Real-World Blur Dataset for Learning and Benchmarking Deblurring Algorithms
����һƪECCV2020�����ݼ����ģ���Ҫ�����������һ����ʵ������Ϳͼ������ݼ�������һ�����ڿӡ�������
����һ��������˵�ġ��ڿӹ�������
���й������Դ��·�Ϊ���֣������������ڿӣ��������������ӣ�����������˻�ѡ���¡��ķ�ʽ��������������������ӣ����ǰ���ڳ����Ŀӣ�����һ�־��Ƕ���һ���µ����⣬��������ȥ������Ƚ��д����Եľ���ImageNet�ˣ���ƪ�������Ҳ����������ڿӡ�
�о��ڿ�Ҫ��������Լ۱ȵĶ�~

GitHub��RealBlur
�ȴӱ��⿴��������ʵֻ��һ���ؼ���Real-World
��Ϊȥģ��������Ӵ�ͳ���������ѧϰ������ʵ���ϲ�û�������Ҫ��ȥģ����ͼƬ����Ϊ�������ʵ��ͼƬ��Ϊģ��ͼƬȥѵ���Ļ�����ȥ�����ҿɹ��ο���GT�أ���û��GTҲ���Ӽ���loss�ˡ�����ȥģ�������������õ����ݼ�GOPRO���ݼ���REDS���ݼ�����Nah����ģ������ø�������ճ���ģ����ͼ��Ȼ������������ϴ�����ģ����ͼ��ԭͼ��������GT����ͳ���һ�����⣬����ô��֤�㴦��������ģ��ͼ���������ʵ�����ģ��ͼ��
��ҵĽ��˼·�����㣬��һ��ѧϰ���ɸ�������ʵ�����ģ��ͼ����
����CVPR2020��ͼʵ���ҵ���ƪ�����ǵ�˼·��ͨ������GAN��һ�������ɸ�������ʵ�����ģ��ͼ��һ������ѧϰȥģ�������DeblurGan����һ���Ľ�����DeblurGan��˼·��ֻ���ǵ���GAN��ѧϰȥģ������
��������ܲ���ֱ��ͨ������������ʵ�����ģ��ͼ������
������뷨���ܲ���ͨ�������̽���ľ�ͷ������ͼ��ԣ�������ͨ������������ͼ�������blur image��GT�أ������Ļ����漰ͼƬ����������ˣ���ƪ������ʵҲ�����������뷨��

����˵������̨���ͬʱ���㣬����һ�����ͨ���Ϳ����ٶȲ���ģ��ͼ����һ��ͨ���߿����ٶȲ���GTͼ��Ȼ����ͨ�����ǵĺ������������ɸ���������ʵGTͼ��
֮ǰ��Һܶ��˶��й����Ƶ��뷨��������Ҳ��ϣ��ͨ�������ķ�ʽ����һ���µ����ݼ���˵���þͶ����˹�������������ͼ����������ʼ��û��˼·��ֱ��������ƪ���ģ��������ڿ��Է������idea��~�˼Ұ�������Ѿ��ں��ˣ���Ҫ����ȥ���Ҫ����ֻ���ڱ�Ŀ��ˡ�
Abstract
Abstract��˵�����㹤����
��һ���������ʵ����ģ��ͼ��͵�����ʵ����ͼ��Ĵ��ģ���ݼ���
�����Ϊ�˴���ͼ������������һ�ֺ������������ɸ������ĵ�����ʵͼ��
1.Introduction
��������һ��Ϊʲô����ȥ����ʵ�����ģ�����ݼ���
�ڴ���ģ��������£�Ӧ��ģ��ͼ������ݼ��������ʵ������ͼ����м��ζ��롣����ζ������ͼ��Ӧ����ͬһ���λ�����㣬������ѣ���Ϊ����ҡ�������������ģ����ͼ����
���⣬����ͼ��ȥģ������ʵ����ģ�����ݼ�Ӧ��������Ҫ�����ȣ����ݼ�Ӧ������������������������˶�ģ����Ƶ�����������������Σ�������������ͼ��Ӧ�þ��о�����С�����������ģ���͵�����ʵ������ͼ��Ӧ������ȶ���
���ݼ���������RealBlur��������������ͬͼ�����ݵ��Ӽ���ɣ�����һ���Ǵ����ԭʼͼ�����ɵģ���һ���������ISP������JPEGͼ�����ɵġ�ÿ���Ӽ��ṩ232�����⾲̬������4,556��ģ������ʵ������GTͼ�����ݼ��е�ģ��ͼ������������ģ�������ڻ谵�Ļ���������ҹ���Ľֵ������ڷ��䣩�в����Ժ����˶�ģ������������
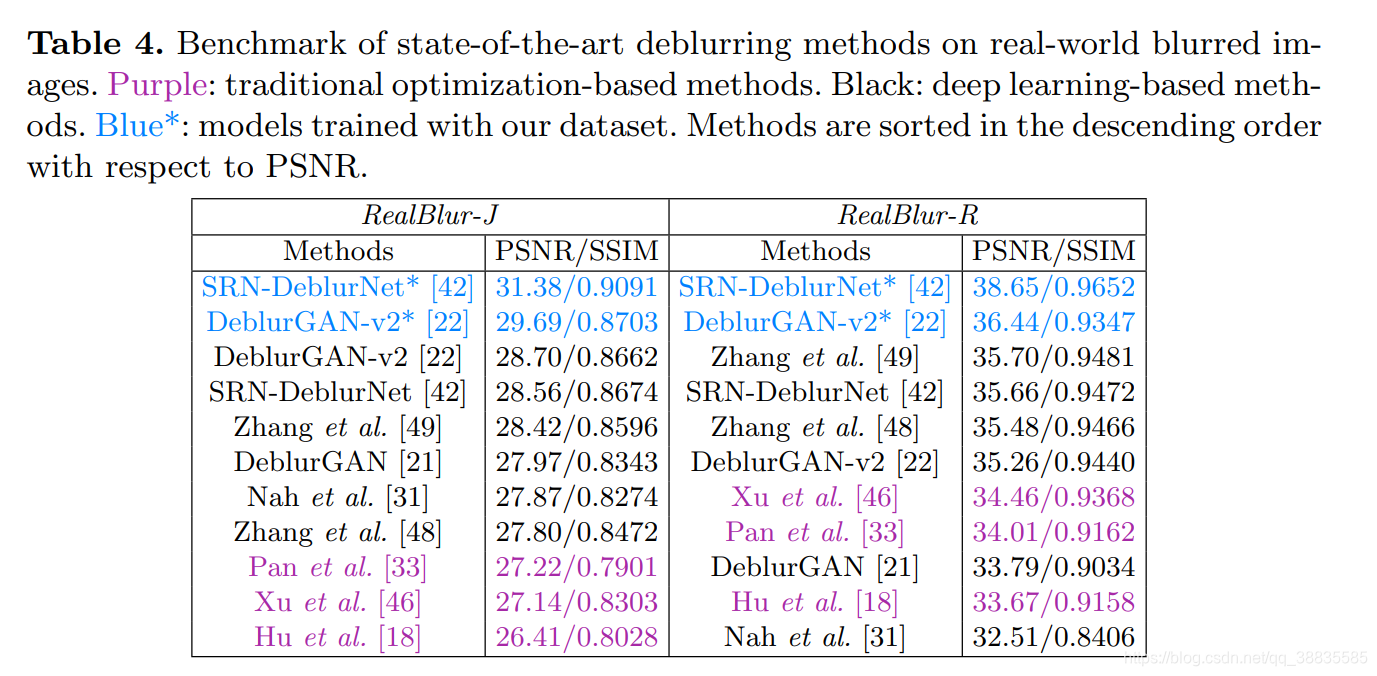
������ƪ����ֻ�����һ�����ݼ���������ȻͶ���˺ܴ�Ĺ������������ϰ����е����ݼ�������REDS��������һ���Աȣ�Ҳ��������ݼ��ϲ����˾������ȥģ��������
���������Լ�Ҳ�ᵽ�����ݼ�û���ռ���̬����ģ��ͼ�����������Ǹ����������ɵġ�big��������������ƣ��������������з�����ʹ��������ݼ�ѵ����������Ȼ���Ժܺõ��ƹ㵽�����ƶ�����Ķ�̬������
2.Related Work
������һ��Ƚ���Ҫ�ľ������߽�����һ��ͨ��GAN���ɸ���ʵ��ģ��ͼ�����ַ�������Ȼͨ��GAN�Ͳ���Ҫ��ģ��������ͼ�ζ����ˣ� ���ǣ����������������������磬��˽������ض����������磬������֡�
Ȼ��ͽ�����һ�����ǵ�ͼ��ɼ�ϵͳ���ܵ���ƪ��ͳ������������
Ben-Ezra, M., Nayar, S.: Motion deblurring using hybrid imaging. In: CVPR. pp. 657�C664 (2003)
Tai, Y.W., Du, H., Brown, M.S., Lin, S.: Image/video deblurring using a hybrid camera. In: CVPR (2008)
Li, F., Yu, J., Chai, J.: A hybrid camera for motion deblurring and depth map super-resolution. In: CVPR (2008)
Yuan, L., Sun, J., Quan, L., Shum, H.: Image deblurring with blurred/noisy image pairs. In: SIGGRAPH (2007)
Ben-Ezra��Nayar ����ƪ�����һ�ֻ�������ϵͳ����ϵͳ�䱸��һ������ĸ��ٵͷֱ����������������������˶��� Tai��ƪ��չ�˿ռ�仯ģ���ķ����� Li�����һ�������˶�ȥģ�������ͼ���ֱ��ʵĻ�������ϵͳ�� Yuan��Sorel����ʹ�ð�Χ�ع�������һ������ģ��ͼ���Խ���ȷ��ģ���˹��ơ�
����������������Щ��������Ϊģ���˹��ƶ���Ƶģ��Ȳ��ṩ����������ʵGTͼ��Ҳ���ṩ���Ը���ͼ�������ĺ���������
�������������Image Acquisition System��Postprocessing��
3.Image Acquisition System and Process
Image Acquisition System
Ϊ��ͬʱ����ģ����������ͼ������˫����ͷϵͳ�����ǵ�ϵͳ����һ������������������ͷ���Ա���Щ����ͷ���Բ�����ͬ�ij�����������ͷ�������װ�ڹ�ѧ����У��Ա����������ܹۿ������ⲿ�Ĺ��ߵ��˺���һ̨����ԵͿ����ٶ�����ģ����ͼ����һ̨����Ը߿����ٶ�����������ͼ������������侵ͷ��Ϊ��ͬ�ͺţ�Sony A7RM3��Samyang 14mm F2.8 MF����������ɶ������������ͬ����ͬʱ����ͼ��������ԭ�����ǵ�ϵͳ���Ϊ����ȫ������������Ǿ��ĸ߶����⾵��� **�� ���ȣ������뽫�������������ڲ�������ӳ�����ǵ����ݼ��У���Ϊ�����ISP������ģ��JPEGͼ���ԭʼͼ���Ϊ����������ȫ������������� ��ͷ��С�ʹ�������խ�Ǿ�ͷ���Ծۼ�����Ĺ⣬������ǿ��Ը���Ч������������ ��Ǿ�ͷ�������ڱ���ɢ��ģ��������ܻ���˶�ģ����ѧϰ��������Ӱ�졣
������������Ͼ����ܶ��롣Ϊ������������Ķ��뷽ʽ�����ǽ���������У[50��15]���������������֮���baseline�����Ƶ�baselineΪ8.22���ף���Ӧ����ȫ�ֱ����¾��볬��7.8�Ķ��������4�����ص��Ӳ�������ǵ��������ݼ��а�����1/4�²�����ͼ�������1�����ص��Ӳ
Image Acquisition Process
ʹ�����ǵ�ͼ��ɼ�ϵͳ�����Dz����˸������ں����ⳡ����ģ��ͼ����ÿ���������������Ȳ���һ�ԣ�����������ͼ����Ϊ�ο��ԣ����ǽ��ں�������������������ģ��ͼ��ļ��κ�ȶ��롣Ȼ�����Dz�����20����ͬ������ģ��������ͼ��������ͼ����������������Ķ����ԡ����ڲο��ԣ����ǽ������ٶ�����Ϊ1/80�롣��������ISO��Ȧ��С���Ա������������ɵ�ģ����Ȼ�����Ƕ�һ̨�����ʹ����ͬ�����������������������ͼ������һ̨������Ŀ����ٶ�����Ϊ1/2�롣 ISOֵ�Ȳο�ISOֵ��40������������ͬ���ȵ�ģ��ͼ��Ϊ�˲�������������������ֻ�轫ϵͳ���־�ֹ�Ի�ȡijЩͼ��Ȼ������ƶ�ϵͳ�Ի�ȡ����ͼ��������������£������ع�ʱ�䳤�����Ի�õ�ͼ��ģ�������Dz�����232����ͬ������4,738��ͼ�����ο��ԡ����Dz��������ԭʼ��ʽ��JPEG��ʽ������ͼ���������������ݼ���ԭʼͼ���е�RealBlur-R��JPEGͼ���е�RealBlur-J��ͼ3��ʾ��RealBlur���ݼ���ģ��ͼ���������

���������������֣��������ͽ��������ζ�������ȶ���,����ϸ�ڿ���ȥ�����������Ͳ�ϸ˵�ˣ�Ҳû̫������
5.Experiments
��ʵ��Ч��
Datasets and evaluation measure.
���ڻ����ԣ���RealBlur-R��RealBlur-J�����ѡ��182��������Ϊ���ǵ�ѵ����������50��������Ϊ���ǵIJ��Լ���ÿ��ѵ������3,758��ͼ�����ɣ����а���182���ο��ԣ���ÿ�����Լ���980��ͼ�����ɣ�û�вο��ԡ�������ѵ�����а����ο��ԣ��Ա��������ѧϰ����ͼ�������ӳ�䡣��RealBlur�⣬���ǻ��������������е�ȥģ�����ݼ���GoPro ��K��ohler�����ݼ��� GoPro���ݼ�������������ѧϰ�ķ�����ʹ����㷺�����ݼ�������ͨ����ϸ�������������������Ƶ֡�����ɵĺϳ����ݼ��� GoPro���ݼ�Ϊ��ѵ���Ͳ��Լ��ṩ��2,103��1,111��ģ����������ͼ�� K��ohler���˵����ݼ���һ�������ʵ���������С��ģͼ����Щͼ�������ܿ�ʵ���һ����в���ġ�����������һ�����ϳ����ݼ���������BSD500ϸ�����ݼ����ɵġ�
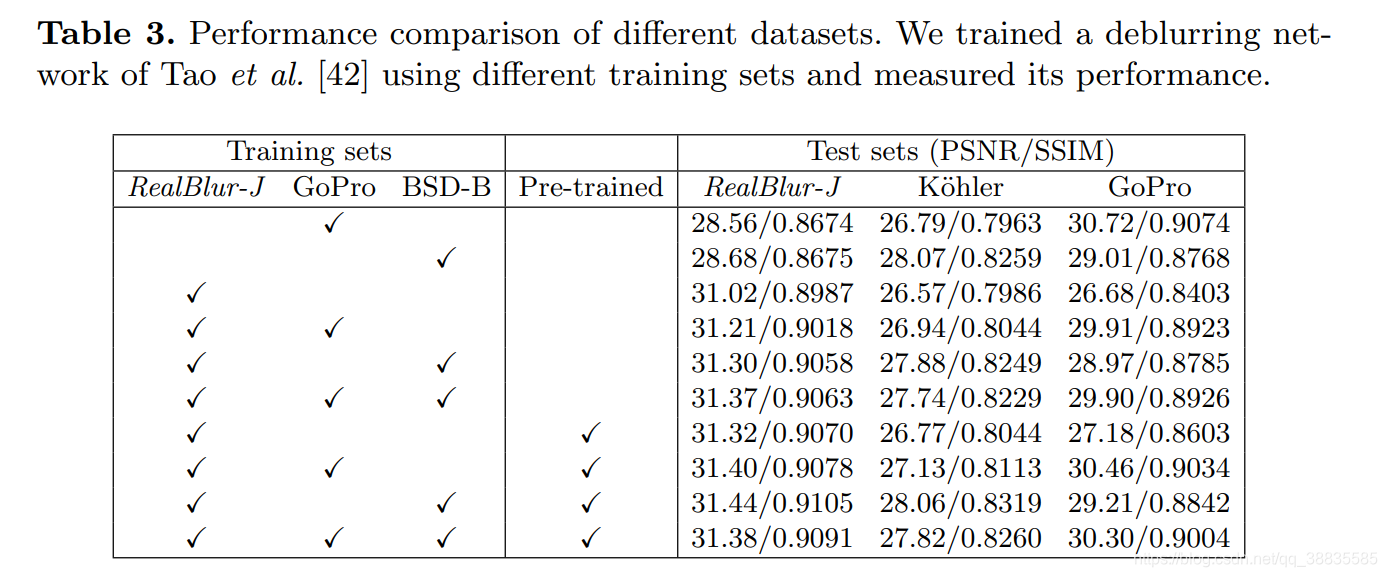
Dataset comparison and training strategy
�ڶ����е�ȥģ���������л�����֮ǰ�����Ƚ����ݼ����������������ݼ��Աȣ���Ѱ��ѵ��ȥģ���������Ѳ��ԡ�������˵��ʹ�ð���RealBlur���ڵIJ�ͬѵ�����ļ��ֿ����������ȥģ������IJ�ͬѵ��ģ�͡�Ȼ���������ڲ�ͬ���Լ��ϵ����ܡ�Ϊ�˽���������ʹ��SRNDeblurNet��
��2��3��ʾ�˲�ͬ���Լ���ѵ�����IJ�ͬ��ϵ����ܡ� ��Ԥѵ������ָʾ��ʹ��GoPro���ݼ�����Ԥ��ѵ����Ȩ�ػ��Ǵ�ͷ��ʼѵ�����硣�ӱ��п��Կ����������������ȣ�GoPro���ݼ�����2��3�еĵ�һ�У���RealBlur���Լ��ϵ����ܽϵͣ���֤��GoPro���ݼ�������ʵ����������ʵ�����ģ��ͼ�� BSD-B���ݼ�����2��3�еĵڶ��У���RealBlur���Լ��ϵ�����Ҳ�ܲ����K��ohler���˵IJ��Լ���ȴ�кܸߵ����ܣ����������ΪK��ohler���ˡ������ݼ��ӽ��ںϳɣ���Ϊ��ͼ�������ܿ�ʵ���һ����в���ġ���һ���棬RealBlur��ѵ��������2�ͱ�3�еĵ����У���RealBlur���Լ��ϻ���˸��ߵ����ܣ���֤������ʵ������ģ��ѵ�����ݵı�Ҫ�ԡ�

6 Conclusion
�����һ������ѧϰͼ��ȥģ���Ĵ��ģ��ʵ����ģ�����ݼ���Ϊ���ռ����ݼ������ǹ�����һ��ͼ��ɼ�ϵͳ����ϵͳ����ͬʱ����һ��ģ����������ͼ������һ�ֺ������������ɸ������ĵ�����ʵͼ���������伸�ζ����Ч����ȷ�ԡ�ͨ��ʵ�������RealBlur���ݼ����Լ������������ѧϰ��ȥģ������������������ƶ������϶���ʵ����ģ��ͼ������ܡ�
��������Ҳ�����˽��µĹ�������
�������������ɸ������ĵ�����ʵͼ���������伸�ζ����Ч����ȷ�ԡ�ͨ��ʵ�������RealBlur���ݼ����Լ������������ѧϰ��ȥģ������������������ƶ������϶���ʵ����ģ��ͼ������ܡ�
��������Ҳ�����˽��µĹ�������
**Limitations and future work.**RealBlur���ݼ��ɾ�̬������ɣ�û���ƶ�������Ȼ֤������RealBlurѵ������������Զ��Դ�����̬���������Ƕ�̬�������ݼ����ڶ�̬����ȥģ���Ķ�������������Ҫ������ʹ�����⾵������ռ���ʵ�����е�ģ��ͼ�����д����û�ʹ�������ֻ��������ˣ��ռ�����Ͷ���������ݼ�����һ����Ȥ��δ��������δ���Ĺ�������Ϊ����������ʵ������ģ��ͼ���ȥģ�������ṩ�������������ںϳ�ģ��ͼ��ĸ���ʵ������ģ��Ҳ������Ȥ����ģ�Ϳ�����ѧϰͼ��ȥģ��������RealBlur���ݼ��������������