[论文阅读] End-to-End Multi-View Fusion for 3D Object Detection in Lidar Point Clouds
原文链接:https://arxiv.org/abs/1910.06528v2
基于激光雷达点云的3D目标检测算法 MVF算法
摘要:
最近的三维物体检测工作提倡在鸟瞰图中点云体素化,即物体保持其物理尺寸并自然可分离。然而,在这个视图中,点云是稀疏的,并且具有高度可变的点密度,这可能会导致探测器很难探测到远处或小的物体(行人、交通标志等)。另一方面,透视图提供了密集的观察,这可以为这种情况提供更好的特性编码。
在本文中,我们的目标是协同鸟瞰图和透视图,并提出了一种新的端到端多视图融合(MVF)算法,可以有效地学习利用两者的互补信息。特别地,我们介绍了动态体素化,它与现有的体素化方法相比有四个优点:
- i)不需要预先分配一个固定大小的张量;
- ii)克服随机点/体素缺失带来的信息损失;
- iii)产生确定的体素嵌入和更稳定的检测结果;
- iv)建立点与体素之间的双向关系,为跨视图特征融合奠定了天然的基础。
通过采用动态体素化,提出的特征融合体系结构使每个点都能从不同的视角学习融合上下文信息。MVF在点上工作,可以自然地扩展到使用激光雷达点云的其他方法。我们在最新发布的Waymo开放数据集和KITTI数据集上对MVF模型进行了广泛的评估,并证明它显著地提高了相对于可比的单视图点柱基线的检测精度。
关键词:目标检测,深度学习,传感器融合
1.介绍
从激光雷达传感器了解三维环境是自动驾驶所需的核心能力之一。 大多数技术都采用了某种形式的体素化,或者通过3D点云的自定义离散化(例如, 或者通过学习体素嵌入(例如体素-?Net?[2],?pointcolumn[3])。 后者通常涉及到将来自相同体素的点之间的信息集中起来,然后用关于相邻点的上下文信息丰富每个点。 然后将这些体素化的特征投射到鸟瞰视图(BEV)表示,该表示与标准2D卷积兼容。 在BEV空间中操作的一个好处是它保留了度量空间,即。 ,相对于到传感器的距离,对象大小保持不变。 这允许模型在训练期间利用关于对象大小的预先信息。 另一方面,随着点云变得更稀疏,或者随着测量距离传感器越来越远,每个体素嵌入可用的点的数量变得更加有限。
近年来,利用透视距离图像这一更为原始的激光雷达数据表示方法取得了很大的进展。这个表征已经被证明在点云变得非常稀疏的较长范围内表现良好,特别是在小对象上。 通过对“密集”距离图像进行运算,这种表示也可以非常高效地进行计算。 然而,由于透视的性质,物体的形状不是距离不变的,在一个杂乱的场景中,物体之间可能会大量重叠。
这些方法中有许多利用了激光雷达点云的单一表示,通常是两者之一BEV或深度图像。由于每个视图都有自己的优点,一个自然的问题是如何将多个激光雷达表示合并到同一个模型中。有几种方法考虑合并BEV激光数据与透视RGB图像,无论是在ROI池阶段,或者每个点的层次。从两个不同的传感器中合并数据有不同的idea,我们关注怎么融合相同传感器的不同视图才可以提供一个比单视图更加丰富信息的模型。
在本文中,我们最做出了两个主要的贡献。
1.我们提出了一个利用新的端到端的多视图融合算法,该算法能够利用相同LiDAR的点云数据中的鸟瞰图和透视图之间的互补信息。在学习生成逐点嵌入的模型的强大性能的激励下,我们设计了我们的融合算法在早期阶段进行操作,在早期阶段,网络仍然保持点级表示(例如,在VoxelNet[2]的最终池化层之前)。现在每一个单独的3D点变成了跨视图共享信息的管道,这是形成多视图融合基础的关键思想。此外,可以为每一个视图定制嵌入式的类型。对于BEV编码,我们使用垂直体像素柱,已经被证实在准确性和延迟方面提供一个非常强的基准。对于嵌入透视图,我们在”类似深度图像“特征图上使用一个标准的2D卷积塔,它可以融合很大接受域的信息,有助于缓解点稀疏性的问题。每一个点现在都从鸟瞰图或者透视图中被注入了其周围点的上下文信息。这些点层级的嵌入在最后一次的时候被pooling生成最终的体像素嵌入。由于MVF在点层次上增强了特征学习的能力,我们的方法可以被方便的整合到其他基于LiDAR的检测器。
2.我们的第二个主要贡献是动态体素化(DV)的概念,它提供了四个优于传统硬体素化hard voxelization (HV))的主要优点:
○ 动态体素化消除了对每一个体素采样预定义点数的需要,这意味着每一个点可以被模型使用,从而减少信息损失。
○ 它消除了将体素填充到预定义大小的需要,即使它们的点非常少。这可以极大地减少来自HV的额外空间和计算开销,特别是在点云变得非常稀疏的较长的范围内。例如,以前的模型如VoxelNet和pointcolumn为每个voxel(或每个等效的3D卷)分配100个或更多的点。
○ DV克服了点/体素的随机缺失,产生了确定的体素嵌入,使得检测结果更加稳定。
○ 它是融合来自多视图的点级上下文信息的自然基础。
MVF和动态体素化技术使我们能够显著提高最近发布的Waymo开放数据集和KITTI数据集的检测精度。
2.相关工作
2D检测:
3D点云中的目标检测:处理激光雷达产生的点云的一个流行的范例是将其投射到鸟瞰视图(BEV)中,并将其转换为一个多通道的2D伪图像,然后由2D CNN架构对其进行2D和3D目标检测。转换过程通常是手工制作的,一些代表性的作品包括
Vote3D [17],Vote3Deep [18], 3DFCN [19], AVOD [20], PIXOR [1], Complex YOLO [21]。
? Zhou等人的VoxelNet .[2]将点云划分为一个3D体素网格(即体素),并使用一个类点素网络
学习点在每个体素中的嵌入。
? pointpillar[3]是基于以下思想构建的VoxelNet将点特征编码到柱子上(即垂直列)。
? Shi等人提出了PointRCNN模型使用了一个两阶段的管道,其中第一阶段生成3D边界框建议,第二阶段细化规范的3D框
? 透视是激光雷达的另一种广泛应用的表现形式。在这方面,有代表性的著作有VeloFCN[23]和LaserNet[4]。
多模式融合:除了使用激光雷达外,MV3D[5]还结合了从多个视图(前视图、鸟瞰视图和相机视图)中提取的CNN特征,以提高3D对象检测的准确性。一个单独的工作,如平截头体PointNet[24]和PointFusion[25],首先生成二维对象建议使用标准的图像从RGB图像探测器和将每个2D检测框挤压成一个3D截锥体,,然后由PointNet-like处理网络(22、26)来预测相应的3 d边界框。ContFuse[27]通过基于3D点邻域插值RGB特征,将离散的BEV特征映射与图像信息相结合。HD-NET[28]将BEV特征图和高度地图信息一起编码。MMF[29]融合通过多任务学习,提高了BEV地形图、高程图和RGB图像的检测精度。
我们的工作引入了一种点方向的特征融合方法,该方法在点水平上操作,而不是在体素或ROI水平上操作。这使得它能够更好地保存原始的三维结构,在通过ROI或体素级池对点进行聚合之前,使用激光雷达数据。
3.多视图融合
Multi-View Fusion (MVF):两个创新:动态体素 和 特征融合网络结构
3.1 Voxelization and Feature Encoding 体素和特征编码
体素化将点云分割成均匀间隔的体素网格,然后生成3D点与其各自体素之间的多对一映射。VoxelNet[2]将voxelization定义为两个阶段的过程:分组和采样。
给定点云P = {p1;::;pN},该过程将N个点分配给大小为 KTF 的缓冲区,其中K为体素的最大数量,T为一个体素的最大的点的数量,F为特征维数。在分组阶段:基于空间的坐标将点{Pi}分配到体素{Vj}.由于一个体素可能被分配了比它的固定点容量T所允许的更多的点,采样阶段子样本从每个体素中抽取固定的T个点。相似的,如果点云产生的体素大于固定体素容量K,则对体素进行降采样。另一方面,当点(体素)比固定容量T (V)少时,缓冲区中未使用的条目将被填充为零。我们称这个过程为硬体素化[2]。
hard voxelization:
将FV (pi)定义为将每个点pi赋值给点所在的体素vj的映射,
将FP (vj)定义为在体素vj中集合点的映射
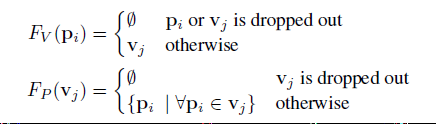
hard voxelization的三个内部局限性:
- (1)当点和体素超出缓冲容量时被丢弃,HV迫使模型丢弃可能对检测有用的信息;
- (2)点和体素的随机缺失也可能导致不确定的体素嵌入,从而导致检测结果的不稳定或抖动
- (3)填充的体素消耗了不必要的计算,阻碍了运行时的性能。
dynamic voxelization (DV):
DV保持了分组阶段的不变,但是,它没有将点采样到固定数量的固定容量体素中,而是保留了点与体素之间的完整映射。因此,体素的数量和每个体素的点的数量都是动态的,这取决于特定的映射函数。这消除了对固定大小缓冲区的需要,并消除了随机点和体素dropout。点体素关系可以形式化为:
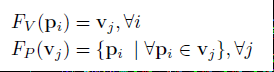
由于保留了所有的原始点和体素信息,动态体素化不会引入任何信息丢失,产生确定的体素嵌入,使得检测结果更加稳定。此外,FV (pi)和FP (vj)在每一对pi和vj之间建立双向关系,这为融合来自不同视图的点级上下文特性奠定了自然基础,稍后将对此进行讨论。
图一说明了hard voxelization and dynamic voxelization之间的差异,

我们设置K = 3和T = 5作为点/体素覆盖率和内存/计算使用量之间的平衡,这仍然会留下近一半的缓冲区为空。此外,由于随机采样,导致了voxel v1中的点缺失和voxel v2的完全缺失。要完全覆盖这四个体素,硬体素化至少需要46F 的缓冲区大小。显然,对于具有高度可变点密度的真实激光雷达扫描,在点/体素覆盖和有效的内存使用之间实现良好的平衡将是硬体素化的一个挑战。
另一方面,动态体素化可以动态有效地分配资源来管理所有的点和体素。在我们的示例中,它以最少13F的内存使用量确保了空间的完全覆盖。完成体素化后,利用文献[22,2,3]中的特征编码技术将激光雷达点转换为高维空间
3.2 特征融合
多视图表示:
我们的目标是在相同的基础上有效地融合来自不同观点的信息激光雷达点云。我们考虑两种观点:鸟瞰视图和透视视图。鸟瞰图是基于笛卡尔坐标系统定义的,在该系统中,物体保持其规范的三维形状信息,并自然可分离。当前的大多数硬体素化的三维物体探测器[2,3]就是在这种情况下工作的。然而,它的缺点是点云在较长的范围内变得高度稀疏。另一方面,透视视图可以表示LiDAR距离图像密集,并能在球面坐标系中对场景进行相应的平铺。透视图的缺点是对象的形状不是距离不变的,而且在一个杂乱的场景中对象之间可能会大量重叠。因此,最好利用两种观点的互补信息
到目前为止,我们认为每个体素在鸟瞰时都是一个长方体的体积。在这里,我们建议将传统的体素扩展为一个更通用的概念,在我们的例子中,在透视图中包含一个3D截锥体。给定点云f(xi;yi;zi) 定义在笛卡尔坐标系中,其球面坐标表示计算为:
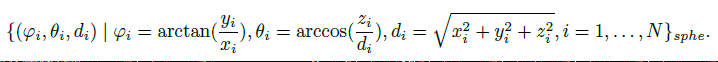
对于激光雷达点云,在鸟瞰图和透视图中应用动态体素化将暴露出不同区域内的每个点,即笛卡儿体素和球面截锥体。因此,允许每个点利用互补的上下文信息。建立的点/体素映射是
对映鸟瞰图的是:
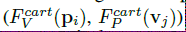
对应透视图的是:
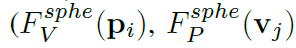
网络体系结构:
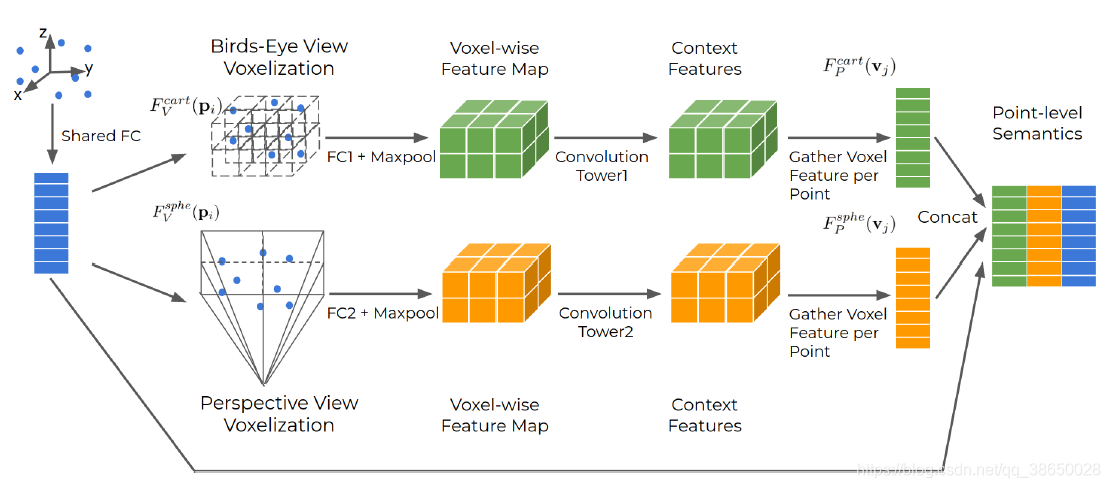
- 1)提出的MVF首先通过一个全连接(FC)层将每个点嵌入到一个高维特征空间中,该层用于不同的视图。
- 2)然后分别在鸟瞰图和透视图中应用动态体素化,建立点与体素之间的双向映射Fv(Pi) 和 Fp(Vj)
- 3)接下来,在每个视图中,它使用一个额外的FC层来学习与视图相关的特性,它通过参考Fv(Pi)来最大池来聚合体素信息
- 4)在体素方向的特征图上,它使用一个卷积塔在扩大的接受域内进一步处理上下文信息,同时仍然保持相同的空间分辨率
- 5)它融合了来自三个不同来源的特征。点,鸟瞰图和透视图的相应体素特征,以及通过共享的FC获得的相应点特征
首先,计算点嵌入。对于每个点,我们计算它的局部它所属体素或截体的三维坐标。将两个视图的局部坐标和点强度连接起来,然后通过一个全连接(FC)层嵌入到一个128D特征空间中。FC层由一个线性层、一个批处理归一化层组成(BN)层和经过整流的线性单元(ReLU)层。在此基础上,将动态体素化方法应用于鸟瞰图和透视图,在点和体素之间建立了动态体素化的双向映射。接下来,在每个视图中,我们使用一个额外的FC层来学习64维视图相关的特性,通过参考Fv(Pi)我们通过最大池化从每个体素中的点聚合体素级别的信息。在这个体素级别的特征映射上,我们使用一个卷积塔来进一步处理上下文信息,其中输入和输出特征维数都是64。它最后融合了来自三个不同来源的特征。点,鸟瞰图和透视图的相应体素特征,以及通过共享的FC获得的相应点特征。
-
1)鸟瞰点对应的笛卡尔体素;
-
2)透视点对应的球面体素;
-
3)共享FC层对应的点向特征。
可以选择将点向特征转换为较低的特征维,以降低计算成本
卷积塔的结构图如图三:

我们使用两个ResNet层[30],每个层有3个2D卷积核,步长为2,将输入体素特征映射逐步降采样为原始特征映射维数为1/2和1/4的张量。然后,我们对这些张量进行采样和连接,构造一个与输入空间分辨率相同的特征图。最后,将这个张量转换成所需的特征维数。注意,输入和输出特征图之间一致的空间分辨率有效地保证了点/体素的对应关系保持不变。
3.3 损失函数
我们定义ground truth 和 anchor box 为:{xg, yg, zg, lg, wg, θg},{xa, ya, za, la, wa, θa},两者之间的回归差值表示如下:
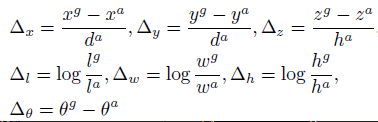
anchor的对角线为da ^2 = la^2 + wa^2, 总的回归损失为
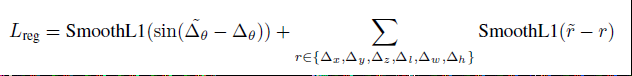
~表示预测的残差值,对于anchor 分类,我们使用focal loss,p表示概率为正锚,推荐α=0.25,γ=2。
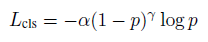
4.实验结果
为了研究提出的MVF算法的有效性,我们复制了最近发布的性能最好的算法pointpillar[3]作为我们的基线。PointPillars是一个基于LiDAR的单视图3D检测器,它使用硬体素化,我们在结果中表示为HV+SV。事实上,PointPillars可以方便地概括为三个功能模块:
鸟瞰视图中的体像素化 、point feature编码和 CNN主干。
为了更直接地检查动态体素化的重要性,我们通过使用动态而不是硬体素化来实现PointPillars的一个变体,我们用DV+SV来表示。最后,我们的MVF方法同时具有动态体素化和多视点特征融合的特点
4.1评估 Waymo Open Dataset
评估度量:
我们评估模型的标准平均精度(AP)指标为7自由度(DOF) 3D box和5自由度BEV box,使用相交超过联合(IoU)阈值,车辆0.7,行人0.5,如数据集官方网站上建议的
实验设置:
我们设置立体像素大小0.32m和检测范围(-74:88)沿着这X轴和Y轴两个类。对车辆和行人设置不同的参数
结果:
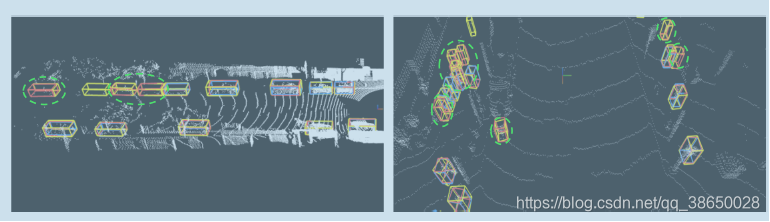
图4显示了车辆和行人检测的两个示例,其中多视图融合生成了更准确的远程遮挡对象检测。实验结果也验证了我们的假设,即与BEV相比,透视图体素化可以捕获互补信息,这在对象距离远、采样稀疏的情况下尤其有用。
5.结论
介绍了一种用于激光雷达点云三维目标检测的新型端到端多视点融合框架MVF。与现存的
三维激光雷达探测器[3,2]使用了硬体素化,我们提出了动态体素化,它保留完整的原始点云,产生确定的体素特征,并作为融合不同视图信息的自然基础。提出了一种多视点融合结构,利用从不同视点提取的不同背景信息对视点特征进行编码。在waymo开放数据集和KITTI数据集上的实验结果表明,我们的动态体素化和多视图融合技术显著提高了检测精度。增加摄像头数据和时间信息是令人兴奋的未来方向,这将进一步完善我们的检测框架。