Meta R-CNN : Towards General Solver for Instance-level Low-shot Learning
Meta R-CNN:面向实例级小样本学习的通用解算器
论文地址:https://openaccess.thecvf.com/content_ICCV_2019/papers/Yan_Meta_R-CNN_Towards_General_Solver_for_Instance-Level_Low-Shot_Learning_ICCV_2019_paper.pdf
代码地址:Meta R-CNN
Abstract
Resembling the rapid learning capability of human, lowshot learning empowers vision systems to understand new concepts by training with few samples. Leading approaches derived from meta-learning on images with a single visual object. Obfuscated by a complex background and multiple objects in one image, they are hard to promote the research of low-shot object detection/segmentation. In this work, we present a flexible and general methodology to achieve these tasks. Our work extends Faster /Mask R-CNN by proposing meta-learning over RoI (Region-of-Interest) features instead of a full image feature. This simple spirit disentangles multi-object information merged with the background, without bells and whistles, enabling Faster /Mask R-CNN turn into a meta-learner to achieve the tasks. Specifically, we introduce a Predictor-head Remodeling Network (PRN) that shares its main backbone with Faster /Mask R-CNN. PRN receives images containing low-shot objects with their bounding boxes or masks to infer their class attentive vectors. The vectors take channel-wise soft-attention on RoI features, remodeling those R-CNN predictor heads to detect or segment the objects consistent with the classes these vectors represent. In our experiments, Meta R-CNN yields the newstateof theart inlow-shot object detection and improve slow-shot objects egmentation by MaskR-CNN.
与人类的快速学习能力类似,少样本学习通过少量样本的训练使视觉系统能够理解新概念。从单一视觉目标图像的元学习中衍生出的领先方法。由于复杂背景和一幅图像中存在多个目标,使得少样本目标检测/分割的研究难以推进。在这项工作中,我们提出了一种灵活和通用的方法来实现这些任务。我们的工作通过在RoI(感兴趣区域)特征上提出元学习而不是完整的图像特征来扩展Faster/Mask R-CNN。这种简单的精神将多目标信息与背景融合在一起,无需bells和whistles,使Faster /Mask R-CNN转变为元学习者来完成任务。具体来说,我们介绍了一种预测头重塑网络(PRN),它与Faster/Mask R-CNN共享其主干。PRN接收包含少样本目标及其边界框或遮罩的图像,以推断其类注意向量。这些向量对RoI特征进行通道式的软注意力,重塑这些R-CNN预测头,以检测或分割与这些向量所代表的类别一致的目标。在我们的实验中,Meta R-CNN产生了少样本目标检测的最新技术状态,并通过MASK R-CNN改进了少样本目标分割。
1 Introduction
Deep learning frameworks dominate the vision community to date, due to their human-level achievements in supervised training regimes with a large amount of data. But distinguished with human that excel in rapidly understanding visual characteristics with few demonstrations, deep neural networks significantly suffer performance drop when training data are scarce in a class. The exposed bottle neck triggers many researches that rethink the generalization of deep learning [46, 11], among which low(few)-shot learning [26] is a popular and very promising direction. Provided with very few labeled data (1?10 shots) in novel classes, low-shot learners are trained to recognize the data-starveclass objects by the aid of base classes with sufficient labeled data (See Fig 1.a). Its industrial potential increasingly drives the emergence of solution, falling under the umbrellas of Bayesian approaches [10, 26], similarity learning [25, 36] and meta-learning [40, 42, 41, 37].
到目前为止,深度学习框架在视觉社区中占据主导地位,因为它们在有监督的训练制度中取得了人类水平的成就,拥有大量数据。但与人类不同的是,深度神经网络擅长快速理解视觉特征,几乎没有演示,当类别中缺乏训练数据时,深度神经网络的性能会显著下降。暴露的瓶颈引发了许多研究,重新思考深度学习的普遍性[46,11],其中少样本学习[26]是一个流行且非常有前途的方向。提供的标签数据很少(1?10个样本)在新的类中,少样本学习者通过使用足够标记数据的基类(见图1.a)进行训练,以识别数据匮乏的类目标。它的工业潜力推动解决方案的出现,在贝叶斯方法[10,26]、相似性学习[25,36]和元学习[40,42,41,37]的基础上。
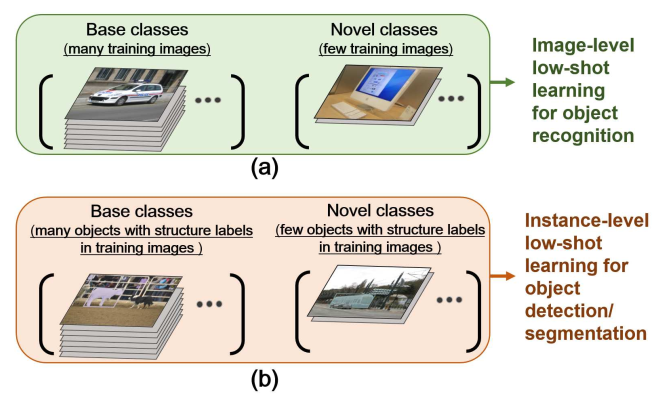
Figure 1. The illustration of labeled training images in low-shot setups for visual object recognition and class-aware object structure (bounding-boxs or masks) prediction. Compared with recognition, novel-class few objects in low-shot object detection/ segmentation blend with other objects in diverse backgrounds, yet requiring a low-shot learner to predict their classes and structure labels. 用于视觉目标识别和类感知目标结构(边界框或遮罩)预测的少样本设置中标记训练图像的图示。与识别相比,少样本目标检测/分割中的新类少数目标与不同背景中的其他目标融合,但需要少样本学习者预测它们的类和结构标签。
However, recognizing a single object in an image is solely a tip of the iceberg in real-world visual understanding. In terms of instance-level learning tasks, e.g., object detection [35, 33]/ segmentation [2], prior works in low-shot learning contexts remain rarely explored (See Fig 1.b). Since learning the instance-level tasks requires bounding-box or masks (structure labels) consuming more labors than image-level annotations, it would be practically impactful if the novel classes, object bounding boxes and segmentation masks can be synchronously predicted by a low-shot learner. Unfortunately, these tasks in object-starve conditions become much tougher, as a learner needs to locate or segment the novelclass number-rare objects beside of classifying them. Moreover, due to multiple objects in one image, novel-class objects might blend with the objects in other classes, further obfuscating the information to predict their structure labels. Given this, researchers might expect a complicated solution, as what were done to solve low-shot recognition [10, 26].
然而,在现实世界的视觉理解中,识别图像中的单个目标只是冰山一角。就实例级学习任务而言,例如,目标检测[35,33]/分割[2],之前在少样本学习环境中的工作仍然很少探索(见图1.b)。由于学习实例级任务需要边界框或遮罩(结构标签),比图像级注释耗费更多的劳动力,因此,如果少样本学习器能够同步预测新的类、目标边界框和分割遮罩,这将具有实际影响。不幸的是,在目标匮乏的情况下,这些任务变得更加困难,因为学习者除了分类之外,还需要定位或分割新类的稀有 目标。此外,由于一幅图像中有多个目标,新类目标可能会与其他类中的目标混合,从而进一步模糊信息以预测其结构标签。考虑到这一点,研究人员可能会期待一个复杂的解决方案,就像我们为解决少样本识别所做的那样[10,26]。
Beyond their expectation, we present an intuitive and general methodology to achieve low-shot object detection and segmentation : we propose a novel meta-learning paradigm based on the RoI (Region-of-Interest) features produced by Faster/Mask R-CNN [35, 17]. Faster /Mask R-CNN should be trained with considerable labeled objects and unsuited in low-shot object detection. Existing meta-learning techniques are powerful in low-shot recognition, whereas their successes are mostly based on recognizing a single object. Given an image with multi-object information merged in background, they almost fail as the meta-optimization could not disentangle this complex information. But interestingly, we found that the blended undiscovered objects could be “pre-processed” via the RoI features produced by the firststage inference in Faster /Mask R-CNNs. Each RoI feature refers to a single object or background, so Faster /Mask RCNN may disentangle the complex information that most meta-learners suffer from.
超出他们的预期,我们提出了一种直观和通用的方法来实现少样本目标检测和分割:我们提出了一种新的元学习范式,该范式基于Faster/Mask R-CNN产生的RoI(感兴趣区域)特征[35,17]。Faster/Mask R-CNN应使用大量标记目标进行训练,且不适合少样本目标检测。现有的元学习技术在少样本识别方面非常强大,而它们的成功主要是基于对单个目标的识别。给定一幅背景中融合了多目标信息的图像,由于元优化无法解开这些复杂信息,它们几乎失败。但有趣的是,我们发现混合的未发现目标可以通过Faster/Mask R-CNN中第一阶段推理产生的RoI特征进行“预处理”。每个RoI特征都指向单个样本或背景,因此Faster/Mask R-CNN可以解开大多数元学习器遇到的复杂信息。
Our observation motivates the marriage between Faster /Mask R-CNN and meta-learning. Concretely, we extend Faster /Mask R-CNN by introducing a Predictor-head Remodeling Network (PRN). PRN is fully-convoluted and shares the main backbone’s parameters with Faster /Mask R-CNN. Distinct from the R-CNN counterpart, PRN receives low-shot objects drawn from base and novel classes with their bboxes or masks, inferring class-attentive vectors, corresponding to the classes that low-shot input objects belong to. Each vector takes channel-wise attention to all RoI features, inducing the detection or segmentation prediction for the classes. To this end, a Faster /Mask R-CNN predictor head has been remodeled to detect or segment the objects that refer to the PRN’s inputs, including the category, position, and structure information of low-shot objects. Our framework exactly boils down to a typical meta-learning paradigm, encouraging the name Meta R-CNN
我们的观察结果推动了Faster /Mask R-CNN和元学习之间的结合。具体来说,我们通过引入预测头重塑网络(PRN),扩展了Faster /Mask R-CNN。PRN是完全卷积的,与Faster/Mask R-CNN共享主主干的参数。与R-CNN不同的是,PRN接收来自基本类和新类的少样本目标及其BBox或掩码,推断出与少样本输入目标所属的类相对应的类注意向量。每个向量都对所有RoI特征进行通道式关注,从而对类进行检测或分割预测。为此,一个Faster/Mask R-CNN预测器头被重新设计,以检测或分割参考PRN输入的目标,包括少样本目标的类别、位置和结构信息。我们的框架完全可以归结为一种典型的元学习范式,鼓励使用meta R-CNN这个名称
Meta R-CNN is general (available in diverse backbones in Faster/Mask R-CNN), simple (a lightweight PRN) yet effective (a huge performance gain in low-shot object detection/ segmentation) and remains fast inference (classattentive vectors could be pre-processed before testing). We conduct the experiments across 3 benchmarks, 3 backbones for low-shot object detection/ segmentation. Meta R-CNN has achieved the new state of the art in low-shot novel-class object detection/ segmentation, and more importantly, kept competitive performance to detect base-class objects. It verifies Meta R-CNN significantly improve the generalization
capability of Faster/ Mask R-CNN.
Meta R-CNN是通用的(在Faster/Mask R-CNN中有多种主干),简单(一个轻量级的PRN)但有效(在少样本目标象检测/分割中有巨大的性能增益),并保持快速推理(ClassAttention向量可以在测试前预处理)。我们在3个基准、3个主干上进行了少样本目标检测/分割实验。Meta R-CNN在少样本新颖类目标检测/分割方面达到了新的水平,更重要的是,在检测基类目标方面保持了竞争力。验证了Meta R-CNN显著提高了Faster/Mask R-CNN的泛化能力。
2. Related Work
Low-shot object recognition aims to recognize novel visual objects given very few corresponding labeled training examples. Recent studies in vision are mainly classed into three streams based on Bayesian approaches, metric learning and meta-learning, respectively. Bayesian approaches [10, 26] presume a mutual organization rule behind the objects, and design probabilistic model to discover the information among latent variables. Similarity learning [25, 36, 38] tend to consider the same-category examples’s features should be more similar than those between different classes. Distinct from them, meta-learning [40, 37, 12, 32, 3, 16, 43, 11] designs to learn a meta-learner to parametrize the optimization algorithm or predict the parameters of a classifier, so-called “learning-to-learn”. Recent theories [1, 23] show that meta-learner achieves a generalization guarantee, attracting tremendous studies to solve low-shot problems by meta-learning techniques. However, most existing methods focus on single-object recognition.
少样本目标识别的目的是在极少的训练样本下识别新的视觉目标。最近的视觉研究主要分为三类,分别基于贝叶斯方法、度量学习和元学习。贝叶斯方法[10,26]假定目标背后存在相互组织规则,并设计概率模型来发现潜在变量之间的信息。相似性学习(25, 36, 38)倾向于考虑同一类别,实例的特征应该比不同类之间的特征更相似。与之不同的是,元学习[40,37,12,32,3,16,43,11]旨在学习元学习者对优化算法进行参数化或预测分类器的参数,即所谓的“学会学习”。最近的理论[1,23]表明,元学习者实现了泛化保证,吸引了大量的研究来通过元学习技术解决低级问题。然而,现有的方法大多集中在单目标识别上。
Object detection based on neural network is mainly resolved by two solver branches: one-stage / two-stage detectors. One-stage detectors attempt to predict bounding boxes and detection confidences of object categories directly, including YOLO [33], SSD [28] and the variants. R-CNN [14] series [18, 13, 35, 8] fall into the second stream. The methods apply covnets to classify and regress the location by the region proposals generated by different algorithms [39, 35]. More recently, low-shot object detection has been extended from recognition [4, 22, 21]. [21] follows fullimage meta-learning principle to address this problem. Instead, we discuss the similarity and difference between lowshot object recognition and detection in Sec 3, to reasonably motivate our RoI meta-learning approach.
基于神经网络的目标检测主要由两个求解器分支解决:一级/两级检测器。单阶段检测器试图直接预测目标类别的边界框和检测可信度,包括YOLO[33]、SSD[28]和变体。R-CNN[14]系列[18,13,35,8]进入第二流。这些方法应用CovNet,根据不同算法生成的区域建议对位置进行分类和回归[39,35]。最近,少样本目标检测从识别扩展到了识别[4,22,21]。[21]遵循fullimage元学习原则解决此问题。相反,我们在第3节中讨论了少样本目标识别和检测之间的相似性和差异,以合理地激发我们的RoI元学习方法。
Object segmentation is expected to pixel-wise segment the objects of interest in an image. Leading methods are categorized into image-based and proposal-based. Proposalbased methods [30, 31, 7, 6] predict object masks based on the generated region proposals while image-based methods [47, 48, 44, 2] produce a pixel-level segmentation map over the image to identify object instance. The relevant researches in few-shot setup remain absent.
目标分割是指对图像中感兴趣的目标进行像素级的分割。主要的方法分为基于图像的和基于建议的。基于建议的方法[30,31,7,6]基于生成的区域建议预测目标掩码,而基于图像的方法[47,48,44,2]在图像上生成像素级分割图,以识别目标实例。有关少样本设置的相关研究尚不多见。
3. Tasks and Motivation
Before introducing Meta R-CNN, we consider low-shot object detection /segmentation tasks it aims to achieve. The tasks could be derived from low-shot object recognition in terms of meta-learning methods that motivate our method.
在引入Meta R-CNN之前,我们考虑它所要达到的少样本目标检测/分割任务。这些任务可以从激发我们方法的元学习方法的少样本目标识别中派生出来。
3.1. Preliminary: low-shot visual object recognition by meta-learning
In low-shot object recognition, a learner h(;θ) receives training data from base classes Cbase and novel classes Cnovel. So the data can be divided into two groups: Dbase= ![]() contains sufficient samples in each base class;
contains sufficient samples in each base class; ![]() contains very few samples in each novel class. h(;θ) aims to classify test samples drawn from Pnovel. Notably, training h(;θ) with small dataset Dnovel to identify Cnovel suffers model overfitting, whereas training h(;θ) with Dbase∪ Dnovel still fails, due to the extreme data quantity imbalance between Dbase and Dnovel(n2<< n1).
contains very few samples in each novel class. h(;θ) aims to classify test samples drawn from Pnovel. Notably, training h(;θ) with small dataset Dnovel to identify Cnovel suffers model overfitting, whereas training h(;θ) with Dbase∪ Dnovel still fails, due to the extreme data quantity imbalance between Dbase and Dnovel(n2<< n1).
在少样本目标识别中,学习器h(;θ)从基类Cbase和新类Cnovel接收训练数据。所以数据可以分为两组:Dbase=![]() 在每个基类中包含足够的样本;
在每个基类中包含足够的样本;![]() 在每一个新类中都包含很少的样本。h(;θ)旨在对从Pnovel提取的测试样本进行分类。值得注意的是,使用小数据集Dnovel训练h(;θ)以识别Cnovel会出现模型过度拟合,而使用Dbase∪ Dnovel训练h(;θ)仍然失败,因为Dbase和Dnovel之间的极端数据量不平衡(n2<<n1)。
在每一个新类中都包含很少的样本。h(;θ)旨在对从Pnovel提取的测试样本进行分类。值得注意的是,使用小数据集Dnovel训练h(;θ)以识别Cnovel会出现模型过度拟合,而使用Dbase∪ Dnovel训练h(;θ)仍然失败,因为Dbase和Dnovel之间的极端数据量不平衡(n2<<n1)。
Recent wisdoms tend to address this problem by recasting it into a meta-learning paradigm [40, 41] to encourage a fast model adaptation (generalization) to novel tasks, e.g., classifying objects in Cnovel. In each iteration, the meta-learning paradigm draws a subset of classes Cmeta? Cbase∪Cnovel and thus, uses the images belonging to Cmeta to construct two batches: a training mini-batch Dtrain and a small-size meta(reference)-set Dmeta(low-shot samples in each class). Given this, a meta-learner h(xi, Dmeta;θ) simultaneously receives an image xi? Dtrain and the entire Dmeta and then, is trained to classify Dtrain into Cmeta. By replacing Dmetawith Dnovel, recent theories [1, 23] present generalization bounds to the meta-learner, enabling h(, Dnovel;θ) to correctly recognize the objects ? Pnovel.
最近的方法倾向于通过将其重新纳入元学习范式[40,41]来解决这个问题,以鼓励快速模型适应(概括)新任务。例如,在Cnovel中对目标进行分类。在每次迭代中,元学习范式都会绘制 Cmeta? Cbase∪Cnovel类的子集。因此,使用属于Cmeta的图像构建两个批次:一个训练小批次Dtrain和一个小尺寸元(参考)集Dmeta(每个类中的少样本)。鉴于此,元学习器![]() 同时接收图像xi? Dtrain和整个Dmeta然后经过训练将Dtrain分类为Cmeta。通过将Dmeta替换为Dnovel,最近的理论[1,23]为元学习者提供了泛化边界,使
同时接收图像xi? Dtrain和整个Dmeta然后经过训练将Dtrain分类为Cmeta。通过将Dmeta替换为Dnovel,最近的理论[1,23]为元学习者提供了泛化边界,使![]() 能够正确识别目标? Pnovel。
能够正确识别目标? Pnovel。
3.2. Low-shot object detection / segmentation
From visual recognition to detection /segmentation, lowshot learning on objects becomes more complex: An image xi might contain ni objects ![]() in diverse classes, positions and shapes. Therefore the low-shot learners need to identify novel-class objects
in diverse classes, positions and shapes. Therefore the low-shot learners need to identify novel-class objects ![]() from other objects and background, and then, predict their classes
from other objects and background, and then, predict their classes ![]() and structure labels snovel i,j (bounding-boxes or masks). Most existing detection/ segmentation baselines address the problems by modeling h(xi; θ), performing poorly in a low-shot scenario. However, meta-predictor h(xi, Dmeta; θ) is also unsuitable, since xi contains multi-object complex information merged in diverse backgrounds.
and structure labels snovel i,j (bounding-boxes or masks). Most existing detection/ segmentation baselines address the problems by modeling h(xi; θ), performing poorly in a low-shot scenario. However, meta-predictor h(xi, Dmeta; θ) is also unsuitable, since xi contains multi-object complex information merged in diverse backgrounds.
从视觉识别到检测/分割,对目标的小样本学习变得更加复杂:图像Xi可能包含ni目标![]() 在不同的类,位置和形状。因此,少样本学习器需要从其他目标和背景中识别新的类目标
在不同的类,位置和形状。因此,少样本学习器需要从其他目标和背景中识别新的类目标![]() ,然后预测他们的类
,然后预测他们的类![]() 和结构标签
和结构标签![]() (边界框或掩码)。大多数现有的检测/分割基线通过建模h(xi;θ)来解决问题,在少样本场景中表现不佳。但是,元预测器h(xi, Dmeta; θ)也不适用,因为xi包含多个目标在不同背景下的复杂信息融合。
(边界框或掩码)。大多数现有的检测/分割基线通过建模h(xi;θ)来解决问题,在少样本场景中表现不佳。但是,元预测器h(xi, Dmeta; θ)也不适用,因为xi包含多个目标在不同背景下的复杂信息融合。
Motivation. The real goal of meta-learning for low-shot object detection/ segmentation is to model![]() rather than
rather than ![]() . Since visual objects
. Since visual objects![]() are blended with each other and merge with the background in xi, meta-learning with
are blended with each other and merge with the background in xi, meta-learning with![]() is prevented. Howbeit in two-stage detection models, e.g., Faster/ Mask R-CNNs, multi-object and their background information can be disentangled into RoI (Region-of-Interest) features
is prevented. Howbeit in two-stage detection models, e.g., Faster/ Mask R-CNNs, multi-object and their background information can be disentangled into RoI (Region-of-Interest) features ![]() , which are produced by taking RoIAlign on the image region proposals extracted by the region proposal network (RPN). These RoI features are fed into the second-stage predictor head to achieve RoI-based object classification, position location and silhouette segmentation for
, which are produced by taking RoIAlign on the image region proposals extracted by the region proposal network (RPN). These RoI features are fed into the second-stage predictor head to achieve RoI-based object classification, position location and silhouette segmentation for ![]() . Given this, it is preferable to remodel the R-CNN predictor head into
. Given this, it is preferable to remodel the R-CNN predictor head into![]() to classify, locate and segment the object
to classify, locate and segment the object ![]() behind each region of interest (RoI) feature
behind each region of interest (RoI) feature ![]() .
.
动机 用于少样本目标检测/分割的元学习的真正目标是建模![]() 而不是
而不是![]() 。由于视觉目标
。由于视觉目标![]() 彼此混合,并且与xi中的背景合并,因此防止了
彼此混合,并且与xi中的背景合并,因此防止了![]() 的元学习。然而,在两阶段检测模型中,例如Faster/ Mask R-CNNs、多目标及其背景信息可以分解为RoI(感兴趣区域)特征
的元学习。然而,在两阶段检测模型中,例如Faster/ Mask R-CNNs、多目标及其背景信息可以分解为RoI(感兴趣区域)特征![]() ,这些特征是通过对区域建议网络(RPN)提取的图像区域建议进行RoIAlign而产生的。这些RoI特征被输入到第二阶段预测头中,以实现基于RoI的目标分类、位置定位和
,这些特征是通过对区域建议网络(RPN)提取的图像区域建议进行RoIAlign而产生的。这些RoI特征被输入到第二阶段预测头中,以实现基于RoI的目标分类、位置定位和![]() 的轮廓分割。鉴于此,最好将R-CNN预测器头部重新建模为
的轮廓分割。鉴于此,最好将R-CNN预测器头部重新建模为![]() ,以分类、定位和分割 每个感兴趣区域(RoI)特征
,以分类、定位和分割 每个感兴趣区域(RoI)特征![]() 中的目标
中的目标![]() 。
。
4. Meta R-CNN
Aiming at meta-learning over regions of interest (RoIs), Meta R-CNN is conceptually simple: its pipeline consists of 1). Faster/ Mask R-CNN; 2). Predictor-head Remodeling Network (PRN). Faster/ Mask R-CNN produces object proposals {? zi,j}ni j=1by their region proposal networks (RPN). Then each ? zi,jcombines with class-attentive vectors inferred by our PRN, which plays the role of h(, Dmeta;θ) to detect or segment the novel-class objects. The Meta RCNN framework is illustrated in Fig 2 and we elaborate it by starting from Faster/ Mask R-CNN.
meta R-CNN旨在通过兴趣区域(ROI)进行元学习,其概念很简单:它的管道由两部分组成1)Faster/ Mask R-CNN;2). 预测头重塑网络(PRN)。Faster/Mask R-CNN通过其区域建议网络(RPN)生成目标建议![]() 。然后,每个
。然后,每个![]() 与我们的PRN推断的类注意向量相结合,该类注意向量扮演
与我们的PRN推断的类注意向量相结合,该类注意向量扮演![]() 的角色来检测或分割新的类目标。Meta RCNN框架如图2所示,我们从Faster/Mask R-CNN开始详细阐述。
的角色来检测或分割新的类目标。Meta RCNN框架如图2所示,我们从Faster/Mask R-CNN开始详细阐述。
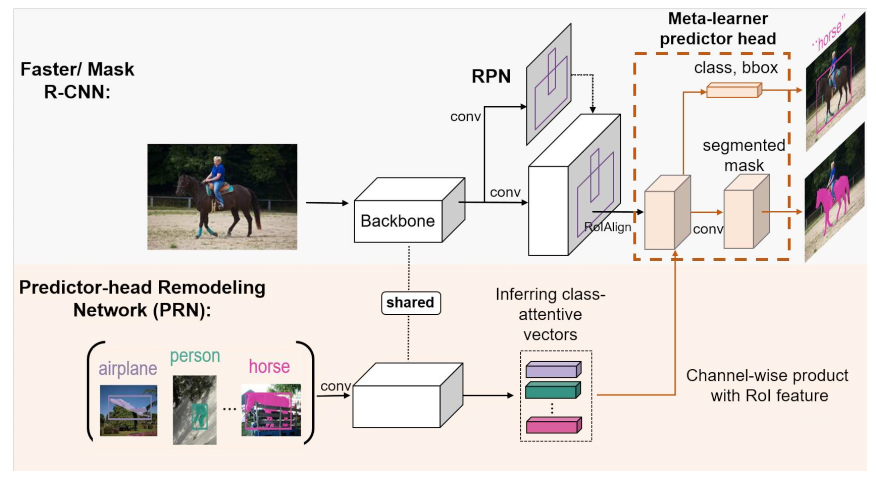
Figure 2. Our Meta R-CNN consists of 1) Faster/ Mask R-CNN; 2) Predictor-head Remodeling Network (PRN). Faster/ Mask RCNN (module) receives an image to produce
RoI features, by taking RoIAlign on the image region proposals extracted by RPN. In parallel, our PRN receives K-shot-m-class resized images with their structure labels (bounding boxes/segmentaion masks) to infer m class-attentive vectors. Given a class attentive vector representing class c, it takes a channel-wise soft-attention on each RoI feature, encouraging the Faster/ Mask R-CNN predictor heads to detect or segment class-c objects based on the RoI features in the image. As the class c is dynamically determined by the inputs of PRN, Meta R-CNN is a metalearner. 我们的Meta R-CNN包括1) Faster/ Mask R-CNN 2) 预测头重塑网络(PRN)。1) Faster/ Mask R-CNN RCNN(模块)接收图像以生成RoI特征,通过对RPN提取的图像区域进行ROIAllign。同时,我们的PRN接收K-shot m类大小调整后的图像及其结构标签(边界框/分段掩码),以推断m类注意向量。给定一个代表c类的类注意向量,它对每个RoI特征进行通道式软注意,鼓励1) Faster/ Mask R-CNN R-CNN预测头根据图像中的RoI特征检测或分割c类对象。由于c类由PRN的输入动态确定,Meta R-CNN是一个元学习器。
4.1. Review the R-CNN family
Faster R-CNN system is known as a two-stage pipeline. The first stage is a region proposal network (RPN), receiving an image xi to produce the candidate object boundingboxes (so-called object region proposals) in this image. The second stage, i.e., Fast R-CNN [13], shares the RPN backbone to extract RoI (Region-of-Interest) features![]() from
from ![]() object region proposals after RoIAlign, enabling its predictor head
object region proposals after RoIAlign, enabling its predictor head ![]() to classify and locate the object
to classify and locate the object ![]() behind the RoI feature
behind the RoI feature![]() of xi. Mask R-CNN activates the segmentation ability in Faster R-CNN by adding a parallel mask branch in the predictor head h(・,θ). Due to our identical technique applied in Faster/ Mask R-CNN, we unify their predictor heads by h(・,θ).
of xi. Mask R-CNN activates the segmentation ability in Faster R-CNN by adding a parallel mask branch in the predictor head h(・,θ). Due to our identical technique applied in Faster/ Mask R-CNN, we unify their predictor heads by h(・,θ).
Faster R-CNN系统被称为两级管道。第一阶段是区域建议网络(RPN),接收图像席(XI)以产生该图像中的候选目标边界框(所谓的目标区域建议)。?第二阶段,即Faster R-CNN(13),共享RPN骨干,在ROIALIGN后从![]() 目标区域建议中提取ROI(感兴趣区域)特征
目标区域建议中提取ROI(感兴趣区域)特征![]() ,使其预测头
,使其预测头![]() 分类和定位目标
分类和定位目标![]() 背后的ROI特征
背后的ROI特征![]() 。Mask R-CNN通过在预测器头部h(・θ)中添加一个平行的Mask分支来激活快速R-CNN中的分割能力。由于我们在Faster/ Mask R-CNN中应用了相同的技术,我们用h(・,θ)统一了它们的预测头。
。Mask R-CNN通过在预测器头部h(・θ)中添加一个平行的Mask分支来激活快速R-CNN中的分割能力。由于我们在Faster/ Mask R-CNN中应用了相同的技术,我们用h(・,θ)统一了它们的预测头。
As previously discussed, predictor head h(・,θ) in Faster/ Mask R-CNN is inappropriate to make low-shot object detection/ segmentation. To this we propose PRN that remodels h(・,θ) into a meta-predictor head h(・, Dmeta;θ).
如前所述,Faster/Mask R-CNN中的预测器头部![]() 不适合进行少样本目标检测/分割。为此,我们提出了PRN,它将
不适合进行少样本目标检测/分割。为此,我们提出了PRN,它将![]() 重构为元预测头
重构为元预测头![]() 。
。
4.2. Predictor-head Remodeling Network (PRN)
A straightforward approach to design h(・, Dmeta;θ) is to learn θ to predict the optimal parameter w.r .t. an arbitrary meta-set Dmeta like [42]. Such explicit “learning-to-learn” manner is sensitive to the architectures and h(・,θ) in Faster/ Mask R-CNN is abandoned. Instead, our work is inspired by the concise spirit of SNAIL [29], thus, incorporating class-specific soft-attention vectors to achieve channelwise feature selection on each RoI feature in![]() [5]. This soft-attention mechanism is implemented by the classattentive vectors vmetainferred from the objects in a metaset Dmeta via PRN. In particular, suppose that PRN denotes as vmeta= f(Dmeta;φ), given each RoI feature ? zi,j that belongs to image xi, it holds
[5]. This soft-attention mechanism is implemented by the classattentive vectors vmetainferred from the objects in a metaset Dmeta via PRN. In particular, suppose that PRN denotes as vmeta= f(Dmeta;φ), given each RoI feature ? zi,j that belongs to image xi, it holds
设计h(・,Dmeta;θ)的一种简单方法是学习θ来预测最佳参数w。RT类似于[42]的任意元集Dmeta。这种明确的“学习-学习”方式对体系结构非常敏感,在Faster/Mask R-CNN中h(・,θ)被放弃。相反,我们的工作受到SNAIL[29]简洁精神的启发,因此,结合特定于类的软注意向量,在![]() [5]中实现对每个RoI特征的通道特征选择。这种软注意机制是通过PRN从元集中的目标
[5]中实现对每个RoI特征的通道特征选择。这种软注意机制是通过PRN从元集中的目标![]() 推断出的类注意向量
推断出的类注意向量![]() 来实现的。特别是,假设PRN表示为
来实现的。特别是,假设PRN表示为![]() ,给定艺龙网的每个ROI特征,即属于图像xi,它有
,给定艺龙网的每个ROI特征,即属于图像xi,它有
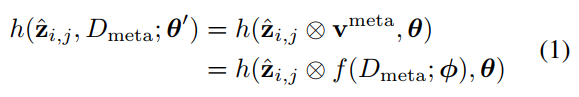
where θ, φ denote the parameters of Faster/Mask R-CNN and our PRN (most of them are shared, θ′ = {θ, φ}); ? indicates the channel-wise multiplication operator. Eq 1 implies that PRN remodels h(・, θ) into h(・, Dmeta; θ) in principles. It is intuitive, flexibly-applied and allows end-to-end joint training with its Faster/ Mask R-CNN counterpart.
其中θ,φ表示Faster/Mask R-CNN和我们的PRN的参数(其中大多数是共享的,θ′={θ,φ});? 指示通道乘法运算符。等式1意味着PRN原则上将h(・,θ)重构为h(・,Dmeta;θ)。它直观、灵活地应用,并允许与Faster/Mask R-CNN进行端到端的联合训练。
Suppose xi as the image Meta R-CNN aiming to detect. After RoIAlign in its R-CNN module, it turns to a set of RoI features {?z}n i,j ?i . Here we explain how PRN acts on them
假设Xi作为图像Meta-R CNN,用于检测。在其R-CNN模块中进行ROAILING之后,它将转向一组RoI特征![]() 。这里我们将解释PRN是如何作用于它们的
。这里我们将解释PRN是如何作用于它们的
Infer class-attentive vectors. As can be observed, PRN f(Dmeta; φ) receives all objects in meta-set Dmeta as input. In the context of object detection/ segmentation, Dmeta denotes a series of objects distributed across images, whose classes belong to Cmeta and there exist K objects per class (K-shot setup). Each object in Dmeta presents a 4-channel input, i.e., an RGB image x with the same-spatial-size foreground structure label s that are combined to represent this object (s is a binary mask derived from the object boundingbox or segmentation mask). Hence given m as the size of Cmeta, PRN receives mK 4-channel object inputs in each inference process. To ease the computation burden, we standardize the spatial size of object inputs into 224×224. During inference, after passing the first convolution layer of our PRN, each object feature would be fed into the second layer of its R-CNN counterpart, undergoing the shared backbone before RoIAlign. Instead of accepting RoIAlign, the feature passes a channel-wise soft-attention layer to produce its object attentive vector v. To this end, PRN encodes mK objects in Dmeta into mK object attentive vectors and then, applies average pooling to obtain the class-attentive vectors vmeta c , i.e., ![]() ,
,![]() represents an object attentive vector inferred from a class-c object and there are K objects per class).
represents an object attentive vector inferred from a class-c object and there are K objects per class).
推断类注意力向量。可以观察到,PRN f(Dmeta;φ)接收元集合Dmeta中的所有目标作为输入。在目标检测/分割的上下文中,Dmeta表示分布在图像上的一系列目标,其类别属于Cmeta,每个类别存在K个目标(K-shot设置)。Dmeta中的每个目标都提供了一个4通道输入,即具有相同空间大小的前景结构标签s的RGB图像x,这些标签组合起来表示该目标(s是从目标边界框或分割掩码派生的二进制掩码)。因此,给定m作为Cmeta的大小,PRN在每个推理过程中接收mK 4通道目标输入。为了减轻计算负担,我们将目标输入的空间大小标准化为224×224。在推理过程中,在通过PRN的第一个卷积层后,每个目标特征将被送入其R-CNN对应物的第二层,在ROIALLIGN之前经历共享主干。该功能不接受RoIAlign,而是通过一个通道软注意层来生成其目标注意向量v。为此,PRN将Dmeta中的mK目标编码为mK对象注意向量,然后应用平均池来获得类注意向量vmeta c,即![]() ,
,![]() 表示从c类对象推断出的目标注意向量,每个类有K个目标)。
表示从c类对象推断出的目标注意向量,每个类有K个目标)。
Remodel R-CNN predictor heads. After obtaining the class-attentive vectors ![]() ,PRN applies them to make channel-wise soft-attention on each RoI feature zi,j. Suppose that
,PRN applies them to make channel-wise soft-attention on each RoI feature zi,j. Suppose that ![]() denotes the RoI feature matrix generated from xi (128 denotes the number of RoI). PRN replaces
denotes the RoI feature matrix generated from xi (128 denotes the number of RoI). PRN replaces ![]() by
by ![]()
![]() to feed the primitive predictor heads in Faster /Mask R-CNNs. The refinement leads to detecting or segmenting all class-c objects in the image xi. In this spirit, each RoI feature ?zi,j produces m binary detection outcomes that refers to the classes in Cmeta. To this Meta R-CNN categorizes ?zi,j into the class c? with the highest confidence score and use the branch
to feed the primitive predictor heads in Faster /Mask R-CNNs. The refinement leads to detecting or segmenting all class-c objects in the image xi. In this spirit, each RoI feature ?zi,j produces m binary detection outcomes that refers to the classes in Cmeta. To this Meta R-CNN categorizes ?zi,j into the class c? with the highest confidence score and use the branch![]() to locate or segment the object. But if the highest confidence score is lower than the objectness threshold, this RoI would be treated as background and discarded.
to locate or segment the object. But if the highest confidence score is lower than the objectness threshold, this RoI would be treated as background and discarded.
改造R-CNN预测头。在获得类注意力向量后![]() ,PRN应用它们对每个RoI特征zi,j进行通道式软注意。假设
,PRN应用它们对每个RoI特征zi,j进行通道式软注意。假设![]() 表示由Xi(128表示的ROI特征矩阵)。PRN将
表示由Xi(128表示的ROI特征矩阵)。PRN将![]() 替换为
替换为![]()
![]() 以Faster /Mask R-CNN为原始预测头提供信息。该细化导致检测或分割图像Xi中的所有C类目标。本着这种精神,每个RoI特征
以Faster /Mask R-CNN为原始预测头提供信息。该细化导致检测或分割图像Xi中的所有C类目标。本着这种精神,每个RoI特征![]() 产生m个二进制检测结果,这些结果指的是Cmeta中的类。根据meta R-CNN将
产生m个二进制检测结果,这些结果指的是Cmeta中的类。根据meta R-CNN将![]() 归类为类c? 具有最高的信心分数,并使用分支
归类为类c? 具有最高的信心分数,并使用分支![]() 定位或分割对象。但是,如果最高置信度得分低于目标性阈值,则该RoI将被视为背景并被丢弃。
定位或分割对象。但是,如果最高置信度得分低于目标性阈值,则该RoI将被视为背景并被丢弃。
5. Implementation
Meta R-CNN is trained under a meta-learning paradigm. Our implementation based on Faster/ Mask R-CNN, whose hyper-parameters follow their original report.
Meta R-CNN是在元学习范式下训练的。我们的实现基于Faster/Mask R-CNN,其超参数遵循其原始报告。
Mini-batch construction. Simulating the meta-learning paradigm we have discussed, a training mini-batch in Meta R-CNN is comprised of m classes Cmeta? Cbase∪Cnovel, a K-shot m-class meta-set Dmetaand m-class training set Dtrain(classes in Dmeta, Dtrainconsistent with Cmeta). In our implementation, Dtrainrepresent the objects in the input x of Faster/ Mask R-CNNs. To keep the class consistency, we choose Cmetaas the object classes image x refers to, and only uses the attentive vectors inferred from the objects belonging to the classes in Cmeta. Therefore, if the R-CNN module receives an image input x that contains objects in m classes, a mini-batch consists of x (Dtrain) and mK resized images with their structure label masks.
小批量建设。模拟我们已经讨论过的元学习范式,meta R-CNN中的一个训练小批量由m个类组成Cmeta? Cbase∪Cnovel,一个K-shot m类元集Dmeta和m类训练集Dtrain(Dmeta中的类,Dtrain与Cmeta一致)。在我们的实现中,Dtrain表示Faster/Mask R-CNN的输入x中的目标。为了保持类的一致性,我们选择Cmeta作为图像x所指的对象类,并且只使用从属于Cmeta中类的目标推断出的注意向量。因此,如果R-CNN模块接收到包含m类对象的图像输入x,则一个小批量由x(Dtrain)和mK大小调整的图像及其结构标签掩码组成。
Channel-wise soft-attention layer . This layer receives the features induced from the main backbone of the R-CNN counterpart. It performs a spatial pooling to align the object features maintaining the identical size of RoI features. Then the features undergo an element-wise sigmoid to produce attentive vectors (the size is 2048×1 in our experiment).
通道式软注意层。该层接收从R-CNN对应物的主主干诱导的特征。它执行空间池来对齐目标特征,保持RoI特征的相同大小。然后对特征进行元素方向的sigmoid生成关注向量(在我们的实验中大小为2048×1)。
Meta-loss. Given an RoI feature ![]() , to avoid the prediction ambiguity after soft-attention, attentive vectors from different-class objects should lead to diverse feature selection effects on
, to avoid the prediction ambiguity after soft-attention, attentive vectors from different-class objects should lead to diverse feature selection effects on ![]() . To this we propose a simple metaloss L(φ)metato diversify the inferred object attentive vectors in meta-learning. It is implemented by a cross-entropy loss encouraging the object attentive vectors to fall in the class each object belongs to. This auxiliary loss powerfully boosts Meta R-CNN performance (see Table 6 Ablation 2).
. To this we propose a simple metaloss L(φ)metato diversify the inferred object attentive vectors in meta-learning. It is implemented by a cross-entropy loss encouraging the object attentive vectors to fall in the class each object belongs to. This auxiliary loss powerfully boosts Meta R-CNN performance (see Table 6 Ablation 2).
元损失。给定RoI特征![]() ,为了避免软注意后的预测模糊,来自不同类别目标的注意向量应导致对
,为了避免软注意后的预测模糊,来自不同类别目标的注意向量应导致对![]() 的不同特征选择效果。为此,我们提出了一种简单的meta loss L(φ)元学习方法,以使元学习中的推断对象注意向量多样化。它是通过一个交叉熵损失来实现的,鼓励对象注意向量落在每个目标所属的类中。这种辅助损耗有力地提高了Meta R-CNN的性能(见表6)。
的不同特征选择效果。为此,我们提出了一种简单的meta loss L(φ)元学习方法,以使元学习中的推断对象注意向量多样化。它是通过一个交叉熵损失来实现的,鼓励对象注意向量落在每个目标所属的类中。这种辅助损耗有力地提高了Meta R-CNN的性能(见表6)。
RoI meta-learning. Following the typical optimization routines in [40, 37, 41], meta-learning Meta R-CNN is divided into two phases. In the first phase (so-called metatrain), we solely consider base-class objects to construct Dmeta and Dtrain in per iter. In the case that an image simultaneously includes base-class and novel-class objects, we ignore the novel-class objects in meta-train. In the second phase (so-called meta-test), objects in base and novel classes are both considered. The objective is formulated as
RoI元学习。按照[40,37,41]中的典型优化例程,元学习meta R-CNN分为两个阶段。在第一阶段(所谓的元计算)中,我们只考虑基类目标来构造每iter中的DmetaA和Dtrain。在图像同时包含基类和新类目标的情况下,我们忽略元序列中的新类目标。在第二阶段(所谓的元测试),基本类和新类中的目标都被考虑。目标的表述如下:

where λ = {0, 1} indicates the activator of mask branch. The illustration of meta-learning for Meta R-CNN is below:
其中λ={0,1}表示掩码分支的激活器。meta R-CNN的元学习示例如下:
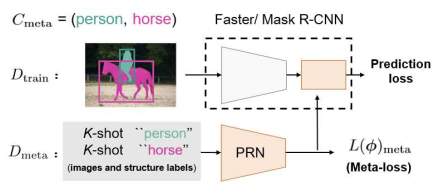
Figure 3. The illustrative instance of RoI meta-learning process in Meta R-CNN. Suppose the image Faster/ Mask R-CNN receiving contains objects in “person”, “horse”. Then Cmeta = ( “person”, “horse” ) and Dmeta includes K-shot “person” and ”horse” images with their structure labels, respectively. As the training image iteratively changes, Cmeta and Dmeta would adaptively change. meta R-CNN中RoI元学习过程的示例。假设R-CNN接收的图像包含“人”、“马”中的目标。然后,Cmeta=(“人”、“马”)和Dmeta分别包括带有结构标签的K-shot“人”和“马”图像。随着训练图像的迭代变化,Cmeta和Dmeta将自适应地变化。
Inference. Meta R-CNN entails two inference processes based on Faster/Mask R-CNN module and PRN. In training, the object attentive vectors inferred from Dmetawould replace the class-attentive vectors to take soft-attention effects on ![]() and produce the object detection/ segmentation losses in Eq 2. In testing, we choose Cmeta= Cbase∪Cnovel. It is because that unknown objects in a test image may cover all possible categories. PRN receives K-shot visual objects in all classes to produce class-attentive vectors to achieve lowshot object detection/ segmentation. Note that, no matter of object or class attentive vectors, they can be pre-processed before testing, and parallelly take soft-attention on RoI feature matrices. It promises the fast inference of Faster/ Mask R-CNN will not be decelerated: In our experiment (using a single GTX TITAN XP), if shot is 3, the inference speed of Faster R-CNN is 83.0 ms/im; Meta R-CNN is 84.2ms/im; if shot is 10, the speed of Meta R-CNN is 85.4ms/im.
and produce the object detection/ segmentation losses in Eq 2. In testing, we choose Cmeta= Cbase∪Cnovel. It is because that unknown objects in a test image may cover all possible categories. PRN receives K-shot visual objects in all classes to produce class-attentive vectors to achieve lowshot object detection/ segmentation. Note that, no matter of object or class attentive vectors, they can be pre-processed before testing, and parallelly take soft-attention on RoI feature matrices. It promises the fast inference of Faster/ Mask R-CNN will not be decelerated: In our experiment (using a single GTX TITAN XP), if shot is 3, the inference speed of Faster R-CNN is 83.0 ms/im; Meta R-CNN is 84.2ms/im; if shot is 10, the speed of Meta R-CNN is 85.4ms/im.
推理 Meta R-CNN包含两个基于Faster/Mask R-CNN模块和PRN的推理过程。在训练中,从DMETA推断出的目标注意向量将取代类注意向量,对![]() 产生软注意效应,并在等式2中产生目标检测/分割损失。在测试中,我们选择Cmeta=Cbase∪Cnovel。这是因为测试图像中的未知目标可能涵盖所有可能的类别。PRN接收所有类中的K-shot视觉目标,生成类注意向量,实现少样本目标检测/分割。请注意,无论是对象还是类关注向量,它们都可以在测试前进行预处理,并并行地对RoI特征矩阵进行软关注。它保证了Faster R-CNN的快速推理不会减速:在我们的实验中(使用单个GTX TITAN XP),如果shot为3,Faster R-CNN的推理速度为83.0 ms/im;Meta R-CNN为84.2ms/im;如果shot为10,Meta R-CNN的速度为85.4ms/im。
产生软注意效应,并在等式2中产生目标检测/分割损失。在测试中,我们选择Cmeta=Cbase∪Cnovel。这是因为测试图像中的未知目标可能涵盖所有可能的类别。PRN接收所有类中的K-shot视觉目标,生成类注意向量,实现少样本目标检测/分割。请注意,无论是对象还是类关注向量,它们都可以在测试前进行预处理,并并行地对RoI特征矩阵进行软关注。它保证了Faster R-CNN的快速推理不会减速:在我们的实验中(使用单个GTX TITAN XP),如果shot为3,Faster R-CNN的推理速度为83.0 ms/im;Meta R-CNN为84.2ms/im;如果shot为10,Meta R-CNN的速度为85.4ms/im。
6. Experiments
In this section, we propose thorough experiments to evaluate Meta R-CNN on low-shot object detection, the related ablation, and low-shot object segmentation.
在本节中,我们提出了全面的实验来评估Meta R-CNN在少样本物体检测、相关消融和少样本物体分割方面的作用。
6.1. Low-shot object detection
In low-shot object detection, we employ a Faster R-CNN [35] with ResNet-101 [17] backbone as the R-CNN module in our Meta R-CNN framework.
在少样本目标检测中,我们在Meta R-CNN框架中使用了一个Faster R-CNN[35],带有ResNet-101[17]主干作为R-CNN模块。
Benchmarks and setups. Our low-shot object detection experiment follows the setup [21]. Concretely, we evaluate all baselines on the generic object detection tracks of PASCAL VOC 2007 [9], 2012 [9], and MS-COCO [27] benchmarks. We adopt the PASCAL Challenge protocol that a correct prediction should have more than 0.5 IoU with the ground truth and set the evaluation metric to the mean Average Precision (mAP). Among these benchmarks, VOC 2007 and 2012 consists of images covering 20 object categories for training, validation and testing sets. To create a lowshot learning setup, we consider three different novel/baseclass split settings, i.e., (“bird”, “bus”, “cow”, “mbike”, “sofa”/ rest); (“aero”, “bottle”,“cow”,“horse”,“sofa” / rest) and (“boat”, “cat”, “mbike”,“sheep”, “sofa”/ rest). During the first phase of meta-learning, only base-class objects are considered. In the second phase, there are K-shot annotated bounding boxes for objects in each novel class and 3K annotated bounding boxes for objects in each base class for training, where K is set 1, 2, 3, 5 and 10. We also evaluate our method on COCO benchmark with 80 object categories including the 20 categories in PASCAL VOC. In this experiment, we set the 20 classes included in PASCAL VOC as the novel classes, then the rest 60 classes in COCO as base classes. The union of 80k train images and a 35k subset of validation images (trainval35k) are used for training, and our evaluation is based on the remaining 5k val images (minival). Finally, we consider the cross-benchmark transfer setup of low-shot object detection from COCO to PASCAL [21], which leverages 60 base classes of COCO to learn knowledge representations and the evaluation is based on 20 novel classes of PASCAL VOC.
VOC 2007和2012由涵盖20个对象类别的图像组成,用于训练、验证和测试集。为了创建一个少样本学习设置,我们考虑三个不同的新类/基类设置,比如(“鸟”、“公共汽车”、“牛”、“姆比克”、“沙发”/“休息”);(“航空”、“瓶子”、“牛”、“马”、“沙发”/“休息”)和(“船”、“猫”、“羊”、“沙发”/“休息”)。在元学习的第一阶段,只考虑基类目标。在第二阶段,每个新类中的目标都有K-shot注释边界框,每个训练基类中的对象都有3K注释边界框,其中K设置为1、2、3、5和10。我们还使用80个目标类别(包括PASCAL VOC中的20个类别)在COCO基准上评估了我们的方法。在本实验中,我们将PASCAL VOC中包含的20个类设置为新类,然后将COCO中的其余60个类设置为基类。80k列车图像和35k验证图像子集(trainval35k)的联合用于培训,我们的评估基于剩余的5k val图像(minival)。最后,我们考虑了从COCO到PASCAL〔21〕的低目标检测的交叉基准转移设置,利用60个COCO基类来学习知识表示,并基于20个新的PASCAL VOC类进行评估。
Baselines. In methodology, Meta R-CNN can be treated as the meta-learning extension of Faster R-CNN (FRCN) [35] in the background of low-shot object detection. To this a question about detector generalization is probably raised:
基线。在方法学上,Meta R-CNN可以被视为在少样本目标检测背景下Faster R-CNN(FRCN)[35]的元学习扩展。为此,可能会提出一个关于检测器泛化的问题:

To answer this question, we compare our Meta R-CNN with its base FRCN. This detector is derived into three base lines according to the different training strategies they use. Specifically, FRCN+joint is to jointly train the FRCN detector with base-class and novel-class objects. The identical number of iteration is used for training this baseline and our Meta R-CNN. FRCN+ft takes a similar two-phase training strategy in Meta R-CNN: it only uses base-class objects (with bounding boxes) to train FRCN in the first phase, then use the combination of base-class and novel-class objects to fine-tune the network. For a fair comparison, the objects in images used to train FRCN+ft is identical to Meta R-CNN, and FRCN+ft also takes the same number of iteration (in both training phases) of Meta R-CNN. Finally, FRCN+ft-full employ the same training strategy of FRCN+ft in the first phase, yet train the detector to fully converge in the second phase. Beyond these baselines, Meta R-CNN is also compared with the state-of-the-art low-shot object detector [21] modified from YOLOv2 [34] (YOLOLow-shot). Note that, YOLO-Low-shot also employs meta learning, whereas distinct from Meta R-CNN based on RoI features, it is based on a full image. Their comparison reveals whether the motivation of Meta R-CNN is reasonable.
为了回答这个问题,我们将Meta R-CNN与其基础FRCN进行了比较。根据检测器使用的不同训练策略,将检测器导出三条基线。具体来说,FRCN+联合是用基类和新类目标联合训练FRCN检测器。相同的迭代次数用于训练该基线和我们的Meta R-CNN。FRCN+ft在Meta R-CNN中采用了类似的两阶段训练策略:它只使用基类目标(带有边界框)在第一阶段训练FRCN,然后使用基类和新类目标的组合来微调网络。为了公平比较,用于训练FRCN+ft的图像中的对象与Meta R-CNN相同,FRCN+ft也采用Meta R-CNN相同的迭代次数(在两个训练阶段)。最后,FRCN+ft在第一阶段完全采用与FRCN+ft相同的训练策略,但在第二阶段训练检测器完全收敛。除了这些基线之外,Meta R-CNN还与最先进的低炮目标探测器[21]进行了比较,后者是由YOLOv2[34](YOLOW shot)改进而来的。请注意,YOLO Low shot也使用元学习,而与基于RoI特征的Meta R-CNN不同,它基于完整图像。他们的比较揭示了Meta R-CNN的动机是否合理。
PASCAL VOC. The experimental evaluation are shown in Table 1. The K-shot object detection is performed based on K = (1,2,3,5,10) across three novel/base class splits. As can be observed, Meta R-CNN consistently outperforms the three FRCN baselines by a large margin across splits. It uncovers the generalization weakness of FRCN: without adequate number of bounding-box annotations, FRCN performs poorly to detect novel-class objects, and this weakness could not be overcome by changing the training strategies. In a comparison, by simply deploying a lightweight PRN, FRCN turns into Meta R-CNN and significantly improve the performance on novel-class object detection. It implies that our approach endows FRCN with the generalization ability in low-shot learning.
PASCAL VOC. 实验评估如表1所示。K-shot目标检测是基于K=(1,2,3,5,10)跨三个新类/基类拆分执行的。正如可以观察到的那样,Meta R-CNN在各个细分市场上的表现都比三个FRCN基线好很多。它揭示了FRCN的泛化弱点:如果没有足够数量的边界框注释,FRCN在检测新类目标方面表现不佳,并且这种弱点无法通过改变训练策略来克服。相比之下,通过简单地部署一个轻量级的PRN,FRCN变成了Meta R-CNN,并显著提高了新类目标检测的性能。这意味着我们的方法赋予了FRCN在少样本学习中的泛化能力。
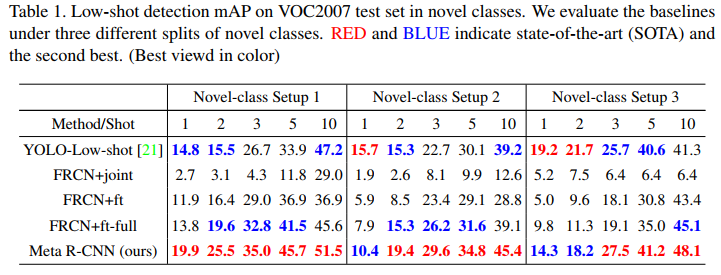
Besides, Meta R-CNN outperforms YOLO-Low-shot in the majority of the cases (except for 1/2-shot in the third split). Since the YOLO-Low-shotresults are borrowed from their report, the 1/2-shot objects are probably different from what we use. Extremely-low-shot setups are sensitive to the change of the low-shot object selection and thus, hard to reveal the superiority of low-shot learning algorithms. In the more robust 5/10-shot setups, Meta R-CNN significantly exceeds YOLO-Low-shot (+11.8% in the 5-shot of the first split; +6.8 in the 10-shot of the third split.)
此外,Meta R-CNN在大多数情况下都优于YOLO Low shot(第三组中的1/2-shot除外)。由于YOLO Low shotresults是从他们的报告中借来的,因此1/2shot目标可能与我们使用的不同。极少样本设置对少样本目标选择的变化非常敏感,因此很难显示少样本学习算法的优越性。在更为稳健的5/10shot设置中,Meta R-CNN显著超过了YOLO Low shot(第一组的5-shot占11.8%;第三组的10-shot占6.8%)
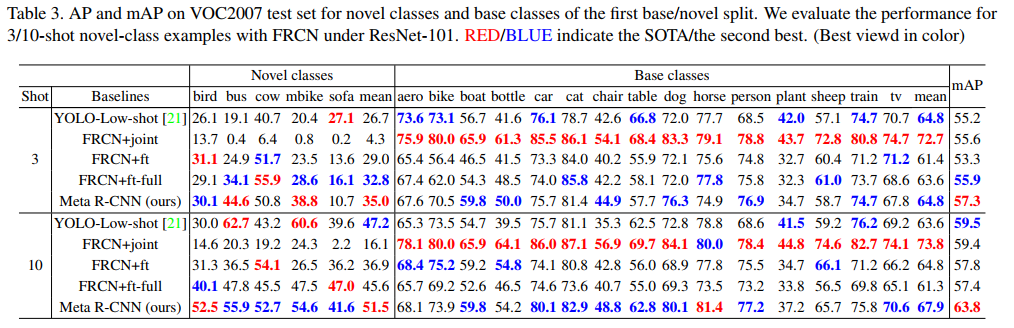
Let’s consider detailed evaluation in Table 3 based on the first base/novel-class split. Note that, FRCN+joint achieved SOTA in base classes, however, at the price of the performance disaster in novel classes (72.7 in base classes yet 4.3 in novel classes given K=3). This sharp contrast caused by the extreme object quantity imbalance in the low-shot setup, further reveal the fragility of FRCN in the generalization problem. On the other hand, we find that Meta R-CNN outperforms YOLO-Low-shot both in base classes and novel classes, which means that Meta R-CNN is the SOTA lowshot detector. Finally, Meta R-CNN outperforms all other baselines in mAP . This observation is significant: Meta R-CNN would not sacrifice the overall performance to make low-shot learning. In Fig 4, we visualize some comparison between FRCN+ft+full and Meta R-CNN on detecting novel-class objects.
让我们考虑基于第一split基类/新类的表3中的详细评估。请注意,FRCN+joint在基类中实现了SOTA,但代价是新类中的性能下降(基类中为72.7,而在新类中为4.3,K=3)。这种由少样本设置中极端目标数量不平衡引起的鲜明对比,进一步揭示了FRCN在泛化问题上的脆弱性。另一方面,我们发现Meta R-CNN在基类和新类中都优于YOLO Low shot,这意味着Meta R-CNN是SOTA 少样本检测器。最后,Meta R-CNN的表现优于mAP中的所有其他基线。这一观察结果意义重大:Meta R-CNN不会牺牲整体表现来进行少样本学习。在图4中,我们可视化了FRCN+ft+full和Meta R-CNN在检测新类目标方面的一些比较。

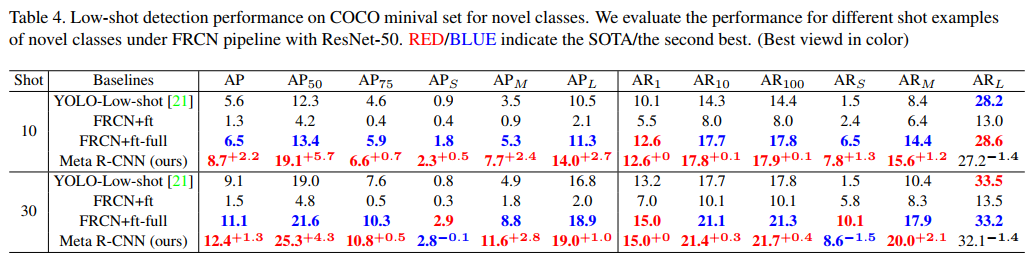
MS COCO. We evaluate 10-shot /30-shot setups on MS COCO [27] benchmark and report the standard COCO metrics. The results on novel classes are presented in Table 4. It shows that Meta R-CNN significantly outperforms other baselines and YOLO-Low-shot. Note that, the performance gain is obtained by our method compared to YOLO-Low-shot (12.4% vs. 11.1%). The improvement is lower than those on PASCAL VOC, since MS COCO is more challenging with more complex scenarios such as occlusion, ambiguities and small objects.
MS COCO。我们在MS COCO[27]基准上评估10/30-shot 设置,并报告标准COCO指标。新类别的结果如表4所示。这表明Meta R-CNN的表现明显优于其他基线和YOLO Low shot。请注意,与YOLO Low shot(12.4%对11.1%)相比,性能增益是通过我们的方法获得的。由于MS COCO在更复杂的场景中更具挑战性,例如遮挡、模糊和小目标,因此改进程度低于PASCAL VOC。
MS COCO to PASCAL. In this cross-dataset low-shot object detection setup, all the baselines are trained with 10shot objects in novel classes on MS COCO while they are evaluated on PASCAL VOC2007 test set. Distinct from the previous experiments that focus on evaluating crosscategory model generalization, this setup further to reveal the cross-domain generalization ability. FRCN+ft and FRCN+ft-full get the detection performances of 19.2% and 31.2% respectively. The low-shot object detector YOLOLow-shot obtains 32.3%. Instead, Meta R-CNN achieves 37.4%, reaping a significant performance gain (approximately 5% mAP) against the second best.
MS COCO to PASCAL。在这个交叉数据集的少样本目标检测设置中,所有基线都在MS COCO上用10shot目标进行训练,在PASCAL VOC2007测试集上进行评估。与以往侧重于评估跨类别模型泛化的实验不同,该设置进一步揭示了跨领域泛化能力。FRCN-ft和FRCN-ft-full的检测性能分别为19.2%和31%。分别为2%。少样本目标探测器YOLOLow-shot获得32.3%. 相反,MetaR-CNN达到37.4%,与次优相比,获得了显著的性能提升(mAP约为5%)。
6.2. Ablation
Here we conduct comprehensive ablation studies to uncover Meta R-CNN. These ablations are based on 3/10-shot object detection performances on PASCAL VOC in the first base/novel split setup.
在这里,我们进行了全面的消融研究,以揭示Meta R-CNN。这些烧蚀基于第一个基类/新类split 设置中PASCAL VOC的3/10shot目标检测性能。
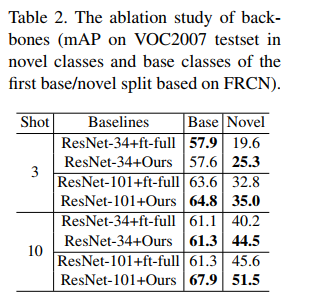
Backbone. We ablate the backbone (i.e. ResNet-34 [17] and ResNet-101 [17]) of Meta R-CNN to observe the object detection performances in base and novel classes (Table 2). It’s observed that our framework significantly outperforms the FRCN-ft-full on base and novel classes across different backbones (large margins of 35.0% vs. 32.8% with ResNet-34 and 51.5% vs. 45.6% with ResNet-101 on novel classes). These verify the potential of Meta R-CNN that can be flexibly-deployed across different backbones and consistently outperforms the baseline methods.
骨干网络 我们切除Meta R-CNN的主干(即ResNet-34[17]和ResNet-101[17]),以观察基类和新类中的目标检测性能(表2)。据观察,我们的框架在不同主干上显著优于FRCN ft全基类和新类(在新类上分别为35.0%和32.8%,以及51.5%和45.6%)。这些验证了Meta R-CNN的潜力,它可以灵活地部署在不同的主干上,并始终优于基线方法。
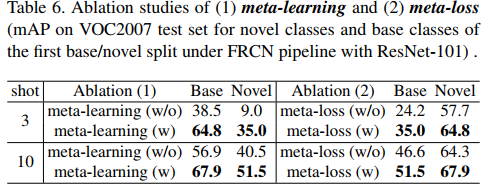
RoI meta-learning. Since Meta R-CNN is formally devised as a meta-learner, it would be important to observe whether it is truly improved by RoI meta-learning. To verify our claim, we ablate Meta R-CNN from two aspects: 1). using meta-learning or not (Ablation 1 in Table 6); 2). meta-learning on full-image or RoI features (Table 5). As illustrated in Table 6 (Ablation 1), meta-learning significantly boosts Meta R-CNN performance by clear large margins both in novel classes (35.0% vs.9.0% in 3-shot; 51.5% vs.40.5% in 10-shot) and in base classes (38.5% vs.64.8% in 3-shot; 67.9% vs.56.9% in 10-shot). As K decreases, the improvement will be more significant. In Table 5, we have observed that full-image meta-learning suffers heavy performance drop compared with RoI meta-learning and moreover, it even performs worse than the Faster R-CNN trained without meta-strategy. It shows that RoI meta-learning indeed encourages the generalization of the R-CNN family.
RoI元学习。由于Meta R-CNN被正式设计为元学习器,因此观察RoI元学习是否真的改善了元学习是很重要的。为了验证我们的说法,我们从两个方面消融了Meta R-CNN:1)。是否使用元学习(表6中的1);2). 关于完整图像或RoI特征的元学习(表5)。如表6(1)所示,元学习显著提高了meta R-CNN的表现,无论是在新类别中(3-shot35.0%对9.0%;10-shot51.5%对40.5%),还是在基类中(3-shot38.5%对64.8%;10-shot67.9%对56.9%)。随着K值的降低,改善将更加显著。在表5中,我们观察到,与RoI元学习相比,全图像元学习的性能严重下降,而且,它的性能甚至比没有元策略训练的Faster R-CNN还要差。这表明RoI元学习确实鼓励了R-CNN家族的推广。


Meta-loss Lmeta(φ). Meta R-CNN takes the control of Faster R-CNN by way of class attentive vectors. Their reasonable diversity would lead to the performance improvement when detecting the objects in different classes. To verify our claim, we ablate the meta-loss Lmeta(φ) used to increase the diversity of class-attentive vectors. The ablation is shown in Table 6 Ablation 2. Obviously, the Meta R-CNN performances in base and novel classes are significantly improved by adding the meta-loss.
元损失Lmeta(φ)。Meta R-CNN通过类注意力向量控制Faster R-CNN。它们合理的多样性将导致在检测不同类别的目标时性能的提高。为了验证我们的说法,我们烧蚀了用于增加类注意向量多样性的元损失Lmeta(φ)。消融见表6-2。显然,通过增加元损失,元R-CNN在基本类和新类中的性能得到了显著改善。
6.3. Low-shot object segmentation
As we demonstrated in our methodology, Meta R-CNN is a versatile meta-learning framework to achieve low-shot object structure prediction, especially, not just limited in the object detection task. To verify our claim, we deploy PRN to change a Mask R-CNN [17] (MRCN) into its Meta RCNN version. This Meta R-CNN using ResNet-50 [19] as its backbone, would be evaluated on the instance-level object segmentation track on MS COCO benchmark. We report the standard COCO metrics based on object detection and segmentation. Noted that, AP in object segmentation is evaluated by using mask IoU. We use the trainval35k images for training and val5k for testing where the 20 classes in PASCAL VOC [9] as novel classes and the remaining 60 categories in COCO [27] as base classes. Base classes have abundant labeled samples with instance segmentation while novel classes only have K-shot annotated bounding boxes and instance segmentation masks. K is set to 5,10 and 20 in our object segmentation experiments.
正如我们在我们的方法中所展示的,Meta R-CNN是一个多功能的元学习框架,可以实现小样本目标结构预测,尤其是不局限于目标检测任务。为了验证我们的说法,我们部署了PRN,将mask R-CNN[17](MRCN)更改为其meta RCNN版本。该meta R-CNN使用ResNet-50[19]作为主干,将在MS COCO基准上的实例级目标分割轨道上进行评估。我们报告了基于目标检测和分割的标准COCO度量。注意,目标分割中的AP是通过使用mask IoU进行评估的。我们使用trainval 35k图像进行训练,使用val5k进行测试,其中PASCAL VOC[9]中的20个类作为新类,COCO[27]中的其余60个类作为基类。基类有大量带有实例分割的标记样本,而新类只有带K-shot注释的边界框和实例分割掩码。在我们的目标分割实验中,K被设置为5、10和20。
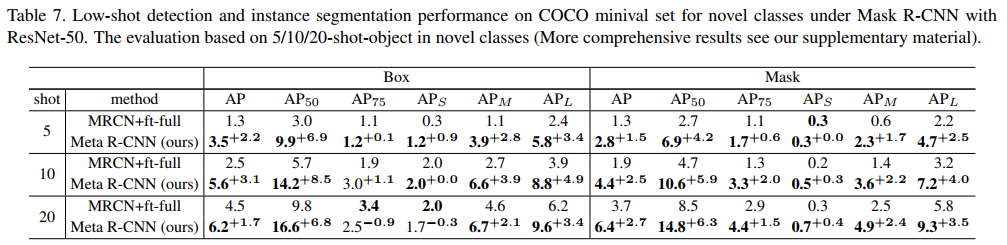
Results. Due to the relatively competitive performances of FRCN+ft+full shown in low-shot object detection, we adopt the same-style training strategy for MRCN, leading to MRCN+ft+full on object detection and instance-level object segmentation results in Table. 7. It could be observed that our proposed Meta R-CNN is consistently superior to MRCN+ft+full across 5,10,20-shot settings with significant margins in low-shot object segmentation tasks. For instance, Meta R-CNN achieves a 1.7% performance improvement (6.2% vs.4.5%) on object detection and 2.7% performance improvement (6.4% vs.3.7%) on instance segmentation. These evidences further demonstrate the superiorityanduniversalityofourMetaR-CNNpresenting. Comprehensive results are found in our supplementary material.
结果 由于FRCN ft full在低镜头目标检测中表现出相对竞争性的性能,我们对MRCN采用了相同的训练策略,导致MRCN ft在目标检测和实例级目标分割结果都在表中7。可以观察到,我们提出的Meta R-CNN在5、10、20 shot设置中始终优于MRCN ft,在少样本目标分割任务中具有显著的裕度。例如,MetaR-CNN实现了1。在目标检测方面,性能提高了7%(6.2%对4.5%),2。实例分割的性能提高了7%(6.4%对3.7%)。这些证据进一步证明了Fourmetar CNN的优越性和普遍性。综合结果见我们的补充材料。
7. Discussion and Future Work
Low-shot object detection/ segmentation are very valuable as their successes would lead to an extensive variety of visual tasks generalizing to newly-emerged concepts without heavily consuming labor annotation. Our work takes an insightful step towards the successes by proposing a flexible and simple yet effective framework, e.g., Meta R-CNN. Standing on the shoulders of Faster/ Mask R-CNN, Meta R-CNN overcomes the shared weakness of existing metalearning algorithms that almost disable to recognize the semantic information entangled with multiple objects. Simultaneously, it endows traditional Faster/ Mask R-CNN with the generalization capability in front of low-shot objects in novel classes. It is lightweight, plug-and-play, and performs impressively in low-shot object detection/ segmentation. It is worth noting that, as Meta R-CNN solely remodels the predictor branches into a meta-learner, it potentially can be extended to a broad range of models [15, 20, 24, 45] in the entire R-CNN family. To this Meta R-CNN might enable visual structure prediction in the more challenging low-shot conditions, e.g., low-shot relationship detection and others.
少样本目标检测/分割是非常有价值的,因为它们的成功将导致大量的视觉任务推广到新出现的概念,而无需耗费大量人力。我们的工作提出了一个灵活、简单但有效的框架,即meta R-CNN。站在Faster/Mask R-CNN的肩膀上,Meta R-CNN克服了现有元学习算法的共同弱点,该算法几乎无法识别与多个目标纠缠的语义信息。同时,它赋予了传统的Faster/ Mask R-CNN在新类中少样本目标面前的泛化能力。它重量轻,即插即用,在少样本目标检测/分割方面表现出色。值得注意的是,由于Meta R-CNN仅将预测分支重塑为元学习者,因此它有可能扩展到整个R-CNN家族中的广泛模型[15、20、24、45]。对此,Meta R-CNN可能在更具挑战性的少样本条件下实现视觉结构预测,例如少样本关系检测等。