����Ŀ¼
- ǰ��
- ��1-2ҳ
-
- ժҪ������
- �в�ģ��
- ��2-3ҳ
-
- ��������
- ��3-4ҳ
-
- ��Ȳв�����
- ��4-8ҳ
-
- һЩʵ��Ľ��
- BasicBlock�� �� BottleNeck��
- �ܽ���˼��
-
- �������Ϊʲô������˻�����
- ResNetΪʲô���Խ�������˻����⣿
- ResNet Ϊʲô���Է�ֹ�ݶ���ʧ��
-
- �����
ǰ��
ResNet�������ص�ַ:https://arxiv.org/pdf/1512.03385.pdf
������Ŀ��Deep Residual Learning for Image Recognition
ResNet ���������Ӿ�����İ���졣
CV���� ����˵������������������μ�����ը����һ����AlexNet���ڶ��ξ���ResNet�ˡ�
���ִ��������� Github��Ҳ����һ��:https://github.com/shitbro6/paper
��1-2ҳ
ժҪ������
�ȼ�����һ�����Ļ�õĽ��
ResNet���� 2016�� CVPR������ģ�2015��ImageNet������coco�����еļ�⡢�ָ��λ����������Ĺھ���
֮ǰѧϰ��VGG�Ѿ��Ǻ�������19�㡣������ߵ�ʵ��ʹ������8��������磬152����ȣ������нϵ͵ĸ��Ӷȣ��������ģ�ͻ����ILSVRC 2015����ھ�����
���Ƕ�֪���������������������Խ��Խ�ã�����Խ���ȡ��ͼƬ����Խ��Խ�ḻ������֮������ܶ������(��Ȼ�Ѿ�����ͨ��BN�ȴֽ��)���������ϻ���������ը���ݶ���ʧ �ݶȱ�ը�ȣ�����������һ������¾ʹﵽ�˾ֲ����Ž⡣
���������ߵ�ʵ���з�����������и������ص�����C�˻���������˻�����Ȳ������ݶ���ʧ��ը����ģ�Ҳ�����ɹ���������(����� ��ѵ�������ͣ����Լ�����)�������˻�������ѵ�����Ͳ��Լ��ϵ����dz��ߣ�
Ϊ�˽��������⣬����˲в������ѧϰ��ܡ�
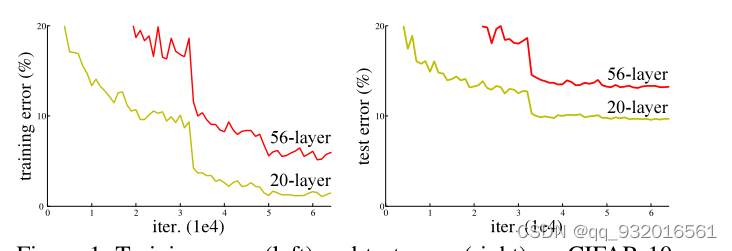
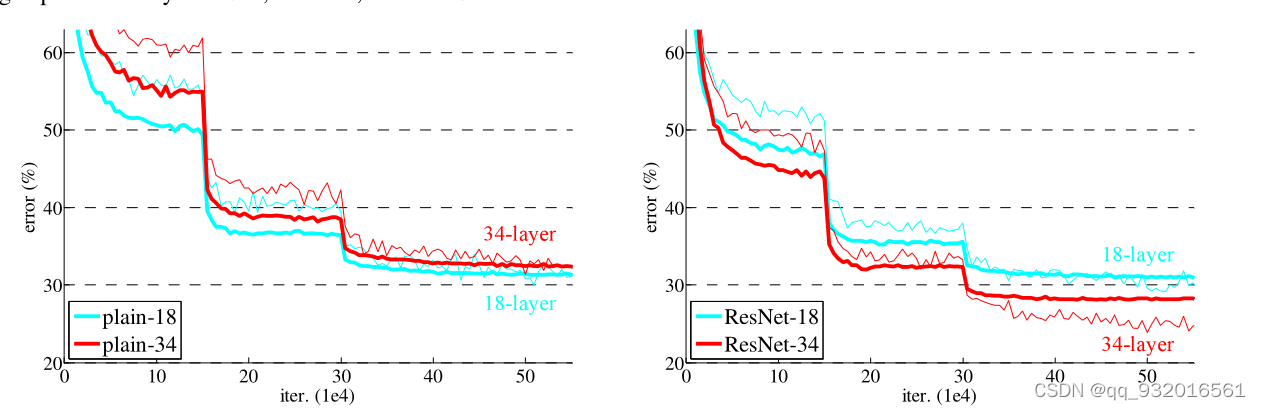
���Բ��ָ���һ��ͼ����ɫ�DZ�ɸ߲�֮���Կ���ѵ���Ͳ��Լ������ʱ��56��֮�����������ߡ�
�в�ģ��
���������һ���в�ģ�飨Residual Block�в�飩���ڽ�������˻����⡣
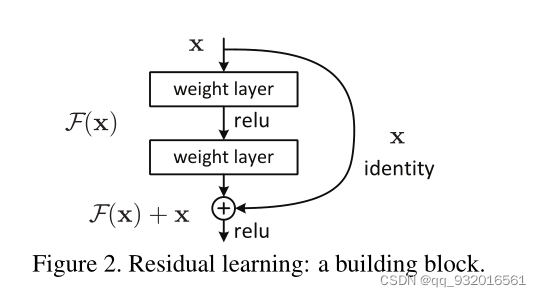
���Կ���x����֮��������·�����ߣ��ұ�һ��·�����м�һ��· ����ߵ�· identity ��Ϊ���ӳ�䣨shortcut connection & skip connection �������ӳ�� ���������IJ������ͼ����������Դ�ʱ�ܵ����ӳ��Ϊ F(x)+xF(x) + xF(x)+x.
�����յõ���ӳ��Ϊ H(s)H(s)H(s) ,�� F(x)=H(x)?xF(x) = H(x) - xF(x)=H(x)?x,��ѧϰ���� Ӧ�е�ӳ����ԭʼ����֮��IJ�ֵ����˱���Ϊ�в�ӳ�䣨residual mapping����
Ҳ��������Ϊ �м��������������·�������ԭʼ�����ƫ�Ҳ����˵��ԭ������������Ҫ������յ�ӳ�� H(x)H(x)H(x)��������ʹ���˲в�ģ��� ��Ҫ��ϵ��� F(x)F(x)F(x),����ӳ����� F(x)+xF(x) + xF(x)+x��
����5����ӳ��Ϊ5.1������в���� 5+0.1����ʱ������5.2������û�вв�ṹ�Ľ����Ӱ���Ϊ0.1/5.1 = 2%�������ڲв�ṹ����� 5+0.2 �� ��0.1�����0.2 Ӱ��Ϊ100%����ô�����ֵ�仯����������ķ����������в�ṹ���Ա���Ŀ�Ϊ��ַŴ�����
�в�ӳ�� H(x)=F(x)+xH(x) = F(x) + xH(x)=F(x)+x,������ʱ��ͱ���� H��(x)=F��(x)+1H^{'}(x) = F{'}(x) + 1H��(x)=F��(x)+1,����ļ�һҲ���Ա�֤�ݶ���ʧ������
��������˵��һ������в�ṹ���е㣺
- �����Ż�������
- ����˻�����
- ����ʹ�����������ȷ�ʴ�����������㸴�Ӷ��Ժܵ͡�
����Ҳ֤�����˻��������κ����ݼ��϶��ձ���ڡ���imagenet���õ��ھ�֮��Ǩ��ѧϰ�õ���cocoͬ���õ��˺ü��������Ĺھ���˵���в�ṹ�����ʵġ�
����ֺ�VGG����һ�£���VGG����8�������㸴����ȴ����VGGС ���������̲�VGG��
��2-3ҳ
��������
����������Ҫ˵��һ�����еIJв��ʾ�������
�ڵͼ��Ӿ������ز��棩�ͼ����ͼ��ѧ��2-3Dͼ����ʾ�ڼ�����е��о����У�Ϊ�����ƫ�ַ��̣�PDE�����㷺��ʹ�ö�����������ֽ�����������⣬ÿ�������ⶼ��Ҫ���һ�������Ⱥ�ϸ���ȵ�һ���в����������滻����ʱʹ�ü������������÷���Ҳ��ʹ�òв������⡣�����й�����û�����ֲв���������ʵ������ڻ���ѧϰ��������
shortcut connections��֮ǰ���б��ἰ���о�������ѵ������֪��ʱ����һ�����Բ��������������㡢GoogleNet�еĸ������������ڽ���ݶ���ʧ�����С�inception��Ҳ�ǰ�����shortcut���ӵġ�
��3-4ҳ
��Ȳв�����
������ǽ���ǰ��˵���Ǹ� ��ֱ����Ϻ���H(x)H(x)H(x)��Ϊ��� �в�F(x)F(x)F(x)��
��������ϴ�ͳ���������ϲ���˺��ӳ��֮���������Ͳ����dz��IJ�(�������˻�����)��������ӳ���Ѿ����ţ���в�ģ��ֻ�����ӳ�䣬���Ժ��������ֻ���ǰ���������������������IJв�(����Ŷ�)���ɡ�
������һ�� ���ܽ��ƶ���(Universal Approximation Theorem)��
�˹���������һ�������Ķ���������˵�����һ��ǰ�������������������������һ�����ز㣬ֻҪ���������㹻��������Ԫ���Ϳ�������κ�һ������������ʱ��֤������Ȼ�� �˹�����=��ѧ��
3.2�ھ�����ѧ��������в���̣����˸���ʽ:
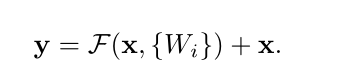
��ʵ�ͻ���ǰ��˵����Щ��x���Ǻ��ӳ��ģ�ǰ��F��һ�Ѿ��Dzв
��������� �� ����һ��ȦȦ��һ�� ����ʾ�������
���������F(x) + x����ʹ��shortcut������Ԫ�ض�Ӧ���( element-wise addition) ��֮����ӵĽ���ٽ���һ�μ��relu������ʵ���������ֻ�������Ǹ��в�ṹͼ��
��ӵ�ʱ�� �в�F(X)����������xά�ȱ���һ�²���ʵ�֡�
������3.3���жԱ��˴��в������Ͳ����в�����磬Ҳ�ǶԱȵķ���̲�VGG������34�����磬�����е�4ҳ��ͷҲ����һ����ͼ���Դ���˵�����ҵIJв��ǿ��
�����ڲв���·�ṹ�У�shortcut�������֣�һ����ʵ��ֱ�ӽ����봫���������������ʹ�����²������²������ò���Ϊ2�ľ��������ﵱ�в�ά�Ȳ�ͬʱ����padding����1 * 1 ��������ά��
3.4��˵��һ��ѵ��ϸ�ڣ����еij���������Ԥ���� ������ǿ�ȶ���Alex����VGGһ��,ֻ��һЩϸС�ĸĶ�����������ijߴ�����[256,480]�ķ�Χֵ�ˣ�û��ȫ���Ӳ�������û��dropout�ȡ�
batch normalization (BN) �� �������� �ӿ������ٶȣ������ݶ���ʧ������ BNԭ����ϸ��
��4-8ҳ
һЩʵ��Ľ��
��������Ҫ����ʹ���˸��ֶԱȷ������ڸ���ģ�ͺ����ݼ��Ͻ��жԱ�ʵ�顣
��һ��� and һ���ʵ��ͼʵ���Ͼͻ�����˵֮ǰ���Ǹ����⣬��ͨ�����������ͳ������˻����������˻����������ݶ���ʧ ����ը����������ġ�ʹ���˲в�ṹ��������Խ����һ�˻������Ҳв����������ܿ죬���ھͺܿ졣
��Ȼ�вв�ģ�飬������Ҳ����һζ�ļ��1202��û��101���Ч���ã���Ϊ����ڳ����ģ�ͣ�ʹ�õ����ݼ�̫С�ˣ�������ˡ�
�������ݼ���ģ�Ƿ�ֹ����ϵĸ�����
������ͼ��ʾ�˺ܶͬ��ȵ�ResNet���磺
�� 18��34��50��101��152��IJ�ͬ��ȡ���һ���������ȫ���ӷ������һ���ģ�ֻ���м�ÿһ���Dz�ͬ�ģ������� x2���Ǹ��������Σ�����ڶ���34���ģ�ͣ��м��� x3 x4 x6 x3 ����һ���� 3+4+6+3 16�飬ÿ��������2�㣬����32�㣬���Ͽ�ͷ�ľ��� ������ȫ���� һ������34�㡣
���߲�û��˵ΪʲôҪ����ȡ�������ǵ������İɣ���ѧ��
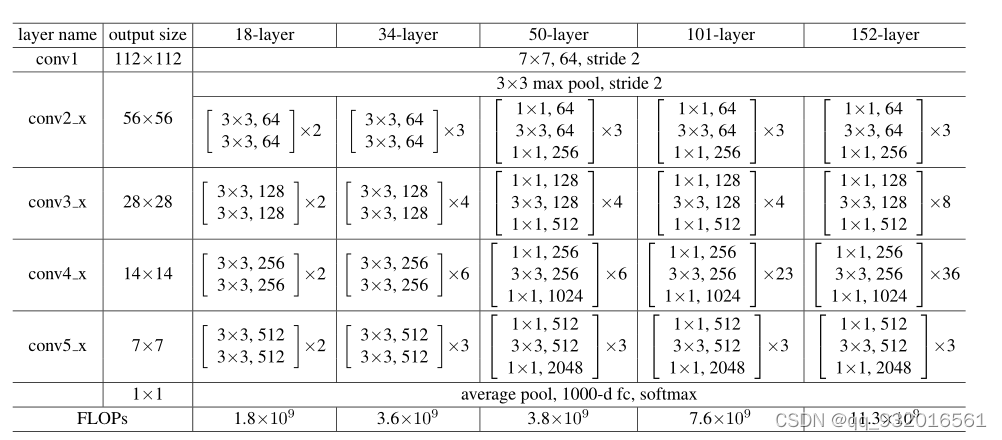
����ͼ�����һ���� FLOPs�����Ǹ������ļ��㷨���Ӷȣ���18���ʱ���Ӷ���1.8 ����34������3.6 ��������һ����������34�㵽50�� ���ӶȽ�����3.6����3.8�����ӶȲ�û���������٣�������ṹ�ı仯���� С����������ṹ���������ṹ������Ǻ�����ܵ�BasicBlock���BottleNeck�顣
������ʵ��ͼ���Ա���ͨ�������磬ʹ���˲в������Խ�������Խ�͡�
ͻȻ�½�����Ϊ�½���ѧϰ�ʣ�ѧϰ�� * 0.1��
BasicBlock�� �� BottleNeck��
���и�����һ��ͼ����Ŀ�ľ��������ResNet�������
��߾���ԭ������� 64ͨ��ʱ�������ò��������ʱ��ͨ����Ҳ���ű�࣬��������ѧ������Ķ����ˣ��ұ߾��Ǹ���֮��ģ�ͨ���������256�����㸴�Ӷ�ֱ��������
Ϊ�˽���ʱ�临�Ӷȣ��ұ�256��ȥ֮���һ���ͨ���� 1 * 1 �ľ�����ά�Ƚ���64.֮����3 * 3�ľ���������ٱ��256��ͨ����(�������Ҫһ��)��
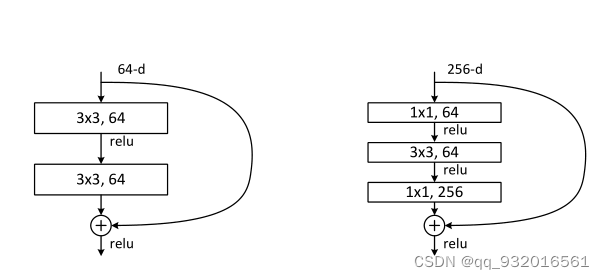
���ĸ�¼��������ϸ��˵��һ�±���ʱ��ĸ��ֵ���ϸ�ڣ����ÿ��ˣ��������ˡ�
�ܽ���˼��
�������Ϊʲô������˻�����
��������֮���ҵ�һ�������뵽��������⣬Ȼ��˼����һ�£���û��ͨΪʲô������˻�������˵�����һ��50������磬ѵ����50��ʱ��Ӧ�ñ�20��Ĵ����ʻ��߰���������Ӧ���Ǹ���ƽ��״̬����Ϊ��50���ѵ�������Ѿ���ǰ20�����ס�ˣ���ô������˻�����ģ�����Ҳ�ᵽ�˲����ǹ���Ϻ��ݶ���ʧ��ը���µ��˻�����(�Ͼ������Ѿ�����BN��������ݶ�����)���ڵ�������д����븴��֮���Ҿ��ÿ�������Ϊ����ݶ��½��������𣿻��п���������ǰ���̫��Relu�ͳػ�����Ϊ�˽����ӶȴӶ���ʧ��Խ��Խ��������Ҳ���������⣿
�����кܶ�Ľ��ͣ�������һ��˵MobileNet V2���ᵽ��������ʧ�����������Ҿ��ÿ��ף�����ʱ�俴һ��MobileNet V2��
ResNetΪʲô���Խ�������˻����⣿
ʵ���Ͼ�����Ϊ�в�ṹ��Ϊһ������IJ�ַŴ��������ԷŴ�֮ǰ�����ĵط��Ӷ����и��õķ������ơ�
���ǿ���ͨ������Ϊ���в�ṹѧϰ���Dz�ֵ��Ӧ�е�ӳ����ԭʼ����֮��IJ�ֵ����
�ٸ����ӣ�����������ͼ��
��ɫ��һ�࣬��ɫ��һ�ࡣ�����һ�ηִ�֮�ִ��IJ��ֻᱻ�Ŵ������´η������´ξͻ����ص�ȥ�����ϴηִ���������Դ����ơ�
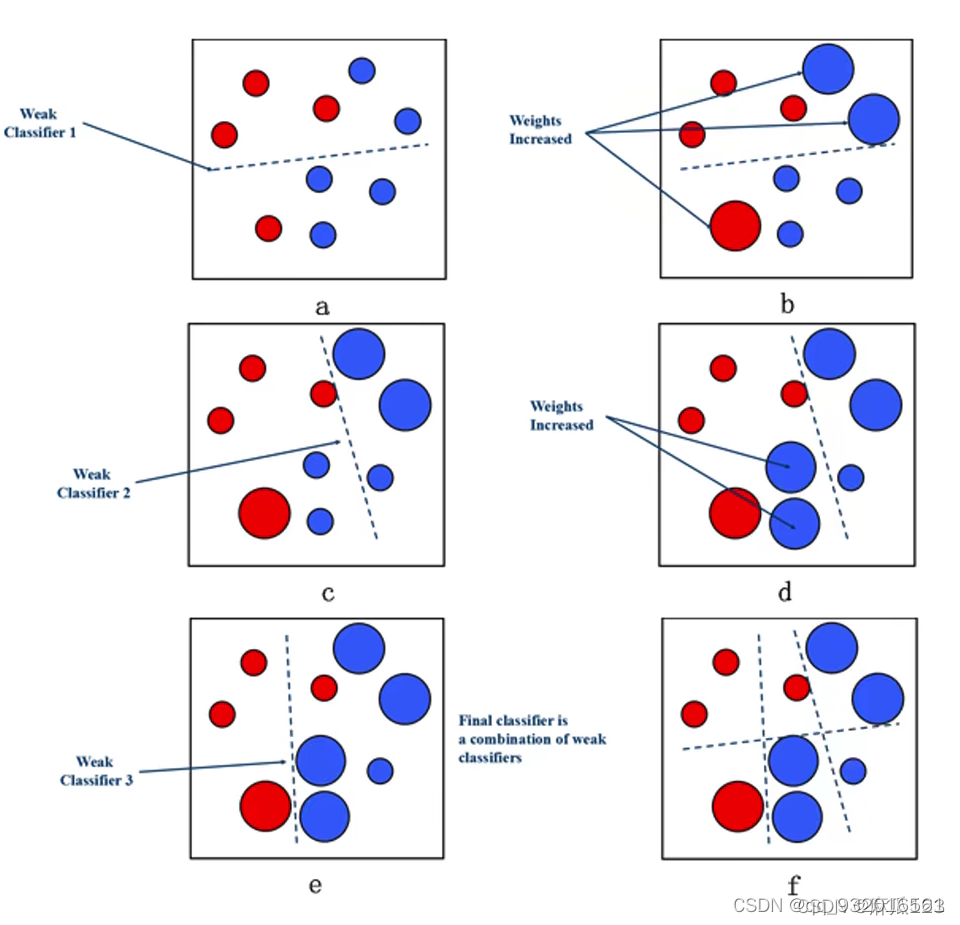
�������ģ����ʵҲ���Կ�������ѧϰ��ÿһ�鶼���������������ɵ�һ��֮��ͱ����ǿ���������Ͳв�ģ��һ����ÿһ��������������һ�����
���ϻ�����һ�������Ҿ���ͦ����˼����ϣ������������ȵ�������ģ��������Խ��ԽԶ�����������˺��ӳ�䣬��ģ�Ͳ������ġ�
ResNet Ϊʲô���Է�ֹ�ݶ���ʧ��
������ȷһ�㣬�ݶ���ʧ�������˻��������£�ԭ��Ҳ������˵�����ˡ�
��ʵ�ܷ�ֹ�ݶ���ʧ���Dzв��ĺ��ӳ��Ĺ��ͣ����ӳ����ݶ�һֱ����1(x����)��������ݶ�ע��ײ�(����ݶȻش�����)����ֹ���ݶ���ʧ��
�����
��ƪ���Ķ���֮�о���ƪ���µ����������������������ʵ��Ϊ������Ҫ���������һ���в�ṹ�����ΰ����и����Ƶ��ĵط��������ѧ��������˵�ܶ�ط�����û��֤���������ˣ����ۺ�ʵ��ֻҪ��һ�������гɹ����Ҿ��㲻���Լ����������Ҳ���Է����ġ�
������ʵ���кܶ�ط�û�ж����ܶ�ط�һ֪����(��������̫����)�����ܻ����ź���ѧϰ��������ɣ�ResNet���кܶ���֣�����ѧ�ɣ���������ȿ�һ��Densenet����transform��
���븴�ֺ���:CNN�������� ����+����---- ResNet(��)