目录
- 一、haproxy的读写分离
- 二、pacemaker管理hapoxy集群
- 三、配置fence防止文件系统脑裂
一、haproxy的读写分离
server2之前安装过php,现在给server3安装php

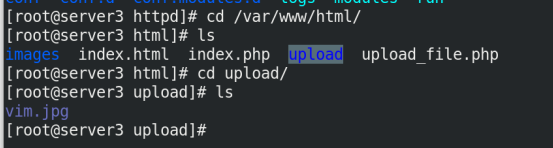
将测试文件放到共享目录下,并修改upload目录权限为777

修改upload_file.php文件的图片大小

修改haproxy中主配置文件 /etc/haproxy/haproxy.cfg,设定当写入数据时由server3提供服务,其余操作(读)默认由server2提供服务
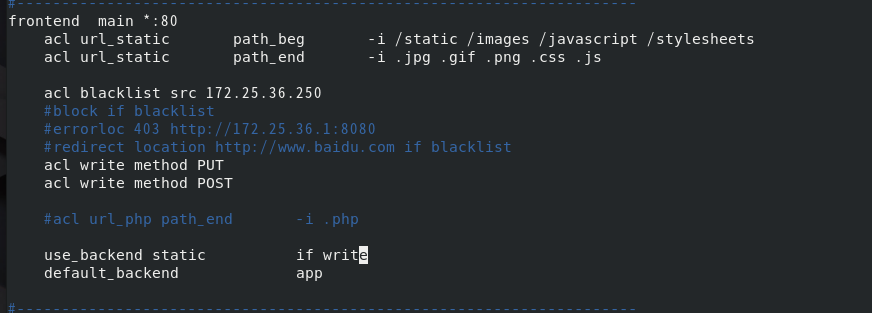
将测试文件复制给server3的共享目录

测试访问(此时访问的是server2的php)
选择图片进行上传
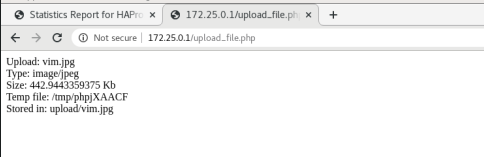
此时可以看到,图片被上传到server3的upload里,而server2上没有
二、pacemaker管理hapoxy集群
pacemaker是高可用集群资源管理器,从逻辑功能而言, pacemaker在集群管理员所定义的资源规则驱动下,负责集群中软件服务的全生命周期管理,这种管理甚至包括整个软件系统以及软件系统彼此之间的交互。
真机的addons目录里由高可用的相关插件

修改软件仓库
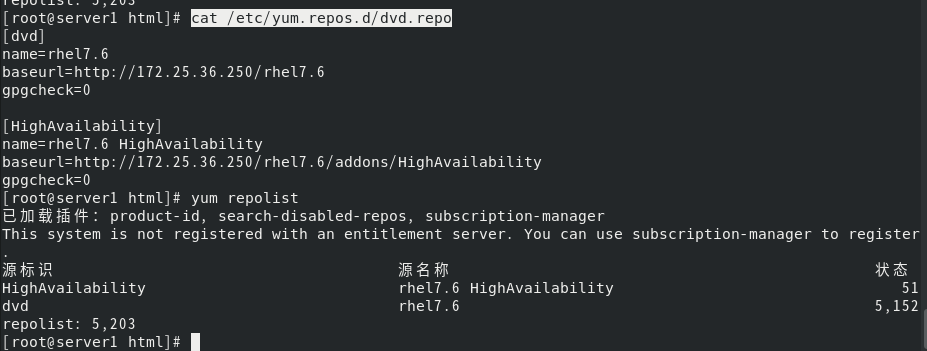
安装高可用插件

server1和server4实现免密登陆
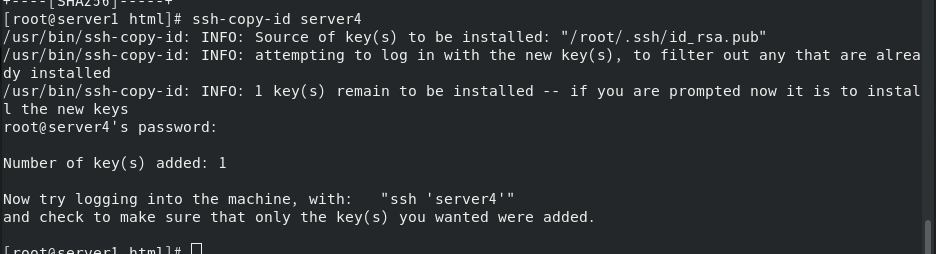
将server1的仓库文件复制给server4,server4上也安装同样的高可用插件

在应用 pcs 进行管理的 pacemaker 集群中,每个节点都会启动一个 pcsd 守护进程

修改高可用集群(High Availability Cluster)hacluster认证用户密码
进行集群认证

在同一个节点上使用pcs集群设置来生成和同步crosync配置(设定集群名为mycluster,包含server1、 server4节点)
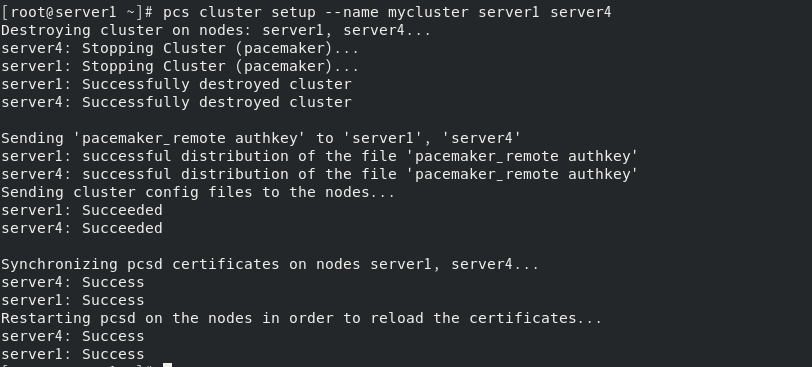
开启集群服务

设定开机自启动

查看集群状态(有一条警告)
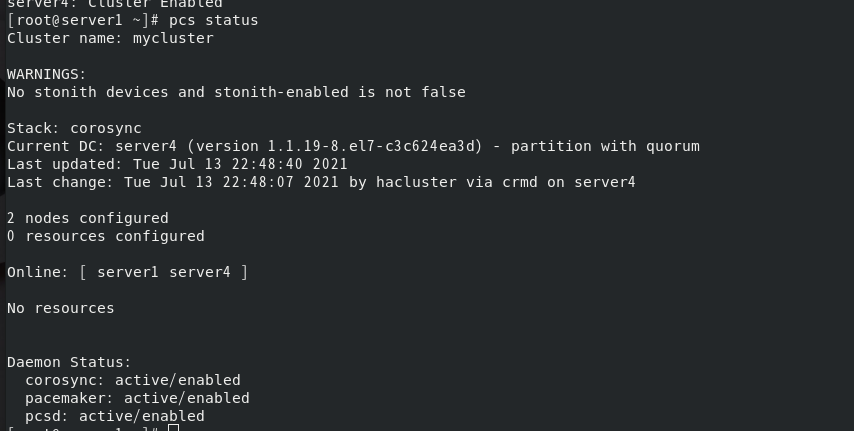
此时会导致查看集群状态报错

因此关闭stonith,此时没有警告信息
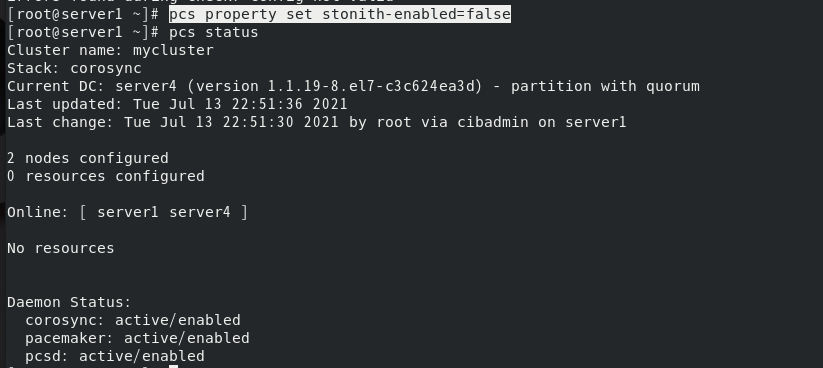
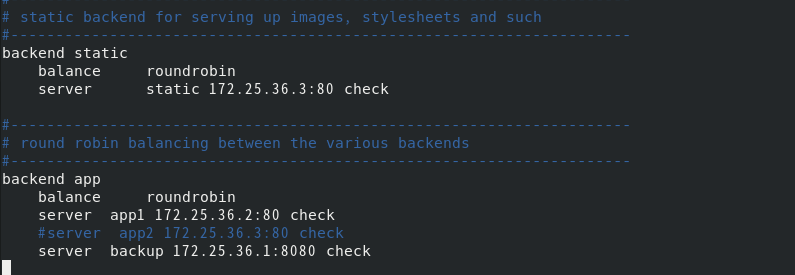
server4安装haproxy


将server1的配置文件给server4一份

server4开启haproxy服务

访问成功
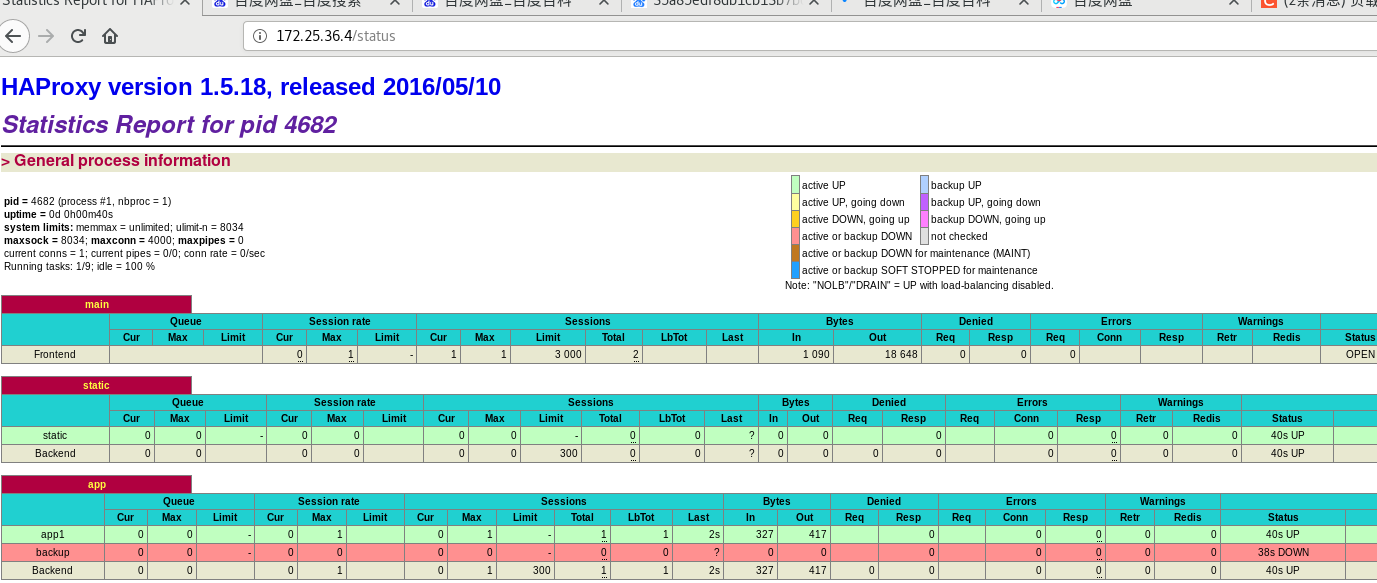
查看pcs支持的脚本和提供者
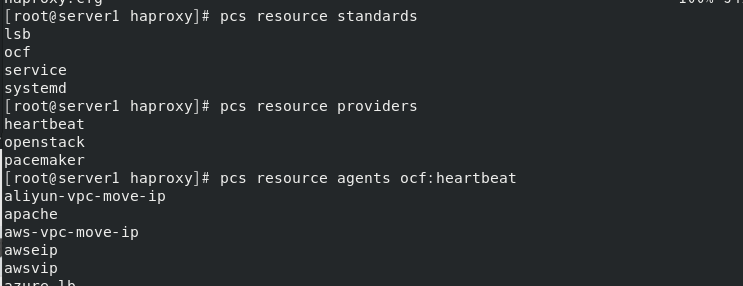
为server1添加 vip ,进行高可用测试
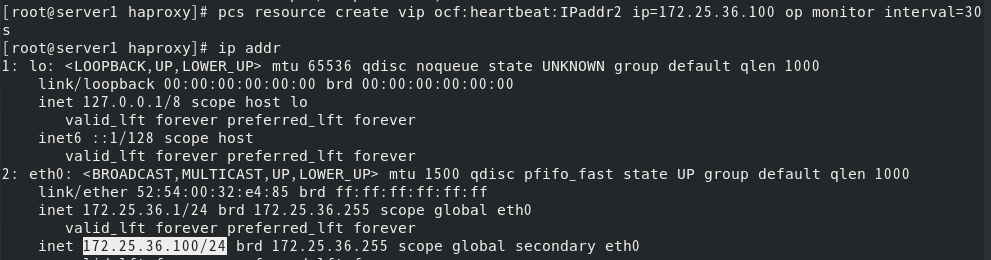
查看状态,可以看到vip在server1上:
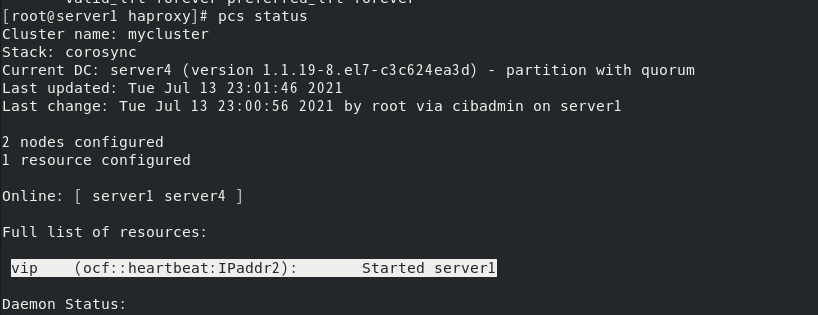
访问vip可以看到默认server2在提供服务
将节点暂停
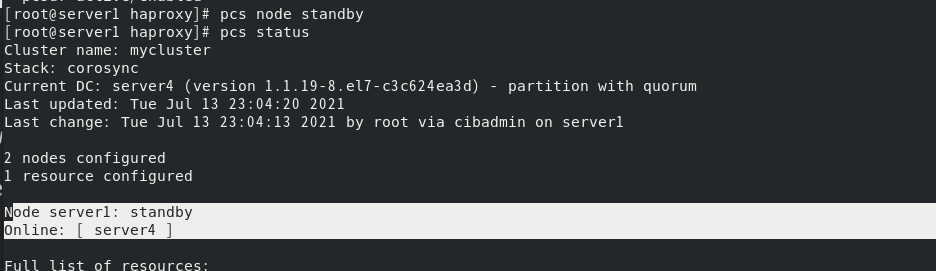
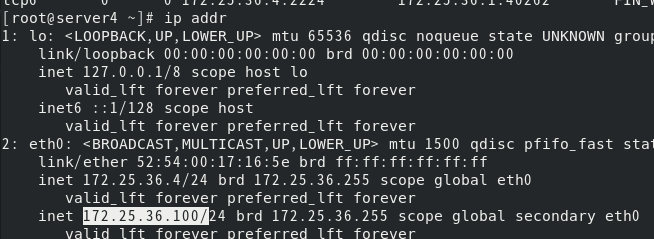
由于高可用,vip会飘到server4上
此时将server4上的vip删掉
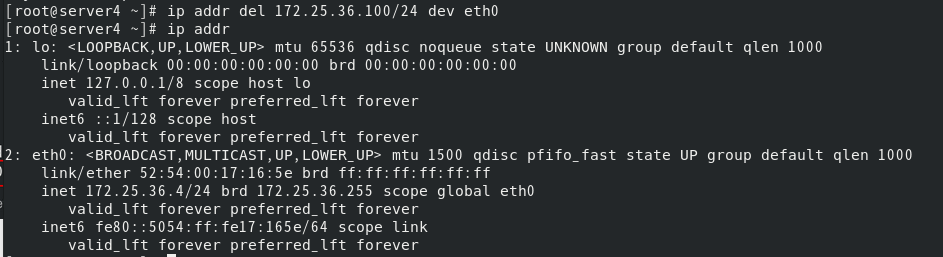
30s后,server4上又会自动添加vip
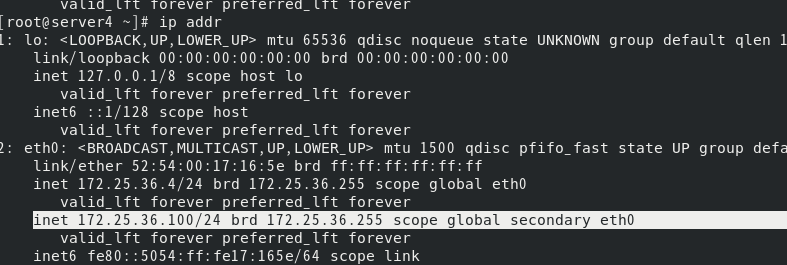
此时查看pcs状态,会有警告信息
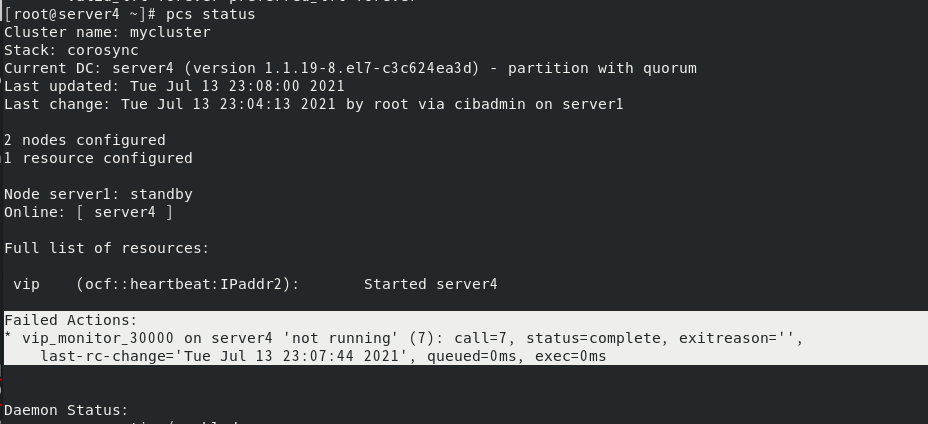
将haproxy服务交给集群之前,需要关闭服务并且关闭开机自启

将haproxy与集群建立连接,将haproxy添加到resource中
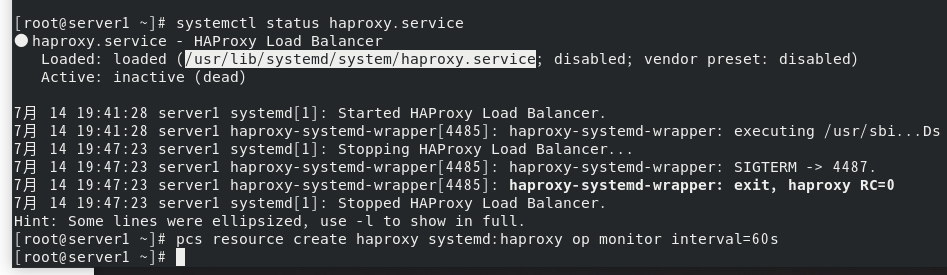
查看pcs状态,但此时ip 和haproxy分别在不同的虚拟机
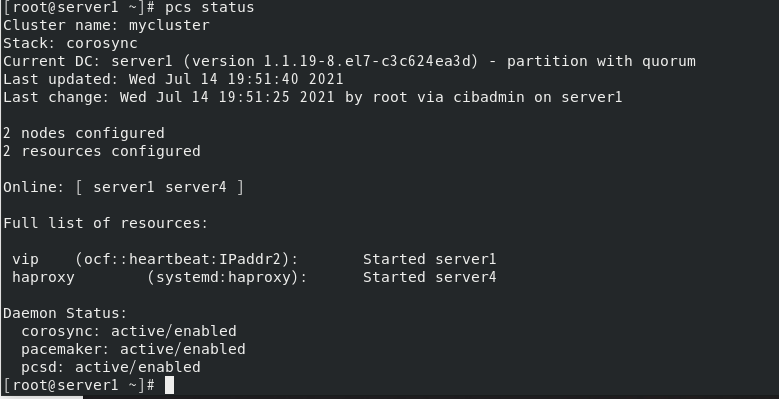
因此我们需要把这两个参数所在的虚拟机固定下来,这样才能实现高可用;
建立资源管理组,约束资源,控制资源启动顺序,使其运行在统一服务器上
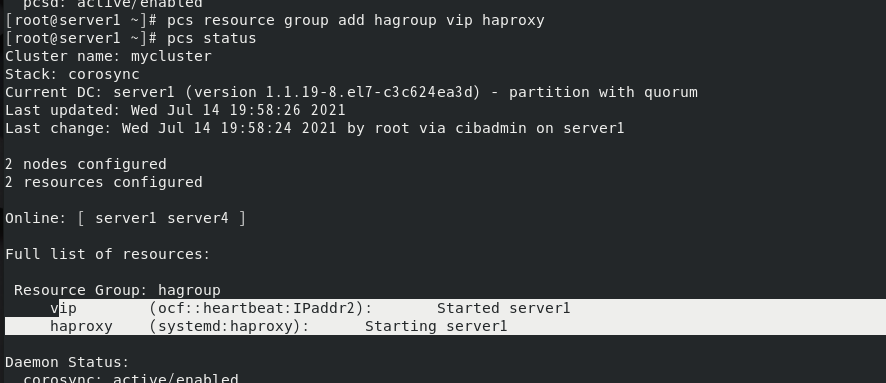
此时暂停server1节点

vip和haproxy都会转移到server4上
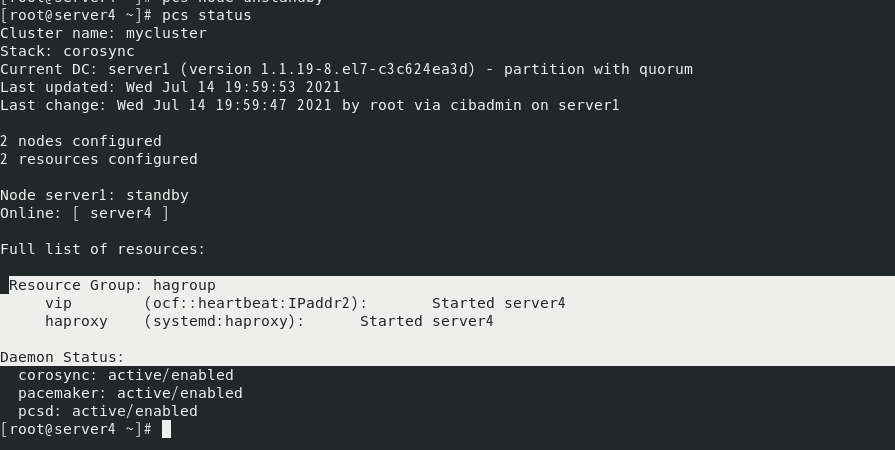
开启server1节点后

资源也不会回切
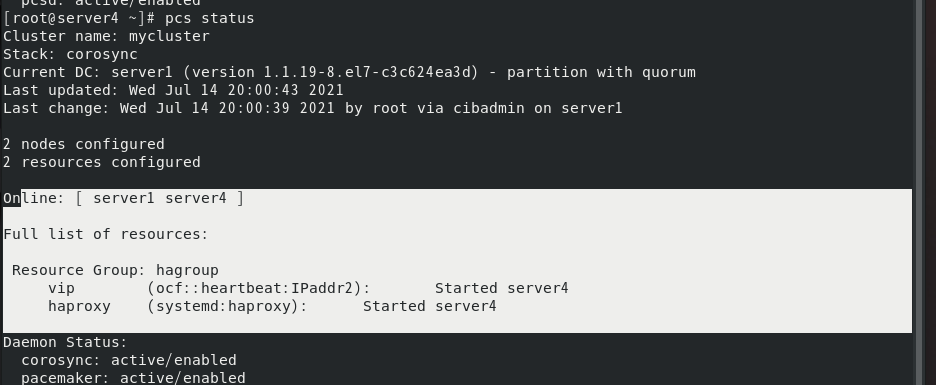
如果将server4的haproxy服务停掉
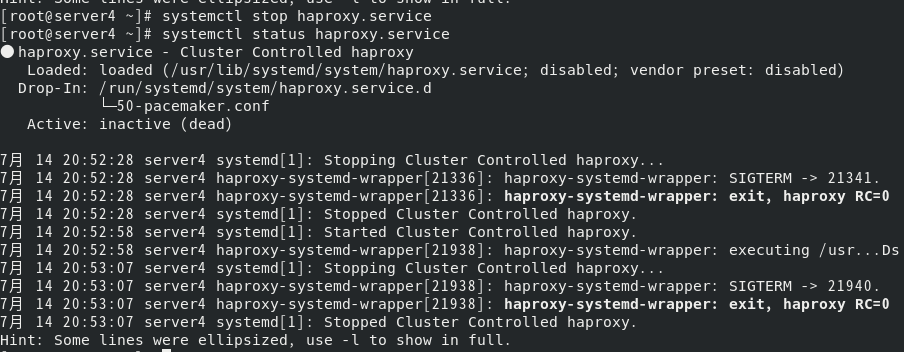
会发现由关于server4的失败提示
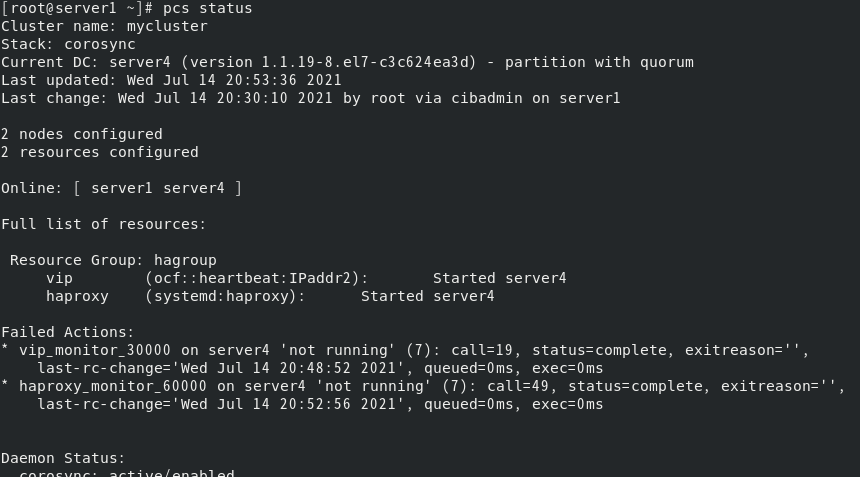
但是等一会再查看就会发现server4的haproxy服务又重启了,这是因为高可用会先检测状态,再启动服务,若是启动失败才会切换master。
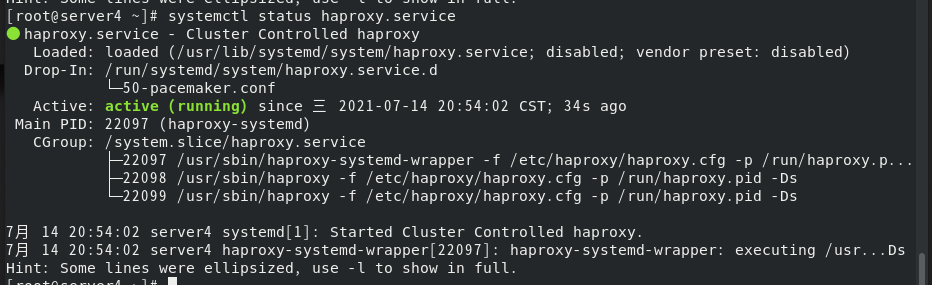
如果我们故意让server4的系统崩溃(crush)

此时服务vip和haproxy都会转移到server1上
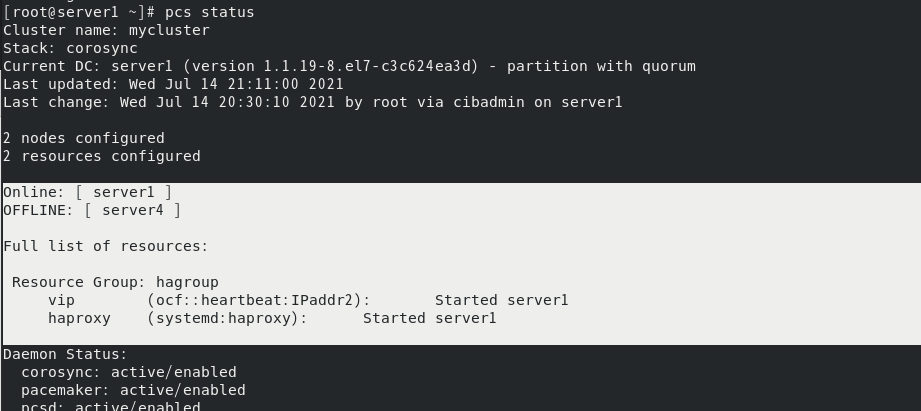

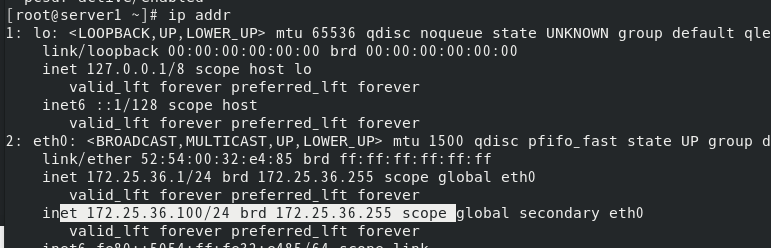
此时server4将一直处于卡死状态,除非手动关掉server4,则server4重启后才会重新加入集群中。但如果server4和server1都出问题了,由于相互失去了联系,都以为是对方出了故障,两个节点将会“本能”地争抢“共享资源”,就会发生严重后果:或者共享资源被瓜分、两边“服务”都起不来了;或者两边“服务”都起来了,但同时读写“共享存储”,导致数据损坏。因此需要使用fence结合pacemaker防止文件系统脑裂
三、配置fence防止文件系统脑裂
真机安装fence组件

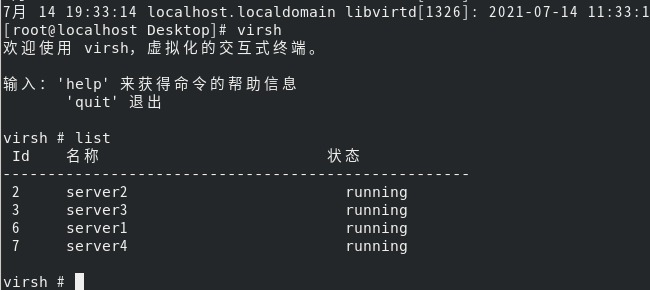
fence_virtd -c编写新的fence信息

其余部分直接回车,知道下图需手动输入br0

它将会在/etc/cluster生成一个密钥文件
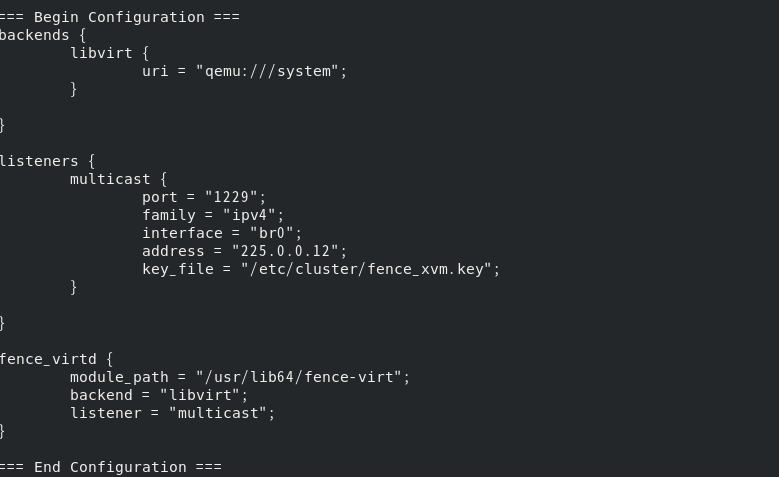
所以我们需要建立这个目录,生成密钥文件后重启服务


server1和server4安装fence客户端

查看模块
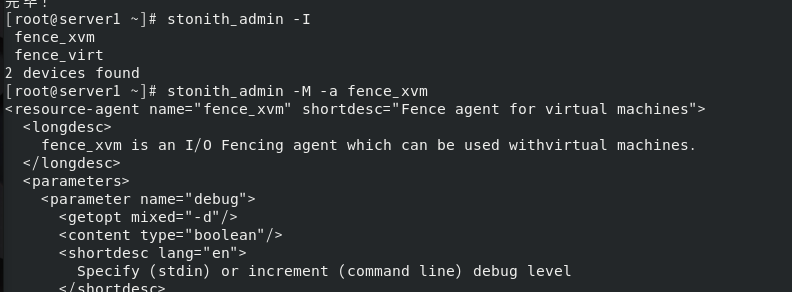
由于密钥文件将存放于此目录
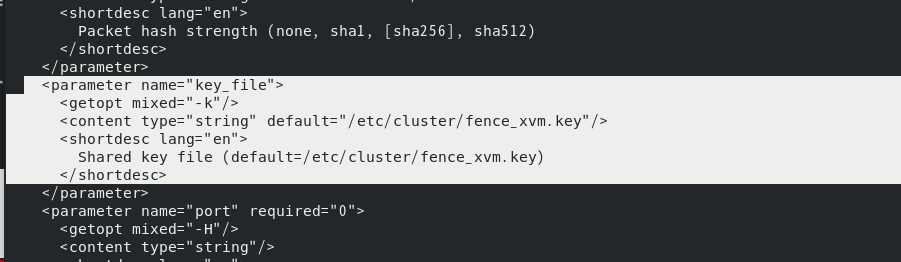
同样的需要建立这个目录

把刚才生成的密钥给资源管理的服务器server1,server4


添加fence模块,连接真机与虚拟机;
启动stonith :
stonith是“shoot the other node in the head”的首字母简写,它是Heartbeat软件包的一个组件,它允许使用一个远程或“智能的”连接到健康服务器的电源设备,自动重启失效服务器的电源。


测试:打开server1的虚拟窗口观察变化

此时server1会自动重启,而前面的keepalived需要手动重启!
查看pcs状态:由于server1内核崩溃了,所以vip和haproxy转移到了server4上,而fence服务修复了server1,所以会停留在server1上

模拟网卡失效,同样的对应的服务器也会自动重启,之后加入集群
