[pytorch] KaggleͼƬ������� ArcFace + Metric Learning ����ѧϰ
- ��������
- ����֪ʶ
-
- [����] ����ѧϰ Metric Learning
- [pytorch] PyTorch Metric Learning
- [����] bounding box Ŀ����
- [python] loggingģ��
- [pytorch] �ݶ��ۼ�(Gradient Accumulation)
- ����Ԥ����
- �������
-
- ����
- ����
- ��ȡcsv����
- �������ݼ�
- ��ȡͼƬ����
- ����ģ��
- ����Loggingģ��
-
- ����hook
- ����tester
- end_of_epoch_hook
- trainer����
- ��ʼѵ��
- Inference Models Ԥ��
-
- ��֤��
- ���Լ�Ԥ��
- ���
�����е����ݰ������� 28 ����ͬ�о������� 30 ����ͬ���֣�����ͺ��ࣩ�� 15,000 ��ֻ���ظ��庣���鶯���ͼ����Ҫ���ǶԲ��Լ�����id�ķ��ࡣ
kaggle �����������鼰���ݼ����أ�Happywhale - Whale and Dolphin Identification
��������
arcface�DZ��α����б�����õķ���֮һ�����룺
- Pytorch Metric Learning [effnet + arcface])
- Pytorch Train Notebook(ArcFace + GeM Pooling)
����֪ʶ
[����] ����ѧϰ Metric Learning
����ѧϰ��Metric Learning���ǻ���ѧϰ�����о����õ���һ�ַ����������Խ���һϵ�й۲⣬�������Ӧ�Ķ����������Ӷ�ѧϰ���ݼ�ľ������죬��Ч����������֮������ƶȡ�������������������ƶȸߵĹ۲�ֵ���᷵��һ��С�ľ���ֵ�����ڲ����Ĺ۲�ֵ����᷵��һ����ľ���ֵ��������������ʱ������ѧϰ�ڴ������������ȷ�ʺ�Ч���ϣ�չ�ֳ����������ơ�
Ȼ�������Ҫ�����ķ�������ʮ�ָ��ӣ����ж����С����������ʱ��������ѧϰ�Ͷ���ѧϰ����ȶ���ѧϰ����Deep Metric Learning����� DML�������������������ߡ���ȶ���ѧϰ�ֱ���Ϊ�������ѧϰ��Distance Metric Learning��������ڶ���ѧϰ����ȶ���ѧϰ���Զ�����������������ӳ�䡣
ͨ��ѵ��һ������ CNN �ķ�����������ȡģ������������ȶ���ѧϰ���Խ���ȡ��ͼ��������Embedding��Ƕ�뵽����λ�ã�ͬʱ����ŷ�Ͼ��롢cosine �Ⱦ����������������ͬ��ͼ���������ֿ�����
��ȶ���ѧϰ�� CV �����һЩ���˷�����������ڶࡢ���������㣩�б������죬Ӧ�ñ鼰����ʶ��������ʶ��ͼ�������Ŀ����١�����ƥ��ȳ�����
�ο����ӣ�
- ����ѧϰ��pytorch-metric-learning��ʹ��
- PyTorch ��ȶ���ѧϰ�� Buff���Ŵ�ģ�顢�������
- ����ѧϰ/�Ա�ѧϰ����: �����Ķ��ʼ�-Deep Metric Learning: A Survey
[pytorch] PyTorch Metric Learning
����ѧϰ��Ϊһ�������������в��ٽ��ܵ����£�pytorch-metric-learning���������������ʵ�ֶ���ѧϰ�����Ĺٷ��ĵ�Ҳ�бȽ���ϸ��˵����demo. ������ѧϰ��pytorch-metric-learning��ʹ��
�ٷ� API �� PyTorch Metric Learning
����εĴ����У�����Ҳ�Ǵ����ĵ�����PyTorch Metric Learning���еĺ��������ں�����װ�̶ȱȽϸߣ����Խ���������ѧϰ������ʹ�ã�����������δ���Ĺؼ���
��������һ���Լ��ܽ��loggingģ���Inferenceģ���˼ά��ͼ������ѵ�����̵Ĺؼ���
[����] bounding box Ŀ����
��ͼ����������У����Ǽ���ͼ����ֻ��һ����Ҫ�����������ֻ��ע���ʶ������� Ȼ�����ܶ�ʱ��ͼ�����ж�����Ǹ���Ȥ��Ŀ�꣬���Dz�����֪�����ǵ���𣬻���õ�������ͼ���еľ���λ�á� �ڼ�����Ӿ�����ǽ����������ΪĿ���⣨object detection����Ŀ��ʶ��object recognition����
��Ŀ�����У�����ͨ��ʹ�ñ߽��bounding box������������Ŀռ�λ�á� �߽���Ǿ��εģ��ɾ������Ͻǵ��Լ����½ǵ� x �� y ��������� ��һ�ֳ��õı߽���ʾ�����DZ߽�����ĵ� (x,y) �������Լ���Ŀ��Ⱥ߶ȡ�



�ο����ӣ�
1.CNN: bounding box prediction 01 problem
2.CNN: bounding box prediction - specify bounding box
3.CNN: bounding box prediction - YOLO algo
4.CNN: 3.9 YOLO �㷨 part1
5.CNN: 3.9 YOLO �㷨 part2
[python] loggingģ��
��ô�� Python �У�������������һ���Ƚϱ�����־��¼�����أ������ܶ��˻�ʹ�� print ������һЩ������Ϣ��Ȼ�����ڿ���̨�۲죬���е�ʱ���ٽ�����ض����ļ���������浽�ļ��У�������ʵ�Ƿdz����淶�ģ��� Python ����һ������ logging ģ�飬���ǿ���ʹ���������б�ע����־��¼�����������ǿ��Ը�����ؽ�����־��¼��ͬʱ��������������ļ��������Լ�һЩ������־��Ϣ�ļ�¼����ʱ�䡢����ģ����Ϣ�ȡ�
�������������˽�һ����־��¼���̵������ܡ�


�ο����ӣ�
- ��ʱ������print�ˣ���ʼ������logging��ǿ��ɣ�
- Python֮��־������loggingģ�飩
[pytorch] �ݶ��ۼ�(Gradient Accumulation)
���Դ����ƣ�����һЩԤѵ����largeģ��ʱ��batch-size�������õıȽ�С1-4������ͻᡮCUDA out of memory������һ��batch-sizeԽ��(һ����Χ��)ģ������Խ�ȶ�Ч�����Խ�ã���ʱ�ݶ��ۼ�(Gradient Accumulation)�Ϳ��Է��������ˣ��ݶ��ۼӿ������ۼӶ��batch���ݶ��ٽ���һ�β������£��൱��������batch-size��
������PytorchΪ����һ���������ѵ������ͨ�����£�
for i, (inputs, labels) in enumerate(trainloader):optimizer.zero_grad() # �ݶ�����outputs = net(inputs) # ����loss = criterion(outputs, labels) # ������ʧloss.backward() # �����������ݶ�optimizer.step() # ���²���if (i+1) % evaluation_steps == 0:evaluate_model()
�Ӵ����п��Ժ�����ؿ������������������ѵ���ģ�
1.��ǰһ��batch����֮��������ݶ�����
2.�����������ݴ������磬�õ�Ԥ����
3.����Ԥ������label��������ʧֵ
4.������ʧ���з�������������ݶ�
5.���ü���IJ����ݶȸ����������
���������ݶ��ۼ���������ģ�
for i, (inputs, labels) in enumerate(trainloader):outputs = net(inputs) # ����loss = criterion(outputs, labels) # ������ʧ����loss = loss / accumulation_steps # ��ʧ����loss.backward() # �����������ݶ�if (i+1) % accumulation_steps == 0:optimizer.step() # ���²���optimizer.zero_grad() # �ݶ�����if (i+1) % evaluation_steps == 0:evaluate_model()
1.�����������ݴ������磬�õ�Ԥ����
2.����Ԥ������label��������ʧֵ
3.������ʧ���з�������������ݶ�
4.�ظ�1-3��������ݶȣ����ǽ��ݶ��ۼ�
5.�ݶ��ۼӴﵽ�̶�����֮���²�����Ȼ���ݶ�����
�ܽ��������ݶ��ۼӾ���ÿ����һ��batch���ݶȣ����������㣬�������ݶȵ��ۼӣ����ۼӵ�һ���Ĵ���֮���ٸ������������Ȼ���ݶ����㡣
ͨ�����ֲ����ӳٸ��µ��ֶΣ�����ʵ������ô�batch size�����Ч������ƽʱ��ʵ������У���һ�������ݶ��ۼӼ��������������£������ݶ��ۼ�ѵ����ģ��Ч����Ҫ�Ȳ���Сbatch sizeѵ����ģ��Ч��Ҫ�úܶࡣ
?
�ο��� �ݶ��ۼ�(Gradient Accumulation)
����Ԥ����
���ȣ�������������ͳ�ƵĽ����[pytorch] Kaggle����ͼ�����ݼ� ���ݷ���+���ӻ�
����ͼƬ�Ĵ�С����dz�����������Ҫ���ľ�������λ��Ҳ�����߰���
Things to know before starting image preprocessing
��������Կ���һЩ���˰���
���ԣ�ͼƬ�����ĵ�һ������ȷ������/�������ͼƬ�е�λ�ã�Ϊ�ˣ�����ʹ����bounding box[YOLOv5].
Happywhale: BoundingBox [YOLOv5]
����������У����ǽ�ʹ�� YOLOv5 ���ɱ߽����ô����Ŀ����Ϊ֮��ͼ���crop�ṩ���Ӷ��Դ�С��������ݼ�ͼƬ���вü������տ��Դﵽ���õķ�����.
����ʹ�� Whale Flute ���ݼ�(��һ��Kaggle�������ݣ�����β����λ)��ѵ���Ͳ���BoundingBoxģ�ͣ������ܹ��� 1200 �����б߽���������֮�����ǽ�ʹ�� Whale Flute ģ�Ͷ����ǵ� Whale �� Dolphin ���ݼ�����Ԥ�⡣
Whales Fluke ���ݼ��еı߽��ܴ� Whales & Dolphin ���ݼ�����С�߽��Ҳ�д�߽�� Ҫ���������⣬�����Գ��Ը��� hyp.yaml �ļ��е� scale ������ Ĭ��ֵΪ 0.5�������Գ������Ӹ�ֵ����Ҳ���Գ��Խ� bbox �Ŵ����� 1.5x �� 1.7x�� �⽫ȷ��������ü���������ࡣ
��ȷ���ñ߽���λ��֮�����Ǽ�����ͼ����м������õ����Ƿ�������Ҫ��ͼ��
Happywhale: Cropped Dataset [YOLOv5]

���գ��ڵ�����С֮�����ǵõ��µ��������ݼ�ͼ��
������Ŀǰ�İ汾������û����bounding box������������ݼ�����ѯ�������ߣ����Ļظ���Ŀǰû�ж�bounding box�����������������ʵ���ϣ���bounding box������������ݼ��У�Ҳ������������ͼƬ������˵�����������ϵ�����ȣ������ԣ�Ŀǰ����ֻʹ���˴�С�任������ݼ���
���ݼ���JPEG Happywhale 384x384
���Ǻ������ʣ�bounding box��һ�ֲ��������ݴ�������������Ҳǿ����������ʱ���˻��Լ�ѵ��bounding box�����ݼ���iԤ�������ݡ�
�������
����
!pip install timm
!pip install pytorch-metric-learning[with-hooks]
��Դ�Ķ���ѧϰ��pytorch-metric-learning�������˵�ǰ���õĸ��ֶ���ѧϰ��������һ���dz����õĹ��ߡ�
import os
import glob
import pandas as pd
import numpy as np
import logging
import timm
from tqdm.notebook import tqdm #������import torch
import torch.nn as nn
import torch.optim as optimfrom torch.utils.data import Dataset, DataLoader
from torchvision.io import ImageReadMode, read_image
from torchvision.transforms import Compose, Lambda, Normalize, AutoAugment, AutoAugmentPolicyimport pytorch_metric_learning
import pytorch_metric_learning.utils.logging_presets as LP
from pytorch_metric_learning.utils import common_functions
from pytorch_metric_learning import losses, miners, samplers, testers, trainers
from pytorch_metric_learning.utils.accuracy_calculator import AccuracyCalculator
from pytorch_metric_learning.utils.inference import InferenceModelfor handler in logging.root.handlers[:]:logging.root.removeHandler(handler) # remove exactly the preexisting handler objectlogging.getLogger().setLevel(logging.INFO) # ��ȡloggerʵ�� ָ����־������������
logging.info("VERSION %s" % pytorch_metric_learning.__version__) # ��ӡ��汾
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device) # cuda:0
print(torch.cuda.get_device_name(0)) # NVIDIA RTX A6000
����
MODEL_NAME='tf_efficientnet_b4_ns'
N_CLASSES=15587 #������
OUTPUT_SIZE = 1792
EMBEDDING_SIZE = 512
N_EPOCH=15
BATCH_SIZE=16
ACCUMULATION_STEPS = int(256 / BATCH_SIZE)
MODEL_LR = 1e-3
PCT_START=0.3
PATIENCE=5
N_WORKER=2
N_NEIGHBOURS = 750
��ȡcsv����
df = pd.read_csv('./happy-whale-and-dolphin/train.csv')
df.head()

df['label'] = df.groupby('individual_id').ngroup()
df['label'].describe()

ʵ���˸������ֵ���ǩ���ֵ�ת��

-
df.groupby
groupby�Ĺ��̾��ǽ�ԭ�е�DataFrame����groupby���ֶΣ�������individual_id��������Ϊ���ɸ�����DataFrame������Ϊ���ٸ�����ж��ٸ�����DataFrame��Pandas�̳� | �����õ�Groupby�÷���� -
GroupBy.ngroup(self, ascending:bool = True) return=ÿ�����Ψһ��š�

-
�����ܽ�df.describe()
�᷵��һ���ж���е����������е�ͳ�Ʊ���ÿ������һ��ͳ��ָ�꣬��������ƽ��������������Сֵ���ķ�λ���ȣ������dz����˽����ݻ��Ǻ������á� �����һ��ʱ��������ᰴʱ����ص��翪ʼ����ʱ�䡢���ڵ���Ϣ��
�������ݼ�
ѵ��������֤��
valid_proportion = 0.05valid_df = df.sample(frac=valid_proportion, replace=False, random_state=1).copy()
train_df = df[~df['image'].isin(valid_df['image'])].copy()print(train_df.shape) # (48481, 4)
print(valid_df.shape) # (2552, 4)
Reset index on both since we want to use it for KNN lookups later:
train_df.reset_index(drop=True, inplace=True)
valid_df.reset_index(drop=True, inplace=True)
��ȡͼƬ����
�������ڼ���ͼ���dataset�ࡣ
class HappyWhaleDataset(Dataset):def __init__(self,df: pd.DataFrame,image_dir: str,return_labels=True,):self.df = dfself.images = self.df["image"]self.image_dir = image_dirself.image_transform = Compose([AutoAugment(AutoAugmentPolicy.IMAGENET),Lambda(lambda x: x / 255),])self.return_labels = return_labelsdef __len__(self):return len(self.images)def __getitem__(self, idx):image_path = os.path.join(self.image_dir, self.images.iloc[idx])image = read_image(path=image_path)image = self.image_transform(image)if self.return_labels:label = self.df['label'].iloc[idx] # iloc������ͨ���к���ȡ������return image, labelelse:return image
train_dataset = HappyWhaleDataset(df=train_df, image_dir=TRAIN_DIR, return_labels=True)
len(train_dataset)#48481
valid_dataset = HappyWhaleDataset(df=valid_df, image_dir=TRAIN_DIR, return_labels=True)
len(valid_dataset)#2552
dataset_dict = {
"train": train_dataset, "val": valid_dataset}
��һ��ѵ����

����ģ��
���ȣ�����PyTorch Metric Learning���еķ�����Ҫʵ�ֶ���ѧϰ�����ֽṹ��һ����Trunk+Embedder�����������Trunk����Ϊresnet�Ⱦ�������ɾ�����ķ���㣬Embedder���Խ�������������ij�Embedder��������Ҳ����˵ģ��ֻ�ǽ�����ͶӰ��Embeding�ռ䣬��������Ԥ��ʱ��Ҫ���ݲ��Լ���ͶӰ�ռ��е�ľ���������Ԥ�⡣�ڶ��ֽṹ�ǣ�Trunk+Embedder+Classifier���Դ��������Ľṹ�ȽϷ�������ƽʱѵ����ϰ�ߣ��ٷ�api����Ӧ�����Ӵ��롣
����������У�����ʹ�õ�һ�ֽṹ��
����������Ҫ������Trunk��Embedder�Ľṹ����Ӧ�ģ�Ҳ��Ҫ�ֱ��������ǵ�optimizer��ѧϰ��˥��schedule��
# Setup the trunk using a pre-trained model from timm:
trunk = timm.create_model(MODEL_NAME, pretrained=True)
trunk.classifier = common_functions.Identity() # ɾ�������
trunk = trunk.to(device)
trunk_optimizer = optim.SGD(trunk.parameters(), lr=MODEL_LR, momentum=0.9)
trunk_schedule = optim.lr_scheduler.OneCycleLR(trunk_optimizer,max_lr=MODEL_LR,total_steps = N_EPOCH * int(len(train_dataset)/BATCH_SIZE),pct_start = PCT_START
)
#Add our embedder. This is just a linear layer that will create the embeddings for KNN:
embedder = nn.Linear(OUTPUT_SIZE, EMBEDDING_SIZE).to(device)
embedder_optimizer = optim.SGD(trunk.parameters(), lr=MODEL_LR, momentum=0.9)
embedder_schedule = optim.lr_scheduler.OneCycleLR(embedder_optimizer,max_lr=MODEL_LR,total_steps = N_EPOCH * int(len(train_dataset)/BATCH_SIZE),pct_start = PCT_START
)
Ϊ��ʵ�����ǵ� ArcFace ������������Ҫ����loss.
loss_func = losses.ArcFaceLoss(num_classes=N_CLASSES, embedding_size=EMBEDDING_SIZE).to(device)
loss_optimizer = optim.SGD(trunk.parameters(), lr=MODEL_LR, momentum=0.9)
loss_schedule = optim.lr_scheduler.OneCycleLR(loss_optimizer,max_lr=MODEL_LR,total_steps = N_EPOCH * int(len(train_dataset)/BATCH_SIZE),pct_start = PCT_START
)
����Loggingģ��
��һ��Ĵ������ʹ����PyTorch Metric Learning���еĺ����������ȿ��������۲��ֵ�˼ά��ͼ��Ӧ�Ŵ������⡣ʹ��Loggingģ��ȡ���˴�ͳ��ѵ�����̡�
Setup some hooks for validation, logging and model saving at the end of the epoch:
����hook
record_keeper, _, _ = LP.get_record_keeper(LOG_DIR)
hooks = LP.get_hook_container(record_keeper, primary_metric='mean_average_precision')
����tester
tester = testers.GlobalEmbeddingSpaceTester(end_of_testing_hook=hooks.end_of_testing_hook,accuracy_calculator=AccuracyCalculator(include=['mean_average_precision'],device=torch.device("cpu"),k=5),dataloader_num_workers=N_WORKER,batch_size=BATCH_SIZE
)
end_of_epoch_hook
end_of_epoch_hook = hooks.end_of_epoch_hook(tester, dataset_dict,MODEL_DIR,test_interval=1, patience=PATIENCE, splits_to_eval = [('val', ['train'])]
)
trainer����
class HappyTrainer(trainers.MetricLossOnly):def __init__(self, *args, accumulation_steps=10, **kwargs):super().__init__(*args, **kwargs)self.accumulation_steps = accumulation_stepsdef forward_and_backward(self):self.zero_losses()self.update_loss_weights()self.calculate_loss(self.get_batch())self.loss_tracker.update(self.loss_weights)self.backward()self.clip_gradients()if ((self.iteration + 1) % self.accumulation_steps == 0) or ((self.iteration + 1) == np.ceil(len(self.dataset) / self.batch_size)):self.step_optimizers()self.zero_grad()def calculate_loss(self, curr_batch):data, labels = curr_batchwith torch.cuda.amp.autocast(): #�Զ���Ͼ��Ȱ�embeddings = self.compute_embeddings(data)indices_tuple = self.maybe_mine_embeddings(embeddings, labels)self.losses["metric_loss"] = self.maybe_get_metric_loss(embeddings, labels, indices_tuple)
��������̳�MetricLossOnly�Լ�д�˸���������gradient accumulation.
��ʼѵ��
trainer.train(num_epochs=N_EPOCH)
ѵ������
INFO:PML:Evaluating epoch 1
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [05:59<00:00, 16.88it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.59it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.07240102325083039
INFO:PML:TRAINING EPOCH 2
total_loss=40.83454: 100%|��������������������| 6060/6060 [20:27<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 2
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [05:58<00:00, 16.92it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.67it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.13497803492981894
INFO:PML:TRAINING EPOCH 3
total_loss=40.78382: 100%|��������������������| 6060/6060 [20:26<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 3
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [06:00<00:00, 16.80it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.50it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.17711614700525016
INFO:PML:TRAINING EPOCH 4
total_loss=44.27713: 100%|��������������������| 6060/6060 [20:26<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 4
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [05:59<00:00, 16.84it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.50it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.19266580949319617
INFO:PML:TRAINING EPOCH 5
total_loss=36.24231: 100%|��������������������| 6060/6060 [20:32<00:00, 4.92it/s]
INFO:PML:Evaluating epoch 5
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [06:02<00:00, 16.72it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.42it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.1933502089360334
INFO:PML:TRAINING EPOCH 6
total_loss=34.66808: 100%|��������������������| 6060/6060 [20:28<00:00, 4.93it/s]
INFO:PML:Evaluating epoch 6
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [06:00<00:00, 16.80it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.36it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.22929256402014356
INFO:PML:TRAINING EPOCH 7
total_loss=28.18377: 100%|��������������������| 6060/6060 [20:25<00:00, 4.95it/s]
INFO:PML:Evaluating epoch 7
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [05:56<00:00, 17.01it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.63it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.2441323797278474
INFO:PML:TRAINING EPOCH 8
total_loss=30.59254: 100%|��������������������| 6060/6060 [20:25<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 8
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [06:00<00:00, 16.82it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.44it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.28265094289081755
INFO:PML:TRAINING EPOCH 9
total_loss=35.66448: 100%|��������������������| 6060/6060 [20:25<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 9
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [05:59<00:00, 16.87it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.54it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.32403233151183974
INFO:PML:TRAINING EPOCH 10
total_loss=28.28654: 100%|��������������������| 6060/6060 [20:37<00:00, 4.90it/s]
INFO:PML:Evaluating epoch 10
INFO:PML:Getting embeddings for the train split
100%|��������������������| 6061/6061 [05:59<00:00, 16.85it/s]
INFO:PML:Getting embeddings for the val split
100%|��������������������| 319/319 [00:19<00:00, 16.50it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.3344724365155899
�����ģ��

Inference Models Ԥ��
��֤��
��Ϊ���Լ���������new_individual�Ĵ��ڣ��������Ǹ�����֤����ѯͼ��Ͳο�ͼ��֮����ʵ�����ѡȡ���ʵ���ֵ�������ֵ�����������ҳ�new_individual����һ���õ���Inference Models ģ��ĺ�����������˼ά��ͼ.
���ȼ���ѵ���õ�ģ�ͣ�trunk��embedder.
best_trunk_weights = glob.glob('./models/{}/trunk_best*.pth'.format(MODEL_NAME))[0]
trunk.load_state_dict(torch.load(best_trunk_weights))
best_embedder_weights = glob.glob('./models/{}/embedder_best*.pth'.format(MODEL_NAME))[0]
embedder.load_state_dict(torch.load(best_embedder_weights))
inference_model = InferenceModel(trunk=trunk,embedder=embedder,normalize_embeddings=True,
)
���ǽ�ѵ������Ϊknn�������ռ䡣
# pass in a dataset to serve as the search space for k-nn
inference_model.train_knn(train_dataset)
valid_dataloader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=N_WORKER, pin_memory=True)
valid_labels_list = []
valid_distance_list = []
valid_indices_list = []for images, labels in tqdm(valid_dataloader):distances, indices = inference_model.get_nearest_neighbors(images, k=N_NEIGHBOURS)# get the k nearest neighbors of a queryvalid_labels_list.append(labels)valid_distance_list.append(distances)valid_indices_list.append(indices)valid_labels = torch.cat(valid_labels_list, dim=0).cpu().numpy()
valid_distances = torch.cat(valid_distance_list, dim=0).cpu().numpy()
valid_indices = torch.cat(valid_indices_list, dim=0).cpu().numpy()

We have the indices of the nearest neighbours in our training set, so setup the lookups to return the individual_id:
new_whale_idx = -1train_labels = train_df['individual_id'].unique()
train_idx_lookup = train_df['individual_id'].copy().to_dict()
train_idx_lookup[-1] = 'new_individual'valid_class_lookup = valid_df.set_index('label')['individual_id'].copy().to_dict()




Loop through a range of thresholds and find which maximises our MAP@5:
thresholds = [np.quantile(valid_distances, q=q) for q in np.arange(0, 1.0, 0.01)]

��������б��е�0.1, 0.2. 0.3�� 1��ֵ����Ϊ������ֵ�IJ���
results = []for threshold in tqdm(thresholds):prediction_list = []running_map=0for i in range(len(valid_distances)):pred_knn_idx = valid_indices[i, :].copy() insert_idx = np.where(valid_distances[i, :] > threshold) if insert_idx[0].size != 0: pred_knn_idx = np.insert(pred_knn_idx, np.min(insert_idx[0]), new_whale_idx) predicted_label_list = []for predicted_idx in pred_knn_idx:predicted_label = train_idx_lookup[predicted_idx]if len(predicted_label_list) == 5:breakif (predicted_label == 'new_individual') | (predicted_label not in predicted_label_list):predicted_label_list.append(predicted_label)gt = valid_class_lookup[valid_labels[i]]if gt not in train_labels:gt = "new_individual"precision_vals = []for j in range(5):if predicted_label_list[j] == gt:precision_vals.append(1/(j+1))else:precision_vals.append(0)running_map += np.max(precision_vals)results.append([threshold, running_map / len(valid_distances)])results_df = pd.DataFrame(results, columns=['threshold','map5'])
������֤���е�ÿ���㣬��������ѵ���������������750���㣬��Щ��ľ��뱣����valid_distances�У���Ӧ��ѵ�����е�����������valid_indices�У�
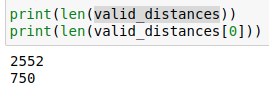

ʵ���ϣ�get_nearest_neighbors�������ص�����������ӽ��ĵ���������ӣ��������ǿ��Կ�������һ��ij���㳬������ֵ����֮��ĵ�һ��Ҳ������ֵ�����������ҳ����������ֵ�ĵ�np.min(insert_idx[0])���������֮������¸�������new_whale_idx.

��Ϊ����Ҫ����Dz������Ԥ���������ԣ����ݾ����Զ��������ѡ��ѵ�����������������label��Ϊ����Ԥ��Ľ����
����ʹ��forѭ����һ�����ļӣ���������ͬ��labelʱ����������˵��һ���͵ڶ����label��ͬ����ֱ�����Dz��������ͬ�Ľ����
Ԥ�����˽�������ǶԱ�һ�º���ʵ�ı�ǩ��ȣ�Ԥ��ı��֡�����ʹ��precision_vals�������ʵ��ǩ��Ԥ�����У����Ϊ1, �����0�� ֮�����Ǽ�¼��ÿ����ֵ�ı��������
results_df = results_df.sort_values(by='map5', ascending=False).reset_index(drop=True)
results_df.head(5)
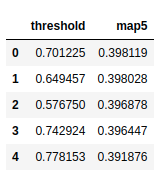
��map�е�ֵ��ʹ��sort_values�Ӵ�С���С�
Ȼ������ѡ�������õĵ�һ�е���ֵ��Ϊ���ǻ����¸���ı�
threshold = results_df.loc[0, 'threshold']
threshold # 0.701225185394287
���Լ�Ԥ��
Ϊ�����յIJ��Լ������ǽ�ѵ��������֤�����������ʹ��ȫ�����������������ǵ������ռ䡣
combined_df = pd.concat([train_df, valid_df], axis=0).reset_index(drop=True)
combined_dataset = HappyWhaleDataset(df=combined_df, image_dir=TRAIN_DIR, return_labels=True)
len(combined_dataset) # 51033
Re-train the KNN model on this:
inference_model.train_knn(combined_dataset)
test_df = pd.read_csv('./happy-whale-and-dolphin/sample_submission.csv')
test_dataset = HappyWhaleDataset(df=test_df, image_dir=TEST_DIR, return_labels=False)
len(test_dataset) # 27956
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=N_WORKER, pin_memory=True)
��������֮ǰ��֤����Ԥ�����һ��
test_distance_list = []
test_indices_list = []for images in tqdm(test_dataloader):distances, indices = inference_model.get_nearest_neighbors(images, k=N_NEIGHBOURS)test_distance_list.append(distances)test_indices_list.append(indices)test_distances = torch.cat(test_distance_list, dim=0).cpu().numpy()
test_indices = torch.cat(test_indices_list, dim=0).cpu().numpy()
combined_idx_lookup = combined_df['individual_id'].copy().to_dict()
combined_idx_lookup[-1] = 'new_individual'
results = []prediction_list = []for i in range(len(test_distances)):pred_knn_idx = test_indices[i, :].copy() insert_idx = np.where(test_distances[i, :] > threshold) if insert_idx[0].size != 0: pred_knn_idx = np.insert(pred_knn_idx, np.min(insert_idx[0]), new_whale_idx) predicted_label_list = []for predicted_idx in pred_knn_idx:predicted_label = combined_idx_lookup[predicted_idx]if len(predicted_label_list) == 5:breakif (predicted_label == 'new_individual') | (predicted_label not in predicted_label_list):predicted_label_list.append(predicted_label)prediction_list.append(predicted_label_list)prediction_df = pd.DataFrame(prediction_list)
prediction_df.head()
������ת��Ϊ����Ҫ��ĸ�ʽ
prediction_df['predictions'] = prediction_df[0].astype(str) + ' ' + prediction_df[1].astype(str) + ' ' + prediction_df[2 ].astype(str) + ' ' + prediction_df[3].astype(str) + ' ' + prediction_df[4].astype(str)
prediction_df.head()
submission = pd.read_csv('./happy-whale-and-dolphin/sample_submission.csv')
submission['predictions'] = prediction_df['predictions']
submission.to_csv('submission.csv', index=False)
���

Ŀǰ�Ľ��һ�㣬��ֻѵ����10��epoch�����������ռ䡣�����ݼ���Ԥ����Ҳ��һ�������Ż��ĵ㡣