�������ӣ�https://arxiv.org/abs/2007.15484
ժҪ
Deep neural networks have been able to outperform humans in some cases like image recognition and image classification. However, with the emergence of various novel categories, the ability to continuously widen the learning capability of such networks from limited samples, still remains a challenge. Techniques like Meta-Learning and/or few-shot learning showed promising results, where they can learn or generalize to a novel category/task based on prior knowledge. In this paper, we perform a study of the existing few-shot meta-learning techniques in the computer vision domain based on their method and evaluation metrics. We provide a taxonomy for the techniques and categorize them as data-augmentation, embedding, optimization and semantics based learning for few-shot, one-shot and zero-shot settings. We then describe the seminal work done in each category and discuss their approach towards solving the predicament of learning from few samples. Lastly we provide a comparison of these techniques on the commonly used benchmark datasets: Omniglot, and MiniImagenet, along with a discussion towards the future direction of improving the performance of these techniques towards the final goal of outperforming humans.
��ijЩ����£���ͼ��ʶ���ͼ����࣬����������Ѿ��ܹ���Խ���ࡣȻ�������Ÿ��������ij��֣������������в��������������ѧϰ������������Ȼ��һ����ս��Ԫѧϰ��/��С����ѧϰ�ȼ�����ʾ������ϣ���Ľ��������Щ�����У����ǿ��Ի�������֪ʶѧϰ�������һ���µ����/�����ڱ����У����ǶԼ�����Ӿ��������еĻ��ڷ���������ָ���С����Ԫѧϰ�����������о�������Ϊ��Щ�����ṩ��һ�����෨���������Ƿ���Ϊ������ǿ��Ƕ�롢�Ż��ͻ��������ѧϰ������few-shot, one-shot �� zero-shot���á�Ȼ��������������ÿ������������Ŀ����Թ����������������ǽ����С������ѧϰ�������ķ�������������ڳ��õĻ����ݼ�Omniglot��MiniImagenet�϶���Щ���������˱Ƚϣ���������δ���Ľ���Щ�������ܵķ�����ʵ�ֳ�Խ���������Ŀ�ꡣ
1 Introduction
Artifical intelligence (AI) based systems are becoming a huge part of the human life whether be it personal or professional. We are surrounded by AI-based machines and applications which intend to make our life easier. For example, the automatic mail filtering (spam detection), suggesting shopping websites, social networking in smartphones, etc. [1], [2], [3], [4]. This impressive progress has been possible due to the breakthrough success achieved by machine or deep learning models [5]. Machine or deep learning occupies a big part of the AI domain. Deep Learning models are built over multiple layers of perceptrons combined with the ability to apply gradient-based optimization techniques. Two of the most common applications of deep learning models are: computer vision (CV), where the goal is to teach machines how to see and perceive things like humans do; Natural Language Processing (NLP) and Natural Language Understanding (NLU), where the goal is to analyze and comprehend large amounts of natural language data. These deep learning models have achieved tremendous success in image recognition [6], [7], [8], speech recognition [9], [10], [11], [12], [13], natural language processing and understanding [14], [15], [16], [17], [18], video analytics [19], [20], [21], [22], [23], cyber security [24], [25], [26], [27], [28], [29], [30]. The most common approach towards machine and/or deep learning is supervised learning, where large number of data samples, towards a particular application, are collected along with their respective labels and formed as a dataset. This dataset is categorized into three parts: training, validation and testing. During the training phase, the model is fed the data from the training and validation sets along with their respective labels and based on back propagation and optimization, the model generalizes to a hypothesis. During testing phase, the testing data is fed to the model and based on the derived hypothesis, the model predicts the output class of the testing data samples.
�����˹����ܣ�AI����ϵͳ���ڳ�Ϊ���������һ����Ҫ��ɲ��֣������Ǹ��������ְҵ���������Χ���ǻ����˹����ܵĻ�����Ӧ�ó�������ּ�������ǵ���������ɡ����磬�Զ��ʼ����ˣ������ʼ���⣩�����鹺����վ�������ֻ��罻�����[1]��[2]��[3]��[4]�����ڻ��������ѧϰģ��ȡ����ͻ���Եijɹ�����һ����ӡ����̵Ľ�����Ϊ����[5]�����������ѧϰռ�����˹���������ĺܴ�һ���֡����ѧϰģ�����ڶ���֪���Ͻ����ģ������Ӧ�û����ݶȵ��Ż����������������ѧϰģ�����������Ӧ���ǣ�������Ӿ���CV������Ŀ���ǽ̻������������һ��������֪�����Ȼ���Դ�����NLP������Ȼ�������⣨NLU������Ŀ���Ƿ��������������Ȼ�������ݡ���Щ���ѧϰģ����ͼ��ʶ��[6]��[7]��[8]������ʶ��[9]��[10]��[11]��[12]��[13]����Ȼ���Դ���������[14]��[15]��[16]��[17]��[18]����Ƶ����[19]��[20]��[21]��[22]��[23]�����簲ȫ[24]��[25]��[26]��[27]��[28]��[29]��[30]�ȷ���ȡ���˾�ɹ���������/�����ѧϰ����ķ����Ǽලѧϰ����������ض�Ӧ�õĴ�����������������Եı�ǩһ���ռ������γ����ݼ��������ݼ���Ϊ�������֣�ѵ������֤�Ͳ��ԡ���ѵ���Σ�ģ�ͽ�����ѵ��������֤�������ݼ�����Եı�ǩ������ģ�ͣ������ڷ������Ż�����ģ���ƹ㵽һ�����衣�ڲ��ԽΣ��������������뵽ģ���У������ڵ����ļ��裬ģ��Ԥ���������������������
The ability to handle large amounts of data, thanks to the power of computational and modern systems [31], [32], has been exceptional. Along with the advancements of various algorithms and models, deep learning has been able to match up to humans and in some cases outperform humans. AlphaGo [33] an AI-based agent, trained without any human guidance was able to defeat the world champion of Go, an ancient board game considered to be 10x complicated than chess [34]; In another example of a complex and strategical multiplayer game called DOTA, the AIagent was able to defeat human players of DOTA [35]; For the task of image recognition and classification models like ResNet [6] and Inception [36], [37], [38] were able to achieve better performance than humans on the popular ImageNet dataset which consists of over 14 million images with over 1000 classes [39].
���ڼ�������ִ�ϵͳ��ǿ���ܣ������������ݵ������dz���ɫ[31]��[32]�����Ÿ����㷨��ģ�͵Ľ��������ѧϰ�Ѿ��ܹ���������ƥ�䣬������ijЩ������������ࡣAlphaGo[33]һ�ֻ����˹����ܵ��ع�����û���κ�����ָ���������ѵ�����ܹ�����Χ������ھ���Χ����һ�ֹ��ϵ�������Ϸ������Ϊ�ȹ������帴��10��[34]������һ����ΪDOTA�ĸ����Ҿ���ս������Ķ�����Ϸʾ���У�AIagent�ܹ�����DOTA���������[35]������ͼ��ʶ��ͷ���������ResNet[6]��Inception[36]��[37]��[38]��ģ���ܹ������е�ImageNet���ݼ���ʵ�ֱ�������õ����ܣ������ݼ���1400������ͼ���1000���������[39]��
One of the ultimate goal of AI is to match or outperform humans in any given task. To achieve this goal, it is imperative to have minimal dependency on large balanced labeled datasets. Current models achieving successful results in tackling tasks with tremendous amounts of labelled data, however, approaches for other large variety tasks where the labelled data is scarce (few samples only) the performance of the respective models drops significantly. It is unrealistic to expect large balanced datasets for any particular task because due to nature of various categories it is nearly impossible to keep up with the producing labelled data. Furthermore, generation of labelled datasets require resources like time, human efforts and can be financially expensive. On the other hand, humans can quickly learn new class or classes, like given a photo of a strange animal, it can easily identify the animal from a photo which consists of a variety of animals. Another advantage of humans over machines is the ability to learn new concepts or classes on the fly, whereas machines have to go through an expensive offline process of training and retraining the entire model repeatedly to learn new classes, provided, the availability of labelled data. Researchers and developers are motivated to bridge this gap between humans and machines. As a potential solution to this problem, we have seen an ever increasing work in the area of meta-learning [40], [41], [42], [43], [44], [45], [46], [47], [48], [49], [50], few-shot learning [51], [52], [53], [54], lowshot learning [55], [56], [57], [58], zero-shot learning [59], [60], [61], [62], [63], [64], [65], where the goal is to make the model generalize better to novel tasks consisting of few labelled samples.
�˹����ܵ�����Ŀ��֮һ�����κθ���������������ƥ�л�Խ���ࡣΪ��ʵ����һĿ�꣬���뾡�����ٶԴ���ƽ�������ݼ�����������ǰ��ģ���ڴ������д���������ݵ�����ʱȡ���˳ɹ��Ľ�������ǣ����ڱ������ϡ�٣�����������������������������Ӧģ�͵����������½��������κ��ض���������˵����������ƽ�����ݼ��Dz���ʵ�ģ���Ϊ���ڸ����������ʣ����������ܸ������ɱ�����ݵIJ��������⣬���ɴ���ǩ�����ݼ���Ҫʱ�䡢��������Դ�����ҿ����ڲ����Ϻܰ�����һ���棬������Կ���ѧϰ�µ��࣬�����һ����ֶ������Ƭһ���������Ժ����ش�һ���ɶ��ֶ�����ɵ���Ƭ��ʶ�������������ȣ��������һ���������ܹ���̬��ѧϰ�¸�����࣬���������뾭��һ����������߹��̣�������ѵ��������ѵ������ģ�ͣ���ѧϰ���࣬ǰ�����б�����ݿ��á��о���Ա�Ϳ�����Ա������ȥ�ֺ��������֮��ĺ蹵����Ϊ��������һ��DZ�ڽ�������������Ѿ�����Ԫѧϰ[40]��[41]��[42]��[43]��[44]��[45]��[46]��[47]��[48]��[49]��[50]��few-shotѧϰ[51]��[52]��[53]��[54]��low-shotѧϰ[55]��[56]��[57]��[58]��zero-shotѧϰ[59]��[60]��[61]��[62]��[63]��[64]��[65]��������Ĺ���Խ��Խ�࣬Ŀ����ʹģ���õ��ƹ㵽�����������������������
1.1 What is Few-shot Learning and Meta-Learning
In few-shot, low-shot, or n-shot learning (where n is generally between 1 to 5), the basic idea is to train the model with large amount of data samples on multiple categories, and during testing, the model is provided with novel categories (also referred to as novel set) where there are multiple data samples for each category and generally the number of categories is limited to five. In meta learning, the goal is to generalize or learn the learning process, where the models are trained on a particular task, and a function of a different classifier is used on the novel set. The objective is to find the best hyperparameters and model weights where the model can easily adapt to the novel tasks without over-fitting to a novel task. In meta-learning, there are two categories of optimizational running simultaneously: one which learns to the new task; another which trains the learner. In recent times, few shot learning and meta-learning techniques have garnered interest, thus becoming a hot topic for research, with a flurry of recent papers1[66].
��few-shot, low-shot��n-shot learning������nͨ����1��5֮�䣩�У�����˼����ʹ�ö�����Ĵ�����������ѵ��ģ�ͣ����ڲ����ڼ䣬��ģ���ṩ�������Ҳ��Ϊ�¼��ϣ�������ÿ������ж����������������ͨ��������������Ϊ�������Ԫѧϰ�У�Ŀ���Ǹ�����ѧϰѧϰ���̣���ѧϰ�����У�ģ������ض��������ѵ���������¼�����ʹ�ò�ͬ�������ĺ�������Ŀ�����ҵ���ѵij�������ģ��Ȩ�أ�ʹģ���ܹ�������Ӧ������������������������Ԫѧϰ�У��������Ż�ͬʱ���У�һ����ѧϰ��������һ��ѵ��ѧϰ���ķ����������С����ѧϰ��Ԫѧϰ�������������ǵ���Ȥ����˳�Ϊ�о������Ż��⣬���������һϵ������[66]��
Early work in the area of meta-learning was done by Y oshua and Samy Bengio [67] and Fei-Fei Li in few-shot learning [68]. Metric learning is one of the older techniques used, where the objective is to learn from the embedding space. Images are transformed to their embeddings and images for a particular category were observed to be in close cluster whereas images from different categories were observed to be far away. Another popular approach where the data is augmented which results in generation of more samples from the limited few samples available. Currently semantics based approaches are extensively researched upon where the classification is based solely on the name of the category and its attribute. This semantics based approach is inspired towards solving zero-shot learning applications.
Ԫѧϰ��������ڹ�����Y oshua��Samy Bengio[67]��Fei Fei Li��С����ѧϰ[68]����ɡ�����ѧϰ��ʹ�õĽ��ϼ���֮һ����Ŀ���Ǵ�Ƕ��ռ�ѧϰ����ͼ��ת��ΪǶ�룬�۲쵽�ض�����ͼ���ڽ��ܵľ����У������Բ�ͬ����ͼ���ڽ�Զ�ľ����С���һ�����еķ������������ݣ��Ӷ������ļ����������������ɸ���������Ŀǰ����������ķ����õ��˹㷺���о������з���������������Ƽ������ԡ����ֻ�������ķ����ܵ��˽��������ѧϰӦ�ó����������
1.2 Transfer Learning and Self-Supervised Learning
The overall objective of transfer learning is to learn knowledge or experience from a set of tasks and transfer it to a task in the similar domain [95]. The task used to train the model to gain knowledge has lots of labelled samples whereas the transferred task has comparatively less labelled data (also called as fine-tuning), which is not enough to train and converge the model to the particular task. The performance of transfer learning technique is dependant on the relevance between the two tasks. While performing transfer learning, the classification layers are trained for the new tasks whereas the weights of the previous layers in a model are kept frozen [96]. For every new task, where we do transfer learning, the choice of learning rate and the number of layers to be frozen has to be decided manually. In contrast to this, meta-learning techniques can quite rapidly adapt to a new task automatically.
Ǩ��ѧϰ������Ŀ���Ǵ�һ��������ѧϰ֪ʶ���飬������Ǩ�Ƶ����������������[95]������ѵ��ģ���Ի�ȡ֪ʶ��������д��������������ת�Ƶ����������Խ��ٵı�����ݣ�Ҳ��Ϊ�������ⲻ����ѵ��ģ�Ͳ������������ض�����Ǩ��ѧϰ�����ı���ȡ������������֮�������ԡ���ִ��Ǩ��ѧϰʱ�������������������ѵ������ģ������ǰ���Ȩ�ر��ֲ���[96]���������ǽ���Ǩ��ѧϰ��ÿ��������ѧϰ���ʵ�ѡ��Ͷ���IJ����������ֶ�����������෴��Ԫѧϰ�������Էdz����ٵ��Զ���Ӧ������
Self-supervised learning research have gained a lot of popularity in recent time [97], [98], [99]. Training of Self-Supervised Learning (SSL) techniques is based on two steps: one, where the model is trained on a pre-defined pre-text task where it it trained on a large corpus of unlabelled data samples; two, where the learned model parameters are used to train or fine-tune the model for the main downstream task. The idea behind meta-learning or few-shot learning techniques is quite similar to self-supervised learning, which is to use prior knowledge, to recognize or fine tune to a novel task. Studies have shown that self supervised learning can be used along with few-shot learning to boost the performance of the model towards novel categories [100], [101].
�����������Ҽලѧϰ�о��õ��˹㷺�Ĺ�ע[97]��[98]��[99]�����Ҽලѧϰ��SSL��������ѵ�������������裺��һ������Ԥ������ı�������ѵ��ģ�ͣ��ڴ���δ�������������ѵ��ģ�ͣ��ڶ���ѧϰ��ģ�Ͳ�������ѵ��������Ҫ���������ģ�͡�Ԫѧϰ��С����ѧϰ���������˼�����Լලѧϰ�dz����ƣ���ʹ������֪ʶʶ������������о��������Լලѧϰ������С����ѧϰһ��ʹ�ã������ģ�Ͷ�����������[100]��[101]��
1.3 Taxonomy and Organization
The main goal of meta-learning, few-shot learning, low-shot learning, one-shot, zero-shot learning, techniques is to make the deep learning model generalize to better to novel categories from handful samples with iterative training based on the prior knowledge or experience. Prior knowledge is knowledge acquired from training the samples on a labelled dataset consisting of large number of samples and then using this knowledge, THA T the model is trained ON, to recognize novel tasks with exposure to limited samples. Therefore, in the paper, we have combined all these techniques together under the main umbrella of fewshot meta-learning. As there is no pre-define taxonomy to these techniques, we have classified these approaches into four main categories: data-augmentation based; metric-learning based, metaoptimization based; and semantic-based (as illustrated in Figure 1). Data-augmentation based techniques are quite popular where the idea is to expand the prior knowledge by augmenting the minimally available samples and generating more diverse samples to train the model. In embedding-based techniques, the data samples are transformed to an another low-level dimension and then classified based on a distance between these embeddings. In optimization based techniques where a meta-optimizer is used to better generalize the model during the initial training and thus can do better prediction for the novel tasks. Semantic-based techniques are where the semantics of the data are used along with the prior knowledge for the model to either learn or optimize to novel categories. Table 1 highlights the commonly used symbols used in various equations and algorithms in the rest of the paper along with their meaning. Our contributions to this paper are summarized as follows:
Ԫѧϰ��������ѧϰ��������ѧϰ��������ѧϰ��������ѧϰ��������ҪĿ����ͨ����������֪ʶ����ĵ���ѵ����ʹ���ѧϰģ�ʹ������������ƹ㵽���õ����������֪ʶ��ָ��һ���ɴ���������ɵı�����ݼ���ѵ��������Ȼ��ʹ�ø�֪ʶ����ѵ��ģ�͵�֪ʶ����ʶ��¶�����������µ�����������õ�֪ʶ����ˣ��ڱ����У�������fewshotԪѧϰ��������½�������Щ���������һ��������Щ����û��Ԥ����ķ��෨�����ǽ���Щ������Ϊ�Ĵ��ࣺ����������ǿ�ķ��������ڶ���ѧϰ������Ԫ�Ż��ͻ�������ģ���ͼ1��ʾ����������������ļ����dz����У���˼����ͨ��������С�������������ɸ���������������ѵ��ģ�ͣ��Ӷ���չ����֪ʶ���ڻ���Ƕ��ļ����У�����������ת������һ���Ͳ�ά�ȣ�Ȼ�������ЩǶ��֮��ľ�����з��ࡣ�ڻ����Ż��ļ����У�Ԫ�Ż��������ڳ�ʼѵ���ڼ���õظ���ģ�ͣ��Ӷ����Ը��õ�Ԥ��������������ļ����ǽ����ݵ�������ģ�͵�����֪ʶһ������ѧϰ���Ż�����𡣱�1ͻ����ʾ�˱������ಿ���и��ַ��̺��㷨��ʹ�õij��÷��ż��京�塣���ǶԱ��ĵĹ����ܽ����£�

? We analyze the seminal work done in the area of few shot meta-learning ( based on published research from the year 2016 to 2020) and provide a taxonomy and categorize the techniques into four categories: data augmentation based, embedding based, optimization based, and semantics based and summarize the work done in each of the proposed category.
? We did a comparison of the performance of the techniques in each category with reference to the two commonly used benchmark dataset: Onmiglot and MiniImagenet and discuss the limitations and possible future directions towards solving the problem of few shot meta-learning.
?���Ƿ�������С����Ԫѧϰ���������Ŀ����Թ���������2016����2020�귢�����о��������ṩ�˷��෨����������Ϊ���ࣺ����������ǿ������Ƕ�롢�����Ż��������������ÿһ�������Ĺ��������ܽᡣ
?���Dzο��������õĻ����ݼ���Onmiglot��MiniImagenet����ÿһ�༼�������ܽ����˱Ƚϣ��������˽��С����Ԫѧϰ����ľ����Ժ�δ�����ܵķ���

Fig. 1: Taxonomy of Few-shot meta-learning techniques. We have classified these techniques under four categories based on data augmentation, embedding, optimization and semantic. Data augmentation based techniques involves approach where the limited data samples are augmented to generate more samples to enrich the training experience. Embedding based techniques involve approaches where the data is transformed to a low dimensional space and then clustered into different groups using a specific distance function. In optimization based techniques, a meta optimizer is used which learns/generalizes from the overall learning process. In semantic based learning, the semantic information of the data samples is used along with the samples to better generalize and thus predict the novel categories. С����Ԫѧϰ�����ķ��ࡣ���Ǹ����������䡢Ƕ�롢�Ż������彫��Щ������Ϊ���ࡣ������������ļ����漰һ�ַ����������������������������������ɸ���������Էḻѵ�����顣����Ƕ��ļ����漰������ת������ά�ռ䣬Ȼ��ʹ���ض��ľ��뺯������ۼ�����ͬ�����еķ������ڻ����Ż��ļ����У�ʹ����һ��Ԫ�Ż�������������ѧϰ������ѧϰ/�������ڻ��������ѧϰ�У�����������������Ϣ������һ���������õظ�����Ԥ�������
The remainder of the paper is structured as following. In subsection 2.1 we discuss the data augmentation based techniques in which the training data is augmented to generate more samples to train the neural network model. In subsection 2.1 the techniques where the input data samples are augmented to increase the training data are discussed. In subsection 2.2, we discuss the techniques where the general approach is to convert the high dimensional data to a lower dimension embedding and then using various distance or metric function compare the embedding of the initial trained tasks to that of the novel tasks. In subsection 2.3, we discuss techniques in which a meta-optimizer is used which can learn from the training set and can generalize well on the novel tasks. In subsection 2.4 we discuss techniques which extract semantic information from the training set to generalize on the novel tasks. In section 3 we compare the performance of the various techniques discussed in the paper. This comparison is done on two benchmark datasets: Omniglot and miniImagenet.
���ĵ����ಿ�ֽṹ���¡��ڵ�2.1С���У����������˻���������ǿ�ļ���������ѵ�����ݱ���ǿ�����ɸ���������ѵ��������ģ�͡��ڵ�2.1С���У�����������������������������ѵ�����ݵļ������ڵ�2.2С���У�����������һ�㷽���ǽ���ά����ת��Ϊ��άǶ�룬Ȼ��ʹ�ø��־���������������ʼѵ�������Ƕ�����������Ƕ����бȽϵļ������ڵ�2.3С���У�����������ʹ��Ԫ�Ż����ļ�����Ԫ�Ż������Դ�ѵ������ѧϰ�����ҿ��Ժܺõظ����������ڵ�2.4С���У����������˴�ѵ��������ȡ������Ϣ�Ը���������ļ������ڵ�3���У����DZȽ��˱��������۵ĸ��ּ��������ܡ����ֱȽ��������������ݼ��Ͻ��еģ�Omniglot��miniImagenet��
2 FEW-SHOT META LEARNING
In this section, we describe the seminal work done in the data augmentation, embedding, optimization and semantic based learning approaches in the few shot meta learning domain as highlighted in Figure 1
�ڱ����У�������������ͼ1��ͻ����ʾ��С����Ԫѧϰ�����У���������ǿ��Ƕ�롢�Ż��ͻ��������ѧϰ�������������Ŀ����Թ���
2.1 Data Augmentation Based Techniques������������ļ���
Data-augmentation based techniques are quite popular in the supervised learning domain. Traditional techniques like scaling, cropping, rotating (clockwise and anti-clockwise) were implemented to expand the size of the training dataset where the goals was to make the model generalize better and avoid overfitting/underfitting scenarios. In the meta-learning space, the idea is to expand the prior knowledge by augmenting the minimally available samples and generating more diverse samples to train the model.
����������ǿ�ļ������мලѧϰ����dz����С�ʵ�������š��ü�����ת��˳ʱ�����ʱ�룩�ȴ�ͳ��������չѵ�����ݼ��Ĵ�С����Ŀ����ʹģ���õ�ͨ�û�����������/Ƿ��ϳ�������Ԫѧϰ�ռ��У���˼����ͨ��������С�������������ɸ��ͬ��������ѵ��ģ�ͣ��Ӷ���չ����֪ʶ��
2.1.1 LaSO: Label-Set Operations networks��ǩ����������
The work done by Alfassy et al. in [71] describes a technique to tackle samples with more than one label for few-shot classification settings. Their novel idea consists to combine multiple labels of samples in the feature space. The resultant feature vector will comprise of labels which have gone through a particular set of operations on the label set of the respective data sample-label pair. Using their method, data samples comprising of intersection, union, or set-difference which are generated from labels present in two different input data samples.
Alfassy et al.��[71]�������Ĺ���������һ�ִ������ж����ǩ�������ļ���������С�����������á����ǵ����뷨���������ռ�����϶��������ǩ�����ɵ������������ɱ�ǩ��ɣ���Щ��ǩ�ڸ�������������ǩ�Եı�ǩ���Ͼ�����һ���ض��IJ�����ʹ�����ǵķ���������������������ͬ�������������еı�ǩ���ɵĽ�������������ɡ�
As illustrated in Figure 2, the input the system are two different images, x and y with the set of their respective multiple labels L(x), L(y). The labels in the feature space F are represented with Fxand Fy. The Inception model [36] is used as backbone B to generate this feature space. The concatenated feature vectors, Fxand Fyare passed as an input to three sub-modules of the network Mint, Muni, Msubwhich synthesize the feature vector in the same space. The original vectors L(x), L(y) along with the generated output of the three sub-modules are passed onto the classifier. Even though a set of pre-defined labels are used, the model can also generalize to labels which are not present into the set and are forced to learn implicitly only by observing the L(x), L(y). Code: https://github.com/leokarlin/LaSO [71]
��ͼ2��ʾ��ϵͳ��������������ͬ��ͼ��x��y�Լ����Ǹ��ԵĶ����ǩL��x����L��y���ļ��ϡ�Ҫ�ؿռ�F�еı�ǩ��Fx��Fy��ʾ����ʼģ��[36]��������B�����ɸ������ռ䡣���ӵ���������Fx��Fy��Ϊ���봫�ݸ�����Mint��Muni��Msub��������ģ�飬������ͬһ�ռ�ϳ�����������ԭʼ����L��x����L��y���Լ�������ģ���������������ݵ�����������ʹʹ����һ��Ԥ����ı�ǩ����ģ��Ҳ�����ƹ㵽�������ڸü����еı�ǩ������ֻ��ͨ���۲�L��x����L��y������ʽѧϰ�����룺https://github.com/leokarlin/LaSO [71]

Fig. 2: The input the system are two different images, x and y with the set of their respective multiple labels L(x), L(y). The labels in the feature space F are represented with Fxand Fy. The original vectors L(x), L(y) along with the generated output of the three sub-modules are passed onto the classifier. Even though a set of pre-defined labels are used, the model can also generalize to labels which are not present into the set and are forced to learn implicitly only by observing the L(x), L(y). Image Source: [71] ϵͳ��������������ͬ��ͼ��x��y�Լ����Ǹ��ԵĶ����ǩL��x����L��y���ļ��ϡ�Ҫ�ؿռ�F�еı�ǩ��Fx��Fy��ʾ��ԭʼ����L��x����L��y���Լ�������ģ���������������ݵ�����������ʹʹ����һ��Ԥ����ı�ǩ����ģ��Ҳ�����ƹ㵽�������ڸü����еı�ǩ������ֻ��ͨ���۲�L��x����L��y������ʽѧϰ��
2.1.2 Recognition by Shrinking and Hallucinating Features ����С�ͻþ�����ʶ��
In the work done by Hariharan and Girshick [69], the authors come up with a low-shot learning benchmark. This benchmark is inspired from the ImageNet1k dataset [102]. In the initial training step of the benchmark the learner is able to generalize to the Dtrainfrom the dataset, and during the few shot training step, the model should be able to generalize from the feature space of the Dtrainand the Dtest, to correctly predict the novel tasks. The benchmark is used to provide a sanity check (by comparing the accuracy) on the model��s ability to learn during its training on Dtrainand testing with Dtest. Code: https://github.com/facebookresearch/low-shot-shrink-hallucinate [69]
��Hariharan��Girshick[69]�����Ĺ����У����������һ���ͳɱ���ѧϰ�����û�����Դ��ImageNet1k���ݼ�[102]���ڻ����Եij�ʼѵ�������У�ѧϰ���ܹ������ݼ��и�����Dtrain����С����ѵ�������У�ģ��Ӧ���ܹ���Dtrain��Dtest�������ռ��и���������ȷԤ���������������ڶ�ģ����Dtrainѵ����Dtest�����ڼ��ѧϰ�������н�ȫ�Լ�飨ͨ���Ƚ�ȷ�ԣ������룺https://github.com/facebookresearch/low-shot-shrink-hallucinate [69]
They showed that by hallucinating the feature vector for the Dtrain, to train the model on more number of images. Doing so, it enhances the model��s ability generalize better to novel class. The hallucination is done by using a G function. The G function consists of three fully connected MLP layers. For the model to learn and generalize better to the novel class, the authors have introduced a new loss function called the squared gradient magnitude loss (SGM) which is applied during the fewshot learning phase. The loss is given by:
����֤����ͨ�����������е��������������þ��������ڸ����ͼ����ѵ��ģ�͡�����������ǿ��ģ�Ͷ�����ĸ��õķ����������þ���ͨ��G����ʵ�ֵġ�G������������ȫ���ӵ�MLP����ɡ�Ϊ��ʹģ���õ�ѧϰ���ƹ㵽���࣬����������һ���µ���ʧ��������Ϊƽ���ݶȷ�����ʧ��SGM�����ú�����fewshotѧϰ��Ӧ�á���ʧ������ʾ��
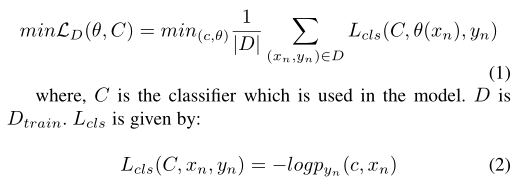
2.1.3 Learning via Saliency-guided Hallucination ͨ�������������Ļþ�ѧϰ
The work done by Zhang et al. in [72] is based on using data hallucination technique in which they use a saliency network [103], [104] to generate the background and foreground information of an image. Using a two-stream network which generates hallucinated data points in the feature space based on the foreground and background information. Their model takes advantage of the generated saliency maps to improve the performance of few-shot technique.
Zhang������[72]�������Ĺ�������ʹ�����ݻþ���������������ʹ������������[103]��[104]������ͼ��ı�����ǰ����Ϣ��ʹ�û���ǰ���ͱ�����Ϣ�������ռ������ɻþ����ݵ��˫�����硣���ǵ�ģ���������ɵ�������ͼ���Ľ�С�������������ܡ�
Their model consists of three modules: one, Saliency Network; two, A network to encode and mix the foreground and background information (FEMN); and three, A Similarity network. The saliency network generates the saliency maps based on the feature vector of the support S samples. The FEMN combines the foreground and background information. The similarity network determines if the query image and and the samples from the support set. The data hallucination process is the summation of foreground and the background information. Code: https://github.com/HongguangZhang/SalNet-cvpr19-master [72]
��ģ��������ģ����ɣ�һ�����������磻���Ƕ�ǰ���ͱ�����Ϣ���б���ͻ�ϵ����磨FEMN�����������������硣�������������֧������������������������������ӳ�䡣FEMN�����ǰ���ͱ�����Ϣ������������ȷ����ѯͼ��������Ƿ�����֧�ּ������ݻþ�������ǰ���ͱ�����Ϣ���ܺ͡����룺https://github.com/HongguangZhang/SalNet-cvpr19-master [72]
2.1.4 Low-Shot Learning from Imaginary Data �����������ݵ�С����ѧϰ
The work done by Wang et al. [70] is based on hallucinating the Dtraindata samples which can be useful for the classifier to learn or generalize to novel tasks. Instead of using hallucination to generate more diverse data like in [69], [72], their goal is to generate hallucinated data which is related to the samples in Dtrain. In their approach, they introduce a hallucinator along with the meta-learner to learn and generalize to the novel tasks. The objective of the hallucinator model is to map the hallucinated data to the original samples in Dtrain. The hallucinator model produces an extended set of Dtrainafter being trained on the base Dtrain. Code: https://github.com/facebookresearch/ low-shot-shrink-hallucinate [70]
Wang����[70]�����Ĺ����ǻ��ڶ����������Ļþ����������ڷ�����ѧϰ���ƹ㵽���������ǵ�Ŀ����������Dtrain�е�������صĻþ����ݣ�������ʹ�ûþ������ɸ������������ݣ���[69]��[72]�������ǵķ����У����������˻þ�����Ԫѧϰ����ѧϰ�����µ����þ���ģ�͵�Ŀ���ǽ��þ�����ӳ�䵽Dtrain�е�ԭʼ�������þ���ģ���ڻ�������ѵ��������һ����չ������ѵ�������룺https://github.com/facebookresearch/ low-shot-shrink-hallucinate[70]
2.1.5 A Maximum-Entropy Patch Sampler ����ط�Ƭ������
The work done by Chu et al. in [73] is based on a ��learned�� form of data augmentation where they search from various sequences of patches generated by sampling the image and perform classification on those patches using the extracted features. They claim that their method, along with the positive and negative sampling rules, together with an improved reward function (based on Maximum Entropy Reinforcement Learning [73]), improves the performance for n-shot learning paradigm.
Chu������[73]�������Ĺ�������һ�֡�ѧϰ����ʽ���������䣬���Ǵ�ͨ������ͼ�����ɵĸ�����Ƭ�����н�����������ʹ����ȡ����������Щ��Ƭ���з��ࡣ�������ƣ����ǵķ������������������Լ��Ľ��Ľ������������������ǿ��ѧϰ[73]�������n-shotѧϰ��ʽ�����ܡ�
Their model consists of five modules: feature extractor, a CNN based model, which at each time step extracts the feature embedding on the patches (generated by the maximum entropy sampler).; state encoder, which is used to aggregate the features generated by the feature extractor step. To achieve this, they use a RNN based GRU [105] model; a maximum entropy Sampler which generates patches from the input data sample. This is build by taking inspiration from Soft Q- Learning [106]; Action context encoder��s goal is to take into consideration all the global information generated by the maximum entropy sampler along with the feature extractor modules; classifier, whose objective is to accurately differentiate the input data sample to generate it predicted label.
���ǵ�ģ�������ģ����ɣ�������ȡ����һ������CNN��ģ�ͣ�����ÿ��ʱ�䲽��ȡǶ������Ƭ�ϵ�������������ز��������ɣ���״̬�����������ھۺ�������ȡ���������ɵ�������Ϊ��ʵ����һ�㣬����ʹ�û���RNN��GRU[105]ģ�͡�����ز���������������������������Ƭ�����Ǵ�Soft Q- Learning[106]�л����й����ġ����������ı�������Ŀ���ǿ�������ز�������������ȡģ�����ɵ�����ȫ����Ϣ������������Ŀ����ȷ����������������������Ԥ���ǩ��
2.1.6 Image Deformation Meta-Networks ͼ�����Ԫ����
The work done by Chen et al. in [74] generates additional training samples by combining a meta-learner module with an image deformation module. These aforementioned modules are trained in an end-to-end manner to significantly outperforms the then state-of-the-art technique. The meta-learning module learns from a group of k ? way, n ? shot tasks to classify samples from Dtrainwhich is then evaluated on samples from Dtest. The deformation module adaptively fuses the images from the support set S to generate synthesized deformed images which are then mapped to the feature vector generated from Dtrainthrough an embedding sub-module to construct the one-shot classification. Code: https://github.com/tankche1/IDeMe-Net
Chen������[74]�������Ĺ���ͨ����Ԫѧϰ��ģ����ͼ�����ģ�����������ɶ����ѵ������������ģ���Զ˵��˵ķ�ʽ����ѵ����������ڵ�ʱ���Ƚ��ļ�����Ԫѧϰģ���һ��k? shot��ѧϰ��n? shot���������dtrain���������з��࣬Ȼ�������Dtest��������������������ģ������Ӧ���ں�����֧�ּ�S��ͼ�������ɺϳɱ���ͼ��Ȼ��ͨ��Ƕ����ģ�齫�ϳɱ���ͼ��ӳ�䵽��Dtrain���ɵ����������Թ���һ���Է��ࡣ���룺https://github.com/tankche1/IDeMe-Net
2.2 Embedding-Based Techniques
In this subsection, we discuss techniques are which are model based, where the goal is to find best possible hypothesis from the hypothesis space and which can generalize well to a variety of tasks. Embedding based techniques also known as metric based techniques, is where the data is transformed to a lower dimension representation and then clustered and compared using a specific distance/metric function.
�ڱ�С���У����ǽ����ۻ���ģ�͵ļ�������Ŀ���ǴӼ���ռ����ҵ���ѿ��ܵļ��裬���ҿ��Ժܺõ��ƹ㵽����������Ƕ��ļ���Ҳ��Ϊ���ڶ����ļ�������������ת��Ϊ��ά��ʾ��Ȼ��ʹ���ض��ľ���/�����������о���ͱȽϡ�
2.2.1 Relation Network
The work done by Sung et al. [78] proposes a flexible and simple yet effective network called as Relation Network (RN), for the n-shot learning settings. The basic idea with RN is based on episode training [75], where an episode consists of randomly selected tasks from the Dtrainwith k number of labelled samples from each class.
Sung����[78]�Ĺ���Ϊn-shotѧϰ���������һ��������Ч�����磬��Ϊ��ϵ���磨RN����RN�Ļ���˼���ǻ����¼�ѵ��[75]������һ���¼��ɴ�K��Dtrsin�����ѡ���������ɣ�ÿ������k�����������
The relation network is based on two steps: one, where the samples from Dtrainand the query set are transformed to a low level embedding space. This process is done by the embedding module; two, using a relation module these low level representations are compared and determined if the query image is matching to any of the output categories. The embedding module consists of four layers of convolutional neural network where each layer consists of 64 convolutional filters with a 3 �� 3 kernel size, followed by batch normalization, ReLU activation and max-pooling performed using a 2 �� 2 window. The relation module is a basic comparison module where the use mean square error (MSE) as a distance function. Code: https://github.com/floodsung/LearningToCompare FSL
��ϵ��������������裺��һ����������DTRAIN�Ͳ�ѯ��������ת��Ϊһ���Ͳ�Ƕ��ռ䡣�ù�����Ƕ��ģ����ɣ��ڶ���ʹ�ù�ϵģ�����Щ�ͼ���ʾ���бȽϣ���ȷ����ѯͼ���Ƿ����κ�������ƥ�䡣Ƕ��ģ�����IJ������������ɣ�ÿ����64�������˲�����ɣ�ÿ���˲������ں˴�СΪ3��3��Ȼ��ʹ��2��2����ִ����������ReLU��������ء���ϵģ����һ�������ıȽ�ģ�飬�����û�ʹ�þ�����MSE����Ϊ���뺯�������룺https://github.com/floodsung/LearningToCompareFSL
2.2.2 Prototypical Network ԭ������
The work done Snell et al. in [77] describes a novel then stateof-the-art network called Prototypical Network to target few-shot and zero-shot applications. The network computes a prototype representation (an M-dimensional representation) of each class using an embedding function f��: RD�� RM, where �� is the learnable parameters. The prototype is given by ck�� RM which is calulated using the mean vector of the embedded support points in the class space. ckis given by:
Snell������[77]�������Ĺ���������һ�ֵ�ʱ���Ƚ����������磬��Ϊԭ�����磬�������few-shot �� zero-shotӦ�á�����ʹ��Ƕ�뺯��f�ȣ�RD�� RM����ÿ�����ԭ�ͱ�ʾ��Mά��ʾ�������Ц��ǿ�ѧϰ�IJ�����ԭ����ck��RM��������ʹ����ռ���Ƕ��֧�ŵ��ƽ����������ġ������¹�ʽ�ó���

where sk is the number of samples in true class k ����sk����ʵ���k�е�������
The authors have primarily used squared Euclidean distance (D) for their prototypical network where where D : RM��RM�� [0,+��]. For a querry x0the prototypical network, based on the softmax [107] performed on the distances to the prototypes in embedding space produces a distribution over the total range of classes using the embedding class meta-data vk. Code: https:// github.com/jakesnell/prototypical-networks
������Ҫʹ��ƽ��ŷ�Ͼ��루D����Ϊ���ǵ�ԭ�����磬����D:RM��RM�� [0,+��]. ����querry X0��ԭ��������ڶ�Ƕ��ռ��е�ԭ�͵ľ���ִ�е�softmax[107]��ʹ��Ƕ����Ԫ����vk������ܷ�Χ�ڲ����ֲ������룺https:// github.com/jakesnell/prototypical-networks

Fig. 3: Figure explaining the prototypical network for few-shot and zero-shot application, where ckare prototypes for few-shot learning application and vkis the meta-data. An embedding of query points for an image ? x is classified using a softmax function performed over the class function using squared Euclidean distance function. Image Source: [77] ������������������Ӧ�õ�ԭ�������ͼ������CKK��������ѧϰӦ�õ�ԭ�ͣ�vk��Ԫ���ݡ�ͼ��?x�IJ�ѯ���Ƕ��ʹ����ʹ��ƽ��ŷ����¾��뺯�����ຯ����ִ�е�softmax�������з��ࡣͼƬ��Դ��[77]
2.2.3 Learning in localization of realistic settings ��ʵ�����µĹ�һ��ѧϰ
Wertheimer et al. [83] proposes an incremental work on top of prototypical network [77] to target the realistic open world images involve thousands of different classes with subtle variations. They target the problems of heavy class imbalance, heavy tailored and fine-grained clutter recognition. Their work is incremental on the existing work of prototypical networks that results in significant increase in the performance without adding much complexity to the over network. They propose a new training approach to tackle the class imbalance problem which is based on top of leaveone-out cross validation. To tackle the clutter problem, they use an learner architecture which can efficiently localize and object before classifying them into various classes. To tackle the finegrain problem and to differentiate subtleties in an object, they use bilinear pooling [108], [109] to increase the representation power of the learner model. Using the combination of the three improvement techniques, Wertheimer et al. were able to double the results with respect to accuracy of prototypical networks on meta-iNat benchmark.
Wertheimer����[83]��ԭ������[77]�Ļ����������һ�������������������ʵ�Ŀ�������ͼ��ͼ���漰��ǧ����ͬ����𣬾���ϸ�ı仯�����ǵ�Ŀ�������ƽ�⡢�زü���ϸ�����Ӳ�ʶ�����⡣���ǵĹ�������ԭ����������й����Ļ����Ͻ��еģ���Щ�����ڲ��������縴���Ե������������������ܡ����������һ���µ�ѵ��������������ƽ�����⣬�÷�������һ��һ������֤��Ϊ�˽���������⣬����ʹ����һ��ѧϰ����ϵ�ṹ������ϵ�ṹ�����ڽ����Ƿ��ൽ��ͬ����֮ǰ��Ч�ض�λ��ʶ��Ϊ�˽����ϸ���Ⲣ����Ŀ���е�ϸ֮��������ʹ��˫���Գ�[108]��[109]������ѧϰ��ģ�͵ı�ʾ������Wertheimer���˽��ʹ�������ָĽ��������ܹ���meta iNat���Ͻ�ԭ������ľ������һ����
Cross Validation using Leave-one-Out Approach: To have a successful prototypical network which can recognise novel rare classes, it needs to be trained on a relatively great size of images belonging to the common class and on the few referenced images belonging to the rare novel class. To achieve this, either the batch size needs to be increased or reduce the number of referenced categories during the training. Increasing the batch size is not always an option due to the computational limitations, whereas reducing the novel referenced images can result in the model learning poorly and the center of each class becoming distorted. To overcome this, their approach uses cross validation based on leave-one-out approach.
ʹ��Leave-one-Out�������н�����֤��Ϊ����һ���ɹ���ԭ�������ܹ�ʶ���µ�ϡ���࣬��Ҫ��������ͨ��Ľϴ�ߴ��ͼ�������ϡ����������ο�ͼ�����ѵ����Ϊ��ʵ����һ�㣬��Ҫ��ѵ���ڼ��������δ�С����ٲο��������������ڼ������ƣ���������С��������һ��ѡ�������µIJο�ͼ����ܵ���ģ��ѧϰЧ�����ѣ�����ÿ��������Ķ���Ť����Ϊ�˿˷���һ�㣬���ǵķ���ʹ���˻��� leave-one-out�Ľ�����֤��
Let c be the entire set of classes and skis the number of samples in each class. vn,k is the feature vector of the nthsample in the cthcategory, the prototypes are generated in the following manner
��cΪ�����༯�ϣ�������ÿ�����е���������vn��k�ǵ� cge ����е�n������������������ԭ�Ͱ����·�ʽ����

Effective Localization: To distinguish relevant object from a clustered image is highly difficult when it is trained on a few images and their respective labels. To address this issue, the authors proposed to localize the object in the referenced image and the query image which can make the process of classification significantly better. They used two approaches to isolate the images: Unsupervised localization - where a category-agnostic learner model is internally developed on the Dtrain; and few-shot localization - where the images from Dtrain are used to generate bounding box on the Dtest.
��Ч��λ����������ͼ������Եı�ǩ����ѵ��ʱ�������Ŀ����ۼ�ͼ�����ֿ����Ƿdz����ѵġ�Ϊ�˽��������⣬��������ڲο�ͼ��Ͳ�ѯͼ���ж�λĿ�꣬�����ʹ����������Ը��á�����ʹ�������ַ���������ͼ���ල��λ������Dtrain���ڲ��������֪ѧϰ��ģ�ͣ�С������λ������������Dtrain��ͼ��������Dtest�����ɱ߽��
The procedure for both the localization techniques is same where a sub-module of localizer is used to classify the location of every object in the final 10 �� 10 feature map layer of the model and categorized as ��foreground�� and ��background�� predictions. A softmax function is applied on these prediction embeddings and using a L2 distance. The training is done end-to-end for both of the localization procedures. The localizer is trained and used only for the purpose of classification.
���ֶ�λ�����IJ�����ͬ������ʹ�ö�λ������ģ���ģ�����10��10������ͼ����ÿ��Ŀ���λ�ý��з��࣬���������Ϊ��ǰ�����͡�������Ԥ�⡣����ЩԤ��Ƕ��Ӧ��softmax��������ʹ��L2���롣���������ػ������ѵ�����Ƕ˵��˽��еġ���λ������ѵ���������ڷ���Ŀ�ġ�
Bilinear pooling: Techniques like fisher vectors [110] and others [111], [112], [113], [114] are used to increase the feature space F, and increase the fine-grain classification power of the models. These techniques are applied to the fully-connected layers or the classifier layers in a model which increases the model parameters and it complexity. The approach used by Wertheimer et al. of bilinear pooling [109] takes into account two feature maps and computes the cross variance amongst them and performs a pixel-wise product and then does average pooling on top of it. By doing so, they claim that no extra parameters are added to the network. Code: https://github.com/daviswer/fewshotlocal
˫���Ժϲ���ʹ��fisher����[110]������[111]��[112]��[113]��[114]�ȼ��������������ռ�F�������ģ�͵�ϸ���ȷ�����������Щ����Ӧ����ģ���е���ȫ���Ӳ��������㣬��������ģ�Ͳ������临���ԡ�Wertheimer����ʹ�õ�˫���Ժϲ�����[109]��������������ӳ�䣬��������֮��Ľ��淽���ִ�����ؼ��˻���Ȼ�������Ͻ���ƽ���ϲ���ͨ������������������û�ж���IJ������ӵ������С����룺https://github.com/daviswer/fewshotlocal
2.2.4 Learning for Semi-Supervised Classification
In this work, Ren et al. [79] propose a semi-supervised and novel extension to the prototypical networks to deal with scenarios where unlabelled data samples are available along with Dtrain samples and their respective labels can generate prototypes. As shown in Figure 4, they take into consideration two scenarios: one where the unlabelled data samples belong to the same set of classes c; and other where the unlabelled data samples belong to another set of classes called as distractor classes. In the semisupervised based few-shot learning approach the Dtrainconsists of a tuple (S, R) where (S) is the set of labelled samples and (R) is the set of unlabelled samples. (S) is the reference set of support set used in the prototypical networks. This set consists of various images and their respective labels
��������У�Ren����[79]����˶�ԭ������İ�ල����ӱ����չ���Դ���δ��ǵ���������������ѵ������һ����õij������������Ǹ��Եı�ǩ��������ԭ�͡���ͼ4��ʾ�����ǿ��������ֳ�����һ����δ��ǵ�������������ͬһ��c�ࣻ�Լ�����δ��ǵ���������������һ���Ϊ����������ࡣ�ڻ��ڰ�ල��С����ѧϰ�����У�Dtrain��Ԫ�飨S��R����ɣ����У�S���DZ������������R����δ�������������S�� ��ԭ��������ʹ�õ�֧�ּ��IJο������˼����ɸ���ͼ������Եı�ǩ���

Fig. 4: Figure explaining the semi-supervised few-shot learning setup. (S) and (R) are sets of labelled and unlabelled data samples respectively and the goal is to use these samples to generalize well on the query set (Q). The green plus sign indicates that the images in the distractor set that belong to the classes that of in the training set, whereas the ones indicated by red minus sign are the images in the distractor class that do not belong to classes in the training dataset. Source: [79] ˵����ලС����ѧϰ���õ�ͼ����S�� �ͣ�R���ֱ��Ǵ���ǩ��δ����ǩ��������������Ŀ����ʹ����Щ�����ڲ�ѯ����Q���Ͻ������õķ�������ɫ�Ӻű�ʾ�����O�е�ͼ������ѵ�����е��࣬����ɫ���ű�ʾ�������е�ͼ������ѵ�����ݼ��е��ࡣ������Դ��[79]
If the original prototypical networks discussed in [77] is considered, it can successfully generate prototypes ckfor the labelled set (S) but fails to generate prototypes ( ? ck) for the unlabelled set (R). The authors provide various techniques to process on the labelled set (S) and generate refined prototypes for the unlabelled (R) set. One the refined prototypes ( ? ck) for (R) are generated, the model is trained with the same loss function as used for the vanilla prototypical network (refer Equation 3) for the refined prototypes ( ? ck). After that each query is classified based on the distance function and the proximity of the query to the generated refined prototypes ( ? ck) using average negative log probability (refer Figure 6. The refined prototypes, which are generated by considering the samples from (R), are seen to be classified accurately.
�������[77]�����۵�ԭʼԭ�����磬�����Գɹ���Ϊ��Ǽ�����ԭ�ͣ�����Ϊδ��Ǽ���R������ԭ�ͣ�?ck���������ṩ�˸��ּ�����������Ǽ�����Ϊδ��Ǽ�����ϸ����ԭ�͡����ɣ�R����ϸ��ԭ�ͣ�?ck����ʹ����ϸ��ԭ�ͣ�?ck������ͨԭ�����磨�ο���ʽ3����ͬ����ʧ������ģ�ͽ���ѵ����֮���ݾ��뺯���Ͳ�ѯ�����ɵ��Ż�ԭ�ͣ�?ck���Ľӽ��̶ȣ�ʹ��ƽ�����������ʶ�ÿ����ѯ���з��ࣨ��ͼ6����ͨ�����ǣ�R���е��������ɵ��Ż�ԭ�ͱ���Ϊȷ���ࡣ

Fig. 6: Figure indicating the prototype clustering before and after refinement. Image Source: [79] ��ʾϸ��ǰ��ԭ�;����ͼ��ͼƬ��Դ��[79]
Technique using using soft k-means: In this approach, the prototype is looked as a separate cluster center and the refinement process tries to cluster locations to better fit the labelled and unlabelled samples. Once the (ck) are generated for the labelled samples and clusters are formed based on the distance between the prototypes and the refined prototypes. For the unlabelled samples, they are first partially assigned to the (ck) clusters based based on the distance between the (ck) and ( ? ck). Finally, refined prototypes are obtained by incorporating the unlabelled samples. This approach is used in cases where the unlabelled image belongs to one of the class in labelled set.
ʹ�� soft k-means�ļ����������ַ����У�ԭ�ͱ���Ϊһ�������ľ������ģ�ϸ��������ͼ��λ�ý��о��࣬�Ը��õ���ϱ�Ǻ�δ��ǵ�������һ��Ϊ������������ˣ�ck��������ԭ�ͺ��Ż�ԭ��֮��ľ����γɴء�����δ��ǵ����������ȸ��ݣ�ck���ͣ�?ck��֮��ľ��뽫���Dz��ַ������ck���ء����ͨ���ϲ�δ��ǵ��������ϸ����ԭ�͡����ַ�������δ���ͼ�����ڱ�Ǽ���ij����������
Technique using using soft k-means with distractor class: The soft k-means approach does not perform on the distractor class (R), where the unlabelled samples does not necessarily are from the range of classes. The distractor class images can be harmful when it comes to the k-means approach as the ( ? ck) prototypes have to be adjusted to the (ck) clusters. To overcome this, the authors suggest to add an additional cluster which can capture the distractors and avoid the unnecessary population of the (ck) clusters.
ʹ�� soft k-means������ļ����� soft k-means�����������ڸ����ࣨR��������δ��ǵ�������һ���������Χ�����漰��k-means����ʱ����������ͼ��������к��ģ���Ϊ��?ck��ԭ�ͱ����������ck���ء�Ϊ�˿˷�������⣬���߽�������һ������ļ�Ⱥ�������Բ�������ﲢ���ⲻ��Ҫ�ģ�ck����Ⱥ��
Technique using using soft k-means and masking: The soft kmeans with distractor class technique works better for distractor class where all the samples belong to one class. But this is was to simplistic and in real world, it is most unlikely to have a distractor class with samples belonging to just one class. To overcome this, the authors consider that the examples are not within some area of any (ck) clusters generated from the labelled data samples. This is achieved using the masking procedure. The high-level goal is to mask more the samples which are further away from a prototype and mask less the ones which are closer. Code: https://github.com/ xinzheli1217/learning-to-self-train
ʹ��soft k-means���ڱεļ�����soft k-means�������༼�����ڸ�������Ч�����ã���Ϊ��������������һ���ࡣ����̫���ˣ�����ʵ�����У��������һ������ֻ����һ����ĸ������ࡣΪ�˿˷���һ�㣬������Ϊ��ʵ�������ɱ�������������ɵ��κΣ�CK���ص�ijЩ�����ڡ�����ͨ���ڱγ���ʵ�ֵġ��߲�ε�Ŀ�����ڸǸ���Զ��ԭ�͵������������ڸǸ��ӽ�ԭ�͵����������룺https://github.com/ xinzheli1217/learning-to-self-train
2.2.5 T ransferable Prototypical Networks
The work done by Yingwei et al. [82] is based on the remoulding the vanilla prototypical network to Transferable Prototypical Network (TPN) which can target the scenario of unlabelled data samples by jointly bridging the domain. The classifiers are constructed with target data which does not have labels along with source data and its respective labels. Initially the transferable prototypical networks classifiers learn from the source data and then directly predict the pseudo labels of the target data which does not have any labels. This results in the generation of two prototypical network based classifiers which are target-only and source-only. TPN training is done to simultaneously reduce the discrepancy at sample level and class level while predicting the correct sample class. They match the prototypes generated from each class and reduce the class-level discrepancy. Also, by enforcing the score distributions over classes of each sample in different domain, the sample-level discrepancy is reduced.
Yingwei����[82]�����Ĺ������ڽ���ͨԭ���������Ϊ��ת��ԭ�����磨TPN�������������ͨ�������Ž��������δ������������ij�������������û�б�ǩ��Ŀ�������Լ�Դ���ݼ�����Եı�ǩ���ɡ���ת��ԭ��������������ȴ�Դ������ѧϰ��Ȼ��ֱ��Ԥ��û���κα�ǩ��Ŀ�����ݵ�α��ǩ����Ͳ��������ֵ��͵Ļ�������ķ����������Ƿֱ��Ǵ�Ŀ��������ʹ�Դ��������TPNѵ����Ϊ����Ԥ����ȷ����������ͬʱ��ͬʱ����������������IJ��졣����ƥ���ÿ�������ɵ�ԭ�ͣ��������༶��IJ��졣���⣬ͨ���ڲ�ͬ�����ÿ�������������ʵʩ�����ֲ�������ˮƽ����Ҳ�õ��˼��١�
As illustrated in Figure 5, firstly, the TPN model allocates a ��pseudo�� label to each of the target class. This is achieved by matching prototypes of each samples from the target class to the nearest prototype from the source data samples. Afterwards, prototypes are generated based on source-only, target-only and source-target samples. Based on a general purpose adaptation, these prototypes (generated from samples in each domain in all the classes) are pushed to the closest domain in the embedding space. TPN simultaneously aligns the distribution of scores generated by the prototypes of all the samples in various domains. This aligning is performed by doing the task-specific adaptation of the data samples. The entire TPN network is end-to-end trained by reducing the classification loss on the source data along with the general-purpose and task-specific adaptation
��ͼ5��ʾ�����ȣ�TPNģ��Ϊÿ��Ŀ�������һ����α����ǩ������ͨ����Ŀ������ÿ��������ԭ����Դ���������������ԭ�ͽ���ƥ����ʵ�ֵġ�Ȼ���ڽ�Դ����Ŀ���Դ-Ŀ����������ԭ�͡�����ͨ�õ�����Ӧ����Щԭ�ͣ�����������ÿ�����е��������ɣ������͵�Ƕ��ռ����������TPNͬʱ�����˸�����������������ԭ�����ɵķ����ֲ������ֶ�����ͨ�����������������ض������������Ӧ��ִ�еġ�����TPN����ͨ������Դ�����ϵķ��ඪʧ�Լ�ͨ�ú��ض����������Ӧ���ж˵���ѵ��
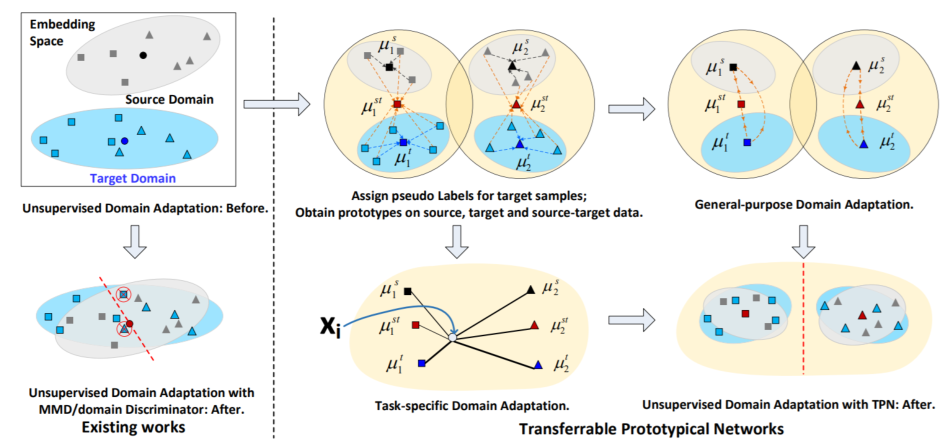
Fig. 5: The difference between the previous unsupervised domain adaption models like MMD [115] and domain discriminator [116]. Compared to these techniques, Transferable Prototypical Network (TPN) can target the scenario of unlabelled data samples by jointly bridging the domain gap and the classifiers are constructed with unlabeled target data and labeled source data. Image Source: [82] MMD[115]���������[116]����ǰ���ල������Ӧģ��֮��IJ��졣����Щ������ȣ���ת��ԭ�����磨transportable prototypic Network��TPN������ͨ�������Ž����϶�����δ������������ij��������ҷ�������δ��ǵ�Ŀ�����ݺͱ�ǵ�Դ���ݹ��ɡ�ͼƬ��Դ��[82]
2.2.6 Matching Network ƥ������
The work done by Vinyals et al. [75] is inspired from metric learning techniques [117], [118], [119], [120], memory networks [121], [122], pointer networks [123] and augmented neural networks [124]. The matching network��s novelty was two-fold: one, a novel training method tailored for one-shot learning applications; two, introduce a novel network called matching network, which is based on the attention mechanism [125], [126]. Code: https://github.com/AntreasAntoniou/MatchingNetworks
Vinyals����[75]�����Ĺ����ܵ�����ѧϰ����[117]��[118]��[119]��[120]����������[121]��[122]��ָ������[123]����ǿ������[124]��������ƥ���������ӱ�����������棺һ�����һ����ѧϰӦ�õ���ӱѵ���������ڶ�������һ�ֻ���ע����Ƶ��������磬��Ϊƥ������[125]��[126]�����룺https://github.com/AntreasAntoniou/MatchingNetworks
In matching network, the use of fully differentiable attention mechanism is done to read and/or write from the external memory. The external memory stores important information or knowledge which is pertinent to the task at hand. The essence of matching networks is, without any modifications to the network it can generate accurate labels for the data samples Dtest. The matching network maps data samples and their respective label in (S), where (S) = {(xn, yn}k, is mapped to a classifier cs(x0) which can define a probability distribution over possible output categories y0, given an input x0from the Dtest. When (S) is mapped to cs(x0), the probability is given by:
��ƥ�������У�ʹ����ȫ��ע����ƴ��ⲿ�洢�����ж�ȡ��/��д�롣�ⲿ�洢���洢����ͷ������ص���Ҫ��Ϣ��֪ʶ��ƥ������ı����ǣ��ڲ������������£�������Ϊ��������Dtest����ȷ�ı�ǩ��ƥ�����罫��������������Եı�ǩӳ�䵽��S���У�����![]() ��ӳ�䵽������cs��x�������÷��������Զ�������Dtest������x0�Ŀ���������y'�ϵĸ��ʷֲ�������S��ӳ�䵽cs��x'��ʱ����������ʽ������
��ӳ�䵽������cs��x�������÷��������Զ�������Dtest������x0�Ŀ���������y'�ϵĸ��ʷֲ�������S��ӳ�䵽cs��x'��ʱ����������ʽ������

where, a is the attention mechanism. So when a small support set (Q) from Dtestis provided to the one-shot learning model, the distribution of the output classes y0is calculated based on:
���У�a��ע����ơ���ˣ�����Dtest��һ����ѧϰģ���ṩһ��С��֧�ּ���Q��ʱ�������Y0�ķֲ��ǻ��ڣ�

2.2.7 Task dependent adaptive metric learning �����������Ӧ����ѧϰ
The work done by Oreshkin [88] focuses on a novel technique of metric scaling which improves the performance of few-shot applications. Metric training is trying to learn a suitable distance function or a similarly measure (example: cosine or euclidean) as shown above in the work done by Snell et al. [77] and Vinyals et al. [75] in prototypical network and matching network, respectively, which is loosely based on the work done by Perez et al. in [127], [128], [129]. They claim that the improvement in the performance of few-shot techniques can be directed key to using different scaling methods and select a particular one based on the softmax from the pool of metrics. They propose a learnable parameter which can make the model understand the best possible metric from the collection of metrics. They also propose to use task conditioning where the embedding generated are not based on a general embedding function but the functions varies with different tasks. Code: https://github.com/ElementAI/TADAM
Oreshkin[88]�����Ĺ���������һ���µĶ������ż������ü��������С����Ӧ�õ����ܡ�����ѵ������ͼѧϰһ�����ʵľ��뺯�������ƵĶ��������磺���һ�ŷ����£�����Snell����[77]��Vinyals����[75]�ֱ���ԭ�������ƥ�������������Ĺ�����ʾ������»���Perez������[127]��[128]��[129]�������Ĺ������������ƣ�С�����������ܵ���߿���ͨ��ʹ�ò�ͬ�����ŷ�����ʵ�֣������ڶ������е�softmaxѡ��һ���ض������ŷ��������������һ����ѧϰ�IJ������ò�������ʹģ�ʹӶ���������������ѿ��ܶ��������ǻ�����ʹ�������������������ɵ�Ƕ�벻�ǻ���һ���Ƕ�뺯�������Ǻ����治ͬ������仯�����룺https://github.com/ElementAI/TADAM
2.2.8 Representative-based metric learning
The work done by Karlinsky et al. in [81] introduces an effective approach for few-shot object classification and detection using a technique based on Distance Metric Learning (DML). Their training is inspired on an end-to-end manner where the network simultaneously trains and learns the network parameters, the embedding space, the feature space and the representative vectors. In their work, every class is represented by a mixture model combined with multiple modes. The center of each of these modes is called as a representative vector. Representative vectors will vary along with their respective class. Code: https://github.com/jshtok/RepMet
Karlinsky������[81]�������Ĺ���������һ��ʹ�û��ھ������ѧϰ��DML���ļ�������С����Ŀ�����ͼ�����Ч���������ǵ�ѵ�����Զ˵��˵ķ�ʽ���еģ�����ͬʱѵ����ѧϰ���������Ƕ��ռ䡢�����ռ�ʹ��������������ǵĹ����У�ÿ�����һ�����ģ�ͺͶ��ģʽ��ʾ��ÿ��ģʽ�����ij�Ϊ����������������������������Ե������仯�����룺https://github.com/jshtok/RepMet
2.2.9 T ask-Aware Feature Embedding
The work done by Wang et al. [80] focuses on the construction of feature embeddings that are set for a particular task. To achieve their goal, they use a novel model called TAFE-Net (TaskAware Feature Embedding Network) which has two modules or subnetworks: meta learner; followed by a prediction network. Depending upon the task, the meta-learner modules learns and produces features for a particular task and the prediction layer adjusts to the new task based on the features generated by meta network.
Wang����[80]�����Ĺ����ص���Ϊ�ض���������Ƕ�롣Ϊ��ʵ�����ǵ�Ŀ�꣬����ʹ����һ�ֳ�ΪTAFE���磨TaskAware Feature Embedded Network�������֪����Ƕ�����磩����ģ�ͣ���ģ��������ģ��������磺Ԫѧϰ����Ȼ����Ԥ�����硣��������Ԫѧϰ��ģ��ѧϰ�������ض������������Ԥ������Ԫ�������ɵ���������������
As illustrated in Figure 7, the TAFE-Net generates the TAFEs from the generic image. This is achieved through the meta learner module which is able to generate the feature representation of the different layers in the classification module. The generated weights for these layers are transformed into a task-specific low dimension embedding whereas the high dimension weights are shared among all the global tasks thus reducing the overall complexity. The classifier module used is the same irrespective of the intended task and the input to the classifier are the TAFEs generated by the meta-learner module. Code: https://github.com/ucbdrive/tafe-net
��ͼ7��ʾ��TAFE�����ͨ��ͼ������TAFE������ͨ��Ԫѧϰ��ģ��ʵ�ֵģ���ģ���ܹ����ɷ���ģ���в�ͬ���������ʾ��Ϊ��Щ�����ɵ�Ȩ�ر�ת��Ϊ�ض�������ĵ�άǶ�룬����άȨ��������ȫ������֮�乲�����Ӷ����������帴���ԡ�����Ԥ��������ʲô����ʹ�õķ�����ģ�鶼����ͬ�ģ���������������Ԫѧϰ��ģ�����ɵ�TAFE�����룺https://github.com/ucbdrive/tafe-net

Fig. 7: The design of the TAFE-Net. TAFE-Net has two modules, meta learner and a prediction network. Depending upon the task, the meta-learner modules learns and produces features for a particular task and the prediction layer adjusts to the new task based on the features generated by meta network. Image Source: [80] TAFE�������ơ�TAFE����������ģ�飬Ԫѧϰ����Ԥ�����硣��������Ԫѧϰ��ģ��ѧϰ�������ض������������Ԥ������Ԫ�������ɵ���������������ͼƬ��Դ��[80]
2.3 Optimization-Based Techniques �����Ż��ļ���
The techniques discussed in the following section involve the use of an meta-optimizer which can generalize better to novel tasks. An external memory network, Long Short-Term Memory (LSTM) [130], a recurrent neural network (RNN), a holistic gradient descent optimizer, etc. are various types of techniques which are used as a meta-optimizer during the initial training phase. The goal of the meta-optimizer is to learns from various tasks and generalize to novel tasks.
��һ�����۵ļ����漰��Ԫ�Ż�����ʹ�ã����Ż������Ը��õ��ƹ㵽�������ⲿ�������硢���ڶ��ڼ��䣨LSTM��[130]���ݹ������磨RNN���������ݶ��½��Ż������Ǹ������͵ļ������ڳ�ʼѵ��������Ԫ�Ż�����Ԫ�Ż�����Ŀ���ǴӸ���������ѧϰ���ƹ㵽������
2.3.1 LSTM-based Meta Learner
The work done by Ravi et al. in [76] is based on a Long ShortTerm Memory (LSTM) network acting as a meta-learner model to generalize and learn the optimal optimization algorithm which can be used to trainer a classifier from another model which has an application towards few-shot regime. Training of most deep neural networks is based on some standard gradient descent algorithm for optimizing the network towards a specific task
Ravi et al.��[76]�������Ĺ�������һ����ΪԪѧϰ��ģ�͵ij���ʱ���䣨LSTM�����磬���ƹ��ѧϰ����Ż��㷨�����㷨������ѵ����һ��ģ���еķ���������ģ��������С���������������������ѵ��������һЩ�����ݶ��½��㷨����������ض������Ż�����

where at tthiteration, �� is neural network parameters, ��tis the learning rate, Ltis the loss and ��t?1Ltis the gradient of the loss.
���У���t����ʱ���������������������ѧϰ�ʣ�lti����ʧ����t?������ʧ���ݶȡ�
The meta-learner LSTM can learn and adapt its rules for training the model. The initial state of the LSTM cell is set to ��t and the candidate cell state is set to the gradient of the loss which is ��t?1Ltwhich can determine how valuable the information of the gradient is. They determine the parameters for ntand ft. The meta-learner takes these values and finds the best possible values which can be used during the training period. ntand ftare given by:
Ԫѧϰ��LSTM����ѧϰ�������������ѵ��ģ�͡�LSTM��Ԫ�ij�ʼ״̬����Ϊ��t����ѡ��Ԫ״̬����Ϊ��ʧ�ݶȦ�t?1�����ȷ���ݶ���Ϣ�ļ�ֵ������ȷ��NTA��ft�IJ�����Ԫѧϰ��ȡ��Щֵ�����ҵ�������ѵ�ڼ�ʹ�õ���ѿ���ֵ��N��F��������Ա������

where W indicates the weights and B indicates the biases of the overall model. Based on the nt and ft information, the LSTM can learn quickly without diverging. Code: https://github. com/markdtw/meta-learning-lstm-pytorch
����W��ʾȨ�أ�B��ʾ����ģ�͵�ƫ�����nt��ft��Ϣ��LSTM���Կ���ѧϰ������ɢ�����룺https://github.com/markdtw/meta-learning lstm-pytorch
2.3.2 Memory Augmented Networks based Learning ���ڼ�����ǿ�����ѧϰ
The work done by Santoro et al. in [84] uses a Neural Turing Machine (NTM) [131] which they consider as a fully differentiable implementation of Memory Augmented Neural Network (MANN). They use a LSTM as the controller which can communicate with the external memory by using a variety of read and write heads. The speed of information exchange between the model and the external memory is rapid as they external memory stores the vector representation which is been moved in or moved out of the memory because of which NTM is a great option for the application of meta-learning and n-shot predictions. Once the NTM learns how to strategically place the vector representation of the data to be later used for making prediction for the data samples in Dtest. Code: https://github.com/vineetjain96/one-shot-mann
ɣ��������[84 ]�������Ĺ���ʹ����һ����ͼ�������NTM��[131 ]��������Ϊ����һ����ȫ����չ�ļ�����ǿ�����磨MN����ʵ�֡�����ʹ��LSTM��Ϊ��������ͨ��ʹ�ø��ֶ�д��ͷ���ⲿ�洢��ͨ�š�ģ�ͺ��ⲿ�洢��֮�����Ϣ�����ٶȺܿ죬��Ϊ�ⲿ�洢���洢����������Ƴ��洢����������ʾ����ΪNTM��Ԫѧϰ��n-shotԤ��Ӧ�õ�һ���ܺõ�ѡ��һ��NTMѧ����β����Եط������ݵ�������ʾ���Ա��Ժ�������Dtest�ж�������������Ԥ�⡣���룺https://github.com/vineetjain96/one-shot-mann
2.3.3 Model Agnostic based Meta Learning ����ģ�Ͳ���֪��Ԫѧϰ
The work done by Finn et al. [85] proposes to train the weights of a given neural network in a way that, the network can generalize to novel tasks with just few samples. Their approach provided the modern performances on the novel tasks along with quick fine-tuning. Their model has produced good results in the reinforcement learning domain as well, where they achieved quick fine-tuning for the gradient based policies. Their mechanism is able to quickly tune the weights of a model so that it can generalize and adapt quickly to novel tasks. The idea behind their approach was based on the fact that some internal parameters are more transferable than others. For example, in a CNN, the higher levels of convolution can learn features which can be applicable to a variety of tasks irrespective of the intended task. The authors exploit this fact and using a gradient based finetuning, they show that the model can rapidly learn and progress onto novel tasks without worrying about overfitting. Algorithm 1 depicts the overall learning process of the MAML approach. Code: https://github.com/cbfinn/maml
Finn����[85]�����Ĺ��������һ��ѵ������������Ȩ�صķ�����������������ƹ㵽ֻ���������������������ǵķ����ṩ����������ִ������Լ������������ǵ�ģ����ǿ��ѧϰ����Ҳȡ�������õ�Ч����ʵ���˻����ݶȲ��ԵĿ����������ǵĻ����ܹ����ٵ���ģ�͵�Ȩ�أ�ʹ���ܹ�������������Ӧ���������ǵķ���������뷨�ǻ�������һ����ʵ����һЩ�ڲ���������������������ת�ơ����磬��CNN�У�������ľ�������ѧϰ�����ڸ������������������Ԥ�������ء�����������һ��ʵ����ʹ�û����ݶȵ��������DZ�����ģ�Ϳ��Կ���ѧϰ���������������ص��Ĺ�����ϡ��㷨1������MAML����������ѧϰ���̡����룺https://github.com/cbfinn/maml
2.3.4 Task-Agnostic Meta-Learning
The work done by Jamal et al. in [90] proposes the use of a task-agnostic learning approach. The model, trained initially on a dataset with a range of tasks, can be biased towards few tasks especially when the novel tasks and the trained have some disparities, which can result in the model to be over-performing to few of the tasks that can prevent the meta-learning to learn better to the novel tasks. To overcome this problem, the authors use an unbiased learner able to learn better on the novel tasks. The authors provide two variants for the task-agnostic meta-learner (TAML): Entropy-Maximization/Reduction (EMR-TAML); and Inequality Minimization (IM-TAML). In EMR-TAML, thus avoid the model to overfit to the novel tasks. The authors use a random guess with an equal probability over the predicted labels, which results in biased predictions towards the novel tasks. This is indicated by maximum entropy over the model parameters (��) and results in the initial model having a large entropy over the predicted labels. The entropy is given in Equation 10. Alternatively, they also propose to minimize the entropy (HTi(f��i)) resulting in higher confidence levels towards the predicted labels after the model parameters are updated from �� to ��iin the process to find the optimum ��.
Jamal������[90]�������Ĺ�������ʹ��������ѧϰ����������ڰ���һϵ����������ݼ���ѵ����ģ�Ϳ���ƫ�������������ر��ǵ��������ѵ�����������һЩ����ʱ������ܵ���ģ����ִ���������Ӷ�����Ԫѧϰ���õ�ѧϰ������Ϊ�˿˷�������⣬����ʹ����һ���ܹ����������и��õ�ѧϰ����ƫ��ѧϰ��������Ϊ����֪Ԫѧϰ����TAML���ṩ�����ֱ��壺�����/Լ��EMR-TAML�����Ͳ���ʽ��С����IM-TAML������EMR-TAML�У�����ģ������Ӧ������������Ԥ���ǩ��ʹ�õȸ��ʵ�����²⣬��¶��������Ԥ����ƫ�����ģ�Ͳ������ȣ��ϵ�����ر�ʾ�������³�ʼģ����Ԥ���ǩ�Ͼ��нϴ���ء�����10�������ء����ߣ����ǻ�������С���أ�HTi��f��i���������ҵ���ѦȵĹ����У���ģ�Ͳ����Ӧȸ���Ϊ��ii��Ԥ���ǩ�������ߵ�����ˮƽ��

To nullify the biased effect of a model to any particular task, they authors use an approach based on ��economic inequality�� [132] to measure the amount of task being biased. The approach of economic inequality is inspired from the statistics family, where the loss for each task Tiof the initial model is looked as an input for the task. Afterwards, the TAML minimizes this loss inequality for multiple tasks, resulting in better meta-learning.
Ϊ������ģ�Ͷ��κ��ض������ƫ��ЧӦ����������ʹ����һ�ֻ��ڡ����ò�ƽ�ȡ��ķ���[132]������ƫ����������������ò�ƽ�ȵķ�����ͳ��ѧ��������������г�ʼģ�͵�ÿ���������ʧ����Ϊ��������롣֮��TAML����������������ʧ����ʽ��С�����Ӷ�ʵ�ָ��õ�Ԫѧϰ��

2.3.5 Meta-SGD
The work done by Li et al. in [86] proposes a SGD like optimizer called Meta-SGD which can easily and quickly adapt to novel tasks and is applicable for supervised learning (classification, regression, etc.) and reinforcement learning [44], [133], [134], [135] domain. Meta-SGD is similar to Meta-Learning LSTM [76] in terms of easy to implement, conceptually simple, easy to train, and can achieve better performance than Meta-Learning LSTM. Experimental results show that Meta-SGD does indeed outperform MAML approach.
Li������[86]�������Ĺ��������һ������SGD���Ż�������ΪԪSGD�����Ż����������ɿ��ٵ���Ӧ�����������ڼලѧϰ�����ࡢ�ع�ȣ���ǿ��ѧϰ[44]��[133]��[134]��[135]����Meta SGD��Meta Learning LSTM[76]������ʵʩ�����������ѵ���������ƣ����ҿ���ʵ�ֱ�Meta Learning LSTM���õ����ܡ�ʵ����������ԪSGDȷʵ����MAML������
Figure 9 ilustrates the overall learning procedure of the MetaSGD. The inspiration is based on a meta-learner, where the metalearner can generalize from a range of different tasks and can generalize better to a novel task. The learning in Meta-SGD is based on two steps: One, where the meta-learner gradually learns on the different tasks in the meta-space (��, ��); two, where based on the feedback of the meta-learner the learning approach of the meta-learner is evolved in the learning space. Code: https://github. com/foolyc/Meta-SGD
ͼ9չʾ��MetaSGD������ѧϰ���̡������Դ��Ԫѧϰ����Ԫѧϰ�����Դ�һϵ�в�ͬ�������и��������ҿ��Ը��õظ���Ϊһ��������ԪSGD�е�ѧϰ��Ϊ�������裺��һ����Ԫѧϰ����Ԫ�ռ䣨�ȣ���������ѧϰ��ͬ�����ڶ�������Ԫѧϰ�ߵķ�����Ԫѧϰ�ߵ�ѧϰ������ѧϰ�ռ��н��������룺https://github. com/foolyc/Meta-SGD

Fig. 9: The overview of the Meta-SGD learning process. The metaSGD which can quickly adapt to novel tasks and is applicable for supervised reinforcement learning domain. Image Source: [86] ԪSGDѧϰ���̵ĸ�����metaSGD�ܿ�����Ӧ�������������мලǿ��ѧϰ����ͼƬ��Դ��[86]
2.3.6 Learning to Learn in the Concept Space �ڸ���ռ���ѧϰ
The work done by Zhou et al. in [87] incorporates the representation power of deep learning into the task of meta learning. As illustrated from Figure 8, their approach includes three sub-modules: a concept generator G; a meta-learner T ; and a concept discriminator D. The concept generator is a deep neural network (e.g. ResNet, Inception, VGG Net) which extracts features from the input images, the meta-learner learns on these extracted features and the concept discriminator (e.g SVM, DNN, fully connected layers, etc.) differentiates between the features to recognize different images. The main goal in this approach is to train the concept generator in parallel with the meta-learner on a series similar tasks, which they claim to improve the performance of a vanilla metalearner. (Deep Meta-Learning) DEML in combination with several other techniques (like Matching Network [75], MAML [85], MetaSGD [86]) has shown to outperform the then best results for the n-shot learning problem.
Zhou������[87]�������Ĺ��������ѧϰ�ı�������������Ԫѧϰ�����С���ͼ8��ʾ�����ǵķ�������������ģ�飺����������G��Ԫѧϰ��T���������D��������������һ����������磨����ResNet��Inception��VGG���磩����������ͼ������ȡ������Ԫѧϰ��ѧϰ��Щ��ȡ���������������������SVM��DNN����ȫ���Ӳ�ȣ�����������ʶ��ͬ��ͼ�����ַ�������ҪĿ������һϵ�����Ƶ�������ѵ��������������Ԫѧϰ�߲��У�����������Щ����������ѧϰ�ߵı��֡������Ԫѧϰ��DEML���������ּ�������ƥ������[75]��MAML[85]��MetaSGD[86]���Ľ�ϱ���������n-shotѧϰ���⣬��������ڵ�ʱ��õĽ����

Fig. 8: The overview of the deep meta-learner. The network consists of three sub-modules: a concept generator G; a meta-learner T ; and a concept discriminator D. The main objective is to train the concept generator in parallel with the meta-learner on a series similar tasks, through which the performance of a vanilla meta-learner is enhanced. Image Source: [87] ���Ԫѧϰ����������������������ģ����ɣ�����������G��Ԫѧϰ��T�����������D����ҪĿ����ѵ��������������Ԫѧϰ���������һϵ���������Ӷ������ͨԪѧϰ����Ч�ʡ�ͼƬ��Դ��[87]
The goal is to minimize joint expectation (J), of the meta learning loss LT(��T, ��G) and the discriminator loss L(x,y)(��D, ��G) of the labelled samples (x, y) in Dtrain
Ŀ������С��Dtrain�б��������x��y����Ԫѧϰ��ʧLT����T����G���ͼ�������ʧL��x��y������D����G��������������J��
2.3.7 ?-encoder
The research done by Schwartz et al. in [89] proposes the use of an effective and comparatively easy approach for the one-shot and few-shot learning settings where they build upon a modified auto-encoder calling it ?-encoder. This ?-encoder can generalize/predict novel tasks based on exposure to few samples from those tasks. The ?s are the transferable intra-class parameters. The classifier used is able learn how to extract these ?s, and at the same time also transfers the ?s towards the prediction of novel samples. Code available at https://github.com/EliSchwartz/ DeltaEncoder
Schwartz et al.��[89]���������о������һ����Ч����Լķ��������ڵ��κ��ٴε�ѧϰ���ã������������У����ǽ�����һ���Ĺ����Զ���������?-����������?-���������Ի��ڶ�������Щ��������������ı�¶������/Ԥ�����������?s�ǿ�ת�Ƶ����ڲ�����ʹ�õķ������ܹ�ѧϰ�����ȡ��Щ��Ϣ?s�� ͬʱҲת����?���Ƕ���������Ԥ�⡣����https://github.com/EliSchwartz/DeltaEncoder
2.4 Semantic-Based Techniques
This section, discusses the semantic-based techniques, in which the semantics is included along with the samples to learn and generalize better to novel tasks. Semantic-based techniques are used more popularly for zero-shot learning (ZSL) settings. The inspiration behind this approach is that, often an adult is accompanied, when pointing out a new thing to a child, to make the association. The information or pointing out of an adult can be compared as a semantic knowledge which helps the child learn novel classes. In traditional zero-shot learning settings, either, the semantics and the data are mapped to a common embedding space [138], or, the semantics are mapped to the data or vice-versa [59], [139].
���ڽ����ۻ�������ļ��������а��������ʾ�����Ա���õ�ѧϰ����������������ļ������㷺�������㾵ͷѧϰ��ZSL�����á����ַ������������ǣ�������������ָ��һ��������ʱ��ͨ����������飬���������뵽����������˵���Ϣ��ָ�������Ϊһ������֪ʶ���бȽϣ���������ѧϰ������ڴ�ͳ��������ѧϰ�����У����������ӳ�䵽����Ƕ��ռ�[138]����������ӳ�䵽���ݣ���֮��Ȼ[59]��[139]��

2.4.1 Learning with Multiple Semantics ��������ѧϰ
Schwartz [92] presents an incremental work to few-shot learning techniques discussed in [140], where they incorporate additional semantic information that can help the learning process to be more effective. They propose that by combining multiple highlevel semantics like natural language description, category labels, and attributes. They split the training into two stages: Phase one, where the train the CNN backbone of the network from scratch using the labelled samples. They, however, believe that a pretrained task specific CNN model fine-tuned to the labelled dataset gives much better performance rather than training it from scratch; Phase two, where the linear classifier is replaced by MLP (multilayer Perceptron), freezing all the previous layers. The MLP is able to generate ��semantic prototypes�� which are then added up to the semantic branches as shown in Figure 10.
Schwartz[92]������[140]�����۵�С���������������������������ǰ����˶����������Ϣ��������ѧϰ���̸�����Ч�����������ͨ����϶��ָ����壬����Ȼ��������������ǩ�����ԡ����ǽ�ѵ����Ϊ�����Σ���һ�Σ�ʹ�ñ�ǵ�������ͷ��ʼѵ�������CNN���ɡ�Ȼ�����������ţ�һ��Ԥ��ѵ�����ض��������CNNģ�ͣ����������ܹ��ṩ���õ����ܣ������Ǵ�ͷ��ʼѵ�����ڶ��Σ����Է�������MLP������֪����ȡ������������֮ǰ�IJ㡣MLP�ܹ����ɡ�����ԭ�͡���Ȼ�������ӵ������֧�У���ͼ10��ʾ��

Fig. 10: The overview of the multiple semantics method where they include various high-level information like natural language, category labels, and attributes. They split the training into two stages: Phase one, where the train the CNN backbone of the network from scratch using the labelled samples. Image Source: [92] �����巽���ĸ��������а������ָ���Ϣ������Ȼ���ԡ�����ǩ�����ԡ����ǽ���ѵ��Ϊ�����Σ���һ�Σ�ʹ�ñ�ǵ�������ͷ��ʼ��ѵ�����CNN���ɡ�ͼƬ��Դ��[92]
2.4.2 Learning via Aligned Variational Autoencoders (VAE)
The work done by Schonfeld et al. [93] is incremental to the feature generation technique where a model shares a latent space of the image embeddings and the respective class embeddings. The shared latent space is learned by variational autoencoders (V AE) [141] which are modality specific. They evaluated the model on several benchmark datasets and claimed that their model is state-of-the-art for generalized zero-shot learning and few-shot learning techniques. Code: https://github.com/edgarschnfld/CADA-VAE-PyTorch [93]
Schonfeld����[93]�����Ĺ����Ƕ��������ɼ����ĸĽ�������ģ����ͼ��Ƕ�����Ӧ��Ƕ���DZ�ڿռ䡣������DZ�ڿռ���ģ̬�ض��ı���Զ���������V AE��[141]ѧϰ�������ڼ��������ݼ��϶�ģ�ͽ��������������������ǵ�ģ���ǹ���������ѧϰ��������ѧϰ����������ģ�͡����룺https://github.com/edgarschnfld/CADA-VAE-PyTorch [93]
2.4.3 Learning by Knowledge T ransfer With Class Hierarchy
Li et al. in [94] propose a large-scale model where the learnt features are transferable between the class hierarchy and can encode the semantic relation between the source and target class, respectively. They claim that their model is able to outperform the then state-of-the-art approach on a large scale zero-shot learning problem and can also be extended to few-shot learning applications. In high level, the prior knowledge they use is the semantic relation between the source classes and target classes and they claim that by transferring the feature embedding of the source class can help in predicting the target class. Code: https://github.com/tiangeluo/fsl-hierarchy
Li������[94]�������һ�����ģģ�ͣ��ڸ�ģ���У�ѧϰ���������������νṹ֮��ת�ƣ����ҿ��Էֱ����Դ���Ŀ����֮��������ϵ���������ƣ����ǵ�ģ���ܹ��ڴ��ģ������ѧϰ���������ڵ�ʱ���Ƚ��ķ��������һ�������չ��������ѧϰӦ�á��ڸ߲㣬����ʹ�õ�����֪ʶ��Դ���Ŀ����֮��������ϵ����������ͨ������Դ�������Ƕ�������Ԥ��Ŀ���ࡣ���룺https://github.com/tiangeluo/fsl-hierarchy
3 DISCUSSION AND FUTURE DIRECTION
This section presents the different techniques used and compare their performance on various benchmarks and datasets. For testing of these techniques, the two most commonly used benchmark datasets: Omniglot and MiniImageNet. Omniglot dataset contain 1623 various handwritten characters from various alphabets. Amazon��s Mechanical Turk was used by 20 different people to online draw these 1623 various characters. Omniglot is similar to MNIST dataset with respect to the complexity of the images. On the 13 other hand, the much complicated, MiniImageNet is a subset of the ImageNet dataset [142]2. The MiniImageNet dataset contains images of size 84 �� 84 which belong to randomly selected 100 output categories, with each category having 600 images, i.e. a total of 6000 images. The standard training procedure in a 5-way settings is to have 1 or 5 samples (or it can be any number of samples in between 1 and 10) for each of the 5 output classes in the support set. ( therefore it is called as 5-way) Out of the 100, 64 categories are used for training, 16 for validation whereas 20 are used for testing.
���ڽ���ʹ�õIJ�ͬ���������Ƚ������ڸ��ֻ����Ժ����ݼ��ϵ����ܡ�Ϊ�˲�����Щ��������������õĻ����ݼ���Omniglot��MiniImageNet��Omniglot���ݼ��������Բ�ͬ��ĸ����1623����д�ַ�������ѷ��Mechanical Turk��20����ͬ����������������1623����ͬ�Ľ�ɫ����ͼ��ĸ����Զ��ԣ�Omniglot��MNIST���ݼ����ơ���һ���棬�dz����ӵ�MiniImageNet��ImageNet���ݼ�[142]2���Ӽ���MiniImageNet���ݼ�������СΪ84��84��ͼ����Щͼ���������ѡ���100��������ÿ�������600��ͼ���ܹ�6000��ͼ�����������еı���ѵ������Ϊ֧�ּ��е�5��������е�ÿ�����ṩ1��5��������Ҳ������1��10֮�������������������������˱���Ϊ5����100������У�64�����������ѵ��16��������֤��20�����ڲ��ԡ�
Table 2 depict the performance of various techniques discussed on the omniglot dataset. The dataset been relative simple, majority of the models are able to achieve high accuracy for 1-shot and 5shot settings. Even though Data Augmentation and Embedding (or metric) learning achieved high accuracies, the optimization based techniques are a clear winner with an accuracy of 99.53% using the Meta-SGD algorithm [86]. Few of the optimizationbased techniques have a broader application scope and can be used in reinforcement settings as well including the Meta-SGD algorithm.
��2������omniglot���ݼ������۵ĸ��ּ��������ܡ����ݼ���Լ������ģ���ܹ�ʵ�� 1-shot �� 5-shot ���õĸ߾��ȡ�����������ǿ��Ƕ�루�������ѧϰʵ���˸߾��ȣ��������Ż��ļ�����Ȼ��Ӯ�ң�ʹ��Meta-SGD�㷨��ȷ��Ϊ99.53%[86]�������л����Ż��ļ������и��㷺��Ӧ�÷�Χ�����ҿ������ڼӹ����ã�����ԪSGD�㷨��
 Table 3 highlights the performance of various techniques discussed on the MiniImageNet dataset 3. As evidently seen, there is a considerable drop in the performance of the techniques discussed compared to their performance on the omniglot dataset. Techniques like Matching Network, MAML, Meta-SGD have 95% accuracy on the omniglot dataset whereas these same models have significantly lower accuracies on the MiniImageNet dataset. A major reason for this drop is that the images in the MiniImageNet dataset are much more complicated in terms of the contextual meaning, rich source of information, etc as compared to the omniglot dataset where the images are just characters. The data augmentation, embedding, optimization approach have 1-shot accuracies around 55%, even though there is a significant rise in the accuracies for the 5-shot settings, accuracies in the 70% ballpark. The trend is, more the number of samples, the better the accuracy. In order to make our model learn from as less samples as possible, we focus on the 1-shot accuracies. The state-of-theart accuracy is achieved through using semantic as an additional source of information along with the data to make the model understand novel categories.
Table 3 highlights the performance of various techniques discussed on the MiniImageNet dataset 3. As evidently seen, there is a considerable drop in the performance of the techniques discussed compared to their performance on the omniglot dataset. Techniques like Matching Network, MAML, Meta-SGD have 95% accuracy on the omniglot dataset whereas these same models have significantly lower accuracies on the MiniImageNet dataset. A major reason for this drop is that the images in the MiniImageNet dataset are much more complicated in terms of the contextual meaning, rich source of information, etc as compared to the omniglot dataset where the images are just characters. The data augmentation, embedding, optimization approach have 1-shot accuracies around 55%, even though there is a significant rise in the accuracies for the 5-shot settings, accuracies in the 70% ballpark. The trend is, more the number of samples, the better the accuracy. In order to make our model learn from as less samples as possible, we focus on the 1-shot accuracies. The state-of-theart accuracy is achieved through using semantic as an additional source of information along with the data to make the model understand novel categories.
��3ͻ����ʾ��MiniImageNet���ݼ�3�����۵ĸ��ּ��������ܡ���Ȼ����omniglot���ݼ��ϵ�������ȣ������۵ļ������������൱����½�����omniglot���ݼ��ϣ�ƥ�����硢MAML��Meta SGD�ȼ�����ȷ��Ϊ95%������MiniImageNet���ݼ��ϣ���Щģ�͵�ȷ�����Խϵ͡������½���һ����Ҫԭ���ǣ�MiniImageNet���ݼ��е�ͼ���������ĺ��塢�ḻ����ϢԴ�ȷ����omniglot���ݼ��е�ͼ������ӣ���omniglot���ݼ��е�ͼ��ֻ���ַ����������䡢Ƕ����Ż������ĵ��ξ���ԼΪ55%������������õľ�����������ߣ���������70%�ķ�Χ�ڡ������ǣ���������Խ�࣬ȷ��Խ�á�Ϊ��ʹ���ǵ�ģ�ʹӾ������ٵ�������ѧϰ�����ǽ��ص���ڵ��ξ����ϡ�ͨ��������������һ������������ϢԴ��ʹģ���ܹ������µ���𣬴Ӷ�ʵ�����µ�ȷ�ԡ�
The present state-of-the-art is still deficient when compared to a 4-5 years old preschooler��s performance, indicating a substantial scope of improvement in these techniques in the near future to compete or match with an adult human being��s performance. A hybrid model which can exploit the advantages of various techniques to boost performance can be the next course of action in the few shot meta learning domain. A hybrid model; a cross-modal implementation which incorporates the semantic information along with the data-augmentation and/or embedding techniques with reference to results in Table 3. An observation at the results generated, acknowledges that using semantic information achieves superiror results in-comparison to data-augmentation or embedding techniques. However,the sole use of semantic based approach still lacks performance quality when compared to that of a human. Incorporating advanced techniques or models like attention mechanism [143], [144], self-attention mechanism, transformers [1] or a variation of variational auto encoders (V AEs) like beta-V AE [145], VQ-V AE [146], VQ-V AE-2 [147] and TDV AE [148] that can better generate low dimension semantic information for better generalization of limited samples and thus can perform better on novel categories along with an improved distance function (euclidean or cosine) which can robustly classify or cluster the low dimensional embeddings
��4-5��ѧ��ǰ��ͯ�ı�����ȣ�Ŀǰ���Ƚ��ļ�����Ȼ���㣬������ڲ��õĽ�������Щ�������кܴ�ĸĽ��ռ䣬��������˵ı����ྺ�������ģ�Ϳ������ø��ּ�����������������ܣ��������������ͷԪѧϰ�������һ���ж������ģ����һ�ֿ�ģ̬ʵ�֣������������Ϣ�Լ����������/��Ƕ�뼼�����ο���3�еĽ���������ɵĽ���Ĺ۲�����������������Ƕ�뼼����ȣ�ʹ��������Ϣ���Ի�ø��õĽ����Ȼ�������˹�������ȣ���ʹ�û�������ķ�����Ȼȱ����������������Ƚ��ļ�����ģ�ͣ���ע�����[143]��[144]������ע����ơ���ѹ��[1]�����Զ���������V AEs���ı��壬��beta-V AE[145]��VQ-V AE[146]��VQ-V AE-2[147]��TDV AE[148]�ܹ����õ����ɵ�ά������Ϣ���Ա���õط��������������Ӷ��ܹ����õش���������Լ��Ľ��ľ��뺯����ŷ����»����ң����ú����ܹ��Ե�άǶ������Ƚ���������
4 CONCLUSION
With the availability of enough data samples and their respective labels, deep learning models can yield better performance by generalizing well to such tasks, but fail where the model has to learn from limited samples. Representation based learning method like few shot learning, meta learning are used improve the ability of the model to learn from limited samples. In this survey, we put forth an investigation on the finding and existing techniques on few shot meta learning techniques for supervised learning in the computer vision domain. We highlighted the fact that why it is imperative to research on techniques where the model needs to generalize well based on limited data samples and the prior knowledge. We classified the techniques into four main categories based on their approach towards solving the few-shot learning problem. We analyzed the performance of these techniques on two benchmarks, Omniglot and MiniImagenet dataset and provided a brief discussion regarding their performance and the ideal settings for those techniques along with a potential future direction for research towards matching or outperforming humans.
�����㹻���������������Ǹ��Եı�ǩ�����ѧϰģ�Ϳ���ͨ���ܺõظ�����Щ������������õ����ܣ������ģ�ͱ��������������ѧϰ�����ʧ�ܡ����û��ڱ�����ѧϰ��������С����ѧϰ��Ԫѧϰ�ȣ������ģ�ʹ�����������ѧϰ������������������У����������һ�����ķ��ֺ����еļ�����С����Ԫѧϰ�����ļලѧϰ�ڼ�����Ӿ���������ǿ����Ϊʲô�����о�ģ����Ҫ����������������������֪ʶ�������ø����ļ��������Ǹ��ݽ��С����ѧϰ����ķ�������Щ������Ϊ�Ĵ��ࡣ������Omniglot��MiniImagenet���ݼ����������Ϸ�������Щ���������ܣ�����Ҫ���������ǵ����ܺ���Щ�������������ã��Լ�δ���о�ƥ���Խ�����DZ�ڷ���