YOLOv4 & scaled YOLOv4
-
- вЛЁЂФПБъМьВтПђМмзмНс
- ЖўЁЂЪ§ОндіЧП
- Ш§ЁЂМЄЛюКЏЪ§
- ЫФЁЂЫ№ЪЇКЏЪ§ & NMS
-
- 4.1 Ы№ЪЇКЏЪ§
- DIOU-NMS
- ЮхЁЂФЃаЭНсЙЙ
-
- 5.1 YOLOv4
- 5.2 Scaled YOLOv4
-
- 5.2.1 Backbone
- 5.2.2 CSPНсЙЙ
- 5.2.3 PANНсЙЙ
- 5.2.4 SPPНсЙЙ
- СљЁЂЪЕбщНсЙћ
- ЦпЁЂВЮПМЮФЯз
ТлЮФЕижЗЧыМћВЮПМЮФЯз
вЛЁЂФПБъМьВтПђМмзмНс
дкYOLOv4ТлЮФжаЃЌзїепЪзЯШЖдЕБЧАФПБъМьВтСьгђЕФФЃаЭНјааСЫзмНсЁЃзїепНЋФПБъМьВтФЃаЭЙщФЩЮЊЯТЭМЫљЪОЕФНсЙЙЃК

зїепНЋФЃаЭЗжЮЊ ЪфШыЁЂbackboneЁЂneckЁЂдЄВтВПЗжЃЌЦфжаDense PredictionМгЧАШ§ВПЗжЮЊone-stageМьВтФЃаЭПђМмЃЌSparse Predition МгЧАШ§ВПЗжЮЊtwo-stage МьВтФЃаЭПђМмЁЃетРяЕФNeckВПЗжжївЊжИЕФЪЧЭјТчжаЖдbackboneЬсШЁЕФЬиеїНјааЖрГпЖШШкКЯ(ШчFPNЕШ)ЛђепНјвЛВНДІРэЃЈзЂвтСІЛњжЦЕШЃЉЁЃВЂЧвзїепвВСаГіРДИїИіВПЗжФПЧАБэЯжНЯКУЕФЗНАИЃЌЫзГЦЁАТжзгЁБЁЃ
YOLOv4жаЦфЪЕУЛгаЬсГіВаВюПщЁЂFPNЕШетжжКмДѓДДаТЕФЗНАИЃЌзїепНЋЩЯУцЕФУПИіВПЗжжаЕНФПЧАЮЊжЙБэЯжБШНЯКУЕФЗНАИНјааХХСазщКЯЃЌНјааДѓСПЪЕбщЃЌзюжебЁШЁСЫзюКУЕФзщКЯЗНЪНЃЌЕУЕНСЫзюКѓЕФYOLOv4ЗНАИЃЌжаМфгавЛаЉЮЂаЁЕФИФНјЃЌКѓУцЛсЯъЯИЫЕУїЁЃ
ЯТУцОЭАДееТлЮФжаЕФЫГађж№вЛНщЩм Ъ§ОндіЧПЁЂМЄЛюКЏЪ§ЁЂЫ№ЪЇКЏЪ§ЁЂФЃаЭНсЙЙвдМАScaled YOLOv4НсЙЙЁЃScaled YOLOv4ЪЧзїепЭХЖгдкYOLOv4ЕФЛљДЁЩЯЖдФЃаЭНјааСЫЕїећЃЌеыЖдВЛЭЌЕФGPUЬсГіСЫYOLOv4-CSPЃЌYOLOv4-largeЃЌYOLOv4-tinyЃЌВЂЧвадФмНЯдYOLOv4вВгавЛЖЈЕФЬсЩ§ЁЃ
ЖўЁЂЪ§ОндіЧП

ТлЮФжаЬсЕНСЫЩЯЭМЫљСаЕФМИжжЪ§ОндіЧПЗНЪНЁЃ
(a)ГЃЙцЪ§ОндіЧПЗНЪНЃЌШчВУМєЁЂа§зЊЁЂЦНвЦЁЂИФБфЩЋЕїЁЂБЅКЭЖШЁЂССЖШЕШЁЃ
(b)MixupЃЌНЋСНеХЭМЦЌвдвЛЖЈЕФБШР§НјааШкКЯЃЌБъзЂАДееБШР§НјааБъзЂЃЌШчЯТУцЕФБэИёЫљЪОЁЃ
(cЃЉCutMixЃЌЫцЛњМєЧавЛеХЭМЦЌКѓгыСэвЛеХЭМЦЌНјааЦДНгЃЌетбљФмЙЛЦШЪЙФЃаЭИљОнФПБъЕФВПЗжЬиеїНјаадЄВт

(d)MosaicЃЌетЫуЪЧYOLOv4жаЪ§ОндіЧПЕФвЛИіССЕуЃЈЫфШЛВЛЪЧзїепЬсГіЕФЃЌЕЋЪЧжЎЧАгУЕФБШНЯЩйЃЉЁЃНЋЫФеХЭМЦЌНјааЫцЛњЫѕЗХЁЂЫцЛњЗжВМЦДНгКЯГЩвЛеХЭМЦЌНјаабЕСЗЁЃMosaicЬсГіЪЧЮЊСЫИФЩЦCOCOЪ§ОнМЏжааЁФПБъЗжВМВЛОљКтЬиЕуЃЌетбљНјааЫцЛњЦДНгФмЙЛдіМгКмЖраЁФПБъЃЌВЂЧвЗсИЛСЫЪ§ОнМЏЃЌФмЙЛЬсЩ§ЭјТчТГАєадЁЃдйепетбљПЩвджБНгМЦЫуЫФеХЭМЦЌЃЌгаРћгкМгПьбЕСЗЃЌВЛашвЊЬЋДѓЕФmini-batchЁЃ

(e)BlurЃЌгыCutMixЯрЫЦЃЌВЛзїЙ§ЖрНщЩмЃЌВЂЧвYOLOv4вВВЂУЛгагУЕНетИіЁЃ
(f)SATЃЌself adversarial trainingЃЌздЖдПЙбЕСЗЁЃдДгкЭМЯёЗчИёзЊЛЛЃЌРћгУСЫЩњГЩЖдПЙЭјТчЯђдЄВтДэЮѓЕФЗНЯђЖдЭМЯёНјааИФЖЏЃЌдйНЋаоИФКѓЕФЭМЦЌЭЖШыФЃаЭНјаабЕСЗЃЌФмЙЛдіЧПФЃаЭЕФТГАєадЁЃ
(g)РрБъЧЉЦНЛЌЃЌвЛИіЭІаТгБЕФЪ§ОндіЧПЗНЪНЃЌжївЊЪЧЮЊСЫвЛЖЈГЬЖШЩЯМѕШѕбЕСЗМЏжаЕФЩйСПБъзЂДэЮѓбљБОЕФИКУцгАЯьЖјЬсГіЕФЃЌЯъЧщПЩвдМћЮвЕФСэвЛЦЊВЉПЭЃКетРяЁЃ
Ш§ЁЂМЄЛюКЏЪ§

YOLOv4жагУЕНСЫМЄЛюКЏЪ§MishКЏЪ§ЃЌЦфЙЋЪНвдМАЧњЯпЭМШчЩЯЭМЫљЪОЁЃ
ДгЭМжаПЩвдПДГіЫћдкИКжЕЕФЪБКђВЂВЛЪЧЭъШЋНиЖЯЃЌЖјЪЧдЪаэБШНЯаЁЕФИКЬнЖШСїШыДгЖјБЃжЄаХЯЂСїЖЏЃЛКЭReLuКЏЪ§ЯрЫЦЃЌMishМЄЛюКЏЪ§ФмЙЛБмУтЬнЖШЯћЪЇЮЪЬтЃЌВЂЧвMishКЏЪ§вВБЃжЄСЫУПвЛЕуЕФЦНЛЌЃЌДгЖјЪЙЕУЬнЖШЯТНЕаЇЙћБШReluвЊКУ
ЫФЁЂЫ№ЪЇКЏЪ§ & NMS
4.1 Ы№ЪЇКЏЪ§
YOLOv4жагУЕНСЫCIOU LossЃЌИУЫ№ЪЇКЏЪ§ЪЧдкDIOUТлЮФжаЬсГіЕФ[3]ЁЃDIOU LossЪЧдкIOUЕФЛљДЁЩЯдіМгПМТЧСЫдЄВтПђгыGound TruthПђЕФжааФОрРыаХЯЂЃЌЖјCIOU ЪЧдкDIOUЕФЛљДЁЩЯдіМгСЫБпПђЕФПэИпБШаХЯЂЁЃЃЈБШНЯШЋУцЃЌЫљвдНаComplete IOU LossЃЉ
ЦфЙЋЪНШчЯТЫљЪОЃК

ОпЬхаХЯЂИааЫШЄЕФЖСепПЩвдШЅПДDIOUЕФТлЮФЁЃ
DIOU-NMS
ЭЌбљЕФЃЌDIOU-NMSвВЪЧдкDIOUЕФТлЮФжаЬсГіЕФЃЌЦфжївЊЫМЯыЪЧдкНјааЗЧМЋДѓжЕвжжЦДІРэдЄВтПђЪБПМТЧDIOUаХЯЂЃЌетРяЬљГіЦфдТлЮФжаЕФЦЌЖЮЃК

ЮхЁЂФЃаЭНсЙЙ
5.1 YOLOv4
YOLOv4ЕФФЃаЭНсЙЙШчЯТЭМЫљЪОЃКЃЈЭМЦЌРДдДгкЦфЫќВЉПЭЃЌЩЯУцгаИУДѓРааХЯЂЃЉ

ПЩвдПДГіећЬхНсЙЙгыYOLOv3КмЯрЫЦЃЌжЛЪЧЖдИїИіФЃПщЖМНјааСЫИФНјЃЌгУгкдЄВтЕФheadВПЗжУЛгаИФЖЏЃЌШдбигУСЫYOLOv3ЕФheadЁЃbackbone ЪЙгУСЫЬэМгСЫCSPНсЙЙЕФdarknet53ЃЌNeckВПЗжЪЙгУСЫPANetНсЙЙЃЌдкЯТУцЕФScaled YOLOv4НсЙЙжаПЩФмИќЧхГўЁЃВЂЧвдкЦфжавВв§НјСЫSPPНсЙЙЃЌетИіРДдДгк2015ФъзѓгвКЮПУїДѓРаЭХЖгЬсГіЕФSPPNetЁЃетМИВПЗжКѓУцЖМЛсНјвЛВННщЩмЁЃ
5.2 Scaled YOLOv4

ШчЩЯЭМЫљЪОЮЊScaled-YOLOv4НсЙЙЃЌПЩЗжЮЊШ§ИіФЃаЭЃЌЗжБ№ЮЊУцЯђдЦGPUЕФYOLOv4-largeЃЌУцЯђГЃЙцGPUЕФYOLOv4-CSPЃЌУцЯђаЁаЭЧсСПМЖGPUЕФYOLOv4-TinyЁЃ
БОЮФНЋжиЕуНщЩмYOLOv4-CSPНсЙЙжаЕФИїИіВПЗжЁЃ
5.2.1 Backbone
YOLOv4вдМАScaled YOLOv4ЕФbackboneЖМВЩгУЬэМгСЫCSPНсЙЙЕФDarkNetНсЙЙЃЌжЛЪЧЦфжаИїПщЕФВуЪ§вдМАЙцФЃВЛЭЌЁЃгЩНсЙЙЭМПЩвдПДЕНЃЌbackboneжївЊгЩCSPblockзщГЩЃЌЖјCSPНсЙЙШЁздгкCSPNetТлЮФ[4]
5.2.2 CSPНсЙЙ
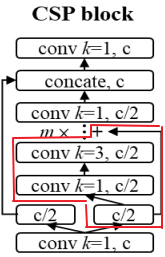
ШчЩЯЭМЫљЪОЮЊвЛИіCSPblockНсЙЙЃЌЖјЭМжаКьПђЧјгђБэЪОЮЊвЛИіВаВюПщНсЙЙ[5]ЃЌЭМжаЕФ m БэЪОетИіCSPblockжаВаВюПщЕФЪ§СПЁЃ
ЧАЮФвВЬсЕНСЫCSPРДдДгкCSPNetЃЌетвЛНсЙЙЙЄзїдРэШчЩЯЭМЃЌЪфШыЬиеїЭМЪзЯШОЙ§вЛИі1ЁС1ОэЛ§ВуЃЌЖјКѓНЋЕУЕНЕФЬиеїЭМдкЩюЖШЮЌЖШЩЯвЛЗжЮЊЖўЃЌвЛВПЗжЪфШыЕНКѓајОэЛ§ВужаНјааДІРэЃЌЖјСэвЛВПЗжжБНгЬјВугыЕквЛВПЗжЖрДЮОэЛ§КѓЕФНсЙћНјааЦДНгзїЮЊетвЛblockЕФЪфГіНсЙћЁЃетбљзіЕФжївЊФПЕФЪЧЮЊСЫМѕЩйМЦЫуСПЁЃЭЈЙ§МЦЫуЕУЕНЯрБШгкDarkNetЃЌCSPDarkNetФмЙЛМѕЩйдМ50%ЕФМЦЫуСПЃЌДѓЗљЬсИпСЫМЦЫуЫйЖШЃЌВЂЧвЪЕбщНсЙћжЄУїзМШЗЖШВЂЮоЖдзМШЗЖШВЂЮоДѓЗљгАЯьЁЃ
жЕЕУвЛЬсЕФЪЧЃЌYOLOv4-CSPжаЕФCSPНсЙЙВЂВЛЪЧжБНгНЋЬиеїЭМЗжЮЊСНВПЗжЗжБ№ДІРэЃЌЖјЪЧЩшЖЈзюГѕЕФ1ЁС1ОэЛ§ВуЕФЪфГіЭЈЕРЮЊc/2ЃЈдЭЈЕРЪ§ЮЊcЃЉ,ЖјКѓдйНЋЦфЗжБ№ЪфШыЕНКѓајОэЛ§ВувдМАЬјВугУгкconcatВйзїЁЃ
5.2.3 PANНсЙЙ

ШчЩЯЭМЫљЪОЮЊYOLOv4-CSPЕФЭјТчНсЙЙЃЌЦфжаЕФNeckВПЗжЮЊPANНсЙЙЃЌheadВПЗжЃЈЭМжаЕФЛвЩЋВПЗжЃЉбигУYOLOv3ЕФheadЁЃ
PANНсЙЙШчЯТЭМЫљЪОЃК

етвЛНсЙЙРДдДгкЗжИюСьгђЕФPANet[6]ЃЌЦфМђвЊРДЫЕЪЧдкFPNЕФЛљДЁЩЯдіМгСЫвЛИіздЕзЯђЩЯЕФДЋЪфТЗОЖ(Bottom-up Path Augmentaion)ЁЃвђЮЊЕзВуЬиеїИќФмЬсЙЉБпдЕЕШЯИНкЬиеїЃЌИпВуЬиеїИќЬсЙЉЩюЖШЕФгявхЬиеїЃЌFPNдкДЋЭГЕФОэЛ§ЭјТчЛљДЁЩЯдіМгСЫздЩЯЖјЯТЕФЬиеїШкКЯЭЈЕРЃЌФмЙЛдіМгИпЮЌЬиеїЕФРћгУТЪЃЌвђЮЊЗжИюЕФ=ашвЊЯёЫиМЖБ№ЕФзМШЗЖШЃЌвђДЫPANдкFPNЛљДЁЩЯдіМгздЯТЖјЩЯЕФЭЈТЗвдЬсЩ§ЖЈЮЛОЋЖШЁЃ
~
дкYOLOv4жаЃЌЖдPANНсЙЙНјааСЫвЛДІаЁЕФИФНјЃЌдкВЛЭЌГпЖШЬиеїШкКЯЪБВЂУЛгаВЩгУдБОЕФжБНгЯрМгЕФЗНЪНЃЌЖјЪЧВЩгУСЫconcatЗНЪННЋЬиеїЭМНјааЦДНгЃЌШчЯТЭМЫљЪОЃЌзѓВрЮЊдРДЕФЯрМгШкКЯЃЌгвВрЮЊYOLOv4ЕФШкКЯЗНЪНЃК

5.2.4 SPPНсЙЙ
ДгНсЙЙЭМжаПЩвдЗЂЯжЛЙгавЛИіCSPSPPПщЃЌетЪЧдкCSPblockЕФНсЙЙжадіМгСЫSPPНсЙЙзщГЩЕФЁЃSPPРДдДгкКЮПУїЭХЖгЬсГіЕФSPPNetЃЌетЦЊТлЮФЕФЗЂБэЪБМфЛЙдкfast-RCNNжЎЧАЃЌВЂЧвfast-RCNNвВЪЧдкЦфЛљДЁЩЯБЛЬсГіЕФЁЃ
ЕБЪБЩёОЭјТчжаАќКЌШЋСЌНгВуЃЌНјЖјЕМжТЭјТчЪфШыЭМЦЌДѓаЁБиаыЮЊЙЬЖЈГпДчЃЌSPPНсЙЙзюГѕдкSPPNetжаБЛЬсГіОЭЪЧЮЊСЫНтОіДЫЮЪЬтЖјЬсГіЕФЁЃ
SPPNetжаSPPНсЙЙШчЯТЃК

ПЩвдПДЕНзюПЊЪМЕФSPPНсЙЙЪфГіЮЊвЛИівЛЮЌЯђСПЃЌгУгкЪфШыЕНШЋСЌНгВуЁЃЦфжївЊЙЄзїдРэЮЊЃКНЋЪфШыЬиеїЭМдкВЛЭЌГпЖШЩЯЛЎЗжЮЊМИИіЧјгђЃЌР§Шч1ЁС1ЃЌ2ЁС2ЃЌ4ЁС4ЃЌШЛКѓЗжБ№ЖдетУПвЛИіаЁПщНјаазюДѓГиЛЏЃЌзюКѓЕУЕН1+4+16 ГЄЕФЯђСПЁЃ
дкКѓРДЕФИїжжШЋОэЛ§ЭјТчжаЖдSPPНјааСЫеыЖдШЋОэЛ§ЭјТчЕФИФНјЃЌИФНјКѓЕФНсЙЙШчЯТЭМЫљЪОЃК

дкНјааГиЛЏВйзїЪБЖдЬиеїЭМЪзЯШНјааСЫPaddingКѓдйНјааВНГЄЮЊ1ЕФГиЛЏЃЌвђДЫГиЛЏКѓЕУЕНЕФЬиеїЭМгыдЬиеїЭМДѓаЁЯрЭЌЃЌЖјКѓдйНЋетаЉЕУЕНЕФЬиеїЭМconcatЃЌЪфШыЕНКѓУцЕФОэЛ§ВужагУгкМЦЫуЁЃ
YOLOv4етРяв§НјSPPНсЙЙЕФжївЊдвђЪЧSPPНсЙЙФмЙЛдіДѓИаЪмвАЃЌВЂЧввВФмЙЛШкКЯВЛЭЌГпЖШЕФЬиеїЁЃ
СљЁЂЪЕбщНсЙћ



ЪЕбщНсЙћШчЩЯУцМИЭМЫљЪОЃЌзїепЛЙзіСЫДѓСПЕФЯћШкЪЕбщРДбщжЄИїИіВПЗжЕФбЁдёЪЧЗёзюгХЃЌОпЬхНсЙћИїЮЛЖСепПЩвддкТлЮФдЮФжаПДЕНЁЃ
ЦпЁЂВЮПМЮФЯз
[1] YOLOv4
[2] Scaled YOLOv4
[3] DIOU
[4] CSPNet
[5] ResNet
[6] PANet
зюКѓЃЌШчЙћЮФжагаДэЮѓЕФЕиЗНЛЙЧыДѓРажИе§