщКҫЎЈФЪХвБҪЦЦЙиЦГПВЈ¬GFP-GAN¶јҙпөҪБЛЧоөНөДLPIPSЈ¬ХвұнГчОТГЗөДҪб№ыФЪёРЦӘЙПҪУҪьУЪGTЎЈGFP-GANТІ»сөГБЛЧоөНөДFIDәНNIQEЈ¬ұнГчКдіц·ЦұрҪУҪьХжКөИЛБі·ЦІјәНЧФИ»НјПс·ЦІјЎЈіэБЛёРЦӘРФДЬЈ¬ОТГЗөД·Ҫ·Ё»№ұЈБфБЛёьәГөДЙн·ЭЈ¬ТФЧоРЎөДіМ¶ИФЪИЛБіМШХчЗ¶ИлЎЈРиТӘЧўТвөДКЗЈ¬ПсЛШіЯ¶ИөДPSNRәНSSIMУлИЛАа№ЫІмХЯөДЦч№ЫЖАјЫөДПа№ШРФІўІ»әГЈ¬ОТГЗөДДЈРНТІІ»ЙГіӨХвБҪёціЯ¶ИЎЈ


¶ЁРФҪб№ыјыНј3ЎўНј4ЎЈ1)TУЙУЪЗҝҙуөДГжІҝЙъіЙПИСйЈ¬ОТГЗөДGFPGAN»ЦёҙИзКөөДПёҪЪФЪСЫҫҰ(Н«ҝЧәНҪЮГ«)Ј¬САіЭөИЈ»2)ОТГЗөД·Ҫ·ЁКЗҪ«ГжІҝЧчОӘТ»ёцХыМеАҙҙҰАн»№ҝЙТФ»ЦёҙәНЙъіЙұЖХжөДН··ўЈ¬¶шТФЗ°ТААөЧйјюЧЦөдөД·Ҫ·Ё(DFDNet)»тХЯҪвОцУіЙд(PSFRGAN)І»ДЬІъЙъИзКөөДН··ўОЖАн(өЪ¶юЕЕЈ¬Нј3)ЎЈ3)GFP-GANДЬ№»ұнКҫұЈіЦұЈХж¶ИЈ¬УлPSFRGANТ»СщЈ¬GFP-GANөДЧмЧФИ»ұХәПЈ¬І»ЗҝЦЖФцјУСАіЭ(өЪ¶юЕЕЈ¬Нј3)ЎЈФЪНј4ЦРЈ¬GFP-GAN»№ДЬ»ЦёҙәПАнөДСЫҫҰЧўКУ·ҪПт
ХжКөКАҪзөДLFW, CelebChildәНWedPhoto-TestЎЈ ОӘБЛІвКФ·ә»ҜДЬБҰЈ¬ОТГЗФЪИэёцІ»Н¬өДХжКөКэҫЭјҜЙПЖА№АОТГЗөДДЈРНЎЈ¶ЁБҝҪб№ыјыұн3ЎЈОТГЗөДGFP-GANФЪИэёцХжКөКАҪзөДКэҫЭјҜЙП¶јИЎөГБЛЧҝФҪөДРФДЬЈ¬ПФКҫБЛЖдЧҝФҪөД·ә»ҜДЬБҰЎЈ
ЛдИ»PULSEТІҝЙТФ»сөГҪПёЯөДёРЦӘЦКБҝ(ҪПөНөДFID·ЦКэ)Ј¬ө«ІўІ»ДЬұЈБфИзНј5ЛщКҫөДИЛБіЙн·ЭЎЈ


¶ЁРФұИҪПИзНј5ЛщКҫЎЈGFP-GANНЁ№эЗҝҙуөДЙъіЙПИСй№ҰДЬЈ¬¶ФХжКөХХЖ¬БӘәПҪшРРГжІҝРЮёҙәНЙ«ІКФцЗҝЎЈОТГЗөД·Ҫ·ЁҝЙТФФЪёҙФУөДХжКөКАҪзНЛ»ҜЗйҝцПВІъЙъұЖХжөДИЛБіЈ¬¶шЖдЛы·Ҫ·ЁОЮ·Ё»ЦёҙЦТКөөДИЛБіПёҪЪ»тІъЙъОұУ°(МШұрКЗФЪНј5өДwebphotoІвКФЦР)ЎЈіэіЈјыөДИЛБііЙ·ЦИзСЫҫҰәНСАіЭНвЈ¬GFP-GANФЪН··ўәН¶ъ¶дЙПөДұнПЦТІёьәГЈ¬ТтОӘGFPУЕПИҝјВЗөДКЗХыёцГжІҝЈ¬¶шІ»КЗөҘ¶АөДІҝ·ЦЎЈК№УГSC-SFTІгЈ¬ОТГЗөДДЈРНДЬ№»КөПЦёЯұЈХж¶ИЎЈИзНј5ЧоәуТ»РРЛщКҫЈ¬ТФНщөД·Ҫ·Ёҙу¶аОЮ·Ё»ЦёҙұХЙПөДСЫҫҰЈ¬¶шОТГЗөД·Ҫ·ЁҝЙТФУГҪПЙЩөДИЛ№ӨіЙ№Ұ»ЦёҙЎЈ
4.3. Ablation Studies
CS-SFTІгЎЈ Изұн4[ЕдЦГa)]әННј6ЛщКҫЈ¬өұИҘіэҝХјдөчЦЖІгЈ¬ИзЈ¬Ц»ұЈБфГ»УРҝХјдРЕПўөДТюұдБҝКұЈ¬јҙК№УРЙн·ЭұЈБфЛрК§Ј¬»ЦёҙәуөДИЛБіИФІ»ДЬұЈБфИЛБіЙн·Э(ҪПёЯөДLIPS scoreәНҪПҙуөДDeg.)ЎЈТтҙЛЈ¬ФЪCS-SFTІгЦРК№УГөД¶а·ЦұжВКҝХјдМШХч¶ФУЪұЈіЦұЈХж¶ИЦБ№ШЦШТӘЎЈөұОТГЗЗР»»CS-SFTІгјтөҘSFTІг(ЕдЦГb)ФЪұн4),ОТГЗ№ЫІмөҪ1)ёРЦӘЦКБҝ»бҪөөНЛщУРЦёұкәН2)ЛьұЈБфЗҝҙуөДЙн·Э(РЎ¶ИЎЈ)ЧчОӘКдИлНјПсМШРФК©јУУ°ПмЛщУРөДөчЦЖМШРФәННЛ»ҜөДКдИлКдіцөДЖ«јы,ҙУ¶шөјЦВҪПөНөДёРЦӘЦКБҝЎЈПаұИЦ®ПВЈ¬CSSFTІгНЁ№эөчХыМШХчөД·ЦБСМṩБЛТ»ёцәЬәГөДХжКөРФәНұЈХж¶ИөДЖҪәвЎЈ
ФӨСөБ·GANОӘGFPЎЈФӨСөБ·өДGANМṩ·бё»¶аСщөД»Цёҙ№ҰДЬЎЈИз№ыОТГЗІ»К№УГЙъіЙИЛБіПИСйЈ¬ҝЙТФ№ЫІмөҪРФДЬПВҪөЈ¬Изұн4[ЕдЦГc)]әННј6ЛщКҫЎЈ
ҪрЧЦЛю»ЦёҙөДЛрК§ЎЈФЪНЛ»ҜИҘіэДЈҝйЦРТэИлБЛҪрЧЦЛю»ЦёҙЛрК§Ј¬ФцЗҝБЛ¶ФПЦКөКАҪзЦРёҙФУНЛ»ҜөД»ЦёҙДЬБҰЎЈИз№ыГ»УРХвЦЦЦРјдја¶ҪЈ¬әуРшөчЦЖөД¶а·ЦұжВКҝХјдМШХчИФҝЙДЬ·ўЙъНЛ»ҜЈ¬өјЦВРФДЬҪПІоЈ¬Изұн4[ЕдЦГd)]әННј6ЛщКҫЎЈ
ГжІҝЧйјюЛрК§ЎЈОТГЗұИҪПБЛ1)ИҘіэЛщУРөДГжІҝіЙ·ЦЛрК§Ј¬2)Ц»ұЈБфіЙ·ЦјшұрЖчЈ¬3)Пс[64]ДЗСщФцјУ¶оНвөДМШХчЖҘЕдЛрК§Ј¬4)»щУЪGramНіјЖ[16]ІЙУГ¶оНвөДМШХч·зёсЛрК§өДҪб№ыЎЈИзНј7ЛщКҫЈ¬МШХч·зёс¶ӘК§өД·ЦБҝјшұрЖчҝЙТФёьәГөШІ¶ЧҪСЫЗт·ЦІјЈ¬Іў»ЦёҙГІЛЖҝЙРЕөДПёҪЪЎЈ

4.4. Limitations
ҫЎ№ЬОТГЗУГәПіЙКэҫЭСөБ·өДДЈРНЦӨГчБЛ¶ФХжКөКАҪзНјПсөДБјәГ·ә»ҜЈ¬ИФИ»УРТ»Р©ҫЦПЮРФЎЈИзНј8ЛщКҫЈ¬НЛ»ҜКұ¶ФХжКөНјПсАҙЛөКЗј«ЖдСПЦШөДЈ¬ёҙФӯөДГжІҝПёҪЪұ»GFP-GANЕӨЗъБЛЎЈОТГЗөД·Ҫ·ЁТІ»бІъЙъІ»ЧФИ»өДҪб№ыЎЈХвКЗТтОӘЧЫәПНЛ»ҜәНСөБ·КэҫЭ·ЦІјУлПЦКөКАҪзөДЗйҝцІ»Н¬ЎЈТ»ёцҝЙДЬөД·Ҫ·ЁКЗҙУХжКөКэҫЭЦРС§П°ХвР©·ЦІјЈ¬¶шІ»КЗЦ»КЗК№УГәПіЙКэҫЭЈ¬ХвКЗОҙАҙөД№ӨЧчЎЈ

5. Conclusion
МбіцGFP-GANҝтјЬЈ¬АыУГ·бё»әН¶аСщ»ҜөДЙъіЙКҪИЛБіПИСйАҙНкіЙҫЯУРМфХҪРФөДГӨДҝөДИЛБіРЮёҙИООсЎЈХвТ»ПИСйұ»ДЙИлөҪРВөДНЁөА·ЦёоҝХјдМШХчЧӘ»»ІгөДРЮёҙ№эіМЦРЈ¬К№ДЈРНДЬ№»әЬәГөШЖҪәвХжКөРФәНұЈХж¶ИЎЈҙЛНвЈ¬ҪйЙЬБЛИЛБіЧйіЙЛрК§ЎўЙн·ЭұЈБфЛрК§әНҪрЧЦЛюРЮёҙЦёөјөИҫ«ПёЙијЖЎЈ№г·әөДұИҪПұнГчЈ¬GFP-GANФЪБӘәПГжІҝ»ЦёҙәНХжКөКАҪзНјПсөДСХЙ«ФцЗҝ·ҪГжҫЯУРУЕФҪөДДЬБҰЈ¬УЕУЪПЦУРјјКхЎЈ
ІОҝјОДПЧ
https://zhuanlan.zhihu.com/p/344602972
https://finance.sina.com.cn/tech/2021-04-05/doc-ikmyaawa6744662.shtml
https://www.bilibili.com/video/BV1qi4y1t7nb?from=search&seid=3107006202936880119
https://www.jianshu.com/p/58fd418fcabf