����
����Ӧ�ö�ѧϰ���ź���ϵͳ��֪���źſ��Է�Ϊʱ�ռ����Լ�Ƶ��ȵȡ���Ȼһ������ѧϰ��������ͼ��Ϊ����ģ�͵�����Ϊͼ���������ڿռ�����Ϣ����ô�����Ƿ��������Ƶ����Ϣ������ͼ�����أ�
ת��ΪƵ���������ͨ������Ҷ�任��ʱ����߿ռ���ת����Ƶ����Ҷ�任���ź���Ϣת����ÿ���ɷ�Ƶ���ϵķ��Ⱥ���λ��
��һƪ��CNN��Ƶ��DCTϵ���������ǿ���RGB����ֱ��ѧϰ��������On using CNN with DCT based Image Data����ƪ������ͼ���������������ʵ�飬����MNIST��CIFAR10��Faster Neural Networks Straight from JPEG���On using CNN with DCT based Image Data���ø����ģ�ͣ�ResNet50���ڸ���ķ������ݼ���ImageNet�������������˸����ʵ�顣���ǽ�����ܵ��������Faster Neural Networks Straight from JPEG����Ӧ�ô�ͼ������ع㵽��ʵ���ָ
Learning in the Frequency Domain
ժҪ
����������ڼ�����Ӿ�������ȡ���������ijɹ������е���������Ҫ����������ߴ�̶��Ŀռ�����ʵ��Ӧ���У�ͼ��ͨ���ܴ��뽵������Ԥ���������������С�������²������������˼������������ͨ�Ŵ���������ͬʱɾ���������������Ϣ���Ӷ����¾����½����������źŴ������۵������£����Ǵ�Ƶ�ʽǶȷ�����Ƶ��ƫ������һ�ֻ���ѧϰ��Ƶ��ѡ����ʶ�����ȥ��������ʧ���ȵ�СƵ�ʷ������������Ƶ��ѧϰ����������ResNet-50��MobileNetV2��Mask R-CNN�����������ͬ�ṹ��ͬʱ����Ƶ����Ϣ��Ϊ���롣ʵ�������������þ�̬�ŵ�ѡ���Ƶ��ѧϰ�����ȴ�ͳ�Ŀռ��²����������и��ߵľ��ȣ�ͬʱ��һ����С�����������������������С��ͬ��ImageNet���࣬�÷�����ResNet-50��MobileNetV2�Ϸֱ������1.60%��0.63%��top-1���ȡ���ʹ�������СΪһ�������£��÷������ܽ�ResNet-50��ǰ1λ�������1.42%�����⣬���ǹ۲쵽��ģR-CNN��ƽ�����������0.8%��������COCO���ݼ��ϵķָ
����
- ���ڼ�����Ӿ������ܵ�������Դ�����ơ������ڴ����ƣ������CNNģ��ֻ���ܵͷֱ��ʵ�RGBͼ������224��224����Ȼ�����ִ���������ͼ��ͨ��Ҫ��öࡣ���磬�ִ�����Ϊ�������ȣ�HD���ֱ���ͼ��1920��1080����Խ�С������**ImageNet���ݼ��е�ƽ��ͼ��ֱ���Ϊ482��415��**��Լ�Ǵ����CNNģ�������ܵĴ�С���ı���
- ͼ����С���ɱ���ػᵼ����Ϣ��ʧ�;����½�����ǰ�Ĺ���ּ��ͨ��ѧϰ�����֪����С������������Ϣ��ʧ��Ȼ������Щ���綼���ض�������ģ���Ҫ����ļ��㣬����ʵ��Ӧ�����Dz����ġ�
- �������Ӿ�ϵͳ��HVS���Բ�ͬƵ�ʷ��������еĹ۲�[11]��������������Ƶ���ڷ�����ͼ����ࡢ���ͷָ�������CNNģ�ͶԵ�Ƶ�ŵ���Ƶ�ŵ��������Ը��ߡ�
����
- ���������һ��Ƶ��ѧϰ������ʹ��DCTϵ����Ϊ���룩���÷��������еIJ���RGB�����CNNģ�ͼ�������Ҫ�ġ�������ResNet50��MobileNetV2����֤�����ǵķ�������ͼ�����������Mask R-CNN����֤�����ǵķ�������ʵ���ָ�����
- ���������Ƶ��ѧϰ�ȴ�ͳ�Ŀռ併������������ͼ��ռ��С����Ϊ224��224�������CNNģ�͵�Ĭ�������С����Ԥ�����θ��õر�����ͼ����Ϣ���Ӷ�����˾��ȡ�
- ���Ǵ�Ƶ�ʵĽǶ�������Ƶ��ƫ����������CNNģ�ͶԵ�Ƶ�ŵ��ȸ�Ƶ�ŵ������У������������Ӿ�ϵͳ��HVS����
- �����һ�ֻ���ѧϰ�Ķ�̬�ŵ�ѡ��������ʶ�������������о�̬ȥ����ƽ��Ƶ�ʷ�����
- ��������֪�����ǵ�һ��̽����Ƶ����ѧϰĿ�����ʵ���ָ�Ĺ�����
���ǵķ���ּ�ڼ����������ݵĴ�С��������ģ�͵ĸ����ԡ�
ģ��
���������һ��ͨ�õ�Ƶ��ѧϰ��������������Ԥ������ˮ�ߺ��������ݴ�С��֦������
�ڴ�ͳ�ķ����У��߷ֱ��ʵ�RGBͼ��ͨ����CPU�Ͻ���Ԥ������Ȼ���䵽GPU/AI����������ʵʱ����������RGB��ʽ��δѹ��ͼ��ͨ���ܴ����CPU��GPU/AI������֮���ͨ�Ŵ���Ҫ��ͨ���ܸߡ�����ͨ�Ŵ���������ϵͳ���ܵ�ƿ������ͼ1��a����ʾ��Ϊ�˽��ͼ���ɱ���ͨ�Ŵ���Ҫ���߷ֱ��ʵ�RGBͼ����Ϊ��С��ͼ���������ᵼ����Ϣ��ʧ���Ӷ������������ȡ�

�����ǵķ����У��߷ֱ��ʵ�RGBͼ����Ȼ��CPU�Ͻ���Ԥ������Ȼ�����������ȱ�ת����YCbCr��ɫ�ռ䣬Ȼ��ת����Ƶ��������㷺ʹ�õ�ͼ��ѹ��������JPEG��һ�¡�ͬһƵ�ʵ����з�������ϳ�һ���ŵ����������Ͳ����˶��Ƶ��ͨ����ijЩƵ��ͨ�����������ȵ�Ӱ���������ͨ������ˣ����ǽ���ֻ��������Ҫ��Ƶ��ͨ�������䴫�䵽GPU/AI�����������ƶϡ��봫ͳ������ȣ��÷�����ͨ�Ŵ�����Ҫ��ϵͣ�ͬʱ���нϸߵľ�����
Ԥ������������ͼ��ʾ��ͬ���ռ������д�ͳ��Ԥ�������̺���ǿ���̱ز����٣�����ͼ���С�������ü��ͷ�ת����ͼ�е�spatial resize and crop����Ȼ��ͼ��ת��ΪYCbCr��ɫ�ռ�Ҳ����Ƶ��Ӧ��ͼDCT transform����֮����ͬƵ�ʵĶ�άDCTϵ�����鵽һ��channel�����γ���άDCT�����壨��ͼ�е�DCT reshape���� ͨ��ͨ��ѡ��ѡ����Ӱ��ϴ��Ƶ�����Ӽ�����ͼ��DCT channel select���� YCbCr��ɫ�ռ��е�ѡ��channel��concat��һ�����γ�һ����������ͼ�е�DCT concatenate���� ���ͨ����ѵ�����ݼ�������ľ�ֵ�ͷ����ÿ��channel���й�һ����

������˵����ͼ��8x8�ֿ飬��Yͨ��ÿ�����õ�64��DCT�źţ���Ӧ64����ͬ��Ƶ�ʷ��������ڳߴ�ΪW x H��ԭʼͼ��, ����W/8 x H/8 ���顣ÿ��������ͬλ�õ�Ƶ�ʷ����������һ���ߴ�ΪW/8 x H/8 ��feature map�����������8x8=64��feature map������Cb��Crͨ����Ҳ���Ը��Բ���64��feature map���ܹ�������64x3=192��feature map������W=H=448, ��ô���еĻ���Ƶ���feature map�ijߴ�Ϊ56x56x192������������ResNet-50������Ϊ224x224������һ�ξ�����pooling�� feature map �ߴ�Ϊ 56x56���������ǿ��� 56x56x192 �� ������˵����ͼ��8x8�ֿ飬��Yͨ��ÿ�����õ�64��DCT�źţ���Ӧ64����ͬ��Ƶ�ʷ��������ڳߴ�ΪW x H��ԭʼͼ��, ����W/8 x H/8 ���顣ÿ��������ͬλ�õ�Ƶ�ʷ����������һ���ߴ�ΪW/8 x H/8 ��feature map�����������8x8=64��feature map������Cb��Crͨ����Ҳ���Ը��Բ���64��feature map���ܹ�������64x3=192��feature map������W=H=448, ��ô���еĻ���Ƶ���feature map�ijߴ�Ϊ56x56x192���� feature map �������T�ɡ�

��ͼ����������У�CNNģ��ͨ������224��224��3��״��������������Щ����ͨ���Ǵӷֱ��ʸ��ߵ�ͼ���н������õ��ġ���Ƶ����з���ʱ�����Խ��ϴ��ͼ����Ϊ��������ResNet50Ϊ������Ƶ���е������������ӵ���һʣ��飬�ŵ�������Ϊ192���γ�56��56��192��״������������������448��448��3��С������ͼ�����dct�任���ڿռ����б�224��224��3��С������ͼ����4�������Ϣ������������������С��4����ͬ��������MobileNetV2ģ�ͣ�����������״Ϊ112��112��192���ɴ�СΪ896��896��3��ͼ�����ܡ�
�������������IJ�ͬͨ�����ڲ�ͬ��Ƶ�ʣ������Ʋ�ijЩƵ��ͨ���Ժ�����ͼ����ࡢĿ���⡢ʵ���ָ���������Ϣ����С��ȥ��ƽ����Ƶ��ͨ�����ᵼ�������½�����ˣ����������һ�ֻ���ѧϰ���ŵ�ѡ�����������ÿ������Ƶ���ŵ��������Ҫ�ԡ����Dz��ö�̬��ģ�飬Ϊÿ��Ƶ��ͨ������һ�������Ʒ���������ͨ������Ϊ1������ͨ������Ϊ0���������Ƶ��ͨ����������롣�Ӷ���С���������ݵĴ�С����������ת���ļ��㸴�ӶȺ�ͨ�Ŵ���������ģ���������Ϊģ�͵�һ����Ӧ��������������

��һ���ܵ�ģ���dynamic gate model��ʵ���Ͼ���SE-Net�������SE-Block����ģ��Ϊÿ��channel����һ�������Ʒ����� ����Ϊ�������channel�������з�����������һ�ֳ�ΪGumbel Softmax���ɵ����²������������÷��������ݶ�ͨ����ɢ�������̷�����
��������ʧ�����м���һ����������ƽ����ѡƵ��ͨ������Ŀ������Ŀ�뽻������ʧ���������������ʧһ����С����
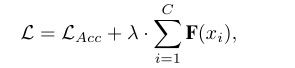

����������ͼ���ӻ������߷����������ĸ����ۡ�
- ���ƵƵ���������ϴ�Ŀ���ȣ���ƵƵ����������С�Ŀ�ѡ��Ƶ�ʸ��ߡ� ����������Ӿ�����������ԣ���Ƶͨ��ͨ���ȸ�Ƶͨ��������Ϣ��
- ��ɫ�ȷ���Cb��Cr�е�Ƶ����ȣ�ģ��Ƶ����ѡ�����ȷ���Y�е�Ƶ���� ��������ȷ��������Ӿ�����������߲ο���ֵ
- ��ͼ�ڷ���ͷָ�����֮�乲��һ������ģʽ�� ��������������۲��������ض���һ�����ܿ��ܶԸ��߲�ε��Ӿ���������ձ���
- ��Щ�۲�����ʾCNNģ�Ϳ���ȷʵ���ֳ��������Ӿ����Ƶ�����������������۵�ͼ��ѹ����������JPEG��Ҳ����������CNNģ�͡�
ʵ��
Ƶ���е����������ɷֱ���Զ���ڿ����Ӧ��ͼ�����ɡ����ǣ�ImageNet���ݼ��е�һЩͼ��ķֱ��ʽϵ͡�����ִ����ռ��������Ƶ�Ԥ�������裬����������С���ü��������ͼ���С������Ҫʱִ���ϲ�����

�������ֻҪѡ��������Ƶ�ŵ����������Ƶ��ѧϰ���ŵ�Ϳ���Ӧ������������ע�⣬�������ݴ�С��Ϊ����ResNet-50��һ�롣����DCT-24S�ṩ���ԺõĽ����ʣ��ľ�̬ѡ����ڽӽ����Ͻǵ�ģʽ��һЩ���½ǵ�ͨ�����ܶ�ʧ����
����ResNet-50��ȣ�ʹ������Ƶ���ŵ�ʱ��top-1���������1.4%����Ӧע�⣬�������RGBת��ΪYCbCr��ɫʱ�����Ȼή�͡�
��һ����Ȥ�Ĺ۲��ǣ�ʹ��һ���Ӽ��ŵ�ѵ����ģ�Ϳ��ܱ�ʹ������192���ŵ�ѵ����ģ�ͱ��ָ��á����ַ�ֱ�۵Ĺ۲���ζ�����������磬24������Ƶ�ŵ����Բ������õ����������Ҹ��ӵ�Ƶ�ʷ�����������������