��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise����ǰ����
��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise��һ������ʽ��̷�ʽ��
��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise������JavaScript �첽��̣�
��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise��������дPromiseԴ�룩
��Part1��ҵ��https://gitee.com/zgp-qz/part01-task
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż���һ��ECMAScript �����ԣ�
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż�������TypeScript ���ԣ�
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż�������JavaScript �����Ż�1��
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż����ġ�JavaScript �����Ż�2��
��Part2��ҵ��https://gitee.com/zgp-qz/part02-homework
JavaScript �����Ż�1
-
-
-
-
- �γ̸���
- �ڴ����
- JavaScript ���������
- GC�㷨����
- ���ü����㷨ʵ��ԭ��
- ���ü����㷨��ȱ��
- �������㷨ʵ��ԭ��
- �������㷨��ȱ��
- ��������㷨ʵ��ԭ��
- ����GC�㷨�ܽ�
- ��ʶ V8
- V8 �������ղ���
- V8 ��������������
- V8 ��������������
- V8 ���������ܽ�
- Performance ���߽���
- �ڴ����������
- ����ڴ�ļ��ַ�ʽ
- �������������ڴ�
- Timeline ��¼�ڴ�
- �ѿ��ղ��ҷ��� DOM
- �ж��Ƿ����Ƶ�� GC
- Performance �ܽ�
- �����Ż�����
- JSBench ʹ��
- ����ȫ�ֱ���
- ����ȫ�ֱ���
- ͨ��ԭ�Ͷ������Ӹ��ӷ���
- �ܿ��հ�����
- �������Է��ʷ���ʹ��
- For ѭ���Ż�
- ѡ�����ŵ�ѭ������
- �ĵ���Ƭ�Ż��ڵ�����
- ��¡�Ż��ڵ����
- ֱ�����滻 new Object
-
-
-
�γ̸���
�����������Ϸ�չ�������Ż��Ǹ����ɱ���Ļ��⣬ʲô������Ϊ����������������Ż��أ���������˵���κ�һ���������Ч�ʣ��������п�������Ϊ�������Կ�����һ���Ż���������Ҳ����ζ�������������Ĺ������кܶ�ֵ���Ż��ĵط���
�ر�����ǰ��Ӧ�ÿ��������У������Ż�����˵�������ڵġ����磺������Դ�õ������磬���ݵĴ��䷽ʽ��������������ʹ�õ��Ŀ�ܵȵȣ������Խ����Ż���

����Ҫ̽�ֵ��� javascript �������Ż���
������˵���ǣ�
����֪�ڴ�ռ��ʹ�ã����������յķ�ʽ���ܣ��Ӷ������ǿ��Ա�д����Ч�� javascript ���롣
���濪һ�������Ż����漰�������ݣ�

�ڴ����
����Ӳ�������IJ��Ϸ�չ��ͬʱ����������Ե���Ҳ���Դ��� GC ���ƣ����ԣ�������һЩ�仯�����������ڲ���Ҫ�ر�ע���ڴ�ռ�ʹ�õ������Ҳ�ܹ������������Ӧ�Ĺ��ܿ�����
Ϊʲô������Ҫ�����ڴ�����أ�
���濴�����Ĵ��룺

- �ڴ棺�ɿɶ�д�ĵ�Ԫ��ɣ���ʾһƬ�ɲ����Ŀռ䡣
- ��������Ϊ��ȥ����һƬ�ռ�����롢ʹ�ú��ͷš�
- �ڴ��������������������ռ䡢ʹ�ÿռ䡢�ͷſռ䡣
- �������̣����� �C ʹ�� �C �ͷ�
JavaScript �е��ڴ����( JS ������ν����ڴ������)��
������������һ���ģ�Ҳ�Ƿ�������ִ������һ�����̣����ǣ����� ECMAScript �в�û���ṩ��Ӧ�IJ��� API������ JS ���Բ����� C ���� C++ �����ɿ����������ĵ�����Ӧ�� API ����������Ŀռ������
��������ʹ��ˣ���Ҳ����Ӱ������ͨ�� JS �ű�����ʾ��ǰ���ڲ�һ���ռ������������������ɵġ�

JavaScript ���������
�����ȿ�һ���� JS �У�ʲô�������ݻᱻ��������������
- JavaScript ���е��ڴ�������Զ���
ÿ������ȥ�������֡��ַ�������ȵ�ʱ�������Զ�������Ӧ�Ŀռ䣬��������ִ�еĹ��������ͨ��һЩ���ù�ϵ�������ҵ�ijЩ�����ʱ����ô��Щ����ͻᱻ���������� - �����ٱ�����ʱ������
�ٻ���˵��Щ������ʵ���Ѿ����ڵģ��������ڴ�����һЩ�����ʵ������˵�ṹ�ԵĴ���������û�а취��ȥ�ҵ��������Ķ������ֶ���Ҳ�ᱻ���������� - �����ܴӸ��Ϸ��ʵ�ʱ������
֪����ʲô������֮��JS����ͻ������������������ռ�ݵĿռ���л��գ�������̾�����ν�� JavaScript �������ա�
JavaScript �е� �ɴ���� ��
- ���Է��ʵ��Ķ�����ǿɴ����(���á���������)��
- �ɴ�ı����ǴӸ��ϳ����Ƿ��ܹ����ҵ���
- �� JavaScript �еĸ���������Ϊ��ǰ��ȫ�ֱ�������(ȫ��ִ��������)��
JavaScript �е�������ɴ�
let obj = {
name: 'xm'} // xm �ռ䱻 obj ���ã���ȫ�ֵ�ִ���������£� ��ǰ�� obj ���ԴӸ��ϱ��ҵ��ģ��ɴ�ģ�let ali = obj // xm �ռ��ֶ���һ�����ã�������ֵ�仯(�������ü����㷨���õ�)��obj = null // obj �� xm �ռ�����ñ��ϵ��ˣ����� xm ���ǿɴ�ģ���Ϊ ali ����������
function objGroup(obj1, obj2) {
obj1.next = obj2obj2.prev = obj1return {
o1: obj1,o2: obj2}
}let obj = objGroup({
name: 'obj1' }, {
name: 'obj2' })console.log(obj);



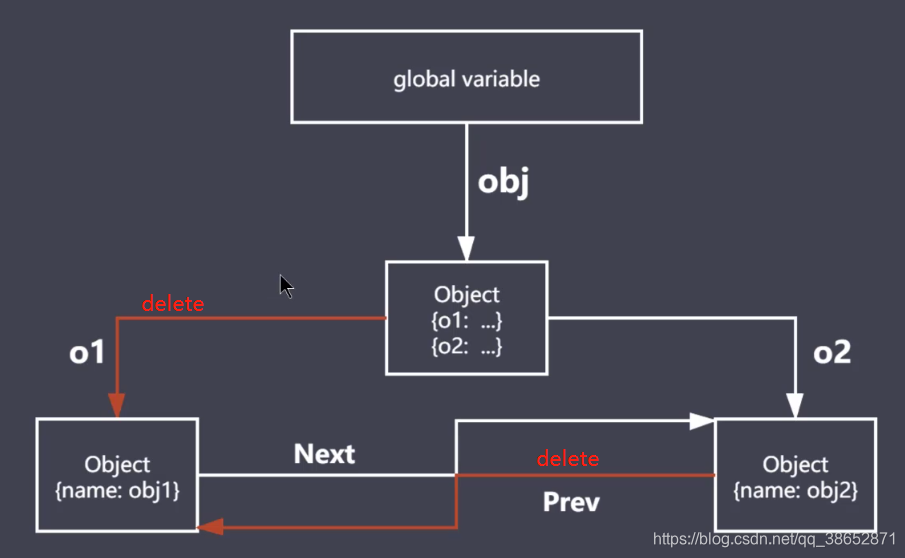

���ܽ�˵����
��д�����ʱ��������һЩ�������õĹ�ϵ�����ԴӸ����±������в��ң���������һ�������չ����ҵ�ij������
�������˵ȥ�ҵ������Ķ����·�����ƻ�������˵�������ˣ����ʱ����û�а취���ҵ������ͻ��������Ϊ����
���Ϳ������������ջ���ȥ�������յ���
GC�㷨����
GC(Garbage Collection)���������ջ��Ƶļ�д��
GC������ʱ�����������ҵ��ڴ��е����������ͷźͻ��տռ䣬�������Ǻ����Ĵ������ȥʹ�á�

GC �㷨��ʲô��
- GC ��һ�ֻ��ƣ�������������ɻ��չ���
- �������ݾ��Dz��������ͷſռ䣬���տռ�
- �㷨���ǹ���ʱ���Һͻ�������ѭ�Ĺ���
���� GC �㷨��
- ���ü���
- ������
- �������
- �ִ�����
���ü����㷨ʵ��ԭ��
����˼�룺�������������жϵ�ǰ�������Ƿ�Ϊ 0
���ڲ�ȥͨ��һ�����ü���������ά����ǰ��������������Ӷ��жϸö����������ֵ�Ƿ�Ϊ 0 ���������Dz���һ���������������ֵΪ 0 ��ʱ�� GC �Ϳ�ʼ�������������ڵĿռ���л����ͷ���ʹ�á�
Ҳ��ʽ��Ϊ���ü������Ĵ��ڣ����������ü����㷨��ִ��Ч������������ GC �㷨�������
���ü����� �ı�Ĺ������ù�ϵ�ı�ʱ����������(��ijһ�������������ù�ϵ�����ı��ʱ�����ü������ͻ������ĵ�ǰ������ö�������Ӧ��������ֵ)
����������Ϊ 0 ��ʱ����������
const user1 = {
age: 111 }
const user2 = {
age: 222 }
const user3 = {
age: 333 }const nameList = [user1.age, user2.age, user3.age]// function fn(){
// num1 = 1
// num2 = 2
// }function fn() {
/** * ���� const ��num1 �� num2 ֻ���� fn �ڲ���Ч������ fn ����֮��* ���ⲿȫ�ֵĵط��Ҳ��� num1 �� num2 ��ʱ�� �������ϵ����ü������� 0 GC �ͻ��������������������������յ� */const num1 = 1const num2 = 2
}fn()
���ü����㷨��ȱ��
�ŵ㣺
- ��������ʱ��������
- ����ȼ��ٳ�����ͣ
ȱ�㣺
- ������ѭ�����õĶ���
- ʱ�俪����
function fn() {
const obj1 = {
}const obj2 = {
}/*** �����ָ����ϵ������������Ҳ���������������ţ����ü����㷨������*/obj1.name = obj2obj2.name = obj1return 'this is a test'
}fn()�������㷨ʵ��ԭ��
����˼�룺�ֱ�Ǻ�������������
��һ���Σ��������еĶ���Ȼ�����еĻ����(�ɴ����)��Ȼ����б�ǣ�
�ڶ����Σ��������еĶ���Ȼ�����Щ����û�б�ǵĶ�����������ͬʱע������ڵڶ����ε��У�����ѵ�һ���������õı�Ǹ�Ĩ�������� GC ��һ�λ��ܹ������Ĺ�����
ע��һ�㣬���������ȥ�����ʱ��ǰ������ֹͣ�����ġ�
��������ͨ�����εı�����Ϊ�ѵ�ǰ�������ռ���л��գ����ս���һ����ν�Ŀ����б�����ά������������ʹ�á�

ͨ�� global ����һֱ�ң��������ҵ��Ķ����ϱ�ǣ��� a1 b1 ������ijһ���ֲ��������ڲ���Ա������ֲ�������ִ�����֮��ͱ������ˣ����Դ� global �������Ҳ��� a1 �� b1 ����ʱ�� GC ���ƾͻ���Ϊ��������������������ǣ������� GC ������ʱ�ͻ�� a1 �� b1 ���յ���
�������㷨��ȱ��
��������ü�����˵����������һ�������ŵ㣺�����Խ��֮ǰ����ѭ�����ò��ܻ��յ�����(������������ͼ����� a1 �� b1 �������ã����ü����㷨�Ͳ�������)��
ȱ�㣺�����֮ǰ���������գ�������ռ���Ƭ�������⣬�����ÿռ�õ����ʹ�á�

��������㷨ʵ��ԭ��
���ȣ�����������Կ����DZ���������ǿ����Ϊ�����ڵ�һ���ζ���һ���ģ����DZ������еĻ������б�ǣ�ֻ��������β�ͬ����������ֱ�ӽ�û�б�ǵ������������������գ����DZ�������������֮ǰ����ȥ��һ�������IJ������ƶ������λ�ã��������ܹ��ڵ�ַ�ϲ���������



����������������ͷų������ڴ�ռ䡣
����GC�㷨�ܽ�
- ���ü���
- ������
- �������
��ʶ V8
V8 ��һ�������� javascript ִ������
javascript ֮�����ܸ�Ч����ת��������Ϊ V8 �Ĵ���
��Ч���� V8 ��һ��������㣬�ٶ�֮���Կ죬���˱�����һ������Ĺ�������֮�⣬V8 ����һ���ص㣺���� ��ʱ����
֮ǰ�ܶ� javascript ���涼��Ҫ��������ת�����ֽ��룬Ȼ��ȥִ�У��� V8 �Ϳ���ֱ�ӽ�Դ�뷭��ɿ���ִ�еĻ����룬������ʱ���ٶ��Ƿdz����
����һ���ص㣺V8 �ڴ�������
64λ �C 1.5G
32λ �C 800M
Ϊʲô����ôһ��������
��һ��������Ϊ�������ȥ����ģ��������е��ڴ��С������ҳӦ����˵�Ѿ��㹻ʹ��
�ڶ���V8 �ڲ����������ջ���Ҳ��������������һ�������Ƿdz�������
�ٷ���������һ�����ԣ�
�������ڴ�ﵽ 1.5G ��ʱ������������㷨�����������գ�ֻ��Ҫ���� 50ms ��������÷��������ȥ���գ���Ҫ 1S�����û�������˵��1S�Ѿ����Ǻܳ���ʱ���ˣ������������ 1.5G Ϊ�磬�� V8 �ڲ����ڴ����һ�����е����á�
�ܽ
- V8 ��һ�������� javascript ִ������
- ���ü�ʱ����
- V8 �ڴ�������
V8 �������ղ���
�ڳ���������У����õ��ܶ�����ݣ���Щ�����ֿ��Է�Ϊԭʼ���ݺͶ������͵����ݣ�������Щ������ԭʼ������˵���������������������Ƶģ������������ᵽ�Ļ�����Ҫ����ָ���ǵ�ǰ��������Ƕ�����Ķ������ݣ���ˣ�����������벻���ڴ�����ġ�
��V8���ж��ڴ����������ģ��������Ǿ�Ҫ֪������������һ������£������������������л��յġ�
- ���÷ִ����յ�˼��
- �ڴ��Ϊ��������������
- ��Բ�ͬ�Ķ�����ò�ͬ���㷨

- �ִ�����
- �ռ临��
- ������
- �������
- �������
V8 ��������������

V8 �ڴ���䣺
- V8 �ڴ�ռ�һ��Ϊ��
- С�ռ����ڴ洢����������32M | 16M��
- ������ָ���Ǵ��ʱ��϶̵Ķ������磺�������������ھֲ�������ı�����ǰ����ִ����֮��Ҫ���л��գ���������ȫ��������ı���һ�㶼��Ҫ���������˳�֮��Ž��л��գ�
�������������ʵ�֣�
- ���չ����в��ø����㷨 + �������
- �������ڴ�����Ϊ�����ȴ�С�ռ�
- ʹ�ÿռ�Ϊ From �����пռ�Ϊ To
- �����洢��From �ռ�
- ����������������� To
- From �� To�����ռ�����ͷ�
����ϸ��˵����
- ���������п��ܻ���ֽ���
- ����ָ���ǽ������������ƶ���������
- һ�� GC ֮������������Ҫ����
- To �ռ�ʹ���ʳ��� 25%
V8 ��������������
����������˵����
- ���������������Ҳ�����������
- 64λ����ϵͳ1.4G��32λ300M
- ����������ָ���Ǵ��ʱ��ϳ��Ķ���
�������������ʵ�֣�
- ��Ҫ���ñ������������������������㷨
- ����ʹ�ñ�������������ռ�Ļ���
- ���ñ���������пռ��Ż�
- ����������ǽ���Ч���Ż�
ϸ�ڶԱȣ�
- ������������������ʹ�ÿռ任ʱ��
- �����������������ղ��ʺϸ����㷨
�����������Ż��������գ�
��ȷһ�㣺���������ս��й�����ʱ�������������� javascript �����ִ�С�
��ν�ı������������˵���ǽ������������ղ����ֳɶ��С���������ȥ��ɵ�ǰ���������գ��Ӷ�ȥ���֮ǰһ����������������ղ�����
�ô������ó���ִ�к���������ȥ��������ɣ���������ǰ�����������е�ʱ�����������գ����������յ�ʱ�������г�������������ʱ�����ĸ��Ӻ���һЩ��

��Ȼ�����������������˾��õ�ǰ����ͣ���˺ܶ�Σ�����Ҫ���ף����� V8 �����������յ����ﵽ 1.5G ��ʱ����÷�������ǵ���ʽʱ��Ҳ������ 1���ӣ����������Ϸָ��Ǻ����ġ���������һ���أ�������ȵİ���ǰ�ĺܳ�һ�ε�ͣ��ʱ��ֱ�Ӳ�ֳɸ�С�Σ����������û���˵���ͻ��Եø��ӵú�һЩ��
V8 ���������ܽ�
- V8 ��һ�������� javascript ִ������
- V8 �ڴ���������
- V8 ���û��ڷִ�����˼��ʵ����������
- V8 �ڴ��Ϊ��������������
- V8 �������ճ����� GC �㷨
Performance ���߽���
Ϊʲôʹ�� Performance ���ߣ�
- GC ��Ŀ����Ϊ��ʵ���ڴ�ռ������ѭ��
- ����ѭ���Ļ�ʯ�Ǻ���ʹ��
- ʱ�̹�ע����ȷ���Ƿ����
- Performance �ṩ���ּ�ط�ʽ
ͨ��ʹ�� Performance ʱ�̼���ڴ�
ʹ�ò��裺
- �����������Ŀ����ַ
- ���뿪����Ա������壬ѡ�� ����(performance)
- ����¼�ƹ��ܣ����ʾ������
- ִ���û���Ϊ��һ��ʱ���ֹͣ¼��
- ���������м�¼���ڴ���Ϣ
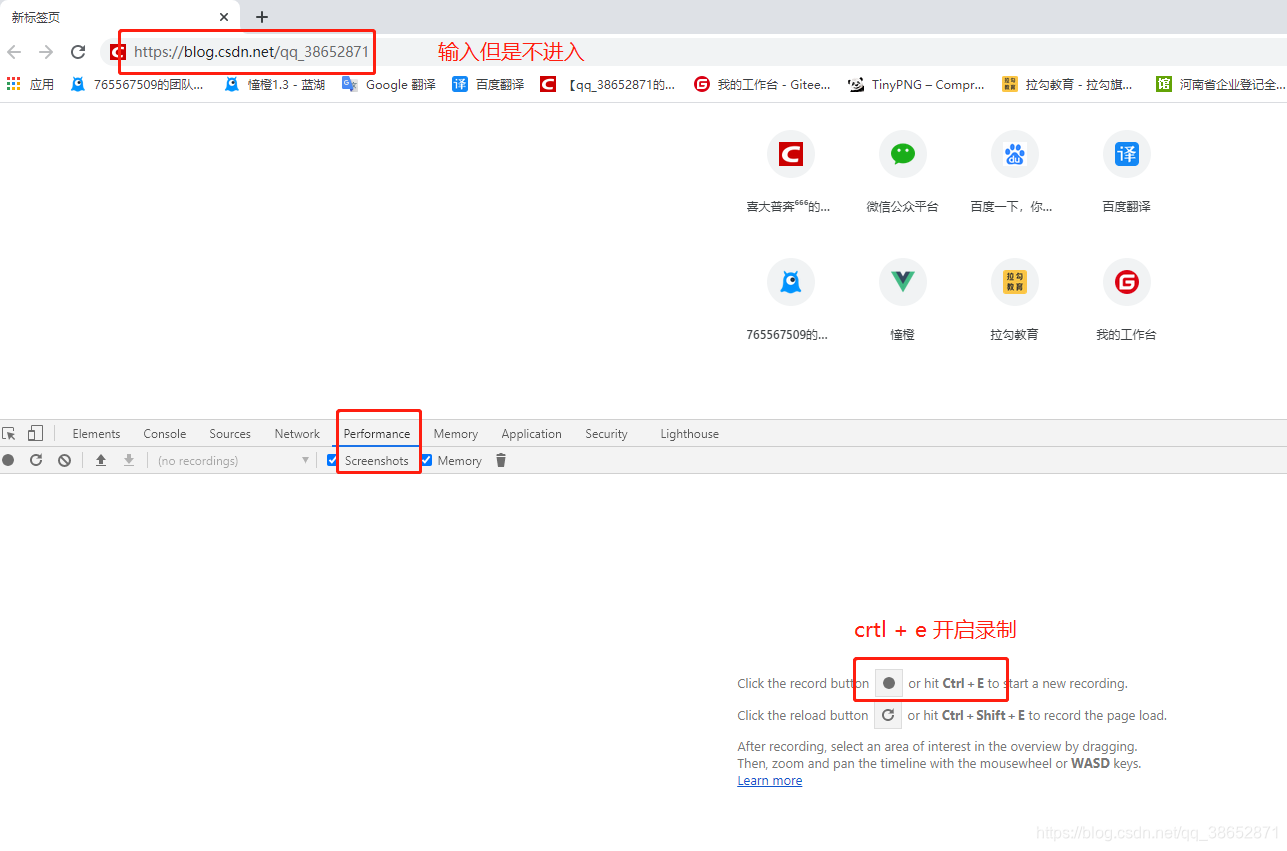
����¼��

����Ŀ����ַ
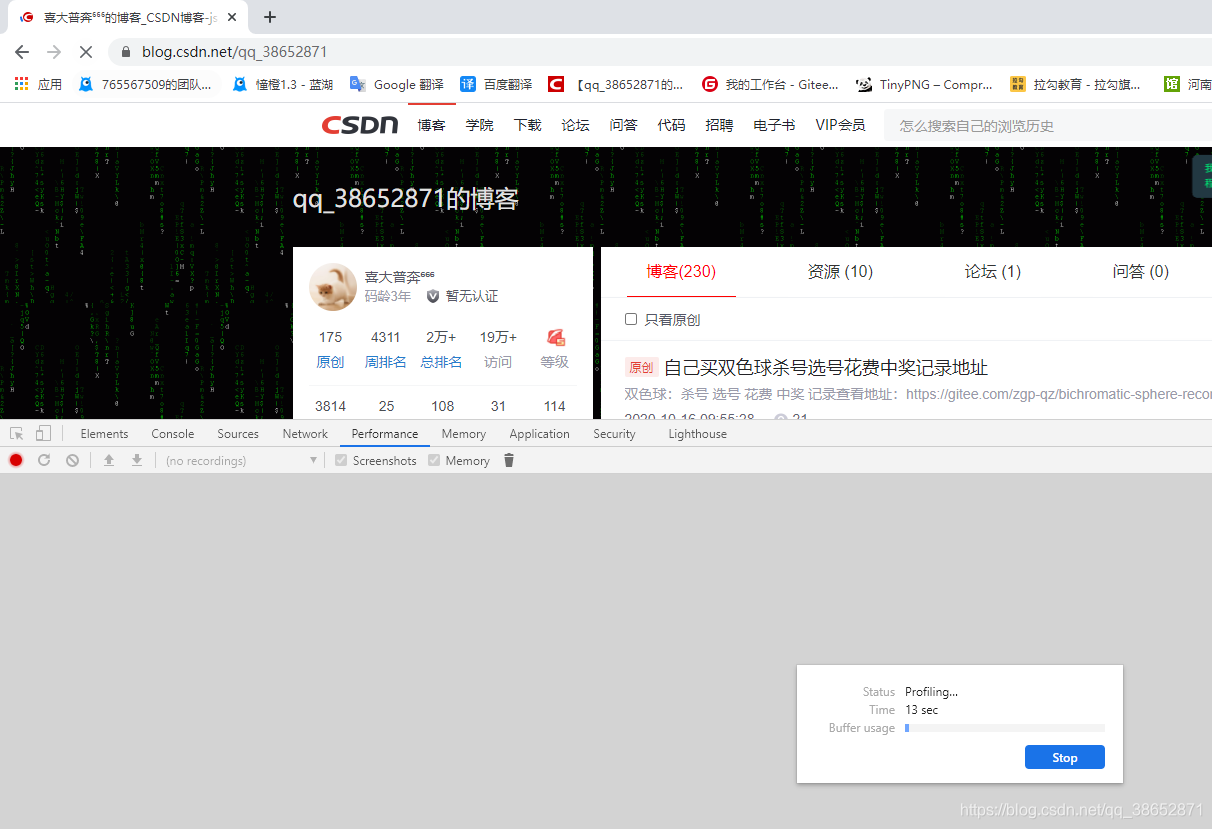
�����û�����

��� stop

�鿴���ɵķ�������

�ڴ����������
���һ�µ����ǵ�Ӧ�ó�����ִ�еĹ����У�����ڴ���������⣬��ô�������ڽ��������չʾ
����Ϳ��Ը��õ���� performance ���߽���һ������Ķ�λ�����������һЩ���ܵ�ģ������һЩ�ж��ı���
�ڴ���������ڱ��֣�
-
ҳ������ӳټ��ػ�����ͣ(���绷������)
һ����ж��ڴ������⣬�����뵱ǰ�� GC ����Ƶ����������������ص� -
ҳ������Գ�����������(���绷������)
һ�����Ϊ�����ڴ����ͣ���ν���ڴ�����ָ���ǵ�ǰ�Ľ���Ϊ�˴ﵽ��ѵ�ʹ���ٶȣ���������һ�����ڴ�ռ䣬��������ڴ�ռ�Ĵ�СԶ������ǰ�豸���������ṩ�Ĵ�С�� -
ҳ�����������ʱ���ӳ�Խ��Խ��
�������һ��������ڴ�й©
��Ϊ����������¸տ�ʼ��û������ģ����ܰ�����ijЩ����ij��֣������ǵ��ڴ�ռ�Խ��Խ�٣��������ν���ڴ�й©
����ڴ�ļ��ַ�ʽ
���ڴ���������ʱ��һ����Թ���Ϊ���������
- �ڴ�й©
- �ڴ�����
- Ƶ������������
�綨�ڴ�����ı���
- �ڴ�й©���ڴ�ʹ�ó�������
- �ڴ����ͣ��ڶ����豸�϶�������������
- Ƶ���������գ�ͨ���ڴ�仯ͼ���з���
����ڴ�ļ��ַ�ʽ��
- ��������������
- Timeline ʱ��ͼ��¼
- �ѿ��ղ��ҷ��� DOM
- �ж��Ƿ����Ƶ������������
�������������ڴ�
demo:
ƽ̨�������
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>�������������ڴ�仯</title>
</head>
<body><button id="btn">Add</button><script>btn.onclick = function() {
let arrList = new Array(1000000)}</script>
</body>
</html>
ʹ���������
shift + esc ������������������

�Ҽ��� javascript �ڴ� �е�����

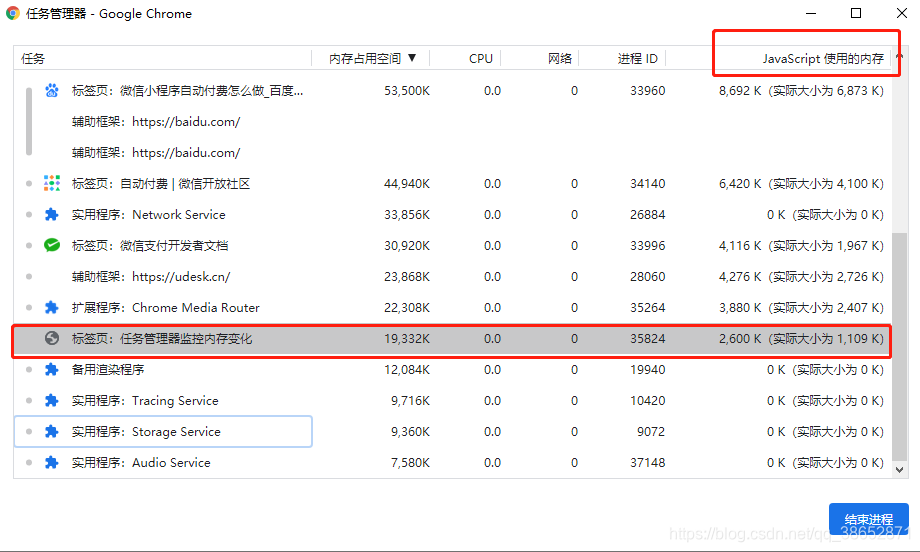
��һ���ڴ�ָ���� DOM �ڴ棬�������ڴ治������˵��ҳ���ڲ����ϵ��ڴ����ڴ�
���һ�� javascript �ڴ棬�����ʾ���� js �Ķѣ���һ�е�����Ҫ��ע����С���������ֵ������ʾ���ǽ��浱�У����пɴ��������ʹ�õ��ڴ��С����������ֵһֱ��������ζ�Ž����У�Ҫô�ڴ����¶���Ҫô�������ж����ڲ��ϵ�������
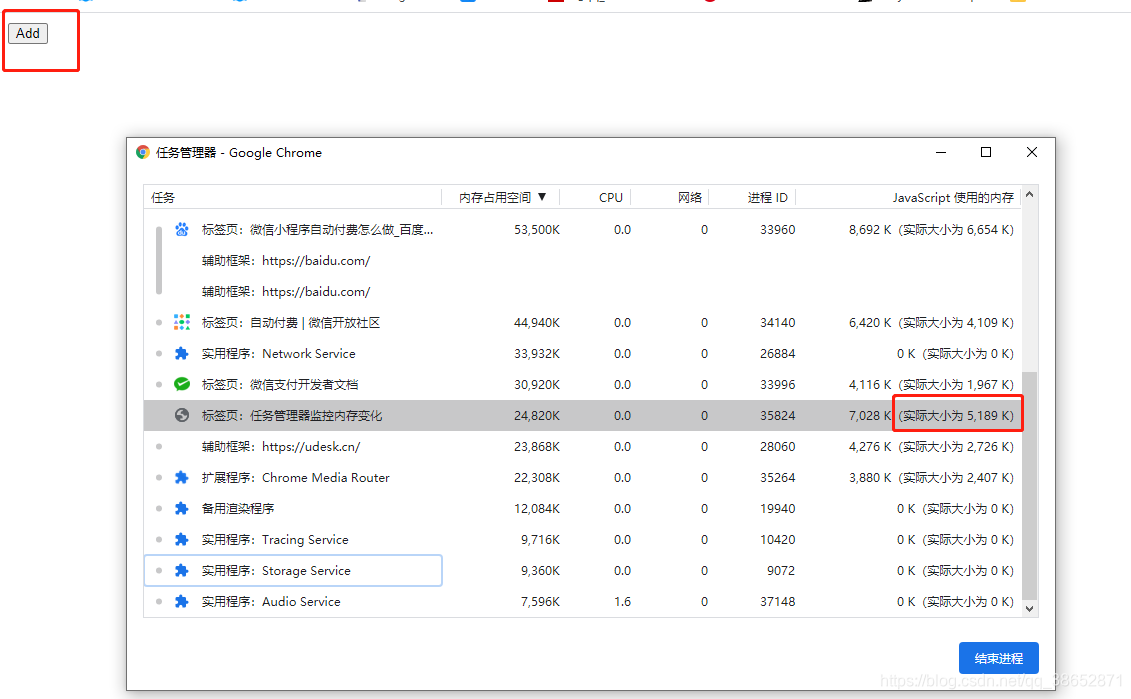
�ó����ۣ����˵С�����������ֵһֱ��������ζ�ŵ�ǰ���ڴ���������ģ�������ʲô���⣬�����������������Ϳ��������ˣ�ֻ�ܿ�������������ģ����ܶ�λ���⡣
Timeline ��¼�ڴ�
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>ʱ����¼�ڴ�仯</title>
</head>
<body><button id="btn">Add</button><script>const arr = []function test() {
for(let i = 0; i<100000; i++){
document.body.appendChild(document.createElement('p'))}arr.push(new Array(1000000).join('x'))}document.getElementById('btn').addEventListener('click',test)</script>
</body>
</html>

��¼�ƣ�������ΰ�ť��ֹͣ¼�ƣ������·�ͼ��

��ɫ��JS�ѣ���ɫ���ĵ�����ɫ��DOM�ڵ㣬��ɫ������������ɫ��GPU

Ϊ�˱��ڹ۲죬������JS��֮���ȫ���ص������ڹ۲�Ŀǰ����ű��� JS �� �ڴ��һ������
���ͼ��ʱ��ͼ������ƶ������Թ������ϱ���һ��ͼ�����Ժ���Ϊ��λ��¼��ҳ��ı仯

���Կ�����ǰҳ���һ��״̬��ͨ����ǰҳ���״̬���Զ�λ������ijһ����롣
����ֻ��ע JS ���ڴ棬���Կ������Ӹտ�ʼ��ƽ��״̬�����ڴ�ͻȻ�����ȥ�ˣ�����Ϊ���ǵĵ����ť����������ȥ֮����������ˣ�������Ϊ������������������ջ��ƣ��ڽű������ȶ�֮�� GC �Ϳ�ʼ�����ˣ����շǻ������ε������������ǵ����������ť���������м䴩����½�����������Լ��Ļ��ջ��ƣ������н���
���˵����ڴ�����ͼ��һֱ�����ߣ��������½�����ô����ʹ����ڴ����ĵ����⣬���п������ڴ�й©����ʱ����ôȥ��λ�����أ�
ע�⣬������һ��ʱ��ͼ�������Ƿ���ij���ڵ��������ʱ����ֱ�Ӷ�λ��ijһ��ʱ��ڵ�

����ֱ�Ӳ鿴ÿһ��ʱ�����ڴ����ģ������Կ�����ǰʱ������չʾ��һ��״̬���Ӷ���λ���µ�һ����������Ĵ���顣
�ѿ��ղ��ҷ��� DOM
����ԭ����
�ҵ���ǰ��JS�ѣ�Ȼ�������Ƭ���棬�Ϳ��Կ��������������Ϣ��������һ��ר����Է���DOM��һ����Ϊ��
ʲô�Ƿ���DOM��
�����Ͽ����ĺܶ�Ԫ�أ���ʵ����DOM �ڵ㣬����Щ�ڵ㱾Ӧ�ô����DOM���ϣ���������DOM�ڵ���м�����̬������������DOM��
�������ڵ��DOM�������룬������JS������Ҳû���������ţ�����ʵ�ͳ�Ϊ��һ�������������˵��ǰ��DOM�ڵ�ֻ�Ǵ�DOM���������ˣ������� JS �����л������������ţ�����DOM�ͽз���DOM��
���ַ���DOM �ڽ������ǿ������ģ��������ڴ���ȴռ���ſռ䣬��������������¾����ڴ�й©����˿���ͨ���ѿ��յĹ��ܰ��������ﶼ�ҳ�����ֻҪ���ҵ����Ϳ��Իص������������������������С�
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>�ѿ��ռ���ڴ�</title>
</head>
<body><button id="btn">Add</button><script>let tmpElefunction fn() {
let ul = document.createElement('ul')for(let i = 0; i < 10; i++){
let li = document.createElement('li')ul.appendChild(li) // �����˵��Dz���ҳ���ϴ���}tmpEle = ul}document.getElementById('btn').addEventListener('click',fn)</script>
</body>
</html>
ʹ������������ html �ű�

������Ϊ���ԣ�
-
û�е�� Add ������»�ȡ�ѿ���


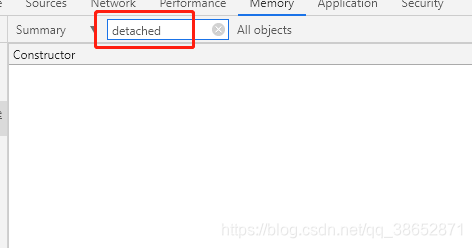
������û�ж�����
-
��� Add ֮���ٴλ�ȡ�ѿ��գ��������� detached
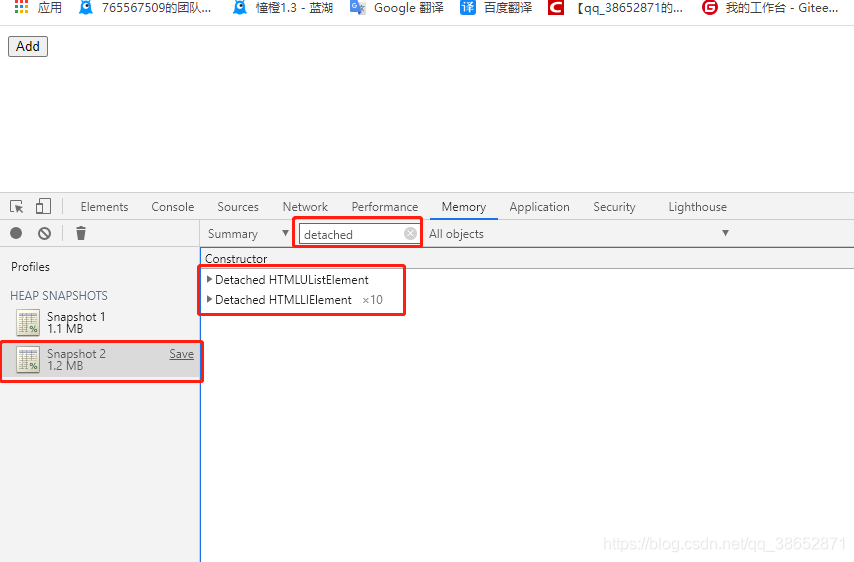
��ᷢ�ֿ���2���������ˣ�����JS������DOM�ڵ㣬��û�����ӵ������У������Ѿ����������ǵ��ڴ浱���ˣ�����ʵ����һ�ֿռ��ϵ��˷ѣ��������ͨ���ѿ��յĹ��ܣ��ҵ��ű���������ڵ����⡣Ҳ���Ǵ�����ν�ķ���DOM ��
Ҫ�����������ܼ��ڴ����н�Ԫ����Ϊ null �����ˣ���Ϊ֮��Ҳ��������������IJ����ˡ�

�ٴ�ʹ������������»�ȡ�ѿ��ղ鿴��

���ǻᷢ��û����
�ܽ
����������ṩ��һ�� �ѿ��� �Ĺ��ܣ��ѵ�ǰ�Ķѽ������ң�������֮���������Ƿ������һЩ��ν�ķ���DOM(detached)����Ϊ����DOM�ڽ����в����֣��������ڴ����ȷʵ���ڣ�����һ���ڴ���˷ѣ�����Ҫ���ľ��Ƕ�λ��������߷���DOM���ڵ�λ�ã�Ȼ����취�����������������ֱ����Ϊ null��
�ж��Ƿ����Ƶ�� GC
Ϊʲôȷ��Ƶ���������գ�
- GC ������ʱ��Ӧ�ó�����ֹͣ��
- Ƶ���ҹ����� GC �ᵼ��Ӧ�ü���
- �û�ʹ���и�֪Ӧ�ÿ���
���ַ�ʽ��
- TimeLine ʱ��ͼ���ڴ�����Ƶ�����������½�
- ���������(������� shift + esc)������Ƶ��������/��С
Performance �ܽ�
�ȸ���������ṩ��һ�����ܹ���
- ʹ������
- �ڴ��������ط���
- Performance ʱ��ͼ����ڴ�仯
- �������������ڴ�仯
- �ѿ��ղ��ҷ��� DOM
�����Ż�����
������ javascript ����
- �����Ͼ��Dzɼ�������ִ������������ѧͳ�ƺͷ���
- ʹ�û��� Benchmark.js �� https://jsperf.com ��ɣ�ֹͣά���ˣ�

JSBench ʹ��
JSBench һ��JSPerf �����Ʒ����Ϊ jsperf ��վֹͣά����
setup: ǰ�ó�ʼ����һЩ����
setup html: ǰ�õ�һЩHTMLԪ��
setup js: ǰ�õ�һЩͳһ��JS����
teardown: һЩ��β��ͳһ�IJ���


��� run ֮�ȴ�������һ��ʱ��
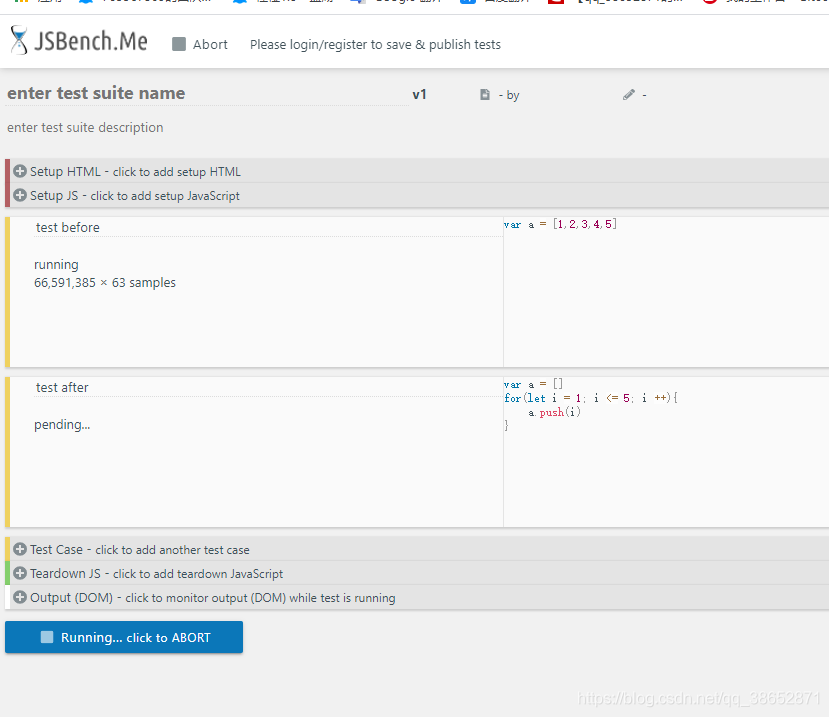

��������ܿ���������ͬ�������Ч����
���飺
ʹ�����ܲ��Ե�ʱ��һ����ǩҳ�������Ķ��ص�����Ϊ������Ƕ��̵߳ģ����Ŵı�ǩҳԽ��Խ�࣬�ụ��֮����ռ��ǰ����Դ��
���о��Dz��Ե�ʱ���ܵ�ͣ�ڵ�ǰ��ҳ�棬��Ϊ������ܻ���һ������IJ���������ϵͳ�ǿ���ͬʱ���������ģ������Թ����д����ִ��������ʱ��ģ���Ϊ��Ҫ������ȡ���������ʱ��ѽ�����С�����߹ص���Ȼ��ȥд�������룬��������������п��ܻᱻ�����ٻ�����ʱ�����ʱ�䲻һ����ȷ�ġ�
���о��dz������Ҫע��ĵ㣬���ܾ�ִ��һ�εõ��Ľ��۸��������һ������˵��һ������Ϊ���Ǻ����Ļ���˵�������յĴ𰸣�����Ӧ���ýű���ִ�м��Σ�Ȼ��ȡ�Ǹ����ʸ��ߵ�һ����������ܾ���������Ҫ�IJ�����Ϊ��
���о����ڳ����ִ���У���Ӧ�þ����ڴ����ִ��ʱ�䣬��ǰ�Ĺ�����Ҫ������һ�´����ִ���ٶȣ����Ƕ������ǵ����ܲ��ԣ������ǹ�ע��ֻ��ʱ�䣬��ֻ���ڶ�����ָ���е�һ����
һ�δ���ִ���ٶȿ죬������ζ����δ���ͺܽ�׳����ע�ĵ㲻һ������ô�����ı��ͽ���Ͳ�ͬ�ˣ������ڴ��������漰�������ܣ���ʵ���������棺Ҫô�ÿռ任ʱ�䣬Ҫô��ʡ����Ŀռ䣬��ȡʱ�䡣
����ȫ�ֱ���
�������Ͽ�������˵����ִ�й����У���������ijЩ������Ҫ���д洢��������Ҫ�����ܵİ��������ھֲ��������б��һ���ֲ�����������˵ΪʲôҪ��ô���������ҿ�������
ΪʲôҪ���ã�
- ȫ�ֱ���������ȫ��ִ�������ģ�������������Ķ���
js �����ǰ��ղ㼶���ϲ��ҵģ��±߾ֲ�������ı���û���ҵ������ն���ȥ�鵽��˵�ȫ�������ģ���������£����ҵ�ʱ�������Ƿdz���ģ������˴����ִ��Ч�ʣ� - ȫ��ִ��������һֱ������������ִ��ջ��ֱ�������˳�
������������¶��� GC �Ĺ����Ƿdz������ģ����������������������л��� - ���ij���ֲ������������ͬ������������ڱλ���Ⱦȫ��
�ܹ���˵��������ʹ��ȫ�ֱ�����ʱ����Ҫ���Ǹ�������飬���ͻ�����Ǵ���һЩ���벻���������
����ֻ����ִ��Ч�ʡ�
// ȫ�ֱ���
var i, str = ''for(i = 0; i < 1000; i++){
str += i
}// �ֲ�����
for(let i = 0; i < 1000; i++){
let str = ''str += i
}


����ȫ�ֱ���
ͨ������ȫ�ֱ����ķ�ʽ���ô����и��ߵ�ִ������
��ʹ���У�������� ȫ�ֱ��������浽�ֲ�
����Ա�һ�²��þֲ�����Ͳ����þֲ����棬���ܲ��쵽���ж��
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>����ȫ�ֱ���</title>
</head>
<body><input type="button" value="btn" id="btn1"><input type="button" value="btn" id="btn2"><input type="button" value="btn" id="btn3"><input type="button" value="btn" id="btn4"><p>111</p><input type="button" value="btn" id="btn5"><input type="button" value="btn" id="btn6"><input type="button" value="btn" id="btn7"><p>222</p><input type="button" value="btn" id="btn8"><input type="button" value="btn" id="btn9"><p>333</p><input type="button" value="btn" id="btn10"><script>// û������function getBtn1(){
let oBtn1 = document.getElementById('btn1')let oBtn3 = document.getElementById('btn3')let oBtn5 = document.getElementById('btn5')let oBtn7 = document.getElementById('btn7')let oBtn9 = document.getElementById('btn9')let oBtn10 = document.getElementById('btn10')}// ������function getBtn2(){
let doc = documentlet oBtn1 = doc.getElementById('btn1')let oBtn3 = doc.getElementById('btn3')let oBtn5 = doc.getElementById('btn5')let oBtn7 = doc.getElementById('btn7')let oBtn9 = doc.getElementById('btn9')let oBtn10 = doc.getElementById('btn10')}</script>
</body>
</html>


���Կ������������Ĵ�������������Ч��
ͨ��ԭ�Ͷ������Ӹ��ӷ���
js �е����ָ��
���캯����ԭ�Ͷ���ʵ�������캯����ʵ�������ǿ���ָ��ԭ�Ͷ���
���ij�����캯�����ڲ���һ����Ա��������������ʵ��������ҪƵ����ȥ���ã�����Ϳ���ֱ�ӽ���������ԭ�Ͷ����ϣ�������Ҫ�������ڹ��캯���ڲ���
�����ֲ�ͬ��ʵ�ַ�ʽ�����������������졣
- ��ԭ�Ͷ���������ʵ��������Ҫ�ķ���
�������һ�½�������ڹ��캯���ڲ��ͷ���ԭ�Ͷ����ϵ����ܲ��죺
var fn1 = function() {
this.foo = function() {
console.log(11111)}
}let f1 = new fn1()var fn2 = function() {
}
fn2.prototype.foo = function() {
console.log(11111)
}let f2 = new fn2()

���Կ���������Ч�ʲ���Ǻܴ��
�ܿ��հ�����
�հ����ص㣺
�ⲿ����ָ���ڲ������ã�
�ڡ��⡱����������ʡ��ڡ��������������

���ڱհ���
- �հ���һ��ǿ����
- �հ�ʹ�ò�����������ڴ�й©
- ��ҪΪ�˱հ����հ�
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>�հ�����</title>
</head>
<body><button id="btn">add</button><script>function foo() {
var el = document.getElementById('btn')el.onclick = function() {
console.log(el.id)}}foo()</script>
</body>
</html>
���Կ�����onclick �������õ���foo������ı���������ߵ� el ��һֱ�������ŵģ��������գ������ִ���Խ��Խ���ʱ�����ڴ��Ƿdz����Ѻõģ�Ҳ���DZհ������ڵ����壬�����ڴ�й©��
������
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>�հ�����</title>
</head>
<body><button id="btn">add</button><script>function foo() {
var el = document.getElementById('btn')el.onclick = function() {
console.log(el.id)}el = null // ���֮�� GC ���Զ��������ڴ�ռ�}foo()</script>
</body>
</html>
�������Է��ʷ���ʹ��
�������Է��ʷ������Ǻ����������صģ�Ϊ��ʵ�ָ��õķ�װ�ԣ����Ը����ʱ����ܻὫһЩ��Ա���Ժͷ���������һ���������ڲ���Ȼ�����ⲿȥ��©������һ�������Ե�ǰ�����Խ�����ɾ�IJ�IJ����������� js ����������в������ر�����á�
��Ϊ
- �� js �����Dz���Ҫ���Եķ��ʷ����ģ����е����Զ����ⲿ�ɼ���
- ��ʹ�����Է��ʷ�����ʱ���൱��������һ���ض��壬û�з��ʿ�����
function Person() {
this.name = 'icoder'this.age = 18this.getAge = function() {
return this.age}
}const p1 = new Person()
const a = p1.getAge()function Person() {
this.name = 'icoder'this.age = 18
}
const p2 = new Person()
const b = p2.age

For ѭ���Ż�
for ѭ���DZ�������о���ʹ�õ�����ṹ��ÿ�������������˵������ṹ�����Բ���forѭ���ķ�ʽ������
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Forѭ���Ż�</title>
</head>
<body><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><p class="btn">add</p><script>var aBtns = document.getElementsByClassName('btn')for(var i = 0; i < aBtns.length; i ++){
console.log(i)}for(var i = 0, len = aBtns.length; i < len; i ++){
console.log(i)}</script>
</body>
</html>

���Կ����ٶ�������һЩ��
ѡ�����ŵ�ѭ������
��ʵ�ʿ���Ӧ���У������������������ݵı����ṹ�����õ������ṹ֮���������ж���ѡ����б��������磺for ��forEach ��for �� in �ȵȡ�
����ȶ�һ��ͬ�������ݣ���ͬ�ı����������ĸ�����Կ�һЩ��
var arrList = new Array(1, 2, 3, 4, 5)arrList.forEach(function(item) {
console.log(item)
})for (var i = arrList.length; i; i--) {
console.log(arrList[i])
}for (var i in arrList) {
console.log(arrList[i])
}

���Կ�����forEach �����ģ�for �� in ��������
�ĵ���Ƭ�Ż��ڵ�����
������ⲿӦ�ÿ�����˵��DOM �����Ƿdz�Ƶ���ģ�������� DOM �Ľ������������Ƿdz��������ܵģ��ر��Ǵ����µĽڵ㣬���ڵ�������������ʱ���������һ�㶼������Ż������ػ棬�����������������ܵ�����ʱ�Ƚϴ�ģ����һ������ڽڵ���������������Ż�������
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>�Ż��ڵ�����</title>
</head>
<body><script>// ֱ�Ӳ���for(var i = 0; i < 10; i++){
var op = document.createElement('p')op.innerHTML = idocument.body.appendChild(op)}// �ȴ����ĵ���Ƭ���ٲ���const fragEl = document.createDocumentFragment()for(var i = 0; i < 10; i++){
var op = document.createElement('p')op.innerHTML = ifragEl.appendChild(op)}document.body.appendChild(fragEl)</script>
</body>
</html>

ͨ�����ֿ��Կ�����ͨ���ĵ���Ƭ�ķ�ʽͳһ����Ҫ��ֱ�� create append �IJ�����Ҫ��ġ�
��¡�Ż��ڵ����
��ν�Ŀ�¡ָ���ǣ�������Ҫȥ�����ڵ��ʱ�����ҵ�һ���������Ƶ�һ���ڵ㣬������¡һ�£�Ȼ���ٰѿ�¡�õ������Ľڵ�ֱ�����ӵ����ǽ��浱�С�
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>��¡�Ż��ڵ����</title>
</head>
<body><p id="box">old</p><script>// �½�for(var i = 0; i < 3; i++){
var op = document.createElement('p')op.innerHTML = idocument.body.appendChild(op)}// ��¡var oldP = document.getElementById('box')for(var i = 0; i < 3; i++){
var op = oldP.cloneNode(false)op.innerHTML = idocument.body.appendChild(op)}</script>
</body>
</html>

ͨ�����Եó�����¡��Ч��Ҫ�����½���Ч��
ֱ�����滻 new Object
��ν��ֱ�����滻 new Object ���ǵ�����Ҫ���������ʱ�����ǿ���ֱ���� new �ķ�ʽ������Ҳ����ֱ�Ӳ���������������
// ������
var a = [1, 2, 3]// new Object
var a1 = new Array(3)
a1[0] = 1
a1[1] = 2
a1[2] = 3

���Կ�����ͨ��������ֱ�Ӵ��������ַ�ʽ���Ч��Ҫ����һ��
��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise����ǰ����
��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise��һ������ʽ��̷�ʽ��
��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise������JavaScript �첽��̣�
��ѧϰ�ʼǡ�Part1��JavaScript���������-����ʽ����� JS �첽��̡���д Promise��������дPromiseԴ�룩
��Part1��ҵ��https://gitee.com/zgp-qz/part01-task
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż���һ��ECMAScript �����ԣ�
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż�������TypeScript ���ԣ�
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż�������JavaScript �����Ż�1��
��ѧϰ�ʼǡ�Part1��JavaScript���������-ES �������� TypeScript��JS �����Ż����ġ�JavaScript �����Ż�2��
��Part2��ҵ��https://gitee.com/zgp-qz/part02-homework