����
����ʣ�ת���ʣ��������Ĺ�ϵ
����һ��������һ��item������ijЩԭ��������feeds�е�չʾͷͼ�ܳ�����ij��user����ĸ��ʺܵͣ������item���ݱ��������������user��ƫ�ã���user�����ȥ����ô��item��userת���ĸ��ʼ��ߡ�CVRԤ��ģ�ͣ�Ԥ�����������ת�����ʣ�����CTRû�о��ԵĹ�ϵ���ܶ�����һ������Ϊ������֪������user��ijitem�ĵ�����ʺܵͣ���user�����item��ת������Ҳ�϶��ͣ����Dz������ġ���ȷ��˵��CVRԤ��ģ�͵ı��ʣ�����Ԥ�⡰item�������Ȼ��ת�����ĸ��ʣ�CTCVR�������ǡ�����item���������ô����ת�����ĸ��ʣ�CVR��������Dz���ֱ��ʹ��ȫ������ѵ��CVRģ�͵�ԭ����Ϊ����ѹ����֪�������Ϣ����Щunclicked��item���������DZ�user����ˣ������Ƿ�ᱻת�������ֱ��ʹ��0��Ϊ���ǵ�label����ܴ�̶�����CVRģ�͵�ѧϰ��
��ʶ�������CTR����ת����CVR�������Ȼ��ת����CTCVR����������ͬ��������������������ߵĹ�����
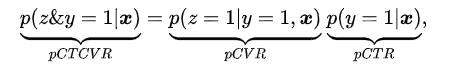
0. ժҪ
ת����(CVR)Ԥ���ǵ����������Ƽ������ؼ�����֮һ����ҵϵͳͨ����Ҫ������ѧϰ�ķ�ʽ����ģ�ͣ��Ը��ϲ��ϱ仯�����ݷֲ������ǣ��ɽ�ת��ͨ���������û�������Ʒ����������������ܻᵼ��label��ȷ�����dz�֮Ϊ�ӳٷ������⡣����ǰ���о��У��ӳٷ���������ͨ����ʱ��ȴ���������������ģ�����ͨ���ڵ�������ʱ�����Ѹ���������Ȼ����֮������ת��ʱ�ٲ������������������ʵ���ϣ��ڵȴ���ȷ��label��ʹ����������֮��������ԣ��������й����в�δ���ǡ�Ϊ������������֮��ȡ��ƽ�⣬��������� (ES-DFM)����ģ�ͶԹ۲�ת���ֲ�(observed conversion)����ʵת���ֲ�(ground truth conversion)֮��Ĺ�ϵ���н�ģ��Ȼ�������ڶ�̬�����ֲ���(elapsed-time sampling)��ͨ����Ҫ�Բ���(importance sampling)���Ż���ʵת���ֲ������������ǽ�һ������ÿ����������Ҫ��Ȩ�أ���CVRԤ����������ʧ������Ȩ�ء�Ϊ��֤��ES-DFM����Ч�ԣ����ǶԹ������ݺ�ҵ���ݼ������˹㷺��ʵ�顣ʵ����֤ʵ�����ǵķ���ʼ��������ǰ�����½����
1. ����
Ϊ�˲����û�����Ķ�̬�仯����ҵϵͳ�����ڶ�ʱ���ڣ���������ѵ���ķ�ʽ��ʹ�����µ�����������ѧϰ��ģ�͡����ڳɽ�ת��ͨ���������û����������������������ʹCVR��Ԥ�����Ӹ��ӡ�Delayed Feedback����ΪCVRģ������ѧϰ������һ�����⣺һ���棬������Ҫ�ȴ��㹻����ʱ�䣬�Ա�۲���Ϣ���Դ��·�ӳ����ʵ�ijɽ�ת��(label corretness)����һ���棬����Ҳ�����ڸ��µ�Ԥ��ģ��(model-freshness)�������Ȩ�����ݵ���ʵ��Ч�Ժ�ģ�͵ļ�ʹ�����⡣
2. ����
����CVRģ������ѧϰ�����������ES-DFM����ģ�Ͷ�observed conversion�ֲ���ground true conversion�ֲ�֮��Ĺ�ϵ���н�ģ�������ǵķ��������붯̬�����ֲ�(elapsed-time sampling)������ͨ�����ͼٸ�����Ȩ�غ�������������Ȩ��������ģ�;�������ƫ�
���ǵ���Ҫ�����Ը������£�
- ��������֪�������ǵ�һ���о�CVRģ������ѧϰ�����£����ƽ��label correctness��model freshness��
- ͨ���Բ���ʱ�佨ģΪ���ʷֲ�������ʵ������ʵת���ֲ�����ƫ���ơ��ر��������ݷֲ��볣�治ͬʱ�����ǵ�ģ��Ҳ��ʾ����³���ԡ�
- �����ṩ��һ���ϸ��ʵ�����ã�������ʽѵ�������������Ը��õ��빤ҵϵͳ����һ�£����ҿ������ɵ�Ӧ����ʵ��Ӧ���С�
3. ģ��
��������£�CVRģ������ѵ������(x,y)�Ļ�����ѵ���ģ���ѵ�������Ǵ�ground truth��p(x,y)p(x,y)p(x,y)�����ݷֲ��еó��ģ��Ӷ��Ż���������ʧ������������ʾ��
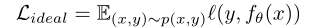
Ȼ���������ӳٵķ������⣬���۲쵽��ѵ������q(x,y)q(x,y)q(x,y)�ķֲ�����ƫ��ground truth p(x,y)p(x,y)p(x,y)�ķֲ�����ˣ�������ʧ���������á�Ϊ�˸���ȷ���ƶ��������ӳٷ������ã���������ͼ������������ʱ������Ӧ��ʱ������������ʱ���ֱ����û�����ij��ʱ�ĵ���ʱ��ctc_tct?������ת������ʱ��ת��ʱ��vtv_tvt?����ȡѵ������ʱ�Ĺ۲�ʱ��oto_tot?��Ȼ��ctc_tct?��oto_tot?֮���ʱ������Ϊ����ʱ��eee����ctc_tct?��vtv_tvt?֮���ʱ������Ϊ�ӳٵķ���ʱ��hhh����ˣ���e>he>he>hʱ��ѵ�������е����������Ϊy=1y=1y=1(��)������e<he<he<hʱ��һЩ������������ر��Ϊy=0y=0y=0��

Ϊ��ʵ�ֶ�ʵ��CVRԤ��Ŀ�����ƫ���ƣ����������һ�������ǵĹ�ȥ�����������Ӧ��������Ҫ�Բ�����������Ҫ�Լ�Ȩ���������ȣ����ͼٸ�����Ȩ�غ�������������Ȩ������������ƫ����Ȼ�������ṩ����ҪȨ�ص�ʵ�ù������������ֹ��������ƫ������˷����������ָ����������ʵ���ʱ��ֲ�p(e�Ox)p(e|x)p(e�Ox)��
ͨ������ʱ��ֲ������������ES-DFM����ģ�ͶԹ۲��ת���ֲ�����ʵת���ֲ�֮��Ĺ�ϵ���н�ģ�����ݣ�

������Ϊ������ӳٷ����������Ҫ����Ϊ���������ӱ�����������ϡ�ٵö࣬���������ӿ���Ϊģ���Ż�ȷ��������ˣ���������У�ֻҪ�û����滥�������ݾͻᱻ���͵���������ǩ��ģ��(����Ѿ����ڼ����ԣ�������ݽ�������)��Ȼ��Ӧ���±���q(y�Ox)q(y|x)q(y�Ox)��������ʾ��

Ϊ�˻���ӳٷ��������е���ƫCVR���ƣ�����ͨ����Ҫ�Բ����Ż��˶�p(y�Ox)p(y|x)p(y�Ox)��������

��Σ����ǽ�һ���ṩ�˽���ľ��������ֲ��µ���Ҫ��Ȩ�ء��ӷ����У����ǿ��Ի�ã�

���Ȩ��CVR��ʧ��������Ҫ��Ϊ��
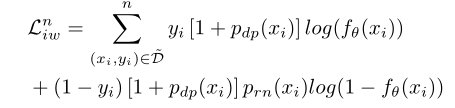
��������У����ǽ�����ֽ�Ϊ�����֣�pdp(x)p_{dp}(x)pdp?(x)��prn(x)p_{rn}(x)prn?(x)����ȷ��˵������ʹ�����������Ʒ��������������������ʡ���������ѵ��һ����������Ԥ���Ϊdelayed positive�ĸ��ʣ���ѵ��һ����������Ԥ���Ϊ��ʵ������
������߶�Ȩ����Ҫ�Խ��з��������ս����ǣ����ǿ��Կ��Ƶȴ�ʱ��ֲ�p(e�Ox)p(e|x)p(e�Ox)������ƫ�����ʵ���������Եĺ��ġ�
4. ʵ����

�ӱ��У����ǿ��Կ�������������ķ��������л��ߵĻ�����������������ܣ��ﵽ�����Ƚ������ܡ�

Ϊ����֤��ͬѡ�������ʱ������ܣ�������Criteo���ݼ���ʹ�ò�ͬ��cֵ������ʵ�顣��ͼ��ʾ��Criteo���ݼ�����õ�c��Լ��15���ӣ���������Թ۲쵽��Լ35%��ת�������⣬�ϴ���С��c���ή�����ܡ��ڽ�С��cʱ�������½�������˵����Ҫ�Լ�Ȩģ�������ƫ���С����c�ϴ�ʱ�������½��ø��죬�������c����ʱ�����ݵ����ʶȸ���Ҫ������c����1Сʱ�����������ܡ�
�����ò�ͬ�ĸ���ǿ��d������ʵ�飬�����ʾ��ͼ�С����ǿ��Կ�������FNW��FSIW��ȣ����ǵķ������и�ǿ�Ŀ������������������Ÿ��ŵ�����(��������NLL��)�����ܲ��Ҳ����