Meta-Tracker: Fast and Robust Online Adaptation for Visual Object Trackers
Ԫ���������Ӿ�����������Ŀ��ٺͽ�׳��������Ӧ
ժҪ
���ĸĽ���Ŀǰ���Ƚ���ʹ����������Ӧ���Ӿ���������������ǵĺ��Ĺ����ǻ�������Ԫѧϰ�ķ���������������������Ӧ���ٵij�ʼ������硣Ԫѧϰ������������Ŀ�������ģ���������ܹ�������Ӧ��δ��֡�ж��ض�Ŀ������Ƚ���ģ����������£����ɵ�ģ�ͽ��ص���ڶ�δ��֡���õ������ϣ������������ϱ����Ӳ���Ŀ���С���ֻ�������ͨ����Ԫѧϰ�ڼ�ִ���������µ������õ�������ѵ���ٶ������ӿ졣�����ڸ����ܸ��ٷ����Ļ�������ʾ�����ַ��������ڼ���MDNet����[1]�ͻ�����ص�CREST����[2]���ڱ�������OTB2015[3]��VOT2016[4]�ϵ�ʵ�������������ǵ�Ԫѧϰ�汾��������������������ٶȡ�ȷ�Ժ�³���ԡ�
1 ����
�Ӿ�Ŀ��������ڸ�����ʼ֡��Ŀ��߽���ͼ��֡�����Ͼ�ȷ��λĿ����������������Ŀ��ʶ��������Ŀ�����ͼ�⣩��ȣ����Ӿ�Ŀ������У�ʵ����ʶ����һ����Ҫ���ء����磬����Ȥ�Ķ����������Ⱥ�е�ij���ض���Ա�������Ǹ��㷺����е�ij���ض���Ʒ��������ֹޣ���������ˮ�ޣ�����ˣ�һ����ȷ��Ŀ�����������Ӧ���ܹ��ӱ����Ӳ�����������Ŀ����ʶ���һ���Ŀ�꣬���һ�Ӧ���ܹ��ڿ�������ͬһ�������Ƹ���Դ��ʶ����ض���Ŀ�ꡣ���⣬�ڸ��ٹ�����ѧϰ��ģ��Ӧ�������ģ��Կ��������ӵ�仯���ڵ��ͱ��ζ����µ�Ŀ����۱仯��
Ӧ����Щ��ս��һ�ַ�����Ӧ��������Ӧ�����ٹ����е�Ŀ��ģ�ͣ�����DCF���б�����˲��������ֵ�������������뱳�����������еĵ�һ֡��ʼ����Ȼ���������Ӧ����֡�е�Ŀ�����[1,2,5,6,7,8,9,10]������ǿ���ͨ�����ѧϰ��ʾ�ij��֣����������õĸ�������������������������ŵ㣺���ѧϰ���Ժ�������Ӧ������Ҳ���������ʹ����ȷ���ѵ�������߸����������кܺõ�Ч���ͺܸߵ��ٶȣ��������Ƚ�����������Ӧ��������ȣ����������½�[11,12,13]�����������Ϊ���Ծ�ϸ��ʶ����Ƶ�е��ض�ʵ����
������ѧϰ��������������Ӧ��һ�ֳ��������������ѧϰ�����Ļ�����ѵ��Ŀ��ģ�ͣ����ڴ��ģ���ݼ��Ͻ���Ԥѵ������Щ����Ԥ��ѵ�������Ա�֤����һ��ǿ����㷺�ı�ʾ������ʶ������ͨ�ö��Ӷ�ʹĿ��ģ�͵���Чѵ���ܹ�������ָ����Ŀ��ʵ������������취����Ϊֹȡ������õijɹ��������м�����Ҫ�����д������
���ȣ�ѵ������������������ڳ�ʼ֡�У����Ǹ���Ŀ��һ���߽��������֡�У��������ռ������ͼ������ͼ���Ƕ���ģ���Ϊ���ǻ���������ͬ��Ŀ��ͱ��������⣬���ΪĿ����۽������ģ�͵�����[1,2]ʹ�����ø�����ս�ԣ���Ϊ���ģ����֪������С���ݼ��Ϲ�����ϡ���ˣ�������ѧϰ�����Ļ�����ѵ����Ŀ��ģ����ʱ���ܵ�Ӱ�죬��Ϊ�������ʺϱ����Ӳ���Ŀ���С���ֻ���������������������о�����˽����Щ����ĸ��ַ�����һЩ��������ʹ�ô������й���������������������[1]�����Ӿ���[6]���ռ�в�ģ��[2]��ϲ���������Ϣ[14]��
��Σ���������Ƚ��ĸ������ڳ�ʼѵ���λ����˴���ʱ��[1,2,6]�����������о�����˿���ѵ������[6,7]��������Ȼ��һ��ƿ������Ŀ����ٵ�����ʵ��Ӧ���У����أ���Ҫʵʱ����������Ӧ�ó���IJ�ͬ������ڳ�ʼ֡������ζ����������ʧ�ܡ���һ���棬δ��ȫѵ���ij�ʼĿ��ģ�Ϳ��ܻ�Ӱ��δ��֡�����ܣ��������������£��ᵼ�����к���֡��ʧ�ܡ���ˣ��ڳ�ʼ֡���ٻ��³��Ŀ��ģ���Ƿdz�����ġ�
��������У����������Ӧ����Щ��ս��һ���Ժ�ԭ���Է����������Ԫѧϰ��learning to learn���о�[15,16,17,18,19,20]��������������ͼѧϰ��λ��Ŀ��ģ�͡��ؼ���˼����ѵ��Ŀ��ģ�ͣ�ʹ���ܹ���δ���Ŀ���еõ��ܺõ��ƹ���������[1,2,5,6,7,8,9,10]�У�Ŀ��ģ�ͱ�ѵ������С����ǰ֡�ϵ���ʧ��������ʹģ�ʹﵽ��һ�����Ž⣬Ҳ��һ����ζ������δ����֡�п��Ժܺõع������෴�����ǽ���ʹ������δ��֡�Ĵ����źš���Ԫѵ���Σ����ǵ�Ŀ�����ҵ�һ��ͨ�õij�ʼ��ʾ���ݶȷ���ʹĿ��ģ���ܹ�רע�ڶ�δ��֡���õ����������⣬���Ԫѵ���������ڱ��������Ӧ��ǰ֡�еĸ��š����⣬ͨ����Ԫѵ���ڼ�ǿ��ִ�и��µ����������õ��������ڳ�ʼ���ڼ�ѵ���ٶ������ӿ졣
��������ķ�������Ӧ�����κλ���ѧϰ�ĸ�������ֻ���Լ��ġ����Ǵӻ��ڷ������ĸ��������������٣������ѡ�����������Ƚ��ĸ�����MDNet[1]�ͻ�����صĸ�����CREST[2]��ʵ�������������ǵ�Ԫѧϰ�汾�ĸ��������Ժܿ����Ӧ��һ֡��һ�ε�����ͬʱ���ȷ�Ժ�³���ԡ���ע�⣬��ʹû��ʹ��һЩ�ֹ���Ƶ�ѵ�����������ӵļܹ���ƺ�ԭʼ�������ij�����ѡ��Ҳ����������һ�㡣�����֮�����������һ�ּķ�����ʹ�dz��õĸ��������ã�������Ҫ̫���Ŭ��������ʾ���������ֲ�ͬ�ĸ��ټܹ��ϵijɹ���������DZ�ڵ��ձ������ԡ�
2 ��ع���
���߸����������ڼ���Ч�ʺ�ʶ���������������߸�����ʹ������˲�����Ϊ�㷨�ĺ�ܡ���MOSSE�����������ڳɹ�[10]�У����Ƿ����˴����ı����[7] ����ѭ������ʹ�����Ч��ͨ������˹��߽������һ���Ľ�[21,22]��ʹ����������Ϣ[14,23]�����ںͳ����ڴ�[24,25]�ͱ�������[26]�ȷ���������������⡣�����������ѧϰ������ʼ������˲����з�����Ҫ����[1,2,5,6,8,27,28]����һ���棬ͨ�������ٵķ���ͨ��ѧϰһ������������ȡ������Ŀ�������Χ����ͼ��顣��[9]����������ѧϰ�����Ѿ�������������ʵ��ѧϰ[29]���ṹ�����֧��������[30]����������[31]��ģ�ͼ���[32]�������MDNet[1]���������������ȷ�����������˸��ߵľ��ȡ�
���߸�����������ļ����о�����������ǿ������ѧϰ���ܣ����ǿ����ڲ��������ߵ���������¹�����ȷ�ĸ�����[11,12,13]���������������ȡһ��СĿ��ͼ����һ��������ͼ��飬ֱ�ӻع�Ŀ��λ��[12]��ͨ����ز�����һ����Ӧͼ[11]��Ϊ�˿���ʱ����Ϣ����[34,35,36,37]��Ҳ�о��˵ݹ����硣
Ԫѧϰ�����ǻ���ѧϰ����Ӧ�õ�һ�������������ⲻ��һ���µĸ���[38,39,40,41]��������������о��ɹ�����ʾ���dz���ϣ���Ľ����ͬʱҲ��ʾ�������ѧϰ�ijɹ���[17,42,43,44]��ͼ��Ԫѧϰ�������ȡ���ֹ����Ƶ��Ż��㷨��[16] ������뷨�����һ����ѧϰ���⡣����Ŀ���Ǹ���ѧϰ������ѭԪѧϰ���IJ���ʱ�Բ���ͼ����з����ȷ����ѧϰ��ѵĸ��²��ԡ�����ɾ�����е��Ż��㷨�����罫�ص�������ʺ������㷨��ѧϰ��ʼ���ϡ�[19] ���ų�ʼ������һ��ѧϰ�����Ż��㷨�IJ�������������ܵķ�����ͬ��Ҳ��һЩ�о�ֱ��Ԥ��ģ�Ͳ��������������Ż�����[37,45,46]��

ͼ1�����ǵ��Ӿ�Ŀ�����Ԫѵ��������Ԫѵ������������ļ���ͼ������ÿһ�ε�������������ݵ�һ֡�����ʧ�õ��ݶȣ���Ԫ���³����ʹ����Щ�ݶȸ��¸������IJ�����Ϊ�������ȶ��Ժ�³���ԣ�ʹ��δ��֡������Ԫ��ʼֵ�趨���Ԫ��������ݶ�w.r.t����������������ʧ������ϸ�ڼ���3�ڡ�
3 �Ӿ�Ŀ���������Ԫѧϰ
����һ�����У����ǽ������Ӿ���������������ͨ��Ԫѵ����ܡ�����Ӧ����ÿ������������ϸ��Ϣ����4�ڡ�
3.1 ����
һ�����͵ĸ��ٳ����ǣ������еij�ʼ֡�У�����ģ����Ӧ��Ŀ����Χָ���Ŀ��û��������Ϳ����Ż�������ʹ������Ӧ/ѵ���ܹ�������ɣ��Ӷ�ʹ���ɵ�ģ�Ͷ�Ŀ��仯�ͻ����仯����³���ԡ�Ȼ�����ø���ģ��Ԥ�����֡�е�Ŀ��λ�á�Ȼ��Ԥ���Ŀ��λ�ú�ͼ��洢�����ݿ��У������ݸ��ԵIJ��Զ������ռ��������ݸ���ģ�͡�
һ���ؼ��Ķ����ǽ���Щʵ�ʵĸ��ٳ�������Ԫѧϰ���̡�����������Ŀ����Ԥ��δ��֡�е�Ŀ��λ�á���ˣ�ѧϰ������һ����Ŀ��ĸ������ǿ�ȡ�ġ����磬������ǿ��Թ۲�δ��֡�еı仯����ô���ǿ��Թ�������׳��Ŀ��ģ�ͣ�����ֹ�����뵱ǰĿ����ۻ��Ӳ�������ϡ����ǿ����˺�һ�����۲�����Ƶ�����еĸ������������������Ƿ��ܺܺõظ������ҳ����Ƿ�ɢ��ԭ����Ӧ�ص�����Ӧ���̡�

3.2 ͨ�õ����߸�����
Ϊ�������ڸ��ָ������������߸��ٵ���һ��ʽ�����˸��������Ǹ������еĹؼ�������y^=F(x,��)\hat{y}=F(x,\theta )y^?=F(x,��)����������x������Ŀ����Χ��ͼ����ͼ�� I ���Լٶ�Ŀ��Ϊ���ĵIJü�ͼ���Լ������������ȣ���������ǩ�Ĺ���ֵy^\hat{y}y^?��������Ӧͼ��֡��ָʾĿ��λ�õ���Ϣ�����ڳ�ʼ����x0x_{0}x0?�Ӿ���ָ��y0y_{0}y0?�ij�ʼ֡I0I_{0}I0?��ʼ�����ǣ����Ƶأ������1(x0,y0)��_{1}(x_{0},y_{0})��1?(x0?,y0?)����1��_{1}��1?��������ʧ��L(F(x0,��1),y0)L(F(x_{0},��_{1}),y_{0})L(F(x0?,��1?),y0?)������ģ��Ԥ��ָ����ǩ�ij̶ȡ����ڸ����ڼ�ĸ��£����Ǵӵ�j-1֡��ȡ������j��_{j}��j?�����ҵ�y^j=F(xj,��j)\hat{y}_{j}=F(x_{j},��_{j})y^?j?=F(xj?,��j?)��Ȼ���ҵ�������ʧ����j+1��_{j+1}��j+1?��Ȼ�����ǿ��Խ�ת��y^j\hat{y}_{j}y^?j?�ϲ���Ŀ��λ�õ��ض������Լ�ʱ��ƽ�����С����ǿ����ڳ�ʼ֡��д����x0x_{0}x0?��y0y_{0}y0?��ʼ���ĸ��ٹ��̣�Ȼ�������֡I1...InI_{1}...I_{n}I1?...In?���и��ٺ��£���Ϊ����(��1(x0,y0),I1,��In)(��_{1}(x_{0},y_{0}),I_{1},��I_{n})(��1?(x0?,y0?),I1?,��In?)�������Ϊy^n\hat{y}_{n}y^?n?����n֡��ָʾĿ��λ�ã��еı�ǩ����ֵ�͵�n֮֡���ģ�Ͳ�����n+1��_{n+1}��n+1?��
3.3 Ԫѧϰ�㷨
���ǵ�Ԫѵ������������Ŀ�ꡣһ���Ƕ������ϵĸ��������г�ʼ���������п���ͨ������0��_{0}��0?��ʼ��Ӧ�����������������ĸ��º���MMM��һ�λ�����������ִ�С���һ��Ŀ���ǵõ��ĸ��������Ժ��֡����ȷ�ͽ�׳�ġ�
�ݶ��½�ʽ���º���M�ɦ���������
M(��,����L;��)=��?���Ѩ���LM\left ( \theta ,\bigtriangledown_{\theta}L;\alpha \right )=\theta -\alpha \odot \bigtriangledown _{\theta }LM(��,����?L;��)=��?��������?L ��1��
���Ц��������������[19]�Ĵ�С��ͬ��L��һ����ʧ������������Ԫ�صij˻�����������һ������ֵ�������ǿ�ѧϰ��[20]���ֶ��̶���[15]�����ǵľ��鷢�֣������ǵ������У�ÿ��������ϵ��������Ч�ġ�
���ǵ�Ԫѵ���㷨��ͨ������������Ƶ�����г�ʼ������ѧϰ���ij�ʼģ��Ӧ������������ǰ��֡��Ȼ������������0��_{0}��0?�����������Ӷ��ҵ�һ���õ���0��_{0}��0?��������������ʼģ��Ӧ����������һ֡������������Ŀ�꣬��ģ��Ӧ���㹻��׳���ܹ�������֡��֡�ı仯��������������ڸ��ٹ����У��������Ҫ̫��������ҲӦ�ý��п��ٸ��¡�
�ڶ������Ƶ�е������ʼ֡���в���֮�����ǶԴ���00=��0\theta _{0}^{0}=\theta _{0}��00?=��0?��ʼ�ij�ʼ�������Ż�������ת��������������(xj,yj)(x_{j},y_{j})(xj?,yj?)���Ż���һ����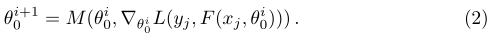
�ò�����ظ���Ԥ������T�����ҵ���1(xj,yj)=��0T��_{1}(x_{j},y_{j})=��_{0}^{T}��1?(xj?,yj?)=��0T?��Ȼ�����������ȡһ��δ��֡Ij+��I_{j+��}Ij+��?���������ڸ�δ��֡�ϵij�ʼ֡��ѵ����ģ�ͣ��õ���y^j+��=F(xj+��,��1)\hat{y}_{j+��}=F(x_{j+��},��_{1})y^?j+��?=F(xj+��?,��1?)��
��Խ��Ŀ�����仯Խ�����仯ҲԽ�����ڣ����ǿ��Ը���δ��֡��ѵ���ĸ�����������������ʧ��Ŀ�꺯������Ϊ
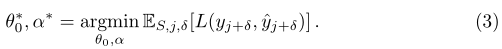
����ʹ��ADAM[47]�ݶ��½��㷨�����Ż���ע����0��_{0}��0?����������һ��С�����IJ�ͬƬ�����ǹ̶��ģ�������01...��0T��_{0}^{1}...��_{0}^{T}��01?...��0T?��ÿ���ж��ᷢ���仯��Ϊ�˼���Ŀ�꺯��������0��_{0}��0?�����������ݶȣ���Ҫ����߽��ݶȣ��ݶȺ������ݶȣ������ּ��㷽����������о��еõ���Ӧ��[15,48,49]�������Զ����컯������[50]�����ǿ��Ժ����ؼ������һ�㡣����ϸ�ڽ����㷨1�н��͡�
���º���֡�Ĺ�������������߸���������������Ԫѵ������������������4�ڣ������ڸ���Ŀ��ģ�ͣ�����Ӧ���ٹ������Լ��ռ�����ʾ�������ǿ��Լ�ʹ��Ԫѵ����������������ģ�ͣ���j=��j?1?����?��j?1L��_{j}=��_{j?1}?��\odot ?_{��_{j?1}}L��j?=��j?1??����?��j?1??L��Ϊ�˼�������ֻ�����һ�ε�������Ȼ�����������ڽϳ������л���зdz�С��֡��֡�仯�������Ϸ�ɢ��������Ϊ����Ҫ����Ϊ����ѵ���������ڳ�ʼ֡���п�����Ӧ�������������ֵ��Խϴ���²��ȶ���������Ϊ����[20]�б��������Ƶ��������ڲ�ͬ���������У�����������������0��_{0}��0?���ʱ���ȶ��ģ������ǿ��Խ�����֡�ĸ��¹�����Ϊ��j=��0?����?��0L��_{j}=��_{0}?��\odot ?_{��_{0}}L��j?=��0??����?��0??L����[20]��ʾ�����ǻ����Խ����ֲ��Խ����������j=��(��j?1?����?��j?1L)+(1?��)(��0?����?��0L����_{j}=��(��_{j?1}-��\odot?_{��_{j?1}}L)+(1-��)(��_{0}-��\odot?_{��_{0}}L����j?=��(��j?1??����?��j?1??L)+(1?��)(��0??����?��0??L������Ȼ���ǿ�������Щ������������ȶ���������Ϊ����û��һ�ֲ��Աȼ�������һ��ѧϰ���ʸ��á���ˣ������ҵ�����֡��ѧϰ�ʣ�Ȼ��ʹ�����е��Ż��㷨����ģ�ͣ�������ԭʼ�汾�ĸ�������������
4 Ԫ������
�ڱ����У����ǽ�չʾ��������Ƚ��ĸ�������ʵ�����������Ԫѧϰ����������ѡ�������ֲ�ͬ���͵ĸ�������һ��������ظ�����CREST[2]����һ�����Լ�������MDNet[1]��
4.1 ��ظ�������Ԫѵ��
CREST���͵�����˲�Ŀ�궨������
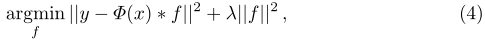
����fff������˲�����*�Ǿ������㣬����������ȡ��������CNN��x����Ŀ��Ϊ���ĵIJü�ͼ��y(H��W)y(H��W)y(H��W)�Ǹ�˹��״����Ӧͼ������HHH��WWW�ֱ��Ǹ߶ȺͿ��ȡ��ü����ͼ��ͨ����Ŀ����������������ṩ�㹻�ı�����Ϣ��һ������ѵ��������˲�������һ���µ�δ��֡�ϵ�Ŀ�궨λ�����ҵ����������Ӧֵ������(h,w)(h,w)(h,w)��

ʽ�У�y^=��(xnew)?f\hat{y}=��(x_{new})*fy^?=��(xnew?)?f����y^(h,w)\hat{y}(h,w)y^?(h,w)��ʾyyy��(h,w)(h,w)(h,w)�����е�Ԫ�ء�CRESTʹ��������˲�Ŀ��ı仯������Ϊ
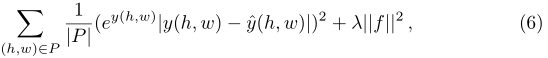
����P=P=P={
(h,w)�O�Oy(h,w)?y^(h,w)�O>0.1(h,w)\mid\left | y(h,w)-\hat{y}(h,w) \right |>0.1(h,w)�O�Oy(h,w)?y^?(h,w)�O>0.1}���⽫����ģ��ע��ЩԶ����ʵλ�õIJ��֡�
ͨ��������˲����������Ϊ�����㣬������Ч�ؽ��伯�ɵ�CNN�����[2]����ʹ�����ǿ��Ժ����������µ�ģ�飬��Ϊ�Ż����Ժܺõ���ɱ��ݶ��½��ڶ˵��˵ķ�ʽ�����Dz���ʱ�ղв�ģ�飬�Ա���Ŀ��ģ��������۱仯���˻������ǻ�����˸��ӵij�ʼ����ѧϰ���ʺ�Ȩ��˥��������������ʱ�ղв�ģ����1000����Ȩ��˥����������û����Щ����������������£����ǵ�Ŀ����ͨ�������Ԫѧϰ������ѧϰһ��³���ĵ�������˲�������CREST���������뵽�������Ԫѵ���������������Ҫ���⣬���ǽ���������½��н������ǵĽ��������
Ԫѧϰά��������CRESTʹ��PCA����ȡ��CNN������ͨ������512�����ٵ�64�����ⲻ�������˼������������������������˲�����³���ԡ��ڳ�ʼ֡��ִ�����ɷַ�������������ʹ��ѧϰ��ͶӰ����Ԫѵ������˲���ʱ����ͳ���һ�����⡣������ͼΪ���Բ�ͬ�¼�������Ŀ���ҵ�����˲�����ȫ�ֳ�ʼ����Ȼ�������ɷַ�����ı�ÿ�����еĻ�����ʹ����ÿ�α仯��ͶӰ�����ռ��������ȫ�ֳ�ʼ�������ǽ���ѧϰ����������ά������CREST�У����ǿ�����������ȡ֮�����1x1�����㣬�ò��ȨֵҲ������Ԫѧϰ������������˲���һ�����Ԫѧϰ������ѵ������ˣ�Ԫѵ������е���0��_{0}��0?�ֱ�����0d��_{0_{d}}��0d??����0f��_{0_{f}}��0f??����ά����������˲�����ɡ�
�淶��С��ʼ��������˲����Ĵ�Сȡ����Ŀ����״�ʹ�С��Ϊ��Ԫѵ������˲�����0f��_{0_{f}}��0f??�Ĺ̶���С��ʼ��������Ӧ�ý����ж����������ͬ��С����ͬ�����ȡ�Ȼ������������Ŀ���ʧ�棬������֪�ή��ʶ������[51,52]��Ϊ�˳����������˲������������������ʹ�ñ��ߴ��ʼ�����������С�ͳ�������Ϊѵ�����ݼ��ж����ƽ��ֵ���ڱ��ߴ��ʼ���Ļ����ϣ����ǽ���Ť��Ϊÿ�������¼���Ŀ���������Ӧ���ض��ߴ磬������^0f=Warp(��0f)\hat{��}_{0_{f}}=Warp(��_{0_{f}})��^0f??=Warp(��0f??)������ʹ�ÿ�˫���Բ�������[53]ͨ���ݶ�һֱ����0f��_{0_{f}}��0f??��
���������������������CRESTԪѵ������У�F(xj,��)F(x_{j},��)F(xj?,��)���ڴ�����֡IjI_{j}Ij?�л�ȡһ���ü�ͼ��xjx_{j}xj?��ͨ��CNN������ȡ����Ȼ����н�ά����Ȩ����0d��_{0_{d}}��0d??��1x1��������Ȼ������˲�����0f��_{0_{f}}��0f??�������������Ӧ������������˲�����^0f\hat{��}_{0_{f}}��^0f??������Ӧͼy^j\hat{y}_{j}y^?j?��ͼ2a����
4.2 �����������ٵ�Ԫѵ��
MDNet��MDNet�ǻ���һ���ɼ������������ȫ���Ӳ���ɵĶ�ֵCNN�����������߽β��ö���ѵ�������Է���������Ԥѵ�����ڳ�ʼ֡�����������ʼ�����һ����ȫ���ӵIJ㣬���ô�����������������ѵ����Լ30�ε�����ͼ2b��������֡�е�Ŀ��λ���ɵ÷���ߵ���������ľ��ο������ƽ��ֵȷ�������ڸ��ٹ����вɼ����������������ڸ��·�����������Ԥѵ����ʵ��³���Ե�һ���ؼ����أ����Dz�����һ�־��й����Ե�dropout�������Ͳ�ͬ��ε�ѧϰ���ʣ��Խ�һ������Ե�ǰĿ����۵Ĺ�����ϡ���û����Щ����������ѵ��������������£����ǵ�Ŀ���ǽ������������Ԫѧϰ���������³���ҿ��ٵ�����Ӧ��������
Ԫѵ������Ҳ���Ժ����ز��뵽�����Ԫѧϰ����С�F(xj;��)F(x_{j};��)F(xj?;��)ȡ����֡IjI_{j}Ij?��yj��y_{j}��yj?��{
0,10,10,1}N����Ӧ�ı�ǩ���е�xjx_{j}xj?��RN��D��Ϊ����ͼ��飬����D�ǿ�Ĵ�С��N�ǿ����Ŀ��Ȼ��Ŀ���ͨ��CNN����������ʧ����L��һ���Ľ�������ʧ ?��K=1Nyjklog(Fk(xj;��))-\sum_{K=1}^{N}y_{j}^{k}log(F^{k}(x_{j};\theta ))?��K=1N?yjk?log(Fk(xj?;��))��
��ǩϴ�ơ���Ȼ���ģ����Ƶ������ݼ������ḻ����Ƶ����仯������������ֹͼ�����ݼ���ȣ�Ŀ��������������ޡ�����ܻᵼ��һ�����CNN��������ס���ݼ��е����ж���ʵ���������¿����Ķ������Ϊ������Ϊ�˱���������⣬���Dz�����[18]�н���ı�ǩϴ�Ƽ��ɡ�ÿ����������һ�����ټ�ʱ�����Ƕ���Ա�ǩ����ϴ�ƣ�����ζ����ʱ�������ı�ǩ��Ϊ0������1���������ı�ǩ��Ϊ1������0��������ɹ���������ͨ���鿴��ǰ��ѵ��ʾ���������Ǽ�ס�ض���Ŀ����ۣ���ѧϰ�������Ŀ�����ͱ�����
5 ʵ��
ʵ�鲿������Ȥ�Ŀ������в��ġ�
6 �ܽ�ͽ��Ĺ���
���������һ������Ԫѧϰ�Ľ����������������߸������ķ���������ͨ���Ľ��������Ƚ��ĸ�������CREST��MDNet����֤����һ�㡣��Ԫѵ���Σ�����ѧϰ��θ�������δ��֡�Ĵ����ź������³���ij�ʼĿ��ģ�͡�ʵ�������������ָ��������ٶȡ����Ⱥ�³���Է��涼�иĽ���������ļ�����ͨ�õģ��������������Ҳ���Դ������档
��Ŀ������㷨�У����˱����ص��о���Ŀ����۽�ģ�⣬����������������Ҫ���ء����磬��ʱ���ø���һ��ģ��[56]����ι������ݿ�[6]���Լ���ζ��������ռ䡣��Щ������ʱ��Ŀ����۽�ģ����Ҫ����δ���Ĺ����У����ǽ��齫��Щ��Ϊѧϰ��Ԫѧϰ��һ������������