文章目录
- 网络搭建
-
- C1层
- S2层
- C3层
- S4层
- C5层
- C6层
- C7层
- S8层
- F9层
- F10层、F11层
- LRN层
- dropout层
- 加入激活函数
- 损失函数与优化器
上一篇文章把AlexNet里的大部分都弄完了,没看的可以去看一下 CNN基础论文复现----AlexNet(一) 今天就开始搭建网络模型。
网络搭建
接着上一次的开始。
论文第6页,第五章一开始就说了一大堆的参数,先大概过一遍,后面用的时候回来再看,直接开始搭网络。
还是用之前的定义,卷积层为C 池化为S 全连接为F。
继续使用优化之后的单GPU训练网络图。
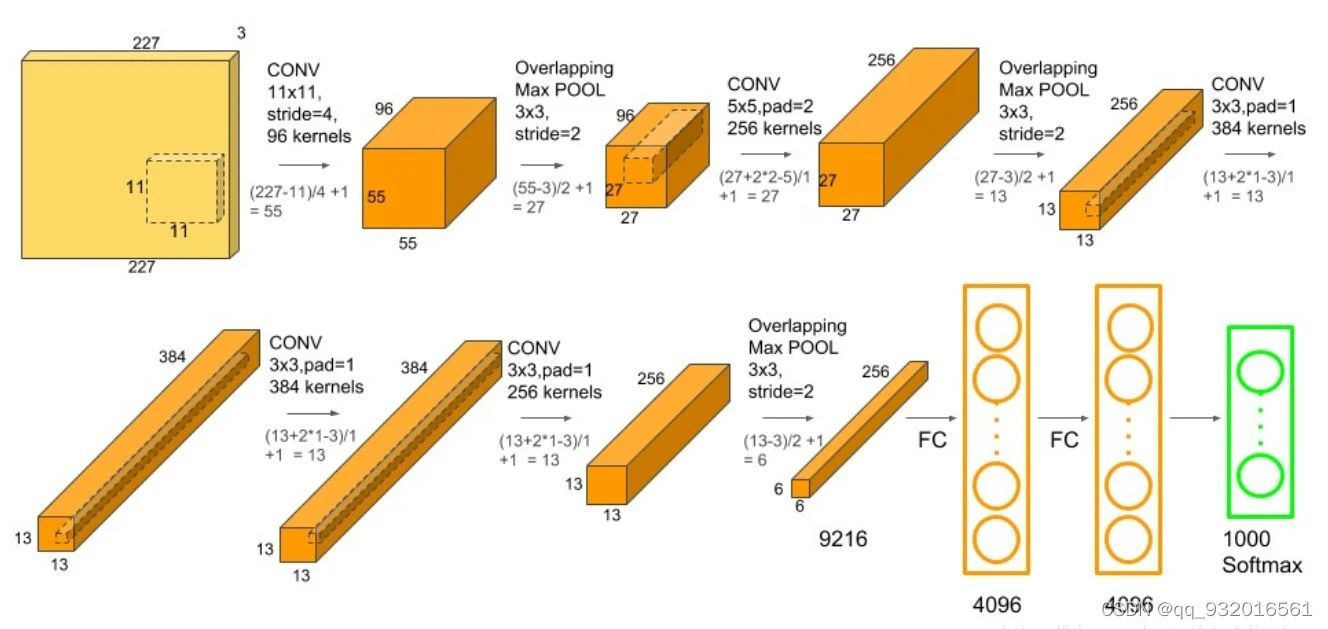
C1层
论文在第四页,3.5节中提到 stride使用步长为4,然后计算一下padding应该是2,计算方法我在LeNet中详细的说过了,这里就不再说了。
看看图,C1层的参数就全都有了。
- in_channels=3
- out_channels=96
- kernel_size=11
- stride=4
- padding=2
C1层的代码也就出来了.
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4,padding=2),
S2层
这是第二层结构,就是池化层。
关于池化层作者在论文3.4中已经设置了大小和步长的情况了。
且在3.5中也说了,使用的是最大池化层。
参数就很明显了。
- kernel_size=3
- stride=2
S2层的代码就有了
nn.MaxPool2d(kernel_size=3,stride=2),
C3层
这一层开始论文就开始将模型分开放到多路GPU上了,而我们复现开始的时候就用的单个GPU所以直接看我上面放的那个彩色的图就行。
照葫芦画瓢和C1一样
- in_channels=96
- out_channels=256
- kernel_size=5
- stride=1
- padding=2
C3层代码
nn.Conv2d(in_channels=96, out_channels=128, kernel_size=5, stride=1,padding=2),S4层
又是一个池化层, 跟S2层一样 继续。。。
- kernel_size=3
- stride=2
nn.MaxPool2d(kernel_size=3,stride=2),
C5层
一个普通的卷积层 参数:
- in_channels=256
- out_channels=384
- kernel_size=3
- stride=1
- padding=1
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1,padding=1),
C6层
一个普通的卷积 参数:
- in_channels=384
- out_channels=384
- kernel_size=3
- stride=1
- padding=1
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1,padding=1),
C7层
一个普通的卷积 参数:
- in_channels=384
- out_channels=256
- kernel_size=3
- stride=1
- padding=1
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1,padding=1),
S8层
一个池化层 参数:
- kernel_size=3
- stride=2
nn.MaxPool2d(kernel_size=3,stride=2),F9层
这是一个全连接层,全连接层要展开成一维进行操作,各参数可以看上面的那个图。
参数:
- in_features=6 * 6 * 256,
- out_features=4096
nn.Linear(in_features=6*6*256, out_features=4096),
F10层、F11层
又是两层全连接, 很简单 参数变化 4096-4096-1000
这两层的代码
nn.Linear(in_features=4096, out_features=4096),
nn.Linear(in_features=4096, out_features=1000),
LRN层
在第3.5节中作者说到,有一个响应归一化层(LRN)接 在1,2层卷积层的后面。
LRN直接使用Pytorch自带的API就行,关于里面的参数,论文中也在3.3节中给出了。
参数:
- size=96
- alpha=0.0001
- beta=0.75
- k=2
nn.LocalResponseNorm(size=96,alpha=0.0001,beta=0.75,k=2),
dropout层
这个层是作用于全连接层的。
文中提到dropout 有0.5的概率输出为0。
也就是说在全连接层的隐层中,每个特征将有一半的概率被扔掉。
像下面这样,但是别忘了放全连接层后面。
nn.Dropout2d(p=0.5),
加入激活函数
激活函数肯定是Relu了。文中3.5节也提到了,Relu函数将作用于每个卷积层和全连接层的输出上。
考虑到文章中说到的 LRN层。
所以 第一层和第二层的 顺序就是 下面四步:
卷积-> Relu -> LRN -> 池化
组合起来 一二两层卷积的代码就是:
# 第一层 卷积-> Relu -> LRN -> 池化
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4,padding=2),
nn.ReLU(True),
nn.LocalResponseNorm(size=96,alpha=0.0001,beta=0.75,k=2),
nn.MaxPool2d(kernel_size=3,stride=2),#第二层 卷积-> Relu -> LRN -> 池化
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1,padding=2),
nn.ReLU(True),
nn.LocalResponseNorm(size=256,alpha=0.0001,beta=0.75,k=2),
nn.MaxPool2d(kernel_size=3,stride=2),
然后文章中又说 3,4,5卷积层之间依次链接,但其中没有归一化和池化层,但第5层卷积层之后有一个池化层, 这里别忘了 Relu可是在每一个卷积和全连接之后的。。
所以3,4,5层卷积层 就是 卷积 -> Relu
# 卷积 -> Relu
# 第三层卷积
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1,padding=1),
nn.ReLU(True),
# 第四层卷积
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1,padding=1),
nn.ReLU(True),
# 第五层卷积
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1,padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=3,stride=2),别忘了全连接层后面也是需要加Relu的,结合上面的dropout层。
在进入全连接层之前别忘了将输入变为一维数据。
所以全连接层的整体代码就有了:
nn.Flatten(),
nn.Linear(in_features=6*6*256, out_features=4096),
nn.ReLU(True),
nn.Dropout2d(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(True),
nn.Dropout2d(p=0.5),
nn.Linear(in_features=4096, out_features=1000),
损失函数与优化器
论文中第五章也提到使用随机梯度下降,然后各种参数学习率,衰减率,动量什么的也都说了。
所以损失函数用交叉熵~~ 优化器 用SGD 。
这俩的代码:
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = optim.SGD(model.parameters(),lr=0.01,weight_decay=0.0005,momentum=0.9)
到这整个网络就已经OK了,但是遗留了一个问题,我刚才在看论文后续的时候,看到还有一个均值和标准差的加入,我在上面复现的时候并没有考虑这个问题,可能还得改一改? 。。不行了,今天属实累了,等明天醒了我再看看这地方(我估计以我的实力可能会跳过哈哈~~~)。