Ŀ¼
һ�����ѧϰ��ʵ������(Practical aspects of Deep Learning)
1 ѵ������֤�����Լ���Train / Dev / Test sets��
2 ƫ����Bias /Variance��
3 ����ѧϰ������Basic Recipe for Machine Learning��
4 ����Regularization��
5 Ϊʲô����������Ԥ��������أ���Why regularization reduces overfitting?��
6 dropout ����Dropout Regularization��
7 ���� dropout��Understanding Dropout��
8 ������������Other regularization methods��
8.1 ��������
8.2 early stopping
һ�����ѧϰ��ʵ������(Practical aspects of Deep Learning)
1 ѵ������֤�����Լ���Train / Dev / Test sets��

�ⲿ�����ݽ�����ѧϰ�����Ч���������磬�����漰���������ţ���ι������ݣ��Լ����ȷ���Ż��㷨�������У��Ӷ�ʹѧϰ�㷨�ں���ʱ�����������ѧϰ��
����ѧϰ���������ѧϰ�е����⣬Ȼ������������磬����ѧϰһЩȷ����������ȷ���еļ��ɡ�������ѵ������֤�Ͳ������ݼ��Ĺ�����������ȷ�����ںܴ�̶��ϰ�����Ҵ�����Ч�������硣ѵ��������ʱ��������Ҫ�����ܶ���ߣ����磺
- ������ֶ��ٲ�
- ÿ�㺬�ж��ٸ����ص�Ԫ
- ѧϰ�����Ƕ���
- ��������������

������Ӧ�õĹ����У����Dz����ܴ�һ��ʼ��ȷԤ�����Щ��Ϣ����������������ʵ���ϣ�Ӧ���ͻ���ѧϰ��һ���߶ȵ����Ĺ��̣�ͨ������Ŀ����ʱ�����ǻ�����һ�������뷨�����繹��һ�������ض����������ص�Ԫ���������ݼ������ȵȵ������磬Ȼ����룬������������Щ���룬ͨ�����кͲ��Եõ������������Щ������Ϣ�����н�������ǿ��ܻ�������������������Լ����뷨���ı���ԣ�����Ϊ���ҵ����õ������粻�ϵ��������Լ��ķ�����
��������ѧϰ�Ѿ�����Ȼ���Դ�����������Ӿ�������ʶ���Լ��ṹ������Ӧ�õ��ڶ�����ȡ�þ�ɹ����ṹ�����������������ӹ�浽�����������������������������������������棬������������վ�������и�����������������������վ���ٵ��������ȫ�������������ж�˾��ȥ�Ľ��ͻ�����Χ֮�㣬��ʤö�١�
�ҷ��֣���������Ȼ���Դ���������˲���̤�������Ӿ������߾���ḻ������ʶ��ר����Ͷ�������ҵ���ֻ��ߣ��е�����ӵ���ȫ��������������ҵ�����ҿ�������һ���������Ӧ�����������ֱ�����飬ͨ����ת�Ƶ�����Ӧ��������Ѿ���ȡ��������ӵ�е��������������������������������������GPUѵ������CPU��GPU��CPU�ľ��������Լ�����������ء�

ĿǰΪֹ�����ںܶ�Ӧ��ϵͳ����ʹ�Ǿ���ḻ�����ѧϰ�м�Ҳ��̫����һ��ʼ��Ԥ�����ƥ��ij�������������˵��Ӧ�����ѧϰ��һ�����͵ĵ������̣���Ҫ���ѭ������������ΪӦ�ó����ҵ�һ�����ĵ������磬���ѭ���ù��̵�Ч���Ǿ�����Ŀ��չ�ٶȵ�һ���ؼ����أ���������������ѵ�����ݼ�����֤���Ͳ��Լ�Ҳ���������ѭ��Ч�ʡ�

��������ѵ�����ݣ���һ�������α�ʾ������ͨ���Ὣ��Щ���ݻ��ֳɼ����֣�һ������Ϊѵ������һ������Ϊ������֤������ʱҲ��֮Ϊ��֤��������������Ҿͽ�����֤����dev set������ʵ����ͬһ��������һ��������Ϊ���Լ���
�����������ǿ�ʼ��ѵ��ִ���㷨��ͨ����֤���������֤��ѡ����õ�ģ�ͣ����������֤������ѡ��������ģ�ͣ�Ȼ��Ϳ����ڲ��Լ��Ͻ��������ˣ�Ϊ����ƫ�����㷨������״����
�ڻ���ѧϰ��չ��С������ʱ�������������ǽ������������߷֣��������dz�˵��70%��֤����30%���Լ������û����ȷ������֤����Ҳ������60%ѵ����20%��֤��20%���Լ������֡�����ǰ�������ѧϰ�����ձ��Ͽɵ���õ�ʵ��������
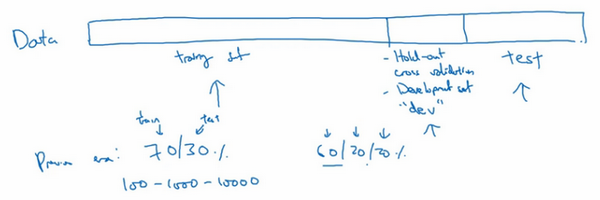
���ֻ��100����1000������1�������ݣ���ô�������������Ƿdz������ġ�
�����ڴ�����ʱ�����������ڵ������������ǰ�����ô��֤���Ͳ��Լ�ռ���������ı����������ڱ�ø�С����Ϊ��֤����Ŀ�ľ�����֤��ͬ���㷨�����������㷨����Ч����ˣ���֤��Ҫ�㹻���������������2������10����ͬ�㷨����Ѹ���жϳ������㷨����Ч�����ǿ��ܲ���Ҫ�ó�20%��������Ϊ��֤����

����������100�������ݣ���ôȡ1�������ݱ����Խ����������ҳ����б�����õ�1-2���㷨��ͬ���أ���������ѡ��ķ����������Լ�����ҪĿ������ȷ���������������ܣ����ԣ����ӵ�а������ݣ�����ֻ��Ҫ1000�����ݣ���������������������������ȷ�����÷����������ܡ�����������100�������ݣ�����1������Ϊ��֤����1������Ϊ���Լ���100����ȡ1������1%������ѵ����ռ98%����֤���Ͳ��Լ���ռ1%�������������������Ӧ�ã�ѵ��������ռ��99.5%����֤�Ͳ��Լ���ռ0.25%��������֤��ռ0.4%�����Լ�ռ0.1%��
�ܽ�һ�£��ڻ���ѧϰ�У�����ͨ���������ֳ�ѵ��������֤���Ͳ��Լ������֣����ݼ���ģ��Խ�С�����ô�ͳ�Ļ��ֱ��������ݼ���ģ�ϴ�ģ���֤���Ͳ��Լ�ҪС������������20%��10%�������һ������λ�����֤���Ͳ��Լ��ľ���ָ����
�ִ����ѧϰ����һ��������Խ��Խ�������ѵ���Ͳ��Լ��ֲ���ƥ�������½���ѵ����������Ҫ����һ���û������ϴ�����ͼƬ��Ӧ�ó���Ŀ�����ҳ�����������è��ͼƬ����������û����ǰ�è��ʿ��ѵ���������Ǵ��������ص�è��ͼƬ������֤���Ͳ��Լ����û������Ӧ�����ϴ���è��ͼƬ������˵��ѵ���������Ǵ�������ץ������ͼƬ������֤���Ͳ��Լ����û��ϴ���ͼƬ�����������ҳ�ϵ�è��ͼƬ�ֱ��ʺܸߣ���רҵ�������������������û��ϴ�����Ƭ���������ֻ���������ģ����صͣ��Ƚ�ģ��������������������ͬ�����������������ݾ��飬������Ҫȷ����֤���Ͳ��Լ�����������ͬһ�ֲ����������������Ҳ��ིһЩ����Ϊ����Ҫ����֤����������ͬ��ģ�ͣ������ܵ��Ż����ܡ������֤���Ͳ��Լ�����ͬһ���ֲ��ͻ�ܺá�

���������ѧϰ�㷨��Ҫ������ѵ�����ݣ�Ϊ�˻�ȡ�����ģ��ѵ�����ݼ������ǿ��Բ��õ�ǰ���еĸ��ִ�����ԣ����磬��ҳץȡ�����۾���ѵ������������֤���Ͳ��Լ������п��ܲ�������ͬһ�ֲ�����ֻҪ��ѭ������鷨����ͻᷢ�ֻ���ѧϰ�㷨���ø��졣
���һ�㣬����û�в��Լ�Ҳ��Ҫ�������Լ���Ŀ���Ƕ�������ѡ����������ϵͳ������ƫ���ƣ��������Ҫ��ƫ���ƣ�Ҳ���Բ����ò��Լ����������ֻ����֤����û�в��Լ�������Ҫ���ľ��ǣ���ѵ������ѵ�������Բ�ͬ��ģ�Ϳ�ܣ�����֤����������Щģ�ͣ�Ȼ�������ѡ�����õ�ģ�͡���Ϊ��֤�����Ѿ����Dz��Լ����ݣ��䲻���ṩ��ƫ������������Ȼ������㲻��Ҫ��ƫ���ƣ��Ǿ��ٺò����ˡ�
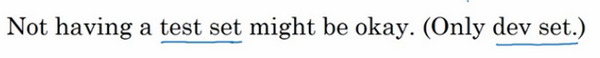
�ڻ���ѧϰ�У����ֻ��һ��ѵ������һ����֤������û�ж����IJ��Լ����������������ѵ�����������dz�Ϊѵ����������֤����Ϊ���Լ���������ʵ��Ӧ���У�����ֻ�ǰѲ��Լ����ɼ�����֤��ʹ�ã���û����ȫʵ�ָ�����Ĺ��ܣ���Ϊ���ǰ���֤�����ݹ�����ϵ��˲��Լ��С�

����˵���ѵ����֤���Ͳ��Լ��ܹ�����������ļ��ɣ�Ҳ���Ը���Ч�غ����㷨��ƫ��ͷ���Ӷ��������Ǹ���Ч��ѡ����ʷ������Ż��㷨��
2 ƫ����Bias /Variance��
�������л���ѧϰ��ҵ��Ա�������������ƫ��ͷ��������������ѧ�Ѿ�����ʹ�����Լ���Ϊ�Ѿ�������ƫ��ͷ���Ļ������ȴ����һЩ���벻�����¶������֡��������ѧϰ��������⣬��һ�������Ƕ�ƫ��ͷ����Ȩ���о���dz�����ǿ�����˵����������������ѧϰ��������Ȩ����ߣ��������Ƿֱ���ƫ��ͷ��ȴ����̸��ƫ��ͷ����Ȩ�����⡣

������������ݼ��������������ݼ����һ��ֱ�ߣ����ܵõ�һ�����ع���ϣ����������ܺܺõ���ϸ����ݣ����Ǹ�ƫ�high bias������������dz�Ϊ��Ƿ��ϡ���underfitting����
�෴������������һ���dz����ӵķ��������������������������ص�Ԫ�������磬���ܾͷdz�������������ݼ��������⿴����Ҳ����һ�ֺܺõ���Ϸ�ʽ����������ϸߣ�high variance�������ݹ�����ϣ�overfitting����
������֮�䣬���ܻ���һЩ��ͼ�������ģ����ӳ̶����У���������ʶȵķ����������������Ͽ��������Ӻ��������dz�֮Ϊ���ʶ���ϡ���just right���ǽ��ڹ�����Ϻ�Ƿ����м��һ�ࡣ

������һ��ֻ�к����������Ķ�ά���ݼ��У����ǿ��Ի������ݣ���ƫ��ͷ�����ӻ����ڶ�ά�ռ������У��������ݺͿ��ӻ��ָ�߽���ʵ�֣������ǿ���ͨ������ָ�꣬���о�ƫ��ͷ��

��������è��ͼƬ����������ӣ����һ����è��ͼƬ���ұ�һ�Ų��ǡ�����ƫ��ͷ���������ؼ�������ѵ������Train set error������֤����Dev set error����Ϊ�˷�����֤���������ǿ��Ա��ͼƬ�е�Сè������������ʶ���Dz�������ġ�
�ٶ�ѵ���������1%��Ϊ�˷�����֤���ٶ���֤�������11%�����Կ���ѵ�������õ÷dz��ã�����֤��������Խϲ���ǿ��ܹ��������ѵ��������ij�̶ֳ��ϣ���֤����û�г�����ý�����֤�������ã���������������dz�֮Ϊ���߷����
ͨ���鿴ѵ����������֤�������DZ��������㷨�Ƿ���и߷��Ҳ����˵����ѵ��������֤�����Ϳ��Եó���ͬ���ۡ�
����ѵ���������15%�����ǰ�ѵ�������д�����У���֤�������16%������ð������˵Ĵ����ʼ���Ϊ0%�����������ЩͼƬ���ֱ���Dz���è���㷨��û����ѵ�����еõ��ܺ�ѵ�������ѵ�����ݵ���϶Ȳ��ߣ���������Ƿ��ϣ��Ϳ���˵�����㷨ƫ��Ƚϸߡ��෴����������֤�������Ľ��ȴ�Ǻ����ģ���֤���еĴ�����ֻ��ѵ�����Ķ���1%�����������㷨ƫ��ߣ���Ϊ�������������ѵ������������һ�Żõ�Ƭ����ߵ�ͼƬ���ơ�
�پ�һ�����ӣ�ѵ���������15%��ƫ���൱�ߣ����ǣ���֤���������������⣬�����ʴﵽ30%������������£��һ���Ϊ�����㷨ƫ��ߣ���Ϊ����ѵ�����Ͻ�������룬���ҷ���Ҳ�ܸߣ����Ƿ���ƫ������������
�ٿ����һ�����ӣ�ѵ���������0.5%����֤�������1%���û����������Ľ����ܿ��ģ�è�������ֻ��1%�Ĵ����ʣ�ƫ��ͷ���ܵ͡�
��һ���������������һ�£���������ں��������イ����Щ�������ǻ��ڼ���Ԥ��ģ��������۱��Ĵ����ʽӽ�0%��һ����˵���������Ҳ����Ϊ��Ҷ˹�����ԣ��������ӽ�0%���ҾͲ�������ϸ���ˣ������������Ҷ˹���dz��ߣ�����15%�������ٿ��������������ѵ�����15%����֤���16%����15%�Ĵ����ʶ�ѵ������˵Ҳ�Ƿdz������ģ�ƫ��ߣ�����Ҳ�dz��͡�

�����з�������������ʱ����η���ƫ��ͷ����أ����磬ͼƬ��ģ������ʹ�����ۣ�����û��ϵͳ����ȷ�����ʶ��ͼƬ������������£�����������ߣ���ô�������̾�Ҫ��Щ�ı��ˣ�������ʱ�Ȳ�������Щϸ����ص���ͨ���鿴ѵ���������ǿ����ж����������������ٶ���ѵ�������������������ж��Ƿ���ƫ�����⣬Ȼ��鿴�������ж�ߡ������ѵ����ѵ������ʼʹ����֤����֤ʱ�����ǿ����жϷ����Ƿ���ߣ���ѵ��������֤������������У����ǿ����жϷ����Ƿ���ߡ�

���Ϸ�����ǰ�ᶼ�Ǽ����������С��ѵ��������֤������������ͬ�ֲ������û����Щ������Ϊǰ�ᣬ�������̸��Ӹ��ӣ����ǽ������Ժ����������ۡ�
����ѧϰ�˸�ƫ��߷���������Ӧ�ö����ʷ���������һ������ʶ��ƫ��ͷ������ʲô�����أ������������������������˵���Ƿdz����ġ�

����֮ǰѧϰ���������ķ��������������ƫ���Ϊ����������϶ȵͣ������ֽӽ����Եķ�������������϶ȵ͡�
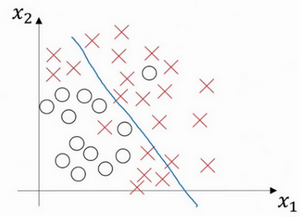
��������������ı�һ�·�������������ɫ�ʻ��������������ϲ������ݣ�����ɫ�����ķ��������и�ƫ��߷��ƫ�������Ϊ��������һ�����Է���������δ������ݡ�
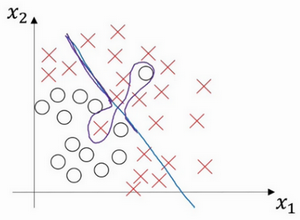
���ֶ��������ܹ��ܺõ�������ݡ�

���������м䲿������Էdz��ߣ�ȴ������������������������������ƫ��ܸߣ���Ϊ�����������Եġ�

���������ߺ��������Ԫ����������߷����Ϊ�����������̫����������������������������м���Щ��Ծ���ݡ�
�⿴������Щ����Ȼ��������ά���Ͽ�����̫��Ȼ�������ڸ�ά���ݣ���Щ��������ƫ��ߣ���Щ��������ߣ������ڸ�ά�����в������ַ������������Ͳ�����ôǣǿ�ˡ�
�ܽ�һ�£����ǽ������ͨ��������ѵ������ѵ���㷨������������֤������֤�㷨���������������㷨�Ƿ���ڸ�ƫ��߷���Ƿ�����ֵ���ߣ���������ֵ�����ߣ������㷨ƫ��ͷ���ľ��������������������Ҫ���Ĺ������²������ݣ����ǻ�����㷨ƫ��ͷ���ĸߵ����ѧϰһЩ����ѧϰ�Ļ������������Ը�ϵͳ���Ż��㷨��
3 ����ѧϰ������Basic Recipe for Machine Learning��
�ϲ�������ѧϰ�������ͨ��ѵ��������֤������ж��㷨ƫ����Ƿ�ƫ�ߣ��������Ǹ���ϵͳ���ڻ���ѧϰ��������Щ�������Ż��㷨���ܡ�
��ͼ������ѵ���������õ��Ļ�����������������Щ�������������ã�����û�ã�

������ѵ��������ʱ�õ��ػ�������.��ʼģ��ѵ����ɺ�����Ҫ֪���㷨��ƫ��߲��ߣ����ƫ��ϸߣ���������ѵ������ѵ�����ݵ����ܡ����ƫ���ȷ�ܸߣ����������ѵ��������ô��Ҫ���ľ���ѡ��һ���µ����磬���纬�и������ز�������ص�Ԫ�����磬�����Ѹ���ʱ����ѵ�����磬���߳��Ը��Ƚ����Ż��㷨.
һ������ǻῴ�����ͬ��������ܹ����������ҵ�һ�������ʽ����������µ�����ܹ����������ţ���Ϊ����һ���������DZ���ȥ���ԣ��������ã�Ҳ����û�ã��������ù�ģ���������ͨ�����������������ӳ�ѵ��ʱ�䲻һ�����ã���Ҳûʲô������ѵ��ѧϰ�㷨ʱ���һ�ϳ�����Щ������ֱ�������ƫ�����⣬������ͱ����������ԣ�ֱ�������������Ϊֹ�������ܹ����ѵ������
��������㹻��ͨ�����Ժܺõ����ѵ������ֻҪ���������������ģ�����ͼƬ��ģ�����㷨��������ϸ�ͼƬ����������˿��Էֱ��ͼƬ��������Ǿ��û������Ǻܸߣ���ôѵ��һ����������磬���Ǿ�Ӧ�ÿ��ԡ������ٿ��Ժܺõ����ѵ���������ٿ�����ϻ��߹����ѵ������һ��ƫ��͵����Խ��ܵ���ֵ�����һ�·�����û�����⣬Ϊ�������������Ҫ�鿴��֤�����ܣ������ܴ�һ�����������ѵ�����ƶϳ���֤���������Ƿ�Ҳ���룬�������ߣ���õĽ���취���Dz��ø������ݣ��������������������һ���İ���������ʱ����������ø������ݣ�����Ҳ���Գ���ͨ�����������ٹ���ϣ���������½ڿλὲ����ʱ�����Dz��ò��������ԣ����ǣ�������ҵ������ʵ��������ܣ���ʱ�����ܻ�һ��˫��ͬʱ���ٷ����ƫ����ʵ���أ���ϵͳ��˵���������ѣ���֮���Dz����ظ����ԣ�ֱ���ҵ�һ����ƫ��ͷ���Ŀ�ܣ���ʱ���Ǿͳɹ��ˡ�
��������Ҫ����ע�⣺
��һ�㣬��ƫ��߷��������ֲ�ͬ����������Ǻ���Ҫ���Եķ���Ҳ������ȫ��ͬ��ͨ������ѵ����֤��������㷨�Ƿ����ƫ������⣬Ȼ����ݽ��ѡ���Բ��ַ������ٸ����ӣ�����㷨���ڸ�ƫ�����⣬������ѵ��������ʵҲûʲô�ô��������ⲻ�Ǹ���Ч�ķ��������Դ��Ҫ������ڵ�������ƫ��Ƿ���������߶������⣬��ȷ��һ������������ѡ�������Ч�ķ�����
�ڶ��㣬�ڻ���ѧϰ�ij��ڽΣ�������ν��ƫ���Ȩ��������ż����ʣ�ԭ���������ܳ��Եķ����кܶࡣ��������ƫ����ٷ��Ҳ���Լ���ƫ����ӷ�����������ѧϰ�����ڽΣ�����û��̫��߿�������ֻ����ƫ���ȴ��Ӱ�쵽��һ�������ڵ�ǰ�����ѧϰ�ʹ�����ʱ����ֻҪ����ѵ��һ����������磬ֻҪ���˸������ݣ���ôҲ����ֻ����������������Ǽٶ�����������ô��ֻҪ�����ʶȣ�ͨ������һ��������������ԣ��ڲ�Ӱ�췽���ͬʱ����ƫ������ø�������ͨ�������ڲ�����Ӱ��ƫ���ͬʱ���ٷ��������ʵ��Ҫ���Ĺ����ǣ�ѵ�����磬ѡ������������������ݣ����������й��߿��������ڼ���ƫ����ͬʱ��������һ�����������Ӱ�졣�Ҿ�����������ѧϰ�Լලʽѧϰ���������һ����Ҫԭ��Ҳ�����Dz���̫����ע���ƽ��ƫ��ͷ����һ����Ҫԭ����ʱ�����кܶ�ѡ����ƫ������������һ�������գ����ǻ�õ�һ���dz��淶�������硣���½ڿο�ʼ�����ǽ���������ѵ��һ����������缸��û���κθ���Ӱ�죬��ѵ��һ���������������Ҫ����Ҳֻ�Ǽ���ʱ�䣬ǰ���������DZȽϹ淶���ġ�
������һ�ַdz�ʵ�õļ��ٷ���ķ���������ʱ�����ƫ���Ȩ�����⣬ƫ������������ӣ���������㹻������ͨ������̫�ߡ�
4 ����Regularization��
���ѧϰ���ܴ��ڹ�������⡪���߷�����������������һ����������һ��������������ݣ����Ƿdz��ɿ��ķ��������������ʱʱ�̿����㹻���ѵ�����ݻ���ȡ�������ݵijɱ��ܸߣ�������ͨ�������ڱ������ϻ�������������
������ǻ��������������������ݣ������ڸ߷������⣬��ô�����뵽�ķ���������������һ������߷���ķ����������������ݣ���Ҳ�Ƿdz��ɿ��İ취�������� ������ʱʱ���㹻���ѵ�����ݣ����ߣ���ȡ�������ݵijɱ��ܸߣ������������ڱ��������ϣ�������������
���������ع���ʵ����Щ���룬��ɱ����� ����Сֵ���������Ƕ���ijɱ���������������һЩѵ�����ݺͲ�ͬ�����и���Ԥ�����ʧ��
��
�����ع������������
��һ����ά�Ȳ���ʸ����
��һ��ʵ���������ع麯���м�������ֻ�����Ӳ����ˣ�Ҳ������������
����
������ƽ����
ŷ����·�����ƽ������
��
ֵ��1��
��ƽ���ĺ�,Ҳ�ɱ�ʾΪ
��Ҳ������������
��ŷ����·�����2��������ƽ�����˷�����Ϊ
������Ϊ��������ŷ����·��ߣ�����Ϊ��������
��
������

Ϊʲôֻ��������Ϊʲô���ټ��ϲ���
�أ��������ô����ֻ����ϰ��ʡ�Բ�д����Ϊ
ͨ����һ����ά����ʸ�����Ѿ����Ա����ƫ�����⣬
���ܰ����кܶ���������Dz�����������в�������
ֻ�ǵ������֣�����
���������������������
��������˲���
����ʵҲû̫��Ӱ�죬��Ϊ
ֻ���ڶ�����е�һ����������ͨ��ʡ�Բ��ƣ����������������������ȫû���⡣

������������������ͣ����ǿ�����˵��
�����ӵIJ���
����������������
����
![]() Ҳ����Ϊ����
Ҳ����Ϊ���� ������
���������۷�ĸ��
����
��������һ������������

����õ�������
���ջ���ϡ��ģ�Ҳ����˵
�������кܶ�0������˵����������ѹ��ģ�ͣ���Ϊ�����в�����Ϊ0���洢ģ����ռ�õ��ڴ���١�ʵ���ϣ���Ȼ
����ʹģ�ͱ��ϡ�裬ȴû�н���̫��洢�ڴ棬��������Ϊ�Ⲣ����
����Ŀ�ģ����ٲ���Ϊ��ѹ��ģ�ͣ�������ѵ������ʱ��Խ��Խ������ʹ��
����
�����������һ��ϸ�ڣ� ��������������ͨ��ʹ����֤������֤��������������������Ը��ָ��������ݣ�Ѱ����õIJ���������Ҫ����ѵ����֮���Ȩ�⣬�Ѳ�������Ϊ��Сֵ���������Ա������ϣ����Ԧ�������һ����Ҫ�����ij���������˳��˵һ�£�Ϊ�˷���д���룬��Python��������У�
��һ�������ֶΣ���д����ʱ������ɾ��
���
��������Python�еı����ֶγ�ͻ������������ع麯����ʵ��
���Ĺ��̣��������������ʵ��
�����أ�

�����纬��һ���ɱ��������ú������� ��
��
�����в�������ĸ
�������������IJ�������˳ɱ���������
��ѵ��������ʧ�������ܺͳ���
��������Ϊ
![]() �����dz�
�����dz� ![]() Ϊ����ƽ�����������������ƽ����������������Ϊ����������Ԫ�ص�ƽ����ͣ�
Ϊ����ƽ�����������������ƽ����������������Ϊ����������Ԫ�ص�ƽ����ͣ�
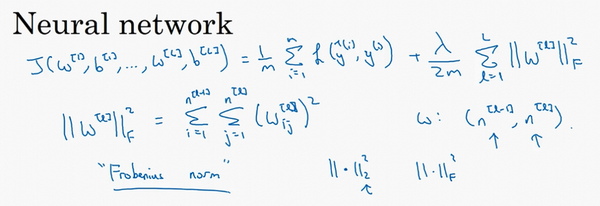
���ǿ������ʽ�ľ����������һ����ͷ�����ֵ ��1��
���ڶ�����
ֵ��1��
����Ϊ
��һ��
�Ķ�ά����
��ʾ
�㵥Ԫ��������
��ʾ��
�����ص�Ԫ��������

�þ����������������ޱ�����˹�����������±� ��ע�����������Դ�����һЩ���ػ�ɬ��ԭ�����Dz���֮Ϊ������
��������������Ϊ�����ޱ�����˹������������
��������������Ȼ��������һЩ�������֪��������ԭ���չ��������dz�֮Ϊ�����ޱ�����˹������������ʾһ������������Ԫ�ص�ƽ���͡�

�����ʹ�ø÷���ʵ���ݶ��½��أ�
��backprop����� ��ֵ��backprop�����
��
?��ƫ������ʵ������?
�滻Ϊ?
��ȥѧϰ�ʳ��� ?
��

�����֮ǰ���Ƕ������ӵ��������Ȼ�Ѿ�����������������������Ҫ���ľ��Ǹ�������һ��
��Ȼ�������������ʹ���¶����
�����Ķ��庬����ز������ۺ��������ͣ��Լ�������ӵĶ����������Ҳ��
������ʱ����Ϊ��Ȩ��˥������ԭ��

�������Ķ����滻�˴���
�����Կ�����
�Ķ��屻����Ϊ
��ȥѧϰ��
����backprop �ټ���
��

��������˵����������ʲô�����Ƕ���ͼ������ø�С��ʵ���ϣ��൱�����Ǹ�����W����
����Ȩ�أ�����
��ȥ
��������Ҳ���������ϵ��
���Ծ���
����ϵ��С��1�����
��������Ҳ����Ϊ��Ȩ��˥��������Ϊ������һ����ݶ��½���
����������
����backprop���������ݶ�ֵ��ͬʱ
Ҳ���������ϵ�������ϵ��С��1�����
����Ҳ����Ϊ��Ȩ��˥������

֮���Խ�����Ȩ��˥��������Ϊ��������ȣ�Ȩ��ָ�������һ��С��1��ϵ�������Ͼ�������������Ӧ�����Ĺ��̡�
5 Ϊʲô����������Ԥ��������أ���Why regularization reduces overfitting?��
Ϊʲô����������Ԥ��������أ�Ϊʲô�����Լ��ٷ������⣿����ͨ������������ֱ�����һ�¡�
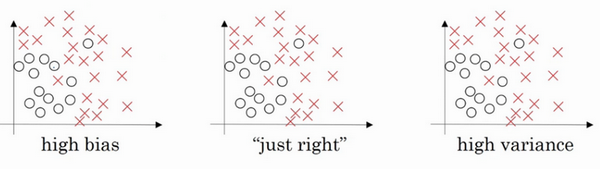

��ͼ�Ǹ�ƫ���ͼ�Ǹ߷���м���Just Right���⼸��ͼ������ǰ��γ��п�������

������������������Ӵ�������������硣��֪������ͼ���������Ҳ���������������������һ������ϵ������硣�������ǵĴ��ۺ��� �����в���
��������������������Ա�������Ȩֵ�����������Ǹ��ޱ�����˹������Ϊʲô
ѹ�����������߸��ޱ�����˹�������߲������Լ��ٹ���ϣ�
ֱ������������������ ���õ��㹻��Ȩ�ؾ���
������Ϊ�ӽ���0��ֵ��ֱ��������ǰѶ����ص�Ԫ��Ȩ����Ϊ0�����ǻ�������������Щ���ص�Ԫ������Ӱ�졣������������������������˵����������һ����С�����磬С����ͬһ�����ع鵥Ԫ���������ȴ�ܴ�����ʹ�������ӹ�����ϵ�״̬���ӽ���ͼ�ĸ�ƫ��״̬��
���������һ���м�ֵ�����ǻ���һ���ӽ���Just Right�����м�״̬��
ֱ������������ӵ��㹻��
��ӽ���0��ʵ�����Dz��ᷢ����������ģ����dz������������ټ����������ص�Ԫ��Ӱ�죬�������������ø������������Խ��Խ�ӽ����ع飬����ֱ������Ϊ�������ص�Ԫ����ȫ�����ˣ���ʵ��Ȼ��ʵ�����Ǹ���������������ص�Ԫ��Ȼ���ڣ��������ǵ�Ӱ���ø�С�ˡ��������ø����ˣ�ò��������������������ϣ�����Ҳ�ȷ�����ֱ�������Ƿ����ã������ڱ����ִ������ʱ����ʵ�ʿ���һЩ������ٵĽ����

��������ֱ�۸���һ�£�����Ϊʲô����Ԥ������ϣ����������õ���������˫���������

�� ��ʾ
,��ô���Ƿ��֣�ֻҪ
�dz������
ֻ�漰������������������������˫�����к���������״̬��ֻҪ
������չΪ�����ĸ���ֵ���߸�Сֵ���������ʼ��÷����ԡ�

������Ӧ���������ֱ��������������˺ܴ�����IJ�������Խ�С����Ϊ���ۺ����еIJ�������ˣ���� ��С��

��� ��С�������˵��
Ҳ���С��

�ر��ǣ���� ��ֵ�����������Χ�ڣ�������Խ�С��ֵ��
���³����ԣ�ÿ�㼸���������Եģ������Իع麯��һ����

��һ�ڿ����ǽ��������ÿ�㶼�����Եģ���ô�����������һ���������磬��ʹ��һ���dz����������磬��������Լ��������������������ֻ�ܼ������Ժ�������ˣ����������ڷdz����ӵľ��ߣ��Լ�����������ݼ��ķ����Ծ��߽߱磬��ͬ�����ڻõ�Ƭ�п����Ĺ�����ϸ߷���������

�ܽ�һ�£������������úܴ��� ��С��
Ҳ����Ա�С����ʱ����
��Ӱ�죬
����Ա�С��ʵ���ϣ�
��ȡֵ��Χ��С������������Ҳ�������ߺ���
����Գ����ԣ��������������������Ժ�������ֵ��������Ժ����dz���������һ�������ӵĸ߶ȷ����Ժ��������ᷢ������ϡ�
����ڱ����ҵ��ʵ������ʱ�����ۿ�����Щ������ܽ�����֮ǰ���Ҹ����һ��ִ�з����С���飬������������ʱ��Ӧ��֮ǰ����Ĵ��ۺ��� �����������ģ�������һ�Ŀ����Ԥ��Ȩ�ع���

�����ʹ�õ����ݶ��½��������ڵ����ݶ��½�ʱ������һ�����ǰѴ��ۺ��� ��Ƴ�����һ���������ڵ����ݶ��½�ʱ���������ݶ��½��ĵ������������Կ��������ۺ��������ݶ��½���ÿ�������������ݼ��������ʵʩ���������������μǣ�
�Ѿ���һ��ȫ�µĶ��塣������õ���ԭ����
��Ҳ�������һ�������������ܿ����������ݼ�����Ϊ�˵����ݶ��½��������ʹ���¶����
�������������ڶ��������������
���ܲ��������е�����Χ�ڶ������ݼ���
����� ������������ѵ�����ѧϰģ��ʱ��õ�һ�ַ����������ѧϰ�У�����һ�ַ���Ҳ�õ�����������dropout����
6 dropout ����Dropout Regularization��
���� ��������һ���dz�ʵ�õ�������������Dropout�����ʧ������������������Ĺ���ԭ����

��������ѵ����ͼ�����������磬�����ڹ���ϣ������dropout��Ҫ�����ģ����Ǹ�����������磬dropout����������ÿһ�㣬�����������������нڵ�ĸ��ʡ����������е�ÿһ�㣬ÿ���ڵ㶼����Ӳ�ҵķ�ʽ���ø��ʣ�ÿ���ڵ���Ա����������ĸ��ʶ���0.5��������ڵ���ʣ����ǻ�����һЩ�ڵ㣬Ȼ��ɾ�����Ӹýڵ���������ߣ����õ�һ���ڵ���٣���ģ��С�����磬Ȼ����backprop��������ѵ����
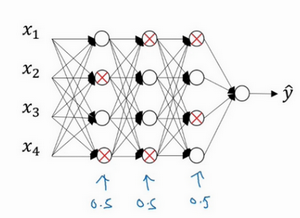

��������ڵ㾫����һ���������������������������վ�����Ӳ�ҵķ�ʽ���ø��ʣ�����һ��ڵ㼯�ϣ�ɾ���������͵Ľڵ㼯�ϡ�����ÿ��ѵ�����������Ƕ�������һ���������������ѵ���������ַ����ƺ��е�֣����������ڵ㣬����Ҳ������ģ����������Ч�����������֪���������ÿ��ѵ������ѵ����ģ��С�����磬�������ܻ���ʶ��ΪʲôҪ�������磬��Ϊ������ѵ����С�����硣

���ʵʩdropout�أ������м��֣���������Ҫ��������õķ�������inverted dropout���������ʧ������������Կ��ǣ�������һ�����㣨������������˵���������л��кܶ��漰��3�ĵط�����ֻ����˵�������ijһ����ʵʩdropout��
������Ҫ�������� ,
��ʾһ�������dropout������
d3 = np.random.rand(a3.shape[0],a3.shape[1])Ȼ�����Ƿ�С��ij�������dz�֮Ϊkeep-prob��keep-prob��һ���������֣��ϸ�ʾ��������0.5��������������0.8������ʾ����ij�����ص�Ԫ�ĸ��ʣ��˴�keep-prob����0.8������ζ����������һ�����ص�Ԫ�ĸ�����0.2���������þ������������������� �������ӷֽ⣬Ч��Ҳ��һ���ġ�
��һ������ÿ��������ÿ�����ص�Ԫ������
�еĶ�ӦֵΪ1�ĸ��ʶ���0.8����ӦΪ0�ĸ�����0.2���������С��0.8��������1�ĸ�����0.8������0�ĸ�����0.2��
������Ҫ���ľ��Ǵӵ������л�ȡ��������������ǽ�����
����Ҫ����ļ������
��������
�ij���
��
a3 =np.multiply(a3,d3)��������Ԫ����ˣ�Ҳ��дΪ���������þ�����
�����е���0��Ԫ�أ��������������Ԫ�ص���0�ĸ���ֻ��20%���˷��������հ�
����ӦԪ�����������
��0Ԫ����
�����Ԫ�ع��㡣

�����pythonʵ�ָ��㷨�Ļ��� ����һ�����������飬ֵΪtrue��false��������1��0���˷�������Ȼ��Ч��python���true��false����Ϊ1��0����ҿ�����python����һ�¡�
�������������չ����������0.8�����߳���keep-prob������

���Ǽ���������ز�����50����Ԫ��50����Ԫ����һά����50������ͨ�����ӷֽ⽫����ֳ�
ά�ģ�������ɾ�����ǵĸ��ʷֱ�Ϊ80%��20%������ζ�����ɾ�������ĵ�Ԫƽ����10��50��20%=10�������������ǿ���
��
![]() �����ǵ�Ԥ���ǣ�
�����ǵ�Ԥ���ǣ� ����20%��Ҳ����˵
����20%��Ԫ�ر����㣬Ϊ�˲�Ӱ��
������ֵ��������Ҫ��
���������������ֲ������������20%��
������ֵ����䣬���߲��־�����ν��dropout������

���Ĺ����ǣ�����keep-prop��ֵ�Ƕ���0.8��0.9������1�����keep-prop����Ϊ1����ô�Ͳ�����dropout����Ϊ���ᱣ�����нڵ㡣�������ʧ�inverted dropout������ͨ������keep-prob��ȷ��������ֵ���䡣
��ʵ֤�����ڲ��ԽΣ�����������һ��������ʱ��Ҳ���������߿��ע�ķ������ʧ�����ʹ���Խα�ø����ף���Ϊ����������չ������١�
Ŀǰʵʩdropout��õķ�������Inverted dropout�������Ҷ���ʵ��һ�¡�Dropout���ڵĵ����汾��û�г���keep-prob�������ڲ��ԽΣ�ƽ��ֵ����Խ��Խ���ӣ�������Щ�汾�Ѿ�����ʹ���ˡ�
������ʹ�õ��� ��������ᷢ�֣���ͬ��ѵ�������������ͬ�����ص�ԪҲ��ͬ��ʵ���ϣ������ͨ����ͬѵ������δ������ݣ�ÿ��ѵ�����ݵ��ݶȲ�ͬ��������Բ�ͬ���ص�Ԫ���㣬��ʱȴ������ˡ����磬��Ҫ����ͬ���ص�Ԫ���㣬��һ�ε����ݶ��½�ʱ����һЩ���ص�Ԫ���㣬�ڶ��ε����ݶ��½�ʱ��Ҳ���ǵڶ��α���ѵ����ʱ���Բ�ͬ���͵����ز㵥Ԫ���㡣����
����
����������������Щ��Ԫ���㣬������foreprop����backprop����������ֻѧϰ��foreprob��
����ڲ��Խ�ѵ���㷨���ڲ��ԽΣ������Ѿ���������������Ԥ��ı������õ��DZ�������������
����0��ļ������עΪ��������
�������ڲ��Խβ�ʹ��dropout�����������������������

�Դ�����ֱ�����һ�㣬Ԥ��ֵΪ��
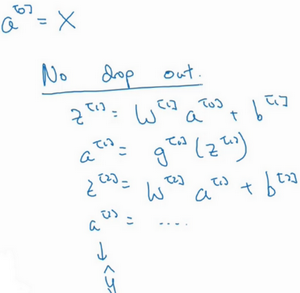
��Ȼ�ڲ��ԽΣ����Dz�δʹ��dropout����ȻҲ�Ͳ�����Ӳ��������ʧ����ʣ��Լ�Ҫ������Щ���ص�Ԫ�ˣ���Ϊ�ڲ��Խν���Ԥ��ʱ�����Dz�����������������ģ�������Խ�Ӧ��dropout������Ԥ����ܵ����š������ϣ���ֻ��Ҫ�������Ԥ������̣�ÿһ�Σ���ͬ�����ص�Ԫ�ᱻ������㣬Ԥ����������ǣ�������Ч�ʵͣ��ó��Ľ��Ҳ������ͬ���������ͬ��������Ľ����Ϊ���ơ�
Inverted dropout�����ڳ���keep-probʱ���Լ�ס��һ���IJ�����Ŀ����ȷ����ʹ�ڲ��Խβ�ִ��dropout��������ֵ��Χ���������Ԥ�ڽ��Ҳ���ᷢ���仯������û��Ҫ�ڲ��Խζ������ӳ߶Ȳ���������ѵ���β�ͬ��
7 ���� dropout��Understanding Dropout��
Dropout�������ɾ�������е���Ԫ����Ϊʲô����ͨ����������˴�������أ�
ֱ�������⣺��Ҫ�������κ�һ����������Ϊ�õ�Ԫ�����������ʱ���������˸õ�Ԫͨ�����ַ�ʽ������ȥ����Ϊ��Ԫ���ĸ���������һ��Ȩ�أ�ͨ����������Ȩ�أ�dropout����������Ȩ�ص�ƽ��������Ч������֮ǰ���� �������ƣ�ʵʩdropout�Ľ��ʵ����ѹ��Ȩ�أ������һЩԤ������ϵ��������
�Բ�ͬȨ�ص�˥���Dz�ͬ�ģ���ȡ���ڼ���������Ĵ�С��

�ڶ���ֱ����ʶ�ǣ����Ǵӵ�����Ԫ���֣���ͼ�������Ԫ�Ĺ����������벢����һЩ������������ͨ��dropout���õ�Ԫ�����뼸������������ʱ��������Ԫ�ᱻɾ������ʱ��ɾ��������Ԫ������˵��������ɫȦ�����������Ԫ�������������κ���������Ϊ�������п��ܱ�������������˵�õ�Ԫ������Ҳ�����ܱ����������Ҳ�Ը������ж�ע������һ���ڵ��ϣ���Ը����κ�һ���������̫��Ȩ�أ���Ϊ�����ܻᱻɾ������˸õ�Ԫ��ͨ�����ַ�ʽ�����ش���������Ϊ��Ԫ���ĸ���������һ��Ȩ�أ�ͨ����������Ȩ�أ�dropout����������Ȩ�ص�ƽ��������Ч����������֮ǰ�������������ƣ�ʵʩdropout�Ľ��������ѹ��Ȩ�أ������һЩԤ������ϵ��������
�ܽ�һ�£�dropout�Ĺ���������������
����ͬ���ǣ���Ӧ�õķ�ʽ��ͬ��dropoutҲ��������ͬ�������������ڲ�ͬ�����뷶Χ��
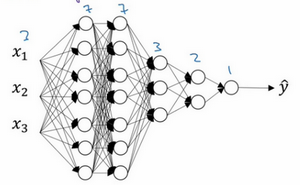
ʵʩdropout����һ��ϸ���ǣ�����һ��ӵ�������������������磬����һ��Ҫѡ��IJ�����keep-prob��������ÿһ���ϱ�����Ԫ�ĸ��ʡ����Բ�ͬ���keep-probҲ���Ա仯����һ�㣬������7��3���ڶ���Ȩ�ؾ���
��7��7��������Ȩ�ؾ���
��3��7���Դ����ƣ�
������Ȩ�ؾ�����Ϊ
ӵ��������������7��7��Ϊ��Ԥ������Ĺ���ϣ�������һ�㣬����Ϊ���ǵڶ��㣬����keep-probֵӦ����Խϵͣ�������0.5�����������㣬����ϵij̶ȿ���û��ô���أ����ǵ�keep-probֵ���ܸ�һЩ��������0.7��������0.7�������ijһ�㣬���Dz��ص��������ϵ����⣬��ôkeep-prob����Ϊ1��Ϊ�˱��������������ɫ�߱ʰ�����Ȧ������ÿ��keep-prob��ֵ���ܲ�ͬ��

ע��keep-prob��ֵ��1����ζ�ű������е�Ԫ�����Ҳ�����һ��ʹ��dropout�������п��ܳ��ֹ���ϣ��Һ����������IJ㣬���ǿ���keep-prob���óɱȽ�С��ֵ���Ա�Ӧ�ø�ǿ���dropout���е����ڴ������� ������
�����dz��Զ�ijЩ��ʩ�и��������Ӽ����Ͻ�������Ҳ���Զ������Ӧ��dropout�������л���ɾ��һ������������������Ȼ��ʵ������ͨ������ô����keep-prob��ֵΪ1���Ƿdz����õ�����ֵ��Ҳ�����ø����ֵ��������0.9����������һ������������Dz�̫���ܵģ�����������������keep-prob��ӽ���1����ʹ��������Ӧ��dropout��
�ܽ�һ�£�����㵣��ijЩ��������������������ϣ�����ijЩ���keep-probֵ���õñ���������ͣ�ȱ����Ϊ��ʹ�ý�����֤����Ҫ��������ij�����������һ�ַ�������һЩ����Ӧ��dropout������Щ�㲻��dropout��Ӧ��dropout�IJ�ֻ����һ����������������keep-prob��
����ǰ��������ʵʩ�����еļ��ɣ�ʵʩdropout���ڼ�����Ӿ������кܶ�ɹ��ĵ�һ�Ρ������Ӿ��е��������dz�������̫�����أ�������û���㹻�����ݣ�����dropout�ڼ�����Ӿ���Ӧ�õñȽ�Ƶ������Щ������Ӿ��о���Ա�dz�ϲ����������������Ĭ�ϵ�ѡ��Ҫ�μ�һ�㣬dropout��һ������������������Ԥ������ϣ���˳����㷨����ϣ���Ȼ���Dz���ʹ��dropout�ģ�����������������Ӧ�õñȽ��٣���Ҫ�����ڼ�����Ӿ�������Ϊ����ͨ��û���㹻�����ݣ�����һֱ���ڹ���ϣ��������Щ������Ӿ��о���Ա���������dropout������ԭ��ֱ��������Ϊ���ܸ�������ѧ�ơ�

dropoutһ��ȱ����Ǵ��ۺ��� ���ٱ���ȷ���壬ÿ�ε�������������Ƴ�һЩ�ڵ㣬�����������ݶ��½������ܣ�ʵ�����Ǻ��ѽ��и���ġ�������ȷ�Ĵ��ۺ���
ÿ�ε������½�����Ϊ�������Ż��Ĵ��ۺ���
ʵ���ϲ�û����ȷ���壬����˵��ij�̶ֳ��Ϻ��Ѽ��㣬��������ʧȥ�˵��Թ���������������ͼƬ����ͨ����ر�dropout��������keep-prob��ֵ��Ϊ1�����д��룬ȷ��
���������ݼ���Ȼ���dropout������ϣ����dropout�����У����벢δ����bug��
8 ������������Other regularization methods��
���� �������ʧ�dropout���������м��ַ������Լ����������еĹ����:

8.1 ��������
�������������è��ͼƬ���������������ͨ������ѵ���������������ϣ����������ݴ��۸ߣ�������ʱ���������������ݣ������ǿ���ͨ����������ͼƬ������ѵ���������磬ˮƽ��תͼƬ�����������ӵ�ѵ��������������ѵ��������ԭͼ�����з�ת�������ͼƬ������ͨ��ˮƽ��תͼƬ��ѵ�������������һ������Ϊѵ���������࣬����Ȼ�������Ƕ����ռ�һ����ͼƬ��ô�ã�����������ʡ�˻�ȡ����è��ͼƬ�Ļ��ѡ�

����ˮƽ��תͼƬ����Ҳ��������ü�ͼƬ������ͼ�ǰ�ԭͼ��ת������Ŵ��ü��ģ����ܱ���ͼƬ�е�è�䡣
ͨ�����ⷭת�Ͳü�ͼƬ�����ǿ����������ݼ����������ɼ�ѵ�����ݡ���ȫ�µģ�������è��ͼƬ������ȣ���Щ����ļٵ�������������ȫ��������ô�����Ϣ����������ô������û�л��ѣ����ۼ���Ϊ�㣬����һЩ�Կ��Դ��ۡ������ַ�ʽ�����㷨���ݣ������������ݼ������ٹ���ϱȽ����ۡ�

�������˹��ϳ����ݵĻ�������Ҫͨ���㷨��֤��ͼƬ�е�è����ˮƽ��ת֮����Ȼ��è�����ע�⣬�Ҳ�û�д�ֱ��ת����Ϊ���Dz������µߵ�ͼƬ��Ҳ�������ѡȡ�Ŵ��IJ���ͼƬ��è���ܻ������档
���ڹ�ѧ�ַ�ʶ�����ǻ�����ͨ���������֣�������ת��Ť���������������ݣ�����Щ�������ӵ�ѵ������������Ȼ�����֡�Ϊ�˷���˵�����Ҷ��ַ�����ǿ���δ�������������4�������Dz��εģ���ʵ���ö�����4����ô���ŵ�Ť����ֻҪ���ı��ξͺã�������������Ϊ���ô�ҿ��ĸ������ʵ�ʲ�����ʱ������ͨ�����ַ��������ı��δ�������Ϊ�⼸��4�������е�Ť�������ԣ�������������Ϊ������ʹ�ã�ʵ�ʹ�����Ҳ���������ơ�
8.2 early stopping
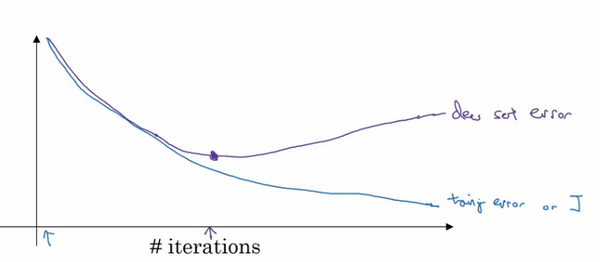
��������һ�ֳ��õķ�������early stopping�������ݶ��½�ʱ�����ǿ��Ի���ѵ������ֻ���ƴ��ۺ������Ż����̣���ѵ��������0-1��¼�������������ʵ����½����ƣ���ͼ��

��Ϊ��ѵ�������У�����ϣ��ѵ�������ۺ��� �����½���ͨ��early stopping�����Dz������Ի���������Щ���ݣ������Ի�����֤��������������֤���ϵķ���������֤���ϵĴ��ۺ���������ʧ�Ͷ�����ʧ�ȣ���ᷢ�֣���֤�����ͨ�����ȳ��½����ƣ�Ȼ����ij���ڵ㴦��ʼ������early stopping�������ǣ����˵���������Ѿ���������������б��ֵúܺ��ˣ������ڴ�ֹͣѵ���ɣ��õ���֤����������ô�������õģ�
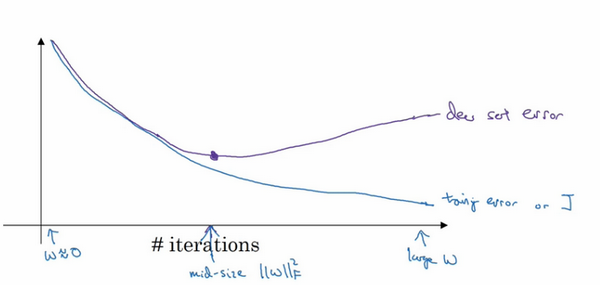
���㻹δ��������������̫��������̵�ʱ���� �ӽ�0����Ϊ�����ʼ��ֵʱ������ֵ���ܶ��ǽ�С�����ֵ���������㳤��ѵ��������֮ǰ
��Ȼ��С���ڵ������̺�ѵ��������
��ֵ����Խ��Խ������������������в���
��ֵ�Ѿ��dz����ˣ�����early stoppingҪ���������м��ֹͣ�������̣����ǵõ�һ��
ֵ�еȴ�С�ĸ��ޱ�����˹��������
�������ƣ�ѡ�����w������С�������磬��Ը��������������ϲ����ء�
����early stopping��������ֹͣѵ�������磬ѵ��������ʱ������ʱ���õ�early stopping��������Ҳ��һ��ȱ�㣬�������˽�һ�¡�
����ѧϰ���̰����������裬����һ����ѡ��һ���㷨���Ż����ۺ���
�������кܶ��ֹ��������������⣬���ݶ��½��������һ���������㷨������Momentum��RMSprop��Adam�ȵȣ������Ż����ۺ���֮����Ҳ���뷢������ϣ�Ҳ��һЩ���߿��Խ�������⣬���������������ݵȵȡ�
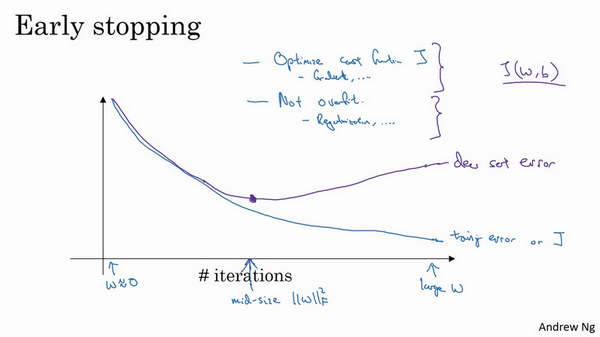
�ڻ���ѧϰ�У���������������ѡ�����е��㷨Ҳ���Խ��Խ���ӡ��ҷ��֣����������һ�鹤���Ż����ۺ��� ������ѧϰ�ͻ��ø������ص��Ż����ۺ���
ʱ����ֻ��Ҫ����
��
��
��ֵԽСԽ�ã���ֻ��Ҫ��취��С���ֵ�������IJ��ù�ע��Ȼ��Ԥ������ϻ������������仰˵���Ǽ��ٷ����һ������������һ������ʵ�֣����ԭ����ʱ����Ϊ������������
��������˵early stopping����Ҫȱ������㲻�ܶ����ش������������⣬��Ϊ����ֹͣ�ݶ��½���Ҳ����ֹͣ���Ż����ۺ�������Ϊ�����㲻�ٳ��Խ��ʹ��ۺ���
�����Դ��ۺ���
��ֵ���ܲ���С��ͬʱ����ϣ�������ֹ���ϣ���û�в�ȡ��ͬ�ķ�ʽ��������������⣬������һ�ַ���ͬʱ����������⣬�������Ľ������Ҫ���ǵĶ�����ø����ӡ�
�������early stopping����һ�ַ������� ����ѵ���������ʱ��Ϳ��ܺܳ����ҷ��֣���³������������ռ�����ֽ⣬Ҳ����������������ȱ�����ڣ�����볢�Ժܶ�������
��ֵ����Ҳ������������
ֵ�ļ������̫�ߡ�
Early stopping���ŵ��ǣ�ֻ����һ���ݶ��½���������ҳ� �Ľ�Сֵ���м�ֵ�ͽϴ�ֵ�������賢��
�����������ĺܶ�ֵ��
��Ȼ
������ȱ�㣬�ɻ����кܶ���Ը���������������ʦ���˸�������ʹ��
ֵ����������Ը�����������Ĵ��ۡ���ʹ��early stoppingҲ�ܵõ����ƽ���������ó�����ô��
�ⲿ�����ݽ������ʹ�������������Լ����ʹ��early stopping�����������еķ����Ԥ������ϡ�