���ĵ�ַ��https://arxiv.org/abs/1704.02447
code:https://github.com/xingyizhou/pytorch-pose-hg-3d
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
Xingyi Zhou1,2, Qixing Huang2, Xiao Sun3, Xiangyang Xue1, Yichen Wei3
��Ұ�����3D������̬���ƣ�һ�����ල����
ժҪ
�ڱ����У������о���Ұ����ά������̬���Ƶ����� ����ȱ��ѵ�����ݣ������������ս�ԣ���Ϊ�������ݼ�Ҫô�Ǿ���2D���Ƶ�Ұ��ͼ��Ҫô�Ǿ���3D���Ƶ�ʵ����ͼ��
���������һ�����ලת��ѧϰ�������÷�����ͳһ��������������ʹ�û�ϵ�2D��3D��ǩ���������������ṹ�� ���ǵ�����ͨ��3D��Ȼع���������ǿ�����Ƚ���2D��̬���������硣 ��֮ǰ�İ�˳��ͷֿ�ѵ�����η�����ͬ�����ǵ�ѵ��������������˵��˲��������2D��̬����ȹ���������֮�������ԡ� ͨ��������ʾ���Ը��õ�ѧϰ��������� ��������ʱ�������Ƶ�ʵ���һ����е�3D���Ʊ�ǩ��ת�Ƶ�Ұ��ͼ���С� ���⣬����������3D����Լ�����淶3D��̬Ԥ�⣬����û�е���ʵ����ȱ�ǩ�����������Ч�ġ� ���ǵķ�����2D��3D��������ʵ�����о������Ľ����
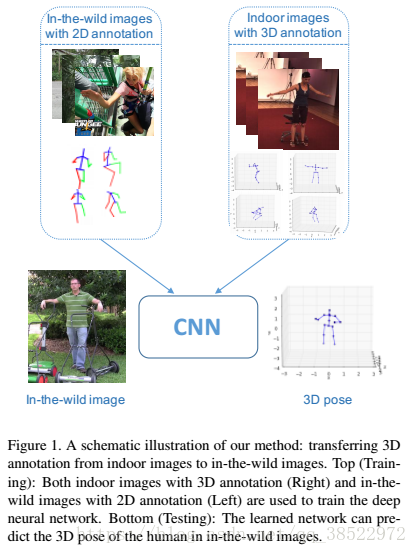
- ���
�������ƹ����������ڼ�����Ӿ��еõ��˴����о��� �����˻�������������ʵ�Ͷ���ʶ������������Ҫ��Ӧ�á� ���е��о�������Ϊ���ࣺ2D��̬���ƺ�3D��̬���ơ� ���ڴ��ģ2D��ע�������ƵĿ����Ժ����������ij��֣�2D�������ƹ����������ȡ���˾�ijɹ�[17,29,11,4,7]�� ���Ƚ��ļ����ܹ��ڸ���������ʵ��ȷ��Ԥ�⣨���磬Ұ��ͼ��[2]����
���֮�£�3D�������ƹ��ƵĽ�����Ȼ���ޡ� ����ԭ�������ڴӵ���ͼ��ָ�3D��Ϣ��ģ���ԣ�����һ����ԭ��������ȱ�ٴ��ģ3D���Ʊ�ע���ݼ��� ȷ��˵����û�����Ұ��ͼ���ȫ���3D�����������ݼ��� ���õ�3D���ݼ�[12,24]���ܿ�ʵ���һ����е�mocapϵͳ��ȡ�� ����Щ���ݼ���ѵ�������������[13,33]�����ܺܺõ��ƹ㵽����ʵ����������Ұ�⡣
mocapϵͳ�����˽⣺https://www.jianshu.com/p/5b35493c386f
https://zhuanlan.zhihu.com/p/37415840
��Ұ���Ѿ��кܶ����3D�������ƹ��ƵĹ����� ����ͨ�������������������[34,26,5,3,30,31]�� ��һ������2D�ؽ�λ��[17,29,11]�� �ڶ�������Щ2D�ؽ�[21,32,1]�ָ�3D���ơ� �����������ѵ���Ƿֿ����еġ� ������Ұ���2D��עѵ��2D����Ԥ�⣬���Ҵ����е�3D MoCap����ѵ������2D�ؽڵ�3D���ƻָ��� ������˳����ˮ����Ȼ�Ǵ��ŵģ���Ϊ�ڵڶ����ж����˰�������3D���ƻָ��ķḻ��ʾ��ԭʼҰ��2Dͼ����Ϣ��
�����Mehta���ˡ� [15]�Ѿ�������2D��3D֪ʶת�ƣ���ʹ��Ԥѵ����2D������������ʼ��3D���ƻع�����������Ÿ���3D���ƹ������ܡ� �����2D��3D���ƹ���������еؾ�����һ���ҿ��Թ�����ͬ�ı�ʾ
���������������������Ϊ����֪ʶ��Եת�ƣ���������ͼ���3Dע�͵�Ұ��ͼ��ΪҰ��3D��̬Ԥ���ṩ����Ч�Ľ�������� ��������У�����������һ��ͳһ�Ŀ�ܣ���������Ұ��ͼ���е�2Dע����Ϊ3D���ƹ������������ǩ�� ���仰˵�����ǿ���һ�����ල��ת��ѧϰ���⣬����Դ�����������ڻ����е���ȫע��ͼ����ɲ���Ŀ������Ұ��������ͼ����ɡ�
��֮ǰ����Ʒ����[34,26,5,3,30,31]�����ǵ�����Ҳ����2Dģ���3Dģ�顣 Ȼ�������ǵķ������ǽ�����2Dģ��������Ϊ�����ṩ��3Dģ�飬���ǽ�3Dģ����2Dģ����м������������ ���������ǹ���2D��3D����֮��Ĺ�ͬ��ʾ�� ��������ͬʱ����2D��3D���ݶ˵��˵�ѵ���� ��ʹ���ǵĹ������������й�����������
Ϊ�˸��õع淶���ල3D��̬���Ƶ�ѧϰ����������������ѵ��3Dģ��ļ���Լ���� ����Լ������������ʵ����������е���Թ������ȱ��ֽ��ƹ̶��� �����������ڻ����еı��ͼ���3D������Ϣ��Ӧ��Ұ���δ���ͼ��ʱ��ʵ����֤�˸�Լ������Ч�ԡ�
������������¹��ף�
�����״������һ������Ұ��ͼ��Ķ˵���3D�������ƹ��ƿ�ܡ� ���ڼ�����������ʵ�������Ƚ������ܡ�
���Ǵӽ�����2D����ע�͵�ͼ�������������3D��̬���Ƶ�3D����Լ��������е��ڴ�ͼ���ɱ��� �������˹������Ƶļ�����Ч�ԡ�
- ��ع���
�������ƹ����ڹ�ȥ�ѱ������о�[16,23]�������ṩ�����������������˱��ĵķ�Χ�� �ڱ����У����ǽ��ص������ǰ����3D������̬���ƵĹ����ϣ���Щ�����뱾�ĵı�����Ϊ��ء� ���ǻ������۹��ڶ�ѵ��������ʩ����/�ලԼ������ع���
3D�������ƹ��ơ� �������ñ�ǵ����ݣ����磬���������3D�ؽ�λ��[12,24]�������Խ�3D�������ƹ��ƹ�ʽ��Ϊ���ļලѧϰ���⡣ һ�����еķ�����ѵ��������ֱ�ӻع�ؽ�λ��[13]�� ����������Ѿ������ַ����ƹ㵽��ͬ�ķ��� Zhou���ˡ� [33]������ȷִ��Ԥ���еĹdz���Լ����ʹ�����ɵ�ǰ���˶���; Tekin ���ˡ� [25]�����綥��Ƕ����һ��Ԥѵ�����Զ��������� ��֮�෴��Pavlakos����������һ��3D�������÷����ع���3D�Ǽܵ������ʾ[19]�� ���ܱ�3D��̬���ƻ����ݼ���������ߣ���������Ȼͼ������Щ�����ݼ���ʹ�õ��ض�����֮���������죬���õ������粻���ƹ㵽Ұ��ͼ��
�����ά�������ƹ������ݼ���Ұ��ͼ��֮��������ı������ǽ�����ֳ�����������������[34,26,5,3,30]����һ�����������2D�ؽ�λ�á�����������������κ����е�2D�������ƹ��Ʒ��������磬[17,29,11,4]�������ҿ��Դ�Ұ��ͼ������ݼ��н���ѵ�����ڶ���������ع���Щ2D�ؽڵ�3Dλ�á����ڴ˲�����������һ��2Dλ�ã���˿������κλ����ݼ���ѵ��3D��̬�������磬Ȼ�������������н��е�������������2D�ؽ�λ�õ�3D��̬���ƣ�[34]ʹ��EMͨ�������2D��ͼ�����ϡ���ֵ�������3D�Ǽܵ��㷨; [30,19]ʹ��3D�������ݼ���2DͶӰ��ѵ��û��ԭʼͼ�����ͼ��3D��������; Bogo�ȡ� [3]�Ż�����3D����ģ��[14]�����ƺ���״�����ѵ������2DͶӰ;�µ��ˡ� [5]ʹ����������������Ƶ�2D������3D�����Լ����ԴӴ���3D���ƿ��������2DͶӰ�������ͼ��ƥ��;�����Tome���ˡ� [26]�����Ԥѵ���ĸ���3D����ģ�Ͳ㣬�������ɺ�����3D����ģ�ʹ�2D��ͼ��Ȼ��ͨ���Ľ���Щ��ͼ���3D����ͶӰ��ͼ���ܡ�������Щ
Ȼ����������һ����ͬ�ľ��ޣ�3D���ƽ���2D�ؽڹ��ƣ���֪2D�ؽڲ���ģ����������֮�£����ǵķ�����������2D�ؽ�λ���Լ�ԭʼͼ����м�����������
3D������̬���Ƶ���һ�ַ����ǴӺϳ����ݼ��н���ѵ������Щ���ݼ���ͨ��ʹ����֪��3D����ʵ����������ģ��ģ�Ͷ����ɵ�[6,22]�� ��ȷʵ��һ�ֿ��еĽ����������������ս����ζ�3D�������н�ģ����ʹ�ϳ�ͼ��ķֲ�����Ȼͼ��ķֲ���ƥ�䡣 ��ʵ֤�������������ߵ����Ƚ��ķ�������Ȼͼ���ϵľ�����������
�����������û��2D��3D���ݽ���3D�������ƹ��ƵĹ����� Mehta�ȡ� [15]ʹ��3D������Ԥѵ����2D��̬�������硣 Popa���ˡ� [20]��3D������̬������Ϊ���в�ͬ���ݵ�2D����Ȼع�Ķ�����ѧϰ�� ��������Щʹ�����ල��ʧ�Ĺ�����ͬ����Щ��ʧ��ؼ���������2D��ͳһ����е�3D���ݡ�
��/�ǼලԼ������ѵ�����ݲ��������£���Ԥ���м���ͨ�û����ලԼ��������Ϊ������ܵ��������ߡ������뷨ͨ������ͼ������ָ Pathak���ˡ� [18]�����һ��Լ���Ż���ܣ��ÿ�����öԱ�ǩ����֮�͵�����Լ�����������ල����ָ Tzeng�ȡ� [28]������������ʧ��������������ݼ�֮��Ļ������Ӷ������������������Hoffman���ˡ� [10]������ڶԿ���ѧϰ��ȫ������뷽��������������ǩԼ����Ұ��Ӧ����ȫ���ӵ����硣�ڱ����У�����չʾ�����һ�����Ҳ�����������ƹ��ơ���������֪�����ǵķ����ǵ�һ�����ü�������Լ�����淶Ұ��ͼ�����̬�������硣
3.����
3.1���Ź�
����������������RGBͼ�����ǵ�Ŀ���ǹ���3D��������Y��Y3D�������������һ��3D�ؽ������ʾ����Y3D��RJ��3������J�ǹؽڵ������� ������ѭ����I������ľֲ��������ϵ�б�ʾÿ��3D����Ĺ���������ǰ����������ͼ���������꣨������Ӧ��2D�ؽ�λ�ã������������������ǹؽ���ȡ� �������꣬���磬������еĺ��ס�
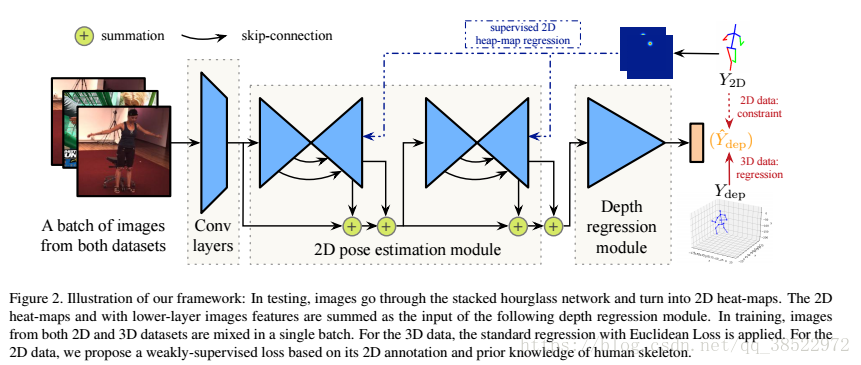
�������������ܹ���ͼ2��ʾ������2D��̬����ģ�飨��3.2�ڣ�����Ȼع�ģ�飨��3.3�ڣ���ɡ� ����Ԥ��2D�ؽ�λ��Y2D��Y2D������Y2D RJ��2�����ֵYdep��Ydep������Ydep RJ��1�ֱ� ���������Y2D��Ydep�Ĵ�����
������ͨ��ʵ�����е�����ͼ��ѵ���ģ�����3D����ʵ��������Y2D��Ydep����Ұ��ͼ������2D����ʵ��������Y2D���� �ڱ��ĵ������У�3D��2Dѵ��ͼ�ֱ��ʾΪI3D��I2D��
3.2�� 2D��̬����ģ��
���Dz���[17]�����Ƚ���ɳ©����ܹ���Ϊ���ǵ�2D��̬����ģ�顣 ���������һ��J�ͷֱ�����ͼ�� ÿ����ͼYHM��RH��W��ʾһ���ؽڵ�2D���ʷֲ��� 2D����Y2D��Y2D�е�Ԥ��ؽ�����Щ��ͼ�ϵķ�ֵλ�á� ������ͼ��ʾ�ܷ��㣬��Ϊ�����Ժ��������
�����ӻ���ͣ��������������ͼ�����磬��ͼ2��ʾ
Ϊ��ѵ�����ģ�飬��ʧ������

��IJ���Ԥ�����ͼYHM��ͨ����˹��[17]�ӵ���ʵ��Y2D��Ⱦ����ͼG��Y2D��֮���L2���롣
3.3�� ��Ȼع�ģ��
�����2D�ؽ�Ԥ��[21,32,1]�ָ�3D�ؽ�λ�õ���ǰ������ȣ����ǵķ����ڣ�i�����ڶ˵�������ѵ����2D��3Dģ��ļ����Լ���ii����������˴��¡� ��ʹ��3D����Լ���������ʧ�� ������������ϸ˵����
����2D��3Dģ�顣 ��ȹ��ƵĹؼ������������Ч������ͼ�������� ��ǰ[34,26,5]�й㷺ʹ�õIJ����ǽ�2D�ؽ�λ����Ϊ���Ԥ���Ψһ���룬��Ϊ�����������ý�Mocap���ݡ� Ȼ�����ò��Ա�������ģ���ģ���Ϊͨ�����ڵ���2D�ǼܵĶ��3D���͡� ���ǽ�����2D�н��2D������ͼ���м�������ʾģ����Ϊ��Ȼع�ģ������롣 ��ЩΪ2D��̬������ȡ��������������Ϣ������Ϊ3D���ƻָ��ṩ�˶���������� ���ֹ����Ĺ�ͬ����ѧϰ�����ǵķ���������Ҫ��
��ά����Լ���������ʧ�� ���ѧϰ��һ����ս�����������ȫ��Ǻ�����ǵ�ͼ�� ������ȫע�͵�3D���ݼ�S3D = {I3D��Y2D��Ydep}��ѵ����ʧ���Լ���ʹ�õ���ʵ����ȱ�ǵı�ŷ�������ʧ�� ��������ǵ����ݼ�S2D = {I2D��Y2D}������������ɼ���Լ��������µ���ʧ�� ��û�е���ʵ����ȱ�ǩ������£��ü���Լ���������Ԥ�����Ч����
�ܵ���˵����Ydep��ʾԤ�����ȡ� ��Ȼع�ģ�����ʧ�ǣ�

���Ц�reg�ͦ�geo����Ӧ����ʧȨ��
Lgeo��Ydep | Y2D���ǽ���ļ�����ʧ�� ���ǻ���������ʵ���dz���֮��ı�������������б�����Թ̶������磬��/�±۾��й̶��ij��ȱȣ���/�Ҽ�ǹ�����ͬ�ij��ȣ���
����أ���Ri�ǹǼ���i�е�һ���漰�Ĺ��������磬 Rarm = {���ϱۣ����±ۣ����ϱۣ����±�}����leΪ��e�ij��ȣ���le��ʾ�淶�Ǽ��й�e�ij��ȣ������ǵ�ʵ���У������趨�� ��Ϊ����3.6M���ݼ�������ѵ����Ŀ��ƽ��ֵ���� ÿ��Ri��ÿ����e�ı���Ӧ���̶ֹ��� �������ʧ����ÿ��Ri��{le le}e��Ri֮��ķ���֮�ͣ�

ע�⣬���������ǹؽ�λ�õĺ��������ؽ�λ������Ԥ����ȵĺ����� ��ˣ�Lgeo�����Ydep�������ҿ��ֵġ� ����������ṩ��ǰ��ͺ��̵���ѧϸ�ڡ���Ҫע�⣬Lgeo�����ڵ���ʵ��2Dλ��Y2D������Ԥ���2Dλ��Y2D�� ��ʹ��ѵ�������ף���Ϊû����2Dģ��ķ�����
�����ǵ�ʵ���У����ǿ���4�������Rarm = {��/����/�ϱ�}��Rleg = {��/����/����}��Rshoulder = {��/�Ҽ��}��Rhip = {��/ ���ι�}�� ���Ƿ��������������ϲ�������������Ϊ���Ƿ��������ڲ�ͬ��������״�ϱ��ֳ���ԽϸߵĹ������ȱ仯����ʹ�����ǵ�Լ������ô��Ч�� ע�������ͬ���ϲ����Ӱ�졣
3.4�� ѵ��
��Ϸ���ʽ�е���ʧ�� ��1������2���ͣ�3����ÿ��ѵ��ͼ��I I2D��I3D������ʧ�ǣ�

����ݶ��½��Ż�����ѵ���� ������[28]��[10]��ÿ��С��������2D��3Dѵ������������룩�����������������
��ʵ���У����Ƿ��ִ�ͷ��ʼ�����������ֱ�Ӷ˵���ѵ��Ч�����ѣ���������Ϊ����ģ��֮��������Ժ��¼���Լ���������ʧ�ĸ߶ȷ��������ԡ� ��ˣ����������һ�����ε�ѵ���ƻ������Ƿ�������ʵ���и����ȶ�����Ч�� ��ע�⣬�����Ƕ˵��˵ġ�
��1ʹ��2Dע��ͼ���ʼ��2D����ģ�飬��[17]�������� ��2��ʼ��3D���ƹ���ģ�鲢��2D���ƹ���ģ�顣 ʹ��2D��3Dע�����ݡ� ͨ�����æ�geo= 0 in���������Լ����ʽ2.��3��ʹ���������ݶ���������������� ����Լ�������
4.ʵ������
Ϊ����֤���ǵķ�����ʹ��Human3.6M����[12]��MPII����[2]ѵ������ģ�͡� ������������ͬ�IJ������ݼ��Ͻ��С�
���������������棺�ල��3D�������ƹ��ƣ���4.2�ڣ�����Ұ��ת�Ƶ�3D�������ƹ��ƣ���4.3�ڣ���
���Խ���ܽ��ڱ��С� 5.����MPII��֤���ĸ��ඨ�Խ�������ڲ���������ҵ���
4.1�� ʵ��װ��
4.1.1ʵʩϸ��
���ǵķ�������torch7ʵ�ֵ�[8]�� ɳ©�������[17]�еĹ������롣 Ϊ�˿���ѵ��������ʹ��dz����ɳ©����ÿ��ɳ©��2������2������ģ��[9]�� ��Ȼع�ģ�����4�������IJв�ͻ㼯ģ�飬������Ϊ��ɳ©�� ��ͬ������ܹ�����ѵ�����ǵ�����ʵ���ж�ʹ�õ�����
��3.4���еĵ�һ��ѵ���λ�����240k������Ϊ6.���������һ��2D��̬����ģ�飬��������[17]�����ơ� ��2�ͽ�3�ֱ������200k��40k������ ����ѵ��������һ��Titan X GPU�л��˴�Լ����ʱ��ʹ��CUDA 8.0��cudnn 5.�����е����ݴ�Լ��30ms�� �������æ�reg= 0.1�ͦ�geo= 0.01�� ���ǰ���[17]����������������������
4.1.2���ݼ��Ͷ�����
MPIIѵ���� MPII���ݼ�[2]����ѵ���� ����һ�����ģ��Ұ�������������ݼ��� ��������Ƶ�ռ�ͼ������ע��J = 16��2D�ؽڡ� ������25k��ѵ��ͼ���2957����֤ͼ��[27]�� �����������ñ߽��ע�͡� ����ʹ��MPII��ѵ������ѵ��2D���ƹ���ģ�顣 ��Ҳ�ṩ������ල��Ȼع�ģ�顣
Human3.6M������3.6M���ݼ�[12]����ѵ���Ͳ��ԡ���������3D�������ƹ��ƵĹ㷺ʹ�õ����ݼ��������ݼ�������MoCapϵͳ�����ڻ����в����360���RGBͼ�����ǽ���Ƶ��50f ps�²�����10f ps������ѵ���Ͳ��Լ����Լ������ࡣ��ѭ[13,34,33]�еı�Э�飬
����ʹ��5����Ŀ��S1��S5��S6��S7��S8������ѵ��������2����Ŀ��S9��S11�����в��ԡ������������ڶ�����ؽڵ����֮���ÿ���ؽ�λ����MPJPE����ƽ��ֵ������ʹ����ͶӰ��2Dλ����ѵ��2Dģ�鼰����Ȼع�ģ������ע�͡�
����ʹ��ѵ�������ݼ����ṩ�ĵ���ʵ��2D�ؽ�λ�ã������ʽʹ�����У��Ϣ��������3D��2D���ơ��ڲ����ڼ䣬ͨ��Ҫ������3D�������ȵ��ܺ͵���Ԥ����淶�Ǽܵ��ܺͣ�����Ҫ������У����[19,35]��������������ת���䷽���£�

����Yout����ϵ�2D�����3D�ؽڣ�������������; SumLenout�Ǽ����������ؽڵĹǼܳ���; ��AvgSumLen��һ����������������Ϊ����3.6M���ݼ�������ѵ�������ƽ���Ǽܳ��Ⱥ�
MPI-INF-3DHP�� MPI-INF-3DHP [15]���������3D�����������ݼ��� ��Щͼ����MoCapϵͳ�����ں����ⳡ���в��� ����ֻʹ������Լ���ֽ��������� ���Լ���������6�������2929����Ч֡��ִ��7�������� ��[15]֮�����Dz���ƽ��PCK����ֵΪ150mm����AUC��Ϊ����ָ�꣬��������ؽڣ����裩�� ��ע�⣬���Ǽ���ȫ��Χ��֪����ʵ�������� ���ǹ۲쵽MPI-INF-3DHP�й���λ�õĶ���������ѵ������ʹ�õĶ��岻ͬ��������3.6M��MPII����������ǽ�������β��Թ̶�������0.2������ ��Ϊ���������еĺ��ڴ�����
MPII��֤�� ��ȻMPII���ݼ����ṩ3D����ע�ͣ���������������ʹ������֤�Ӽ�[27]������Ŀ�ġ� ������ѵ�����е�2958��Ұ��ͼ��
���ȣ������ṩ���Ե�3D���ƹ��ƽ����������������ƺ������������ŷ��� �ڲ�������в鿴������Ϣ
��Σ�������Ȼ�����������Ƶ�3D���Ƶļ�����Ч�ԣ������ͨ�����������Լ�����Ľ��� ����ʹ�öԳƹ������ȵIJ��죨���磬���ϱۺ����ϱۣ���Ϊ���������� Ϊ�˼�����������ǽ�2D�ؽڱ���Ϊ256��256���أ��Ա����������ͼ����ֱ�ӻ���Ԥ��Ĺؽڣ��� ��Ȱ���ͬ���������� Ȼ�����Ǽ������ҶԳƹ���֮���L1���룬���磬 �����ϱۣ�����|| Y����磩Y�������䣩|| || Y���Ҽ磩Y�����⣩|||�� �˶�����������MPI-INF-3DHP���ݼ���MPII��֤����������������������ල������ʧ����Ч��
4.1.3�����о��Ļ���
����ʵʩ�����ֻ��߷���������������ķ�����ͬ�ķ�ʽѵ������ģ�͡�
3D / wo geo��ֻʹ��3D��ǵ�������ѵ��Sec��Stage2��Stage3�е����硣3.4�� ��ʹ��Ұ��ͼ�� ��ע�⣬2Dɳ©ģ������Stage1�е�2D���ݼ���Ԥ��ѵ���ġ�
3D / w geo��������Լ���������ʧ���ӵ���һ�������С�
3D + 2D / wo geo������ķ�����Ψһ�������ڣ���ѵ��3Dģ��ʱ������Լ��������2D������ݡ�
������ķ�����ʾΪ3D + 2D / w geo��
4.2�� �ල3D������̬����
�������ȱ���ͷ������ǵķ�����Human 3.6M���ݼ��ϵı���[12]��
���߱Ƚϡ� ��1������ķ������������߽����˱Ƚϡ� ����3D / wo geo��ƽ��MPJPEΪ82.44mm�� ���Ѿ����������Ƚ��ķ������[33,26,35]�� ��ע�⣬�˻�����Metha�������ơ� [15]����3D������2D��̬����[11]������Ϣ���ݡ� ��֮ͬ����������û�ж�ת�ƵIJ�ʹ��1000��ѧϰ��˥���������ǵ�����²����˸�������ܡ�
���Ӽ���Լ������3D / w geo���ṩ�˲������������档
ʹ��2D��3D���ݣ�3D + 2D / wo geo������ѵ����������������� - ƽ��MPJPE����64.90mm������֮ǰ�����й���[15,19]������֤�������ǵ�ͳһ��ѵ���������Դ����Ч�ԡ�
�������ķ���3D + 2D / w geoʵ������ѽ������ע�⣬Լ��Ӧ���ڲ��ཻ��2D���ݼ����������ṩ������֪ʶ��ͨ�õġ����ǻ������˶���ȫ�ල��3D���ݵ�����Լ������������Ƶġ�
������Ұ�ⷽ�����бȽϡ����ǵķ�������������Ұ��ͼ���������������������������ȣ�Chen��Ramanan [5]��MPJPEΪ114.18mm���ܵ��˵�MPJPE�� [35]��79.9���ס� Pavlakos�ȡ� [19]�ṩ��һ������Ľ���汾��Ҳ������Ұ��Ӧ�ã�����MPJPE���ӵ�78.1mm�� MPJPE���ǵķ�����64.90mm�����Ը��á�
Ϊʲô���2D��3D���ݸ��ã� һ�������������ǣ�Ŀǰ�в�������ѵ���ĺô������Ը��õ���ȹ��ƣ��������Ը�ȷ��2D��̬���ơ�
Ϊ�˻ش�������⣬���ǽ�ʹ�ñ�����PCKh@0.5����2D��̬���Ƶ�ȷ�ԣ���[2]���� Tab�еĽ���� ͼ2ʾ�����������������ߺ�������ķ�����2D���Ʒdz�ȷ�� �������ŷ��ر�������2D�������ӵ�ѵ���в��������2D���ȣ�����Ҫͨ���������������ʾʹ��Ȼع�ģ�����档
4.3�� ��Ұ��ת����������
�������������ǵķ����ڲ�ͬ��Ұ����в�����������ݼ����ƹ㡣

4.3.1 MPI-INF-3DHP���ݼ�
�����ֳ�����MPII��Human 3.6M���ݼ����൱�����ת�ơ� ��3�Ƚ��˸��ַ�����MPI-INF-3DHP�����ܡ� ����������£�ǰ���ֻ��߷�������3D / wo geo��3D / w geo�����е����ܡ� �Ⲣ����֣���Ϊ3Dѵ��������������ͼ�� ����ע���ʹ����������£�����Լ����Ȼ��Ч��3D / wo geo��3D / w geo����⡣
3D + 2D / wo geo�ֱ���PCK��AUC�дﵽ65.8��32.1�� ��Щ����������3.6Mѵ������[15]������ͬ�����ݣ�64.7 PCK��31.7 AUC�����ٴ���ʾ������ѵ���ƻ������ơ�
����ķ�����PCK�в���69.2����AUC�в���32.5�� ��Щ���ֽӽ���MPI-INF-3DHP [15]��ԭʼѵ�����ݣ�����PCKΪ72.5��AUCΪ36.5�� ��ʹ����û��ʹ�����ǵ�ѵ�����ݣ����ǵĽ����Ȼ��ǿ�� ��֤ʵ�����ǵķ�����Ұ��ͼ���������
���ǻ����������ҶԳ��ԣ���ڶ���������4.1.2�� ��������� 4���ײ�����ʾʹ�ü���Լ����������˼�����Ч��


4.3.2 MPII��֤���ݼ�
��������������ս�Ե�Ұ��MPII��֤�����������ǵķ����� ��5�еĶ���3D���ƽ���dz�������
������Ч�ԡ� ��ڶ��������� 4.1.2�������������ҶԳƶ����� ��4����ͼ���еĽ���������ǵķ���Ҫ�õöࡣ
2D������3D���ȡ� ����ע����ǵķ������б�ԭʼɳ©ģ���Ե͵�2D�ؽھ��ȡ� �����Ԥ�ڣ���Ϊ���ǵ�ģ��ѧϰ�˶������Ȼع����� Ȼ�������ü���Լ��Ҳ������2D�ؽھ��ȡ� ��������ǵ������ܹ������ּ���Լ����3Dģ�鴫����2Dģ�飬��֤����������������Ŀ��
��


5.δ���Ĺ����ͽ���
�ڱ����У����ǽ�����һ�ֶ˵���ϵͳ����ϵͳ�����Ұ���2D��̬��ǩ���������е�3D���Ʊ�ǩ����Ӧ��Ұ��3D������̬���Ƶ���ս���⡣ ��δ�������Ǽƻ�̽������ķ�/���ලԼ����ʵ�ָ��õĴ��䣬����[10,28]�е���������硣 ����ϣ����������Լ���������ڷ�/���ලת��ѧϰ��Ұ��3D�������ƹ��ƵĹ�����
��л
���Ǹ�лDushyant Mehta��Helge Rhodin��������MPI-INF-3DHP���ݼ�������лDanlu Chen��ͼ2�İ��������⣬���Ǹ�лWei Zhang���������ۡ� ��������ֵõ��˹�����Ȼ��ѧ���𣨣�U1611461����61572138�����Ϻ��п�ѧ����ίԱ�ᣨ��16JC1420401����֧�֡�
�����
[1] I. Akhter and M. J. Black. Pose-conditioned joint angle lim?its for 3d human pose reconstruction. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition, pages 1446�C1455, 2015. 2, 4
[2] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2d human pose estimation: New benchmark and state of the art analysis. In IEEE Conference on Computer Vision and Pat?tern Recognition (CVPR), June 2014. 1, 5, 7
[3] F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero,and M. J. Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. In European Conference on Computer Vision, pages 561�C578. Springer,2016. 2
[4] A. Bulat and G. Tzimiropoulos. Human pose estimation via convolutional part heatmap regression. In European Conference on Computer Vision, pages 717�C732. Springer, 2016. 1,2
[5] C.-H. Chen and D. Ramanan. 3d human pose estimation= 2d pose estimation+ matching. arXiv preprint arXiv:1612.06524, 2016. 2, 4, 6, 7
[6] W. Chen, H. Wang, Y. Li, H. Su, Z. Wang, C. Tu, D. Lischin?ski, D. Cohen-Or, and B. Chen. Synthesizing training images for boosting human 3d pose estimation. In 3D Vision (3DV),2016 Fourth International Conference on, pages 479�C488.IEEE, 2016. 3
[7] X. Chu, W. Yang, W. Ouyang, C. Ma, A. L. Yuille, and X. Wang. Multi-context attention for human pose estimation. arXiv preprint arXiv:1702.07432, 2017. 1
[8] R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, 2011. 5
[9] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770�C778, 2016. 5
[10] J. Hoffman, D. Wang, F. Yu, and T. Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 3, 4, 8
[11] E. Insafutdinov, L. Pishchulin, B. Andres, M. Andriluka, and B. Schiele. Deepercut: A deeper, stronger, and faster multiperson pose estimation model. In European Conference on Computer Vision, pages 34�C50. Springer, 2016. 1, 2, 6
[12] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(7):1325�C1339, jul 2014. 1, 2, 5, 6
[13] S. Li and A. B. Chan. 3d human pose estimation from monocular images with deep convolutional neural network. In Asian Conference on Computer Vision, pages 332�C347. Springer, 2014. 1, 2, 5
[14] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. Smpl: A skinned multi-person linear model. ACM Transactions on Graphics (TOG), 34(6):248, 2015. 2
[15] D. Mehta, H. Rhodin, D. Casas, O. Sotnychenko, W. Xu,and C. Theobalt. Monocular 3d human pose estimation using transfer learning and improved cnn supervision. arXiv preprint arXiv:1611.09813, 2016. 2, 3, 5, 6, 7
[16] T. B. Moeslund and E. Granum. A survey of computer vision-based human motion capture. Computer vision and image understanding, 81(3):231�C268, 2001. 2
[17] A. Newell, K. Yang, and J. Deng. Stacked hourglass net?works for human pose estimation. In European Conference on Computer Vision, pages 483�C499. Springer, 2016. 1, 2, 4,5
[18] D. Pathak, P. Krahenbuhl, and T. Darrell. Constrained convolutional neural networks for weakly supervised segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 1796�C1804, 2015. 3
[19] G. Pavlakos, X. Zhou, K. G. Derpanis, and K. Daniilidis. Coarse-to-fine volumetric prediction for single-image 3d human pose. arXiv preprint arXiv:1611.07828, 2016. 2, 5, 6,7
[20] A.-I. Popa, M. Zanfir, and C. Sminchisescu. Deep multitask architecture for integrated 2d and 3d human sensing. arXiv preprint arXiv:1701.08985, 2017. 3
[21] V. Ramakrishna, T. Kanade, and Y. Sheikh. Reconstructing 3d human pose from 2d image landmarks. In European Conference on Computer Vision, pages 573�C586. Springer, 2012.2, 4
[22] G. Rogez and C. Schmid. Mocap-guided data augmentation for 3d pose estimation in the wild. In Advances in Neural Information Processing Systems, pages 3108�C3116, 2016. 3
[23] N. Sarafianos, B. Boteanu, B. Ionescu, and I. A. Kakadiaris. 3d human pose estimation: A review of the literature and analysis of covariates. Computer Vision and Image Under?standing, 152:1�C20, 2016. 2
[24] L. Sigal, A. O. Balan, and M. J. Black. Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. International journal of computer vision, 87(1-2):4, 2010. 1, 2
[25] B. Tekin, I. Katircioglu, M. Salzmann, V. Lepetit, and P. Fua.Structured prediction of 3d human pose with deep neural networks. arXiv preprint arXiv:1605.05180, 2016. 2
[26] D. Tome, C. Russell, and L. Agapito. Lifting from the deep:Convolutional 3d pose estimation from a single image. arXiv preprint arXiv:1701.00295, 2017. 2, 4, 6
[27] J. Tompson, R. Goroshin, A. Jain, Y. LeCun, and C. Bregler. Efficient object localization using convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 648�C656, 2015. 5
[28] E. Tzeng, J. Hoffman, T. Darrell, and K. Saenko. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision,pages 4068�C4076, 2015. 3, 4, 8
[29] S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4724�C4732, 2016. 1, 2
[30] J. Wu, T. Xue, J. J. Lim, Y. Tian, J. B. Tenenbaum, A. Torralba, and W. T. Freeman. Single image 3d interpreter network. In European Conference on Computer Vision, pages 365�C382. Springer, 2016. 2
[31] H. Yasin, U. Iqbal, B. Kruger, A. Weber, and J. Gall. A dual?source approach for 3d pose estimation from a single image.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4948�C4956, 2016. 2
[32] X. Zhou, S. Leonardos, X. Hu, and K. Daniilidis. 3d shape estimation from 2d landmarks: A convex relaxation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4447�C4455, 2015. 2,4
[33] X. Zhou, X. Sun, W. Zhang, S. Liang, and Y. Wei. Deep kinematic pose regression. In Computer Vision�CECCV 2016 Workshops, pages 186�C201. Springer, 2016. 1, 2, 5, 6
[34] X. Zhou, M. Zhu, S. Leonardos, K. G. Derpanis, and K. Daniilidis. Sparseness meets deepness: 3d human pose estimation from monocular video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4966�C4975, 2016. 2, 4, 5
[35] X. Zhou, M. Zhu, G. Pavlakos, S. Leonardos, K. G. Derpanis, and K. Daniilidis. Monocap: Monocular human motion capture using a cnn coupled with a geometric prior. arXiv preprint arXiv:1701.02354, 2017. 5, 6, 7