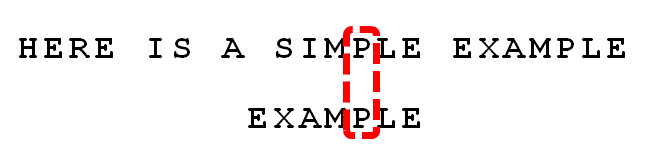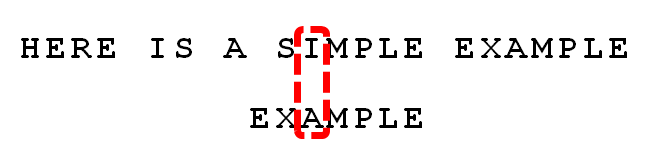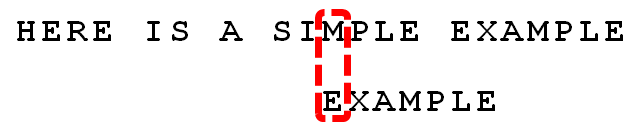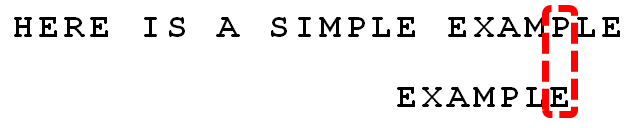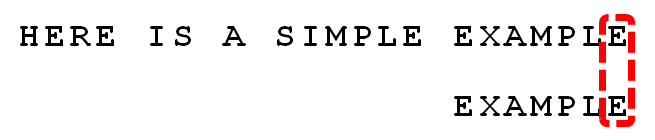д
ДгЭЗЕНЮВГЙЕзРэНтKMPЃЈ2014Фъ8дТ22ШеАцЃЉ
жУЖЅ
2011Фъ12дТ05Ше 13:05:28 v_JULY_v
дФЖСЪ§ 410723
ИќЖр
ДгЭЗЕНЮВГЙЕзРэНтKMP
зїепЃКJuly
1. в§бд
БОKMPдЮФзюГѕаДгк2ФъЖрЧАЕФ2011Фъ12дТЃЌвђЕБЪБГѕДЮНгДЅKMPЃЌЫМТЗЛьТвЕМжТаДвВаДЕУЛьТвЁЃЫљвдвЛжБЯыевЛњЛсжиаТаДЯТKMPЃЌЕЋПргквЛжБвдРДЖдKMPЕФРэНтЪМжеВЛЙЛЃЌЙЪВХГйГйУЛгааоИФБОЮФЁЃ
ШЛНќЦквђПЊСЫИіЫуЗЈАрЃЌАрЩЯзЈУХНВНтЪ§ОнНсЙЙЁЂУцЪдЁЂЫуЗЈЃЌВХдйДЮзаЯИЛиЙЫСЫетИіKMPЃЌдкзлКЯСЫвЛаЉЭјгбЕФРэНтЁЂвдМАЫуЗЈАрЕФСНЮЛНВЪІХѓгбВмВЉЁЂзоВЉЕФРэНтжЎКѓЃЌаДСЫ9еХPPTЃЌЗЂдкЮЂВЉЩЯЁЃЫцКѓЃЌвЛВЛзіЖўВЛанЃЌЫїадНЋPPTЩЯЕФФкШнећРэЕНСЫБОЮФжЎжаЃЈКѓРДЮФеТдНаДдНЭъећЃЌЫљКЌФкШндчвбВЛдйЪЧОХеХPPT ФЧбљМђЕЅСЫЃЉЁЃ
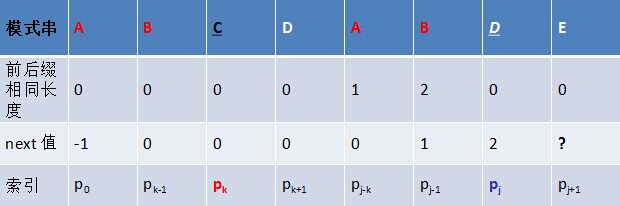
KMPБОЩэВЛИДдгЃЌЕЋЭјЩЯОјДѓВПЗжЕФЮФеТЃЈАќРЈБОЮФЕФ2011ФъАцБОЃЉАбЫќНВЛьТвСЫЁЃЯТУцЃЌдлУЧДгБЉСІЦЅХфЫуЗЈНВЦ№ЃЌЫцКѓВћЪіKMPЕФСїГЬ ВНжшЁЂnext Ъ§зщЕФМђЕЅЧѓНт ЕнЭЦдРэ ДњТыЧѓНтЃЌНгзХЛљгкnext Ъ§зщЦЅХфЃЌЬИЕНгаЯозДЬЌздЖЏЛњЃЌnext Ъ§зщЕФгХЛЏЃЌKMPЕФЪБМфИДдгЖШЗжЮіЃЌзюКѓМђвЊНщЩмСНИіKMPЕФРЉеЙЫуЗЈЁЃ
ШЋЮФСІЭМИјФувЛИізюЮЊЭъећзюЮЊЧхЮњЕФKMPЃЌЯЃЭћИќЖрЕФШЫВЛдйБЛKMPелФЅЛђОРВјЃЌВЛдйБЛвЛаЉЛьТвЕФЮФеТЫљЛьТвЁЃгаКЮвЩЮЪЃЌЛЖгЫцЪБСєбдЦРТлЃЌthanksЁЃ
2. БЉСІЦЅХфЫуЗЈ
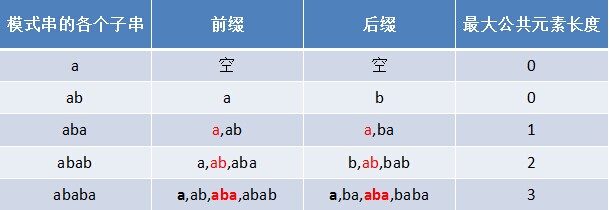
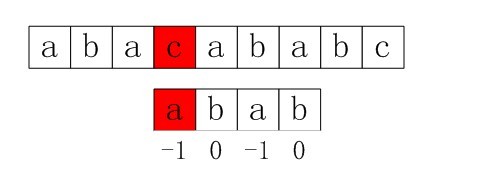
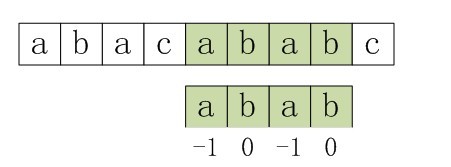
МйЩшЯждкЮвУЧУцСйетбљвЛИіЮЪЬтЃКгавЛИіЮФБОДЎSЃЌКЭвЛИіФЃЪНДЎPЃЌЯждквЊВщевPдкSжаЕФЮЛжУЃЌдѕУДВщевФиЃП
ШчЙћгУБЉСІЦЅХфЕФЫМТЗЃЌВЂМйЩшЯждкЮФБОДЎSЦЅХфЕН i ЮЛжУЃЌФЃЪНДЎPЦЅХфЕН j ЮЛжУЃЌдђгаЃК
ШчЙћЕБЧАзжЗћЦЅХфГЩЙІЃЈМДS[i] == P[j]ЃЉЃЌдђi++ЃЌj++ЃЌМЬајЦЅХфЯТвЛИізжЗћЃЛ
ШчЙћЪЇХфЃЈМДS[i]! = P[j]ЃЉЃЌСюi = i - (j - 1)ЃЌj = 0ЁЃЯрЕБгкУПДЮЦЅХфЪЇАмЪБЃЌi ЛиЫнЃЌj БЛжУЮЊ0ЁЃ
РэЧхГўСЫБЉСІЦЅХфЫуЗЈЕФСїГЬМАФкдкЕФТпМЃЌдлУЧПЩвдаДГіБЉСІЦЅХфЕФДњТыЃЌШчЯТЃК
int ViolentMatch (char * s, char * p)
while (i < sLen && j < pLen)
ОйИіР§згЃЌШчЙћИјЖЈЮФБОДЎSЁАBBC ABCDAB ABCDABCDABDEЁБЃЌКЭФЃЪНДЎPЁАABCDABDЁБЃЌЯждквЊФУФЃЪНДЎPШЅИњЮФБОДЎSЦЅХфЃЌећИіЙ§ГЬШчЯТЫљЪОЃК
1. S[0]ЮЊBЃЌP[0]ЮЊAЃЌВЛЦЅХфЃЌжДааЕкЂкЬѕжИСюЃКЁАШчЙћЪЇХфЃЈМДS[i]! = P[j]ЃЉЃЌСюi = i - (j - 1)ЃЌj = 0ЁБЃЌS[1]ИњP[0]ЦЅХфЃЌЯрЕБгкФЃЪНДЎвЊЭљгввЦЖЏвЛЮЛЃЈi=1ЃЌj=0ЃЉ
2 . S[1]ИњP[0]ЛЙЪЧВЛЦЅХфЃЌМЬајжДааЕкЂкЬѕжИСюЃКЁАШчЙћЪЇХфЃЈМДS[i]! = P[j]ЃЉЃЌСюi = i - (j - 1)ЃЌj = 0ЁБЃЌS[2]ИњP[0]ЦЅХфЃЈi=2ЃЌj=0ЃЉЃЌДгЖјФЃЪНДЎВЛЖЯЕФЯђгввЦЖЏвЛЮЛЃЈВЛЖЯЕФжДааЁАСюi = i - (j - 1)ЃЌj = 0ЁБЃЌiДг2БфЕН4ЃЌjвЛжБЮЊ0ЃЉ
3 . жБЕНS[4]ИњP[0]ЦЅХфГЩЙІЃЈi=4ЃЌj=0ЃЉЃЌДЫЪБАДееЩЯУцЕФБЉСІЦЅХфЫуЗЈЕФЫМТЗЃЌзЊЖјжДааЕкЂйЬѕжИСюЃКЁАШчЙћЕБЧАзжЗћЦЅХфГЩЙІЃЈМДS[i] == P[j]ЃЉЃЌдђi++ЃЌj++ЁБЃЌПЩЕУS[i]ЮЊS[5]ЃЌP[j]ЮЊP[1]ЃЌМДНгЯТРДS[5]ИњP[1]ЦЅХфЃЈi=5ЃЌj=1ЃЉ
4 . S[5]ИњP[1]ЦЅХфГЩЙІЃЌМЬајжДааЕкЂйЬѕжИСюЃКЁАШчЙћЕБЧАзжЗћЦЅХфГЩЙІЃЈМДS[i] == P[j]ЃЉЃЌдђi++ЃЌj++ЁБЃЌЕУЕНS[6]ИњP[2]ЦЅХфЃЈi=6ЃЌj=2ЃЉЃЌШчДЫНјааЯТШЅ
5 . жБЕНS[10]ЮЊПеИёзжЗћЃЌP[6]ЮЊзжЗћDЃЈi=10ЃЌj=6ЃЉЃЌвђЮЊВЛЦЅХфЃЌжиаТжДааЕкЂкЬѕжИСюЃКЁАШчЙћЪЇХфЃЈМДS[i]! = P[j]ЃЉЃЌСюi = i - (j - 1)ЃЌj = 0ЁБЃЌЯрЕБгкS[5]ИњP[0]ЦЅХфЃЈi=5ЃЌj=0ЃЉ
6 . жСДЫЃЌЮвУЧПЩвдПДЕНЃЌШчЙћАДееБЉСІЦЅХфЫуЗЈЕФЫМТЗЃЌОЁЙмжЎЧАЮФБОДЎКЭФЃЪНДЎвбОЗжБ№ЦЅХфЕНСЫS[9]ЁЂP[5]ЃЌЕЋвђЮЊS[10]ИњP[6]ВЛЦЅХфЃЌЫљвдЮФБОДЎЛиЫнЕНS[5]ЃЌФЃЪНДЎЛиЫнЕНP[0]ЃЌДгЖјШУS[5]ИњP[0]ЦЅХфЁЃ
ЖјS[5]ПЯЖЈИњP[0]ЪЇХфЁЃЮЊЪВУДФиЃПвђЮЊдкжЎЧАЕк4ВНЦЅХфжаЃЌЮвУЧвбОЕУжЊS[5] = P[1] = BЃЌЖјP[0] = AЃЌМДP[1] != P[0]ЃЌЙЪS[5]БиЖЈВЛЕШгкP[0]ЃЌЫљвдЛиЫнЙ§ШЅБиШЛЛсЕМжТЪЇХфЁЃФЧгаУЛгавЛжжЫуЗЈЃЌШУi ВЛЭљЛиЭЫЃЌжЛашвЊвЦЖЏj МДПЩФиЃП
Д№АИЪЧПЯЖЈЕФЁЃетжжЫуЗЈОЭЪЧБОЮФЕФжїжМKMPЫуЗЈЃЌЫќРћгУжЎЧАвбОВПЗжЦЅХфетИігааЇаХЯЂЃЌБЃГжi ВЛЛиЫнЃЌЭЈЙ§аоИФj ЕФЮЛжУЃЌШУФЃЪНДЎОЁСПЕивЦЖЏЕНгааЇЕФЮЛжУЁЃ
3. KMPЫуЗЈ
3.1 ЖЈвх
Knuth-Morris-Pratt зжЗћДЎВщевЫуЗЈЃЌМђГЦЮЊ ЁАKMPЫуЗЈЁБЃЌГЃгУгкдквЛИіЮФБОДЎSФкВщеввЛИіФЃЪНДЎP ЕФГіЯжЮЛжУЃЌетИіЫуЗЈгЩDonald KnuthЁЂVaughan PrattЁЂJames H. MorrisШ§ШЫгк1977ФъСЊКЯЗЂБэЃЌЙЪШЁет3ШЫЕФаеЪЯУќУћДЫЫуЗЈЁЃ
ЯТУцЯШжБНгИјГіKMPЕФЫуЗЈСїГЬЃЈШчЙћИаЕНвЛЕуЕуВЛЪЪЃЌУЛЙиЯЕЃЌМсГжЯТЃЌЩдКѓЛсгаОпЬхВНжшМАНтЪЭЃЌдНЭљКѓПДдНЛсСјАЕЛЈУї?ЃЉЃК
МйЩшЯждкЮФБОДЎSЦЅХфЕН i ЮЛжУЃЌФЃЪНДЎPЦЅХфЕН j ЮЛжУ
ШчЙћj = -1ЃЌЛђепЕБЧАзжЗћЦЅХфГЩЙІЃЈМДS[i] == P[j]ЃЉЃЌЖМСюi++ЃЌj++ЃЌМЬајЦЅХфЯТвЛИізжЗћЃЛ
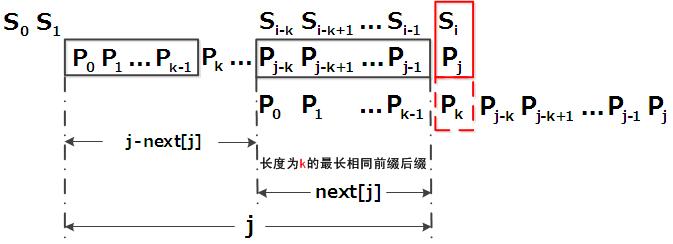
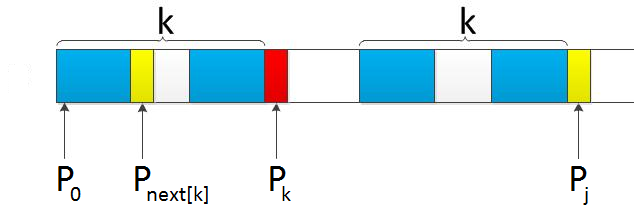
ШчЙћj != -1ЃЌЧвЕБЧАзжЗћЦЅХфЪЇАмЃЈМДS[i] != P[j]ЃЉЃЌдђСю i ВЛБфЃЌj = next[j]ЁЃДЫОйвтЮЖзХЪЇХфЪБЃЌФЃЪНДЎPЯрЖдгкЮФБОДЎSЯђгввЦЖЏСЫj - next [j] ЮЛЁЃ
ЛЛбджЎЃЌЕБЦЅХфЪЇАмЪБЃЌФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ЮЊЃКЪЇХфзжЗћЫљдкЮЛжУ - ЪЇХфзжЗћЖдгІЕФnext жЕЃЈnext Ъ§зщЕФЧѓНтЛсдкЯТЮФЕФ3.3.3НкжаЯъЯИВћЪіЃЉЃЌМДвЦЖЏЕФЪЕМЪЮЛЪ§ЮЊЃКj - next[j] ЃЌЧвДЫжЕДѓгкЕШгк1ЁЃ
КмПьЃЌФувВЛсвтЪЖЕНnext Ъ§зщИїжЕЕФКЌвхЃКДњБэЕБЧАзжЗћжЎЧАЕФзжЗћДЎжаЃЌгаЖрДѓГЄЖШЕФЯрЭЌЧАзККѓзКЁЃР§ШчШчЙћnext [j] = kЃЌДњБэj жЎЧАЕФзжЗћДЎжагазюДѓГЄЖШЮЊk ЕФЯрЭЌЧАзККѓзКЁЃ
ДЫвВвтЮЖзХдкФГИізжЗћЪЇХфЪБЃЌИУзжЗћЖдгІЕФnext жЕЛсИцЫпФуЯТвЛВНЦЅХфжаЃЌФЃЪНДЎгІИУЬјЕНФФИіЮЛжУЃЈЬјЕНnext [j] ЕФЮЛжУЃЉЁЃШчЙћnext [j] ЕШгк0Лђ-1ЃЌдђЬјЕНФЃЪНДЎЕФПЊЭЗзжЗћЃЌШєnext [j] = k Чв k > 0ЃЌДњБэЯТДЮЦЅХфЬјЕНj жЎЧАЕФФГИізжЗћЃЌЖјВЛЪЧЬјЕНПЊЭЗЃЌЧвОпЬхЬјЙ§СЫk ИізжЗћЁЃ
зЊЛЛГЩДњТыБэЪОЃЌдђЪЧЃК
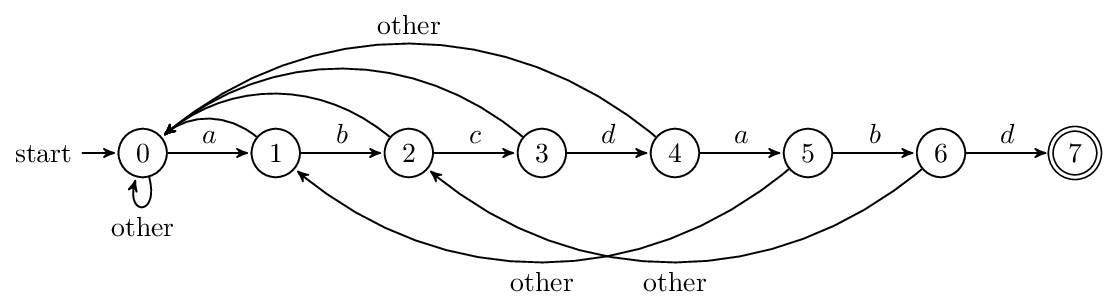
int KmpSearch (char * s, char * p)
while (i < sLen && j < pLen)
if (j ==
-1 || s[i] == p[j])
МЬајФУжЎЧАЕФР§згРДЫЕЃЌЕБS[10]ИњP[6]ЦЅХфЪЇАмЪБЃЌKMPВЛЪЧИњБЉСІЦЅХфФЧбљМђЕЅЕФАбФЃЪНДЎгввЦвЛЮЛЃЌЖјЪЧжДааЕкЂкЬѕжИСюЃКЁАШчЙћj != -1ЃЌЧвЕБЧАзжЗћЦЅХфЪЇАмЃЈМДS[i] != P[j]ЃЉЃЌдђСю i ВЛБфЃЌj = next[j]ЁБЃЌМДj Дг6БфЕН2ЃЈКѓУцЮвУЧНЋЧѓЕУP[6]ЃЌМДзжЗћDЖдгІЕФnext жЕЮЊ2ЃЉЃЌЫљвдЯрЕБгкФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ЮЊj - next[j]ЃЈj - next[j] = 6-2 = 4ЃЉЁЃ
ЯђгввЦЖЏ4ЮЛКѓЃЌS[10]ИњP[2]МЬајЦЅХфЁЃЮЊЪВУДвЊЯђгввЦЖЏ4ЮЛФиЃЌвђЮЊвЦЖЏ4ЮЛКѓЃЌФЃЪНДЎжагжгаИіЁАABЁБПЩвдМЬајИњS[8]S[9]ЖдгІзХЃЌДгЖјВЛгУШУi ЛиЫнЁЃЯрЕБгкдкГ§ШЅзжЗћDЕФФЃЪНДЎзгДЎжабАевЯрЭЌЕФЧАзККЭКѓзКЃЌШЛКѓИљОнЧАзККѓзКЧѓГіnext Ъ§зщЃЌзюКѓЛљгкnext Ъ§зщНјааЦЅХфЃЈВЛЙиаФnext Ъ§зщЪЧдѕУДЧѓРДЕФЃЌжЛЯыПДЦЅХфЙ§ГЬЪЧеІбљЕФЃЌПЩжБНгЬјЕНЯТЮФ3.3.4НкЃЉЁЃ
3.2 ВНжш
ЂйбАевЧАзККѓзКзюГЄЙЋЙВдЊЫиГЄЖШ
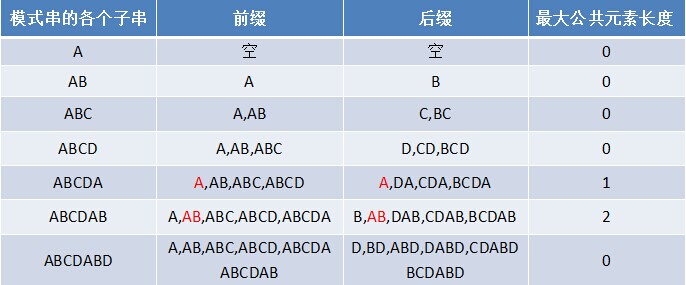
ЖдгкP = p0 p1 ...pj-1 pjЃЌбАевФЃЪНДЎPжаГЄЖШзюДѓЧвЯрЕШЕФЧАзККЭКѓзКЁЃШчЙћДцдкp0 p1 ...pk-1 pk = pj- k pj-k+1...pj-1 pjЃЌФЧУДдкАќКЌpjЕФФЃЪНДЎжагазюДѓГЄЖШЮЊk+1ЕФЯрЭЌЧАзККѓзКЁЃОйИіР§згЃЌШчЙћИјЖЈЕФФЃЪНДЎЮЊЁАababЁБЃЌФЧУДЫќЕФИїИізгДЎЕФЧАзККѓзКЕФЙЋЙВдЊЫиЕФзюДѓГЄЖШШчЯТБэИёЫљЪОЃК
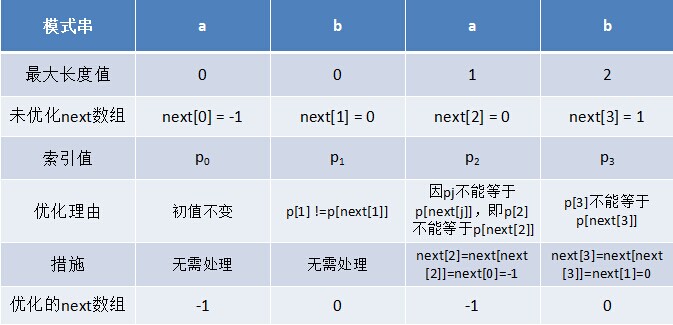
БШШчЖдгкзжЗћДЎabaРДЫЕЃЌЫќгаГЄЖШЮЊ1ЕФЯрЭЌЧАзККѓзКaЃЛЖјЖдгкзжЗћДЎababРДЫЕЃЌЫќгаГЄЖШЮЊ2ЕФЯрЭЌЧАзККѓзКabЃЈЯрЭЌЧАзККѓзКЕФГЄЖШЮЊk + 1ЃЌk + 1 = 2ЃЉЁЃ
ЂкЧѓnextЪ§зщ
next Ъ§зщПМТЧЕФЪЧГ§ЕБЧАзжЗћЭтЕФзюГЄЯрЭЌЧАзККѓзКЃЌЫљвдЭЈЙ§ЕкЂйВНжшЧѓЕУИїИіЧАзККѓзКЕФЙЋЙВдЊЫиЕФзюДѓГЄЖШКѓЃЌжЛвЊЩдзїБфаЮМДПЩЃКНЋЕкЂйВНжшжаЧѓЕУЕФжЕећЬхгввЦвЛЮЛЃЌШЛКѓГѕжЕИГЮЊ-1ЃЌШчЯТБэИёЫљЪОЃК
БШШчЖдгкabaРДЫЕЃЌЕк3ИізжЗћaжЎЧАЕФзжЗћДЎabжагаГЄЖШЮЊ0ЕФЯрЭЌЧАзККѓзКЃЌЫљвдЕк3ИізжЗћaЖдгІЕФnextжЕЮЊ0ЃЛЖјЖдгкababРДЫЕЃЌЕк4ИізжЗћbжЎЧАЕФзжЗћДЎabaжагаГЄЖШЮЊ1ЕФЯрЭЌЧАзККѓзКaЃЌЫљвдЕк4ИізжЗћbЖдгІЕФnextжЕЮЊ1ЃЈЯрЭЌЧАзККѓзКЕФГЄЖШЮЊkЃЌk = 1ЃЉЁЃ
ЂлИљОнnextЪ§зщНјааЦЅХф
ЦЅХфЪЇХфЃЌj = next [j]ЃЌФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ЮЊЃКj - next[j]ЁЃЛЛбджЎЃЌЕБФЃЪНДЎЕФКѓзКpj-k pj-k+1, ..., pj-1 ИњЮФБОДЎsi-k si-k+1, ..., si-1ЦЅХфГЩЙІЃЌЕЋpj ИњsiЦЅХфЪЇАмЪБЃЌвђЮЊnext[j] = kЃЌЯрЕБгкдкВЛАќКЌpjЕФФЃЪНДЎжагазюДѓГЄЖШЮЊk ЕФЯрЭЌЧАзККѓзКЃЌМДp0 p1 ...pk-1 = pj-k pj-k+1...pj-1ЃЌЙЪСюj = next[j]ЃЌДгЖјШУФЃЪНДЎгввЦj - next[j] ЮЛЃЌЪЙЕУФЃЪНДЎЕФЧАзКp0 p1, ..., pk-1ЖдгІзХЮФБОДЎ si-k si-k+1, ..., si-1ЃЌЖјКѓШУpk Ињsi МЬајЦЅХфЁЃШчЯТЭМЫљЪОЃК
злЩЯЃЌKMPЕФnext Ъ§зщЯрЕБгкИцЫпЮвУЧЃКЕБФЃЪНДЎжаЕФФГИізжЗћИњЮФБОДЎжаЕФФГИізжЗћЦЅХфЪЇХфЪБЃЌФЃЪНДЎЯТвЛВНгІИУЬјЕНФФИіЮЛжУЁЃШчФЃЪНДЎжадкj ДІЕФзжЗћИњЮФБОДЎдкi ДІЕФзжЗћЦЅХфЪЇХфЪБЃЌЯТвЛВНгУnext [j] ДІЕФзжЗћМЬајИњЮФБОДЎi ДІЕФзжЗћЦЅХфЃЌЯрЕБгкФЃЪНДЎЯђгввЦЖЏ j - next[j] ЮЛЁЃ
НгЯТРДЃЌЗжБ№ОпЬхНтЪЭЩЯЪі3ИіВНжшЁЃ
3.3 НтЪЭ
3.3.1 бАевзюГЄЧАзККѓзК
ШчЙћИјЖЈЕФФЃЪНДЎЪЧЃКЁАABCDABDЁБЃЌДгзѓжСгвБщРњећИіФЃЪНДЎЃЌЦфИїИізгДЎЕФЧАзККѓзКЗжБ№ШчЯТБэИёЫљЪОЃК
вВОЭЪЧЫЕЃЌдФЃЪНДЎзгДЎЖдгІЕФИїИіЧАзККѓзКЕФЙЋЙВдЊЫиЕФзюДѓГЄЖШБэЮЊЃЈЯТМђГЦЁЖзюДѓГЄЖШБэЁЗ ЃЉЃК
3.3.2 ЛљгкЁЖзюДѓГЄЖШБэЁЗЦЅХф
вђЮЊФЃЪНДЎжаЪзЮВПЩФмЛсгажиИДЕФзжЗћЃЌЙЪПЩЕУГіЯТЪіНсТлЃК
ЪЇХфЪБЃЌФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ЮЊЃКвбЦЅХфзжЗћЪ§ - ЪЇХфзжЗћЕФЩЯвЛЮЛзжЗћЫљЖдгІЕФзюДѓГЄЖШжЕ
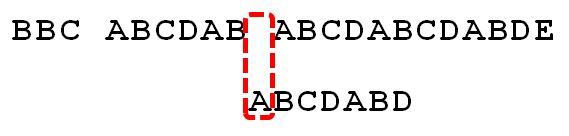
ЯТУцЃЌдлУЧОЭНсКЯжЎЧАЕФЁЖзюДѓГЄЖШБэЁЗКЭЩЯЪіНсТлЃЌНјаазжЗћДЎЕФЦЅХфЁЃШчЙћИјЖЈЮФБОДЎЁАBBC ABCDAB ABCDABCDABDEЁБЃЌКЭФЃЪНДЎЁАABCDABDЁБЃЌЯждквЊФУФЃЪНДЎШЅИњЮФБОДЎЦЅХфЃЌШчЯТЭМЫљЪОЃК
1. вђЮЊФЃЪНДЎжаЕФзжЗћAИњЮФБОДЎжаЕФзжЗћBЁЂBЁЂCЁЂПеИёвЛПЊЪМОЭВЛЦЅХфЃЌЫљвдВЛБиПМТЧНсТлЃЌжБНгНЋФЃЪНДЎВЛЖЯЕФгввЦвЛЮЛМДПЩЃЌжБЕНФЃЪНДЎжаЕФзжЗћAИњЮФБОДЎЕФЕк5ИізжЗћAЦЅХфГЩЙІЃК
2 . МЬајЭљКѓЦЅХфЃЌЕБФЃЪНДЎзюКѓвЛИізжЗћDИњЮФБОДЎЦЅХфЪБЪЇХфЃЌЯдЖјвзМћЃЌФЃЪНДЎашвЊЯђгввЦЖЏЁЃЕЋЯђгввЦЖЏЖрЩйЮЛФиЃПвђЮЊДЫЪБвбОЦЅХфЕФзжЗћЪ§ЮЊ6ИіЃЈABCDABЃЉЃЌШЛКѓИљОнЁЖзюДѓГЄЖШБэЁЗПЩЕУЪЇХфзжЗћDЕФЩЯвЛЮЛзжЗћBЖдгІЕФГЄЖШжЕЮЊ2ЃЌЫљвдИљОнжЎЧАЕФНсТлЃЌПЩжЊашвЊЯђгввЦЖЏ6 - 2 = 4 ЮЛЁЃ
3 . ФЃЪНДЎЯђгввЦЖЏ4ЮЛКѓЃЌЗЂЯжCДІдйЖШЪЇХфЃЌвђЮЊДЫЪБвбОЦЅХфСЫ2ИізжЗћЃЈABЃЉЃЌЧвЩЯвЛЮЛзжЗћBЖдгІЕФзюДѓГЄЖШжЕЮЊ0ЃЌЫљвдЯђгввЦЖЏЃК2 - 0 =2 ЮЛЁЃ
4 . AгыПеИёЪЇХфЃЌЯђгввЦЖЏ1 ЮЛЁЃ
5 . МЬајБШНЯЃЌЗЂЯжDгыC ЪЇХфЃЌЙЪЯђгввЦЖЏЕФЮЛЪ§ЮЊЃКвбЦЅХфЕФзжЗћЪ§6МѕШЅЩЯвЛЮЛзжЗћBЖдгІЕФзюДѓГЄЖШ2ЃЌМДЯђгввЦЖЏ6 - 2 = 4 ЮЛЁЃ
6 . ОРњЕк5ВНКѓЃЌЗЂЯжЦЅХфГЩЙІЃЌЙ§ГЬНсЪјЁЃ
ЭЈЙ§ЩЯЪіЦЅХфЙ§ГЬПЩвдПДГіЃЌЮЪЬтЕФЙиМќОЭЪЧбАевФЃЪНДЎжазюДѓГЄЖШЕФЯрЭЌЧАзККЭКѓзКЃЌевЕНСЫФЃЪНДЎжаУПИізжЗћжЎЧАЕФЧАзККЭКѓзКЙЋЙВВПЗжЕФзюДѓГЄЖШКѓЃЌБуПЩЛљгкДЫЦЅХфЁЃЖјетИізюДѓГЄЖШБуе§ЪЧnext Ъ§зщвЊБэДяЕФКЌвхЁЃ
3.3.3 ИљОнЁЖзюДѓГЄЖШБэЁЗЧѓnext Ъ§зщ
гЩЩЯЮФЃЌЮвУЧвбОжЊЕРЃЌзжЗћДЎЁАABCDABDЁБИїИіЧАзККѓзКЕФзюДѓЙЋЙВдЊЫиГЄЖШЗжБ№ЮЊЃК
ЖјЧвЃЌИљОнетИіБэПЩвдЕУГіЯТЪіНсТл
ЪЇХфЪБЃЌФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ЮЊЃКвбЦЅХфзжЗћЪ§ - ЪЇХфзжЗћЕФЩЯвЛЮЛзжЗћЫљЖдгІЕФзюДѓГЄЖШжЕ
ЩЯЮФРћгУетИіБэКЭНсТлНјааЦЅХфЪБЃЌЮвУЧЗЂЯжЃЌЕБЦЅХфЕНвЛИізжЗћЪЇХфЪБЃЌЦфЪЕУЛБивЊПМТЧЕБЧАЪЇХфЕФзжЗћЃЌИќКЮПіЮвУЧУПДЮЪЇХфЪБЃЌЖМЪЧПДЕФЪЇХфзжЗћЕФЩЯвЛЮЛзжЗћЖдгІЕФзюДѓГЄЖШжЕЁЃШчДЫЃЌБув§ГіСЫnext Ъ§зщЁЃ
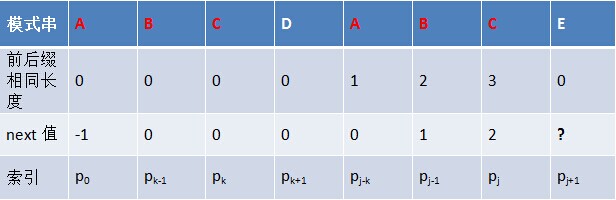
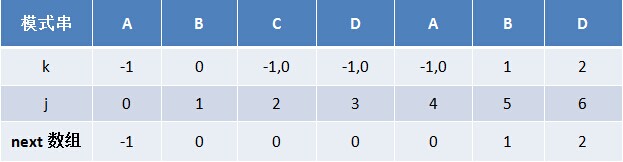
ИјЖЈзжЗћДЎЁАABCDABDЁБЃЌПЩЧѓЕУЫќЕФnext Ъ§зщШчЯТЃК
Абnext Ъ§зщИњжЎЧАЧѓЕУЕФзюДѓГЄЖШБэЖдБШКѓЃЌВЛФбЗЂЯжЃЌnext Ъ§зщЯрЕБгкЁАзюДѓГЄЖШжЕЁБ ећЬхЯђгввЦЖЏвЛЮЛЃЌШЛКѓГѕЪМжЕИГЮЊ-1 ЁЃвтЪЖЕНСЫетвЛЕуЃЌФуЛсОЊКєдРДnext Ъ§зщЕФЧѓНтОЙШЛШчДЫМђЕЅЃКОЭЪЧевзюДѓЖдГЦГЄЖШЕФЧАзККѓзКЃЌШЛКѓећЬхгввЦвЛЮЛЃЌГѕжЕИГЮЊ-1ЃЈЕБШЛЃЌФувВПЩвджБНгМЦЫуФГИізжЗћЖдгІЕФnextжЕЃЌОЭЪЧПДетИізжЗћжЎЧАЕФзжЗћДЎжагаЖрДѓГЄЖШЕФЯрЭЌЧАзККѓзКЃЉЁЃ
ЛЛбджЎЃЌЖдгкИјЖЈЕФФЃЪНДЎЃКABCDABDЃЌЫќЕФзюДѓГЄЖШБэМАnext Ъ§зщЗжБ№ШчЯТЃК
ИљОнзюДѓГЄЖШБэЧѓГіСЫnext Ъ§зщКѓЃЌДгЖјга
ЪЇХфЪБЃЌФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ЮЊЃКЪЇХфзжЗћЫљдкЮЛжУ - ЪЇХфзжЗћЖдгІЕФnext жЕ
ЖјКѓЃЌФуЛсЗЂЯжЃЌЮоТлЪЧЛљгкЁЖзюДѓГЄЖШБэЁЗЕФЦЅХфЃЌЛЙЪЧЛљгкnext Ъ§зщЕФЦЅХфЃЌСНепЕУГіРДЕФЯђгввЦЖЏЕФЮЛЪ§ЪЧвЛбљЕФЁЃЮЊЪВУДФиЃПвђЮЊЃК
ИљОнЁЖзюДѓГЄЖШБэЁЗЃЌЪЇХфЪБЃЌФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ = вбОЦЅХфЕФзжЗћЪ§ - ЪЇХфзжЗћЕФЩЯвЛЮЛзжЗћЕФзюДѓГЄЖШжЕ
ЖјИљОнЁЖnext Ъ§зщЁЗЃЌЪЇХфЪБЃЌФЃЪНДЎЯђгввЦЖЏЕФЮЛЪ§ = ЪЇХфзжЗћЕФЮЛжУ - ЪЇХфзжЗћЖдгІЕФnext жЕ
ЦфжаЃЌДг0ПЊЪММЦЪ§ЪБЃЌЪЇХфзжЗћЕФЮЛжУ = вбОЦЅХфЕФзжЗћЪ§ЃЈЪЇХфзжЗћВЛМЦЪ§ЃЉЃЌЖјЪЇХфзжЗћЖдгІЕФnext жЕ = ЪЇХфзжЗћЕФЩЯвЛЮЛзжЗћЕФзюДѓГЄЖШжЕЃЌСНЯрБШНЯЃЌНсЙћБиШЛЭъШЋвЛжТЁЃ
ЫљвдЃЌФуПЩвдАбЁЖзюДѓГЄЖШБэЁЗПДзіЪЧnext Ъ§зщЕФГћаЮЃЌЩѕжСОЭАбЫќЕБзіnext Ъ§зщвВЪЧПЩвдЕФЃЌЧјБ№ВЛЙ§ЪЧдѕУДгУЕФЮЪЬтЁЃ
3.3.4 ЭЈЙ§ДњТыЕнЭЦМЦЫуnext Ъ§зщ
НгЯТРДЃЌдлУЧРДаДДњТыЧѓЯТnext Ъ§зщЁЃ
ЛљгкжЎЧАЕФРэНтЃЌПЩжЊМЦЫуnext Ъ§зщЕФЗНЗЈПЩвдВЩгУЕнЭЦЃК
ОйИіР§згЃЌШчЯТЭМЃЌИљОнФЃЪНДЎЁАABCDABDЁБЕФnext Ъ§зщПЩжЊЪЇХфЮЛжУЕФзжЗћDЖдгІЕФnext жЕЮЊ2ЃЌДњБэзжЗћDЧАгаГЄЖШЮЊ2ЕФЯрЭЌЧАзККЭКѓзКЃЈетИіЯрЭЌЕФЧАзККѓзКМДЮЊЁАABЁБЃЉЃЌЪЇХфКѓЃЌФЃЪНДЎашвЊЯђгввЦЖЏj - next [j] = 6 - 2 =4ЮЛЁЃ
ЯђгввЦЖЏ4ЮЛКѓЃЌФЃЪНДЎжаЕФзжЗћCМЬајИњЮФБОДЎЦЅХфЁЃ
2 . ЯТУцЕФЮЪЬтЪЧЃКвбжЊnext [0, ..., j]ЃЌШчКЮЧѓГіnext [j + 1]ФиЃП
ЖдгкPЕФЧАj+1ИіађСазжЗћЃК
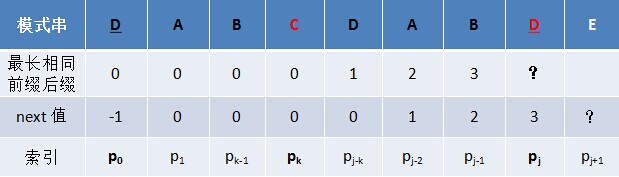
Шєp[k] == p[j]ЃЌдђnext[j + 1 ] = next [j] + 1 = k + 1ЃЛ
Шєp[k ] Ёй p[j]ЃЌШчЙћДЫЪБp[ next[k] ] == p[j ]ЃЌдђnext[ j + 1 ] = next[k] + 1ЃЌЗёдђМЬајЕнЙщЧАзКЫїв§k = next[k]ЃЌЖјКѓжиИДДЫЙ§ГЬЁЃ ЯрЕБгкдкзжЗћp[j+1]жЎЧАВЛДцдкГЄЖШЮЊk+1ЕФЧАзК"p0 p1, Ё, pk-1 pk"ИњКѓзКЁАpj-k pj-k+1, Ё, pj-1 pj"ЯрЕШЃЌФЧУДЪЧЗёПЩФмДцдкСэвЛИіжЕt+1 < k+1ЃЌЪЙЕУГЄЖШИќаЁЕФЧАзК ЁАp0 p1, Ё, pt-1 ptЁБ ЕШгкГЄЖШИќаЁЕФКѓзК ЁАpj-t pj-t+1, Ё, pj-1 pjЁБ ФиЃПШчЙћДцдкЃЌФЧУДетИіt+1 БуЪЧnext[ j+1]ЕФжЕЃЌДЫЯрЕБгкРћгУвбОЧѓЕУЕФnext Ъ§зщЃЈnext [0, ..., k, ..., j]ЃЉНјааPДЎЧАзКИњPДЎКѓзКЕФЦЅХфЁЃ
вЛАуЕФЮФеТЛђНЬВФПЩФмОЭДЫвЛБЪДјЙ§ЃЌЕЋДѓВПЗжЕФГѕбЇепПЩФмЛЙЪЧВЛФмКмКУЕФРэНтЩЯЪіЧѓНтnext Ъ§зщЕФдРэЃЌЙЪНгЯТРДЃЌЮвдйРДзХжиЫЕУїЯТЁЃ
ШчЯТЭМЫљЪОЃЌМйЖЈИјЖЈФЃЪНДЎABCDABCEЃЌЧввбжЊnext [j] = kЃЈЯрЕБгкЁАp0 pk-1ЁБ = ЁАpj-k pj-1ЁБ = ABЃЌПЩвдПДГіkЮЊ2ЃЉЃЌЯжвЊЧѓnext [j + 1]ЕШгкЖрЩйЃПвђЮЊpk = pj = CЃЌЫљвдnext[j + 1] = next[j] + 1 = k + 1ЃЈПЩвдПДГіnext[j + 1] = 3ЃЉЁЃДњБэзжЗћEЧАЕФФЃЪНДЎжаЃЌгаГЄЖШk+1 ЕФЯрЭЌЧАзККѓзКЁЃ
ЕЋШчЙћpk != pj Фи ЃПЫЕУїЁАp0 pk-1 pkЁБ Ёй ЁАpj-k pj-1 pjЁБЁЃЛЛбджЎЃЌЕБpk != pjКѓЃЌзжЗћEЧАгаЖрДѓГЄЖШЕФЯрЭЌЧАзККѓзКФиЃПКмУїЯдЃЌвђЮЊCВЛЭЌгкDЃЌЫљвдABC Ињ ABDВЛЯрЭЌЃЌМДзжЗћEЧАЕФФЃЪНДЎУЛгаГЄЖШЮЊk+1ЕФЯрЭЌЧАзККѓзКЃЌвВОЭВЛФмдйМђЕЅЕФСюЃКnext[j + 1] = next[j] + 1 ЁЃЫљвдЃЌдлУЧжЛФмШЅбАевГЄЖШИќЖЬвЛЕуЕФЯрЭЌЧАзККѓзКЁЃ
НсКЯЩЯЭМРДНВЃЌШєФмдкЧАзК ЁА p0 pk-1 pk ЁБ жаВЛЖЯЕФЕнЙщЧАзКЫїв§k = next [k]ЃЌевЕНвЛИізжЗћpkЁЏ вВЮЊDЃЌДњБэpkЁЏ = pjЃЌЧвТњзуp0 pk'-1 pk' = pj-k' pj-1 pjЃЌдђзюДѓЯрЭЌЕФЧАзККѓзКГЄЖШЮЊk' + 1 ЃЌДгЖјnext [j + 1] = kЁЏ + 1 = next [k' ] + 1ЁЃЗёдђЧАзКжаУЛгаDЃЌдђДњБэУЛгаЯрЭЌЕФЧАзККѓзКЃЌnext [j + 1] = 0ЁЃ
ФЧЮЊКЮЕнЙщЧАзКЫїв§k = next[k]ЃЌОЭФмевЕНГЄЖШИќЖЬЕФЯрЭЌЧАзККѓзКФиЃПетгжЙщИљЕНnextЪ§зщЕФКЌвхЁЃЮвУЧФУЧАзК p0 pk-1 pk ШЅИњКѓзКpj-k pj-1 pjЦЅХфЃЌШчЙћpk Ињpj ЪЇХфЃЌЯТвЛВНОЭЪЧгУp[next[k]] ШЅИњpj МЬајЦЅХфЃЌШчЙћp[ next[k] ]ИњpjЛЙЪЧВЛЦЅХфЃЌдђашвЊбАевГЄЖШИќЖЬЕФЯрЭЌЧАзККѓзК ЃЌМДЯТвЛВНгУp[ next[ next[k] ] ]ШЅИњpjЦЅХф ЁЃДЫЙ§ГЬЯрЕБгкФЃЪНДЎЕФздЮвЦЅХфЃЌЫљвдВЛЖЯЕФЕнЙщk = next[k]ЃЌжБЕНвЊУДевЕНГЄЖШИќЖЬЕФЯрЭЌЧАзККѓзКЃЌвЊУДУЛгаГЄЖШИќЖЬЕФЯрЭЌЧАзККѓзКЁЃШчЯТЭМЫљЪОЃК
в§гУЯТвЛЖСепwudehua55555гкБОЮФЦРТлЯТСєбдЃЌвдИЈжњДѓМвДгСэвЛИіНЧЖШРэНтЃКЁА вЛжБвдЮЊВЉжїдкгУЕнЙщЧѓnextЪ§зщЪБУЛНВЧхГўЃЌЮЊКЮвЊгУk = next[k],заЯИПДСЫетИіКьЛЦРЖЗжЧјЭМВХЭЛШЛЛаШЛДѓЮђЃЌОЭЪЧевЕНp[k]ЖдгІЕФnext[k]ЃЌИљОнЖдГЦадЃЌжЛашдйХаЖЯp[next[k]]гыp[j]ЪЧЗёЯрЕШМДПЩЃЌгкЪЧСюk = next[k],етРяЧЁКУОЭЪЙгУСЫЕнЙщЕФЫМТЗЁЃЦфЪЕЮвОѕЕУВЛвЊвЛПЊЪМОЭЯнШыЕнЙщЕФЗНЗЈжаЃЌЛЛвЛжжЫМТЗЃЌжБНгДгПМТЧЖдГЦадШыЪжЃЌПЩжБНгЕУГіk = next[k]ЃЌЖјете§КУЪЧЕнЙщАеСЫЁЃвдЩЯЪЧвЛаЉИіШЫПДЗЈЃЌЗЧГЃИааЛВЉжїЬсЙЉЕФНтЮіЃЌЗЧМЦЫуЛњЕФбЇЩњвВФмПДЖЎЃЌЫфШЛДгзђЭэ9ЕуПДЕНСЫЯждкЁЃИпаЫЁЃЁБ
ЫљвдЃЌвђзюжедкЧАзКABCжаУЛгаевЕНDЃЌЙЪEЕФnext жЕЮЊ0ЃК
ФЃЪНДЎЕФКѓзКЃКABDE
ФЃЪНДЎЕФЧАзКЃКABC
ЧАзКгввЦСНЮЛЃК ABC
ЖСЕНДЫЃЌгаЕФЖСепПЩФмгжгавЩЮЪСЫЃЌФЧФмЗёОйвЛИіФмдкЧАзКжаевЕНзжЗћDЕФР§згФиЃПOKЃЌдлУЧБуРДПДвЛИіФмдкЧАзКжаевЕНзжЗћDЕФР§згЃЌШчЯТЭМЫљЪОЃК
ИјЖЈФЃЪНДЎDABCDABDEЃЌЮвУЧКмЫГРћЕФЧѓЕУзжЗћDжЎЧАЕФЁАDABCDABЁБЕФИїИізгДЎЕФзюГЄЯрЭЌЧАзККѓзКЕФГЄЖШЗжБ№ЮЊ0 0 0 0 1 2 3ЃЌЕЋЕББщРњЕНзжЗћDЃЌвЊЧѓАќРЈDдкФкЕФЁАDABCDABDЁБзюГЄЯрЭЌЧАзККѓзКЪБЃЌЮвУЧЗЂЯжpjДІЕФзжЗћDИњpkДІЕФзжЗћCВЛвЛбљЃЌЛЛбджЎЃЌЧАзКDABCЕФзюКѓвЛИізжЗћC ИњКѓзКDABDЕФзюКѓвЛИізжЗћDВЛЯрЭЌЃЌЫљвдВЛДцдкГЄЖШЮЊ4ЕФЯрЭЌЧАзККѓзКЁЃ
дѕУДАьФиЃПМШШЛУЛгаГЄЖШЮЊ4ЕФЯрЭЌЧАзККѓзКЃЌдлУЧПЩвдбАевГЄЖШЖЬЕуЕФЯрЭЌЧАзККѓзКЃЌзюжеЃЌвђдкp0ДІЗЂЯжвВгаИізжЗћDЃЌp0 = pjЃЌЫљвдp[j]ЖдгІЕФГЄЖШжЕЮЊ1ЃЌЯрЕБгкEЖдгІЕФnext жЕЮЊ1ЃЈМДзжЗћEжЎЧАЕФзжЗћДЎЁАDABCDABDЁБжагаГЄЖШЮЊ1ЕФЯрЭЌЧАзККЭКѓзКЃЉЁЃ
злЩЯЃЌПЩвдЭЈЙ§ЕнЭЦЧѓЕУnext Ъ§зщЃЌДњТыШчЯТЫљЪОЃК
void GetNext (char * p,int next[])
if (k ==
-1 || p[j] == p[k])
гУДњТыжиаТМЦЫуЯТЁАABCDABDЁБЕФnext Ъ§зщЃЌвдбщжЄжЎЧАЭЈЙ§ЁАзюГЄЯрЭЌЧАзККѓзКГЄЖШжЕгввЦвЛЮЛЃЌШЛКѓГѕжЕИГЮЊ-1ЁБЕУЕНЕФnext Ъ§зщЪЧЗёе§ШЗЃЌМЦЫуНсЙћШчЯТБэИёЫљЪОЃК
ДгЩЯЪіБэИёПЩвдПДГіЃЌЮоТлЪЧжЎЧАЭЈЙ§ЁАзюГЄЯрЭЌЧАзККѓзКГЄЖШжЕгввЦвЛЮЛЃЌШЛКѓГѕжЕИГЮЊ-1ЁБЕУЕНЕФnext Ъ§зщЃЌЛЙЪЧжЎКѓЭЈЙ§ДњТыЕнЭЦМЦЫуЧѓЕУЕФnext Ъ§зщЃЌНсЙћЪЧЭъШЋвЛжТЕФЁЃ
3.3.5 ЛљгкЁЖnext Ъ§зщЁЗЦЅХф
ЯТУцЃЌЮвУЧРДЛљгкnext Ъ§зщНјааЦЅХфЁЃ
ЛЙЪЧИјЖЈЮФБОДЎЁАBBC ABCDAB ABCDABCDABDEЁБЃЌКЭФЃЪНДЎЁАABCDABDЁБЃЌЯждквЊФУФЃЪНДЎШЅИњЮФБОДЎЦЅХфЃЌШчЯТЭМЫљЪОЃК
дке§ЪНЦЅХфжЎЧАЃЌШУЮвУЧРДдйДЮЛиЙЫЯТЩЯЮФ2.1НкЫљЪіЕФKMPЫуЗЈЕФЦЅХфСїГЬЃК
2. P[1]ИњS[5]ЦЅХфГЩЙІЃЌP[2]ИњS[6]вВЦЅХфГЩЙІ, ...ЃЌжБЕНЕБЦЅХфЕНP[6]ДІЕФзжЗћDЪБЪЇХфЃЈМДS[10] != P[6]ЃЉЃЌгЩгкP[6]ДІЕФDЖдгІЕФnext жЕЮЊ2 ЃЌЫљвдЯТвЛВНгУP[2] ДІЕФзжЗћCМЬајИњS[10]ЦЅХфЃЌЯрЕБгкЯђгввЦЖЏЃКj - next[j] = 6 - 2 =4 ЮЛЁЃ
3 . ЯђгввЦЖЏ4ЮЛКѓЃЌP[2]ДІЕФCдйДЮЪЇХфЃЌгЩгкCЖдгІЕФnextжЕЮЊ0 ЃЌЫљвдЯТвЛВНгУP[0] ДІЕФзжЗћМЬајИњS[10]ЦЅХфЃЌЯрЕБгкЯђгввЦЖЏЃКj - next[j] = 2 - 0 = 2 ЮЛЁЃ
4 . вЦЖЏСНЮЛжЎКѓЃЌA ИњПеИёВЛЦЅХфЃЌФЃЪНДЎКѓвЦ1 ЮЛЁЃ
5 . P[6]ДІЕФDдйДЮЪЇХфЃЌвђЮЊP[6]ЖдгІЕФnextжЕЮЊ2 ЃЌЙЪЯТвЛВНгУP[2] МЬајИњЮФБОДЎЦЅХфЃЌЯрЕБгкФЃЪНДЎЯђгввЦЖЏ j - next[j] = 6 - 2 = 4 ЮЛЁЃ
ЦЅХфЙ§ГЬвЛФЃвЛбљЁЃвВДгВрУцзєжЄСЫЃЌnext Ъ§зщШЗЪЕЪЧжЛвЊНЋИїИізюДѓЧАзККѓзКЕФЙЋЙВдЊЫиЕФГЄЖШжЕгввЦвЛЮЛЃЌЧвАбГѕжЕИГЮЊ-1 МДПЩЁЃ
3.3.6 ЛљгкЁЖзюДѓГЄЖШБэЁЗгыЛљгкЁЖnext Ъ§зщЁЗЕШМл
ЮвУЧвбОжЊЕРЃЌРћгУnext Ъ§зщНјааЦЅХфЪЇХфЪБЃЌФЃЪНДЎЯђгввЦЖЏ j - next [ j ] ЮЛЃЌЕШМлгквбЦЅХфзжЗћЪ§ - ЪЇХфзжЗћЕФЩЯвЛЮЛзжЗћЫљЖдгІЕФзюДѓГЄЖШжЕЁЃдвђЪЧЃК
j Дг0ПЊЪММЦЪ§ЃЌФЧУДЕБЪ§ЕНЪЇХфзжЗћЪБЃЌj ЕФЪ§жЕОЭЪЧвбЦЅХфЕФзжЗћЪ§ЃЛ
гЩгкnext Ъ§зщЪЧгЩзюДѓГЄЖШжЕБэећЬхЯђгввЦЖЏвЛЮЛЃЈЧвГѕжЕИГЮЊ-1ЃЉЕУЕНЕФЃЌФЧУДЪЇХфзжЗћЕФЩЯвЛЮЛзжЗћЫљЖдгІЕФзюДѓГЄЖШжЕЃЌМДЮЊЕБЧАЪЇХфзжЗћЕФnext жЕЁЃ
ЕЋЮЊКЮБОЮФВЛжБНгРћгУnext Ъ§зщНјааЦЅХфФиЃПвђЮЊnext Ъ§зщВЛКУЧѓЃЌЖјвЛИізжЗћДЎЕФЧАзККѓзКЕФЙЋЙВдЊЫиЕФзюДѓГЄЖШжЕКмШнвзЧѓЁЃР§ШчШєИјЖЈФЃЪНДЎЁАababaЁБЃЌвЊФуПьЫйПкЫуГіЦфnext Ъ§зщЃЌеЇвЛПДЃЌУПДЮЧѓЖдгІзжЗћЕФnextжЕЪБЃЌЛЙЕУАбИУзжЗћХХГ§жЎЭтЃЌШЛКѓПДИУзжЗћжЎЧАЕФзжЗћДЎжагазюДѓГЄЖШЮЊЖрДѓЕФЯрЭЌЧАзККѓзКЃЌДЫЙ§ГЬВЛЙЛжБНгЁЃЖјШчЙћШУФуЧѓЦфЧАзККѓзКЙЋЙВдЊЫиЕФзюДѓГЄЖШЃЌдђКмШнвзжБНгЕУГіНсЙћЃК0 0 1 2 3ЃЌШчЯТБэИёЫљЪОЃК
ШЛКѓет5ИіЪ§зж ШЋВПећЬхгввЦвЛЮЛЃЌЧвГѕжЕИГЮЊ-1ЃЌМДЕУЕНЦфnext Ъ§зщЃК-1 0 0 1 2ЁЃ
3.3.7 Next Ъ§зщгыгаЯозДЬЌздЖЏЛњ
next ИКд№АбФЃЪНДЎЯђЧАвЦЖЏЃЌЧвЕБЕкjЮЛВЛЦЅХфЕФЪБКђЃЌгУЕкnext[j]ЮЛКЭжїДЎЦЅХфЃЌОЭЯёДђСЫеХЁАБэЁБЁЃДЫЭтЃЌnext вВПЩвдПДзїгаЯозДЬЌздЖЏЛњЕФзДЬЌЃЌдквбОЖССЫЖрЩйзжЗћЕФЧщПіЯТЃЌЪЇХфКѓЃЌЧАУцЖСЕФШєИЩИізжЗћЪЧгагУЕФЁЃ
3.3.8 Next Ъ§зщЕФгХЛЏ
ааЮФжСДЫЃЌдлУЧШЋУцСЫНтСЫБЉСІЦЅХфЕФЫМТЗЁЂKMPЫуЗЈЕФдРэЁЂСїГЬЁЂСїГЬжЎМфЕФФкдкТпМСЊЯЕЃЌвдМАnext Ъ§зщЕФМђЕЅЧѓНтЃЈЁЖзюДѓГЄЖШБэЁЗећЬхгввЦвЛЮЛЃЌШЛКѓГѕжЕИГЮЊ-1ЃЉКЭДњТыЧѓНтЃЌзюКѓЛљгкЁЖnext Ъ§зщЁЗЕФЦЅХфЃЌПДЫЦбѓбѓШїШїЃЌЧхЮњЭИГЙЃЌЕЋвдЩЯКіТдСЫвЛИіаЁЮЪЬтЁЃ
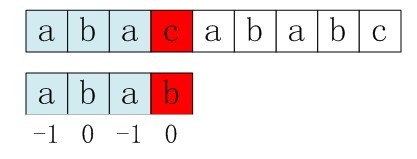
БШШчЃЌШчЙћгУжЎЧАЕФnext Ъ§зщЗНЗЈЧѓФЃЪНДЎЁАababЁБЕФnext Ъ§зщЃЌПЩЕУЦфnext Ъ§зщЮЊ-1 0 0 1ЃЈ0 0 1 2ећЬхгввЦвЛЮЛЃЌГѕжЕИГЮЊ-1ЃЉЃЌЕБЫќИњЯТЭМжаЕФЮФБОДЎШЅЦЅХфЕФЪБКђЃЌЗЂЯжbИњcЪЇХфЃЌгкЪЧФЃЪНДЎгввЦj - next[j] = 3 - 1 =2ЮЛЁЃ
гввЦ2ЮЛКѓЃЌbгжИњcЪЇХфЁЃЪТЪЕЩЯЃЌвђЮЊдкЩЯвЛВНЕФЦЅХфжаЃЌвбОЕУжЊp[3] = bЃЌгыs[3] = cЪЇХфЃЌЖјгввЦСНЮЛжЎКѓЃЌШУp[ next[3] ] = p[1] = b дйИњs[3]ЦЅХфЪБЃЌБиШЛЪЇХфЁЃЮЪЬтГідкФФФиЃП
ЮЪЬтГідкВЛИУГіЯжp[j] = p[ next[j] ]ЁЃЮЊЪВУДФиЃПРэгЩЪЧЃКЕБp[j] != s[i] ЪБЃЌЯТДЮЦЅХфБиШЛЪЧp[ next [j]] Ињs[i]ЦЅХфЃЌШчЙћp[j] = p[ next[j] ]ЃЌБиШЛЕМжТКѓвЛВНЦЅХфЪЇАмЃЈвђЮЊp[j]вбОИњs[i]ЪЇХфЃЌШЛКѓФуЛЙгУИњp[j]ЕШЭЌЕФжЕp[next[j]]ШЅИњs[i]ЦЅХфЃЌКмЯдШЛЃЌБиШЛЪЇХфЃЉЃЌЫљвдВЛФмдЪаэp[j] = p[ next[j ]] ЁЃШчЙћГіЯжСЫp[j] = p[ next[j] ]еІАьФиЃПШчЙћГіЯжСЫЃЌдђашвЊдйДЮЕнЙщЃЌМДСюnext[j] = next[ next[j] ]ЁЃ
ЫљвдЃЌдлУЧЕУаоИФЯТЧѓnext Ъ§зщЕФДњТыЁЃ
void GetNextval (char * p, int next[])
if (k ==
-1 || p[j] == p[k])
РћгУгХЛЏЙ§КѓЕФnext Ъ§зщЧѓЗЈЃЌПЩжЊФЃЪНДЎЁАababЁБЕФаТnextЪ§зщЮЊЃК-1 0 -1 0ЁЃПЩФмгааЉЖСепЛсЮЪЃКдЪМnext Ъ§зщЪЧЧАзККѓзКзюГЄЙЋЙВдЊЫиГЄЖШжЕгввЦвЛЮЛЃЌ ШЛКѓГѕжЕИГЮЊ-1ЖјЕУЃЌФЧУДгХЛЏКѓЕФnext Ъ§зщШчКЮПьЫйаФЫуГіФиЃПЪЕМЪЩЯЃЌжЛвЊЧѓГіСЫдЪМnext Ъ§зщЃЌБуПЩвдИљОндЪМnext Ъ§зщПьЫйЧѓГігХЛЏКѓЕФnext Ъ§зщЁЃЛЙЪЧвдababЮЊР§ЃЌШчЯТБэИёЫљЪОЃК
жЛвЊГіЯжСЫp[next[j]] = p[j]ЕФЧщПіЃЌдђАбnext[j]ЕФжЕдйДЮЕнЙщЁЃР§ШчдкЧѓФЃЪНДЎЁАababЁБЕФЕк2ИіaЕФnextжЕЪБЃЌШчЙћЪЧЮДгХЛЏЕФnextжЕЕФЛАЃЌЕк2ИіaЖдгІЕФnextжЕЮЊ0 ЃЌЯрЕБгкЕк2ИіaЪЇХфЪБЃЌЯТвЛВНЦЅХфФЃЪНДЎЛсгУp[0] ДІЕФaдйДЮИњЮФБОДЎЦЅХфЃЌБиШЛЪЇХфЁЃЫљвдЧѓЕк2ИіaЕФnextжЕЪБЃЌашвЊдйДЮЕнЙщЃКnext[2] = next[ next[2] ] = next[0] = -1ЃЈДЫКѓЃЌИљОнгХЛЏКѓЕФаТnextжЕПЩжЊЃЌЕк2ИіaЪЇХфЪБЃЌжДааЁАШчЙћj = -1ЃЌЛђепЕБЧАзжЗћЦЅХфГЩЙІЃЈМДS[i] == P[j]ЃЉЃЌЖМСюi++ЃЌj++ЃЌМЬајЦЅХфЯТвЛИізжЗћЁБЃЉЃЌЭЌРэЃЌЕк2ИіbЖдгІЕФnextжЕЮЊ0ЁЃ
ЖдгкгХЛЏКѓЕФnextЪ§зщПЩвдЗЂЯжвЛЕуЃКШчЙћФЃЪНДЎЕФКѓзКИњЧАзКЯрЭЌЃЌФЧУДЫќУЧЕФnextжЕвВЪЧЯрЭЌЕФЃЌР§ШчФЃЪНДЎabcabcЃЌЫќЕФЧАзККѓзКЖМЪЧabcЃЌЦфгХЛЏКѓЕФnextЪ§зщЮЊЃК-1 0 0 -1 0 0ЃЌЧАзККѓзКabcЕФnextжЕЖМЮЊ-1 0 0ЁЃ
ШЛКѓв§гУЯТжЎЧА3.1НкЕФKMPДњТыЃК
int KmpSearch (char * s, char * p)
while (i < sLen && j < pLen)
if (j ==
-1 || s[i] == p[j])
НгЯТРДЃЌдлУЧМЬајФУжЎЧАЕФР§згЫЕУїЃЌећИіЦЅХфЙ§ГЬШчЯТЃК
1 . S[3]гыP[3]ЦЅХфЪЇАмЁЃ
2 . S[3]БЃГжВЛБфЃЌPЕФЯТвЛИіЦЅХфЮЛжУЪЧP[next[3]]ЃЌЖјnext[3]=0ЃЌЫљвдP[next[3]]=P[0]гыS[3]ЦЅХфЁЃ
3 . гЩгкЩЯвЛВНжшжаP[0]гыS[3]ЛЙЪЧВЛЦЅХфЁЃДЫЪБi=3ЃЌj=next [0]=-1ЃЌгЩгкТњзуЬѕМўj==-1ЃЌЫљвджДааЁА++i, ++jЁБЃЌМДжїДЎжИеыЯТвЦвЛИіЮЛжУЃЌP[0]гыS[4]ПЊЪМЦЅХфЁЃзюКѓj==pLenЃЌЬјГібЛЗЃЌЪфГіНсЙћi - j = 4ЃЈМДФЃЪНДЎЕквЛДЮдкЮФБОДЎжаГіЯжЕФЮЛжУЃЉЃЌЦЅХфГЩЙІЃЌЫуЗЈНсЪјЁЃ
3.4 KMPЕФЪБМфИДдгЖШЗжЮі
ЯраХДѓВПЗжЖСепЖСЭъЩЯЮФжЎКѓЃЌвбОЗЂОѕЦфЪЕРэНтKMPЗЧГЃШнвзЃЌЮоЗЧЪЧбађНЅНјАбЮеКУЯТУцМИЕуЃК
ШчЙћФЃЪНДЎжаДцдкЯрЭЌЧАзККЭКѓзКЃЌМДpj-k pj-k+1, ..., pj-1 = p0 p1, ..., pk-1ЃЌФЧУДдкpjИњsiЪЇХфКѓЃЌШУФЃЪНДЎЕФЧАзКp0 p1...pk-1ЖдгІзХЮФБОДЎsi-k si-k+1...si-1ЃЌЖјКѓШУpkИњsiМЬајЦЅХфЁЃ
жЎЧАБОгІЪЧpjИњsiЦЅХфЃЌНсЙћЪЇХфСЫЃЌЪЇХфКѓЃЌСюpkИњsiЦЅХфЃЌЯрЕБгкj БфГЩСЫkЃЌФЃЪНДЎЯђгввЦЖЏj - kЮЛЁЃ
вђЮЊk ЕФжЕЪЧПЩБфЕФЃЌЫљвдЮвУЧгУnext[j]БэЪОjДІзжЗћЪЇХфКѓЃЌЯТвЛДЮЦЅХфФЃЪНДЎгІИУЬјЕНЕФЮЛжУЁЃЛЛбджЎЃЌЪЇХфЧАЪЧjЃЌpjИњsiЪЇХфЪБЃЌгУp[ next[j] ]МЬајИњsiЦЅХфЃЌЯрЕБгкjБфГЩСЫnext[j]ЃЌЫљвдЃЌj = next[j]ЃЌЕШМлгкАбФЃЪНДЎЯђгввЦЖЏj - next [j] ЮЛЁЃ
Жјnext[j]гІИУЕШгкЖрЩйФиЃПnext[j]ЕФжЕгЩj жЎЧАЕФФЃЪНДЎзгДЎжагаЖрДѓГЄЖШЕФЯрЭЌЧАзККѓзКЫљОіЖЈЃЌШчЙћj жЎЧАЕФФЃЪНДЎзгДЎжаЃЈВЛКЌjЃЉгазюДѓГЄЖШЮЊkЕФЯрЭЌЧАзККѓзКЃЌФЧУДnext [j] = kЁЃ
ШчжЎЧАЕФЭМЫљЪОЃК
НгЯТРДЃЌдлУЧРДЗжЮіЯТKMPЕФЪБМфИДдгЖШЁЃЗжЮіжЎЧАЃЌЯШРДЛиЙЫЯТKMPЦЅХфЫуЗЈЕФСїГЬЃК
ЁА KMPЕФЫуЗЈСїГЬЃК
МйЩшЯждкЮФБОДЎSЦЅХфЕН i ЮЛжУЃЌФЃЪНДЎPЦЅХфЕН j ЮЛжУ
ШчЙћj = -1ЃЌЛђепЕБЧАзжЗћЦЅХфГЩЙІЃЈМДS[i] == P[j]ЃЉЃЌЖМСюi++ЃЌj++ЃЌМЬајЦЅХфЯТвЛИізжЗћЃЛ
ШчЙћj != -1ЃЌЧвЕБЧАзжЗћЦЅХфЪЇАмЃЈМДS[i] != P[j]ЃЉЃЌдђСю i ВЛБфЃЌj = next[j]ЁЃДЫОйвтЮЖзХЪЇХфЪБЃЌФЃЪНДЎPЯрЖдгкЮФБОДЎSЯђгввЦЖЏСЫj - next [j] ЮЛЁЃЁБ
ЮвУЧЗЂЯжШчЙћФГИізжЗћЦЅХфГЩЙІЃЌФЃЪНДЎЪззжЗћЕФЮЛжУБЃГжВЛЖЏЃЌНіНіЪЧi++ЁЂj++ЃЛШчЙћЦЅХфЪЇХфЃЌi ВЛБфЃЈМД i ВЛЛиЫнЃЉЃЌФЃЪНДЎЛсЬјЙ§ЦЅХфЙ§ЕФnext [j]ИізжЗћЁЃећИіЫуЗЈзюЛЕЕФЧщПіЪЧЃЌЕБФЃЪНДЎЪззжЗћЮЛгкi - jЕФЮЛжУЪБВХЦЅХфГЩЙІЃЌЫуЗЈНсЪјЁЃ
4. РЉеЙ1ЃКBMЫуЗЈ
KMPЕФЦЅХфЪЧДгФЃЪНДЎЕФПЊЭЗПЊЪМЦЅХфЕФЃЌЖј1977ФъЃЌЕТПЫШјЫЙДѓбЇЕФRobert S. BoyerНЬЪкКЭJ Strother MooreНЬЪкЗЂУїСЫвЛжжаТЕФзжЗћДЎЦЅХфЫуЗЈЃКBoyer-MooreЫуЗЈЃЌМђГЦBMЫуЗЈЁЃИУЫуЗЈДгФЃЪНДЎЕФЮВВППЊЪМЦЅХфЃЌЧвгЕгадкзюЛЕЧщПіЯТO(N)ЕФЪБМфИДдгЖШЁЃдкЪЕМљжаЃЌБШKMPЫуЗЈЕФЪЕМЪаЇФмИпЁЃ
BMЫуЗЈЖЈвхСЫСНИіЙцдђЃК
ЛЕзжЗћЙцдђЃКЕБЮФБОДЎжаЕФФГИізжЗћИњФЃЪНДЎЕФФГИізжЗћВЛЦЅХфЪБЃЌЮвУЧГЦЮФБОДЎжаЕФетИіЪЇХфзжЗћЮЊЛЕзжЗћЃЌДЫЪБФЃЪНДЎашвЊЯђгввЦЖЏЃЌвЦЖЏЕФЮЛЪ§ = ЛЕзжЗћдкФЃЪНДЎжаЕФЮЛжУ - ЛЕзжЗћдкФЃЪНДЎжазюгвГіЯжЕФЮЛжУЁЃДЫЭтЃЌШчЙћ"ЛЕзжЗћ"ВЛАќКЌдкФЃЪНДЎжЎжаЃЌдђзюгвГіЯжЮЛжУЮЊ-1ЁЃ
КУКѓзКЙцдђЃКЕБзжЗћЪЇХфЪБЃЌКѓвЦЮЛЪ§ = КУКѓзКдкФЃЪНДЎжаЕФЮЛжУ - КУКѓзКдкФЃЪНДЎЩЯвЛДЮГіЯжЕФЮЛжУЃЌЧвШчЙћКУКѓзКдкФЃЪНДЎжаУЛгадйДЮГіЯжЃЌдђЮЊ-1ЁЃ
ЯТУцОйР§ЫЕУїBMЫуЗЈЁЃР§ШчЃЌИјЖЈЮФБОДЎЁАHERE IS A SIMPLE EXAMPLEЁБЃЌКЭФЃЪНДЎЁАEXAMPLEЁБЃЌЯжвЊВщевФЃЪНДЎЪЧЗёдкЮФБОДЎжаЃЌШчЙћДцдкЃЌЗЕЛиФЃЪНДЎдкЮФБОДЎжаЕФЮЛжУЁЃ
1 . ЪзЯШЃЌ"ЮФБОДЎ"гы"ФЃЪНДЎ"ЭЗВПЖдЦыЃЌДгЮВВППЊЪМБШНЯЁЃ"S"гы"E"ВЛЦЅХфЁЃетЪБЃЌ"S"ОЭБЛГЦЮЊ"ЛЕзжЗћ"ЃЈbad characterЃЉЃЌМДВЛЦЅХфЕФзжЗћЃЌЫќЖдгІзХФЃЪНДЎЕФЕк6ЮЛЁЃЧв"S"ВЛАќКЌдкФЃЪНДЎ"EXAMPLE"жЎжаЃЈЯрЕБгкзюгвГіЯжЮЛжУЪЧ-1ЃЉЃЌетвтЮЖзХПЩвдАбФЃЪНДЎКѓвЦ6-(-1)=7ЮЛЃЌДгЖјжБНгвЦЕН"S"ЕФКѓвЛЮЛЁЃ
2 . вРШЛДгЮВВППЊЪМБШНЯЃЌЗЂЯж"P"гы"E"ВЛЦЅХфЃЌЫљвд"P"ЪЧ"ЛЕзжЗћ"ЁЃЕЋЪЧЃЌ"P"АќКЌдкФЃЪНДЎ"EXAMPLE"жЎжаЁЃвђЮЊЁАPЁБетИіЁАЛЕзжЗћЁБЖдгІзХФЃЪНДЎЕФЕк6ЮЛЃЈДг0ПЊЪМБрКХЃЉЃЌЧвдкФЃЪНДЎжаЕФзюгвГіЯжЮЛжУЮЊ4ЃЌЫљвдЃЌНЋФЃЪНДЎКѓвЦ6-4=2ЮЛЃЌСНИі"P"ЖдЦыЁЃ
3 . вРДЮБШНЯЃЌЕУЕН ЁАMPLEЁБЦЅХфЃЌГЦЮЊ"КУКѓзК"ЃЈgood suffixЃЉЃЌМДЫљгаЮВВПЦЅХфЕФзжЗћДЎЁЃзЂвтЃЌ"MPLE"ЁЂ"PLE"ЁЂ"LE"ЁЂ"E"ЖМЪЧКУКѓзКЁЃ
4 . ЗЂЯжЁАIЁБгыЁАAЁБВЛЦЅХфЃКЁАIЁБЪЧЛЕзжЗћЁЃШчЙћЪЧИљОнЛЕзжЗћЙцдђЃЌДЫЪБФЃЪНДЎгІИУКѓвЦ2-(-1)=3ЮЛЁЃЮЪЬтЪЧЃЌгаУЛгаИќгХЕФвЦЗЈЃП
5 . ИќгХЕФвЦЗЈЪЧРћгУКУКѓзКЙцдђЃКЕБзжЗћЪЇХфЪБЃЌКѓвЦЮЛЪ§ = КУКѓзКдкФЃЪНДЎжаЕФЮЛжУ - КУКѓзКдкФЃЪНДЎжаЩЯвЛДЮГіЯжЕФЮЛжУЃЌЧвШчЙћКУКѓзКдкФЃЪНДЎжаУЛгадйДЮГіЯжЃЌдђЮЊ-1ЁЃ
6 . МЬајДгЮВВППЊЪМБШНЯЃЌЁАPЁБгыЁАEЁБВЛЦЅХфЃЌвђДЫЁАPЁБЪЧЁАЛЕзжЗћЁБЃЌИљОнЁАЛЕзжЗћЙцдђЁБЃЌКѓвЦ 6 - 4 = 2ЮЛЁЃвђЮЊЪЧзюКѓвЛЮЛОЭЪЇХфЃЌЩаЮДЛёЕУКУКѓзКЁЃ
гЩЩЯПЩжЊЃЌBMЫуЗЈВЛНіаЇТЪИпЃЌЖјЧвЙЙЫМЧЩУюЃЌШнвзРэНтЁЃ
5. РЉеЙ2ЃКSundayЫуЗЈ
ЩЯЮФжаЃЌЮвУЧвбОНщЩмСЫKMPЫуЗЈКЭBMЫуЗЈЃЌетСНИіЫуЗЈдкзюЛЕЧщПіЯТОљОпгаЯпадЕФВщевЪБМфЁЃЕЋЪЕМЪЩЯЃЌKMPЫуЗЈВЂВЛБШзюМђЕЅЕФcПтКЏЪ§strstr()ПьЖрЩйЃЌЖјBMЫуЗЈЫфШЛЭЈГЃБШKMPЫуЗЈПьЃЌЕЋBMЫуЗЈвВЛЙВЛЪЧЯжгазжЗћДЎВщевЫуЗЈжазюПьЕФЫуЗЈЃЌБОЮФзюКѓдйНщЩмвЛжжБШBMЫуЗЈИќПьЕФВщевЫуЗЈМДSundayЫуЗЈЁЃ
SundayЫуЗЈгЩDaniel M.Sundayдк1990ФъЬсГіЃЌЫќЕФЫМЯыИњBMЫуЗЈКмЯрЫЦЃК
жЛВЛЙ§SundayЫуЗЈЪЧДгЧАЭљКѓЦЅХфЃЌдкЦЅХфЪЇАмЪБЙизЂЕФЪЧЮФБОДЎжаВЮМгЦЅХфЕФзюФЉЮЛзжЗћЕФЯТвЛЮЛзжЗћЁЃ
ШчЙћИУзжЗћУЛгадкФЃЪНДЎжаГіЯждђжБНгЬјЙ§ЃЌМДвЦЖЏЮЛЪ§ = ЦЅХфДЎГЄЖШ + 1ЃЛ
ЗёдђЃЌЦфвЦЖЏЮЛЪ§ = ФЃЪНДЎжазюгвЖЫЕФИУзжЗћЕНФЉЮВЕФОрРы+1ЁЃ
ЯТУцОйИіР§згЫЕУїЯТSundayЫуЗЈЁЃМйЖЈЯждквЊдкЮФБОДЎ"substring searching algorithm"жаВщевФЃЪНДЎ"search"ЁЃ
1 . ИеПЊЪМЪБЃЌАбФЃЪНДЎгыЮФБОДЎзѓБпЖдЦыЃКi ng searching algorithm2 . НсЙћЗЂЯждкЕк2ИізжЗћДІЗЂЯжВЛЦЅХфЃЌВЛЦЅХфЪБЙизЂЮФБОДЎжаВЮМгЦЅХфЕФзюФЉЮЛзжЗћЕФЯТвЛЮЛзжЗћЃЌМДБъДжЕФзжЗћ iЃЌвђЮЊФЃЪНДЎsearchжаВЂВЛДцдкiЃЌЫљвдФЃЪНДЎжБНгЬјЙ§вЛДѓЦЌЃЌЯђгввЦЖЏЮЛЪ§ = ЦЅХфДЎГЄЖШ + 1 = 6 + 1 = 7ЃЌДг i жЎКѓЕФФЧИізжЗћЃЈМДзжЗћnЃЉПЊЪМЯТвЛВНЕФЦЅХфЃЌШчЯТЭМЃК
substring sea r ching algorithm3 . НсЙћЕквЛИізжЗћОЭВЛЦЅХфЃЌдйПДЮФБОДЎжаВЮМгЦЅХфЕФзюФЉЮЛзжЗћЕФЯТвЛЮЛзжЗћЃЌЪЧ'r'ЃЌЫќГіЯждкФЃЪНДЎжаЕФЕЙЪ§Ек3ЮЛЃЌгкЪЧАбФЃЪНДЎЯђгввЦЖЏ3ЮЛЃЈr ЕНФЃЪНДЎФЉЮВЕФОрРы + 1 = 2 + 1 =3ЃЉЃЌЪЙСНИі'r'ЖдЦыЃЌШчЯТЃК
4 . ЦЅХфГЩЙІЁЃ
ЛиЙЫећИіЙ§ГЬЃЌЮвУЧжЛвЦЖЏСЫСНДЮФЃЪНДЎОЭевЕНСЫЦЅХфЮЛжУЃЌдЕгкSundayЫуЗЈУПвЛВНЕФвЦЖЏСПЖМБШНЯДѓЃЌаЇТЪКмИпЁЃЭъЁЃ
6. ВЮПМЮФЯз
ЁЖЫуЗЈЕМТлЁЗЕФЕкЪЎЖўеТЃКзжЗћДЎЦЅХфЃЛ
БОЮФжаФЃЪНДЎЁАABCDABDЁБЕФВПЗжЭМРДздгкДЫЮФЃКhttp://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.htmlЃЛ
БОЮФ3.3.7НкжагаЯозДЬЌздЖЏЛњЕФЭМгЩЮЂВЉЭјгб@ЙЈТНАВ ЛцжЦЃКhttp://d.pr/i/NEizЃЛ
ББОЉ7дТЪюМйАрзоВЉАыаЁЪБKMPЪгЦЕЃКhttp://www.julyedu.com/video/play/id/5ЃЛ
ББОЉ7дТЪюМйАрзоВЉЕкЖўДЮПЮЕФPPTЃКhttp://yun.baidu.com/s/1mgFmw7uЃЛ
РэНтKMP ЕФ9еХPPTЃКhttp://weibo.com/1580904460/BeCCYrKz3#_rnd1405957424876ЃЛ
ЯъНтKMPЫуЗЈЃЈЖрЭМЃЉЃКhttp://www.cnblogs.com/yjiyjige/p/3263858.htmlЃЛ
БОЮФЕк4ВПЗжЕФBMЫуЗЈВЮПМздДЫЮФЃКhttp://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.htmlЃЛ
http://youlvconglin.blog.163.com/blog/static/5232042010530101020857ЃЛ
ЁЖЪ§ОнНсЙЙ ЕкЖўАцЁЗЃЌбЯЮЕУє & ЮтЮАУёБржјЃЛ
http://blog.csdn.net/v_JULY_v/article/details/6545192ЃЛ
http://blog.csdn.net/v_JULY_v/article/details/6111565ЃЛ
SundayЫуЗЈЕФдРэгыЪЕЯжЃКhttp://blog.chinaunix.net/uid-22237530-id-1781825.htmlЃЛ
ФЃЪНЦЅХфжЎSundayЫуЗЈЃКhttp://blog.csdn.net/sunnianzhong/article/details/8820123ЃЛ
вЛЦЊKMPЕФгЂЮФНщЩмЃКhttp://www.inf.fh-flensburg.de/lang/algorithmen/pattern/kmpen.htmЃЛ
Юв2014Фъ9дТ3ШедкЮїАВЕчзгПЦДѓЕФУцЪд&ЫуЗЈНВзљЪгЦЕЃЈЕк36Зжжг~Ек94ЗжжгНВKMPЃЉЃКhttp://www.julyedu.com/video/play/21ЃЛ
вЛЗљЭМРэНтKMP nextЪ§зщЕФЧѓЗЈЃКhttp://v.atob.site/kmp-next.html
7. КѓМЧ
ЖджЎЧАЛьТвЕФЮФеТИјЙуДѓЖСепДјРДЕФРЇШХБэЪОжТЧИЃЌЖджиаТаДОЭКѓЕФБОЮФМДНЋИјЖСепДјРДЕФЧхЮњБэЪОаРЮПЁЃЯЃЭћДѓВПЗжЕФГѕбЇепЃЌЩѕжСЩйВПЗжЕФЗЧМЦЫуЛњзЈвЕЖСепвВФмПДЖЎДЫЮФЁЃгаШЮКЮЮЪЬтЃЌЛЖгЫцЪБХњЦРжИе§ЃЌthanksЁЃ
JulyЁЂЖўСувЛЫФФъАЫдТЖўЪЎЖўШеЭэОХЕуЁЃ