集成学习:
常见的集成学习思想有:
? Bagging (并联)
代表:随机森林
? Boosting(串联)
代表:Adaboost ―― 根据正确率修改样本权重
GBDT ―― 根据残差(梯度)修改样本标签值
? Stacking
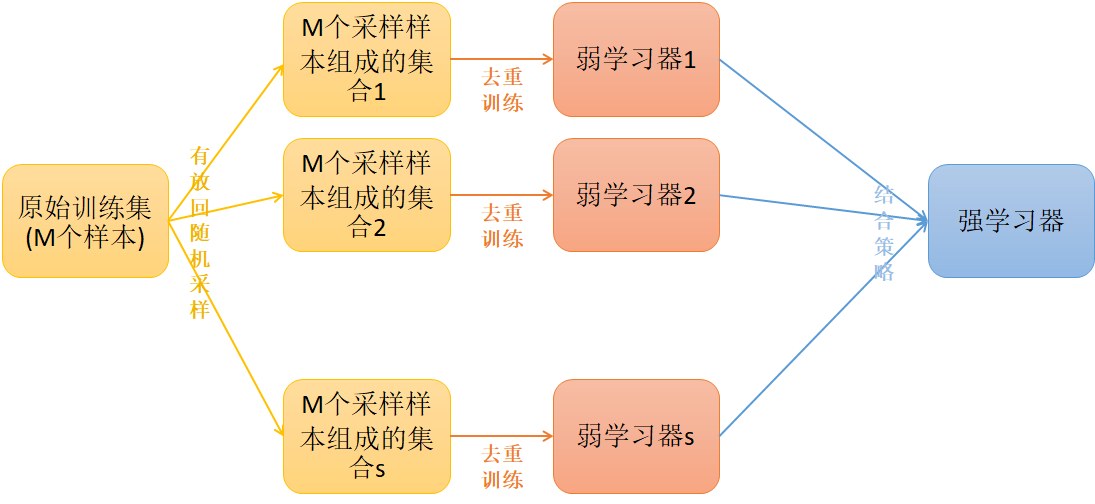
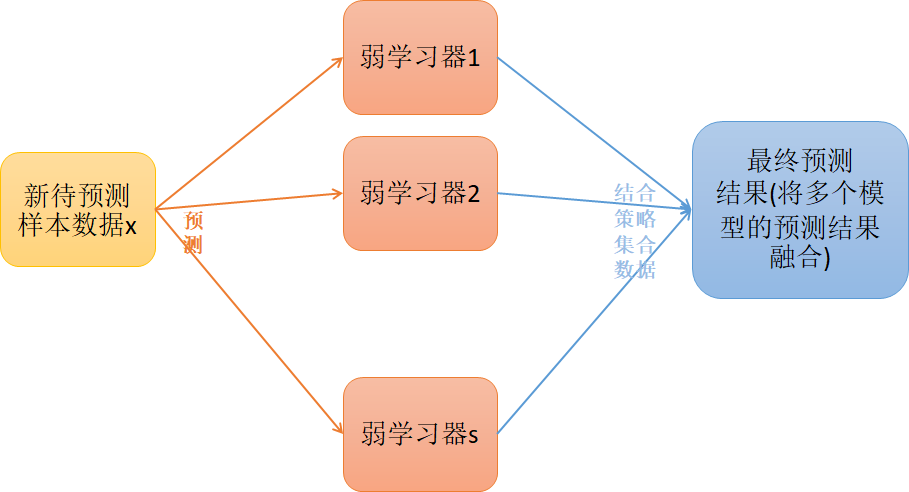
Bagging 并联训练:-------------------------------------------------------------------------------------
预测:
随机森林:
? 在Bagging策略的基础上进行修改后的一种算法
? 1. 从原始样本集(n个样本)中有放回重采样选出n个样本并去重,也就是训练的样本数目实际上应该是小于n。
? 2. 从所有属性中随机选择K个属性,(不放回采样)从K个属性中选择出最佳分割属性作为节点来迭代的创建决策树
? 3. 重复以上两步m次,即建立m棵决策树;
? 4. 这m个决策树形成随机森林,通过投票表决结果决定数据属于哪一类
Extra Tree:
Extra Tree会随机的选择一个特征值来划分决策树。
这样会导致决策树的规模一般大于RF所生成的决策树。也就是说Extra Tree模型的方差相对于RF进一步减少。在某些情况下,Extra Tree的泛化能力比RF的强。
Totally Random Trees Embedding(TRTE)
TRTE算法的转换过程类似RF+KDTree算法的方法,建立T个决策树来拟合数据(是类似KD-Tree一样基于特征属性的方差选择划分特征)
Isolation Forest(IForest)
异常值检测。少量数据,深度和规模较小
样本在各个决策树生的深度 和 在所有决策树上的深度的平均值比较,计算异常值概率,判断异常值。
其实一般数据清洗,先进行聚类。
无论怎么调参或用什么模型,一直过拟合怎么办?
考虑下样本是否有噪音,把错误的样本挑出来,统计一下特征值方差、值得分布等,聚类、随机森林、人工标注,进行清洗。
Boosting(串联训练):--------------------------------------------------------------------------------

效果表示误差等,注意,都是M个样本。涉及到的算法很多,十种以上,这个只是一个框架。
常见的模型有:? Adaboost ? Gradient Boosting(GBT/GBDT/GBRT)
1. Adaboost
Adaboost 算法利用前一轮的弱学习器的误差来更新样本权重值,分类错误的样本的权重会变大,分类正确的样本的权重会变小。这样后面的弱分类器就会更加注重分类错误的样本。将基分类器的线性组合作为强分类器,同时给分类误差率较小的基本分类器以大的权值,给分类误差率较大的基分类器以小的权重值;构建的线性组合为:
 a 为分类器的权重,G分类器的预测值
a 为分类器的权重,G分类器的预测值
最终分类器是在线性组合的基础上进行Sign函数转换:

sign()函数为符号函数,图像如下:

Adaboost 算法的损失函数定义如下(因为左边的不利于计算):

G(xi)为 sign(f(x)) 取值为-1/1,yi为sign(yi) 取值为-1/1,f(x)为分类器预测值,取值R。
f(x)是上面图像上x轴的取值,yi是上面图像上y轴的取值,有点像标签平滑,预测正确,左边是0,右边就是一个很小的数。预测错误,左边是1,右边是一个大于1的数。
缺点:对异常值非常敏感。
总结:通过弱分类器权重来集成。
机器学习算法推导当中,有的时候能看到一个函数 ,这个函数代表什么意思?
代表的是指示函数(indicator function)。
它的含义是:当输入为True的时候,输出为1,输入为False的时候,输出为0。
例如: ,表示当
不等于
的时候输出为1,否则输出为0。
具体训练过程步骤如下:

机器学习算法推导当中,有的时候能看到一个函数 ,这个函数代表什么意思?
代表的是指示函数(indicator function)。
它的含义是:当输入为True的时候,输出为1,输入为False的时候,输出为0。
例如: ,表示当
不等于
的时候输出为1,否则输出为0。
梯度提升迭代决策树GBDT

决策树和Adaboost通过特征找到特征的分割点,不断来决策。
GBDT通过误差找分割点,通过误差进行分割,残差即为误差。上图红色部分:20+6+3+1=30岁
原值拟合模型+该模型的误差拟合模型,主要用于特征值选择。
yi是真实值,y^it是预测值,是误差拟合函数,Ω是正则。i表示第i个样本,t和t-1表示运算次数(每次都用上一次的结果加上误差拟合函数)
即此时最优化目标函数,就相当于求得了
GBDT容易陷入过拟合,一般工作中使用XGBoost
训练过程:(特征值,标签值已知)
GBDT在迭代过程中,特征属性值不变,每次下一个模型决策后根据梯度值(残差)改变样本标签值,将标签值设置成残差值,每用下一个模型迭代一次,就根据残差修改一次标签值,然后进行下一次(下一个决策树)的分类(决策),下一步的残差就是当前平均值和标签(残差)的差值,这里预测的是标签值,即是残差(梯度值)。然后计算预测标签和当前修改的标签值之间的误差作为下一次迭代的残差(下一次迭代改变的标签值),如此类推, 直到修改到最后的标签值为0,即残差为0,这时候就能拟合实际值了。也就是说,每一层的模型不但要确定特征和分割值,还要讲将本层的残差确定下来,一共要确定3个值。这样在预测过程中,直接根据新样本特征,分到每一层,将每一层的训练过程中确定好的残差值,相加求和,即为预测的标签结果。
为什么这里梯度会等于残差,因为GBDT的损失函数使用的是最小二乘损失函数,在梯度下降过程中,损失函数对预测函数求偏导后,就变成了 f(xi) - F(i),预测值 - 实际值。
预测的时候,直接将各个模型的预测值(即各层的残差)相加求和即可得到预测的标签值。
GBDT回归算法和GBDT分类算法的唯一区别就是损失函数不同。
GBDT关键也是求分割特征排序和特征分割值,和决策树一样。
预测过程将每个层的残差相加即可得到。
具体的损失函数解析可以看这篇文章:https://blog.csdn.net/lvsehaiyang1993/article/details/88640935
Adaboost 和 GBDT 的区别:
Adaboost底层的分类器没有要求,默认是决策树;GBDT底层的分类器必须是决策树(回归树)
Adaboost基于权重来更新;GBDT优化方向是让模型的样本误差尽可能的小,这个过程不是通过更改样本权重来实现,是基于梯度值来更新的。
bagging为了解决过拟合
boosting为了提高准确率,即解决欠拟合,但有可能过拟合,xgboost在提高准确率基础上,解决过拟合