这是一个新系列
差不多是一年以前,我定导后没多久,接手了读研后的第一个课题。合作方是医院,和我对接的是一名博一的医学生,最开始两边的老师很排斥常规的单细胞文章思路,即各大类细胞分群、注释、描述,所以起初的几个月都在摸索一条主线,再后来有主线了,要加实验验证,周期有点长。我这边的分析基本做完。读研生活还在继续,我也不能太在意这一个课题,尽管有些时候我也很着急,尽管我在这个课题上花了很多时间。整理分析流程是个好习惯,最大的受益者还是自己,所以接下来我打算把我在处理单细胞转录组过程中,学到的用到的所有技能以这样的形式写出来,估计有二三十篇吧~
我想先从Cell Hashing这样一种改良的单细胞测序技术开始
1. CITE-seq

事实上Cell Hashing是在CITE-seq的基础上改进的,CITE-seq全称cellular indexing of transcriptomes and epitopes by sequencing,是一种同时对细胞内RNA和细胞表面蛋白进行测序的技术。
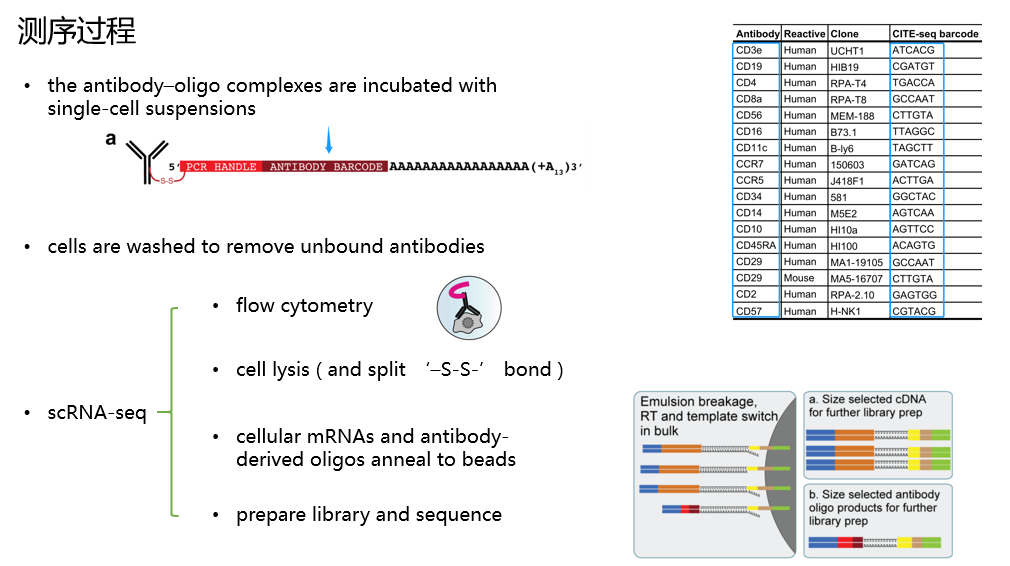
测序原理如上图,将特定的抗体连上一段序列,序列上包含与抗体信息对应的antibody barcode,像右上方表格一样,还包含一段ploy-A。该抗体复合物和细胞共培养后,细胞表面就会连上一些抗体,某种蛋白分子越多,连上的抗体就会越多。过流式之后,裂解细胞,断开二硫键,此时细胞内的RNA和抗体复合物来源的序列都会连到磁珠上,像右下图那样,这两种类型的序列长度不同,可以分开建库,调整核酸浓度,以确保两者都有合适的测序深度。

所以这样一种技术,除了提供转录组的信息,还提供了部分蛋白的信息。正如作者所说,多模态数据应用得越来越多。
支持cite-seq的R包去年看的时候,我知道有Seurat和CiteFuse,CiteFuse今年发表在Bioinformatics。
2. Cell Hashing
Cell Hashing和CITE-seq的测序原理基本一样,只是换了一个应用场景。它解决的问题是:如何将不同样本的细胞混起来测序(便宜),测完了还能区分哪个细胞来源于哪个样本,这样做也减少了批次效应。

标题里面提到了doublet检测仅针对来源于两个样本的doublet,不是指不同cell type的doublet。

背景中提到了另一种解决这类问题的方案就是提供样本的遗传多态性信息(单细胞数据比对后也能得到部分信息,和已知的样本信息比较,就能知道细胞来源于哪个样本了),当然这个信息不那么容易获取。
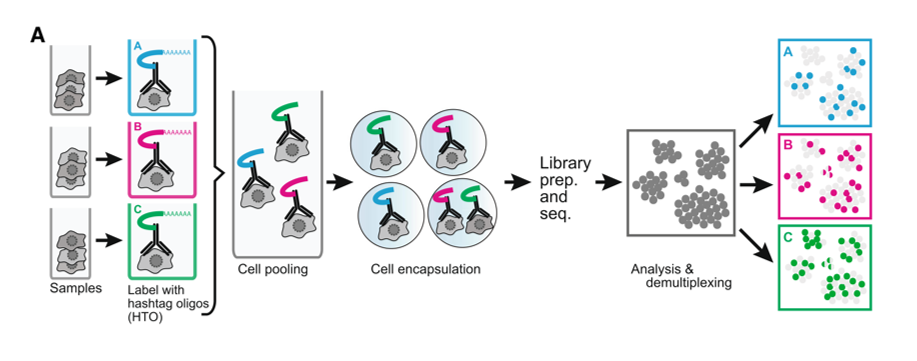
如图,不同的样本有不同的antibody barcode。

实验过程如上图,在选择抗体时,尽量选择普适的抗体,比如CD45,免疫细胞都表达。是用一种还是多种无所谓(原文用了4种,CD45, CD98, CD44, and CD11a),只要保证antibody barcode与样本对应即可。
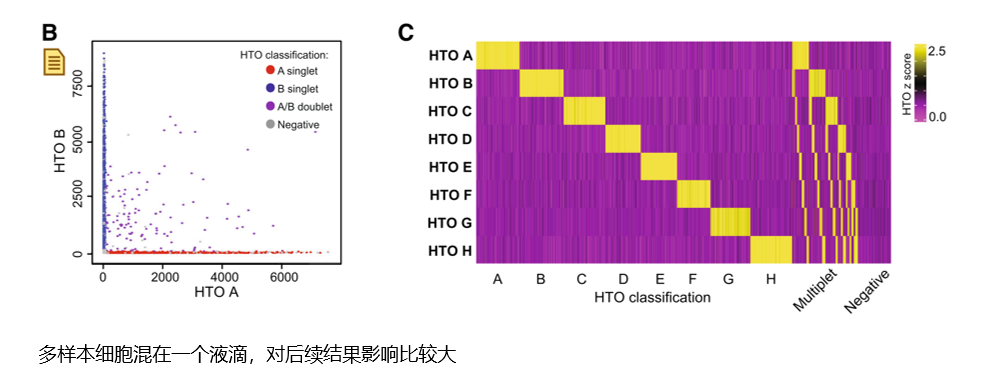
原文提供了针对cell hashing数据的拆分方法,这是对应的两个图。B图中的一个点和C图中的一列表示一个液滴(或者理解为一个cellular barcode)。正常情况下,一个液滴里面只有一个细胞,那么对应的样本tag (HTO) 只有一个,也就是只有一个tag有UMI,其他tag的UMI应该为0,不然就是doublet或者空的液滴(negative)。
3. Cell Hashing测序的拆分原理

通常我们在完成测序数据比对后,能得到一个表达矩阵,行为gene列为细胞,而cell hashing的数据,比对后得到的是行为gene+tag,列为细胞。上图给出的tag x cell的一个例子,我们利用的是这个矩阵来判定每个细胞属于哪个样本。
- 第一步是对UMI矩阵标准化,式子里的i表示第几行,n表示样本(tag)的总数;
- 第二步是粗分类,最后一类要么是8个UMI都和高,要么都很小;

- 第三步,假设第9类细胞的tag x cell矩阵每一行都服从负二项分布,根据观测值拟合之后,求0.99分位数,据此来判断某一个值是positive还是negative;
- 第四步,一列一列看,如果只有一个positive,说明是有效的CB,根据较大的HTO归到对应的样本里去;两个或多个positive则是doublet;没有positive则是空液滴。
预告
- 下篇写如何从测序数据得到表达矩阵,普通10X以及cell hashing数据都适用
- 下下篇写cell hashing数据拆分实战,用seurat和citefuse两种方法
因水平有限,有错误的地方,欢迎批评指正!