����
��һƪ���ļ�ƪ����Կ�����������Ҫ������������ݶ����Ŷ������Ż����������ܱ�֤�µ��Ŷ�����������֣�ȴ�����ģ�͵����ܡ���һƪ���ǽ�����һЩ������˼�ĶԿ������������ɣ��������ؼ�����Ŷ��Լ��������ɣ�DeepFool��One pixel attack��Universal adversarial perturbations��ATN����
DeepFool: a simple and accurate method to fool deep neural networks
����
��������˼��������ԭʼͼ�����˶���ľͿ�����ƭAIģ���أ�����˵�����ǣ���ξ����ٵ���ԭʼͼ��Ϳ��Դﵽ��ƭAIģ�͵�Ŀ���أ�����֮�����Ŷ���С���ٺ��ʣ�ȡֵ��С�����㷨Ч�������ܴ�Ӱ�죬��ô���������㷨���Ա���������⡣
�㷨
�����״������һ��������³���Ե�����ָ�꣬����ͼ������xxx��������$k^(?)\hat k\left( \cdot \right)k^(?)���Կ��Ŷ�rrr����ô�÷�������xxx³��������ָ��Ϊ��
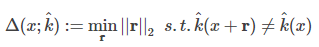
�÷�����������³����Ϊ��
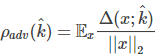
���ڶ��������⣺
�����߽�Ϊ��?={x:f(x)=0}\ell = \left\{ {x:f\left( x \right) = 0} \right\}?={
x:f(x)=0}���Ŷ�����Ϊr(x0)=arg?min?��r��2r\left( {
{x_0}} \right) = \arg \min {\left\| r \right\|_2}r(x0?)=argmin��r��2?������sign(f(x0+r))��sign(f(x0))=?f(x0)��w��2wsign\left( {f\left( {
{x_0} + r} \right)} \right) \ne sign\left( {f\left( {
{x_0}} \right)} \right) = - {
{f\left( {
{x_0}} \right)} \over {
{
{\left\| w \right\|}_2}}}wsign(f(x0?+r))??=sign(f(x0?))=?��w��2?f(x0?)?w��
���ǽ���ԭͼ��ʾ�������ʽ

��������Ĺ�ʽ�Ϳ�������Ϊ����������߽����̾��롣
���ڶ�������⣺
�����������Կ������������������Ĺ�ͬ���á���ͬ������һ����������Ҫ�õ�һ�����ij���ຯ���߽����С���롣
l^(x0)=arg?min?k��k^(x0)�Ofk(x0)?fk^(x0)�O��wk?wk^��2\hat l\left( {
{x_0}} \right) = \arg \mathop {\min }\limits_{k \ne \hat k\left( {
{x_0}} \right)} {
{\left| {
{f_k}\left( {
{x_0}} \right) - {f_{\hat k}}\left( {
{x_0}} \right)} \right|} \over {
{
{\left\| {
{w_k} - {w_{\hat k}}} \right\|}_2}}}l^(x0?)=argk??=k^(x0?)min?����?wk??wk^?����?2?�O�O?fk?(x0?)?fk^?(x0?)�O�O??
�������е�ͼʾ�������£�

�������㷨�����������£�

ʵ��

�������ʵ����������deepfool��������FGSM�������ǹ�����ȷ�ʻ����ڽ����Ŷ����档
One pixel attack for fooling deep neural networks
����
��������˼��һ�����ؼ������е�ԭ��
- ��Ȼͼ������ķ�������ǰͨ�����ƹ̶������������ȷ�����ȻͼƬ�������磬ͨ���Ŷ���ÿ������������һЩС�ı仯����ͼ�����Χ������η�Χ�ڵĶԿ�������ͬʱ�����������Ŷ����Կ����Ƕ�����ռ��Խϵ�ά�Ƚ����з֣���DNN�����и�ά����ȡ����������ͬ��
- ʵ�ʹ����У��������Զ����صĶԿ���Ϣ��Ч����ǰ�˵Ĺ���û�п��Ա�֤���ĸı䲻���˹۲쵽��һ��ֱ�ӷ�ʽ�Ǿ������ٵ����Ŷ�������������˼������Ŷ����صĸ��������������Ӷ����������������Ƹ��ӵ���ʧ���������Ŷ�������֮������ͨ�������Ŷ����صĸ����������Ŷ������������Ŷ���ǿ�ȡ�������������Σ��������ص�������
����
���������һ���ں�DNN���������Ŷ�һ����ֽ����ĵ������أ�������Ψһ���õ���Ϣ�Ǹ��ʱ�ǩ���������£�
��1����Ч�ԣ���CIFAR-10���ݼ��ϣ�����������������ṹ����Ͻ�����Ŀ�깥������Ч��Ϊ68.71%,72.85%,63.53%��ƽ��ÿ��ͼƬ���Ա��Ŷ�Ϊ1.9��2.3��1.7�������������ImageNet��BVLC��AlexNetģ��������Ч��Ϊ41.22%��
��2����ںй�����ֻ��Ҫ���ظ��ʱ�ǩ��������Ҫ�������ݶȺ�����ṹ���ڲ���Ϣ�ȡ�����ֻ�����˸��ʱ�ǩ��������������ȷĿ��ij���
��3) ����ԣ����Զ��ݶ����Լ���Ͳ�����������й�����
�㷨��ʽ
�Կ�ͼƬ�����ɿ��Կ�����һ�����������Ż����⣬�ٶ�ÿ��ͼƬ������������ʾ��ÿ�������е�Ԫ�ش���ͼ���һ������ֵ��fff��ΪĿ��ͼ�������������һ��nnnά�����룬��x=(x1,x2,?,xn)x = \left( {
{x_1},{x_2}, \cdots ,{x_n}} \right)x=(x1?,x2?,?,xn?)����ԭʼ��ȷ����Ϊttt��ͼƬ�����Ǹ���ԭʼ������Ϊ��Ƶĸ�������Ϊe(x)=(e1,e2,?,en)e\left( x \right) = \left( {
{e_1},{e_2}, \cdots ,{e_n}} \right)e(x)=(e1?,e2?,?,en?)����ô���ڹ��������⣬��Ҫ���Ż����µķ��̣�
maximizefadv(x+e(x)){
{\mathop{\rm maximize}\nolimits} {f_{adv}}\left( {x + e\left( x \right)} \right)}maximizefadv?(x+e(x))
subjuect?to��e(x)��L{subjuect - to\left\| {e\left( x \right)} \right\| \le L}subjuect?to��e(x)����L
������Ҫ��Ϊ�������֣�1����Ҫ���ŵ�ά�ȣ�2��ÿ��ά����Ҫ���Ŷ������������е㲻ͬ�����ڵ����أ�dΪ1,��ǰ�Ĺ�����Ҫ�IJ������ء� ���ڵ����ص��Ŀ��Կ���������nά�����е�һ��ƽ�еķ�������ݵ�����Ŷ���һ����˵���������ع�������������Ƭ��ά������Ŷ���ʵ���ϣ����������Ŷ���ǿ�ȣ��������ؿ��Զ�ͼƬ�е�n��������ж��ά������ǿ�ȵĹ���������ͼ��ʾ��

��ֽ���(DE) ��ֽ����㷨�ǽ�����Ӷ�ģ���Ż�������Ż��㷨��DE����һ��Ľ����㷨����population select�ο��Ա��ֶ����ԣ�ʵ��������ݶȺ����������㷨�����Ӹ�Ч��Ѱ�ҿ��н⣬��ÿ�ε��������У����ݵ�ǰ��population��father�����ɺ�ѡ�⼯�ϣ�child����ÿ�����������Ӧ�ĸ�����бȽϣ�����ȸ�����ʺϣ����������������������ֻ�븸���������бȽϣ��ڱ��ֶ�����ͬʱ���Ի�ýϸߵ��ȶ�ֵ�����ڣ�DE����Ҫ�ݶȵ���Ϣ�����Ż�����ˣ���Ҫ��Ŀ�꺯������֪�Ļ����ǿ��ֵġ����ݶ��½�������Ӧ�õ�������㣨�ɷ֣���̬�����ȣ�������DE�㷨���жԿ�ͼ������������¼����ŵ㣺
I.�����Ը���ĸ����ҵ�ȫ�����Ž�
II.��Ҫ����Ϣ���١�
III�����ԡ�
ʵ��
����˵һ������ָ�ꡣ
Success Rate: �ڷ�Ŀ�깥��������£�������Ϊ�Կ�ͼ�ɹ���Ϊ�����������ı����� ��Ŀ�깥��������£���������Ϊ��ͼ���Ŷ�Ϊһ���ض�Ŀ����ĸ��ʡ�
Adversarial Probability Labels(confidences):�ۼ�ÿ�γɹ��Ŷ�ΪĿ��������ֵ��Ȼ����Գɹ��Ŷ�����������ʾģ�ͶԶԿ�ͼ�����������ࡱ��confidence��
Number of target classes ����ɹ��Ŷ���һ����������ͼƬ�����������䣬����������������Ŷ���ͼƬ����������������Ŀ�깥������Ч�ԡ�

��Ȼ������������ĿԽ��Խ�ã�
Adversarial Transformation Networks: Learning to Generate Adversarial Examples
����
�����е�������У������ݶ���Ϣ���й����ķ���ռ������������������辶���������һ�ַ�����ѵ��һ��������磬��ԭͼ��Ϊ���룬���Ϊ�Կ�������
�㷨
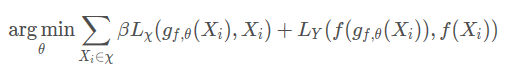
f(x)f\left( x \right)f(x)��ѵ�������ڷ�������磬Ҳ�������ǹ�����Ŀ�ꡣ
gf,��(X){g_{f,\theta }}\left( X \right)gf,��?(X)������Ҫѵ�����������磬����Ϊԭʼ���������Ϊ�Կ�������
Lx{L_x}Lx?��һ����ʧ��������������L2{L_2}L2? Loss��
�������ᵽ���������ɷ�����

ʵ��


���߿����ڹ���ʱ��ͬʱѡ����Model���й�����ѵ����ʽ��֮ǰ������ͬ��ֻ���ڴ�ʱ��Ҫͬʱ�Զ��Model�ֱ���м��㣬����С�����Է��֣�����ѵ��ʱ������ģ��ʱ���乥���ɹ����ʴ���������һ������˶�����δ������ģ�͵Ĺ���������������ˣ������ѵ��ʱ���������ģ�ͽ��й�����������ĶԿ�������Ǩ���������кܴ�ĸ��ʵõ������ġ�
Universal adversarial perturbations
����
������������ĸ�ЧDNN�����������߶���Ϊ����ͼƬʩ��һ���Ŷ���ʹ�÷������Խϴ���ʷ�����Ӷ�ʵ�ֶ���dCNN�Ĺ�����������Ŷ����������ص㣺��.universal�����Ŷ�������ͼƬ�أ�����ģ�ͱ�����ء���.very small������С�ķ������Ӷ����ı�ͼƬ�����Ľṹ�����⣬���������һ���㷨��ʹ�ö��ڲ�ͬ��ģ��VGG��GoogLeNet��ResNet�ȶ�������������Զ�Ӧ���Ŷ���

���¹���
���ĵĹ���������
- ˵����ͨ���Ŷ�ȷʵ����
- ������Ŷ������㷨
- չʾ���Ŷ�����ķ������ܣ�ͨ����С������ͼƬ���Ͼ��������Ŷ���
- չʾ�Ŷ�������������ͼƬ��universal����������ܹ�ͬ����universal
- ������universal perturbations�����ڹ���DNN��һЩ��ѧ����
�㷨
�������ͼƬ����ΪX={x1,x2,?,xm}X = \left\{ {
{x_1},{x_2}, \cdots ,{x_m}} \right\}X={
x1?,x2?,?,xm?}��K^\hat KK^�Ƿ���������������
���Ŷ�����Ϊvvv����Ҫ��������Լ����
��v��p�ܦ�{\left\| v \right\|_p} \le \varepsilon ��v��p?����
Px?��(k^(x+v)��k^(x))��1?��{
{\rm P}_{x \sim \mu }}\left( {\hat k\left( {x + v} \right) \ne \hat k\left( x \right)} \right) \ge 1 - \delta Px?��?(k^(x+v)??=k^(x))��1?��
������\varepsilon��Ϊ�����Ŷ��ķ�������\delta��Ϊ��ƭ�ʡ�
�Ŷ��㷨�������ǻ��ڳ�ʼΪ0���Ŷ�����������ѵ��Ŷ��ģ�
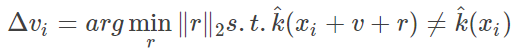
�����㷨����ͼ���£�
