AVR:Attention based Salient Visual Relationship Detection
arXiv2020
我是目录?
-
- 针对问题
- 算法思想
- 算法内容
-
- Predicate Prediction Module
- Attention Module
- 利用数据集先验知识部分
针对问题
以前的工作都对一幅图像中所有可见的关系都一视同仁,而一些不重要的关系会对结果在一定程度上造成影响,因此需要筛选出更显著(salient)的关系对。
算法思想
结合视觉特征、语义信息(类别标签)、空间信息(位置)预测关系并计算各个关系的显著性(或者说重要性)程度。然后该重要程度会用于计算损失函数,越重要的关系损失越小,反之越大。算法中还进一步提取数据集的先验知识,并与预测结果结合作为最终结果。
算法内容
场景图生成任务可以视为由图像计算得到主语目标S, 宾语O, 以及对应的类别标签Cs, Co, 还有主宾之间的关系P
文中提出,预测结果的条件概率可以表示为如下的形式:
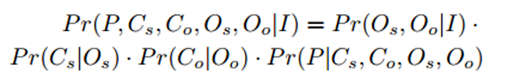
右侧后三项分别表示主语、宾语以及关系的类别置信度,而右式的第一项作者认为是对目标对(Os, Oo)的关注程度的概率
这种理解真的对吗…
右式第2、3项与目标检测类似可以直接由faster R-CNN得到,然后剩下的任务就是要计算 右式的第一项和最后一项
论文提出了两个模块Attention Module 和 predicate prediction Module分别计算上述两个概率值


Predicate Prediction Module
本模块用来求上面说到的最后一项,即预测主宾的谓词,这一部分与其他论文的网络结构比较相似,都是结合主语、宾语、谓词的视觉特征+bbox位置信息+类别的词向量编码预测关系谓词,这一模块使用交叉熵损失,形式如下:
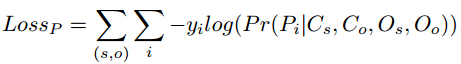
Attention Module
这一模块为本论文的主要工作之一,因为前文提到想要让网络更偏重于“重要的”关系对,因此就需要计算每个关系对的显著性指标e(s,o),经过softmax就得到了
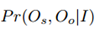
(两者其实是一样的)
网络结构如Figure4的b图所示,对于每一对目标,将其主语、宾语、谓词的视觉特征+整个图片的特征图结合在一起计算显著性指标e(s,o)(这里整幅图的特征图可以视为加入了全局上下文信息)
计算出显著性指标后需要与真实标签对比,即损失函数,这里作者将评判重要程度视为一个二分类问题:重要or不重要, 对应的损失函数如下:
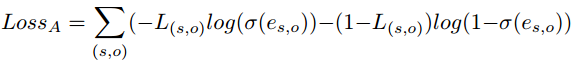
这里L(s,o)为真实标签:如果这一目标对在GT中存在,就为1,即重要目标对,否则为不重要目标对。
吐槽一下,论文开头说的是对关系的重要程度进行衡量,但是这里明显是计算目标对的重要程度。。。这两者还是有区别的。衡量关系的重要程度会让人理解为对每一个预测出的关系谓词计算显著性指标
将上述两部分的损失相加就是最终的损失函数。
利用数据集先验知识部分
作者还结合了数据集的先验知识来提升检测准确率。

将数据集GT中的每一类关系谓词都视一个节点,每一类<主-宾>的目标对也视为一个节点。
目标对节点 < s-o > 与谓词节点p 之间的边代表了这一类< s-o >之间的关系为p 在数据集中出现的次数。另外在目标对节点之间还增加了边,用来衡量目标对的相似程度(有点motif的思想)
使用时采用了随机漫步算法(random walker)来计算从谓词节点p走到目标对< s-o >的概率,在计算的时候可以化为矩阵相乘的形式来计算,解释起来有点麻烦,直接贴论文原文:

在得到关系对 < s-p-o > 的先验概率后,将其与之前预测的结果相乘得到最终结果:
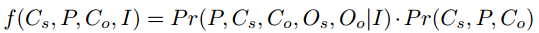
这种感觉会加剧长尾效应?尾部类的概率本身就小,再乘以一个更小的先验会更小…
这种方式感觉只是引入了目标对之间的关系信息,有点类似于显式的motifs思想
实验结果就不放了,作者分别在VRD、VG-VtransE、VG-MSDN数据集上做了实验,并没有展示在VG150数据集上的结果,和一些关键工作(例如VCTree, motifsNet)无法对比,(个人感觉不会太好。。。),就当只是学习一下思想吧